Oracle 12c可插拔数据库通用架构图
【12c新特性】多LGWR进程SCALABLE LGWR “_use_single_log_writer”
2014/12/07 by Leave a Comment
SCALABLE LGWR是12cR1中引入的一个令人激动的特性, 这是由于在OLTP环境中LGWR写日志往往成为系统的主要性能瓶颈, 如果LGWR进程能像DBWR(DBW0~DBWn)那样多进程写出redo到LOGFILE那么就可能大幅释放OLTP的并发能力,增长Transcation系统的单位时间事务处理能力。
在12cR1 中真正用SCALABLE LGWR实现了这个目的, 也可以俗称为多LGWR进程。
select * from opt_12cR1 where name like '%log%' _use_single_log_writer ADAPTIVE Use a single process for redo log writing _max_outstanding_log_writes 2 Maximum number of outstanding redo log writes
SCALABLE LGWR主要受到隐藏参数_use_single_log_writer的控制, 该参数默认值为ADAPTIVE 。
该参数主要有三个可选值 true, false, adaptive, 默认值为ADAPTIVE。
- 对于ADAPTIVE 和False 如果CPU个数大于一个则会有多个lg0n进程
- 对于true 则不会生成多个lg0n进程,而如同12.1之前那样仅有单个LGWR
SQL> show parameter _use_single_log_writer NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ _use_single_log_writer string ADAPTIVE [oracle@maclean1 ~]$ ps -ef|grep lg grid 4344 1 0 08:07 ? 00:00:00 asm_lgwr_+ASM1 oracle 12628 1 0 08:48 ? 00:00:00 ora_lgwr_MAC_1 oracle 12636 1 0 08:48 ? 00:00:00 ora_lg00_MAC_1 oracle 12640 1 0 08:48 ? 00:00:00 ora_lg01_MAC_1 oracle 13206 7447 0 08:51 pts/2 00:00:00 grep lg
可以使用 10468 level 2 来trace adaptive scalable LGWR
[oracle@maclean1 trace]$ oerr ora 10468 10468, 00000, "log writer debug module" // *Document: NO // *Cause: // *Action: Set this event to the appropriate level for log writer debugging. // alter system set events '10468 trace name context forever,level 2'; LGWR TRACE: kcrfw_slave_adaptive_updatemode: time=426523948079110 scalable slave=1 arbiter=3 group0=10678 all=12733 delay=100 rw=98774 single=1973 48 scalable_nopipe=197548 scalable_pipe=108651 scalable=180439 kcrfw_slave_adaptive_savewritecounts: time=426523954275133 group0=10695 all=12752 kcrfw_slave_adaptive_savewritecounts: time=426523954662537 group0=10696 all=12753 CKPT TRACE: *** 2014-12-07 10:52:21.528 kcrfw_slave_adaptive_saveredorate: time=426523941528521 curr=16649627696 prev=16635613056 rate=14014640 avg=14307212 *** 2014-12-07 10:52:24.553 kcrfw_slave_adaptive_saveredorate: time=426523944553556 curr=16664120996 prev=16649627696 rate=14493300 avg=14318490
实际测试可以发现 仅在redo 生成率非常高的环境中SCALABLE LGWR 对于redo写出的吞吐量有所帮助,进而提高OLTP环境的TPS。
_use_single_log_writer = adaptive 2个LG slave进程:
| Per Second | Per Transaction | Per Exec | Per Call | |
|---|---|---|---|---|
| DB Time(s): | 2.8 | 0.0 | 0.00 | 0.33 |
| DB CPU(s): | 2.6 | 0.0 | 0.00 | 0.31 |
| Redo size (bytes): | 8,180,730.6 | 545.6 | ||
| Logical read (blocks): | 46,382.1 | 3.1 | ||
| Block changes: | 60,219.5 | 4.0 |
| Function Name | Reads: Data | Reqs per sec | Data per sec | Writes: Data | Reqs per sec | Data per sec | Waits: Count | Avg Tm(ms) |
|---|---|---|---|---|---|---|---|---|
| LGWR | 1M | 0.14 | .004M | 4.3G | 29.80 | 16.16M | 1785 | 79.10 |
_use_single_log_writer = true 使用single lgwr
| Per Second | Per Transaction | Per Exec | Per Call | |
|---|---|---|---|---|
| DB Time(s): | 2.8 | 0.0 | 0.00 | 0.34 |
| DB CPU(s): | 2.6 | 0.0 | 0.00 | 0.32 |
| Redo size (bytes): | 8,155,843.5 | 545.0 | ||
| Logical read (blocks): | 46,550.1 | 3.1 | ||
| Block changes: | 60,036.7 | 4.0 |
| Function Name | Reads: Data | Reqs per sec | Data per sec | Writes: Data | Reqs per sec | Data per sec | Waits: Count | Avg Tm(ms) |
|---|---|---|---|---|---|---|---|---|
| LGWR | 1M | 0.13 | .003M | 4.8G | 25.49 | 16.141M | 1611 | 95.97 |
相关AWR附件:
_use_single_log_writer = adaptive
LGWR Scalability 的正面积极意义:
12c通过并发辅助进程以及优化的log file写算法有效改善 多CPU环境中由LGWR引起的等待瓶颈,释放LGWR性能。
一般来说这种性能改善在中小型的数据库实例中并不明显,实际上它们主要是为了那些64个CPU或更多CPU可用的数据库实例。但有性能测试报告显示在最少8个CPU的情况下对性能也有改善。
在之前的版本中,单一的LGWR处理所有的redo strands收集redo记录并将其写出到redo logfile中。在Oracle Database 12c中,LGWR开始并协调多个辅助helper进程,并行地完成以前LGWR一个人做的工作。
- LGWR进程变成了多个LGnn形式的helper进程的协调指挥者,并负责保证这一堆并发进程所做的工作仍满足正确的LGWR顺序
- LGnn进程负责读取一个或多个redo strands,负责实际写出到log file以及post前台进程
限制
在Oracle database 12c中,当使用SYNC同步redo传输方式传输redo到standby database时, 不支持使用上述的并行写SCALABLE LGWR,讲返回到串行写的老路子上。 但是Parallel LGWR/SCALABLE LGWR是支持ASYNC异步redo 传输的。
基于12c in-memory新特性的SQL优化比拼
2014/11/30 by 1 Comment
在本次中#2014年Orcl-Con甲骨文控活动#引入了一个利用12c in-memory特性优化查询语句的workshop ,在不考虑索引等特性的前提下,仅仅使用12c IMCC特性,崔胄同学利用inmemory和并行特性将原本需要1分钟运行的SQL,优化到1.37秒,提升数十倍,成功赢得ipad!
该次SQL优化比拼的 原帖地址http://t.cn/RzURLTJ
OKAY 我们来优化一下, 既然索引,物化视图等传统技术无法使用,我们只能使用使用一些oracle的大数据处理技术来提高性能
首先创建表 scripts 可以查看 xxxxxxxx
这里提一下, 在创建表的时候使用pctfree 0 来适当的降低了逻辑读。
创建完毕
COUNT(*)||'TIME_ROWS'
58432 time_rows
29402976 sales_rows
1776000 customers_rows
160 channles_rows
创建完后 跑了一下
no tuning
172706 consistent gets
Elapsed: 00:00:22.11
oooooopss~ 22秒 看来需要优化
开始使用 in-memory 组件 来优化
SQL> select * from v$version;
BANNER
Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production
SQL> show parameter inmemory
NAME TYPE VALUE
------------------------------------ --------------------------------- ------------------------------
inmemory_clause_default string
inmemory_force string DEFAULT
inmemory_max_populate_servers integer 7
inmemory_query string ENABLE
inmemory_size big integer 16G
inmemory_trickle_repopulate_servers_ integer 1
percent
optimizer_inmemory_aware boolean TRUE
如果内存有限 可以适当的只存放 需要的 列来降低使用memory
alter table SHOUG.times inmemory;
alter table SHOUG.sales inmemory;
alter table shoug.sales no inmemory(PROD_ID,PROMO_ID,QUANTITY_SOLD);
alter table shoug.customers inmemory;
alter table SHOUG.channels inmemory;
Statistics
41 recursive calls
17 db block gets
54 consistent gets
2 physical reads
1188 redo size
1584 bytes sent via SQLNet to client
562 bytes received via SQLNet from client
3 SQL*Net roundtrips to/from client
5 sorts (memory)
0 sorts (disk)
24 rows processed
Elapsed: 00:00:19.70
可以看到 物理读几乎已经很弱了, 但是速度还是不快
优化CPU使用, 可以看到 inmemory 使用后 cpu 使用率达到了100% 但是, 可以看到等待全落在了 单颗 cpu上
所以根据数据量的大小, 来设置并行度
conn shoug/oracle
alter table shoug.sales parallel 8;
alter table shoug.times parallel 1;
alter table shoug.customers parallel 8;
alter table shoug.channel parallel 4;
select table_name,degree from user_tables;
set timing on
SELECT /* use inmemory / /+parallel (shoug.customers 8)*/ c.cust_city,
t.calendar_quarter_desc,
SUM(s.amount_sold) sales_amount
FROM SHOUG.sales s, SHOUG.times t, SHOUG.customers c
WHERE s.time_id = t.time_id
AND s.cust_id = c.cust_id
AND c.cust_state_province = 'FL'
AND t.calendar_quarter_desc IN ('2000-01', '2000-02', '1999-12')
AND s.time_id IN
(SELECT time_id
FROM SHOUG.times
WHERE calendar_quarter_desc IN ('2000-01', '2000-02', '1999-12'))
AND s.cust_id IN
(SELECT cust_id FROM SHOUG.customers WHERE cust_state_province = 'FL')
AND s.channel_id IN
(SELECT channel_id
FROM SHOUG.channels
WHERE channel_desc = 'Direct Sales')
GROUP BY c.cust_city, t.calendar_quarter_desc;
24 rows selected.
Elapsed: 00:00:01.37
Statistics
203 recursive calls
0 db block gets
254 consistent gets
0 physical reads
0 redo size
1574 bytes sent via SQLNet to client
562 bytes received via SQLNet from client
3 SQL*Net roundtrips to/from client
0 sorts (memory)
[root@db ~]# top
top - 23:51:34 up 6 days, 18:18, 6 users, load average: 0.65, 0.17, 0.15
Tasks: 391 total, 3 running, 387 sleeping, 0 stopped, 1 zombie
Cpu0 : 23.3%us, 0.0%sy, 0.0%ni, 76.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu1 : 22.6%us, 0.3%sy, 0.0%ni, 77.1%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu2 : 23.7%us, 0.3%sy, 0.0%ni, 76.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu3 : 22.3%us, 0.0%sy, 0.0%ni, 77.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu4 : 54.8%us, 0.7%sy, 0.0%ni, 44.5%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu5 : 22.1%us, 0.0%sy, 0.0%ni, 77.9%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu6 : 24.3%us, 0.0%sy, 0.0%ni, 75.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu7 : 22.6%us, 0.3%sy, 0.0%ni, 77.1%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 32882416k total, 32061328k used, 821088k free, 13416k buffers
Swap: 8388600k total, 52k used, 8388548k free, 30221056k cached
可以看到cpu使用率达到了30% 以上, 并且, 已经没有内存排序
PS: 恭喜 oracle 在12.1.0.2 版本内 以inmemory 列存储的方式 推出了 vector计算方式, 打破了actian vector db 在大数据市场独领风骚的格局。
Oracle 12.1.0.2新特性 Approximate Count Distinct
2014/10/11 by Leave a Comment
[oracle@PD009 ~]$ grep -i approx_count oracle.str
settings for approx_count_distinct optimizations
qkaGBPushdown: estimated memory without GPD = groupSize (%.2f) * aclsum (%u) = %.2f; estimated memory with GPD = optHllEntry (%u) * # of approx_count_distinct (%d) * parallelDegree (%.0f) = %.2f
APPROX_COUNT_DISTINCT
APPROX_COUNT_DISTINCT
APPROX_COUNT_DISTINCT
_approx_cnt_distinct_gby_pushdown = choose
_approx_cnt_distinct_optimization = 0
alter system flush shared_pool;
alter session set events '10053 trace name context forever ,level 1';
select count( distinct prod_id) from sales_history where amount_sold>1;
select approx_count_distinct(prod_id) from sales_history where amount_sold>1;
oradebug setmypid;
oradebug tracefile_name;
/s01/diag/rdbms/pdprod/PDPROD/trace/PDPROD_ora_4086.trc
sql= select count( distinct prod_id) from sales_history where amount_sold>1
----- Explain Plan Dump -----
----- Plan Table -----
============
Plan Table
============
---------------------------------------------+-----------------------------------+
| Id | Operation | Name | Rows | Bytes | Cost | Time |
---------------------------------------------+-----------------------------------+
| 0 | SELECT STATEMENT | | | | 4912 | |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | VIEW | VW_DAG_0 | 72 | 936 | 4912 | 00:00:59 |
| 3 | HASH GROUP BY | | 72 | 648 | 4912 | 00:00:59 |
| 4 | TABLE ACCESS FULL | SALES_HISTORY| 3589K | 32M | 4820 | 00:00:58 |
---------------------------------------------+-----------------------------------+
sql= select approx_count_distinct(prod_id) from sales_history where amount_sold>1
----- Explain Plan Dump -----
----- Plan Table -----
============
Plan Table
============
----------------------------------------------+-----------------------------------+
| Id | Operation | Name | Rows | Bytes | Cost | Time |
----------------------------------------------+-----------------------------------+
| 0 | SELECT STATEMENT | | | | 4820 | |
| 1 | SORT AGGREGATE APPROX | | 1 | 9 | | |
| 2 | TABLE ACCESS FULL | SALES_HISTORY| 3589K | 32M | 4820 | 00:00:58 |
----------------------------------------------+-----------------------------------+
Predicate Information:
12c RMAN新特性restore/recover from service远程恢复
2014/10/04 by 1 Comment
12c中提供了基于网络的RMAN Restore和recover功能:
About Restoring Files Over the Network
RMAN restores database files, over the network, from a physical standby database by using the
FROM SERVICEclause of theRESTOREcommand. TheFROM SERVICEclause provides the service name of the physical standby database from which the files must be restored. During the restore operation, RMAN creates backup sets, on the physical standby database, of the files that need to be restored and then transfers these backup sets to the target database over the network.Use the
SECTION SIZEclause of theRESTOREcommand to perform a multisection restore operation. To encrypt the backup sets created on the physical standby database, use theSET ENCRYPTIONcommand before theRESTOREcommand to specify the encryption algorithm used.To transfer files from the physical standby database as compressed backup sets, use the
USING COMPRESSED BACKUPSETclause in theRESTOREcommand. By default, RMAN compresses backup sets using the algorithm that is set in the RMAN configuration. You can override the default and set a different algorithm by using theSET COMPRESSION ALGORITHMcommand before theRESTOREstatement.
About Recovering Files Over the Network
RMAN can perform recovery by fetching an incremental backup, over the network, from a primary database and then applying this incremental backup to the physical standby database. RMAN is connected as
TARGETto the physical standby database. The recovery process is optimized by restoring only the used data blocks in a data file. Use theFROM SERVICEclause to specify the service name of the primary database from which the incremental backup must be fetched.To use multisection backup sets during the recovery process, specify the
SECTION SIZEclause in theRECOVERcommand. To transfer the required files from the primary database as encrypted backup sets, use theSET ENCRYPTIONcommand before theRESTOREcommand to specify the encryption algorithm used to create the backup sets.To compress backup sets that are used to recover files over the network, use the
USING COMPRESSED BACKUPSET. RMAN compresses backup sets when it creates them on the primary database and then transfers these backup sets to the target

可以通过restore .. from service指定的对象类型:
- database
- datafile
- tablespace
- 控制文件
- SPFILE

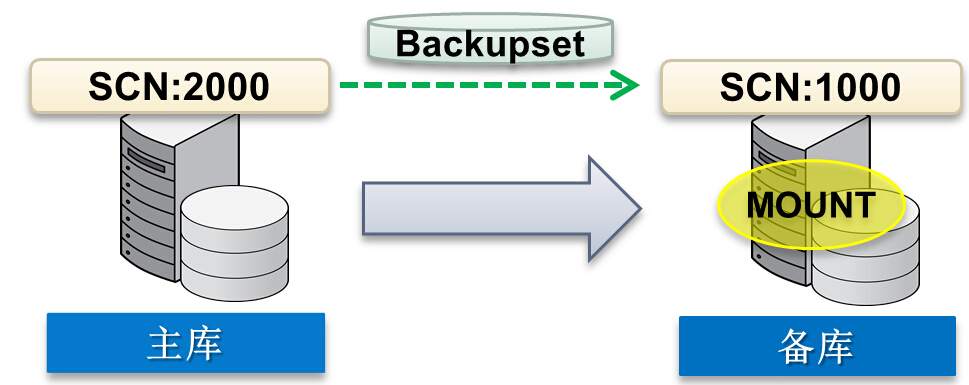
当在主库Primary丢失/或损坏FILE#=6的user01.dbf数据文件时,可以直接使用restore datafile from service来从standby(其实并不要求一定是DataGuard,只需要是合适的备用库即可)上获得数据文件,例如:
select * from v$version; BANNER CON_ID ------------------------------------------------------------------------------------------ ---------- Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production 0 PL/SQL Release 12.1.0.2.0 - Production 0 CORE 12.1.0.2.0 Production 0 TNS for Linux: Version 12.1.0.2.0 - Production 0 NLSRTL Version 12.1.0.2.0 - Production askmac.cn RMAN> select name from v$datafile where file#=6; NAME -------------------------------------------------------------------------------- /s01/oradata/PDPROD/datafile/o1_mf_users_b2wgb20l_.dbf RMAN> alter database datafile 6 offline; Statement processed RMAN> restore datafile 6 from service pdstby; Starting restore at 04-OCT-14 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=51 device type=DISK channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: using network backup set from service pdstby channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00006 to /s01/oradata/PDPROD/datafile/o1_mf_users_b2wgb20l_.dbf channel ORA_DISK_1: restore complete, elapsed time: 00:00:01 Finished restore at 04-OCT-14 RMAN> recover datafile 6 from service pdstby; Starting recover at 04-OCT-14 using channel ORA_DISK_1 channel ORA_DISK_1: starting incremental datafile backup set restore channel ORA_DISK_1: using network backup set from service pdstby destination for restore of datafile 00006: /s01/oradata/PDPROD/datafile/o1_mf_users_b2wgb20l_.dbf RMAN-00571: =========================================================== RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS =============== RMAN-00571: =========================================================== RMAN-03002: failure of recover command at 10/04/2014 02:57:09 ORA-19845: error in backupDatafile while communicating with remote database server ORA-17628: Oracle error 19648 returned by remote Oracle server ORA-19648: datafile : incremental-start SCN equals checkpoint SCN ORA-19660: some files in the backup set could not be verified ORA-19661: datafile 6 could not be verified ORA-19845: error in backupDatafile while communicating with remote database server ORA-17628: Oracle error 19648 returned by remote Oracle server ORA-19648: datafile : incremental-start SCN equals checkpoint SCN 之后recover 并online datafile 6即可
具体的几种用法:
- 数据库级别: restore database from service <服务别名>
- 表空间: restore tablespace from service <服务别名>
- 控制文件: restore controlfile to ‘指定的位置’ from service <服务别名>
- SPFILE: restore spfile from service <服务别名>
通过recover .. from service命令可以通过网络将service指定的数据库的增量备份拉过来在本地做recover从而让本地数据库跟上远程数据库的SCN。
CONNECT TARGET “sys/<password>@standby as sysdba” RECOVER DATABASE FROM SERVICE primary;
此外上述增量备份还可以是基于压缩备份的:
SET COMPRESSION ALGORITHM ‘BASIC’;
SET COMPRESSION ALGORITHM ‘LOW’;
SET COMPRESSION ALGORITHM ‘MEDIUM’;
SET COMPRESSION ALGORITHM ‘HIGH’;
CONNECT TARGET “sys/<password>@standby as sysdba”
SET COMPRESSION ALGORITHM ‘BASIC’;
RECOVER DATABASE FROM SERVICE primary
USING COMPRESSED BACKUPSET;
【Oracle 12c】In-Memory Database Cache内存数据库选项
2014/09/04 by 1 Comment
| NAME | AVALUE | SDESC |
| _inmemory_check_prot_meta | FALSE | If true, marks SMU area read only to prevent stray writes |
| _inmemory_private_journal_quota | 100 | quota for transaction in-memory private journals |
| _inmemory_private_journal_sharedpool_quota | 20 | quota for transaction in-memory objects |
| _inmemory_private_journal_numbkts | 512 | Number of priv jrnl ht bkts |
| _inmemory_private_journal_numgran | 128 | Number of granules per HT node |
| _inmemory_jscan | 0 | inmemory jscan enable |
| _inmemory_pin_hist_mode | 16 | settings for IM pinned buffer history |
| _inmemory_txn_checksum | 0 | checksum for SMUs and private journals |
| _inmemory_buffer_waittime | 100 | wait interval for one SMU or IMCU to be freed |
| _inmemory_cu_timeout | 100 | maximum wait time for one IMCU to be freed |
| _inmemory_cudrop_timeout | 1000 | maximum wait time for IMCU to be freed during drop |
| _inmemory_exclto_timeout | 1000 | maximum wait time to pin SMU for cleanout |
| _inmemory_num_hash_latches | 256 | Maximum number of latches for IM buffers |
| _inmemory_strdlxid_timeout | 0 | max time to determine straddling transactions |
| _inmemory_incremental_repopulation | FALSE | If true, incremental repopulation of IMCU will be attempted |
| _inmemory_lock_for_smucreate | FALSE | take object lock during smu creation |
| _inmemory_auto_distribute | TRUE | If true, enable auto distribute |
| _inmemory_autodist_2safe | FALSE | If true, enable auto distribute with 2safe |
| _inmemory_distribute_timeout | 300 | If true, enable auto distribute with 2safe |
| _inmemory_distribute_ondemand_timeout | 300 | On demand timeout for redistribute |
| inmemory_size | 0 | size in bytes of in-memory area |
| _inmemory_64k_percent | 30 | percentage of in-memory area for 64k pools |
| _inmemory_min_ima_defersize | 0 | Defer in-memory area allocation beyond this size |
| _inmemory_memprot | TRUE | enable or disable memory protection for in-memory |
| _inmemory_analyzer_optimize_for | 0 | inmemory analyzer optimize for |
| _inmemory_default_flags | 8459 | Default flags based on inmemory_clause_default |
| _inmemory_default_new | FALSE | Force in-memory on new tables |
| inmemory_clause_default | Default in-memory clause for new tables | |
| inmemory_force | DEFAULT | Force tables to be in-memory or not |
| inmemory_query | ENABLE | Specifies whether in-memory queries are allowed |
| _inmemory_query_scan | TRUE | In-memory scan enabled |
| _inmemory_scan_override | FALSE | In-memory scan override |
| _inmemory_scan_threshold_percent_noscan | 50 | In-memory scan threshold maximum percent dirty no scan |
| _inmemory_small_segment_threshold | 65536 | In-memory small segment threshold (must be larger for in-memory) |
| _inmemory_query_fetch_by_rowid | FALSE | In-memory fetch-by-rowid enabled |
| _inmemory_pruning | ON | In-memory pruning |
| _inmemory_enable_sys | FALSE | enable in-memory on system tablespace with sys user |
| _inmemory_populate_fg | FALSE | populate in foreground |
| _inmemory_pga_per_server | 536870912 | minimum pga needed per inmemory populate server |
| inmemory_max_populate_servers | 0 | maximum inmemory populate servers |
| _inmemory_servers_throttle_pgalim_percent | 55 | In-memory populate servers throttling pga limit percentage |
| inmemory_trickle_repopulate_servers_percent | 1 | inmemory trickle repopulate servers percent |
| _inmemory_populate_wait | FALSE | wait for population to complete |
| _inmemory_populate_wait_max | 600 | maximum wait time in seconds for segment populate |
| _inmemory_imco_cycle | 120 | IMCO cycle in seconds (sleep period) |
| _inmemory_enable_population_verify | 1 | verify in-memory population |
| _inmemory_log_level | 1 | in-memory log level |
| _inmemory_fs_verify | FALSE | in-memory faststart verify |
| _inmemory_force_fs | FALSE | in-memory faststart force |
| _inmemory_force_fs_tbs | SYSAUX | in-memory faststart force tablespace |
| _inmemory_force_fs_tbs_size | 1073741824 | in-memory faststart force tablespace size |
| _inmemory_fs_raise_error | FALSE | in-memory faststart raise error |
| _inmemory_fs_nodml | FALSE | in-memory faststart assumes no dmls while populating |
| _inmemory_fs_enable | FALSE | in-memory faststart enable |
| _inmemory_fs_enable_blk_lvl_inv | TRUE | in-memory faststart enable block level invalidation |
| _inmemory_fs_blk_inv_blkcnt | in-memory faststart CU invalidation threshold(blocks) | |
| _inmemory_fs_blk_inv_blk_percent | 20 | in-memory faststart CU invalidation threshold(blocks) |
| _inmemory_enable_stat_alert | FALSE | dump in-memory stats in alert log file |
| _inmemory_imcu_align | TRUE | Enforce 8M IMCU alignment |
| _inmemory_max_populate_retry | 3 | IM populate maximum number of retry |
| _inmemory_imcu_target_rows | 1048576 | IMCU target number of rows |
| _inmemory_imcu_target_bytes | 0 | IMCU target size in bytes |
| _inmemory_imcu_source_extents | 0 | number of source extents per IMCU |
| _inmemory_imcu_source_blocks | 0 | number of source blocks per IMCU |
| _inmemory_imcu_source_minbytes | 1048576 | number of minimum source bytes per IMCU |
| _inmemory_imcu_populate_minbytes | 5242880 | minimum free space in IMA for populating IMCU |
| _inmemory_imcu_source_analyze_bytes | 134217728 | number of source analyze bytes per IMCU |
| _inmemory_imcu_target_maxrows | 8388608 | IMCU maximum target number of rows |
| _inmemory_imcu_source_maxbytes | 536870912 | IMCU maximum source size in bytes |
| _inmemory_max_queued_tasks | 0 | Maximum queued populating tasks on the auxiliary queue |
| _inmemory_repopulate_threshold_rows | In-memory repopulate threshold number of modified rows | |
| _inmemory_repopulate_threshold_blocks | In-memory repopulate threshold number of modified blocks | |
| _inmemory_pct_inv_rows_invalidate_imcu | 50 | In-memory percentage invalid rows for IMCU invalidation |
| _inmemory_pct_inv_blocks_invalidate_imcu | 100 | In-memory percentage invalid blocks for IMCU invalidation |
| _inmemory_repopulate_threshold_mintime_factor | 5 | In-memory repopulate minimum interval (N*timetorepop) |
| _inmemory_repopulate_threshold_mintime | 0 | In-memory repopulate minimum interval (millisec) |
| _inmemory_repopulate_threshold_scans | 0 | In-memory repopulate threshold number of scans |
| _inmemory_repopulate_priority_scale_factor | 100 | In-memory repopulate priority threshold scale factor |
| _inmemory_repopulate_invalidate_rate_percent | 100 | In-memory repopulate invalidate rate percent |
| _inmemory_repopulate_priority_threshold_row | 20 | In-memory repopulate priority threshold row |
| _inmemory_repopulate_priority_threshold_block | 40 | In-memory repopulate priority threshold block |
| _inmemory_repopulate_threshold_rows_percent | 5 | In-memory repopulate threshold rows invalid percentage |
| _inmemory_repopulate_threshold_blocks_percent | 10 | In-memory repopulate threshold blocks invalid percentage |
| _inmemory_repopulate_disable | FALSE | disable In-memory repopulate |
| _inmemory_check_protect | FALSE | If true, marks in-memory area read only to prevent stray writes |
| _inmemory_checksum | FALSE | If true, checksums in-memory area to detect stray writes |
| _inmemory_validate_fetch | FALSE | If true, validate single-row fetch between in-memory and disk |
| _inmemory_journal_row_logging | FALSE | If true, log the entire row into the in-memory journal |
| _inmemory_journal_check | 0 | Depending on value does one of the DML verifications |
| _inmemory_rows_check_interrupt | 1000 | Number of rows buffered before interrupt check |
| _inmemory_dbg_scan | 0 | In-memory scan debugging |
| _inmemory_segment_populate_verify | 0 | In-memory segment populate verification |
| _inmemory_query_check | 0 | In-memory query checking |
| _inmemory_test_verification | 0 | In-memory verification testing |
| _inmemory_invalidate_cursors | TRUE | In-memory populate enable cursor invalidations |
| _inmemory_prepopulate_fg | 0 | Force prepopulate of in-memory segment in foreground |
| _inmemory_prepopulate | TRUE | Enable inmemory populate by IMCO |
| _inmemory_trickle_repopulate | TRUE | Enable inmemory trickle repopulate |
| _inmemory_trickle_repopulate_threshold_dirty_ratio | 0 | IMCO Trickle Repopulate threshold dirty ratio |
| _inmemory_trickle_repopulate_min_interval | 300 | IMCO Trickle Repopulate Interval |
| _inmemory_trickle_repopulate_fg | 0 | Trickle Repopulate in the Foreground |
| _inmemory_force_non_engineered | FALSE | force non-engineered systems in-memory behavior on RAC |
| _inmemory_suppress_vsga_ima | FALSE | Suppress inmemory area in v$sga |
| optimizer_inmemory_aware | TRUE | optimizer in-memory columnar awareness |
| _optimizer_inmemory_table_expansion | TRUE | optimizer in-memory awareness for table expansion |
| _optimizer_inmemory_gen_pushable_preds | TRUE | optimizer generate pushable predicates for in-memory |
| _optimizer_inmemory_autodop | TRUE | optimizer autoDOP costing for in-memory |
| _optimizer_inmemory_access_path | TRUE | optimizer access path costing for in-memory |
| _optimizer_inmemory_quotient | 0 | in-memory quotient (% of rows in in-memory format) |
| _optimizer_inmemory_pruning_ratio_rows | 100 | in-memory pruning ratio for # rows (% of rows remaining after pruning) |
| _parallel_inmemory_min_time_threshold | AUTO | threshold above which a plan is a candidate for parallelization for in-memory tables (in seconds) |
| _parallel_inmemory_time_unit | 1 | unit of work used to derive the degree of parallelism for in-memory tables (in seconds) |
| _optimizer_inmemory_bloom_filter | TRUE | controls serial bloom filter for in-memory tables |
| _optimizer_inmemory_cluster_aware_dop | TRUE | Affinitize DOP for inmemory objects |
| _optimizer_inmemory_minmax_pruning | TRUE | controls use of min/max pruning for costing in-memory tables |
test
In-Memory Database Cache
IM in-memory ((null))
IM_transaction IM transaction layer ((null))
IM_Txn_PJ IM Txn Private Journal (ktmpj)
IM_Txn_SJ IM Txn Shared Journal (ktmsj)
IM_Txn_JS IM Txn Journal Scan (ktmjs)
IM_Txn_Conc IM Txn Concurrency (ktmc)
IM_Txn_Blk IM Txn Block (ktmb)
IM_Txn_Read IM Txn Read (ktmr)
IM_space IM space layer ((null))
IM_data IM data layer (kdm)
IM_populate IM populating (kdml)
IM_background IM background (kdmr)
IM_scan IM scans ((null))
IM_journal IM journal ((null))
IM_dump IM dump ((null))
IM_FS IM faststart ((null))
IM_optimizer IM optimizer (kdmo)
alter session set events 'trace[IM_scan] disk=medium';
SQL> alter system set inmemory_size=2g scope=spfile;
System altered.
SQL> shutdown immediate;
[oracle@mlab2 ~]$ sqlplus / as sysdba
SQL*Plus: Release 12.1.0.2.0 Production on Wed Sep 3 23:18:18 2014
Copyright (c) 1982, 2014, Oracle. All rights reserved.
Connected to an idle instance.
SQL> startup;
ORACLE instance started.
Total System Global Area 2684354560 bytes
Fixed Size 2928008 bytes
Variable Size 402653816 bytes
Database Buffers 117440512 bytes
Redo Buffers 13848576 bytes
In-Memory Area 2147483648 bytes
Database mounted.
Database opened.
alter session set events 'trace[IM_scan] disk=medium';
select count(*) from mac_imm1;
SQL> oradebug setmypid
Statement processed.
SQL> oradebug tracefile_name
/s01/diag/rdbms/c12r1/C12R1/trace/C12R1_ora_16700.trc
kdmsirs(): map with 13 extents
Ext: 0, dba: 0x18000db, len: 5, skp: 0
Ext: 1, dba: 0x18000e0, len: 8, skp: 0
Ext: 2, dba: 0x18000e9, len: 7, skp: 0
Ext: 3, dba: 0x18000f0, len: 8, skp: 0
Ext: 4, dba: 0x18000f9, len: 7, skp: 0
Ext: 5, dba: 0x1800100, len: 8, skp: 0
Ext: 6, dba: 0x1800109, len: 7, skp: 0
Ext: 7, dba: 0x1800110, len: 8, skp: 0
Ext: 8, dba: 0x1800119, len: 7, skp: 0
Ext: 9, dba: 0x1800120, len: 8, skp: 0
Ext: 10, dba: 0x1800129, len: 7, skp: 0
Ext: 11, dba: 0x1800130, len: 8, skp: 0
Ext: 12, dba: 0x1800139, len: 1, skp: 0
kdmsStartEndDBA(): scan start: 0x18000db end: 0x18000df rdba[0]: 0x18000db size[0]: 5, nblks: 5 extno: 0, skip: 0
kdmsGetIMCU(): In arguments: nblks 5: start_addr 25166043, end_addr 25166047
kdmsGetIMCU(): Mem addr: baffffd0: mem len: 1048576: Start dba: 0x18000db 25166043: len: 5 smu: fbf44770 td: 0x7f76515361a8
kdmsGetIMCU(): range: 0 lrid dba: 0x0 slot: 0 hrid dba: 0x0 slot: 0
kdmsGetIMCU(): found imcu 0xbaffffd0 25166043 25166047 1
kdst_fetch_imc(): imcu get 0x18000db
kdmsTransGet(): got ktmrds for dba 0x18000db, td : 0x7f76515361a8
kdmsFindEndDba: ext in imcu is 0, and on disk 0
IMCU extents
extent 0: 25166043 0x18000db + 5
extent 1: 25166048 0x18000e0 + 8
extent 2: 25166057 0x18000e9 + 7
extent 3: 25166064 0x18000f0 + 8
extent 4: 25166073 0x18000f9 + 7
extent 5: 25166080 0x1800100 + 8
extent 6: 25166089 0x1800109 + 7
extent 7: 25166096 0x1800110 + 8
extent 8: 25166105 0x1800119 + 7
extent 9: 25166112 0x1800120 + 8
extent 10: 25166121 0x1800129 + 7
extent 11: 25166128 0x1800130 + 8
extent 12: 25166137 0x1800139 + 1
Disk extents
extent 0: 25166043 0x18000db + 5 (skip = 0)
extent 1: 25166048 0x18000e0 + 8 (skip = 0)
extent 2: 25166057 0x18000e9 + 7 (skip = 0)
extent 3: 25166064 0x18000f0 + 8 (skip = 0)
extent 4: 25166073 0x18000f9 + 7 (skip = 0)
extent 5: 25166080 0x1800100 + 8 (skip = 0)
extent 6: 25166089 0x1800109 + 7 (skip = 0)
extent 7: 25166096 0x1800110 + 8 (skip = 0)
extent 8: 25166105 0x1800119 + 7 (skip = 0)
extent 9: 25166112 0x1800120 + 8 (skip = 0)
extent 10: 25166121 0x1800129 + 7 (skip = 0)
extent 11: 25166128 0x1800130 + 8 (skip = 0)
extent 12: 25166137 0x1800139 + 1 (skip = 0)
kdmsFindEndDba(): begin: 25166043, end dba: 25166137 done ext in imcu 12 on disk 12
min of imcu end 25166138 0x180013a disk end 25166138 0x180013a discont 0
kdst_fetch_imc(): done: 1, empty: 0, ftch: 0
kdst_fetch_imc(): fetch: 0, invalid: 0
kdmsRepopulate(): repop 0 nblks 89 0 nrows 2342 0 cnt 5
kdstf00100010001101kmP(): create vv 18000db 95
kdmsCreateIMCUValidVector: Scan range (25166043, 25166137)
Extent map passed into kdzd layer:
Extent 0: (25166043, 25166047)
Extent 1: (25166048, 25166055)
Extent 2: (25166057, 25166063)
Extent 3: (25166064, 25166071)
Extent 4: (25166073, 25166079)
Extent 5: (25166080, 25166087)
Extent 6: (25166089, 25166095)
Extent 7: (25166096, 25166103)
Extent 8: (25166105, 25166111)
Extent 9: (25166112, 25166119)
Extent 10: (25166121, 25166127)
Extent 11: (25166128, 25166135)
Extent 12: (25166137, 25166137)
kdzd_dump_validvec:
IMCU: 1
Num slots: 2342 set: 2342 rounded to 8: 2368 bytes: 296
Flag if all rows valid: 1
ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.
ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.
ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.
ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.
ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.
ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.
ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.
ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.
ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.
ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.
ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.
ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.ff.3f.
3 final 0
kdzd_dump_validvec: End Dumping Valid Vector
**************** ktmrDS Dump *****************
pdb=0, tsn=4, rdba=25166043, objn=91999, objd=91999, typ=1, gflg=0 flg=0
loadscn=scn: 0x0000.001af80b
invalid blkcnt=0, fetch blkcnt=0
env [0x7f765152af6c]: (scn: 0x0000.001af830 xid: 0x0000.000.00000000 uba: 0x00000000.0000.00 statement num=0 parent xid: 0x0000.000.00000000 st-scn: 0x0000.00000000 hi-scn: 0x0000.00000000 ma-scn: 0x0000.001af82c flg: 0x00000660)invalid rowcnt=0,
fetch rowcnt=0
kdst_fetch_imc(): release 0x18000db from td: 0x7f76515361a8
kdmsGetJournalRows(): done with IMC fetch; journal rows -1
kdmsEnd(): imcuctx 0x7f7651688b78 release 0x18000db from td: 0x7f76515361a8
Oracle 12c新特性学习列表
2014/09/03 by Leave a Comment
DB 12c Admin New Features Self-Studies
- Phase 1 (estimated completion February 2012):
- Oracle Database 12c: Container Database
- Phase 2 (estimated completion April 2012):
- Oracle Database 12c: Data Guard New Features
- Oracle Database 12c: Oracle Availability Machine [was OHARA; may move this to phase 3 or 4]
- Oracle Database 12c: Recovery Manager New Features
- Oracle Database 12c: Resource Manager and Scheduler New Features
- Phase 3 (estimated completion May 2012):
- Oracle Database 12c: Data Pump and SQL*Loader New Features
- Oracle Database 12c: Information Lifecycle Management New Features [may move this to phase 2]
- Oracle Database 12c: Performance Enhancements
- Phase 4 (estimated completion June 2012)
- Oracle Database 12c: Application Continuity [not much functionality exposed to customer?]
- Oracle Database 12c: Automatic Storage Management
- Oracle Database 12c: Clusterware and Grid Infrastructure New Features
- Oracle Database 12c: Installation and Upgrade New Features
- Oracle Database 12c: Networking New Features
- Oracle Database 12c: Online Operations New Features
- Oracle Database 12c: Cloud Computing New Features [was Private Database Cloud]
- Oracle Database 12c: Real Application Clusters New Features
- Oracle Database 12c: Security New Features
DB 12c App Dev New Features Self-Studies
- Phase 1 (estimated completion February 2012):
- None
- Phase 2 (estimated completion April 2012):
- Oracle Database 12c: Application Migration New Features
- Oracle Database 12c: BI and Data Warehousing New Features
- Oracle Database 12c: Application Development New Features
- Oracle Database 12c: Miscellaneous Database Enhancements
- Oracle Database 12c: PL/SQL New Features
- Phase 3 (estimated completion May 2012):
- Oracle Database 12c: OCI / OCCI New Features [may not create this due to limited interest]
- Oracle Database 12c: Oracle Data Mining New Features
- Oracle Database 12c: Oracle Spatial New Features
- Oracle Database 12c: Real Application Security
- Oracle Database 12c: SQL Tuning New Features
- Phase 4 (estimated completion June 2012)
- Oracle Database 12c: Application Express New Features [APEX 4.2]
- Oracle Database 12c: Java and JDBC New Features
- Oracle Database 12c: ODP .Net New Features
- Oracle Database 12c: Oracle XML DB New Features
- Oracle Database 12c: Oracle Text New Features
- Oracle Database 12c: Real Application Testing New Features

#ORACLE 12c in-memory#
2014/07/02 by Leave a Comment
#ORACLE 12c in-memory# IBM这次很敏捷,马上就DB2 BLU和Oracle 12c in-memory做对比。其攻击矛头指向几点:Oracle磁盘上的数据仍以行row形式存,存放重复列存数据,O必须把所有列存数据放入内存,内存列存让重启预热变长。Oracle说我只是蛋糕上加了草莓而已,别整那些没用的。
#揭秘Oracle 12c in-memory option#
2014/06/10 by Leave a Comment
#揭秘Oracle 12c in-memory option#
#揭秘Oracle 12c in-memory option# 参数inmemory_columnar_size将控制IMCC的大小,注释为:size in bytes of imc pool。使用前提之一应当是compatible为12.0.0以上,所以这个IMCC特性是几乎不可能backport到11.2上。Oracle 12c最卖座特性!
#揭秘Oracle 12c in-memory option#和Oracle的其他特性一样,IMCC特性也会引入一些隐藏参数来控制特性行为,这些参数会包括_enable_imc_sys 是否在SYSTEM表空间上启用IMC,_imc_dbg_scan 用来debug IMC扫描,同时引入了IMC_SCAN TRACE机制,喜欢研究新特性的同学有的搞了
#揭秘Oracle 12c in-memory option#这个option在内部叫做in memory columnar & compression (IMCC) project,缩写IMCC,例如其引入了一个新的in-memory数据引擎,称之为IMCC-DE。 IMCC项目最早大概在2006年被提出,该项目的三大目标:快的离谱的全表扫描,连接和聚集,DML于内存压缩数据的速度几乎一样
