华南某电商企业出现ASM diskgroup损坏情况,直接导致生产核心EBS数据库无法使用。 诗檀软件工程师在分析了其具体ASM DISKGROUP的受损情况后,手动Patch了对应的ASM DISK后,成功将ASM Diskgroup MOUNT起来,将用户的宕机时间减到了最少。
华南某电商企业出现ASM diskgroup损坏情况,直接导致生产核心EBS数据库无法使用。 诗檀软件工程师在分析了其具体ASM DISKGROUP的受损情况后,手动Patch了对应的ASM DISK后,成功将ASM Diskgroup MOUNT起来,将用户的宕机时间减到了最少。
D公司的某套核心CRM库由于加入到ASM Diskgroup中的少量磁盘存在I/O问题,导致SYSTEM表空间的DBF数据文件发生讹误,导致数据库无法打开。
此时即可以通过PRM恢复软件从ASM Diskgroup中将DATAFILE全部克隆到文件系统上,如恢复场景6中所述,并进一步修复数据库。
也可以通过PRM的《Dictionary Mode(ASM)》即基于ASM的字典模式来直接恢复问题数据库。其简要步骤如下:
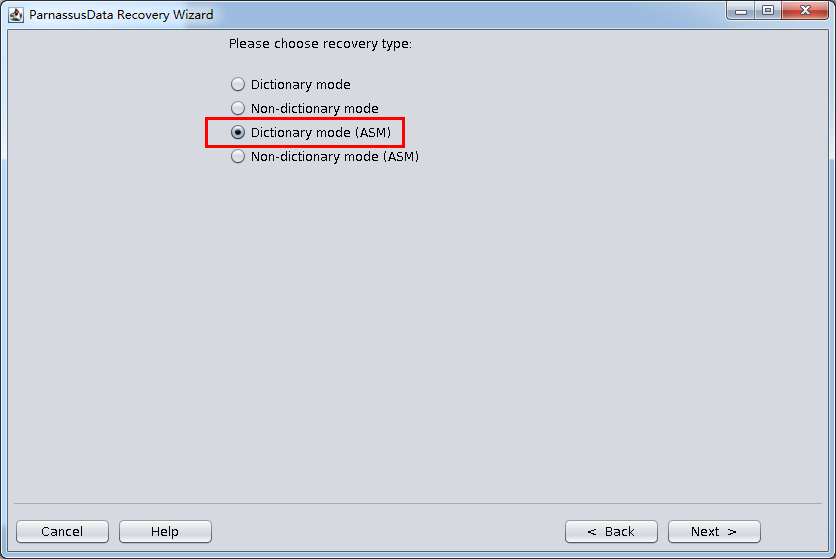
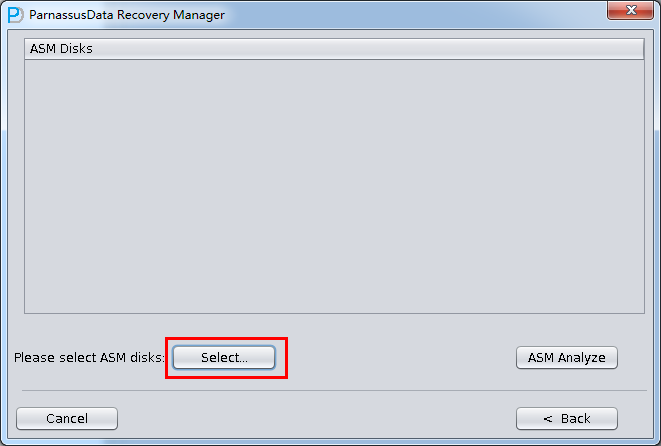
Oracle ASM Diskgroup数据恢复终极方案PRM-DUL工具
下载最新版PRM:
https://zcdn.parnassusdata.com/DUL5108.zip
PRM用户手册:
http://www.parnassusdata.com/sites/default/files/ParnassusData%20Recovery%20Manager%20For%20Oracle%20Database%E7%94%A8%E6%88%B7%E6%89%8B%E5%86%8C%20v0.3.pdf
ORACLE的ASM自动存储管理技术正被越来越多的企业采用,数据库采用ASM存储对比传统文件系统具有高性能、支持集群、管理方便等优势。 但ASM的问题在于,对于普通用户而言ASM的存储结构过于黑盒了,一旦ASM中的某个Disk Group的内部数据结构发生了损坏导致Disk Group无法被成功MOUNT,也就意味着用户重要的数据被锁死在这个ASM的黑盒中了。在这种场景中往往需要熟悉ASM内部数据结构的ORACLE原厂的资深工程师到达用户现场后通过手动修复ASM内部结构;而购买ORACLE原厂的现场服务对普通用户而言显得即昂贵又耗时。
基于PRM的研发人员(前ORACLE公司资深工程师)对ORACLE ASM内部数据结构的深入理解,PRM中加入了特别针对ASM的数据恢复功能。
PRM目前支持的ASM数据恢复功能包括:
1. 即便Disk Group无法正常MOUNT,仍可以通过PRM直接读取ASM磁盘上的可用的元数据metadata,并基于这些元数据将Disk Group中的ASM文件拷贝出来
2. 即便Disk Group无法正常MOUNT,仍可以通过PRM直接读取ASM上的数据文件,并抽取其中的数据,支持传统抽取方式和数据搭桥方式。
PRM对ASM的支持
| 功能 | Supported |
| 支持直接从ASM中抽取数据,无需拷贝到文件系统上 | YES |
| 支持从ASM中拷贝数据文件 | YES |
| 支持修复ASM metadata | YES |
| 支持图形化展示ASM黑盒 | Future |
社区版中ASM clone功能无任何限制,今后社区版将加入更多免费新特性
D公司开始采用ASM方案来替代文件系统和裸设备,但是由于使用的11.2.0.1版本ASM上Bug较多导致ASM DISKGROUP磁盘组无法加载MOUNT,通过多方修复ASM Disk Header无果。
此场景可以使用PRM的ASM Files Clone文件克隆功能从受损的ASM Diskgroup中拷贝出数据库数据文件。
之后点击ASM Clone按钮,进入文件克隆阶段。
文件克隆阶段中,将列出ASM File的克隆进度,克隆完成后点击OK。
克隆阶段的进度日志输出如下:
| Preparing selected files…
Cloning +DATA2/ASMDB1/DATAFILE/TBS2.256.839732369: ……………………..1024MB ………………………………..2048MB ………………………………..3072MB ………………………………….4096MB ………………………………..5120MB ………………………………….6144MB ……………………………….7168MB …………………………………8192MB …………………………………9216MB …………………………………10240MB …………………………………11264MB …………………………………..12288MB …………………………………….13312MB …………………………….14336MB ……………………………………..15360MB ……………………………….16384MB …………………………………17408MB …………………………………18432MB …………………………………………………………………………………………….19456MB …………………………………… Cloned size for this file (in byte): 21475885056
Cloned successfully!
Cloning +DATA2/ASMDB1/ARCHIVELOG/2014_02_17/thread_1_seq_47.257.839732751: …… Cloned size for this file (in byte): 29360128
Cloned successfully!
Cloning +DATA2/ASMDB1/ARCHIVELOG/2014_02_17/thread_1_seq_48.258.839732751: …… Cloned size for this file (in byte): 1048576
Cloned successfully!
All selected files were cloned done. |
| rman target /
RMAN> catalog datafilecopy ‘/home/oracle/asm_clone/TBS2.256.839732369.dbf’;
cataloged datafile copy datafile copy file name=/home/oracle/asm_clone/TBS2.256.839732369.dbf RECID=2 STAMP=839750901
RMAN> validate datafilecopy ‘/home/oracle/asm_clone/TBS2.256.839732369.dbf’;
Starting validate at 17-FEB-14 using channel ORA_DISK_1 channel ORA_DISK_1: starting validation of datafile channel ORA_DISK_1: including datafile copy of datafile 00016 in backup set input file name=/home/oracle/asm_clone/TBS2.256.839732369.dbf channel ORA_DISK_1: validation complete, elapsed time: 00:03:35 List of Datafile Copies ======================= File Status Marked Corrupt Empty Blocks Blocks Examined High SCN —- —— ————– ———— ————— ———- 16 OK 0 2621313 2621440 1945051 File Name: /home/oracle/asm_clone/TBS2.256.839732369.dbf Block Type Blocks Failing Blocks Processed ———- ————– —————- Data 0 0 Index 0 0 Other 0 127
Finished validate at 17-FEB-14
|
对于使用ASMLIB的ASM环境要如何使用PRM呢?
其实也很简单,asmlib相关的ASM DISK在OS操作系统上会以ll /dev/oracleasm/disks 的形式存放,例如:直接将/dev/oracleasm/disks下的文件加入到PRM ASM DISK中即可
| $ll /dev/oracleasm/diskstotal 0
brw-rw—- 1 oracle dba 8, 97 Apr 28 15:20 VOL001 brw-rw—- 1 oracle dba 8, 81 Apr 28 15:20 VOL002 brw-rw—- 1 oracle dba 8, 65 Apr 28 15:20 VOL003 brw-rw—- 1 oracle dba 8, 49 Apr 28 15:20 VOL004 brw-rw—- 1 oracle dba 8, 33 Apr 28 15:20 VOL005 brw-rw—- 1 oracle dba 8, 17 Apr 28 15:20 VOL006 brw-rw—- 1 oracle dba 8, 129 Apr 28 15:20 VOL007 brw-rw—- 1 oracle dba 8, 113 Apr 28 15:20 VOL008 |
直接将/dev/oracleasm/disks下的文件加入到PRM ASM DISK中即可。
某用户ASM实例遇到ORA-00600 [kfdAuDealloc2]错误,详细日志如下:
Errors in file /opt/oracle/diag/asm/+asm/+ASM1/trace/+ASM1_arb6_15539.trc: ORA-00600: internal error code, arguments: [kfdAuDealloc2], [35], [272], [748], [], [], [], [], [], [], [], [] NOTE: stopping process ARB6 ERROR: ORA-600 thrown in ARB2 for group number 1 Errors in file /opt/oracle/diag/asm/+asm/+ASM1/trace/+ASM1_arb2_15523.trc: ORA-00600: internal error code, arguments: [kfdAuDealloc2], [148], [270], [720], [], [], [], [], [], [], [], [] NOTE: stopping process ARB2 ERROR: ORA-600 thrown in ARB3 for group number 1 Errors in file /opt/oracle/diag/asm/+asm/+ASM1/trace/+ASM1_arb3_15527.trc: ORA-00600: internal error code, arguments: [kfdAuDealloc2], [196], [271], [0], [], [], [], [], [], [], [], [] NOTE: stopping process ARB3 ERROR: ORA-600 thrown in ARB5 for group number 1 Errors in file /opt/oracle/diag/asm/+asm/+ASM1/trace/+ASM1_arb5_15535.trc: ORA-00600: internal error code, arguments: [kfdAuDealloc2], [363], [272], [1], [], [], [], [], [], [], [], [] NOTE: stopping process ARB5 Errors in file /u02/oracle/ASM/diag/asm/+asm/+ASM/trace/+ASM_rbal_27162.trc (incident=674120): ORA-00600: internal error code, arguments: [kfdAuDealloc2], [101], [335], [300], [], [], [], [], [], [], [], [] Incident details in: /u02/oracle/ASM/diag/asm/+asm/+ASM/incident/incdir_674120/+ASM_rbal_27162_i674120.trc Use ADRCI or Support Workbench to package the incident. See Note 411.1 at My Oracle Support for error and packaging details. ERROR: An unrecoverable error has been identified in ASM metadata. The instance will be taken down. Sun Nov 25 20:51:11 2012 NOTE: AMDU dump of disk group DWHCTL1 created at /u02/oracle/ASM/diag/asm/+asm/+ASM/incident/incdir_674120 NOTE: starting check of diskgroup DWHCTL1 ERROR: file +dwhctl1.330.797592669: F330 PX11 => D0 A7650 => F385 PX135: fnum mismatch ERROR: file +dwhctl1.330.797592669: F330 PX12 => D0 A7651 => F385 PX136: fnum mismatch
kfdAuDealloc2意味着Kernel Files Disk AU DEALLOCate ,其负责回收ASM DISK上的AU 。发生该错误一般说明 ASM metadata中的allocation table可能存在逻辑上的数据不一致。
相关bug :
Bug 5682184 OERI[kfdAuDealloc2] from resize/drop more than 16TB ASM file
Bug 10621169 I/O errors during RAC ASM recovery may drop redo and cause metadata corruptions / ORA-600
BUG 10017130 – ORA-600 [KFDAUDEALLOC2] DURING REBALANCE AFTER ADDING DISKS
出现该问题情况下可能需要手动patch asm metadata,建议联系Oracle Support原厂 或诗檀软件 13764045638。
More about _asm_repairquantum
参数_asm_repairquantum的值调大。让rebalance有足够的时间 结束。对于10g 的版本我们可以调高参数_asm_droptimeout 来拉长drop的间隔, 对于11g的版本,这个参数被重命名为_asm_repairquantum。
某10.2.0.5 ASM系统由于存储故障导致normal redundancy diskgroup中的4个failgroup中的2个failgroup的ASM DISK均无法访问,在10g中若ASM disk无法访问将直接将disk drop出diskgroup中。
报错如下:
Sat Nov 15 17:05:36 CST 2013 WARNING: PST-initiated drop disk 1(739802527).1(3915943320) WARNING: PST-initiated drop disk 1(739802527).3(3915943321) Sat Nov 15 17:05:36 CST 2013 NOTE: PST update: grp = 1 Sat Nov 15 17:05:36 CST 2013 ERROR: too many offline disks in PST (grp 1) Sat Nov 15 17:05:36 CST 2013 ERROR: ORA-15066 signalled during reconfiguration of diskgroup DATADG NOTE: requesting all-instance membership refresh for group=1 Sat Nov 15 17:05:36 CST 2013 NOTE: membership refresh pending for group 1/0x2c187d9f (DATADG) WARNING: rejecting drop force of disk number 1 WARNING: rejecting drop force of disk number 3 SUCCESS: refreshed membership for 1/0x2c187d9f (DATADG) Sat Nov 15 17:05:39 CST 2013 ERROR: PST-initiated disk drop failed Sat Nov 15 17:05:39 CST 2013 ERROR: PST-initiated MANDATORY DISMOUNT of group DATADG NOTE: cache dismounting group 1/0x2C187D9F (DATADG) Sat Nov 15 17:05:39 CST 2013 NOTE: halting all I/Os to diskgroup DATADG
由于是normal redundancy,所以只能丢失一个failgroup。ASM尝试drop 2个failgroup时会导致diskgroup被强制DISMOUNT,即PST-initiated MANDATORY DISMOUNT of group DATADG。
PST-initiated drop disk =》 PST初始化drop disk
ERROR: too many offline disks in PST (grp 1) ==> ASM认为若drop 这么多disk会导致丢失数据,所以是too many offline disk
WARNING: rejecting drop force of disk number 1
WARNING: rejecting drop force of disk number 3 ==> ASM拒绝drop这些disk
ERROR: PST-initiated disk drop failed==> PST初始化drop disk失败
ERROR: PST-initiated MANDATORY DISMOUNT of group ORADATA==》 强制dismount diskgroup
以上对于该asm diskgroup的维护将陷入死循环,即 mount diskgroup => 开始drop disk=> 由于drop disk过多 导致asm 强制dismount diskgroup => 人为再次手动mount diskgroup。 该ASM Diskgroup实际变得不可用了。
我们可以通过设置隐藏参数或者手动patch PST的方式来绕过该问题,具体需要了解ASM 底层数据结构的工程师现场根据实际情况实施,再次不再鏖述。
_ __
(_)/ \
<‘_, ____)~~~~~~~
^^ ^^
【Oracle ASM数据恢复】ORA-00600 [KFRVALACD30]错误解析,某用户遇到ORA-00600 [kfrValAcd30]错误 且导致无法打开ASM实例,之前用户有断电重启过操作系统。
该错误的stack call如下:
如果自己搞不定可以找诗檀软件专业ORACLE数据库修复团队成员帮您恢复!
诗檀软件专业数据库修复团队
服务热线 : 13764045638 QQ号:47079569 邮箱:service@parnassusdata.com
STACK TRACE:
————
skdstdst <- ksedst1 <- ksedst <- dbkedDefDump <- ksedmp
<- ksfdmp <- dbgexPhaseII <- dbgexProcessError <- dbgeExecuteForError
<- dbgePostErrorKGE
<- 1615 <- dbkePostKGE_kgsf <- kgeadse <- kgerinv_internal <-
kgerinv
<- kgeasnmierr <- kfrValAcd <- kfrgnr <- kfrgnc <- kfrPass1
<- kfrcrv <- kfcMountPriv <- kfcMount <- kfgInitCache <-
kfgFinalizeMount
<- 2149 <- kfgscFinalize <- kfgForEachKfgsc <- kfgsoFinalize <-
kfgFinalize
<- kfxdrvMount <- kfxdrvEntry <- opiexe <- opiosq0 <- kpooprx
<- kpoal8 <- opiodr <- ttcpip <- opitsk <- opiino
<- opiodr <- opidrv <- sou2o <- opimai_real <- ssthrdmain
<- main <- libc_start_main <- start
kfrValAcd Reap the current log read I/O.
该错误的原因是当recovery diskgroup时,发现ACD记录的seq=111,而实际ACD记录的seq=6
针对该问题 我们可以通过 PRM工具来抽取该问题diskgroup中的数据文件,并重建Diskgroup。
关于PRM FOR ORACLE 详见 http://parnassusdata.com/
ORA-15196: 无效的 ASM 块标头 [:] [] [] [] [ != ]
例如:
ORA-15196: invalid ASM block header [kfc.c:7997] [endian_kfbh] [1] [93] [211 != 0]
具体引起ORA-00600 [KFCEMA02]的场景是存在bug 6163771的版本上,可能当ASM实例崩溃后,mount一个diskgroup失败且报错为ORA-00600 [KFCEMA02]。
虽然ORACLE在多个平台上均提供了补丁bug 6163771,但由于这个补丁仅仅是预防出现该故障,而不能实际修复该故障。由于该故障的特殊性,其需要特殊的内部工具FACP才能具体修复,该工具负责修复ASM checkpoint信息,该工具的功能就是修复ASM Diskgroup上的特性metadata源数据。
ORA-00600: internal error code, arguments: [kfcema02], [0], [165057275], [], [], [], [], [], [], [], [], []
如果自己搞不定可以找诗檀软件专业ORACLE数据库修复团队成员帮您恢复!
诗檀软件专业数据库修复团队
服务热线 : 13764045638 QQ号:47079569 邮箱:service@parnassusdata.com
首先注意我们是不推荐用asmlib的,为什么请见Why ASMLIB and why not?
但如果真的遇到了使用asmlib的场景且用户误操作oracleasm deletedisk删除了ASM Disk上的 asmlib标签的话,可以通过下面的步骤来恢复:
1. backup database using RMAN
2. dismount the active Disk group
3. Create KFED following ‘unpublished’ Note 284646.1 Creating and using the kfed utility to view ASM disk header 4. Follow same note to perform kfed read on the affected disk headers.
5. Examine the output to verify that the header appears similar to the following:
kfbh.endian: 1 ; 0x000: 0x01
kfbh.hard: 130 ; 0x001: 0x82
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
kfbh.datfmt: 1 ; 0x003: 0x01
kfbh.block.blk: 0 ; 0x004: T=0 NUMB=0x0
kfbh.block.obj: 2147483648 ; 0x008: TYPE=0x8 NUMB=0x0 kfbh.check: 3808867501 ; 0x00c: 0xe306b4ad kfbh.fcn.base: 1463 ; 0x010: 0x000005b7
kfbh.fcn.wrap: 0 ; 0x014: 0x00000000
kfbh.spare1: 0 ; 0x018: 0x00000000
kfbh.spare2: 0 ; 0x01c: 0x00000000
kfdhdb.driver.provstr: ORCLCLRD ; 0x000: length=8 kfdhdb.driver.reserved[0]: 0 ; 0x008: 0x00000000 kfdhdb.driver.reserved[1]: 0 ; 0x00c: 0x00000000 kfdhdb.driver.reserved[2]: 0 ; 0x010: 0x00000000 kfdhdb.driver.reserved[3]: 0 ; 0x014: 0x00000000
The value ORCLCLRD is set after using /etc/init.d/oracleasm deletedisk 6. Assuming that kfbh.type = KFBTYP_DISKHEAD
and that kfdhdb.driver.provstr: = ORCLCLRD
for each disk this operation will be successful.
7. kfed read <device name> > fix.txt
8. Edit fix.txt to change only ORCLCLRD to ORCLDISK 9. kfed merge <device name> text=fix.txt
10. etc/init.d/oracleasm listdisk
11. etc/init.d/oracleasm force-renamedisk
This command requires 2 arguments the first is the full path to the disk the second is the LABEL that will be stamped on the disk.
如果自己搞不定可以找诗檀软件专业ORACLE数据库修复团队成员帮您恢复!
诗檀软件专业数据库修复团队
服务热线 : 13764045638 QQ号:47079569 邮箱:service@parnassusdata.com
