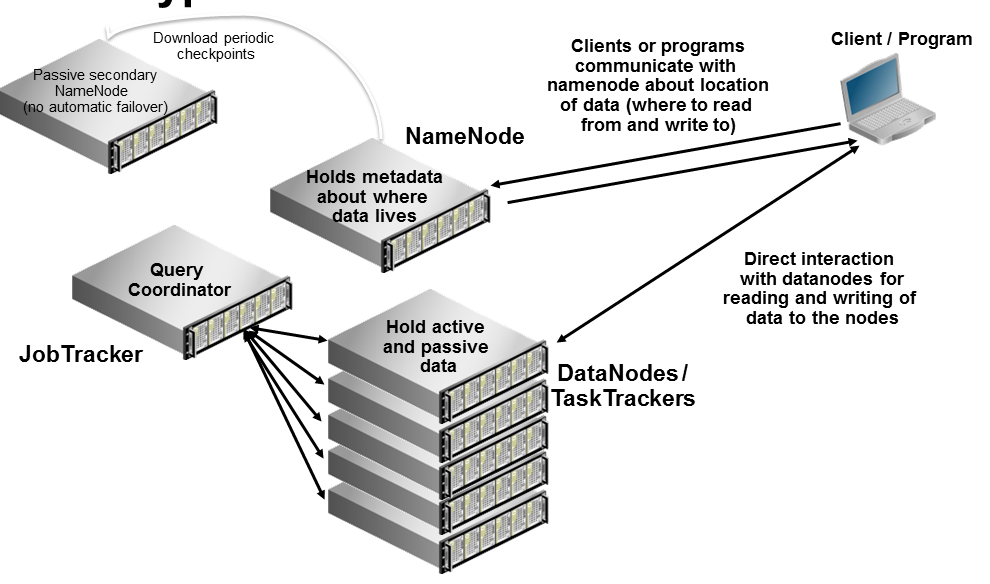
随着DigitalOcean上专用网络来临,我想用一个基于droplet的集群取代我的本地物理Cloudera Hadoop集群。其中关于使用DigitalOcean droplet最好的就是,你可以快照任何图像和破坏VM,当他们不在使用和你无需他们。不好的方面是,专用网络上DigitalOcean droplet实施并不能保证任何安全,只要其他主机在同一专用网络上,你应该在使用专用网络时考虑到这一点;因频宽是自由的,它不是真正的私有。
这里我们概述了4主机群集耗资0.15美元 /小时(1X0.06美元+ 3X0.03美元/小时),使之成为一个连接率很高的平台。
如果你不熟悉DigitalOcean – 它们提供了非常简单,便宜的虚拟服务器(droplets在DigitalOcean说法)。
我将使用Cloudera Manager自动化安装程序指南,我发现这是管理群集一个很好的工具。