プロのOracle Databaseの復旧サービスを提供
携帯番号: +86 13764045638 メール:service@parnassusdata.com
バックアップリカバリはOracleに永遠の話。データさえあれば、リカバリする必要が現れる。けど、中国でバックアップはいつも無視された。これで、東と西の相違が現れた。海外のDBAはいつもOracle内部的な原理やオプティマイザに専念している。
DBAの習得する必要があるわざの一つ:バックアップなしにOracleデータベースのデータをリカバリする技術。海外ではかなり高級なわざだが、いつの間にか DBAに必要としているわざになった。
もちろん、バックアップなしにデータをリカバリするのはOracleデータファイル、データブロック及びデータディクショナリーに対する詳しい知識が必要としている。
ここではOracleデータリカバリの文である:何のバックアップもない状況でリカバリできる。例えば、DULとBBEDツールリカバリなどの技術。
【データリカバリ】ROWIDを構造することで、バックアップなしにORA-1578、ORA-8103、ORA-1410などのこわれたブロックトラブルを避けられる
【データリカバリ】ORA-600[kccpb_sanity_check_2]一例
Oracle rmanでset newnameが遅いかもしれない
どうやってOracleコントロールファイルの無駄記録を削除できるか。例えばv$archived_logのdeletedアーカイブログ記録
create or replaceに上書きされたPL/SQL对をどうやって取り戻せる
Archivelog Completed Before VS UNTIL TIME
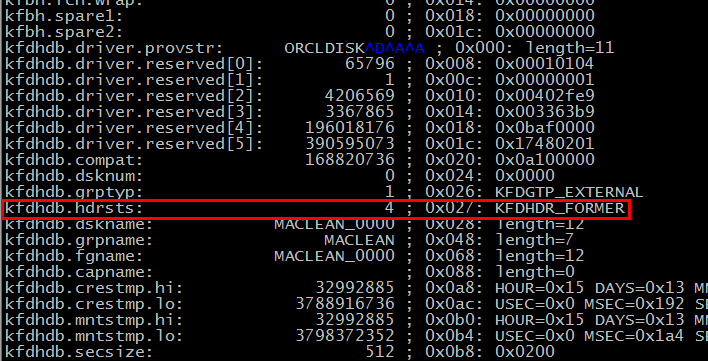
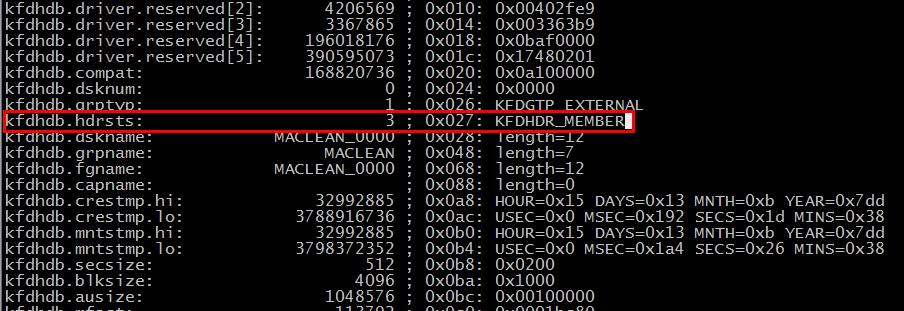
ASMがdisk headerをなくしたから、ORA-15032、ORA-15040、ORA-15042 になって、Diskgroupがmountできなくなった
Overcome ORA-600[4xxx] open database
データリカバリ:ORA-600[kghstack_free2][kghstack_err+0068]解決例
datafile nameに文字化けを含むデータファイルをどうやって再命名できるか
どうやってSYSAUXテーブルスペースの対象をリカバリできるか
Oracleデータリカバリ:ORA-00600:[4000] ORA-00704: bootstrap process failureエラ解決例
Script:データベースにバックアップしているかを確認してください
データリカバリ: 二つのこわれたブロックをシミュレーションする
Script:Oracleバックアップリカバリ情報を収集する
Oracleバックアップリカバリ:Rman Backupディレイトラブル一例
Oracle内部的なエラ:ORA-00600[2608]一例
bbedでORA-01189エラを解決する
Fractured block found during backing up datafile
人工的にSCN番号を増やす方法:How to increase System Change Number by manual
Oracle損害とこわれたブロックは主に以下の通り:
ORA-1578
ORA-8103
ORA-1410
ORA-1499
ORA-1578
ORA-81##
ORA-14##
ORA-26040
ORA-600 Errors
Block Corruption
Index Corruption
Row Corruption
UNDO Corruption
Control File
Consistent Read
Dictionary
File/RDBA/BL
| Error | Description | Corruption related to: | ||
| ORA-1578 | ORA-1578 is reported when a block is thought to be corrupt on read. | Block | ||
| OERR: ORA-1578 “ORACLE data block corrupted (file # %s, block # %s)” Master Note | ||||
| OERR: ORA-1578 “ORACLE data block corrupted (file # %s, block # %s)” | ||||
| Fractured Block explanation | ||||
| Handling Oracle Block Corruptions in Oracle7/8/8i/9i/10g/11g | ||||
| Diagnosing and Resolving 1578 reported on a Local Index of a Partitioned table | ||||
| ORA-1410 | This error is raised when an operation refers to a ROWID in a table for which there is no such row. The reference to a ROWID may be implicit from a WHERE CURRENT OF clause or directly from a WHERE ROWID=… clause. ORA 1410 indicates the ROWID is for a BLOCK that is not part of this table. |
Row | ||
| Understanding The ORA-1410 | ||||
| Summary Of Bugs Containing ORA 1410 | ||||
| OERR: ORA 1410 “invalid ROWID” | ||||
| ORA-8103 | The object has been deleted by another user since the operation began. If the error is reproducible, following may be the reasons:- a.) The header block has an invalid block type. b.) The data_object_id (seg/obj) stored in the block is different than the data_object_id stored in the segment header. See dba_objects.data_object_id and compare it to the decimal value stored in the block (field seg/obj). |
Block | ||
| ORA-8103 Troubleshooting, Diagnostic and Solution | ||||
| OERR: ORA-8103 “object no longer exists” / Troubleshooting, Diagnostic and Solution | ||||
| ORA-8102 | An ORA-08102 indicates that there is a mismatch between the key(s) stored in the index and the values stored in the table. What typically happens is the index is built and at some future time, some type of corruption occurs, either in the table or index, to cause the mismatch. | Index | ||
| OERR ORA-8102 “index key not found, obj# %s, file %s, block %s (%s) | ||||
| ORA-1499 | An error occurred when validating an index or a table using the ANALYZE command. One or more entries does not point to the appropriate cross-reference. |
Index | ||
| ORA-1499. Table/Index row count mismatch | ||||
| OERR: ORA-1499 table/Index Cross Reference Failure – see trace file | ||||
| ORA-1498 | Generally this is a result of an ANALYZE … VALIDATE … command. This error generally manifests itself when there is inconsistency in the data/Index block. Some of the block check errors that may be found:- a.) Row locked by a non-existent transaction b.) The amount of space used is not equal to block size c.) Transaction header lock count mismatch. While support are processing the tracefile it may be worth the re-running the ANALYZE after restarting the database to help show if the corruption is consistent or if it ‘moves’. Send the tracefile to support for analysis. If the ANALYZE was against an index you should check the whole object. Eg: Find the tablename and execute: ANALYZE TABLE xxx VALIDATE STRUCTURE CASCADE; |
Block | ||
| OERR: ORA 1498 “block check failure – see trace file” | ||||
| ORA-26040 | Trying to access data in block that was loaded without redo generation using the NOLOGGING/UNRECOVERABLE option. This Error raises always together with ORA-1578 |
Block | ||
| OERR ORA-26040 Data block was loaded using the NOLOGGING option | ||||
| ORA-1578 / ORA-26040 Corrupt blocks by NOLOGGING – Error explanation and solution | ||||
| ORA-1578 ORA-26040 in a LOB segment – Script to solve the errors | ||||
| ORA-1578 ORA-26040 in 11g for DIRECT PATH with NOARCHIVELOG even if LOGGING is enabled | ||||
| ORA-1578 ORA-26040 On Awr Table | ||||
| Errors ORA-01578, ORA-26040 On Standby Database | ||||
| Workflow Tables ORA-01578 ORACLE data block corrupted ORA-26040 Data block was loaded using the NOLOGGING option | ||||
| ORA-1578, ORA-26040 Data block was loaded using the NOLOGGING option | ||||
| ORA-600[12700] | Oracle is trying to access a row using its ROWID, which has been obtained from an index. A mismatch was found between the index rowid and the data block it is pointing to. The rowid points to a non-existent row in the data block. The corruption can be in data and/or index blocks. ORA-600 [12700] can also be reported due to a consistent read (CR) problem. |
Consistent Read | ||
| Resolving an ORA-600 [12700] error in Oracle 8 and above. | ||||
| ORA-600 [12700] “Index entry Points to Missing ROWID” | ||||
| ORA-600[3020] | This is called a ‘STUCK RECOVERY’. There is an inconsistency between the information stored in the redo and the information stored in a database block being recovered. |
Redo | ||
| ORA-600 [3020] “Stuck Recovery” | ||||
| Information Required for Root Cause Analysis of ORA-600 [3020] (stuck recovery) | ||||
| ORA-600[4194] | A mismatch has been detected between Redo records and rollback (Undo) records. We are validating the Undo record number relating to the change being applied against the maximum undo record number recorded in the undo block. This error is reported when the validation fails. |
Undo | ||
| ORA-600 [4194] “Undo Record Number Mismatch While Adding Undo Record” | ||||
| Basic Steps to be Followed While Solving ORA-00600 [4194]/[4193] Errors Without Using Unsupported parameter | ||||
| ORA-600[4193] | A mismatch has been detected between Redo records and Rollback (Undo) records. We are validating the Undo block sequence number in the undo block against the Redo block sequence number relating to the change being applied. This error is reported when this validation fails. |
Undo | ||
| ORA-600 [4193] “seq# mismatch while adding undo record” | ||||
| Basic Steps to be Followed While Solving ORA-00600 [4194]/[4193] Errors Without Using Unsupported parameter | ||||
| Ora-600 [4193] When Opening Or Shutting Down A Database | ||||
| ORA-600 [4193] When Trying To Open The Database | ||||
| ORA-600[4137] | While backing out an undo record (i.e. at the time of rollback) we found a transaction id mis-match indicating either a corruption in the rollback segment or corruption in an object which the rollback segment is trying to apply undo records on. This would indicate a corrupted rollback segment. |
Undo/Redo | ||
| ORA-600 [4137] “XID in Undo and Redo Does Not Match” | ||||
| ORA-600[6101] | Not enough free space was found when inserting a row into an index leaf block during the application of undo. | Index | ||
| ORA-600 [6101] “insert into leaf block (undo)” | ||||
| ORA-600[2103] | Oracle is attempting to read or update a generic entry in the control file. If the entry number is invalid, ORA-600 [2130] is logged. |
Control File | ||
| ORA-600 [2130] “Attempt to access non-existant controlfile entry” | ||||
| ORA-600[4512] | Oracle is checking the status of transaction locks within a block. If the lock number is greater than the number of lock entries, ORA-600 [4512] is reported followed by a stack trace, process state and block dump. This error possibly indicates a block corruption. |
Block | ||
| ORA-600 [4512] “Lock count mismatch” | ||||
| ORA-600[2662] | A data block SCN is ahead of the current SCN. The ORA-600 [2662] occurs when an SCN is compared to the dependent SCN stored in a UGA variable. If the SCN is less than the dependent SCN then we signal the ORA-600 [2662] internal error. |
Block | ||
| ORA-600 [2662] “Block SCN is ahead of Current SCN” | ||||
| ORA 600 [2662] DURING STARTUP | ||||
| ORA-600[4097] | We are accessing a rollback segment header to see if a transaction has been committed. However, the xid given is in the future of the transaction table. This could be due to a rollback segment corruption issue OR you might be hitting the following known problem. |
Undo | ||
| ORA-600 [4097] “Corruption” | ||||
| ORA-600[4000] | It means that Oracle has tried to find an undo segment number in the dictionary cache and failed. | Undo | ||
| ORA-600 [4000] “trying to get dba of undo segment header block from usn” | ||||
| ORA-600[6006] | Oracle is undoing an index leaf key operation. If the key is not found, ORA-00600 [6006] is logged. ORA-600[6006] is usually caused by a media corruption problem related to either a lost write to disk or a corruption on disk. |
Index | ||
| ORA-600 [6006] | ||||
| ORA-600[4552] | This assertion is raised because we are trying to unlock the rows in a block, but receive an incorrect block type. The second argument is the block type received. |
Block | ||
| ORA-600 [4555] | ||||
| ORA-600[6856] | Oracle is checking that the row slot we are about to free is not already on the free list. This internal error is raised when this check fails. |
Row | ||
| ORA-600 [6856] “Corrupt Block When Freeing a Row Slot | ||||
| ORA-600[13011] | During a delete operation we are deleting from a view via an instead-of trigger or an Index organized table and have exceeded a 5000 pass count when we raise this exception. | Row | ||
| ORA-600 [13011] “Problem occurred when trying to delete a row” | ||||
| ORA-600[13013] | During the execution of an UPDATE statement, after several attempts (Arg [a] passcount) we are unable to get a stable set of rows that conform to the WHERE clause. | Row | ||
| ORA-600 [13013] “Unable to get a Stable set of Records” | ||||
| How to resolve ORA-00600 [13013], [5001] | ||||
| ORA-600[13030] | ||||
| ORA-600 [13030] | ||||
| ORA-600[25012] | We are trying to generate the absolute file number given a tablespace number and relative file number and cannot find a matching file number or the file number is zero. | afn/rdba/tsn | ||
| ORA-600 [25012] “Relative to Absolute File Number Conversion Error” | ||||
| ORA-600[25026] | Looking up/checking a tablespace invalid tablespace ID and/or rdba found |
afn/rdba/tsn | ||
| ORA-600 [25026] | ||||
| ORA-600[25027] | Invalid tsn and/or rfn found | afn/rdba/tsn | ||
| ORA-600 [25027] | ||||
| ORA-600[kcbz_check_objd_typ] | An object block buffer in memory is checked and is found to have the wrong object id. This is most likely due to corruption. | Buffer Cache | ||
| ORA-600 [kcbz_check_objd_typ_3] | ||||
| ORA-600 [kcbz_check_objd_typ] | ||||
| ORA-600[kddummy_blkchk] ORA-600[kdblkcheckerror] | ORA-600[kddummy_blkchk] is for 10.1/10.2 and ORA-600[kdblkcheckerror] for 11 onwards. | Block | ||
| ORA-600 [kddummy_blkchk] | ||||
| How to Resolve ORA-00600[kddummy_blkchk] | ||||
| ORA-600 [kdblkcheckerror] | ||||
|
||||
|
||||
| ORA-600[ktadrprc-1] | Dictionary | |||
| ORA-600 [ktadrprc-1] | ||||
| ORA-600[ktsircinfo_num1] | This exception occurs when there are problems obtaining the row cache information correctly from sys.seg$. In most cases there is no information in sys.seg$. | Dictionary | ||
| ORA-600 [ktsircinfo_num1] | ||||
| ORA-600[qertbfetchbyrowid] | Row | |||
| ORA-600 [qertbfetchbyrowid] | ||||
| ORA-600[ktbdchk1-bad dscn] | This exception is raised when we are performing a sanity check on the dependent SCN and fail. The dependent scn is greater than the current scn. |
Dictionary | ||
| ORA-600 [ktbdchk1: bad dscn] |