原文链接: http://www.dbaleet.org/exadata_how_to_caculate_iops/
Thomas Zhang 同学曾经提到一个很有意思的话题:Exadata datasheet的IOPS是怎样计算的?这个问题我想很多Exadata用户都会有同样的困惑,客户隐含的意思就是主机和存储我打过的交道也不少,你这个数据在我看来应该是有水分的,厂商嘛,都喜欢吹吹牛。
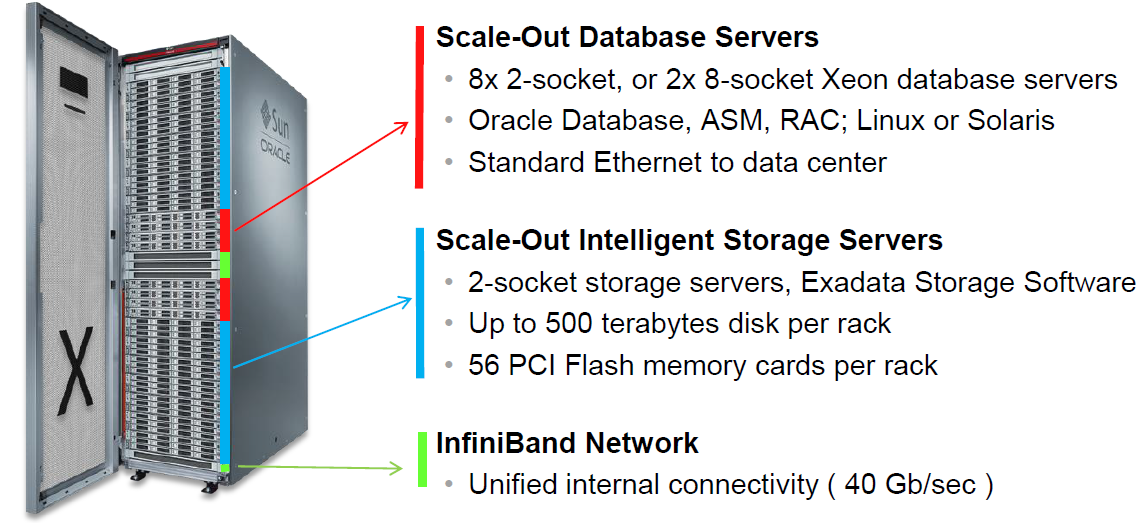
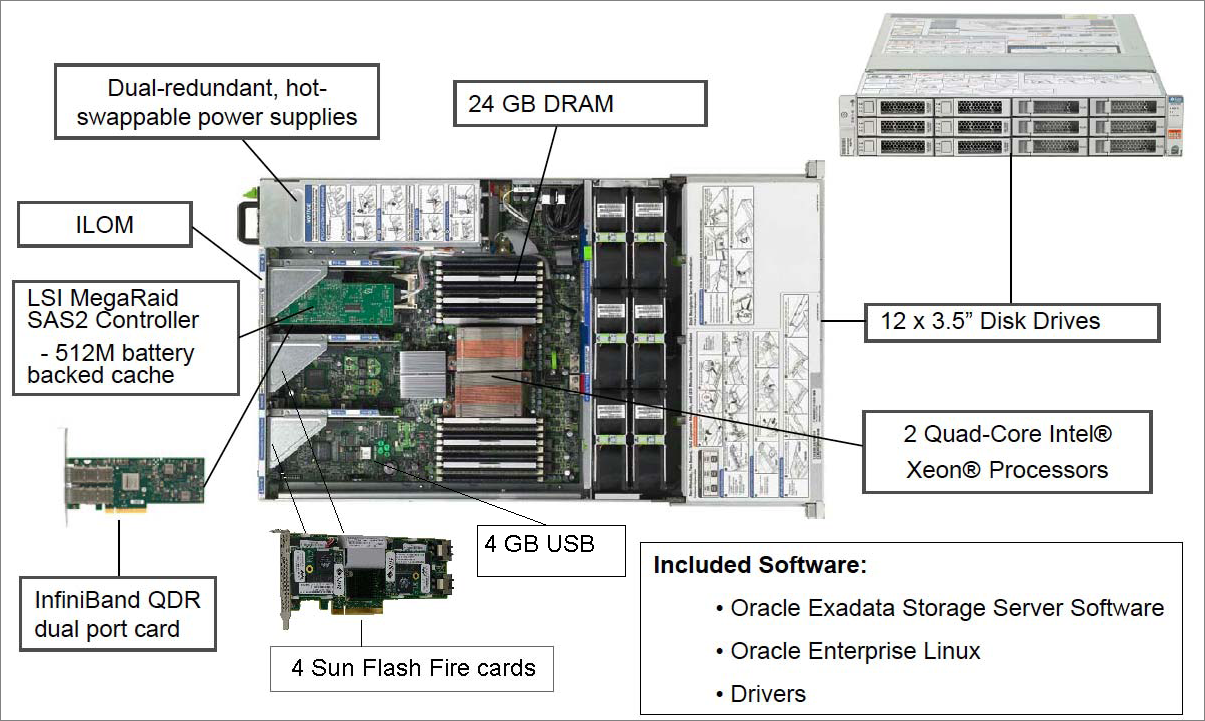
比如1/4配的Exadata,使用的是HC(High Capacity)的磁盘。也就是说3个存储节点,每个节点12个7200rpm 3TB SAS盘。官方给的数据是6000 IOPS。那么这6000是怎么得到的?下面简单的做一下推测:

从上图可以看到, HC和HP的IOPS是分开计算的。 为了说明问题简单的列一下表格:
| Exadata Rack | Disk Type | Disk Count | Disk Model | IOPS |
| FULL(1/1) | HP | 14*12=168 | 15000rpm SAS 600G | 50000 |
| HC | 7200rpm SAS 3T | 28000 | ||
| HALF(1/2) | HP | 7*12=68 | 15000rpm SAS 600G | 25000 |
| HC | 7200rpm SAS 3T | 14000 | ||
| QUAR(1/4) | HP | 3*12=36 | 15000rpm SAS 600G | 10800 |
| HC | 7200rpm SAS 3T | 6000 |
简单的看一下可以发现其中的规律: datasheet上给出的总的IOPS实际上是叠加的。
例如HC 1/4配IOPS为6000,得出一个存储节点的IOPS为6000/3=2000, 一块高容量单盘的IOPS为 2000/12=166.67。HP 1/4配IOPS为10800, 得出一个存储节点的IOPS为10800/3=3600, 一块高性能单盘的IOPS为3600/12=300。所以可以得出结论: 一块高性能盘是按照300 IOPS来计算的,而一块高容量盘是按照166.67 IOPS来计算的。
那么现在的疑问就是到底转速在7200rpm SAS接口容量为3T盘的IOPS有没有166.67? 15000rpm SAS接口容量为600G盘的IOPS有没有300?
首先把这个问题交给wikipedia大神:传送们
在这里提到15000rpm的单块SAS盘的IOPS大概在175-210,而7200rpm的单块SATA盘的
IOPS在75-100, 我们取这个区间的最大值重新计算1/4 HC的总的IOPS只有3600, 相比官方宣称的6000少了40%。同样实际计算出来的HP也将近少了33%。为什么会存在如此大的差异?难道这个数值不准?那么同样我们使用另外一种计算方式来得到IOPS,以下采用一种比较流传甚光的方式来计算硬盘的IOPS:IOPS(每秒IO次数) = 1s/(寻道时间+旋转延迟+数据传输时间)
假设磁盘平均物理寻道时间为3ms, 磁盘转速为7200,10K,15Krpm,则磁盘IOPS理论最大值分别为:
IOPS(7200rpm)= 1000 / (3 + 60000/7200/2) = 140
IOPS (10000rpm) = 1000 / (3 + 60000/10000/2) = 167
IOPS (15000rpm)= 1000 / (3 + 60000/15000/2) = 200
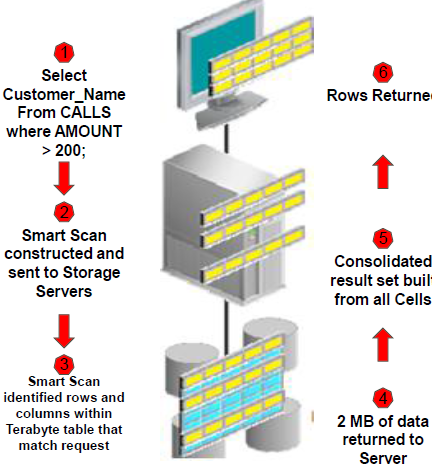
从这种方式来看除了7200rpm的IOPS可以加权40%以外,15000rpm盘的IOPS几乎不变。综上,可以看到实际上Exadata的IOPS与官方宣称的IOPS相差接近30% 到底是什么原因导致了这种差异呢?oracle采用了另外一个名词 Database Disk IOPS(见上面的截图),那么Database Disk IOPS又是什么呢?来看以下官方的解释: Based on read IO requests of size 8K running SQL. Note that the IO size greatly affects Flash IOPS. Others quote IOPS based on 2K, 4K or smaller IOs and are not relevant for databases. Exadata Flash read IOPS are so high they are typically limited by database server CPU, not IO. This is especially true for the Storage Expansion Racks. 这里有亮点很重要的信息:1. 这个指标的衡量是基于读I/O请求计算的。2.是基于8K的I/O大小。言外之意就是早期的Exadata是为DW设计的,读操作对于DW系统更关键。另外就是数据库系统的I/O大小会在8K以上,小于8K的I/O请求在oracle database中是没有太多意义的。
实际上在Exadata安装的时候,有一个测试磁盘I/O性能的步骤,一般是在第9步——INFO: Step 9 RunCalibrate 。这个步骤会对Exadata Cell的磁盘进行IOPS和MBPS的测试。如果有硬盘的IOPS达不到指定的要求,在安装的时候就会报错。 例如有一种很常见的情况: 希捷的硬盘在室温低于20摄氏度的情况下,IOPS会变得较差。见Bug 9476044: CALIBRATE IOPS SUBSTANDARD。 这个问题属于希捷(Seagate)SAS盘的一个“特性”, 后来Exadata使用的日立(Hitachi)没有发现此问题。Exadata的硬盘供应商目前就只有这两家,鉴于此,一般我们并不建议将机房的空调对准Exadata吹来散热。
以下是其中一个客户使用的是希捷 7200rpm SAS接口3T 高容量盘calibrate的真实数据,限于篇幅,我仅仅截取了cel01上面的结果,其它cel的结果基本类似。
INFO: Running /usr/local/bin/dcli -g /opt/oracle.SupportTools/onecommand/cell_group -l root cellcli -e calibrate force to calibrate cells...
SUCCESS: Ran /usr/local/bin/dcli -g /opt/oracle.SupportTools/onecommand/cell_group -l root cellcli -e calibrate force and it returned: RC=0
cel01: Calibration will take a few minutes...
cel01: Aggregate random read throughput across all hard disk luns: 1466 MBPS
cel01: Aggregate random read throughput across all flash disk luns: 4183.67 MBPS
cel01: Aggregate random read IOs per second (IOPS) across all hard disk luns: 2369
cel01: Aggregate random read IOs per second (IOPS) across all flash disk luns: 157585
cel01: Controller read throughput: 2020.61 MBPS
cel01: Calibrating hard disks ...(read only)
cel01: Lun 0_0 on drive [20:0 ] random read throughput: 126.08 MBPS, and 194 IOPS
cel01: Lun 0_1 on drive [20:1 ] random read throughput: 122.98 MBPS, and 190 IOPS
cel01: Lun 0_10 on drive [20:10 ] random read throughput: 132.91 MBPS, and 200 IOPS
cel01: Lun 0_11 on drive [20:11 ] random read throughput: 126.68 MBPS, and 199 IOPS
cel01: Lun 0_2 on drive [20:2 ] random read throughput: 132.73 MBPS, and 204 IOPS
cel01: Lun 0_3 on drive [20:3 ] random read throughput: 126.32 MBPS, and 201 IOPS
cel01: Lun 0_4 on drive [20:4 ] random read throughput: 131.33 MBPS, and 202 IOPS
cel01: Lun 0_5 on drive [20:5 ] random read throughput: 129.67 MBPS, and 202 IOPS
cel01: Lun 0_6 on drive [20:6 ] random read throughput: 131.65 MBPS, and 201 IOPS
cel01: Lun 0_7 on drive [20:7 ] random read throughput: 127.67 MBPS, and 200 IOPS
cel01: Lun 0_8 on drive [20:8 ] random read throughput: 127.63 MBPS, and 201 IOPS
cel01: Lun 0_9 on drive [20:9 ] random read throughput: 130.88 MBPS, and 201 IOPS
cel01: Calibrating flash disks (read only, note that writes will be significantly slower) ...
cel01: Lun 1_0 on drive [FLASH_1_0] random read throughput: 273.71 MBPS, and 20013 IOPS
cel01: Lun 1_1 on drive [FLASH_1_1] random read throughput: 272.84 MBPS, and 20014 IOPS
cel01: Lun 1_2 on drive [FLASH_1_2] random read throughput: 272.78 MBPS, and 19996 IOPS
cel01: Lun 1_3 on drive [FLASH_1_3] random read throughput: 273.64 MBPS, and 19962 IOPS
cel01: Lun 2_0 on drive [FLASH_2_0] random read throughput: 273.73 MBPS, and 20738 IOPS
cel01: Lun 2_1 on drive [FLASH_2_1] random read throughput: 273.81 MBPS, and 20724 IOPS
cel01: Lun 2_2 on drive [FLASH_2_2] random read throughput: 273.69 MBPS, and 20734 IOPS
cel01: Lun 2_3 on drive [FLASH_2_3] random read throughput: 273.96 MBPS, and 20737 IOPS
cel01: Lun 4_0 on drive [FLASH_4_0] random read throughput: 273.63 MBPS, and 19959 IOPS
cel01: Lun 4_1 on drive [FLASH_4_1] random read throughput: 273.85 MBPS, and 19933 IOPS
cel01: Lun 4_2 on drive [FLASH_4_2] random read throughput: 273.76 MBPS, and 19944 IOPS
cel01: Lun 4_3 on drive [FLASH_4_3] random read throughput: 272.97 MBPS, and 19911 IOPS
cel01: Lun 5_0 on drive [FLASH_5_0] random read throughput: 273.87 MBPS, and 20022 IOPS
cel01: Lun 5_1 on drive [FLASH_5_1] random read throughput: 273.04 MBPS, and 20002 IOPS
cel01: Lun 5_2 on drive [FLASH_5_2] random read throughput: 273.66 MBPS, and 19998 IOPS
cel01: Lun 5_3 on drive [FLASH_5_3] random read throughput: 273.77 MBPS, and 19991 IOPS
cel01: CALIBRATE results are within an acceptable range.
从上面的日志中,我们清楚看到每个盘的Database IOPS在200左右,单个cell的IOPS为2369, 比官方提供的166.67和2000要略高。顺便说一下,早期的HC SAS盘实际值在180左右。
综上,我个人的看法是Exadata中说的IOPS特定指的是Database IOPS,也就是在限定在特定条件下得出来的IOPS。实际的IOPS应该会低不少,Exadata上的Oracle Database 使用ASM Normal冗余,实际可用Database IOPS也要减半。真实的IOPS用户可以使用其它专业第三方工具进行测试,有的人说使用oracle的orion (笑)。真实的IOPS多少,Oracle完全可以送交专业的SPC/SPC-1测试,这可是业界大名鼎鼎的权威测试。为什么Oracle不这么做呢?硬件控可以说Oracle忽悠,但是平心而论,Exadata从来不是靠堆硬件来获取高性能的。Exadata是一个工程系统,工程系统最重要的是平衡,从一些客户的使用情况来看,磁盘的I/O通常是一个瓶颈。如果您是OLTP系统,并且有大量很小很密集的I/O写操作,请不要使用高容量的X2(现在默认下单是X3了)。Oracle似乎已经意识到这个问题,并且在下一版的X3中间大量使用了flashdisk的技术来弥补物理盘本身IOPS瓶颈,因为flash的IOPS远比harddisk要高得多。
附录1:
Exadata使用的硬盘提供商及型号如下,读者可以自行google其详细参数:(注意2T盘已经停产)
600G 1500rpm HP disk:Seagate ST3600057SS, Hitachi HUS156060VLS600
3T 7200rpm HC disk: Seagate ST33000650SS
2T 7200rpm HC disk: Seagate ST32000444SS, Hitachi HUS723020ALS640
附录2:
测试Exadata上硬盘和闪存卡database IOPS的工具metric_iorm.pl,有时对Exadata I/O问题的诊断很有用:
Tool for Gathering I/O Resource Manager Metrics: metric_iorm.pl (Doc ID 1337265.1)
以上
如果单纯从硬件的角度来看,我个人认为Oracle官方提供磁盘IOPS信息并不可靠,理由如下:
1. 这里提供的IOPS是一个最大值,也就是maximum value, 也就是说这个IOPS只是一个瞬间的极值,通常只能维持较短的时间,而不是能够一直保持的。
2. Others quote IOPS based on 2K, 4K or smaller IOs and are not relevant for databases 这句话显然是有问题的。尽管数据库块大小是8192字节,但是在Linux的OS blocksize是4096字节, Solaris的OS blocksize是512字节, 也就是说大于4096字节和512字节的块在操作系统层面是不识别的,最终是将数据库的块进行分拆,所以这里说2k, 4k的IO与database不相关显然是不准确的。另外磁盘的最小的读写单位是扇区,而绝大多数磁盘的扇区大小是4096字节。参看http://www.ibm.com/developerworks/linux/library/l-4kb-sector-disks/ , 所以这里说的无关是不准确的。
3. 绝大多数的IOPS测试是基于4k的, 同样的F20的flash卡是提供4k随机读写的IOPS的指标的,为什么硬盘不能提供这个指标?