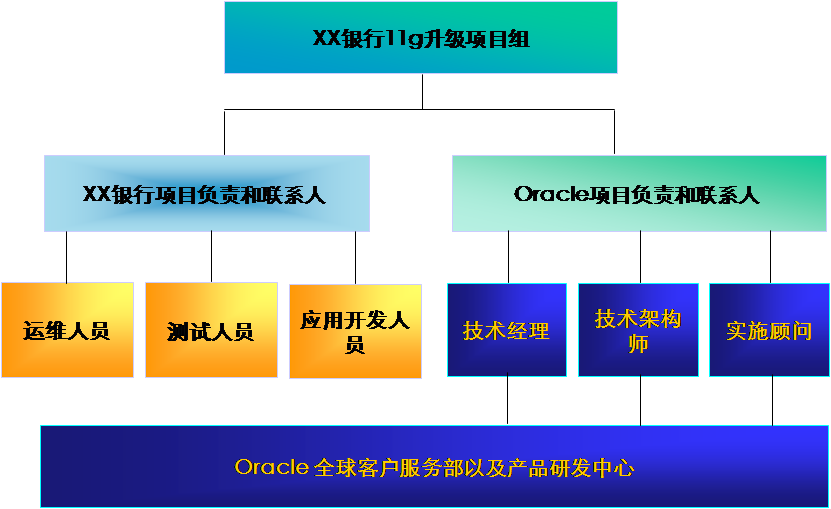
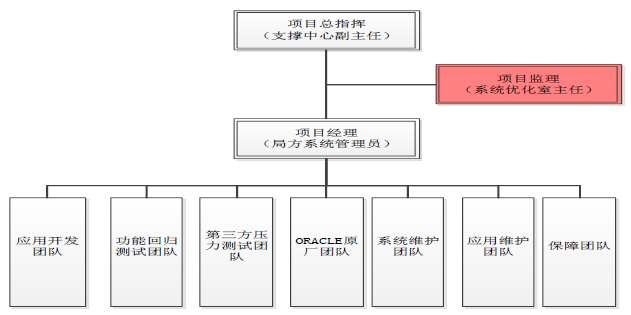
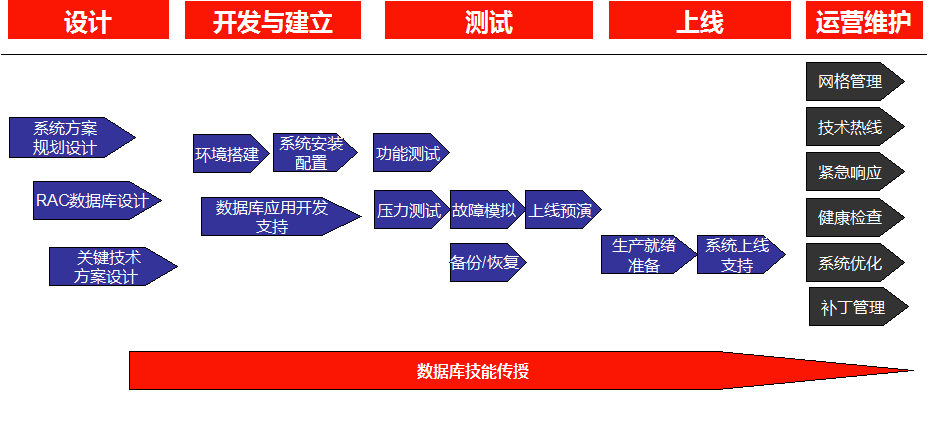
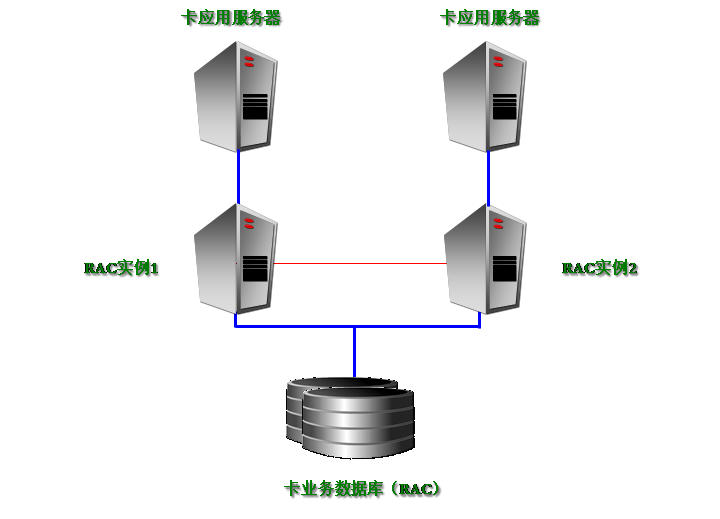
本文固定链接:https://www.askmac.cn/archives/hadoop-permissions-guide.html
本文是官方文档的翻译,原文地址是:
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsPermissionsGuide.html
1.概述
HDFS为文件和目录实现了一个权限模块,一大部分共享是POSIX模式。每个文件和目录关联到一个用户和一个组。文件和目录以用户所有者来权限划分,其他的用户可以是一个组的成员,也可以是所有其他的用户。对于文件来说,r 权限是读文件的权限,w 权限是写或者追加到文件的权限。对于目录来说,r权限是列出目录内容的权限,w权限是删除和创建文件或目录的权限,x权限是访问子目录的权限。
于POSIX模式对比,文件没有setuid或setgid位,因为没有可执行文件的概念。同样地,对于目录也没有setuid和setgid位。粘贴位可以被设置在目录上,可以防止除了超级用户之外,目录所有者或文件所有者在这个目录中删除或移动文件。在文件上设置粘贴位没有作用。总的来说,一个文件或目录的权限是它们的模式。一般来说,Unix用户的表现模式将被使用,包括这个表述上的8进制方法。当文件或目录被创建,它们的所有者是客户端进程的标识,它们的组时父目录的组(BSD规则)。
HDFS也提供了POSIX ACLs(访问控制列表)支持,来增加对特定命名用户或命名组的更细粒度规则的文件权限。ACLs在后面有更详细的讨论(www.askmac.cn)。
每个客户端进程访问HDFS拥有2部分标识:用户名和组列表。当文件和目录被一个客户端进程访问时,HDFS必须进行权限检查。
- 如果用户名匹配所有者,那么所有者权限是通过的。
- 如果组权限匹配组列表中任何一个成员,那么组权限是通过的。
- 否则,其他权限是通过的。
如果权限检查失败,客户端操作就失败。