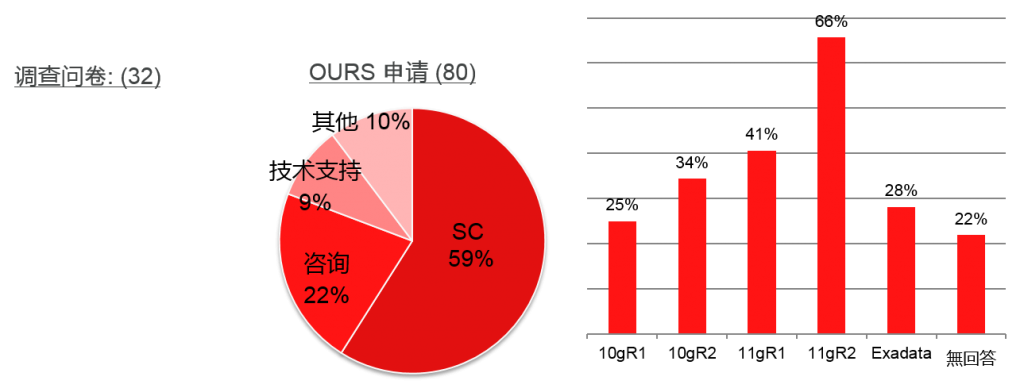
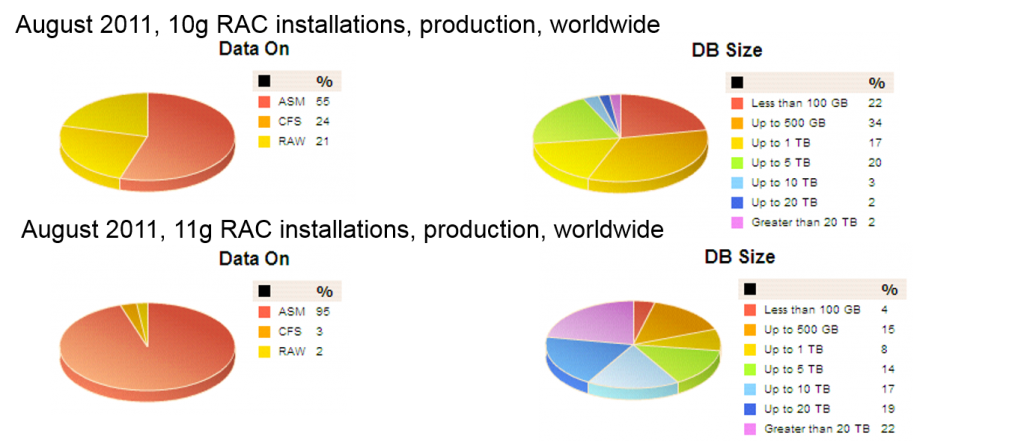
11g的asmca图形化工具启动后可能存在问题, 对于已经启动的ASM实例无法识别, 报是否需要启动asm实例。
asmca的日志位于 ASMCA logs from $ORACLE_BASE/cfgtoollogs/asmca/*
日志显示:
[main] [ 2013-09-26 15:53:29.906 GMT+08:00 ] [InventoryUtil.getOUIInvSession:336] oracleHome is null. Leaving OUI properties to defaults [Finalizer thread] [ 2013-09-26 15:53:29.912 GMT+08:00 ] [Util.finalize:126] Util: finalized called for oracle.ops.mgmt.has.Util@32523252 [main] [ 2013-09-26 15:53:29.917 GMT+08:00 ] [InventoryUtil.getOUIInvSession:347] setting OUI READ level to ACCESSLEVEL_READ_LOCKLESS [main] [ 2013-09-26 15:53:29.917 GMT+08:00 ] [OracleHome.getVersion:957] Current Version From Inventory: null [main] [ 2013-09-26 15:53:29.918 GMT+08:00 ] [SQLPlusEngine.getCmmdParams:222] m_home null [main] [ 2013-09-26 15:53:29.918 GMT+08:00 ] [SQLPlusEngine.getCmmdParams:223] version > 112 false [main] [ 2013-09-26 15:53:29.918 GMT+08:00 ] [SQLEngine.getEnvParams:555] Default NLS_LANG: AMERICAN_AMERICA.AL32UTF8 [main] [ 2013-09-26 15:53:29.918 GMT+08:00 ] [SQLEngine.getEnvParams:565] NLS_LANG: AMERICAN_AMERICA.AL32UTF8 [main] [ 2013-09-26 15:53:29.919 GMT+08:00 ] [SQLEngine.initialize:325] Execing SQLPLUS/SVRMGR process... [main] [ 2013-09-26 15:53:29.920 GMT+08:00 ] [UsmcaLogger.logException:173] SEVERE:method oracle.sysman.assistants.usmca.backend.USMInstance:checkAndStartupInstance [main] [ 2013-09-26 15:53:29.920 GMT+08:00 ] [UsmcaLogger.logException:174] There is an error in creating the following process: null/bin/sqlplus -S /NOLOG The error is: null/bin/sqlplus: not found [main] [ 2013-09-26 15:53:29.920 GMT+08:00 ] [UsmcaLogger.logException:175] java.io.IOException: There is an error in creating the following process: null/bin/sqlplus -S /NOLOG The error is: null/bin/sqlplus: not found
oracleHome is null 与 null/bin/sqlplus: not found 2点都很可疑,怀疑是ORACLE_HOME/ORACLE_BASE/ORAINVENTORY信息问题, 之后发现/etc/目录下 缺失oraInst.loc和oratab。
重建oratab并填入ASM实例名字及ORACLE_HOME后问题解决, 真的是什么细节都不能忽视