SHOUG成员 – ORACLE ACS高级顾问罗敏
本文永久地址为:https://www.askmac.cn/?p=16596
某天与一位新来的销售同事一同去拜访客户,当我们在调研客户数据库系统版本和补丁情况时,销售同事迷惑了。于是,我不得不私下向他简要介绍Oracle数据库版本和补丁的命名规则。他一边听我介绍,一边发出感慨:Oracle版本和补丁也太复杂了!
是啊,像我的销售同事一样,国内很多客户也不了解Oracle复杂的版本和补丁概念,更没有积极主动地进行补丁评估和实施。这也是导致国内很多Oracle数据库系统运行状况不佳的重要原因。
本章就将从Oracle版本和补丁的基本概念讲起,并重点讲述Oracle公司建议的积极、主动地实施补丁计划的策略和方法论,以及相关的最佳实践经验。
16.1 关于Bug和补丁的一个典型故事
2011年在走访某省网通公司时,对其网管部门的一个重要生产系统进行了一番调研。以下就是该系统在上午业务高峰时期最消耗时间的部分语句列表:
| Elapsed Time (s) | CPU Time (s) | Executions | Elap per Exec (s) | % Total DB Time | SQL Id | SQL Module | SQL Text |
| 4,517 | 597 | 22 | 205.33 | 5.72 | 57h0pvsntqc2p | SELECT related_mscserver, subc… | |
| 4,505 | 557 | 24 | 187.70 | 5.71 | 8fk8d1qshkkd9 | SELECT related_mscserver, subc… | |
| 3,836 | 543 | 38 | 100.94 | 4.86 | 5s9qphjwbhjqg | DELETE FROM w_kpi_trunkgroup W… | |
| 3,830 | 563 | 32 | 119.68 | 4.85 | 58qvpgs5n4t2y | DELETE FROM w_kpi_nodeb_rnc_h … | |
| 3,239 | 309 | 16 | 202.43 | 4.10 | b8243sy9bdwmc | SELECT territory_id, subcounte… | |
| 3,182 | 297 | 16 | 198.91 | 4.03 | 3b94wb17m9scp | SELECT territory_id, subcounte… | |
| 1,792 | 188 | 11 | 162.87 | 2.27 | gb7c1tx1rjcwk | SELECT distinct ne_id, start_t… |
从单条语句执行时间分析,几乎都达到100、200多秒,也就是说好几分钟才运行出来。我的妈呀,这是交易系统啊,前台用户难道就没有抱怨?
仔细分析上述第一个语句:
| SQL Id | SQL Text |
| 57h0pvsntqc2p | SELECT related_mscserver, subcounter1, F0059, F0060, F0061, F0063, F0064, F0065, F0067, F0003, F0005, F0008, F0010, F0013, F0015, F0018, F0020, F0025, F0026, F0031, F0032, F0038, F0044, F0045, F0048, F0049, F0051, F0052, F0053, F0055, F0056, F0057 FROM wp_rnc_cause WHERE START_TIME =:1 AND related_mscserver=:2 |
发现应用开发人员已经在wp_rnc_cause表的START_TIME等字段上建立了索引,Oracle应该通过相关索引进行访问,但实际执行计划如下:
| Id | Operation | Name | Rows | Bytes | Cost (%CPU) | Time | Pstart | Pstop |
| 0 | SELECT STATEMENT | 70886 (100) | ||||||
| 1 | PARTITION LIST ALL | 2179 | 183K | 70886 (1) | 00:14:11 | 1 | 25 | |
| 2 | TABLE ACCESS FULL | WP_RNC_CAUSE | 2179 | 183K | 70886 (1) | 00:14:11 | 1 | 25 |
即对wp_rnc_cause表进行不合理的全表扫描。为什么Oracle会选择错误的执行计划呢?仔细分析现象:语句使用了BIND变量,并且wp_rnc_cause表按List进行分区了,再看数据库版本:10.2.0.1,于是猜想可能是撞上Oracle某个Bug了。赶紧上metalink去查询,果然是撞上这个与BIND Peeking功能相关的Bug了:
Bug 4652100: Poor plan with bind peeking for SQL against LIST partitioned tables
该Bug在10.2.0.3 Patchset就修复了。当我与该系统DBA沟通,询问为什么没有安装10g的最新Patchset时,得到的答复是:只要系统没有遇到宕机这样严重问题,否则他们从来不安装什么补丁。—– 这就是国内很多IT系统的现状:很少安装Oracle补丁,更没有积极、主动地制定补丁评估和实施计划,甚至连Oracle版本和补丁的概念都不是很清晰,还担心安装补丁反而导致系统不稳定。一旦真遇到因Oracle Bug所导致的问题,只是一味埋怨Oracle公司,甚至还有点幸灾乐祸:你看,Oracle也有Bug啊。其实,真遇到Bug,最受伤的还是客户自己。
Oracle版本和补丁概念
欲有效防范Oracle Bug的发生,加强Oracle版本管理,并及时安装需要的补丁,首先要弄明白Oracle版本和补丁等概念和术语。其实对大部分客户包括DBA而言,这并不是件容易的事情。
Oracle数据库版本命名规则
Oracle公司从9i之后,对Oracle数据库版本命名规则定义如下:
A.B.C.D
其中第一位(A)表示大版本号,第二位(B)表示小版本号。前两位(A.B)合称示主版本号(Major Version),例如9.2、10.1、11.2等。
对数据库产品而言,第三位(C)永远为0,该位是为Oracle其它产品所使用的。
第四位则表示补丁集(Patche Set)号,例如10.2.0.4、10.2.0.5、11.2.0.2、11.2.0.3等。下面将对Patch Set等各种补丁类型进行详细说明。
Oracle补丁术语
以下就是Oracle各种类型补丁的实施策略、修复Bug数量、发布频度,以及具体含义的综述。
| 类型 | 实施策略 | 修复Bug数量 | 发布频度 | 含义 |
| Patch Set(补丁集) | 主动式 | 1000个以上 | 1次/年 | 补丁集(Patch Set)是Oracle公司经过完整的集成和认证测试之后提供的一组补丁,在 Oracle数据库中以版本的第四位表示。例如11.2版本的第一个Patch Set为11.2.0.2。Patche Set具有累积关系,即10.2.0.5包含了10.2.0.2、10.2.0.3、10.2.0.4的补丁,11.2.0.3包含了11.2.0.2的补丁等。因此,Patche Set可以采取跳跃式安装策略,例如直接在11.2.0.1基础上安装11.2.0.3,无需安装11.2.0.2。
通常而言,除非指定与平台相关的Patch,否则所有平台的相同Patche Set所包含的Patch是一样的。 本表格下面描述的其它 Patch类型都是针对特定Patch Set的。 |
| Update | 主动式 | 50个以内 | 4次/年 (1月,4月, 7月,10月) | Oracle定期发布的比Patch Set要小的一组补丁,发布周期为一个季度一次(1月、4月、7月、10月)。包括如下两类同时发布的补丁:
PSU和CPU补丁都是针对指定Path Set,例如10.2.0.5 、11.2.0.2等版本的 PSU、CPU补丁。PSU和CPU补丁也具有对以前版本的累积关系,例如11.2.0.2.3包括11.2.0.2.1和11.2.0.2.2的补丁。 PSU补丁总是位于Oracle公司的推荐补丁列表之中。 在Windows平台,PSU和CPU补丁的内容则以季度Bundle补丁形式(Quarterly Bundle Patch)进行发布。 |
| Bundle | 主动式或被动式 | 10到100个 | 根据需要 | Bundle补丁则通常是针对某个Oracle特性的一组补丁,该类补丁也具有累积关系
Oracle公司针对Bundle补丁没有定期发布,因此客户主要根据需要采取被动安装的策略。 |
| Interim Patch | 被动式 | 1 | 根据需要 | Interim补丁或称one-off补丁,则是针对某个版本和平台之上一个具体问题的小补丁。
Windows平台没有Interim补丁概念,Windows平台Patch Set补丁集之间的补丁都以Bundle补丁形式发布。 |
16.3 主动安装补丁是防范故障的最有效办法
所谓Bug,就是软件设计和开发过程中存在的一些小错误,而补丁(Patch)就是对这类错误的修复程序。就象我们普通人经常会生点小病一样,我们也经常需要对症下药。但保障身体健康的最有效方法应该是加强体育锻炼、改善营养,保持健康的生活方式,以此来预防疾病发生。与此相似,主动安装补丁也是防范因Bug而导致故障的最有效办法。
在补丁实施策略方面,Oracle公司划分为主动和被动两种。主动式( Proactive)策略就是按照Oracle公司不同类型补丁定期发布的规律,积极评估和分析,并加以实施的策略。而被动式(Reactive)策略则是针对突发问题而被迫采取的实施策略。显然,被动式策略给系统导致的风险和损失可能更大,例如系统异常宕机等,这种异常故障无论是对客户还是对Oracle技术人员而言,面临的难度和压力也更大。
以下就是Oracle公司曾经统计的在10g平台主动安装不同的Patch Set之后,遇到各种Bug的数量:
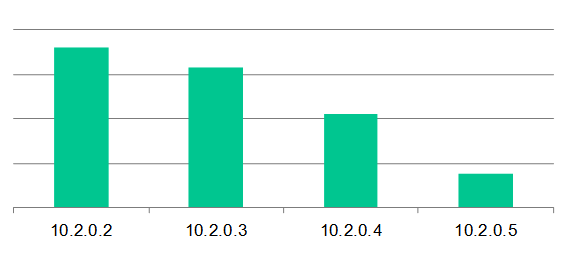
可见,安装的Patch Set越新,遇到的问题逐步下降,系统稳定性也得到显著提高。
除了系统稳定性之外,主动的补丁实施策略还将达到如下目标:
- 主动安装CPU、PSU补丁,将保持系统安全性。
- 符合法律、审计、合规性等业界标准。
- 符合Oracle产品生命周期支持政策。
有关Oracle产品生命周期支持政策详细内容,请访问以下链接:
http://www.oracle.com/us/support/lifetime-support/index.html
该网页详细描述了Oracle针对软件、硬件和操作系统的PS(Premier Support,标准服务)、ES(Extended Support,扩展服务)、SS(Sustaning Support,延伸服务)的含义和内容。例如,以下就是Oracle产品处于PS、ES、SS服务期内所能提供的服务内容:
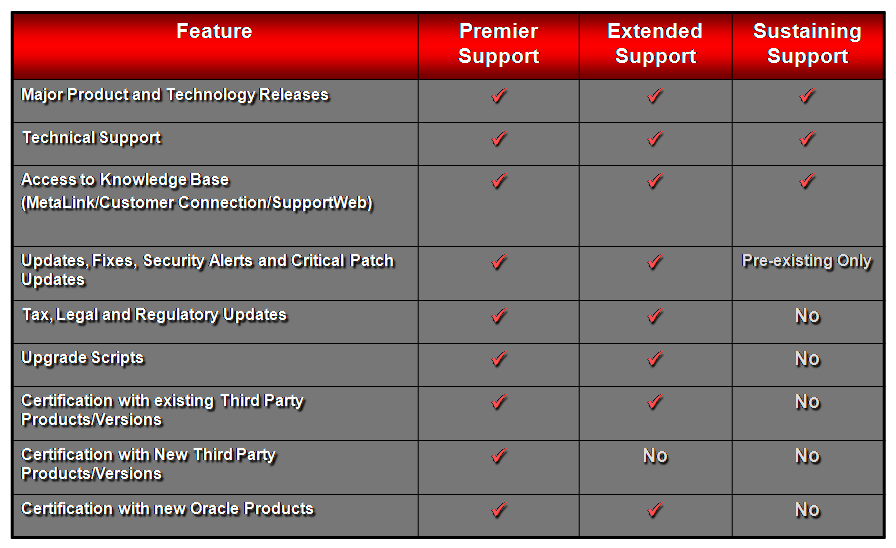
可见,当产品处于PS支持阶段,得到的服务更全面,而且更省钱。而当产品处于ES、SS支持阶段,得到的服务相对少一些,而且需要花费更多的钱。
因此,积极主动升级版本和安装相关补丁,将及时得到PS更全面、更省钱的服务。
16.4 Oracle数据库版本和补丁集发布时间表
欲主动、积极地实施版本和补丁管理,当然需要了解Oracle公司的版本和补丁集发布时间表,方能结合自己应用软件设计、开发进度,合理制定相应的版本和补丁管理计划。
各平台数据库版本发布时间表
以下就是Oracle公司2013年初公布的各平台数据库版本和补丁集发布时间表:
| Platform | 10.1.0.5 | 10.2.0.44 | 10.2.0.53 | 11.1.0.71 | 11.2.0.12 | 11.2.0.2 | 11.2.0.3 | 11.2.0.4 |
| Linux x86 | 30-JAN-2006 | 22-FEB-2008 | 30-APR-2010 | 18-SEP-2008 | 1-SEP-2009 | 13-SEP-2010 | 23-SEP-2011 | 2HCY2013 |
| Linux x86-64 | 24-FEB-2006 | 17-MAR-2008 | 30-APR-2010 | 18-SEP-2008 | 1-SEP-2009 | 13-SEP-2010 | 23-SEP-2011 | 2HCY2013 |
| Linux Itanium9 | 30-APR-2006 | 24-SEP-2008 | 17-MAR-2011 | Platform desupported (see Doc ID 1130325.1) |
Platform desupported (see Doc ID 1130325.1) |
Platform desupported (see Doc ID 1130325.1) |
Platform desupported (see Doc ID 1130325.1) |
Platform desupported (see Doc ID 1130325.1) |
| IBM Linux on POWER | Not planned | 9-JAN-2009 | 17-MAR-2011 | Not planned | Not planned | Not planned (see Doc ID 1310584.1) |
Not planned (see Doc ID 1310584.1) |
Not planned (see Doc ID 1310584.1) |
| IBM Linux on System z | 26-AUG-2006 | 16-DEC-2008 | 3-JAN-2011 | Not planned | Not planned | 30-MAR-2011 | 1-DEC-2011 | Q1CY2014 |
| HP-UX PA-RISC (64-bit) See footnote 8 below regarding future support for this platform |
05-FEB-2006 | 02-JUN-2008 | 15-DEC-2010 | 11-Nov-2008 | 20-MAY-2010 | 15-MAR-2011 | 16-FEB-2012 | Q1CY2014 |
| HP-UX Itanium9 | 07-JUN-2006 | 30-APR-2008 | 3-JUN-2010 | 06-OCT-2008 | 22-DEC-2009 | 19-OCT-2010 | 29-OCT-2011 | 2HCY2013 |
| Oracle Solaris SPARC (64-bit) | 05-FEB-2006 | 30-APR-2008 | 19-MAY-2010 | 06-OCT-2008 | 6-Nov-2009 | 24-SEP-2010 | 1-OCT-2011 | 2HCY2013 |
| Oracle Solaris x86-64 (64-bit) | Not planned | 13-NOV-2008 | 19-MAY-2010 | Not planned | 25-Nov-2009 | 24-SEP-2010 | 1-OCT-2011 | 2HCY2013 |
| IBM AIX on POWER Systems | 05-FEB-2006 | 15-MAY-2008 | 3-JUN-2010 | 06-OCT-2008 | 22-DEC-2009 | 19-OCT-2010 | 29-OCT-2011 | 2HCY2013 |
| Microsoft Windows (32-bit) | 13-FEB-2006 | 17-MAR-2008 | 19-JUL-2010 | 10-OCT-2008 | 5-APR-2010 | 15-DEC-2010 | 11-NOV-2011 | 2HCY2013 |
| Microsoft Windows x64 (64-bit) | Not planned | 16-MAY-2008 | 27-JUL-2010 | 13-NOV-2008 | 2-APR-2010 | 15-DEC-2010 | 11-NOV-2011 | 2HCY2013 |
| Microsoft Windows Itanium (64-bit) 9 | 30-JAN-2006 | 2-FEB-2009 | 12-MAY-2011 | Not planned (see Doc ID 1307745.1) |
Not planned (see Doc ID 1307745.1) |
Not planned (see Doc ID 1307745.1) |
Not planned (see Doc ID 1307745.1) |
Not planned (see Doc ID 1307745.1) |
| Apple Mac OS X (PowerPC) | 08-JAN-2007 | Platform Obsolete | Platform Obsolete | Platform Obsolete | Platform Obsolete | Platform Obsolete | Platform Obsolete | Platform Obsolete |
| Apple Mac OS X (Intel) | Not planned | 10-April-2009 Single Instance only |
Sched TBA | Not planned | Sched TBA | Sched TBA | Q2CY2012 (Instant Client Only) | TBD |
| HP Tru64 UNIX | 18-OCT-2006 | 20-FEB-2009 | 21-Apr-2011 | Platform Obsolete | Platform Obsolete | Platform Obsolete | Platform Obsolete | Platform Obsolete |
| Oracle Solaris x86 (32-bit) | 18-JUN-2006 | 14-Nov-2008 Last patch set for this platform |
Platform Obsolete | Platform Obsolete | Platform Obsolete | Platform Obsolete | Platform Obsolete | Platform Obsolete |
| HP OpenVMS Alpha | 15-FEB-2008 | 15-Dec-2008 | 31-Oct-2012 | Platform Obsolete | Platform Obsolete | Platform Obsolete | Platform Obsolete | Platform Obsolete |
| HP OpenVMS Itanium | Not planned | 15-Dec-2008 | 31-Oct-2012 | Not planned (see Doc ID 1307745.1) |
Not planned (see Doc ID 1307745.1) |
Not Planned (see Doc ID 1307745.1) |
Not Planned (see Doc ID 1307745.1) |
Not Planned (see Doc ID 1307745.1) |
| IBM z/OS on System z | 06-MAR-2006 | Not planned | 26-OCT-2012 | Unsupported Platform (see Doc ID 461234.1) |
Unsupported Platform (see Doc ID 461234.1) |
Unsupported Platform (see Doc ID 461234.1) |
Unsupported Platform (see Doc ID 461234.1) |
Unsupported Platform (see Doc ID 461234.1) |
| Platform | 10.1.0.5 | 10.2.0.44 | 10.2.0.53 | 11.1.0.71 | 11.2.0.12 | 11.2.0.2 | 11.2.0.3 | 11.2.0.4 |
可见:
- 目前最新的版本为2.0.3,11.2.0.4最早将在2013年下半年(2HCY2013)提供。
- Oracle从11g开始已经不支持Linux Itanium、IBM z/OS on System z等平台,并且有些平台本身也已经被淘汰了。
11g补丁集发布计划和服务周期
以下是11g的补丁集发布计划和服务周期表:
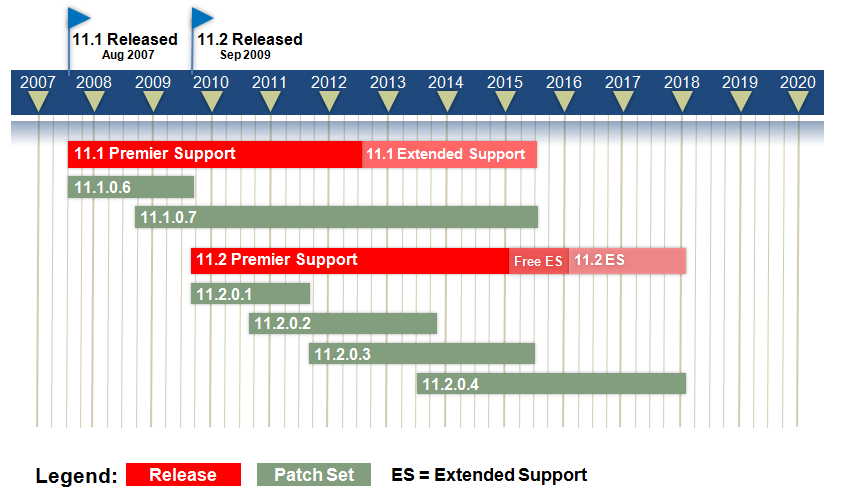
从上述周期图可见:
- 11g的最后一个补丁集将于2013年下半年发布,并且Oracle一直会提供服务到2018年。因此,针对当前的Oracle数据库系统,主动制定升级到2.0.4的升级计划,将会得到Oracle最有效的技术支持和服务。
- Oracle的补丁集通常会间隔12-24个月进行发布,但最后一个补丁集,例如2.0.4可能会延长到25-30个月才发布。
- 当新的补丁集发布之后,Oracle对老补丁集的支持可能仍然会持续1-2年不等,即在老补丁集继续提供相关Bug的补丁。
- PSU和CPU补丁固定每个季度发布一个,因此上述周期图不包括PSU和CPU。
什么叫补丁终止日期(Patching end date)?
所谓补丁终止日期(Patching end date),就是Oracle公司公布在某个补丁集之上发布PSU、CPU和one-off小补丁的最终日期。除非特别说明,该时间表针对所有平台,也就是与平台无关。以下就是Oracle的Patching end date表:
| Release | Patching Ends | Exceptions* | |
| 11.2.0.4 | 31-Jan-2018 | HP-UX Itanium: Patching ends Jan 2020. Beginning Feb 1, 2018, Sev 1 fixes only (no PSU or CPU will be produced). | |
| 11.2.0.3 | TBD6 | ||
| 11.2.0.2 | 31-Oct-2013 | End date extended beyond normal to overlap with 11.2.0.4. | |
| 11.2.0.1 | 13-Sep-2011 | Patch end date for Exadata is 30-Apr-2012 | |
| 11.1.0.7 | 31-Aug-20157 | HP-UX Itanium – Patching ends Dec 2015. Beginning Sep 1, 2015 Sev 1 fixes only (no PSU or CPU will be produced). | |
| 11.1.0.6 | 18-Sep-2009 | ||
| 10.2.0.5 | 31-Jul-20137 | HP-UX, Linux, and Windows Itanium – patching ends Dec 2015. Beginning Aug 1, 2013, Sev 1 fixes only (no PSU or CPU will be produced). | |
| 10.2.0.4 | 31-Jul-20115 | ||
| 10.2.0.3 | 22-Feb-2009 | IBM Linux on Power | 9-Apr-2009 |
| IBM Linux on System z | 16-May-2009 | ||
| Microsoft Windows Itanium (64-bit) | 2-May-2009 | ||
| HP Tru64 UNIX | 20-May-2009 | ||
| 10.1.0.4 | 30-Jan-2007 | ||
相关说明如下:
- 10g版本至少应该安装补丁集到2.0.5,但Oracle也只支持到2013年7月31日。
- 2.0.3的最终支持日期需要等待11.2.0.4发布之后才能确定。
16.5 补丁实施那些事
如何降低补丁实施对业务的影响?
为什么很多客户不愿意去主动实施补丁?除了不太了解Oracle版本、补丁等概念之外,在11g之前的版本,安装补丁通常需要关闭数据库,这样对业务连续性会造成一定影响,这也是客户不轻易安装补丁的重要原因。
为降低补丁实施对业务连续性的影响,Oracle从11g之后提供了越来越多的补丁实施技术。以下分别介绍之:
- In-place和 Out-of-place补丁实施方法
在11gR2版本之前,补丁集(Patchset)相对于基础版本没有增加任何功能,例如10.2.0.5与10.2.0.1功能是完全相同的,10.2.0.5只是修复了更多的Bug。再则,10.2.0.5补丁集是直接安装在10.2.0.1的Oracle Home目录中。这种补丁实施方法叫做In-place方法。
在11g R2版本之后,补丁集(Patchset)相对于基础版本增加了新功能,也可以说补丁集成了一个新版本。例如11.2.0.3与11.2.0.1相比,不仅修复了很多Bug,而且完全是一个新版本。再则,11g R2之后补丁集必须安装在一个新的Oracle Home目录中。这种补丁实施方法叫做Out-of-place方法。
为什么Oracle要提供Out-of-place方法?就是为了降低安装补丁集对业务连续性的影响!在Out-of-place补丁实施方法中,可以在将原有版本正常工作的情况下,将新的补丁集安装在新的Oracle Home目录,在安装完成之后,再进行数据库的升级,这样有效提高了业务连续性的影响。同时,Out-of-place方法也是一种提高补丁实施可回退性的做法,因为原有版本在原来的Oracle Home目录中原封未动呢。
- 滚动升级(Rolling Upgradable)方法
所谓滚动升级(Rolling Upgradable)方法,主要是在RAC环境下,Oracle可支持挨个节点轮流安装补丁或升级的做法,例如先将节点1的RAC、ASM、Clusterware停下来,并安装相应的补丁,而其它节点保持正常对外服务。当第一个节点完成补丁安装工作并重启之后,再在节点2进行类似的工作,依次完成所有节点的补丁安装。Oracle可支持在短时间内的各节点Clusterware、RAC等版本的不一致。这样,通过滚动升级方法,Oracle最大限度地保障了业务连续性。
- 在线(Online)补丁实施方法
Oracle在11g R2版本之后还推出了所谓在线(Online)或者热(Hot)补丁实施方法,即在不停止数据库软件运行的情况下,直接安装one-off补丁。
以下就是Oracle官方给出的不同Patch类型的安装工具,安装方法是In-place或者Out-of-place,以及是否支持滚动升级:
| Patch type | Tool | Method | Rolling Upgradable |
| Patchset | OUI | Out-of-place | Yes |
| Patch bundle | OPatch/Enterprise Manager | In-place | Most (check) |
| One-off patch | OPatch/Enterprise Manager | In-place | Most (check) |
可见,补丁集(Patchset)通过OUI图像化工具安装,安装方法是Out-of-place,并且支持滚动升级。而Patch Bundel和One-off Patch则是通过OPatch工具,或者OEM进行安装,这些补丁安装方法都是In-place,而且大部分都支持滚动升级。通过如下命令,可确认该补丁是否支持滚动升级(Rolling Upgradable)?
— unzip patch到某个目录
— cd到该目录
$ ORACLE_HOME/OPatch/opatch query – is_rolling_patch <patch_loction>
代价不菲的升级操作
2012年某银行实施了第一套10g数据库升级到11g。虽然作为解决方案顾问,本人并未参与到实际的升级测试和实施之中,但升级之后第一天本人就接到了该银行技术人员的电话:“怎么搞的,你们11g怎么吃内存这么多?每个Server Process进程比原来大了好多倍,幸亏我们先把机器内存扩容了,否则系统要崩溃的!”
我突然想到前一年某电信公司CRM系统升级也遇到了同样的问题,甚至比该银行更不幸,直接导致了系统宕机。原因如何呢?《11gR2/Aix – Dedicated Server Processes Have Large Usla Heap Segment Compared To Older Versions (Doc ID 1260095.1)》详细描述了原委及解决方案。简言之,就是11g R2为了支持在线(Online)补丁实施功能,在AIX平台的每个Server Process需要记录更多的信息,因此内存从10g之前的几十KB,涨到了7MB!如何解决呢?去掉该功能呗。以下就是更详细的描述:
- 问题现象
通过AIX如下命令:
$ svmon -P PID(PID为某个Server Process的ID号)
…
89b38e 80020014 work USLA heap sm 1904 0 0 1904
可观察到USLA heap区域增长到1904*4K = 7MB左右,其中1904表示内存页面数,4K表示一个内存页面大小。
- 问题原因
原因就是为了支持在线(Online)补丁实施功能,Server Process连接时采用了“-bexpful”和“ –brtllib”选项,也就是通过更多内存来保留在线补丁升级所涉及的shared library等文件信息。
- 解决方式
解决方式是将AIX升级到AIX 6.1 TL07版本或AIX 7.1版本,并安装Oracle补丁13443029。
若AIX版本低于AIX 6.1 TL07版本或AIX 7.1版本,则安装Oracle补丁10190759,安装该补丁的作用就是去掉在线补丁实施功能。
安装补丁的风险
为什么很多用户除非出问题,否则不愿意主动安装补丁?的确,有很多客户安装了一些不必要的补丁之后,反而导致了一些新问题。部分原因也的确是Oracle针对各类补丁的测试强度不一而导致。以下就是Oracle针对各类补丁的测试情况:
| Test | Interim | PSU/CPU | Bundle Patch | Patch Set |
| Install | Yes | Yes | Yes | Yes |
| Fix Verification | If possible | If applicable and possible | If applicable and possible | No |
| Basic DB Activity | No | Optional | Desired | Yes |
| Basic Application Functionality | No | Optional | Desired | Yes |
| Basic Load Test | No | Optional | Desired | Yes |
| Complete App Functional Flow | No | No | No | Yes |
| DB & App Performance & stress testing | No | No | No | Yes |
可见,补丁集(PatchSet)的确是Oracle各类补丁中,进行各类测试最全面的,包括数据库基本功能测试、基础压力测试、完整的应用功能兼容性测试、数据库和应用的性能和压力测试等,从而稳定性、健壮性是最好的。因此,在Oracle推出新的补丁集(PatchSet)之后,建议客户应尽快考虑升级到这个新的补丁集(PatchSet)。
其次,PSU/CPU补丁,以及主要是针对Windows平台的Bundle Patch,虽然没有补丁集(PatchSet)测试这么全面,但毕竟这些补丁是定期(每个季度)发布的一些常见问题的修复,因此也应积极、主动考虑这些补丁的评估和实施。
而Interim补丁,或One-off补丁,则应视情况而定了。如果的确发生了与某个Patch相关的问题,则一定要及时安装这个补丁,否则就无需无病乱投医了。凡药三分毒呢。呵呵。
如何提高Bug和补丁分析和实施能力?最好的办法还是解铃还需系铃人,找Oracle原厂服务啊,这是最正宗的出处。呵呵。
一位客户的SR处理
2013年,采购了Exadata服务器的国内某客户不幸发生了多起严重程度不一的故障。该客户具有比较强的技术水准和服务意识,针对这些问题,他们充分利用Oracle的后台服务资源,在my.oracle.support(metalink)网站分别建立了相应的SR。但这些问题的处理却因多方因素,进展不一,有些问题甚至长达数月都未得到彻底解决,客户对Oracle服务充满了抱怨。
于是,为安抚客户情绪,我和服务销售一起去走访客户了。其实,我们还有”不可告人”的目的:那就是怀揣着 “趁火打劫”的心理,看看有没有机会兜售更高级服务,呵呵。
在本书,我们还是从问题本身着手来分析一些技术原委,以及处理SR的经验。由于这些问题几乎都与Oracle Bug和补丁相关,因此,我把这个案例放在本章了。
几个月都没有进展的问题 —- 客户郁闷死了
该客户采用了Active Data Guard(ADG)作为生产系统的容灾和查询系统。不幸的是,ADG作为11g新技术,又是在Exadata上面部署,发生了一个看似很传统,但实际上完全是一个新的ORA-1555错误。客户为此创建了SR:3-7782930901,但该SR自9月8日建立,到写作本节的11月21日,期间经历了很多的反反复复,例如Oracle后台技术人员一会儿怀疑是Bug 16745102,一会儿又给了个将DELAY参数设置为30分钟的Workaround,但仍然没有找到问题的根源。
目前的状态还是让客户提供如下信息:
Please provide the requested data and answers to below questions:
1)
output of
select * from v$undostat;
from each machine (all nodes, primary and standby)
2) Since when is this error being observed? Was there some specific event
(maintenance, switchover between primary and standby, application/db/OS
upgrade, patch) after which the issue started occurring? Or did it start
suddenly without anything having changed from the setup of their system?
Further please provide
3) AWR reports from each machine (all nodes, primary and standby)
4) Does this issue happen only on one specific instance (node2)?
If so, what is specific for this node (configuration, application use)?
/
即一方面让客户提供生产和容灾两个节点的v$undostat视图信息,另一方面询问客户在发生ORA-1555错误之前,是否做了什么特别的操作?例如生产和容灾系统切换?应用/数据库/操作系统升级?打补丁等。同时还要生产和容灾系统的AWR报告,以及询问该错误是否只发生在一个节点,等等,等等。
试想这个SR在长达几个月的处理中,Oracle后台技术人员不断让客户收集相关数据,SR都升级到最高级别1级了,但却一直没有给出问题的根源分析,客户的可怜和悲催心情,可想而知,本人也只能深表同情。就在那天现场安抚时,我也只能对客户提出如下诚恳的建议:你就按人家的建议继续提供信息吧,而且千万别迟缓,否则你的SR老处于“Customer Working”状态,哪天人家把你的SR关闭了,就是你自己的责任了。唉!
问题已经解决了 — 客户还是不放心
- 问题现象
客户ADG环境在2013年9月5日中午12:00,突然出现数据库Hang情况,连select 1 from dual都无法返回,同时alert.log记录有大量ORA-1555错误(事后证明,ORA-1555与数据库Hang没有直接关系)。
- 问题分析和诊断过程
客户在第一时间创建了SR:3-7774805121。Oracle后台技术人员在接到SR之后的第一时间就直接电话客户,得知了系统基本配置:两台1/2配置的 Exadata服务器搭建了ADG环境,数据库版本为11.2.0.3,也已经知晓客户在重起容灾系统之后问题消失,但客户希望能找出问题根源。
于是,Oracle后台技术人员请求客户先上传相关节点的alert.log日志文件。根据alert.log日志文件信息,又请求客户上传相关trace文件、OSWatcher日志文件,以及事故发生前后的AWR报告。但客户由于对OSWatcher工具不熟悉,于是请求Oracle现场技术支持团队(ACS)到现场协助工作,将oswvmstat.zip、oswtop.zip、oswslabinfo.zip等日志信息上传给Oracle后台。
Oracle后台进一步要求客户在容灾数据库执行如下一些操作,确认数据库状态,并上传进一步的trace文件:
- Please execute select * from v$database for the standby database into an Excel file and upload.
2. The following SQL is used to track if database recovery progress is hanging.
SQL> select * from v$recovery_progress order by start_time;3. Please zip and upload the following files from instance 1 so I will try to find where it hang:
/u01/app/oracle/diag/rdbms/fossstd/fossdb1/trace/fossdb1_ora_89823.trc
/u01/app/oracle/diag/rdbms/fossstd/fossdb1/trace/fossdb1_ora_95210.trc
/u01/app/oracle/diag/rdbms/fossstd/fossdb1/trace/fossdb1_ora_96306.trc4. Please zip and upload the following files from instance 2:
/u01/app/oracle/diag/rdbms/fossstd/fossdb2/trace/fossdb2_ora_112518.trc
/u01/app/oracle/diag/rdbms/fossstd/fossdb2/trace/fossdb2_ora_1169.trc
/u01/app/oracle/diag/rdbms/fossstd/fossdb2/trace/fossdb2_ora_1177.trc
终于,Oracle后台技术专家在对这些system state dump文件的分析中,发现了问题的蛛丝马迹:
SO: 0x843f69648, type: 78, owner: 0x834f3f1b0, flag: INIT/-/-/0x00 if: 0x3 c: 0x3
proc=0x8288d7330, name=LIBRARY OBJECT LOCK, file=kgl.h LINE:8547, pg=0
LibraryObjectLock: Address=0x843f69648 Handle=0x857d42810 Mode=X CanBeBrokenCount=1 Incarnation=1 ExecutionCount=0 <— exclusive mode
User=0x82cdfacd0 Session=0x82cdfacd0 ReferenceCount=1 Flags=CNB/[0001] SavepointNum=2
LibraryHandle: Address=0x857d42810 Hash=d306ca9c LockMode=X PinMode=0 LoadLockMode=0 Status=0 <— owned by process LGWR
ObjectName: Name=SYS.fossdb
- 问题原因和解决方式
原来是一个Bug!
Keywords: standby library cache lock LibraryObjectLock sys.
Found:Bug 16753640 : ALL STANDBY NODES OF ADG WERE HUNG WITH “LIBRARY CACHE LOAD LOCK”
—> Bug 16717701 : ADG SHOULD GET THE INSTANCE PARSE LOCK WITH A TIMEOUT
而且该问题是修复Bug 11664426之后带出来的问题,呵呵,也就是按下葫芦起了瓢。以下就是Oracle专家的详细描述:
This fix supersedes the fix done in bug 11664426.
This only happens when the fix of bug 11664426 is in place which is the case for 11.2.0.3
or for customers who applied an one off patch for bug 11664426.
A Standby Active Dataguard database may encounter severe library cache lock contention with
possible deadlock causing the database to hang when there are a lot of DDLs on the Primary
Database.
This fix may not help much if dealing with pure contention as opposed to deadlock. But if the ADG instance
is running a RAC configuration, then it might be worthwhile applying this fix even in non-deadlock situations.
Rediscovery Notes:
If the fix of bug 11664426 is present then the ADG hang scenario shows as LGWR holding
the DBINSTANCE namespace library cache lock for the instance in X mod. LGWR itself
may appear idle but other sessions will be blocked waiting on “library cache lock” for
the DBINSTANCE namespace lock.
Workaround
Cancel the media recovery and restart.
该问题将在11.2.0.4以及12.2版本才能解决,目前的Workaround是取消Media Recovery操作,并重新启动容灾节点。
至此,Oracle后台认为针对该问题已经给出了解决方案,希望客户认可并关闭此SR。
- 客户的进一步要求
显然,客户难以接受这种处理方式,升级到11.2.0.4毕竟是一件浩大的工程,而重起容灾节点更是无法接受,鬼知道容灾节点什么时候会出现Hang的情况?于是时隔多日之后,客户要求Oracle提供一个基于11.2.0.3的该Bug的补丁,也就是要求Oracle做backport工作。
于是,在客户将 SR升级到1级,并且与Oracle后台进行一番“讨价还价”,客户也提供现有系统补丁情况之后,Oracle终于承诺满足客户需求,做backport工作去了。接下来,Oracle后台在经过BugDB、BDE等一番流程之后,Oracle还算给力,仅仅在一周之后,就提供了该Bug在11.2.0.3版本的补丁。
最终,客户下载了Oracle专门给他们开发这个补丁,并在生产系统直接进行实施,问题再未爆发。
- 启示及题外的话
首先,该问题从爆发到原因确认仅有4天时间,除去等待客户提供相关诊断信息的时间,Oracle后台的分析、诊断效率还是比较高的。当然,Oracle ACS现场的信息采集和问题分析,以及与后台专家的紧密配合,对促进该问题的最终解决也是功不可没的。
其次,在整个SR处理中,客户与Oracle后台服务(PS)、现场服务(ACS )紧密配合,客户不仅应Oracle要求,及时提供了各类诊断数据,而且在Oracle已经提供了解决方式的情况下,大胆提出自己的进一步诉求,即请求Oracle专门开发针对这个问题的补丁,最终最大限度地满足了自己的服务需求。
题外的话是:当本人在那次走访该客户时,客户对该问题的解决却仍然是放心不下、惴惴不安。我问他为什么?他说:“现在Hang的问题是暂时没有出现了,不知道以后会不会还出现。”我的妈呀,我不得不给他做安抚工作了:第一, Oracle专家已经根据各种诊断信息,准确地分析出是一个Bug了。第二,Oracle甚至已经为这个Bug专门为你们开发了补丁。第三,你们安装这个补丁之后问题也不再重现了。Oracle是有理有据在处理这个问题,还有什么不放心呢?”
我在这番解释之后,客户依然是半信半疑,还在那儿跟Oracle,也是跟自己较劲,于是我只好在邮件中继续给他做心理疏导工作了:
“请相信Oracle Metalink给出的分析和建议是有官方和法律意义的,这也是Oracle作为原厂服务区别于第三方服务的一个特点。即便问题重现,Oracle也可以继续分析,不会放弃的,但建议客户自己别放弃。”
客户的回复是:“嗯,这点我绝对相信,要不然我们不会关闭SR的。 只是说现在还无法验证而已。”
我的再次回复是:“SR代表官方,SR中的描述本身就是一种承诺和验证。如果再爆发同样问题,再继续跟踪。”
客户最后缄默了,也真心希望他能释然了。呵呵。
本章参考资料及进一步读物
本章参考资料及进一步读物:
| 序号 | 资料类别 | 资料名称 | 资料概述 |
| 1. | My Oracle Support | 《Lifetime Support and Support Policies – Oracle Database Overview[ID 1351163.1]》 | 该文档是Oracle公司关于数据库产品服务周期和支持政策的官方文档,包括Premier、Extended、Sustaining等服务的服务期限和服务政策的详细描述。 |
| 2. | My Oracle Support | 《Release Schedule of Current Database Releases [ID 742060.1]》 | 欲了解Oracle数据库在不同平台的各个版本发布计划和服务期限,从而合理规划自己的Oracle数据库版本和升级计划吗?请看这篇文档。 |
| 3. | My Oracle Support | 《Oracle Recommended Patches — Oracle Database [ID 756671.1]》 | 该文档描述了Oracle官方建议的在数据库不同版本下应该安装的补丁列表。包括常见补丁,与RAC、Data Guard、Exadata、E-Business Suite相关补丁等。 |
| 4. | My Oracle Support | 《Introduction to Oracle Recommended Patches [ID 756388.1]》 | 此文档列出了Oracle数据库、OEM、中间件(OFM)、Exalogic、Solaris、E-Business Suite等产品推荐安装补丁的文档链接。 |
| 5. | My Oracle Support | 《Patch Set Updates for Oracle Products [ID 854428.1]》 | 这是一篇全面介绍PSU补丁的文档。 |
| 6. | My Oracle Support | 《Quick Reference to Patch Numbers for Database PSU, SPU(CPU), Bundle Patches and Patchsets (Doc ID 1454618.1)》 | 在Metalink中搜索需要的PSU、CPU等补丁号,并不是一件容易的事情。该文档就给出了一个各版本下PSU、CPU、GI PSU、Windows下Bundle Patch的清单,方便大家快速查找相应的补丁。 |
| 7. | My Oracle Support | 《Oracle 11g Release 2 (11.2) Support Status and Alerts [ID 880782.1 ]》 | 该文档汇集了Oracle数据库11.2版本有关信息。例如各平台和版本的认证信息、各Patchset修复的补丁列表等。 |
| 8. | My Oracle Support | 《Oracle Database Support Newsletter[ID 230.1]》 | 这是Oracle标准服务(Premier Support)有关Oracle数据库的定期技术通讯。既有版本和补丁发布的最新消息,更有数据库的最新发展技术研讨和介绍。 |
| 9. | Oracle 11g R2联机文档 | 《Oracle® Database Upgrade Guide》 | 这是Oracle联机文档中有关数据库升级的专题文档,其中也不乏版本和补丁的描述。 |
| 10. | My Oracle Support | 《Do Patchset Updates (PSU’s) Change the Oracle Release Version/Fifth Digit? [ID 861152.1]》 | PSU是数据库版本的第5位,但Oracle并不直接显示数据库版本的第5位。如何知道什么安装了PSU补丁?请看这篇文档介绍的办法。 |
| 11. | My Oracle Support | 《Patching & Maintenance Advisor: Database (DB) Oracle Database 11.2.0.x [ID 331.1]》 | 这是一篇介绍Oracle数据库版本和补丁管理的实施方法论文章。例如如何采取主动预防式策略,如何从评估、计划、测试、实施等全生命周期角度去进行版本和补丁管理。 |
| 12. | My Oracle Support | 《Oracle Database, Networking and Grid Agent Patches for Microsoft Platforms [ID 161549.1]》 | 这是一篇全面介绍Windows平台的Oracle数据库、网络和Grid Agent的版本和补丁的官方文档。 |