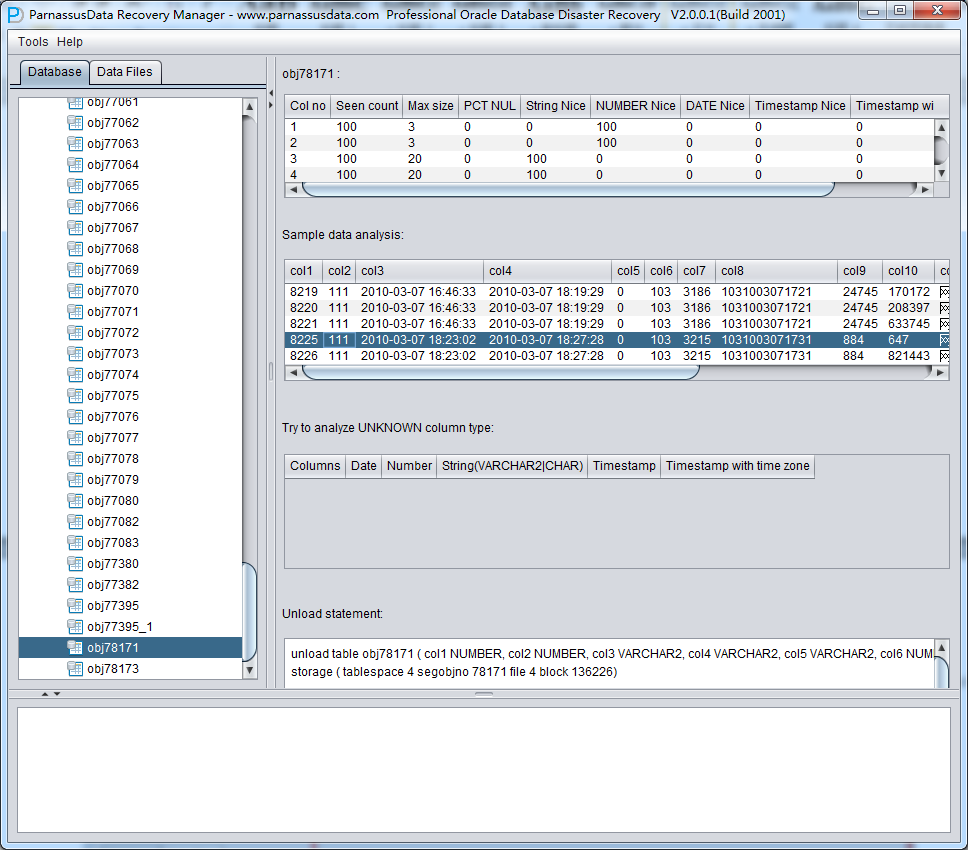
この文はOracleに壊れたブロックに対して、どうやって対応できるかを検討する文である。このあと、主な対応法が紹介するので、完全に読みきった前に、勝手に手を打たないでください。
ファイル履歴レコード
この文に掲載したすべてのSQL文もSQL*Plusに適用する。あるいはSYSDBAとして。リンクする時に、server manager(
Orale7/8.0)にも適用する。(例えば“connect / as sysdba”或“connect internal”)
サマリー
この文はOracleに壊れたブロックに対して、どうやって対応できるかを検討する文である。このあと、主な対応法が紹介するので、完全に読みきった前に、勝手に手を打たないでください。
この文は壊れたメモリーブロック問題について、検討していない。
注意:もし起動するときに、ORA-600[17XXX]タイプエラが出たら、地方のサポートセンタに連絡してください。
Doc 106638.1-このファイルはお客様に見せられないが、経験豊かな技術員がその中の一部なステップを提供してもいい。
この文で、いろんなタイプなミスを紹介した、ほかのいろんなところにもこの文を使える。大事なのは以下壊れたブロックについての情報を知るべきだと思う:
壊れたブロックを含むファイルの番号(file number)
この文で&.AFNと言う。
壊れたブロックを含む名
この文で&.FILENAMEと言う。
(ファイル番号を知ったが、ファイルなを知らない場合に、V$DATAFILEでファイル名を獲得する:
SELECT name FROM v$tempfile
WHERE file#=(&AFN – &DB_FILES_value);
)
ファイル番号がOracle8iのV$DATAFILEに映していない、&AFNがDB_FILESバラメタ値に超えた場合に、そのファイルが一時的なファイルかもしれない。この場合に以下の問合せでファイル名を見つけ出せる:
SELECT name FROM v$tempfile
WHERE file#=(&AFN – &DB_FILES_value);
)
ファイルの中のブロック番号
この文で&.BLと言う。
影響を受けたブロックのテーブルスペース番号と名を含んで、この文で“&TSN”と“&TABLESPACE_NAMEと言う。
これについての情報を知らない場合に、以下の問合せで見つけ出してください:
SELECT ts# “TSN” FROM v$datafile WHERE file#=&AFN;
SELECT tablespace_name FROM dba_data_files WHERE file_id=&AFN;
テーブルスペースの壊れたブロックのサイズ
この文で“&TS_BLOCK_SIZE”と言う
Oracle9i+に対して、以下の問合せで該当するブロックサイズを確かめてください。:
SELECT block_size FROM dba_tablespaces WHERE tablespace_name =
(SELECT tablespace_name FROM dba_data_files WHERE file_id=&AFN);
Oracle7・8.0及び8.1:
データベースにすべてのテーブルスペースが使っている同じなブロックサイズ。これらのバーションに対して、コマンド”SHOW PARAMETER DB_BLOCK_SIZE”で返した数値は“ &TS_BLOCK_SIZE”とする
例えば、ORA-1578エラ:
ORA-01578: ORACLE data block corrupted (file # 7, block # 12698)
ORA-01110: data file 22: ‘/oracle1/oradata/V816/oradata/V816/users01.dbf’
では:
&AFN は”22″ (エラORA-1110から部分的に獲得する)
&RFN は “7” (エラORA-1578の”file #”から部分的に獲得する)
&BL は “12698” (エラORA-1578の”block #”から部分的に獲得する)
&FILENAME 为 ‘/oracle1/oradata/V816/oradata/V816/users01.dbf’ &TSN 及びほかの情報は、前述したSQL文から獲得する
そのほかのエラにたいしては(ORA-600、ORA-1498など)Oracle supportあるいは関連するエラを含む文から獲得してください。
一部なエラに対して、例えば(ORA-1410“invalid ROWID、ORA-12899“value too large for columnなど)、壊れたファイル/ブロックについての詳しい情報を得ていないため、Document 869305.1 を使ってください。
壊れたブロックの対応策:
ブロックが壊れた原因はさまざま:
- ハードウェアが壊れた
- Osトラブル
- Oracleトラブル
- “UNRECOVERABLE”あるいは“NOLOGGING”操作を実行したデータベースをリカバリする(この場合にORA-1578エラになるかもしれない、以下の通り)
Oracleエラが発生したタイミングは最初に起きたミスのタイミングと比べて、大分遅くなるかもしれない。
壊れたブロックが現れた時に、すぐその場で根本的な原因を解き明かす訳にはいかない。それに多くの場合に、一番大事なのはデータベースを再起動して運用させることである。よって、この文は壊れたブロックトラブルを解決するステップを紹介する。詳しい内容は以下の通り:
(1)トラブルが起きたブロックのエクステントを確認する。これらのトラブルは一時的なものかあるいは持続的なものかを確かめてください。
エクステントが予想外に大きく拡張した場合やトラブルが不安定な場合に、大事なのは原因を判明する(ハードウェアをテストするなど)。これはとっても大切なことである。ハードウェアがトラブルに落ちた場合に、システムをリカバリするのは何の意味もないから。
(2)問題を起こすようなハードウェアを変更する
(3)データベース目標が影響を受けたことを確かめる。
(4)最適なデータベースリカバリオプションを選択する。
以上のステップに対して、証拠を収集してやるべきことを詳しく記録する。
NOLOGGINGあるいはUNRECOVERABLE操作でブロックを壊した。
もし誰かがNOLOGGINGあるいはUNRECOVERABLE操作を実行したまたその目標を含んだファイルをリカバリしたとしたら、 NOLOGGING操作に影響を受けたデータブロックは壊れたブロックに標識され、このブロックをアクセスするときにORA-1578エラが出てくる。Oracle8iで、このようなエラも出てくる:ORA-26040 エラ“ORA-26040: Data block was loaded using the NOLOGGING option (データブロックがNOLOGGINGオプションでロードする)。この時に、原因は一目瞭然である。その前のバーションでそのエラ情報を追加していないので、もし壊れたブロックは実行したNOLOGGING操作のデータファイルをリカバリしたから現れたとしたら、この文で第三章の内容を利用してください。だが以下の問題を注意してください:
- リカバリ操作がNOLOGGING操作の影響を受けたデータをリカバリできない。
- ブロック内部的なデータを救えない。
- 壊れたブロック問題のエクステントを確かめる:
ブロックが壊れた場合に、エラ情報を完全に記す必要がある。そして、関連したすべての問題を解き明かすために、そのインスタンスのアラームログとファイルを確認してください。まず、これらのステップは大事なので、壊れたのは一つブロックか、UNRECOVERABLE操作で起こしたエラか、あるいはもっとひどい問題なのかを確かめられる。
DBVERIFYで影響を受けたファイルをスキャンするという方法も悪くないが、これでほかのブロックが壊れていたか否かを確かめて、エクステントを確認できる。DBVERIFYの詳しい情報はDocument 35512.1を参考してください。
壊れたファイル/ブロックリストが作成したら、次のようなステップでどんな処置をとるべきかを確認できる。
証拠
完全なレコード及びトラブルが起きたアプリケーションの詳しい情報。
アラームログが初めて(FIRST)の警告が出すタイミングから、トラブルになるまで数時間の内容
アラームログのすべてのトランクファイル
最近レコードが直面したあらゆるosトラブル
レコードが特別な機能を使用しているか否か、例えば:
今のバックアップ位置を覚えてください(日付き、タイプなど)
データベースは今ARCHIVELOGモードにあるか否か例えば:SQL*Plus(或 Server Manager)中运行“ARCHIVE LOG LIST”
(2)壊れそうなハードウェアを変更してください
一般的に、ブロックが壊れたのはハードウェアがトラブルに落ちたからである。壊れそうなハードウェアを見つけたら、すぐに修復してください。また、リカバリする前に、独立したディスクシステムには、リカバリするためのスペースを確保してください。
以下のステップで、データファイルを移動できる:
- 移動したいファイルがアウトラインの状態を確保してください。あるいはデータベースインスタンスがmount状態を確保してください。
- このデータファイルを物理的に新しい位置にリカバリ(あるいはコピ)してください。
- このファイルの新しい位置をOracleに知らせてください。
例えば:ALTER DATABASE RENAME FILE ‘/oldlocation/myfile.dbf’
TO ‘/newlocation/myfile.dbf’;
(一時的なファイルを再命名できない。一時的なファイルを削除した後で新たな位置に改めて作成してください)
4.関連するデータファイル/テーブルスペースをオンラインしてください(データベースを起動した状態で)。
重要情報:
いくつのエラが存在している(NOLOGGING操作によるものじゃない)。
影響を受けたファイルがあるOSインタフェースにエラになる。
エラは一時的で不安定なものの場合。
では、根本的なトラブルを解決しないかぎりあるいはほかのディスクスペースを用意しないかぎり、どんな操作を実行しようと、何の意味もない。
ハードウェアアフタサービスに連絡して、全面的にシステムをテストしてください。そしてOracle supportにエラについてのすべての詳しい情報を知らせてください。
ハードウェアテストが失敗した場合に、ハードウェア自身には問題が起こったと示している。けどハードウェアテストが成功したとはハードウェアがトラブルに落ちていないと言えない。ハードウェアテスト成功したが、トラブルに落ちたこともよくある。
もし、特別なIOオプションを使用した場合に、(direct IO、async IOのようなオプション)、これらのオプションがまた新たなトラブルにならないように、それを停止してください。
(3)どんなものが影響を受けるでしょうか
リカバリ策を作成する前に、どんなものが影響を受けたことを確かめたほうがいい。壊れたブロックは再作成したものでよくある。例えば、5行だけのテーブルにあるブロックがこわれた場合に、リカバリするより、削除して再作成するのはずっと速い。
壊れた各ブロックに対して、以下の情報を収集してください。これを実行するステップは以下の通り:
针对每次坏块需记录的信息 |
||||||||
绝对文件 |
相关文件 |
块编号 |
段 |
|||||
初始错误 |
号 |
号 |
表空间 |
段类型 |
所有者.名 |
相关对象 |
恢复选项 |
|
&AFN |
&RFN |
&BL |
称 |
|||||
最初から報告してきたエラ、例えば:ORA-1578/ORA-1110、ORA-600及びすべてのバラメタ
絶対ファイル番号、関連するファイル番号及びブロック番号
ファイル番号とブロック番号はエラで現れる。あるいはOracle supportから提供する。
Oracle8/8i/9i/10で、一般的に絶対ファイル番号と関連するファイル番号が同じようになる。もし異なった場合に(特にOracle7から移した場合)、ぜひ正確な&AFNと&RFN番号を獲得してください。さもなければ、リカバリしたのは誤った目標という状況になるかもしれない!
ORA-1578は関連するファイル番号を報告する。絶対ファイル番号は後のORA-1110に映す。ORA-600に対して、絶対ファイル番号を知らせる。
以下の問合せでデータベースのデータファイルの絶対ファイル番号と関連するファイル番号を知らせる。
SELECT tablespace_name, file_id “AFN”, relative_fno “RFN” FROM dba_data_files;
Oracle8i/9i/10で:
Oracle8についての説明以外、、Oracle8iから一時的なファイルを持っているから、以下の問合せはデータベースにいる一時的なファイルの絶対ファイル番号、関連するファイル番号を映す:
SELECT tablespace_name, file_id+value “AFN”, relative_fno “RFN” FROM dba_temp_files, v$parameter
WHERE name=’db_files’;
Oracle7で、絶対ファイル番号と関連するファイル番号が同じようになる。
セグメントタイプ、所有者及び関連ファイル番号
壊れたブロックの絶対ファイル番号&AFNとブロック番号&Bが示された場合に、以下の問合せは目標のセグメントタイプ、所有者及び名前を示す。データベースが起動した後でこの問合せが使える:
SELECT tablespace_name, segment_type, owner, segment_name FROM dba_extents
WHERE file_id = &AFN
and &BL between block_id AND block_id + blocks – 1
;
壊れたブロックが一時的なファイルにあるとしたら、前の問合せが何のデータも返さない。
一時的なファイルに対して、セグメントタイプはTEMPORARY。
もし問合せが行を返さないと、壊れたブロックはロカールマネジテーブルスペース(Locally Managed Tablespace, LMT)のセグメントヘッダにあるかもしれない。この場合に、問合せはアラームログで壊れたブロックメッセージが作成し、問合せも失敗しない、この場合に、以下の問合せを使ってください:
SELECT owner, segment_name, segment_type, partition_name FROM dba_segments
WHERE header_file = &AFN and header_block = &BL
;
セグメントタイプで分類された関連する目標と可能なリカバリオプション:
関連する目標と使用可能なオプションはSEGMENT_TYPEに頼っている。よく見られるセグメントタイプ、問合せ及び使えるリカバリオプションは以下の通り:
CACHE
もしセグメントタイプはCACHEであれば、再び正確なSQL文とバラメタを入力したことを確かめてください。
また同じ結果が得たとしたら、Oracle supportに連絡して、自分の知る限りの情報を知らせてください。
オプション:
データベースをリカバリする必要があるかもしれない
CLUSTER
セグメントタイプはCLUSTERの場合に、どんなテーブルを含めているかを確かめる必要がある。
例えば:
SELECT owner, table_name FROM dba_tables
WHERE owner=’&OWNER‘
AND cluster_name=’&SEGMENT_NAME‘
;
オプション:
所有者はSYSの場合、Oracle supportに連絡して、すべての詳しい情報を知らせてください。
データベースをリカバリする必要があるかもしれない。
非データディクショナリーCLUSTERに対して、可能なオプションはリカバリを含んている。
あるいはCLUSTERにあるすべてのデータをリカバリする。
そしてCLUSTERとすべてのテーブルを再作成する。
CLUSTERにはいくつかのテーブルを含むかもしれないので、やる前に、CLUSTERにある各テーブルの情報を収集してください。
INDEX PARTITION
もしセグメントタイプはINDEX PARTITIONの場合に、名前と所有者を記録して、どんなPARTITIONが影響を受けるかを確かめてください:
SELECT partition_name FROM dba_extents WHERE file_id = &AFN
AND &BL BETWEEN block_id AND block_id + blocks – 1
;
そしてINDEXセグメントのステップで、以下の操作を実行してください。
オプション:
以下の文を使って、INDEX PARTITIONを再作成できる:
ALTER INDEX xxx REBUILD PARTITION ppp;
INDEX
もしセグメントタイプはINDEX 、そして所有者はSYS の場合にOracle supportに連絡して、すべての詳しい情報を知らせてください。
非データディクショナリーINDEX あるいはINDEX PARTITIONに対して、インディクスがどこのテーブルにあるかを確かめてください。
例えば:
SELECT table_owner, table_name FROM dba_indexes
WHERE owner=’&OWNER‘
AND index_name=’&SEGMENT_NAME‘
;
Eg: SELECT owner, constraint_name, constraint_type, table_name FROM dba_constraints
WHERE owner=’&TABLE_OWNER‘
AND constraint_name=’&INDEX_NAME‘
;
CONSTRAINT_TYPEの可能値は以下のようなものを含んでいる:
P インディクスが主キー制約を支持する
U インディクスが唯一制約を支持する
もしインディクスが主キー制約を支持すれば、主キーが外部キー制約に利用されたかを確認してください。
例えば:
SELECT owner, constraint_name, constraint_type, table_name FROM dba_constraints
WHERE r_owner=’&TABLE_OWNER‘
AND r_constraint_name=’&INDEX_NAME‘
;
オプション:
所有者はSYSの場合、Oracle supportに連絡して、すべての詳しい情報を知らせてください。
データベースをリカバリする必要があるかもしれない。
非ディクショナリーインディクスに対して、可能なオプションはリカバリ
あるいはインディクスを再作成する
ROLLBACK
もしセグメントタイプはROLLBACKの場合に、Oracle supportに連絡してください。ROLLBACKセグメントにブロックが壊れたとしたら、特別な処置が必要としている。
オプション
データベースをリカバリする必要があるかも知れない。
TYPE2 UNDO
TYPE2 UNDOはシステム管理のUNDOセグメントで、これはROLLBACKセグメントの特別形式で、これらのセグメントにある壊れたブロックは特別な処置が必要としている。
オプション:
データベースをリカバリする必要がある
TABLE PARTITION
セグメントタイプはTABLE PARTITIONの場合に、名前と所有者を記して、どれのPARTITIONが影響を受けたかを確かめてください:
SELECT partition_name FROM dba_extents WHERE file_id = &AFN
AND &BL BETWEEN block_id AND block_id + blocks – 1
;
そしてテーブルセグメントのステップで以下の操作を実行する。
オプション:
もしすべての壊れたブロックが同じPARTITIONに属している場合に、空っぽなテーブルで壊れたブロックを含むPARTITIONを代われる。これでアプリケーションが実行し続ける(),そして空っぽなテーブルから損害を受けていないデータを抽出できる。
ほかのオプションについて、次のTABLEオプションを参考してください。
TABLE
所有者はSYSの場合、Oracle supportに連絡して、すべての詳しい情報を知らせてください。
データベースをリカバリする必要があるかもしれない。
非ディクショナリーTABLEあるいはTABLE PARTITIONについて、テーブルにどんなインディクスがあるかを確認してください。
例えば:
SELECT owner, index_name, index_type FROM dba_indexes
WHERE table_owner=’&OWNER‘
AND table_name=’&SEGMENT_NAME‘
;
そしてテーブルに主キーが存在しているか否かを確認してください:
Eg: SELECT owner, constraint_name, constraint_type, table_name FROM dba_constraints
WHERE owner=’&OWNER‘
AND table_name=’&SEGMENT_NAME‘ AND constraint_type=’P’
;
主なキーが存在している場合に:
例えば:
SELECT owner, constraint_name, constraint_type, table_name
FROM dba_constraints WHERE r_owner=’&OWNER‘
AND r_constraint_name=’&CONSTRAINT_NAME‘
;
オプション:
所有者はSYSの場合、Oracle supportに連絡して、すべての詳しい情報を知らせてください。
データベースをリカバリする必要があるかもしれない。
非ディクショナリーテーブルに対して、可能なオプションは:
リカバリ
あるいは テーブルのデータを救う。そしてテーブルを再作成する。
あるいは 壊れたブロックを無視する。(例えば: で問題が起きたブロックをスキップする。
インディクス組織テーブル(IOT)
IOTテーブルで壊れたブロックはテーブルあるいはPARTITIONテーブルの形式で処理する。
唯一の例外はPKが壊れた場合である。
IOTテーブルのPKはテーブル自身であるから、削除も再作成もできない。
オプション:
所有者はSYSの場合、Oracle supportに連絡して、すべての詳しい情報を知らせてください。
データベースをリカバリする必要があるかもしれない。
非ディクショナリーテーブルに対して、可能なオプションは:
リカバリ
あるいは テーブルのデータを救う。そしてテーブルを再作成する。
あるいは 壊れたブロックを無視する。
LOBINDEX
LOBはどのテーブルに属している:
SELECT table_name, column_name FROM dba_lobs
WHERE owner=’&OWNER‘
AND index_name=’&SEGMENT_NAME‘;
所有者はSYSの場合、Oracle supportに連絡して、すべての詳しい情報を知らせてください。
LOBインディクスを再作成できないから、そのトラブルを影響を受けたテーブルでLOB列の壊れたブロックとして対応する。
TABLE部分中のSQL文で壊れた LOBインディクスのテーブルのインディクスと限り情報を含んでいて、またここに帰る。
オプション:
所有者はSYSの場合、Oracle supportに連絡して、すべての詳しい情報を知らせてください。
データベースをリカバリする必要があるかもしれない。
非ディクショナリーテーブルに対して、可能なオプションは:
リカバリ
あるいは テーブルのデータを救う。そしてテーブルを再作成する。
一般的には、壊れたブロックを無視できない。
LOBSEGMENT
LOBはどこのテーブルに属しているかを確かめる:
例えば:
SELECT table_name, column_name FROM dba_lobs
WHERE owner=’&OWNER‘
AND segment_name=’&SEGMENT_NAME‘;
所有者はSYSの場合、Oracle supportに連絡して、すべての詳しい情報を知らせてください。
データベースをリカバリする必要があるかもしれない。
非ディクショナリーテーブルに対して、
TABLE部分中のSQL文で壊れたLOBインディクスのテーブルのインディクスを含む情報を獲得して、またここに返って、影響を受けた行の詳しい情報を検索する。
報告で壊れたLOBデータがどこの行に属していることをいわないから、壊れたLOBの具体的行を検索するのは難しいかもしれない。
一般的に、トラブルが起きたアプリケーションログ、SQL_TRACE及びセッションの10046トランクファイルを参考して、あるいは事件1578 trace name errorstack level 3をセットして、今のSQL/バイナリ/行を標識するには力になれるかどうかを検討してください。
例えば:
ALTER SYSTEM SET EVENTS ‘1578 trace name errorstack level 3’;
そして、アプリケーションがこのトラブルを発生させて、トランクファイルを追及する。
もし何の手がかりもない場合に、PLSQLブロックを作成してください。一行ずつ問題があるテーブルをスキャンして、LOB列データを抽出する。スキャンはトラブルが起きたまでずっと続く。この方法は時間をかかるが、最終的には壊れた部分を見つけ出せる。
例えば:
set serverout on
exec dbms_output.enable(100000); declare
error_1578 exception;
pragma exception_init(error_1578,-1578); n number;
cnt number:=0; badcnt number:=0; begin
for cursor_lob in
(select rowid r, &LOB_COLUMN_NAME L from &OWNER..&TABLE_NAME) loop
begin n:=dbms_lob.instr(cursor_lob.L,hextoraw(‘AA25889911’),1,999999) ;
exception
when error_1578 then
dbms_output.put_line(‘Got ORA-1578 reading LOB at ‘||cursor_lob.R);
badcnt:=badcnt+1; end;
cnt:=cnt+1; end loop;
dbms_output.put_line(‘Scanned ‘||cnt||’ rows – saw ‘||badcnt||’ errors’);
end;
/
壊れたLOBブロックに古いバーションが示される(一貫性を守るために)、それにブロックは再利用されていない。この場合に、すべてのテーブルの行もアクセスできるが、リサイクルされて再利用される場合に、LOB列をインサート/アップロードできなくなる。
オプション:
所有者はSYSの場合、Oracle supportに連絡して、すべての詳しい情報を知らせてください。
データベースをリカバリする必要があるかもしれない。
非ディクショナリーテーブルに対して、可能なオプションは:
リカバリ
あるいは テーブルのデータを救う。そしてテーブルを再作成する。
あるいは 壊れたブロックを無視する。
TEMPORARY
もしセグメントタイプはTEMPORARYとしたら、壊れたブロックが永久的な目標に影響を及ばない。トラブルが起きたテーブルスペースはTEMPORARYテーブルスペースに使っているか否かを確認してください。
SELECT count(*) FROM dba_users
WHERE temporary_tablespace=’&TABLESPACE_NAME‘
;
オプション:
の場合に、新たな一時テーブルスペースを作成できて、すべてのユーザーをこのテーブルスペースに切り替えて、そしてトラブルが起きたテーブルスペースを削除する。
もし、一時テーブルスペースではない場合に、そのブロックは再び読み取らない。そして次に使う時に再びフォーマッティングされる。根本的な問題を解決されていない場合に、同じようなトラブルが起こらないはずである。
一般的にはリカバリ必要としていないが、ディスクが問題になったかもしれないので、それにテーブルスペースに使えるデータをまだ残っているから、データベースに影響を受けたファイルに対してリカバリしたほうがいい。
ほかのセグメントタイプ
もし返ってきたセグメントタイプは以上のどんなタイプにも属していない場合に、Oracle supportに連絡して、今まで知っているすべての詳しい情報を提供してください。
行が返っていない
壊れたブロックを含むエクステントがなければ、問合せで使っているバラメタをもう一度チェックしてください。ファイル番号もブロック番号も正確で、DBA_EXTENTSでどれにも属していない場合に、以下の操作を実行してください:
再び関連するファイルをチェックして、一時的ファイルか否かを確認してください。一時ファイルのファイル番号はデータベースバラメタDB_FILESによるもので、このバラメタにどんな変更を加えようと、報告の絶対ファイル番号を変える。
DBA_EXTENTSはローカル管理テーブルスペースでローカルスペース管理するためのブロックを含んでいない。
もしデータベースが問合せ文を運用するタイミングとトラブルが起きたタイミングと違っているとしたら、トラブルが」起きた目標が削除されたかもしれないので、DBA_EXTENTSに対する問合せが何の行も映さない。
もし調査しているのトラブルはDBVERRFYによって報告されるとしたら、DBVは何に属しているかを問わずに、すべてのブロックを検索するから、壊れたブロックがデータファイルにあるが、誰にも使われていない。
オプション:
使われていないOracleブロックのトラブルが無視できるが、いざそのブロックを使いたくなった場合にOracleは新たなブロクインメージを作成する(フォーマッティング)から、このブロックでどんなトラブルも読み取らない。
もしそのブロックがスペース管理ブロックと疑わっているなら、 パッケージを使ってください:
exec DBMS_SPACE_ADMIN.TABLESPACE_VERIFY(‘&TABLESPACE_NAME‘);
以上のコマンドは不整合なところをトランクファイルに書き込むが、致命的なトラブルが起こったら、以下のようなトラブルが返される。
ORA-03216: Tablespace/Segment Verification cannot proceed
ビットマップスペース管理ブロックで起こるトラブルは以下のコマンドで修復できる。
exec DBMS_SPACE_ADMIN.TABLESPACE_REBUILD_BITMAPS(‘&TABLESPACE_NAME‘);
証拠:
各壊れたブロックに対して、その原因を調べたいなら、以下のような物理証拠を収集するのもいい策とおもう:
壊れたブロック及びブロックhexをダンプする
UNIXで
exec DBMS_SPACE_ADMIN.TABLESPACE_REBUILD_BITMAPS(‘&TABLESPACE_NAME‘);
例えば:
BL=1224:
dd if=ts11.dbf bs=4k skip=1223 count=3 of=1223_1225.dd
VMS で:
DUMP/BLOCKS=(start:XXXX,end:YYYY)/out=dump.out &FILENAME
XXXXはオペレーションシステムブロック番号(512バイトブロックで)。この数値を計算したいとすれば、報告のブロック番号で“&TS_BLOCK_SIZE/512”に加算してください。
ARCHIVELOGモードで、コピにトラブルが起きた時間前後のアクチブロゴのセキュリティコピはトラブルを報告する数時間前のコピを格納してください。前のデータファイルインメージとredoレコードは原因を探し出せる。(一般的にDBVはトラブルがファイルバックアップコピにあるか否かを確認するときに使われる)。理想的な状況はトラブルが起こった前のデータファイルバックアップインメージを獲得する、そしてそのタイミングから初めてのエラ報告が返った時点までのすべてのredoレコード。
トラブルブロックのOracleダンプを獲得する
ALTER SYSTEM DUMP DATAFILE ‘&FILENAME’ BLOCK &BL
;
4)リカバリオプションを選ぶ
今、理想的なリカバリオプションは影響された目標に左右される。前の(3)部分で、影響を受けた目標が使用可能なオプションを紹介したが、選択する実際のリカバリ方法は多数の方法を含むことができる。
リカバリ操作が必要としているかいなか?
トラブルはTEMPORARYテーブルスペースに起きたやどんなデータベース目標のブロックにも位置していない場合には何の操作もいらない。トラブルが起きたテーブルスペースをほかのストレージマシンに格納すればいい。「アラーム」を参考してください。
完全にリカバリできるか?
完全にリカバリしたいとすれば、以下の条件を満たさればならない:
-データベースはARCHIVELOGモードにある(“ARCHIVE LOG LIST”コマンドはArchivelogモードを映す
-影響されたファイルの完全なバックアップを持っている。けど、ある場合に、壊れたブロックも既に存在していたが、長い間に見つからない。もし、最新のバックアップにはまだ壊れたブロックを含んでいれば、保存ログが必要になる。もっと早いバックアップを利用できる。
(一般的にはDBV START= / END=オプションでバックアップファイルのリカバリコピのある特定したブロックが壊れていたか否かを確認する)
バックアップ時間から今まですべてのアクチブログも使用可能
すべてのオンラインログが使用可能で、無傷である。
トラブルはNOLOGGINGを実行したリカバリよるものではない
以上の条件を満たせば、最優先なのは完全にリカバリする
以下のようなことを注意してください
(a)トランザクションロールバックが目標にはブロックが壊れたことを気づいたとしたら、rollbackセグメント自身ではなく、undo操作が諦められたかもしれない。この場合に、リカバリ完成したあと、インディクス/データの整合性をチェックして再構造する。
(b)もしリカバリしたいファイルは前回バックアップしたあとのNOLOGGING操作データの場合にデータファイルあるいはデータベースリカバリを運用している途中で、これらのブロックは壊れたブロックと標識される。ある場合に、これは状況を一層ひどくさせる。
もしデータベースリカバリを実行した後も壊れたブロックがまだ残っているとすれば、これはすべてのバックアップに壊れたブロックを含んでいることを意味する。この場合に、ほかのリカバリオプションを選んでください。
「(4A)完全にリカバリ」を参考して、完全リカバリのステップを理解してください。目標から何のデータを抽出する必要がなくなった場合に、目標を削除して、再作成できるでしょうか。
PARTITION …
テーブルパーティションに対して、影響を受けたパーティションだけを削除すればいい。例えば:ALTER TABLE …DROP PARTITION …
壊れたブロックがセグメントヘッダに影響を与えたあるいはパーティションヘッダがアウトラインの状態で、DROP PARTITIONが失敗するかもしれない。対応策はまずそれを同じ定義のテーブルに変更して、削除する。
例えば:ALTER TABLE ..EXCHANGE PARTITION ..WITH TABLE ..;
一番よく見られる状況は再構造できる目標はインディクスの場合。詳しい情報は「(4B)インディクスを再構造する」を参考してください。
どんなセグメントに対しても、壊れたブロックの絶対ファイル番号とブロック番号を持っていれば、以下の方法を試してください:
set long 64000
select dbms_metadata.get_ddl(segment_type, segment_name, owner) FROM dba_extents
WHERE file_id=&AFN
AND BL BETWEEN block_id AND block_id + blocks -1;
データを再作成する前にデータを救う必要があるか?
もしトラブルは定期的にアップロードする肝心なアプリテーブルにあるとしたら、できるだけ多くのデータをリカバリしてください、そしてそのテーブルを再作成する。
詳しい情報は(4C)テーブルデータに対する緊急処置
目前の壊れたブロックを無視できるか?
在某些情况下,最直接的选项可能就是忽略坏块,并阻止应用程序对它进行访问。
ある場合に、一番やりやすいオプションは壊れたブロックを無視して、アプリがそれをアクセスすることも阻止する。
詳しい情報は「(4D)壊れたブロックを無視する」に参考してください。
最后的选项
最後の選択肢
以下のような選択が実行できるか?「データベースあるいはテーブルスペースをより早い時点へリカバリする(タイミング修復)」、「壊れたブロック前にcold backupをリカバリする」および「既存するファイルをエクステントする」についての詳しい情報は(4E)最後の選択肢に参考してください。
(4A)完全にリカバリする
データベースはARCHIVELOGモードで、そして影響を受けていないファイルのバックアップを持っていれば、リカバリするのが一番いい方法である。必ずトラブルを解決できるとは限らないが、大多数の壊れたブロックによるトラブルを解決できる。再び同じような問題が起こったら、また別の方法に選んでください。
もし運用しているのはOracle9i(あるいはもっと高いバーション)であれば、RMAN BLOCKRECOVERコマンドでブロックレベルのリカバリを実行できる。
もし運用しているのはより古いバーションであれば、データファイルリカバリ(ほかのデータベース部分を持続的に使用できる)あるいはデータベースリカバリ(データベースを閉めてください)。
もし、使っているのはOracle 11g(あるいはもっと高いバーション)であれば、Data Recovery Advisor(データリカバリガイド)を使ってください。
ブロックレベルリカバリ
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Oracle9iから、RMANが一つのブロックをリカバリできる。同時にデータベースのほかの部分もアクセスできる(データファイルのほかのブロックも含む)。ブロックレベルリカバリはせいぜいブロックを今のタイミングまでしかリカバリできない。
ば、必ずRMANでバックアップする必要があるとは限らない。例えば:実際の状況で、ファイル6のブロック30でORA-1578エラが起こったら、メディアトラブルでブロックを壊れたかもしれないので、もし完全なコールドバックアップがあれば、
“…/RESTORE/filename.dbf”。にリカバリしてください。
仮にすべてのアクチブログもあって(ディフォルト位置にある)、RMANで以下のコマンドでリカバリできる:
rman nocatalog connect target
catalog datafilecopy ‘…/RESTORE/filename.dbf’; run {blockrecover datafile 6 block 30;}
この操作は登録したデータファイルバックアップインメージとアクチブログでブロックレベルのリカバリを実行する。トラブル があったブロックだけを現在の時点にリカバリする。
RMAN BLOCKRECOVERコマンドや制約について、関連するファイルに参考してください。
データファイルリカバリ
~~~~~~~~~~~~~~~~~~
データファイルリカバリは以下のステップを含んでいる。多数のファイルを持っていれば、各ファイルにこれらのステップを繰り返してください。後のデータベースリカバリを参考してください。データベースがOPEN あるいはMOUNTED状態で、これらのステップも全部利用できる。
影響を受けたデータファイルをアウトラインさせてください
例えば:ALTER DATABASE DATAFILE ‘name_of_file’ OFFLINE;
ファイルを安全な場所へコピする(バックアップが壊れることを防ぐため)
ファイルの最新なバックアップを安全ディスクへリカバリする。
DBVERIFYでリカバリしたファイルに壊れたブロックが残っているかをチェックする
DBVERIFYについての詳しい情報をDocument 35512.1に参考してください
仮にリカバリしたファイルは無傷とする。では、データファイルを再命名して、新たな位置に格納する(元の位置じゃなければ)
例えば:ALTER DATABASE RENAME FILE ‘old_name’ TO ‘new_name’;
データファイルをリカバリする 例えば:RECOVER DATAFILE ‘name_of_file’;
データファイルをオンラインさせる
例えば:ALTER DATABASE DATAFILE ‘name_of_file’ ONLINE;
データベースリカバリ
~~~~~~~~~~~~~~~~~
一般的にはデータベースリカバリが以下のステップを含んている:
データベースを閉じる(immediate あるいはabortを使う)
リカバリしたいファイルを安全な場所へコピ
バックアップファイルを無傷なディスクにリカバリする。コントロールファイルやオンラインREDOログファイルをリカバリしないでください。
DBVERIFYでリカバリしたファイルに壊れたブロックが残っているかをチェックする
DBVERIFYについての詳しい情報をDocument 35512.1に参考してください
データベースを起動して、MOUNT状態にしてください(startup mount)
どんな再定位が必要とするデータファイルにも再命名する
例えば:ALTER DATABASE RENAME FILE ‘old_name’ TO ‘new_name’;
必要とするすべてのファイルもオンラインの状態で保ってください
例えば:ALTER DATABASE DATAFILE ‘name_of_file’ ONLINE;
データベースをリカバリする 例えば:RECOVER DATABASE
データベースを起動する
例えば:ALTER DATABASE OPEN;
完全にリカバリした
~~~~~~~~~~~~~~~~~~~~~~~~~~
完全になリカバリを実行する前に、データベースをチェックしてください:
各トラブル目標にも“ANALYZE <table_name> VALIDATE STRUCTURE CASCADE”を実行する,テーブルとインディクスの間で、ミスマッチが存在しているかをチェックしてください。もしundo 操作を諦めることがあれば、そのコマンドはミスマッチと示す。この場合はインディクスを再構造してください。
アプリレベルでテーブルデータのロジック整合性をチェックしてください。
(4B)インディクスを再構造する
壊れた目標はユーザーインディクスの場合に、バックグラウンドテーブルが壊れていないとすれば、インディクスを削除して、再構造できる。もしバックグラウンドテーブルも壊れた場合に、インディクスを再構造する前に、まず壊れたブロックを解決してください。
もし収集してきた情報はインディクスに従属外部キー制約があると示されるとしたら、以下の操作を実行してください
ALTER TABLE <child_table> DISABLE CONSTRAINT <fk_constraint>;
各外部キーに対して
以下のコマンドで主キーを再構造する
ALTER TABLE <table> DISABLE CONSTRAINT <pk_constraint>; DROP INDEX <index_name>;
CREATE INDEX <index_name> .. with appropriate storage clause ALTER TABLE <table> ENABLE CONSTRAINT <pk_constraint>;
外部キー制約を起動する
ALTER TABLE <child_table> ENABLE CONSTRAINT <fk_constraint>;
インディクスパーティションに対して、以下のコマンドを実行してください:
ALTER INDEX …REBUILD PARTITION …;
注意:
(1)ALTER INDEX .. REBUILDコマンドで壊れた非パーティションインディクスを再構造しないようにしてください。
“ALTER TABLE … REBUILD ONLINE”和“ALTER INDEX … REBUILD PARTITION …”古いインディクスセグメントから新たなインディクスを構造しないから、使える。
(2)新たなインディクスにある列は既存するインディクスのサブセットであれば、Create INDEXは既存するインディクスのデータを使える。よって、二つのインディクスが壊れたとしたら、再構造する前に二つも削除してください。
インディクスを再構造する前に、正確な格納オプションを確保してください。
(4C)テーブルのデータを救う
TABLE 、CLUSTER 、 LOBSEGMENTが壊れたら、ブロックのデータもなくしたと理解してください。僅かなデータだけがHEXダンプ、あるいはインディクスの列からリカバリできる。
重要情報:
インディクスからブロックのデータをリカバリするかもしれないから、必要なデータを抽出したまで、既存するインディクスを削除しないでください。
壊れたブロックのテーブルからデータを抽出するのかいくつの方法がある。それらの同じなところはより多くのデータをリカバリすることである。一般的に、壊れたテーブルを再命名するのはいい方法である、これで正確の名で新しい目標を作成できる。
例えば:RENAME <emp> TO <emp_corrupt>;
壊れたテーブルからデータを抽出する方法
(1)Oracle 7.2から(Oracle 8.0、8.1 及び9iも含む)、テーブルに壊れたブロックをスキップできる。これは今まで一番やりやすい抽出法である、詳しい情報は以下のファイルに参考してください。
Document 33405.1 – Extracting data using DBMS_REPAIR.SKIP_CORRUPT_BLOCKS or Event 10231
もし壊れたブロックはIOT overflowセグメントにあるなら、同じ方法を使ってください。異なった場合にEvent 10233と全インディクススキャンを使ってください。
もしトラブルはORA-600 あるいはほかのORA-1578ではないトラブルであれば、DBMS_REPAIRでテーブルに壊れたテーブルをソフトブロックと標識できる。これで、そのブロックをアクセスするときに、ORA-1578エラになり、DBMS_REPAIR.SKIP_CORRUPT_BLOCKSが使えるようになった。
注意:“FIX_CORRUPT_BLOCKSプログラムに壊れたブロックと標識したブロックは、リカバリした後も壊れたブロックと標識する。
DBMS_REPAIRについて、この操作すべての詳しい情報は、関連するファイルに参考してください。ステップは以下の通り:
DBMS_REPAIR.CHECK_OBJECTでトラブルブロックを見つけだす。
そしてORA-1578と映す
必要であればDBMS_REPAIR.SKIP_CORRUPT_BLOCKSで壊れたブロックをスキップできる。
(2)Oracle 7.1から、ROWIDスキャンを選べる。けど、この機能のアルゴリズムが複雑で、ROWIDで壊れたブロックのデータをヒントする。
Document 61685.1 – Using ROWID Range Scans to extract data in Oracle8 and higher Document 34371.1 – Using ROWID Range Scans to extract data in Oracle7
(3)もし、主キーが存在すれば、このインディクスでテーブルデータを選べる。あるいはほかのインディクスで一部のデータを選べる。この方法はかなり時間をかかる。
(4)いろんなリカバリプログラムPLSQLスクリプトがテーブルのデータをリカバリできる。前述したものと比べて、これらの方法はセットや運用にはより時間をかかるが、ORA- 1578以外のいろんな壊れたブロックを処置するときによく効く。けど、これらの方法はすごく高い技術を要求しているから、一般的にお客様がこれについての文はあまり見られない。
以下のプログラムを実行するには、Pro*Cを使う必要がある。それにPro*Cについての知識をよく身につける必要がある:
Document 2077307.6 – SALVAGE.PC for Oracle7
以下のプログラムで、人工的に介入するが必要としている:
Document 2064553.4 – SALVAGE.SQL for Oracle7/8
壊れたLOBSEGMENTブロックを含んだテーブルからデータを抽出する方法
LOBセグメントにDBMS_REPAIRを使えない。
壊れたLOBブロックはどんなテーブルにも利用されていないであればCREATE TABLE as SELECT (CTAS)を使って、テーブルを作成する。あるいは元通りにエクステント/削除/インポートする。もし壊れたLOBブロックが利用されたら、トラブルが起きた行を含まないWHEREで選ぶあるいはエクスポートする。
アラーム:
トラブルが起きたLOB列値をNULLに更新できる。これでSELECT操作を実行するときにORA-1578エラを返せないが、壊れたブロックが再び利用される。LOB列をインサートするやアップデートするときに、壊れたブロックが再利用されると、またORA-1578エラになる。これは知っていた行に壊れたブロックが出たこともよりもっとまずい。だから、テーブルを再作成するときだけLOB列をNULLにセットする。
壊れたブロックからデータを抽出する
壊れたブロック自身が壊れたから、そのブロックから抽出したどんなデータも怪しいデータと見られる。
-TABLEのブロックに対して、Oracle Supportはブロック内容を解説できるアプリを利用できる
テーブルあるインディクスを使って、ブロックにあるROWIDを利用して、列データインディクスを抽出する。前述したROWIDでエクステントスキャンでこれについて紹介していた:
Oracle8/8iに対して,Document 61685.1を参考してください
Oracle7に対して、 Document 34371.1を参考してください
RedoフロでLogMinerを運用することによって、壊れたブロックに対してデータをロードするインサート/アップロード操作を見つけ出せる。ここで主なファクトはデータが実際にトラブルブロックに加わった時点である。例えば、行2は昨日でインサートしたが、行1が5年前にインサートしたかもしれない。
(4D)壊れたブロックを無視する
トラブルが起きたときに、このような操作もいけると思う:壊れたブロックを無視して、報告のトラブルを受け取る。あるいはアプリレベルで、下位行がアクセスされないように、トラブルが起きたブロックにアクセスすることを阻止すてください。
こうすれば、バルクデータアクセスやほかの任務に向いていないが、ブロックがアクセスされるとエラ報告を阻止するために、4C に検討したDBMS_REPAIRもいい策だとおもう。
ブロックを無視するのは老化しやすく、まもなく削除されるデータにはいい選択肢である。(例えば、日付きによって、パーティションされるテーブルで、古いパーティションがある時点に削除される)。
LOBセグメントで壊れたブロックを無視する
アプリレベルで、テーブルを再作成まで、壊れたLOB列を無視できる。
以上のアラームを出せないように、アプリケーションはテーブルにWHERE述語のビューで、パーティションのデータをアクセスする。
例えば:もしテーブルに MYTAB(a number primary key,b clob)は一行あるいは多数行で壊れたLOBデータに指す。
ALTER TABLE MYTAB ADD ( BAD VARCHAR2(1) );
CREATE VIEW MYVIEW AS SELECT a,b FROM MYTAB WHERE BAD is null;
どんな壊れた行にもBAD=’Y’とセットする
MYVIEWだけでMYTABをアクセスすれば、その行は永遠に隠されるので、アップロードもできない。トラブルが解決するまで隔離される。
このインスタンスにはデザインするときの解決策が、あるアプリケーションには似たようなメカニズムがあるかも知れないので、トラブル行を隠せる。
壊れたブロックに対するアラーム
ブロックを無視できるが、注意すべきことは壊れたブロックがDBVERIFY、RMANバックアップを運用するときに警告や/エラの形式で現れる。
すべての壊れたブロックを記録してください。特にRMANでスキップしたいどんなブロック(例えばMAX_CORRUPTとセットした)、それに壊れたブロックを排除する、
例えば:もし壊れたブロックは無視するブロックと処置され、アプリレベルで、トラブルの行をスキップする
RMANはバックアップするときに壊れたブロックと受け止めて、後のテーブル再作成するときにテーブルを再作成する。
もしRMANはアップロードして今のエラを報告していない場合に、RMANは後に出るブロックを無視する。
それ以外、後はテーブルセグメントのブロックを無視して、問合せで返した結果が一致していないかもしれない。
もし、ブロックを無視したが、DBMS_REPAIR.FIX_CORRUPT_BLOCKS標識を使っているであれば後のリカバリオプションに影響を与える。
(4E)最後の選択肢
もしstandby環境があればまずそれをチェックしてください。
トラブルがどんなタイプのブロックにいようと、ある選択肢が選べる。それはデータベースあるいはトラブルテーブルスペースをブロックが出る前のある時点に帰れる。だが難しいところはトラブルが出た時間を知らなから。
DBVERIFYはリカバリファイルに壊れたブロックがあるか否かをチェックできる。DBVERIFYについての詳しい情報はDocument 35512.1に参考してください。特に
START= / END= DBVオプションはリカバリしたバックアップインメージで手早くテストを実行できる。
この部分にはリカバリ操作の最終的なオプションをあげた。ここまで読んだ方は、必ず以下の通りの一つ状況が起こったでしょう。
-とても大切なデータファイルをなくしたが(あるいはデータファイルに壊れたブロックが現れた)、トラブルのないファイルバックアップもない。
– ARCHIVELOGモードじゃない。それにアクチブログもない
-完全にリカバリしたあとまた同じようなトラブルが繰り返す
最後の機会:
もしデータファイルすべてのコピもなくしたが、ファイル作成したからすべてのアクチブロゴがまだ残っていれば、リカバリできる。例えば:
ALTER DATABASE CREATE DATAFILE ‘….'[as ‘…’] ; RECOVER DATAFILE ‘….’
ALTER DATABASE DATAFILE ‘….’ONLINE;
もしこの状況に逢えたら、以下の操作を実行する前にこれらのステップでデータファイルをリカバリしてみてください。
ここまでたどり着いたら、それはほかの方法がないからである。この時にはインスタンスを閉じて、今のデータベースをバックアップしてください。(例えばバックアップに壊れたブロックがない場合)
使用可能なオプションは以下の通り:
より早いコールドバックアップにリカバリする
例えば:NOARCHIVELOGの場合:
コールドバックアップからコーピーデータベースを作り上げる。
トラブルテーブルを抽出する。あるいはトラブルテーブルスペースを伝送する。
時点に基づくリカバリはデータベースを一致した時点に戻れる。
完全なバックアップとアクチブログが必要としている
すべてのファイルをリカバリして、データベースごとに適当な時点に戻らせる必要がある。
データベースに時点に元づくリカバリを実行できて、トラブルテーブルスペースをトラブルデータベースに伝送する。あるいはトラブルテーブルに伝送する。
時点に基づくテーブルスペースリカバリ
-影響を受けたテーブルスペースだけに時点リカバリするとことができる。いろんなファイルもこの方法を紹介している、例えば、Document 223543.1。
ロジックからコピをエクスポートして、データベースを再作成する。
このオプションを使うにはデータベースを再作成する必要がある。
ほかのオプションと同じように、より完全なインメージを獲得するために、コピデータベースで再作成できる。
完全なバックアップが持っていれば、DB_BLOCK_CHECKING=TRUEでロールバックして、初めてのトラブルが起きた時点を見つけ出せる。リカバリオプションを調査するときに、トラブルデータベースを閉じる必要がない。例えば:システムテーブルスペースとトラブルスペースデータファイルを異なった位置やマシンにリカバリする。異なったインスタンスとして、どこまでの時点までロールバックできるかを確認できる。Oracle9iからテストリカバリオプションで、オプションを研究しながら、リカバリバックアップを用意せねばならない状況に抜け出せる。