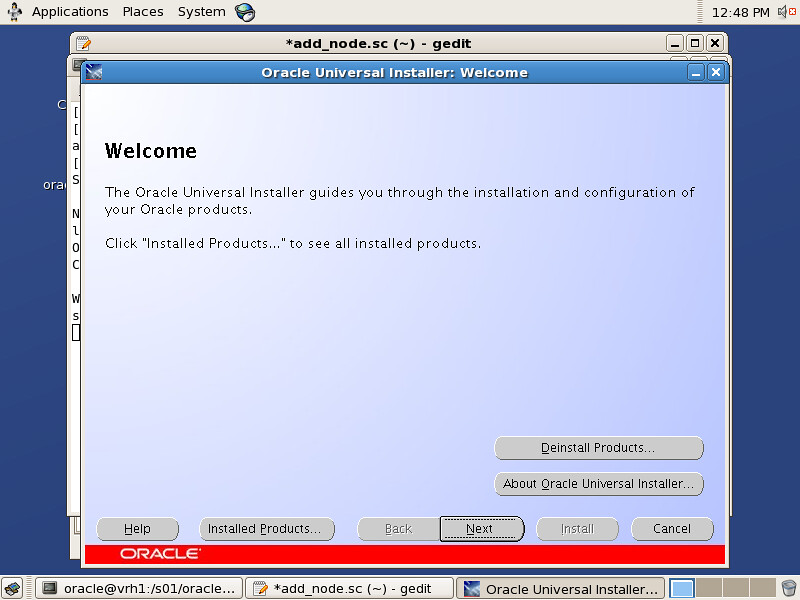
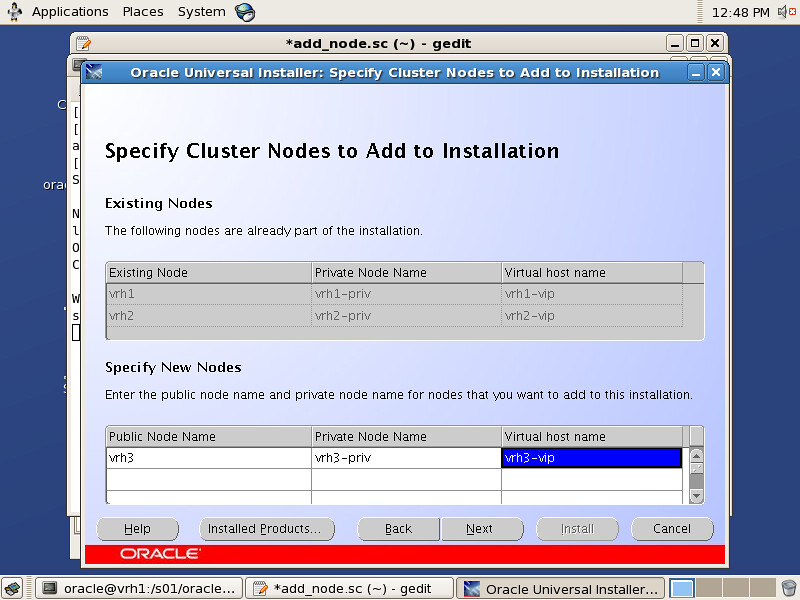
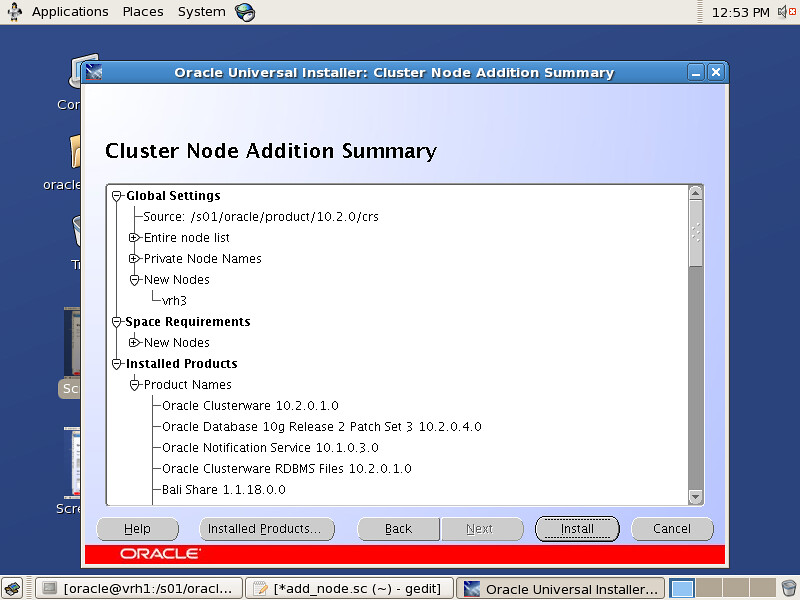
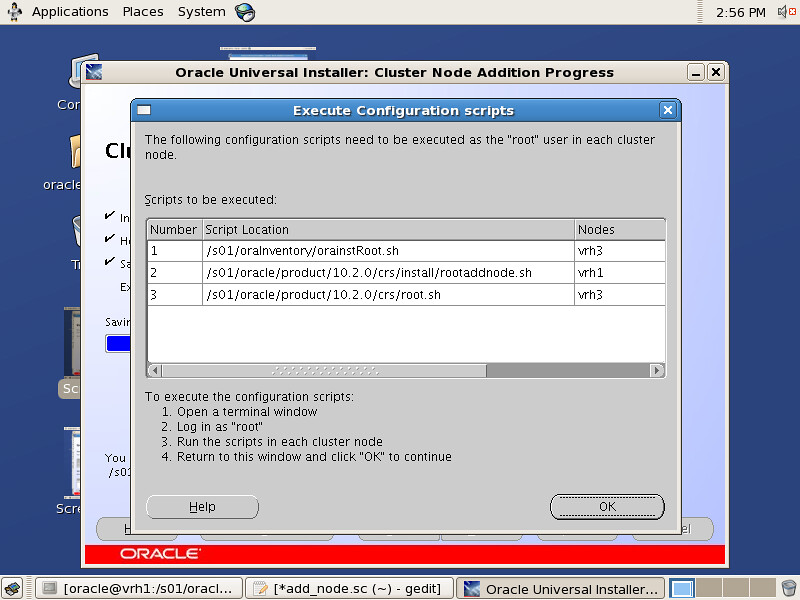
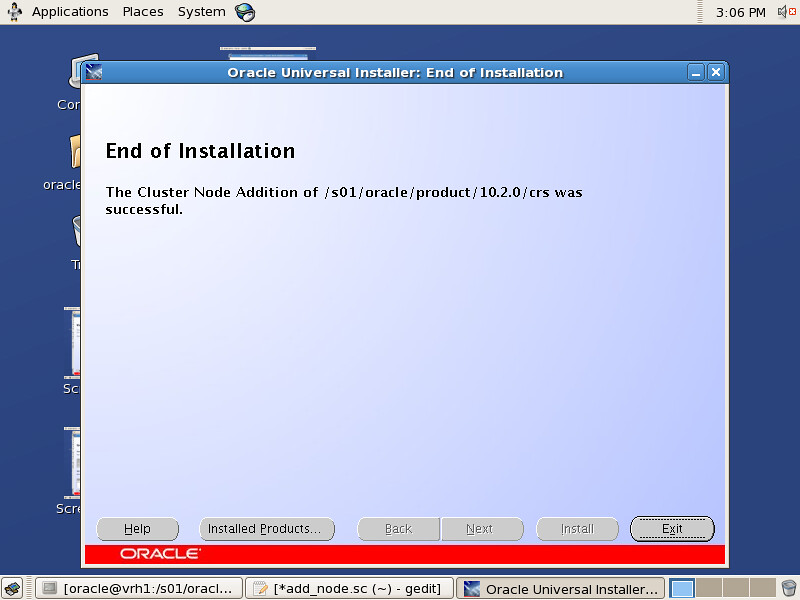
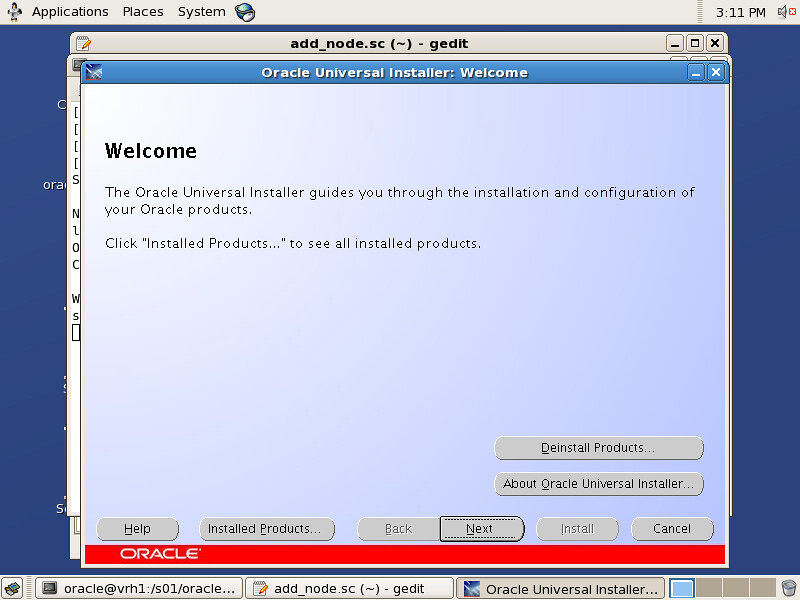
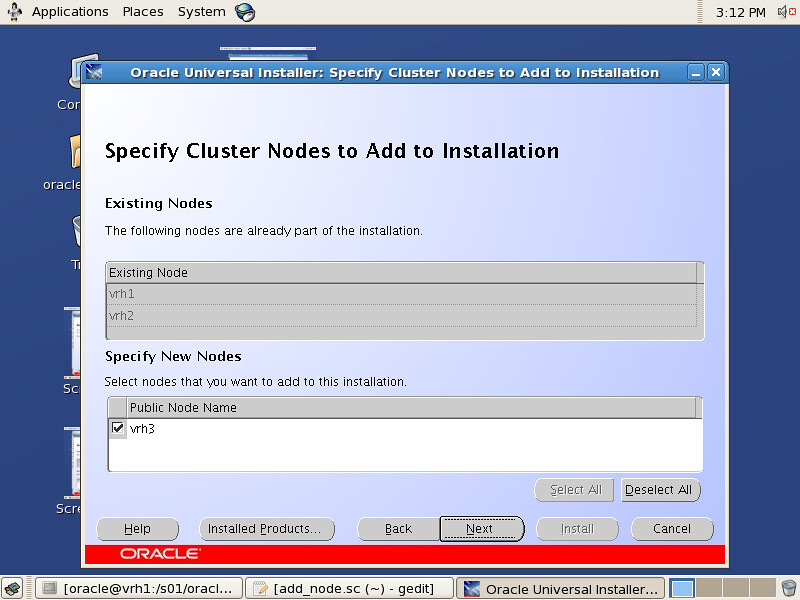
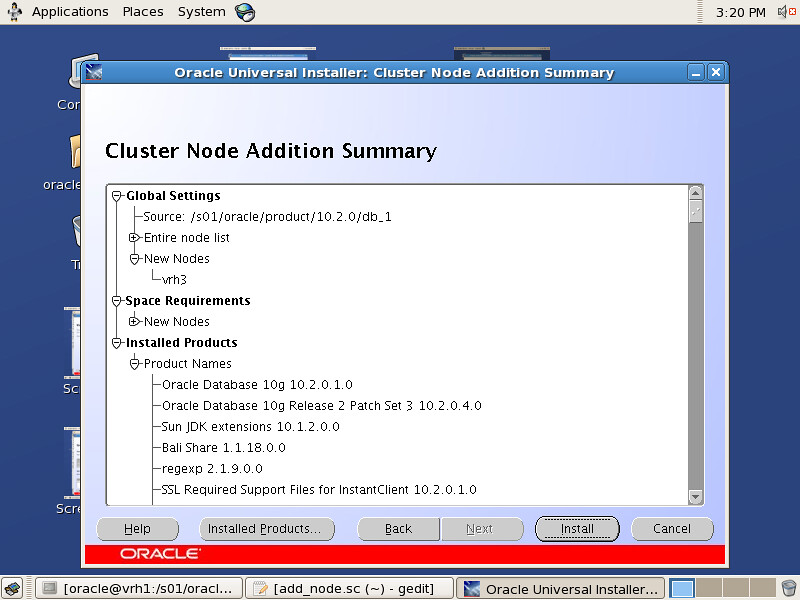
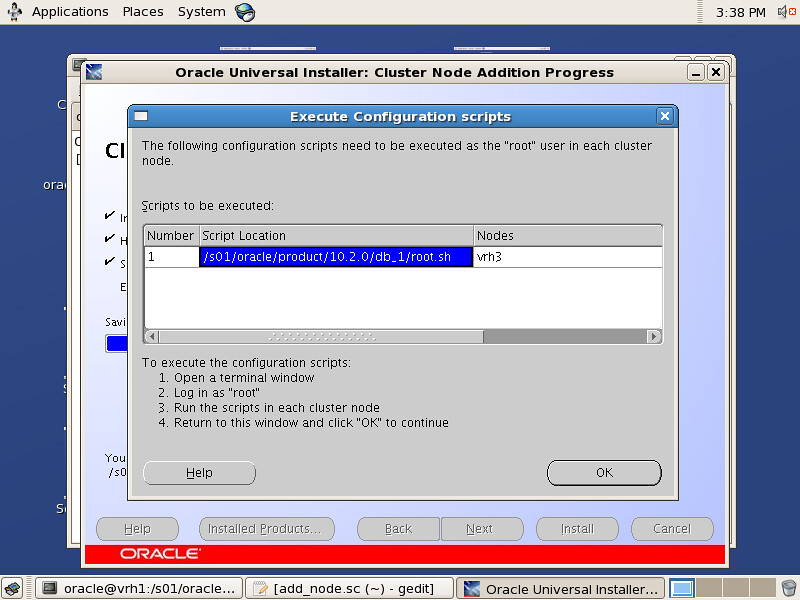
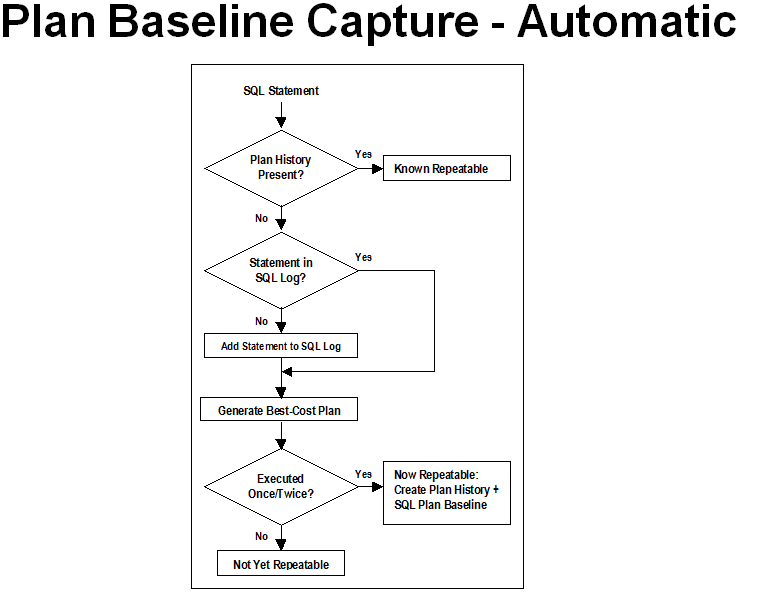
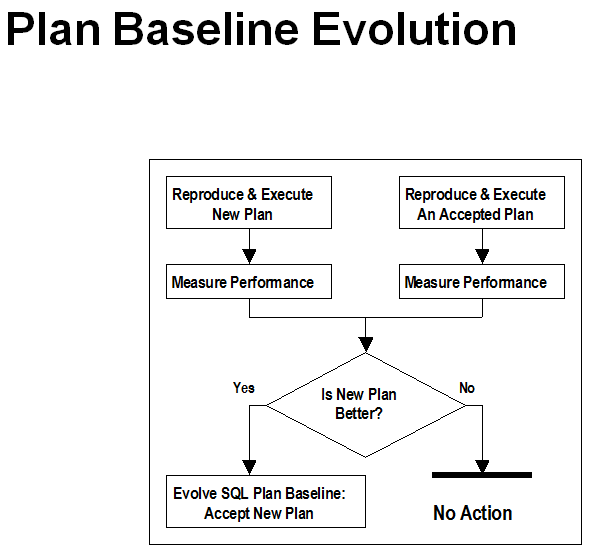
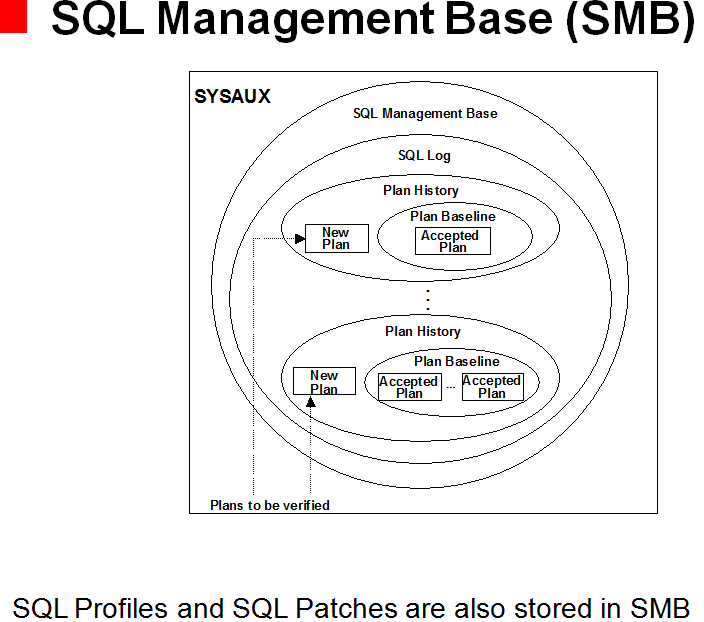
Oracle SPM SQL PLAN MANAGEMENT执行计划管理流程图如下:

SQL> create table mac_spm tablespace users as select * from dba_objects;
Table created.
SQL> analyze table mac_spm compute statistics;
Table analyzed.
SQL> alter session set optimizer_capture_sql_plan_baselines=true;
Session altered.
SQL>
SQL> select sum(object_id) from mac_spm;
SUM(OBJECT_ID)
--------------
2911455720
SQL> select sum(object_id) from mac_spm;
SUM(OBJECT_ID)
--------------
2911455720
alter session set optimizer_capture_sql_plan_baselines=false;
SQL> alter system flush shared_pool;
System altered.
SQL> set autotrace on;
SQL> select sum(object_id) from mac_spm;
SUM(OBJECT_ID)
--------------
2911455720
Execution Plan
----------------------------------------------------------
Plan hash value: 874020942
------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 301 (1)| 00:00:04 |
| 1 | SORT AGGREGATE | | 1 | 4 | | |
| 2 | TABLE ACCESS FULL| MAC_SPM | 75535 | 295K| 301 (1)| 00:00:04 |
------------------------------------------------------------------------------
Note
-----
- SQL plan baseline "SQL_PLAN_cjd95ftv8ct90eca706bd" used for this statement
Statistics
----------------------------------------------------------
240 recursive calls
0 db block gets
1289 consistent gets
0 physical reads
0 redo size
536 bytes sent via SQL*Net to client
524 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
25 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> create index ind_objd on mac_spm(object_id);
Index created.
oradebug setmypid
oradebug tracefile_name
SQL> alter system flush shared_pool;
System altered.
alter system set events 'trace[SQL_Plan_Management] disk highest';
select sum(object_id) from mac_spm;
*** 2013-04-11 09:28:49.628
SPM: statement found in SMB
SPM: planId's of plan baseline are: 3970369213
SPM: using qksan to reproduce, cost and select accepted plan, sig = 14462506969095103776
SPM: plan reproducibility round 1 (plan outline + session OFE)
SPM: using qksan to reproduce accepted plan, planId = 3970369213
SPM: planId in plan baseline = 3970369213, planId of reproduced plan = 3970369213
SPM: best cost so far = 301.13, current accepted plan cost = 301.13
SPM: re-parse to use selected accepted plan, planId = 3970369213
SPM: statement found in SMB
SPM: re-parsing to generate selected accepted plan, planId = 3970369213
SPM: kkopmCheckSmbUpdate (enter) xscP=0x7f8e30491298, pmExCtx=0xc7463800, ciP=0xc99f7e78, dtCtx=0xbaf7c20
SQL> select /*+ index( MAC_SPM ind_objd) */ sum(object_id) from mac_spm;
SUM(OBJECT_ID)
--------------
2911455720
Execution Plan
----------------------------------------------------------
Plan hash value: 45369511
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 169 (1)| 00:00:03 |
| 1 | SORT AGGREGATE | | 1 | 4 | | |
| 2 | INDEX FULL SCAN| IND_OBJD | 75535 | 295K| 169 (1)| 00:00:03 |
-----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
168 consistent gets
168 physical reads
0 redo size
536 bytes sent via SQL*Net to client
524 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> insert into mac_spm select * from mac_spm;
75535 rows created.
SQL> commit;
Commit complete.
SQL> exec dbms_stats.gather_table_stats(user,'MAC_SPM');
PL/SQL procedure successfully completed.
SQL> alter system flush shared_pool;
System altered.
SQL> oradebug setmypid
Statement processed.
SQL> select sum(object_id) from mac_spm;
SUM(OBJECT_ID)
--------------
5822911440
SQL> oradebug tracefile_name
/s01/diag/rdbms/prodb/PRODB/trace/PRODB_ora_11126.trc
*** 2013-04-11 09:45:24.248
SPM: statement found in SMB
SPM: planId's of plan baseline are: 3970369213
SPM: using qksan to reproduce, cost and select accepted plan, sig = 14462506969095103776
SPM: plan reproducibility round 1 (plan outline + session OFE)
SPM: using qksan to reproduce accepted plan, planId = 3970369213
SPM: planId in plan baseline = 3970369213, planId of reproduced plan = 3970369213
SPM: best cost so far = 623.28, current accepted plan cost = 623.28
SPM: re-parse to use selected accepted plan, planId = 3970369213
SPM: statement found in SMB
SPM: re-parsing to generate selected accepted plan, planId = 3970369213
SPM: kkopmCheckSmbUpdate (enter) xscP=0x7f6066c949f8, pmExCtx=0xc8876e48, ciP=0xc86784c0, dtCtx=0xbaf7c20
qksan是负责SQL ANALYZE 的函数,如果看到 类似如下的信息 则说明 存在过 SQL ANALYZE
sql=/* SQL Analyze(168,0) */ select sum(object_id) from mac_spm
End parsing of cur#=4 sqlid=72ph25kpkkqhs
Semantic Analysis cur#=4 sqlid=72ph25kpkkqhs