作者为: SHOUG成员 – ORACLE ACS高级顾问罗敏
第一章 逻辑设计中那些事
数据库逻辑设计是从事数据库应用设计、开发、运行维护等各方面工作的一个重要的基础性工作。根据不同的业务和应用需求,确定并遵循数据库逻辑设计原则,比如按照第三范式(3NF)开展逻辑设计,不仅能满足减少数据冗余、保证数据一致性和完整性、易扩展性和伸缩性等需求,而且也是保障系统高性能的一个重要基础。
一次,本人与一家公司进行为期3天的数据库性能优化培训。为达到良好的培训效果,事前与该公司几位技术骨干就培训大纲进行讨论,其中一位客户就提到:“罗老师,增加一个逻辑设计的专题吧,特别是讲讲一些最佳实践经验和常见的设计错误。”可见,该客户也深深体验到了逻辑设计的重要性。
于是,本书就以数据库逻辑设计开篇了。本章首先将以若干年前一个典型案例开始,进而介绍关于数据库设计的规范化理论,以及逻辑设计的工具Oracle Data Modeler,然后介绍非规范化设计的若干最佳实践,最后将针对逻辑设计发表若干感悟。
还是从案例开始
十多年前在一个网站从事专职DBA工作的某一天,一位开发人员过来请我帮忙分析她编写的一个简单SQL语句的性能问题。以下是具体情况:
- 语句和执行计划
语句再简单不过,即查询“喜欢文学的所有客户”。
Select id,name,hobby from customer where hobby like ‘%文学%’
执行计划如下:

可见对CUSTOMER表进行全表扫描。当年该网站客户数就已经达到千万级,查询性能可想而知。
- 问题原因分析
事实上,该开发人员已经在hobby字段上建立了索引,为什么Oracle不采用这个索引来提高查询效率呢?原因就在于like ‘%文学%’操作中的前面一个%号。因为B*树索引是个排序的东西,如果你需要匹配查询包含‘文学’二字的所有内容,那Oracle就无序可循,没必要使用这个索引了。
进一步观察customer表的内容如下:
SQL> Select id,name,hobby from customer; ID NAME HOBBY ---------- -------------------- ------------------------------ 1 张三 文学,艺术,电影 2 李四 运动,文学,电影 3 王五 登山,旅游,文学,艺术 … … … …
哦,原来她是这么设计表的,把客户所有爱好都塞在一个字段HOBBY中了,所以查询条件只能写成like ‘%文学%’。问题根本原因是该表的逻辑设计不符合规范化设计理论,从而导致了全表扫描。
下面先介绍数据库规范化设计原理,然后再回头介绍该简单案例在数据库设计和应用方面的优化。
什么叫规范化设计?
关于数据库规范化设计定义
以下是维京百科中关于数据库规范化设计的经典定义:
“数据库规范化,又称数据库或资料库正规化、标准化,是数据库设计中的一系列原理和技术,以减少数据库中数据冗余,增进数据的一致性。关系模型的发明者埃德加·科德最早提出这一概念,并于1970年代初定义了第一范式、第二范式和第三范式的概念,还与Raymond F. Boyce于1974年共同定义了BC范式。”
以下是关系数据库老大Oracle公司对第一范式、第二范式和第三范式的经典定义:
| Rule | Description |
| First normal form (1NF) | All attributes must be single-valued. |
| Second normal form (2NF) | An attribute must be dependent upon its entity’s unique identifier. |
| Third normal form (3NF) | No non-UID attribute can be dependent on another non-UID attribute. |
深奥吧。老罗略加翻译,并给出一些更通俗的解释:
- 第一范式(1NF):所有属性必须是单值的,或者说是原子化(primitive)的,不可分割的。
- 第二范式(2NF):所有属性必须依赖于该实体的唯一标识属性,也就是说每个实体应该有唯一标识属性。
- 第三范式(3NF):没有一个非唯一标识属性依赖于另一个非唯一标识属性,也就是说实体中不存在传递的依赖关系。
不符合规范化设计的若干案例
对抽象概念加深理解的最好办法就是举例。
- 违反第一范式的例子
显然,上述案例就是违反了第一范式。因为HOBBY字段不是单值的,包含了“文学,艺术,电影”等多个值,因此也不是原子化的,是可以分割的。该案例的优化设计将在下节专门讲述。
如下的客户表( CLIENT)设计也是违反第一范式的:

一个客户可能被联系多次,这样客户表(CLIENT)的联系日期(Data Contacted)、联系详情(Contact Details)字段都包含多个值。正确的设计应该如下:
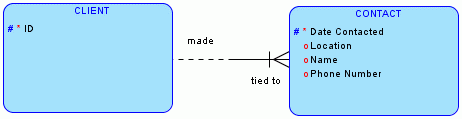
即再设计一个联系表(CONTACT),将每位客户的每次联系信息都记录在该表中,因此CLIENT表和CONTACT表形成1对多的关系。这样,两张表的所有属性都是单值了。
- 违反第二范式的例子
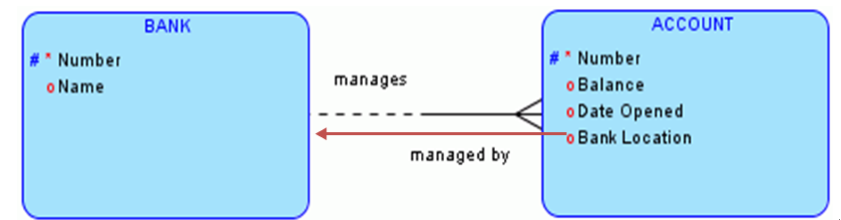
上述为银行表(BANK)、账户表(ACCOUNT)的设计,二者为1对多关系。即一个银行包含多个账户,而一个账户只属于一个银行。该设计违反了第二范式,因为ACCOUT表中的Bank Location字段并不依赖于该表的主键Number字段,而是依赖于BANK表的主键Number字段。正确设计是将BANK Location字段移到BANK表。
- 违反第三范式的例子
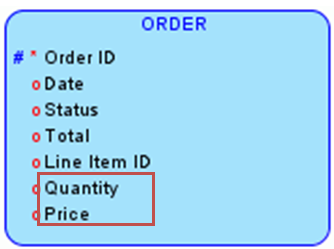
上述订单表(ORDER)的设计违反了第三范式。因为数目(Quantity)和 价格(Price)字段依赖于订单号(Order ID)和产品号(Line Item ID)组成的组合字段,而ORDER表的主键是Order ID,也就是说该表存在传递的依赖关系。
正确的设计应该如下:
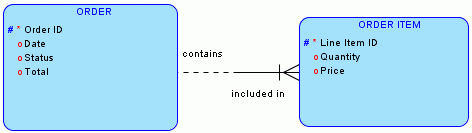
即另外设计一张订单详情表(ORDER ITEM),二者为1对多关系,而ORDER ITEM表的主键为(Order ID、Line Item ID),这样Quantity和Price就依赖于ORDER ITEM表的主键(Order ID、Line Item ID)了。
回到案例
我们再回到上述案例,看如何进行数据库设计的优化和应用优化。
数据库设计优化
以下是该案例优化之后的实体-关系(E-R)图设计:

即保持原来的客户表(CUSTOMER),但去掉爱好(HOBBY)字段,同时增加爱好代码表(HOBBY)用于保存所有爱好信息,以及描述客户-爱好关系的CUST_HOBBY表。 CUSTOMER表和HOBBY表形成n:m关系,即每个客户可能有多个爱好,每个爱好可能为多个客户所具有。其中CUST_HOBBY表的主键为客户编号(C_ID)和爱好编号(H_ID)所形成的组合字段。
这样,每个字段都是不可分解的(1NF),每个表的字段都依赖于其主键( 2NF),每个表也没有传递依赖关系的存在(3NF)。—– 这就是符合第三范式的设计。
应用优化
根据上述数据库优化设计结果,查询所有喜爱“文学”的客户信息SQL语句如下:
SQL> Select c.c_id, c.c_name from customer c, cust_hobby c_h, hobby h where c.c_id = c_h.c_id and h.h_id = c_h.h_id and h.h_name = '文学'
执行计划如下:
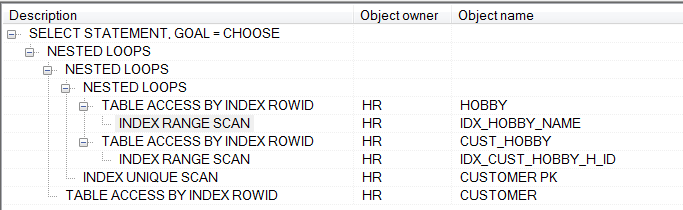
可见该语句已经没有任何全表扫描操作,查询效率显著提高。具体过程为:
- 先通过在HOBBY表的H_NAME字段的索引检索出“文学”记录。
- 其次,通过在CUST_HOBBY表H_ID字段上的索引检索出喜欢“文学”的客户号(C_ID)。
- 最后,根据这些C_ID号,通过在 CUSTOMER表C_ID段上的主键检索出这些客户的详细信息。
SQL语句和执行过程虽然复杂了,但效率显著提高了。
规范化设计的好处
我们现在普遍采用的数据库技术包括Oracle、DB2、SQL*Server等在内,都是典型的关系型数据库。所谓关系型数据库就是基于关系代数理论,依据规范化设计原则,将现实世界中的事物按实体、关系、属性等要素进行划分和描述,并通过结构化查询语言(SQL)进行数据的存储、访问、操作和管理的技术。1970年,IBM研究员E.F.Codd发表了著名的《A Relational Model of Data for Large Shared Data banks》,首次提出了数据库的关系模型的概念,并奠定了关系模型的理论基础。在关系模型中,最重要的设计原则就是规范化设计。规范化设计的好处如下:
- 提高访问效率
通过上述案例的详细介绍,大家已经看到了通过规范化设计和合理的索引设计,如何保证查询效率的提高。
- 降低数据冗余
继续分析案例,最初的设计不遵循第一范式,这样,“文学”一词在多条记录中会重复出现,导致了数据出现冗余。
- 保证数据一致性
在上述案例中,多条记录出现“文学”。如果一不小心,录成了“文 学”,就成了不同的内容,like ‘%文学%’就查不出“文 学”了。这就是数据不一致性。
- 易扩展性和伸缩性
逻辑设计来源于具体的应用需求,但我们应尽可能建立一个与应用无关的逻辑模型,这样使得业务的变化对数据模型的影响最小,避免出现大规模的数据库结构重组,从而保证灵活适应应用变化的易扩展性和伸缩性。
感慨:在国内 IT系统中,很多数据库都包含成百上千的表,甚至上万的表。我们猜想数据库设计和应用开发人员一定没有综合分析各种数据特点和访问需求,更没有按规范化设计原则对信息进行分类、归类和汇总,而是将各种业务简单映射成不同的表,所以导致太多表的存在。这里面有多少数据冗余、多少数据不一致啊。作为客户和IT系统最重要资源的信息资源就这么杂乱无章地堆砌在一起,不仅数据质量不高,访问效率低下,也无法得到有效应用,多么让人心痛啊!
“这系统是你设计的?”
2012年秋天,本人去拜访某银行客户,共同商讨该银行征信系统的服务问题。接待我们的客户DBA虽然是初次相识,但因我当年曾全程参与过该系统的设计、开发、测试和上线工作,因此,DBA早就对我有所耳闻了。于是,有这么个重要系统作为共同交流的平台,我们很快就熟络了,DBA对我也很快从最初的客套和尊敬,转为单刀直入了:
“这系统是你设计的?”DBA这口气分明是兴师问罪嘛,呵呵。
“我参与设计了,有什么具体问题吗?”我不是谦虚,而是实话实说。
“这系统好多信息都塞在一个字段里面,我们现在都无法按某些要素进行查询!”DBA一脸怨气。
哈哈,我很快就明白了。因为DBA来该银行时间不太长,并没有参与当年的逻辑设计,于是我就将这个问题的来龙去脉讲给他听了:2004年该系统在进行逻辑设计时,我就发现开发单位的设计人员将很多信息都塞在一个字段里面了,例如将信用卡未按时还款的各种原因信息都塞在一个字段里,我当时与设计人员讨论,这不符合规范化设计的第1范式呀,以后要按某种原因进行信用卡未还款的统计分析就查不出来了!但是,当时设计人员告诉我的是,现在征信业务部门还没有提出这样具体的统计分析需求,于是,他们决定暂时不对这些信息进行结构化设计,而是先保存到数据库之中,以后再说。
没想到的是,业务部门很快就提出了这样的信息统计分析需求,更没想到的是,业务增长会这么快,该系统最核心的基础库已经快20TB了。此时进行数据库逻辑结构的大调整,不仅涉及表结构本身的调整,而且涉及数据加载、查询统计、数据管理等大量应用程序的调整,难度太大了。
这就是IT行业的一个典型问题:虽然技术是为业务服务的,但技术应该有一定的前瞻性。不过也难怪,毕竟征信业务在中国是新鲜事物,大家都在摸着石头过河。于是征信二代系统已经在规划,并且已经启动了。这次我没有机会参与其中了,衷心希望新一代设计人员能站在更高的高度上,在充分了解业务需求基础上,设计出一个比一代系统更漂亮的逻辑模型,避免若干年后再出现我的上述尴尬。呵呵。
规范化设计工具:Oracle Data Modeler
针对企业级数据库和数据仓库系统的设计,切勿停留于刀耕火种的手工操作阶段了,而是充分发挥相关数据库设计工具的使用。下面简要介绍Oracle 11g的Oracle SQL Developer Data Modeler工具。该工具为Oracle公司提供的免费软件,可从该地址下载:http://www.oracle.com/technetwork/developer-tools/datamodeler/downloads/datamodeler-087275.html。本书只介绍该工具的主要功能,该工具的详细使用说明请见该工具的联机文档了。
Data Modeler工具概述
以下是数据库和应用设计开发的主要阶段和内容:
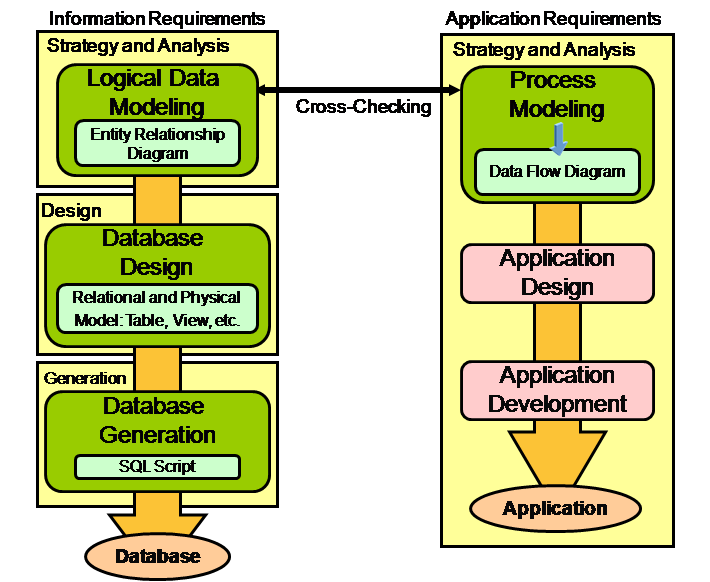
Data Modeler工具可支持上述阴影部分内容,即数据库设计方面的逻辑模型设计、关系模型设计和物理模型设计,以及数据库最终脚本的产生。同时具有反向工程(re-enginnering)能力,即将现有的一个数据库系统的指定对象可还原成关系模型和逻辑模型。
在应用开发方面,Data Modeler只支持数据流程图(Data Flow Diagram, DFD图)的设计,而不支持应用设计和应用开发阶段的工作。
Data Modeler中的E-R图设计
E-R图的设计是规范化设计的重要手段,通过Data Modeler工具,可有效进行E-R图设计,例如:
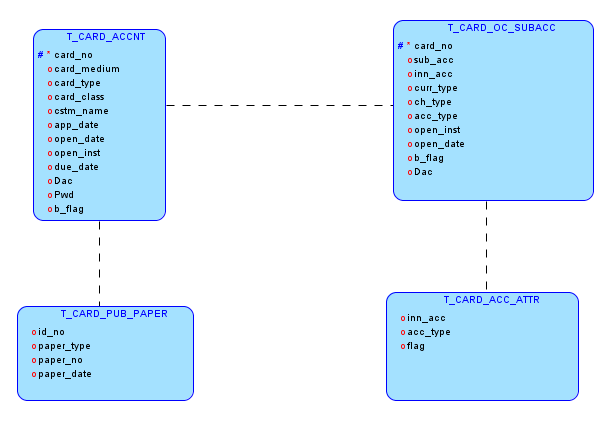
通过E-R图,可以达到如下目的:
- 清晰、准确地描述数据关联关系
- 增强数据库规范化设计
- 管理、业务、技术人员之间沟通的有效工具
- 有效指导设计、开发过程
- 增强数据库字典和元数据管理
- 灵活适应未来业务变更和扩展性需求
- 有效定义项目边界
Data Modeler中的DFD图设计
Data Modeler可全面支持DFD图的设计,例如以下是Data Modeler中设计的DFD图范例:
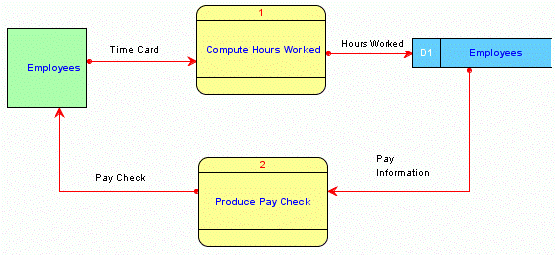
数据流向图(DFD图)的设计,可以达到如下目的:
- 清晰、准确地描述应用对数据的操作关系,以及数据流向关系
- 有利于业务功能模块的划分
- 管理、业务、技术人员之间沟通的有效工具
- 分析数据处理特点,有利于数据库物理设计
- 灵活适应未来业务变更和扩展性需求
- 有效定义项目边界
1.7 非规范化设计若干案例
最后招数:非规范化设计
一次在与客户进行培训交流中,当我准备开始规范化设计的专题介绍时,一位客户突然打断我:“罗老师,你先讲讲非规范化设计的经验吧。”我当时笑言之:“您别着急,我们先学会走,再开始跑吧,否则会摔跤的。”—-国内很多IT技术控都是这样,基本技术都没掌握住,老想整点邪的。呵呵。
什么叫非规范化设计?非规范化设计就是当运用其它优化手段,例如索引策略等,已经很难达到理想的性能状态的时候,通过降低数据库规范化设计程度,特别是增加数据库冗余的方式来提高性能的一种策略。这种策略虽然在某些情况下的确能显著提高性能,但付出的代价是数据冗余和数据一致性的下降,数据维护成本(DML操作)的提高,特别是应用复杂性的增加。因此,关于非规范化设计,Oracle公司给出如下建议:
- 先从规范化设计开始
- 将非规范化设计作为性能优化的最后招数
- 当性能指标满足之后,不要再做进一步的非规范化设计工作了
- 将整个非规范化过程记录在案,包括非规范化的模型设计,以及应用程序进行的相应变更
下面还是满足部分技术控们的好奇心,介绍非规范化设计的若干最佳实践经案例。
案例1:保存导出值或汇总值
以下是案例E-R图:
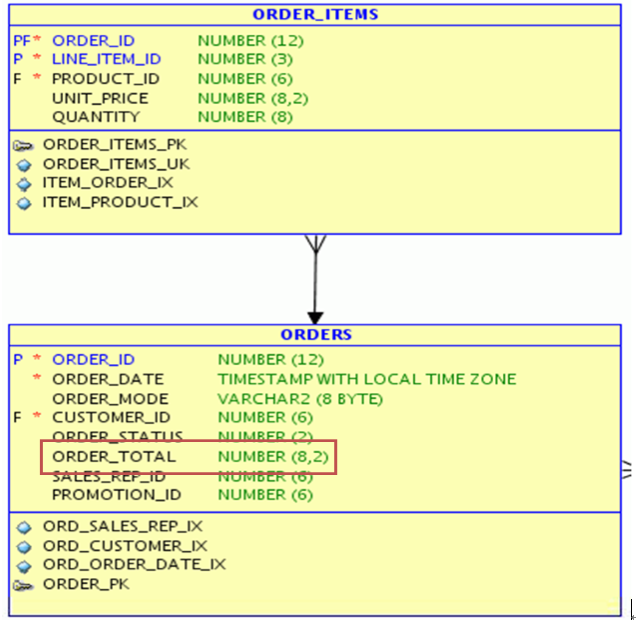
上述模型包括订单主表(ORDERS)和订单详表(ORDERS_ITEMS),二者为1:N关系。如果在ORDERS表中增加一个ORDER_TOTAL字段,用于保存某份订单的总金额。这样,在需要频繁查询订单总金额的情况下,就只需要查询ORDERS一张表就可以了。
这种技术的优点是:只需访问导出或汇总数据,无需访问明细表,也无需进行复杂的计算。但缺点是:当明细数据发生变化时,需要重新计算导出或汇总数据,不仅导致正常交易性能受影响,而且应用复杂性增加。同时,这种设计违反了第二范式,即ORDER_TOTAL字段并不依赖于ORDERS表的主键ORDER_ID字段,这种情况下有可能导致数据不一致性。
因此,这种技术适合于如下情况:
- 明细数据比较多,甚至分布在多张子表。
- 频繁访问导出值或汇总值,而明细数据访问频度不高。
- 明细数据修改频度不高。
案例2:预连接表
以下是案例E-R图:
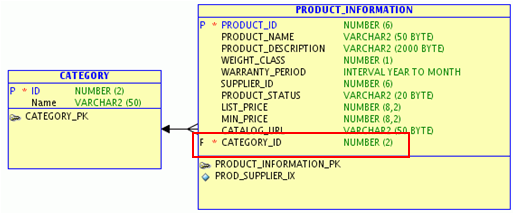
上述模型包括产品信息表(PRODUCT_INFORMATION)和产品分类表(CATEGORY),二者为1:N关系。通常情况下,查询分类信息需要对两张表进行连接操作。但如果在PRODUCT_INFORMATION表中增加CATEGORY_NAME字段,如下图所示:
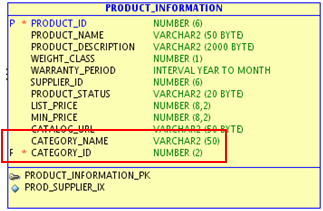
则不需要进行两张表的连接操作了,将显著提高查询效率。
这种技术的优点是:避免了很大耗时、消耗资源的连接操作,但缺点也非常明显:首先设计违反了第三范式。其次,当代码数据变化时,有可能导致数据不一致性,需要额外的DML来维护主表和代码表的数据一致性。第三,耗费了更多的数据和索引空间。
因此,这种技术适合于如下情况:
- 频繁访问,并且涉及多个表的连接
- 被预连接表的数据相对稳定,或者允许有一定的数据不一致性。
案例3:取消代码表
以下是案例E-R图:
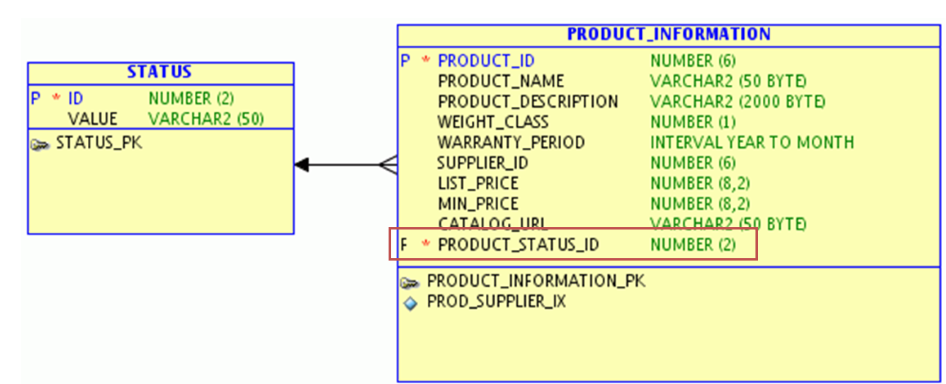
上述模型包括产品信息表(PRODUCT_INFORMATION)和产品状态表(STATUS),二者为1:N关系。假设产品状态就这么几种固定值,例如0,1,2等。这样,可以在PRODUCT_INFORMATION表的PRODUCT_STATUS_ID中增加一个CHECK constaint检查,只允许输入0,1,2几个值。同时在应用编程中,通过 case … when … 语句将这些状态代码(0,1,2等)转换为具体的状态值。因此,STATUS表就可以不要了。
这种技术的优点是:很多简单的代码表就可以不要了,降低了表连接的开销。缺点是当代码值发生变化时,需要修改相关CHECK constaint,甚至需要修改相关的SQL语句。
因此,这种技术适合于如下情况:
- 代码值不多,例如少于30。
- 代码值相对稳定,变化较少。
案例4:主表保存明细数据
以下是案例E-R图:
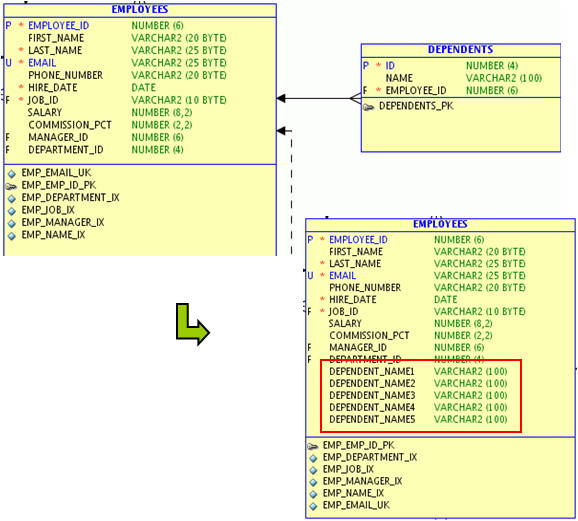
上述模型包括员工信息表(EMPLOYEES)和员工下属表(DEPENDENTS),二者为1:N关系。如果每名员工的下属表比较少,则可以将下属信息直接作为字段存储在EMPLOYEES主表中,如上图下角的EMPLOYEES表。
这种技术的优点是:避免了表连接操作,节约了部分空间,因为DEPENDENTS子表不需要了,也不存储多余的主键字段了。缺点是:数据维护成本提高,数据可能不一致性。
因此,这种技术适合于如下情况:
- 明细数据或子表数据较少,例如不超过30。
- 明细数据或子表数据变化较少。
案例5:主表保存最新明细数据
以下是案例E-R图:
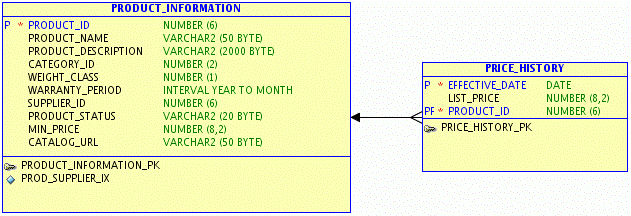
上述模型包括产品信息表(PRODUCT_INFORMATION)和产品价格历史信息表(PRICE_HISTORY),二者为1:N关系。PRICE_HISTORY表记录了产品价格变化的历史信息。如果大多数情况下只需要查询当前最新的产品价格,则可以进行如下的模型调整:
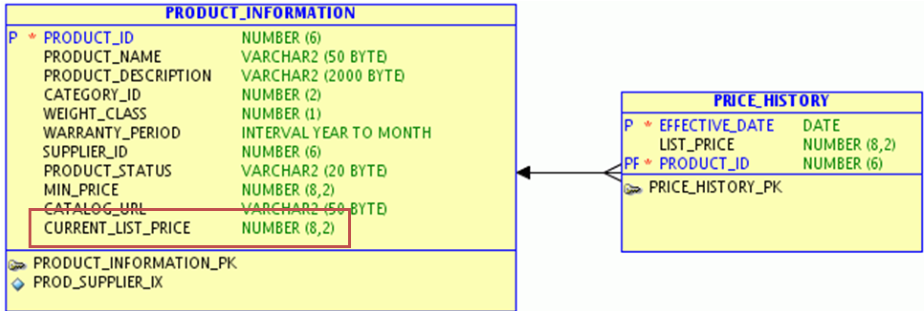
即在PRODUCT_INFORMATION主表中增加一个CURRENT_LIST_PRICE字段,用于保存最新的产品价格,这样就可以通过只查询PRODUCT_INFORMATION表而获得最新产品价格了。
这种技术的优点是:避免了表连接操作。缺点是:数据维护成本提高,数据可能不一致性。
因此,这种技术适合于如下情况:
- 通常只访问当前最新数据,访问历史明细数据的频度较低。
- 最新数据在历史明细数据表中能清晰地表示出来,例如在上述PRICE_HISTORY表中,可提高对EFFECTIVE_DATE字段进行排序而检索出最新数据。
案例6:与祖辈直接关联
以下是案例E-R图:
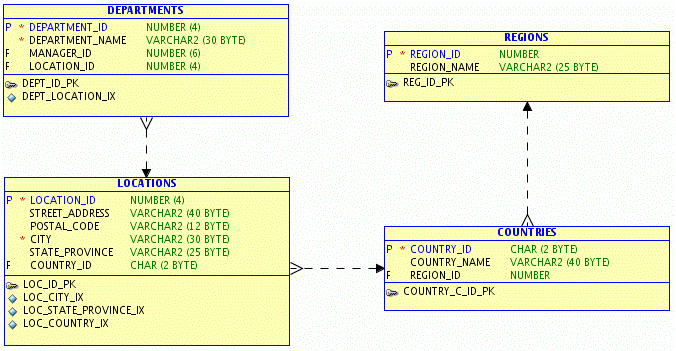
上述模型包括部门信息表(DEPARTMENTS)、地区表(LOCATIONS)、国家表(COUNTRIES)和洲表(REGIONS),并依次形成1:N关系,这种模型在数据仓库雪花模型中经常出现。如果频繁查询DEPARTMENTS表和REGIONS,则可以考虑进行如下的模型调整:
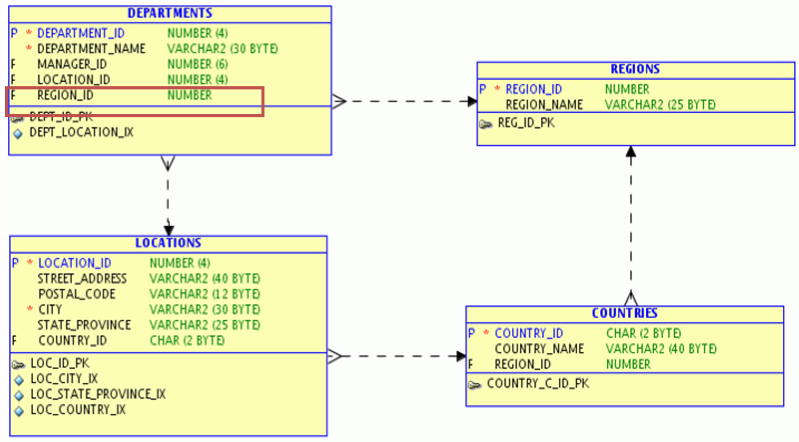
即在DEPARTMENTS表中增加一个REGION_ID字段,这样就可以避免对LOCATIONS和COUNTRIES表的查询,而只查询DEPARTMENTS和REGIONS表了。
这种技术的优点是:避免了表连接操作,上例中只需要与曾祖父进行连接,不需要与父亲和祖父进行连接。缺点是:由于增加了额外的外键,导致数据维护成本提高,数据可能出现不一致性。
因此,这种技术适合于如下情况:
- 频繁访问高层数据,例如祖父和曾祖父的数据。
- 高层数据相对稳定。
关于数据库逻辑设计的感悟
写了那么多数据库逻辑设计方面的东西,尤其是画了或拷贝、粘贴了那么多图,联想到与之相关的诸多往事,也触发了很多感悟。现表述如下:
20多年前的数据库逻辑设计
在我刚参加工作的1988年,就有幸接触了当年的Oracle 5版数据库,并摸着石头开始进行数据库设计和开发工作。感谢当年遇到了一位好领导,在那个数据库应用刚起步,Oracle公司都没有进入中国的年代,他带领我们进行数据库逻辑设计和应用开发的第一课就是画 E-R图和数据流程图。当年别提数据库设计工具软件了,连个像样的画图软件都没有,于是我们直接用笔在纸上画。以下是我们当年画的E-R图模样:
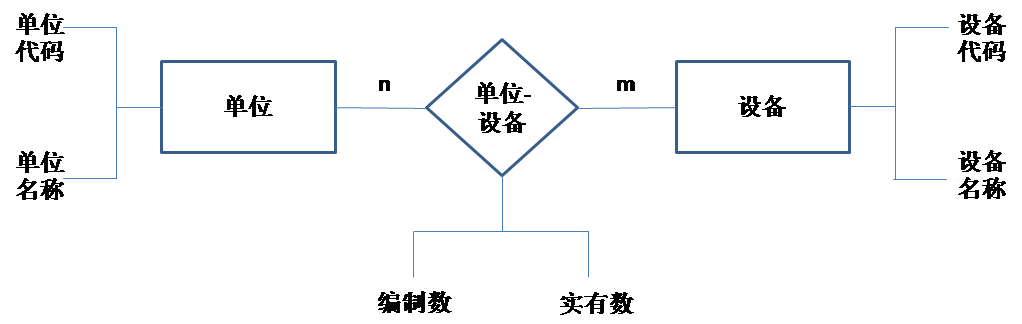
上述E-R图包括单位和设备两个实体表,单位和设备之间形成n:m关系,因此还有单位-设备关系表。其中单位实体包括单位代码、单位名称等属性,设备实体包括设备代码、设备名称等属性,单位-设备关系表则包括单位代码、设备代码、编制数、实有数等。
以下是我们当年画的数据流程图模样:

这是当年软件工程学中讲述的IPO(Input – Process – Output)图,可不是现在股票市场的IPO(首次公开募股,Initial Public Offerings)的概念哦。呵呵。
我现在是通过PPT画的,比当年手工描绘的漂亮多了。在20多年后我初次接触Data Modeler工具时,发现该工具所具有的功能与我们20多年前所做的工作惊人的相似!再次感叹当年那位领导的睿智和前瞻性。
一幅图抵过千言万语
2011年国内某银行要在Oracle数据库平台实施全国大集中了,为确保系统设计质量,我们Oracle公司技术服务团队被盛情邀请加入到该项目组中,并被明确赋予参与物理设计的重任。
数据库逻辑设计是物理设计的重要依据。于是,在参加项目第一天,我们就向应用开发商询问逻辑设计情况,开发商设计人员倒是非常支持和配合,马上给了我们大量设计文档。但除了一大堆描述各表结构的 Word文档之外,一张图都没有,包括E-R图和数据流向图。尽管设计人员后来分专题给我们介绍逻辑设计情况,我们仍然是如坠云雾之中。试想如果盖房子连个结构设计图都没有,施工者如何理解、如何施工?施工质量如何保障?这种情况在国内IT系统建设中并不少见。
当然,经过我们的努力推荐,后来该项目组还是通过Data Modeler工具在E-R图和数据流向图方面进行了大量工作,为提高系统设计质量打下了非常好的基础。
别自己吓唬自己
还是回到上述银行案例,待我们与设计人员深入沟通,特别是想通过Data Modeler工具描述E-R图时,才发现该系统在逻辑设计上具有如下一些特点:
- 很多表都没有主键
- 没有设计一个外键关系
- 多个标志信息全部压缩在一个字段中
- … …
据说没有主键是因为业务数据本身的问题,我们姑且不论。我们在此仅讨论后两个问题。
- 外键问题
没有一个外键关系,说明表和表之间没有任何关联关系,也就没有什么E-R图可画了。即便在Data Modeler中画出来,也是一个个信息孤岛,无任何美感而言,呵呵。当然更重要的是数据一致性无法保障,数据冗余度大。
为什么不设计外键关系呢?设计人员的回答是担心影响性能。于是,我们还真的开展了一次外键性能测试。测试结果如下:
| 类型 | 无外键 | 有外键 | 效率差别 |
| 主表单条插入时长 | 99 | 99 | 100% |
| 子表单条插入时长 | 98 | 122 | 124% |
| 子表单条更新时长 | 89 | 85 | 96% |
| 子表批量更新时长 | 21 | 21 | 100% |
可见,在有外键的情况下,对主表没有任何影响。对子表的插入操作回略微慢一点,子表的单条记录更新反而更快,批量更新则相当。
总之,有无外键对性能影响并不大。即便略有下降,也总比冒着数据不一致、数据质量不高等风险要强吧。凡事都要综合平衡,更不要自己吓唬自己。
- 标志位问题
该系统逻辑设计大量采用一个字段保存多个标志位的方案。据设计人员讲好处在于节省存储空间,也易于扩展。但风险和问题呢?
首先,由于没有遵循第一范式,可能存在无法使用索引的风险。例如,很可能按如下形式进行操作:
where … substr(flag1,1,2)=’01’ and substr(flag,3,2)=’02’ …
大家一定知道这样编写语句的风险:字段中包括函数会抑制索引的;创建函数索引代价也太高。
其次,如果按这种标志位进行检索和统计汇总,更有效的索引应该是位图(Bitmap)索引。但这样把所有标志位都塞在一个字段里,Bitmap索引怎么建?
第三,所谓节省存储空间纯属多虑。如果设计一个Flag字段为8位number,与设计8个1位number的Flag字段, Oracle存储开销是一样的。大不了,后者数据字典的内容略多一点而已。
第四,所谓易于扩展也是多虑。在表的最初设计时可以预留几个字段作为未来扩展之需。即便以后需要增加字段,现在技术已经高速发展,也不是什么大不了的难事。Oracle 9i就有在线表结构重定义(Online Redefinination)功能,可以不用停止应用运行,就在线修改表结构。
还是这句话:凡事都要综合平衡,更不要自己吓唬自己。再加一句:按事物本身规律办。
授人以鱼不如授人以渔
一本书涉足诸多技术领域,又想写出一定深度和实用性,几乎是不可能的。于是,本人在该书写作过程中,遵循出版社的真知灼见,将在每章描述一个专题之后,提供编写本章的参考资料及进一步读物,供大家深入研究之用。这些资料分为如下几类:
- Oracle联机文档
毫无疑问,Oracle联机文档不仅是Oracle公司最权威、最官方的技术资料,而且也是浩瀚的Oracle知识海洋。不客气地讲,不阅读Oracle联机文档,其实还没有完全入Oracle的门。再次重复本人在《品悟性能优化》一书中一句话:“如果想成为Oracle技术专家,每天阅读Oracle联机文档一个小时!”。
以下就是Oracle 11g、12c联机文档的下载网址:
http://www.oracle.com/technetwork/database/enterprise-edition/documentation/index.html
建议大家免费登陆Oracle官方技术网站,并将这些联机文档下载至本地。
- Oracle技术白皮书
针对不同技术领域和产品,Oracle公司都编写了技术白皮书(White Paper),描述该技术和产品的概述、定位和运用场景。这些白皮书都可以在Oracle官方技术网站http://www.oracle.com/technetwork/index.html通过输入技术关键字、White Paper等进行搜索。 例如输入“RAC、White Paper”等关键字。
- Oracle大学教材
Oracle大学(Oracle University,OU)为学习Oracle产品和技术提供了良好途径。本人在相关章节编写中,也参考了OU部分教材。可惜这些教材是Oracle公司内部资料,普通用户无法直接访问,除非报名参加了OU大学相关课程的培训。
- My Oracle Support(Metalink)
作为Oracle官方技术支持网站,My Oracle Support(http://support.oracle.com)或Metalink更是蕴藏了丰富的技术资源,例如针对某个技术或产品,Metalink中都有一个Master Notes的文档,汇集了该领域的相关文档目录,Metalink也是本人写作此书的重要源泉。不过该网站不是免费的,是需要客户在每年采购Oracle标准服务(Preimier Service)之后,通过账号进行访问,强烈建议大家能拥有访问该网站的能力。当年本人能访问Metalink了,才感觉到真正打开了Oracle大门,更发现原来Oracle世界这么精彩!
在本书每章罗列的资料中,有关Metalink资料均可通过搜索ID号进行访问。例如:《Master Note: Troubleshooting Oracle Database Initialization Parameters (Doc ID 1515259.1)》的ID号为1515259.1,该文档描述了有关Oracle数据库初始化参数故障诊断的文章。
“罗老师,能提供中文资料吗?”的确,上述资料几乎全是英文资料。其实从事IT技术工作的阅读英文没有问题,只是大家的习惯问题。还是给大家提个建议:针对Oracle这样的技术资料,还是阅读英文原文吧,毕竟这才是最原汁原味的。
一个小段子:90年代我的一位老同事及老前辈成为了中国的第一个8i OCP。但是当年有一门考试他差点没及格,原因就是考题翻译成中文了,他对很多翻译后的题目都不知所云。而后一门改成英文之后,他考了个满分!
1.10 本章参考资料及进一步读物
本章的参考资料及进一步读物:
| 序号 | 资料类别 | 资料名称 | 资料概述 |
| 1. | Oracle 11g R2联机文档 | 《Oracle Database Concept》 | 该书若干章节,特别是Part II的第2章至第6章,讲述了数据库表、索引、分区、视图、物化视图、数据库一致性、数据字典等相关技术原理和设计工作的方方面面。这些就是普通数据库逻辑设计的重要内容。 |
| 2. | Oracle 11g R2联机文档 | 《Oracle Data Warehousing Guide》 | 该书若干章节,特别是Part II Logical Design等内容是数据仓库系统逻辑设计的重要内容,例如星型模型、事实表、维表、层次的设计等。 |
| 3. | Oracle大学教材 | 《Oracle Data Modeling and Relational Database Design》 | 该教材第11章:“Normalizing Your Data Model”和第17章“Denormalizing Your Design to Increase Performance”介绍了规范化设计基础理论和非规范化设计最佳实践经验,可惜普通读者访问不了Oracle大学的教材,除非您报名参加了这门课程的培训。 |