SHOUG成员 – ORACLE ACS高级顾问罗敏
IT系统安全性,特别是数据库系统安全性,成了当下IT行业一个热门话题。本人曾听一位销售同事曾说:“在XX集团计划部,现在只要说申报与安全性相关的项目,准保一路绿灯。”
但也如另外一位同行所说:“安全性是说起来重要,做起来次要,忙起来不要。”无论重要也罢,次要、不要也罢。安全性特别是数据库安全性的确是值得深入探讨的话题,更具有广泛、全面实施空间的领域。
本章就将从数据库安全性需求及现状说起,再对Oracle数据库安全性解决方案进行一番介绍,然后结合某银行客户的安全性需求,制定安全性解决方案策略,最后系统描述了针对该银行的某关键业务系统的安全性评估情况。
数据库安全性需求及现状
IT 系统发展的一大趋势就是业务和数据的大集中。大集中之后的IT系统在系统的高可用性、高性能、可管理性、扩展性、安全性等方面,都将面临更严峻的挑战。具体在数据库安全性方面,在身份鉴别、数据存储层面、访问控制、安全审计和日志管理等诸多方面,IT系统都应得到进一步加强和加固,从而满足不断增长的数据安全管理和合规性需求。
目前,各类IT 系统安全事故的频发,例如客户资料流失等,不仅给各企业带来巨大损失,而且也造成非常不良的社会影响。于是,各行业领导都更高度重视数据库安全性。
安全性是涉及硬件、网络、操作系统、数据库软件、中间件软件、应用软件等各层面的系统工程。但是,据本人的了解,很多行业的安全性解决方案主要在服务器、网络等层面展开实施,例如某通信行业的4A认证体系。而在数据库层面,特别是Oracle数据库中,安全性实施的力度和强度并不充分。在大部分Oracle系统中,我们发现基本只采用了一些传统的安全性技术。例如:
- 防范非法用户访问的身份认证,如操作系统层、数据库层的口令管理。
- 基于数据库对象的防范非授权数据访问的权限控制。包括系统权限(system privileges)以及对象权限(object privileges)的设计,以及便于安全管理的角色(role)设计等。
- 为实现记录级的安全控制,采用了视图(View)方式。
- 关闭操作系统级不必要服务。如telnet、FTP服务等。
这种传统技术的安全保护强度是远远不够的,满足不了日益增长的安全性和合规性需求,导致数据库系统的各种安全风险暴露在外。例如,国内Oracle数据库几乎没有采取加密技术,特别是关键和敏感的客户资料全部是明文存储在数据库中;DBA权限过高,能访问所有应用数据;对重要操作行为缺乏审计等。
为什么在客户最为关注的Oracle数据库领域,客户反而没有充分实施安全解决方案呢?因为商务方面因素?的确Oracle大部分安全产品都需要单独购买。因为技术因素?的确Oracle大部分安全产品在实施方面还是有一定工作量和技术难度的,而且多数技术人员缺乏这方面实施经验。因为体制问题?的确很多行业明确规定安全性技术不能采用国外技术,只能采用国内自有技术体系。
但本人一次与一个国内重要客户DBA有关安全性的沟通内容,则耐人寻味,也有点啼笑皆非。
我问:“为什么你们的系统只在操作系统和网络层面实施安全性,而不在Oracle数据库内部加强安全性呢?”
DBA回答:“你们Oracle数据库现在就那么多Bug,就象个大马蜂窝,我们哪敢还去实施那么多安全性产品,去捅这个马蜂窝啊?你们Oracle更像个核反应堆,我们宁可在外面构筑铜墙铁壁,也不轻易碰你们这个核反应堆。”
我说:“再坚固的钢筋水泥也抵挡不住内部的核泄露啊,就象日本福岛核电站爆炸事故一样。”
DBA无语,但也未必赞同我的解释。
Oracle数据库安全性解决方案
从源头说起
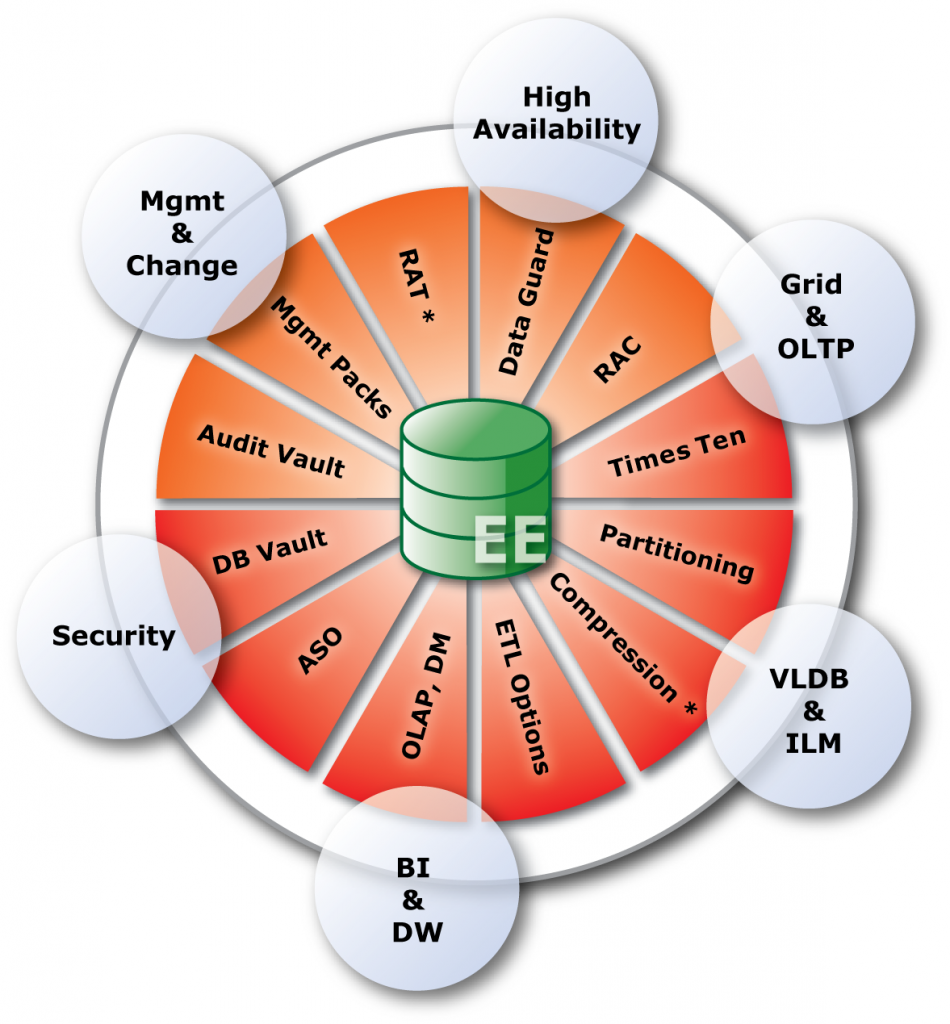
在IT系统日益面临各种内外安全攻击和挑战的严峻环境下,为满足IT系统不断增长的安全需求,为符合各种安全性和合规性要求,Oracle数据库安全性技术和产品也在不断推陈出新,以下就是Oracle在不同版本下安全性技术不断发展的示意图:

其实追根溯源从Oracle数据库诞生之日起,Oracle就非常重视数据库安全性。值得一提的是上图第一行所谓政府客户(Government Customer),实际上就是美国军方。Oracle数据库其实就是来源于当年的RSI公司(Oracle公司前身)为美国中央情报局设计开发的一套专用信息处理系统,因为该项目名称叫Oracle,所以RSI公司更名为寓意更深远、发音也更响亮的Oracle公司,并从此扬名天下。而在数据库安全领域,由于来源于政府和军方的缘故,Oracle具有先天优势,诸多产品如Oracle Label Security等也带有浓郁的美国政府特别是军方色彩。
从总体上而言,Oracle数据库是业界安全性方面最完备的数据库产品。在数据库安全性的国际标准中,Oracle通过了14项标准的测试,是所有数据库产品中通过安全性标准最多、最全面的产品。Oracle在C2级的操作系统上(如商用UNIX、VMS操作系统),不仅满足NCSC C2级安全标准,而且已经正式通过了NCSC C2标准的测试。在B1级的操作系统上不仅满足NCSC B1级安全标准,而且已经通过了NCSC B1级标准的测试。
数据库安全性全面解决方案
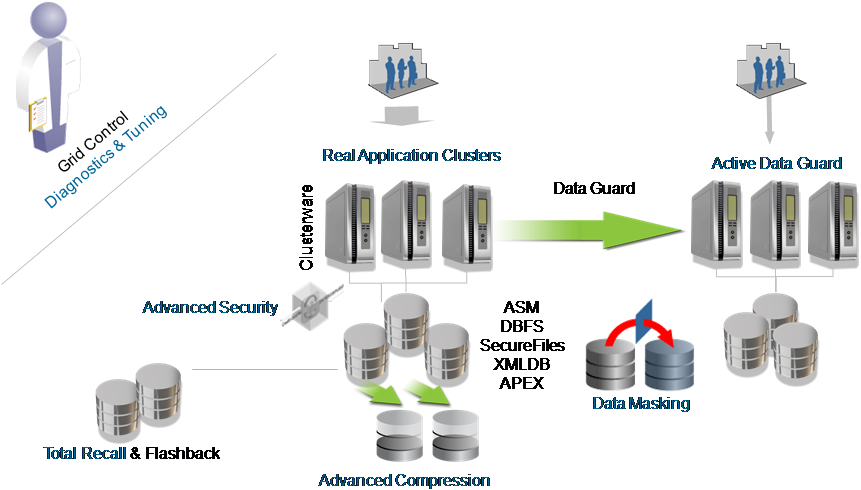
以下示意图从一个角度代表了Oracle数据库安全性全面解决方案:
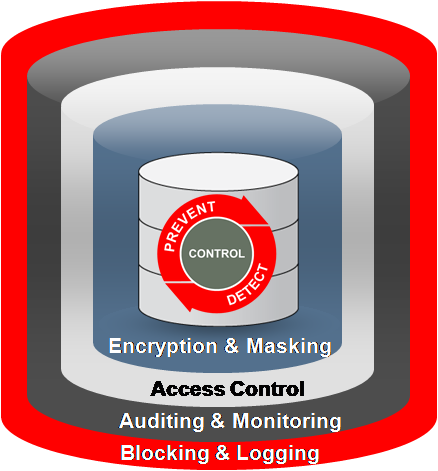
还记得前面一个DBA的话语吗?他把数据库安全性比喻成一个核反应堆。上图不就是非常形象的Oracle数据库安全性的核反应堆吗?
即在核反应堆的最外层,Oracle通过数据库防火墙(Database Firewall)产品构筑了一层坚固的钢筋水泥保护墙,用于阻断(Blocking)和记录(Logging)对数据库的恶意攻击。例如,监视数据库活动,防止未授权的数据库访问、SQL 注入、权限或角色升级、对敏感数据的非法访问等。
而在数据库内部,除传统的数据库用户、口令、角色、权限、审计等功能之外,在安全监控层、访问控制层和数据存储层面,均推出了功能更强、更符合安全性需求的产品和技术,使得Oracle数据库安全性得到全面加强。下图更清晰地展现了各层面的相关技术和产品:
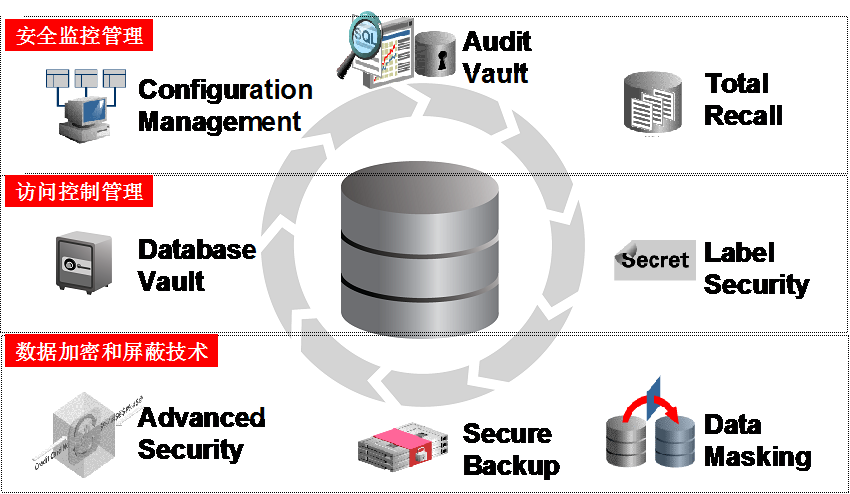
即在安全监控管理层,提供了对企业内部所有数据库的审计数据进行收集、监控、存储、检验和生成报表的集成化平台产品:Audit Vault;也提供了加强对历史数据的安全审计的产品:Total Recall;以及对企业数据库的配置进行集中管理的产品:Configuration Management。
在访问控制层面,不仅有传统的虚拟私有数据库(Virtual Private Database)技术,以及具有美国政府色彩的标签数据库(Oracle Label Security)技术,还有从10g以后发展的用于访问权限控制和职责分离(Seperation of Duty)的新产品:Oracle Database Vault。
在数据存储层面,既有对数据库内部敏感数据进行加密的高级安全产品(Oracle Advanced Security),也有对备份数据进行加密的Secure Backup技术,同时还有对敏感数据进行屏蔽或漂白,用于开发测试环境的Data Masking技术。
Oracle数据库安全性实施基本策略:快速原型法
由上可见,Oracle数据库安全性实施是涉及数据存储、访问控制和安全监控等多层面,由多项技术组成的庞大系统工程。为降低实施风险,特别是降低对应用程序的影响,建议采取如下图所示的快速原型法:
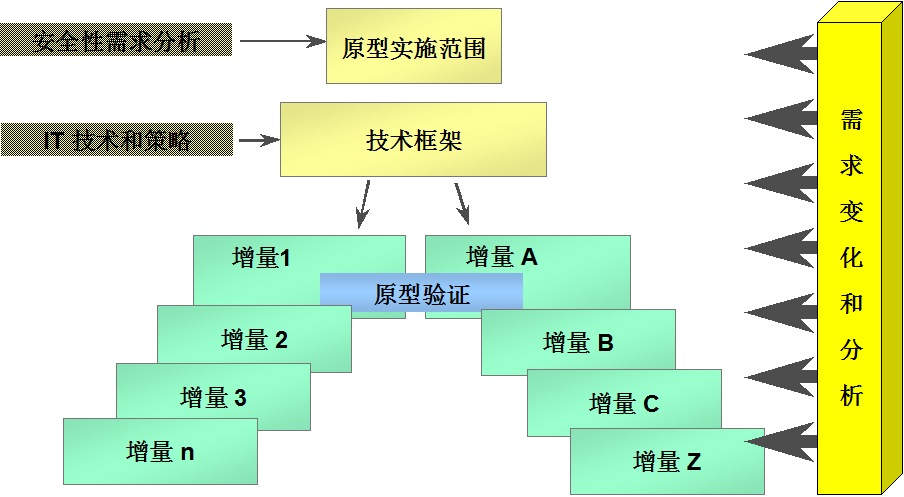
即在全面分析安全性需求基础上,先采用Oracle数据库常规性安全性技术,并依赖现有IT技术框架,先满足数据库安全性基本需求,形成安全性原型系统。在原型系统基础上,根据安全需求的不断变化和分析,逐步采用更全面、深入的安全性产品和技术,丰富安全性原型系统,像滚雪球一样,最终逼近最终的安全性系统,全面满足数据库安全性需求。
17.3 某银行客户安全性需求和Oracle策略
以下我们通过对一个银行客户的安全性需求的详细分析,以及对应的Oracle安全性总体解决策略,来展现数据库安全性解决方案的全面性、系统性和复杂性:
根据上述对该银行客户数据库安全性的需求分析,可总结如下特点:
- 可通过Oracle常规安全性技术,满足大部分安全性需求。
- 部分安全性需求需要通过Oracle 安全性高级技术和产品加以实现。例如数据库内部敏感数据加密、备份数据加密、网络传输加密等需求可通过Oracle Advanced Security,Secure Backup、Data pump加密等技术实现;访问控制需求可通过Oracle Database Vault等新技术加强实现;高级审计需求可通过集中审计平台(Oracle Audit Vault)加以实现。
- 尚未提出数据屏蔽(Data Masking)、记录级访问控制(VPD、Oracle Label Security)、配置管理(Configuration Vault)、历史数据审计分析(Total Recall)等需求。
安全性需求需要通过安全管理制度和流程控制的改造和加强,加以保障。
从安全性评估开始
如前所述,IT系统安全性是涉及硬件、网络、操作系统、数据库软件、中间件软件、应用软件等各层面的系统工程。Oracle数据库安全性也是包括数据库防火墙、安全监控层、访问控制层和数据存储层面等诸多产品和技术。限于篇幅,本书无意介绍具体安全性产品和技术,也避免产品推广之嫌。另外,作为安全性系统工程,应先对现有系统数据库安全性展开评估,发现现有系统存在的各种安全风险和漏洞,然后再展开相对应的安全性加固工作。因此,本章下面将通过以一个银行系统为对象,展开安全性评估的介绍。
安全性评估内容
我们在参考了Oracle官方若干安全性评估文档、国内外若干行业的安全性评估标准、Oracle服务部门在国内若干实施案例,以及结合该银行系统特点,最终提出了如下的安全评估性分类和具体评估项目:
评估方法和举例
该系统的详细评估报告长达近百页,以下我们从每个评估大类中挑选1个评估项目的详细内容,以舐读者,也让读者了解我们的评估过程,包括评估目的和内容、评估方法、评估结果、安全加固建议等。
- 缺省安全设置
- 评估目的和内容
10g 数据库在安装完成之后,在初始化参数和Profile参数方面将进行一些缺省的安全设置。通常情况下,应保持这些设置。
- 评估方法
这些初始化参数和Profile参数包括:
| 参数名 | 缺省值 | 参数类型 |
| AUDIT_TRAIL | NONE | 初始化参数 |
| O7_DICTIONARY_ACCESSIBILITY | FALSE | 初始化参数 |
| PASSWORD_GRACE_TIME | UNLIMITED | Profile参数 |
| PASSWORD_LOCK_TIME | UNLIMITED | Profile参数 |
| FAILED_LOGIN_ATTEMPTS | 10 | Profile参数 |
| PASSWORD_LIFE_TIME | UNLIMITED | Profile参数 |
| PASSWORD_REUSE_MAX | UNLIMITED | Profile参数 |
| PASSWORD_REUSE_TIME | UNLIMITED | Profile参数 |
| REMOTE_OS_ROLES | FALSE | 初始化参数 |
- 评估结果
针对初始化参数检测方法如下:
SQL> show parameter; NAME TYPE VALUE ------------------------------------ ---------------------- ---------------------- … O7_DICTIONARY_ACCESSIBILITY boolean FALSE audit_trail string NONE remote_os_roles boolean FALSE …
上述初始化参数符合缺省安全设置。
针对Profile参数检测方法如下:
SQL> select * from dba_profiles; PROFILE RESOURCE_NAME RESOURCE_TYPE LIMIT -------------------- ---------------------------------------------------------------- ---------------- ----------DEFAULT COMPOSITE_LIMIT KERNEL UNLIMITED DEFAULT SESSIONS_PER_USER KERNEL UNLIMITED DEFAULT CPU_PER_SESSION KERNEL UNLIMITED DEFAULT CPU_PER_CALL KERNEL UNLIMITED DEFAULT LOGICAL_READS_PER_SESSION KERNEL UNLIMITED DEFAULT LOGICAL_READS_PER_CALL KERNEL UNLIMITED DEFAULT IDLE_TIME KERNEL UNLIMITED DEFAULT CONNECT_TIME KERNEL UNLIMITED DEFAULT PRIVATE_SGA KERNEL UNLIMITED DEFAULT FAILED_LOGIN_ATTEMPTS PASSWORD 10 DEFAULT PASSWORD_LIFE_TIME PASSWORD UNLIMITED DEFAULT PASSWORD_REUSE_TIME PASSWORD UNLIMITED DEFAULT PASSWORD_REUSE_MAX PASSWORD UNLIMITED DEFAULT PASSWORD_VERIFY_FUNCTION PASSWORD NULL DEFAULT PASSWORD_LOCK_TIME PASSWORD UNLIMITED DEFAULT PASSWORD_GRACE_TIME PASSWORD UNLIMITED PROFILE_NEW COMPOSITE_LIMIT KERNEL DEFAULT PROFILE_NEW SESSIONS_PER_USER KERNEL DEFAULT PROFILE_NEW CPU_PER_SESSION KERNEL DEFAULT PROFILE_NEW CPU_PER_CALL KERNEL DEFAULT PROFILE_NEW LOGICAL_READS_PER_SESSION KERNEL DEFAULT PROFILE_NEW LOGICAL_READS_PER_CALL KERNEL DEFAULT PROFILE_NEW IDLE_TIME KERNEL DEFAULT PROFILE_NEW CONNECT_TIME KERNEL DEFAULT PROFILE_NEW PRIVATE_SGA KERNEL DEFAULT PROFILE_NEW FAILED_LOGIN_ATTEMPTS PASSWORD UNLIMITED PROFILE_NEW PASSWORD_LIFE_TIME PASSWORD DEFAULT PROFILE_NEW PASSWORD_REUSE_TIME PASSWORD DEFAULT PROFILE_NEW PASSWORD_REUSE_MAX PASSWORD DEFAULT PROFILE_NEW PASSWORD_VERIFY_FUNCTION PASSWORD DEFAULT PROFILE_NEW PASSWORD_LOCK_TIME PASSWORD DEFAULT PROFILE_NEW PASSWORD_GRACE_TIME PASSWORD DEFAULT SQL> select username,profile from dba_users; USERNAME PROFILE ------------------------------------------------------------ -------------------- PROPS DEFAULT MONITOR PROFILE_NEW EXPUSER PROFILE_NEW BOCRPT PROFILE_NEW PERFSTAT DEFAULT ORACLE_OCM DEFAULT DIP DEFAULT TSMSYS DEFAULT DBSNMP DEFAULT WMSYS DEFAULT SYSTEM DEFAULT OUTLN DEFAULT BOCNET PROFILE_NEW SYS DEFAULT
可见,该系统的MONITOR、EXPUSER、BOCRPT、BOCNET等用户采用的PROFILE为PROFILE_NEW,而PROFILE_NEW的FAILED_LOGIN_ATTEMPTS设置为UNLIMITED,不符合缺省安全设置。
- 安全加固建议
建议执行如下命令,将PROFILE_NEW的FAILED_LOGIN_ATTEMPTS设置为缺省值10:
SQL> alter profile PROFILE_NEW limit FAILED_LOGIN_ATTEMPTS 10;
上述加固建议将使得客户尝试登录的错误次数上限为10,加强防范恶意用户攻击能力。
该安全加固措施实施难度小,不会产生其它风险。
- 口令复杂度评估
- 评估目的和内容
按照安全规范,用户的口令设置必须符合相关复杂性管理的相关规定。例如:
- 口令不能等同于用户名
- 长度必须为8 – 30位
- 必须包含数据、字母,以及_、$、#等特殊字符
- 必须使用大小写字母(11g)
- 不得包含有意义的单词
- 评估方法
可进行如下检查:
SQL> select * from dba_profiles where resource_name=’PASSWORD_VERIFY_FUNCTION’;
如果为空或DEFAULT VALUE,则系统没有设置口令复杂度检查。
- 评估结果
上述语句检查结果如下:
PROFILE RESOURCE_NAME RESOURCE_TYPE LIMIT -------------------- ---------------------------------------------------------------- ---------------- ----------DEFAULT PASSWORD_VERIFY_FUNCTION PASSWORD NULL PROFILE_NEW PASSWORD_VERIFY_FUNCTION PASSWORD DEFAULT
可见,DEFAULT和PROFILE_NEW均没有进行口令复杂度检查。
- 安全加固建议
Oracle已经提供了一个脚本utlpwdmg.sql,通过运行该脚本将创建口令复杂度检查函数verify_function,并为DEFAULT profile赋予该口令复杂度检查函数。
SQL> @?/rdbms/admin/utlpwdmg.sql; SQL> select * from dba_profiles where resource_name='PASSWORD_VERIFY_FUNCTION';
可修改该脚本,为PROFILE_NEW设置口令复杂度检查。
对管理用户如SYS/SYSTEM的口令管理实施难度很小。但是,口令管理各参数涉及业务和按管理需求,另外,该系统各应用程序中直接写入了口令,因此,加强口令管理的难度较大。
- SYSDBA角色访问控制检查
- 评估目的和内容
根据安全管理规范,一方面可限制SYSDBA角色从远程登录,另一方面在本地以’/as sysdba’登录时,需要输入口令。
为实现上述目标,可将sqlnet.ora文件中的SQLNET.AUTHENTICATION_SERVICES设置为NONE。
- 评估方法
检查sqlnet.ora文件中的SQLNET.AUTHENTICATION_SERVICES。
- 评估结果
以下是该系统的sqlnet.ora文件内容:
# sqlnet.ora.netdb1 Network Configuration File: /oracle/app/oracle/product/10.2.0/db/network/admin/sqlnet.ora.netdb1 # Generated by Oracle configuration tools. NAMES.DIRECTORY_PATH= (TNSNAMES) 可见,该系统目前没有进行SYSDBA角色访问控制。 加固实施建议 可在sqlnet.ora文件进行如下配置: SQLNET.AUTHENTICATION_SERVICES = (none)
该安全加固措施难度很小,并可以限制未获得密码的人员不能以SYSDBA身份登录数据库,但可能会对数据库日常管理造成一定影响。
- 限制IP地址检查
- 评估目的和内容
Oracle可在sqlnet.ora文件中,对tcp.validnode_checking、tcp.excluded_nodes、tcp.invited_nodes等参数进行设置,从而达到指定或限制IP地址访问数据库的目的。
- 评估方法
检查sqlnet.ora文件是否包含类似如下的配置:
tcp.validnode_checking = YES
tcp.excluded_nodes = {list of IP addresses}
tcp.invited_nodes = {list of IP addresses}
其中tcp.validnode_checking = Yes将打开IP地址检查功能,tcp.excluded_nodes为禁止访问数据库的IP地址列表,tcp.invited_nodes为允许访问数据库的IP地址列表。
- 评估结果
以下是该系统的sqlnet.ora文件内容:
# sqlnet.ora.netdb1 Network Configuration File: /oracle/app/oracle/product/10.2.0/db/network/admin/sqlnet.ora.netdb1 # Generated by Oracle configuration tools. NAMES.DIRECTORY_PATH= (TNSNAMES)
可见,该系统目前没有进行IP访问地址的限制。
- 安全加固建议
如果根据网络管理规范,需要加强访问数据库的网络连接安全,可直接在sqlnet.ora文件中手工增加上述配置。例如只允许指定WAS服务器、管理监控终端等访问数据库。
但需要重新启动Listener,应用也需要重新连接Oracle数据库服务器。
- 透明数据加密实施检查
- 评估目的和内容
为加强数据本身存储的安全性,Oracle提供了多种透明加密技术(Transparent Data Encryption),并可在表、字段、表空间(11g)等不同级别进行加密处理。对帐户信息、信用卡号等敏感和关键字段进行加密,将有效提高数据安全性,并满足日益增加的安全性和合规性要求。
- 评估方法
执行如下脚本可查询当前数据库已经进行加密处理的字段: SQL> select * from DBA_ENCRYPTED_COLUMNS;
在11g中,执行如下脚本可查询当前数据库已经进行加密处理的表:
SQL> select * from V$ENCRYPTED_TABLESPACES;
- 评估结果
检查结果如下:
SQL> select * from DBA_ENCRYPTED_COLUMNS; no rows selected
即该系统目前没有采取Oracle的数据透明加密技术。
- 安全加固建议
为了提高数据安全性,特别是实现对关键而敏感数据的存储加密,建议尽快制定完备的数据存储加密实施计划。
为实现Oracle数据存储加密,需要采购Oracle Advanced Security选项,同时对数据库性能、存储空间略有影响。而且加密技术实施涉及安全需求分析,方案设计、测试和上线等工作,因此工作量和难度均较大。
- 标准审计评估
- 评估目的和内容
审计的主要功能是实现操作留痕,以此来发现系统可能存在的安全漏洞,辅助管理员及时修补,防止系统未来继续受到类似侵害。标准审计包含以下几种类型:
- 语句审计:对一类特定数据库结构或对象执行的一组相关语句进行审计,而不针对某个数据库结构或对象,其包含对DDL和DML两类语句的审计;语句审计面向所有数据库用户或某些特定用户的操作。
- 权限审计:审计使用了系统权限的语句,只有当用户执行的语句使用了系统权限,才会被审计;权限审计面向所有数据库用户或某些特定用户的操作。
- 对象审计:审计所有具有对象权限执行的相关SELECT和DML语句,控制这些对象权限的GRANT和REVOKE语句也会被审计;引用TABLE、VIEW、SEQUENCE、独立的Procedure、Function和Package等语句可以被审计;而引用CLUSTER、INDEX、DB LINK 、SYNONYM的语句无法被直接审计,但可以审计对应的基表。对象审计只面向所有数据库用户。
- 网络审计:可以揭示一些非连接错误的原因,例如加密配置的错误。
- 管理用户审计:审计以SYSDBA/SYSOPER身份连接数据库的用户。
标准审计提供的功能可以粗粒度地、在数据库对象一级审计所有数据库用户或特定用户执行的语句。为正常操作、可疑操作提供了统计、追逐手段。
- 评估方法
查看初始化参数和相关视图确认当前的标准审计配置情况。例如:
SQL> show parameter audit SQL> select count(*) from sys.aud$; SQL> select * from ALL_DEF_AUDIT_OPTS; SQL> select * from DBA_STMT_AUDIT_OPTS SQL> select * from DBA_PRIV_AUDIT_OPTS; SQL> select * from DBA_OBJ_AUDIT_OPTS; SQL> select * from DBA_AUDIT_TRAIL; SQL> select * from DBA_AUDIT_OBJECT; SQL> select * from DBA_AUDIT_SESSION; SQL> select * from DBA_AUDIT_STATEMENT; SQL> select * from DBA_AUDIT_EXISTS;
- 评估结果
检查结果如下:
SQL> show parameter audit NAME TYPE VALUE ------------------------------------ ---------------------- ------------------------------ audit_file_dest string /oracle/app/oracle/admin/oraDB /adump audit_sys_operations boolean FALSE audit_syslog_level string audit_trail string NONE SQL> select count(*) from sys.aud$; COUNT(*) ---------- 0 select * from ALL_DEF_AUDIT_OPTS; select * from DBA_STMT_AUDIT_OPTS; select * from DBA_PRIV_AUDIT_OPTS; select * from DBA_OBJ_AUDIT_OPTS; select * from DBA_AUDIT_TRAIL; select * from DBA_AUDIT_OBJECT; select * from DBA_AUDIT_SESSION; select * from DBA_AUDIT_STATEMENT; select * from DBA_AUDIT_EXISTS; select * from DBA_AUDIT_POLICIES; select * from DBA_FGA_AUDIT_TRAIL; All no rows selected
可见,该系统目前没有进行任何标准审计操作。
- 安全加固建议
建议针对不同的数据访问监控需求,合理使用标准审计技术。
审计操作涉及审计需求分析,方案设计、测试和上线工作,工作量和难度较大。
安全性评估总结
以下是针对该系统所发现安全性问题的汇总:
| 评估类别 | 评估项 | 问题描述 | 影响程度 | 解决方式建议 | 难度及风险 | 备注 |
| 数据库安装及配置 | 缺省安全设置 | PROFILE_NEW的FAILED_LOGIN_ATTEMPTS设置为UNLIMITED | 小 | 将PROFILE_NEW的FAILED_LOGIN_ATTEMPTS设置为缺省值10 | 小,无风险 | |
| UNLIMITED表空间检查 | BOCNET、BOCRPT具有UNLIMITED TABLESPACE权限 | 中 | 将不需要UNLIMITED TABLESPACE权限的用户,在指定表空间设置quota | 中等难度和风险 | ||
| 应用级用户对SYSTEM和SYSAUX表空间没有将使用限额设置为0 | 小 | 将应用级用户对SYSTEM和SYSAUX表空间的使用限额设置为0 | 小,无风险 | |||
| 版本和安全补丁检查 | 10.2.0.4版本旧,而且没有实施PSU补丁和CPU补丁 | 高 | 升级到10.2.0.5,以及相应的PSU补丁和小补丁 | 大,有一定风险 | 参照版本和补丁分析报告 | |
| 用户帐号安全性 | 缺省帐号保护评估 | SYSTEM用户状态为LOCKED(TIMED),无法访问SYSTEM用户 | 小 | 将 SYSTEM用户恢复为OPEN状态 | 小,无风险 | |
| 缺省口令检查 | 处于OPEN状态的PERSTAT为缺省口令 | 小 | 修改缺省口令
删除PERFSTAT用户 |
小,无风险 | ||
| 口令管理策略评估 | 口令管理没有严格的安全限制 | 高 | 根据安全管理需要,设置不同的口令管理参数 | 大,有一定风险 | 需要采购Oracle Advanced Security产品 | |
| 口令复杂度评估 | 没有设置口令复杂度检查 | 高 | 运行Oracle提供的utlpwdmg.sql | 大,有一定风险 | 涉及应用程序的改造 | |
| 外部口令实施评估 | 没有使用外部口令 | 高 | 通过Oracle高级安全产品,实施外部口令管理 | 大,有一定风险 | 需要采购Oracle Advanced Security产品 | |
| 用户权限安全性 | 权限及角色评估 | 角色激活无口令认证 | 小 | 为角色激活增加口令认证 | 大,有一定风险 | 重建角色,并重新为用户分配角色 |
| BOCNET、BOCRPT帐号被赋予了DBA角色 | 小 | 确认是否可以收回 | 小,有一定风险 | |||
| 系统权限评估 | BOCNET、BOCRPT具有UNLIMITED TABLESPACE权限 | 中 | 将不需要UNLIMITED TABLESPACE权限的用户,在指定表空间设置quota | 中等难度和风险 | ||
| SYSDBA角色访问控制 | 没有进行SYSDBA角色访问控制 | 中 | sqlnet.ora文件进行如下配置:
SQLNET.AUTHENTICATION_SERVICES = (none) |
小,无风险 | ||
| Nologging表检查 | 存在大量设置为nologging方式的表 | 中 | 与应用开发团队确认这些nologging表 | 大,有一定风险 | ||
| 用户资源管理检查 | 没有实施用户资源管理技术 | 中 | 根据不同用户级别资源管理需求,实施资源管理技术 | 大,有一定风险 | ||
| 数据库网络传输安全性 | 网络连接安全性检查 | 没有进行SSL配置 | 中 | 实施SSL配置 | 大,有一定风险 | 需要采购Oracle Advanced Security产品 |
| 没有进行IP访问地址的限制 | 中 | 实施IP访问地址的限制,例如只允许指定WAS服务器、管理监控终端等访问数据库。 | 小,有一定风险 | 重新启动Listener,应用也需要重新连接 | ||
| 没有进行连接超时检查 | 小 | 实施连接超时检查 | 小,有一定风险 | 重新启动Listener,应用也需要重新连接 | ||
| 网络传输加密检查 | 服务器与客户端之间传递数据采用明文方式 | 高 | Net8通讯等实施SSL加密传输 | 大,有一定风险 | 需要采购Oracle Advanced Security产品 | |
| 数据加密和访问控制 | 透明数据加密 | 没有实施Oracle的数据透明加密技术 | 高 | 实施Oracle的数据透明加密技术 | 大,有一定风险 | 需要采购Oracle Advanced Security产品 |
| 文件级加密 | 没有采用Secure Backup技术 | 中 | 实施Secure Backup技术 | 大,有一定风险 | 需要采购Oracle Advanced Security产品 | |
| Data Pump没有采用加密口令技术 | 中 | 实施Data Pump加密口令技术 | 大,有一定风险 | 需要采购Oracle Advanced Security产品 | ||
| 应用级加密检查 | 采用应用级数据加密技术 | 中 | 为实现对数据存储更灵活的加密,建议考虑应用级数据加密技术的实施 | 大,有一定风险 | 需要采购Oracle Advanced Security产品 | |
| 常规访问控制检查 | BOCNET、BOCRPT等普通用户对保存在SYS用户中的REPORT_DIR、EXPDP_DIR等表有访问权限 | 小 | 与该系统应用团队沟通,如果不合理,建议改进。 | 中,风险待估 | ||
| Recyclbin没有进行定期删除 | 小 | DBA定期进行Recyclbin清理 | 小,有一定风险 | |||
| 普通用户对其他普通用户对象的访问权限较多 | 小 | 如无访问必要,建议收回 | 大,有一定风险 | 与应用紧密相关 | ||
| 虚拟私有数据库(VPD)实施检查 | 目前没有采用VPD技术 | 中 | 实施VPD技术 | 大,有一定风险 | ||
| 标签安全数据库(Label Security)实施检查 | 没有采用Label Security技术 | 中 | 实施Label Security技术 | 大,有一定风险 | 该产品为Oracle安全产品选项 | |
| 数据屏蔽实施检查 | 没有实施Data Masking产品 | 中 | 实施Data Masking产品 | 大,有一定风险 | 该产品为Oracle安全产品选项 | |
| Oracle Database Vault实施检查 | 没有实施Oracle Database Vault产品 | 中 | 实施Oracle Database Vault产品 | 大,有一定风险 | 该产品为Oracle安全产品选项 | |
| 数据库审计 | 标准审计评估 | 没有进行任何标准审计操作 | 中 | 针对不同的数据访问监控需求,合理使用标准审计技术 | 大,有一定风险 | |
| FGA审计信息评估 | 没有实施FGA审计操作 | 中 | 针对不同的数据访问监控需求,合理使用FGA审计技术 | 大,有一定风险 | ||
| 集中审计评估 | 未实施Audit Vault产品 | 中 | 针对不同的数据访问监控需求,合理使用Audit Vault集中审计技术 | 大,有一定风险 | 该产品为Oracle安全产品选项 |
- 安全性评估汇总
- 虽然该系统存在一定的安全性问题,但在总体上,特别是在不涉及Oracle高级安全选项的常规安全性配置方面,并没有特别严重的安全性问题。
- 该系统版本较低,是需要急待改进的问题。
- 该系统目前存在的大部分安全问题的解决,一方面都涉及到Oracle安全性相关高级产品的采购和实施。例如:Oracle Advanced Security、Data Masking、Oracle Database Vault、Oracle Audit Vault等。另一方面与应用紧密相关,需要与应用开发团队全面合作,共同进行加固方案的设计和实施。
- Oracle安全性相关高级产品的实施,都需要进行安全需求分析、方案设计、测试和上线等工作,工作量和难度均较大。
本章参考资料及进一步读物
本章参考资料及进一步读物:
| 序号 | 资料类别 | 资料名称 | 资料概述 |
| 1. | Oracle 11g R2联机文档 | 《Oracle® Database Security Guide》 | 这是Oracle联机文档中有关数据库安全性的权威文档,涉及数据层、访问控制层、审计层等多个层面的产品和技术。 |
| 2. | My Oracle Support | 《Security Checklist: 10 Basic Steps to Make Your Database Secure from Attacks (Doc ID 1545816.1)》 | “10件防止数据库遭受攻击的基本措施”―――― 看标题就很诱人。 |
| 3. | My Oracle Support | 《Security Vulnerability FAQ for Oracle Database and Fusion Middleware Products (Doc ID 1074055.1)》 | “Oracle数据库和中间件安全性和易攻击性常见问题解答”――――题目同样诱人。 |
| 4. | My Oracle Support | 《All About Security: User, Privilege, Role, SYSDBA, O/S Authentication, Audit, Encryption, OLS, Database Vault, Audit Vault (Doc ID 207959.1)》 | 有关用户、权限、角色、审计、加密等多个Oracle数据库安全性产品和技术的资料集结地。 |
| 5. | My Oracle Support | 《System Change Number (SCN), Headroom, Security and Patch Information (Doc ID 1376995.1)》 | 什么叫SCN?Headroom?该文档给出了官方解释,包括SCN和Headroom概念、工作原理,以及可能遇到的Bug和patch等。 |
| 6. | My Oracle Support | 《UNIX: Checklist for Resolving Connect AS SYSDBA Issues (Doc ID 69642.1)》 | 当以SYSDBA方式连接数据库时,可能发生ORA-03113、ORA-01031、ORA-01034等多种错误。该文档给出了这些错误的发生原因和解决办法。 |