COMMIT操作是RDBMS中事务结束的标志,在Oracle中与commit紧密相关的是SCN(System Change Number)。
引入SCN的最根本目的在于:
- 为读一致性所用
- 为redolog中的记录排序,以及恢复
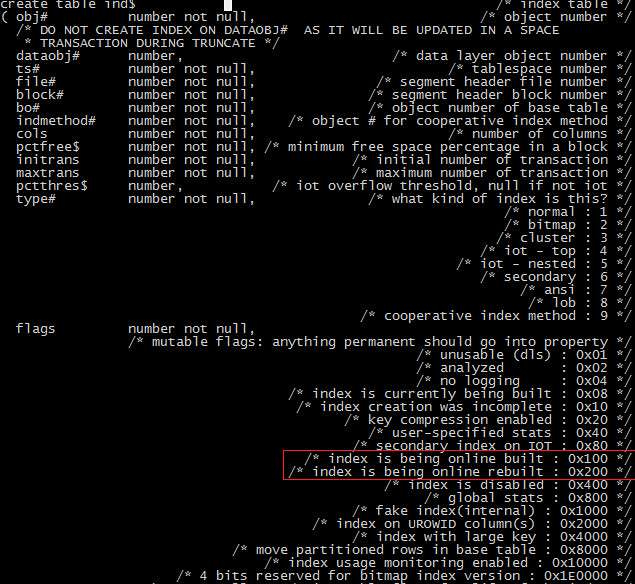
SCN由SCN Base和Scn Wrap组成,是一种6个字节的结构(structure)。其中SCN Base占用4个字节,而SCN wrap占用2个字节。但在实际存储时SCN-like的stucture常会占用8个字节。
ub4 kscnbas
ub2 kscnwrp
struct kcvfhcrs, 8 bytes @100 Creation Checkpointed at scn
ub4 kscnbas @100 0x000a8849
ub2 kscnwrp @104 0x0000
在Oracle中一个事务的开始包含以下操作:
- 绑定一个可用的rollback segment
- 在事务表(transaction table)上分配一个必要的槽位
- 从rollback segment中分配undo block
注意system rollback segment是一种特殊的回滚段,在10g以后普通回滚段的类型都变成了”TYPE2 UNDO”,而唯有system rollback segment的类型仍为”ROLLBACK”,这是由其特殊性造就的:
SQL> col segment_name for a20 SQL> col rollback for a20 SQL> select segment_name,segment_type from dba_segments where segment_type='ROLLBACK'; SEGMENT_NAME SEGMENT_TYPE -------------------- ------------------ SYSTEM ROLLBACK
System rollback segment面向的是SYSTEM表空间上数据字典对象相关事务的数据,以及由对用户数据产生的递归SQL调用所产生的数据。
Oracle不使用基于内存锁管理器的行锁,Oracle中的row lock是基于数据块的。数据块中的Interested Transaction List(ITL)是行锁的重要标志。
ITL的分配遵循以下的原则:
- 找出未被使用的ITL
- 找出最老的已经事务提交的ITL
- 做部分的块清理,直到有可用的ITL
- 扩展ITL区域,一条ITL占用24字节
当事务提交COMMIT时,需要完成以下步骤的操作:
- 得到一个SCN值
- 使用得到的SCN更新事务表中的槽位
- 在redo log buffer中创建一条commit记录
- 将redo log buffer刷新到磁盘上的在线日志文件
- 释放表和行上的锁(may cause delayed block cleanout)