连接Oracle Real Application Clusters
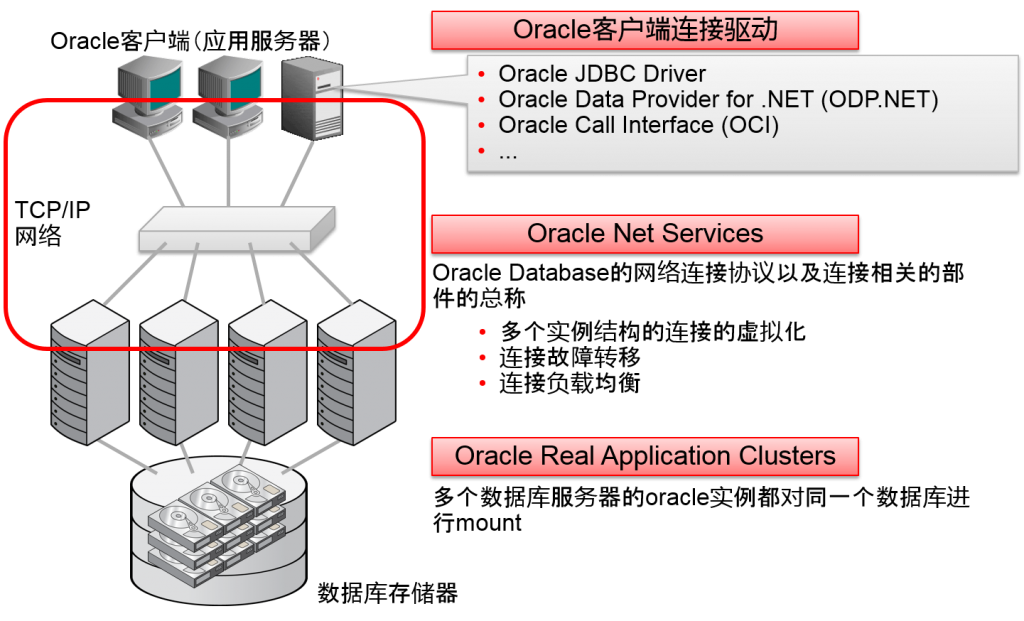
- 所有的数据库节点可以访问数据库中所有的数据
- 自动维持节点之间的数据一致性
SQL的并行执行(Parallel Execution)
- 可以自动并列化一个SQL的执行
- 从Oracle客户端开始的连接与串行处理相同
- 无论是单一实例或是RAC都是可行的
-1024x459.png)
- 安装两个软件
1.Oracle Grid Infrastructure 11g Release 2
- Oracle Clusterware 与 Oracle ASM 之间的紧密合作
- Oracle listener也是归Grid Infrastructure所有
2.Oracle Database 11g Release 2
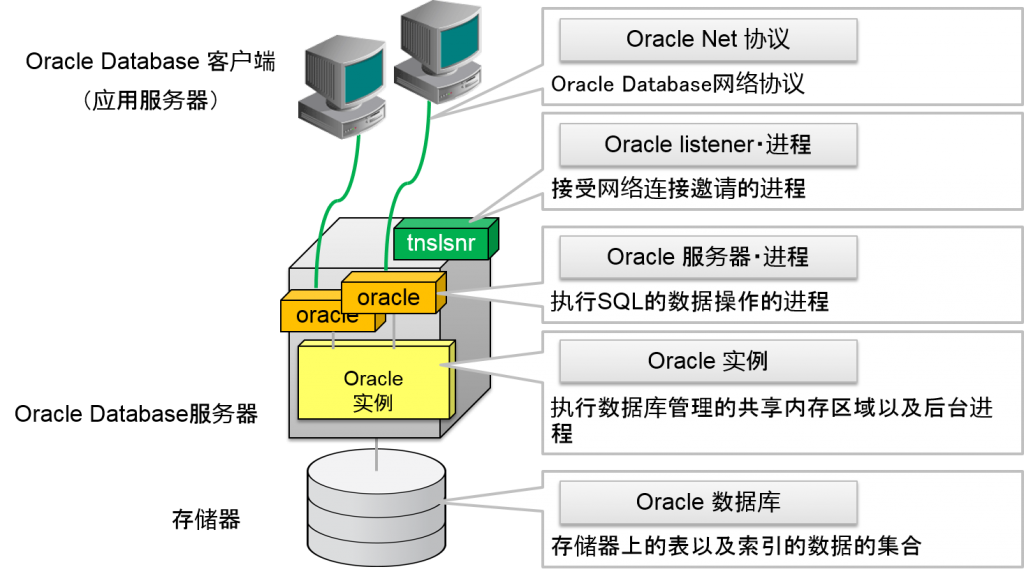
Oracle Database的网络连接
Oraclelistener・进程
这是保存TCP/IP服务器socket的进程。在Oracle Database服务器上,需要接收oracle客户端的连接需求的进程。
Oracle服务器・进程
执行SQL的数据操作的进程。
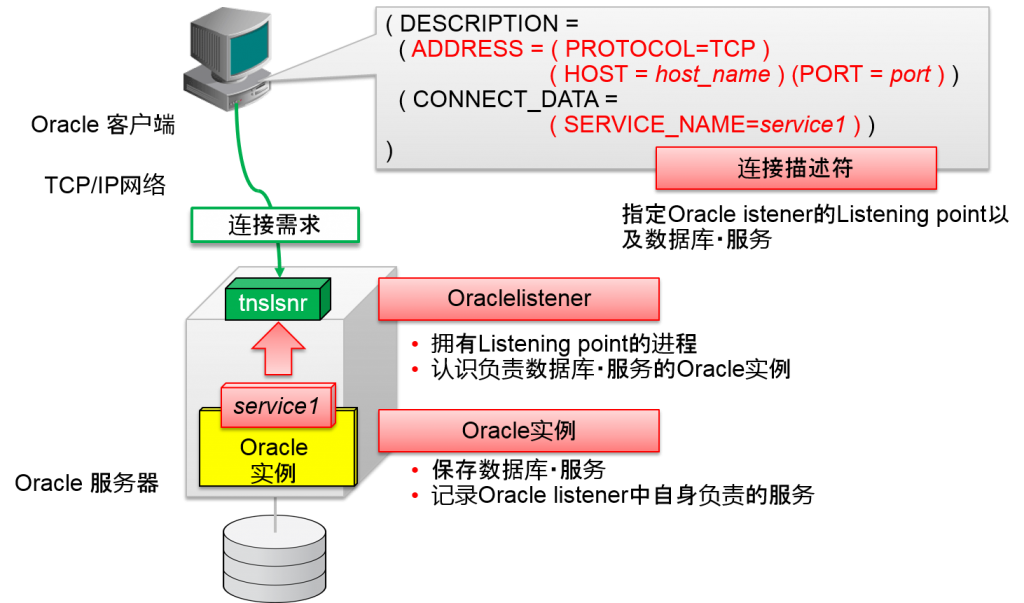
Oracle客户端的网络连接设定
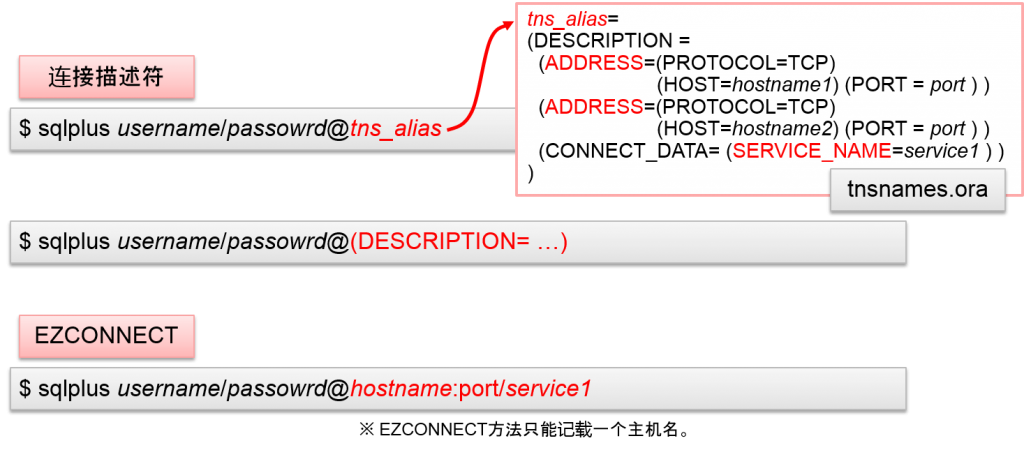
- Oracle客户端可以指定以下两个要素
- Oracle listener的网络地址 (IP地址与TCP port编号)
- 数据库・服务名
Oraclelistener进程
Oracle listener进程是接收Oracle客户端的连接需求进程。Oracle Net协议一般而言使用TCP/IP。Oracle listener进程拥有TCP服务器socket。除TCP/IP以外,同样的服务器中,还可以使用经过共享内存的连接(PROTOCOL=IPC)。
Oraclelistener・进程的实体是 $ORACLE_HOME/bin/tnslsnr 。
Oraclelistener的设定文件是$ORACLE_HOME/network/admin/listener.ora。在此会记录TCP服务器socket中使用的主机名以及port编号。Oracle客户端用连接描述符指定的主机名以及port编号是指 。Oracle listener的主机名以及port编号。
通过在1个Oraclelistener的描述符中记录多个ADDRESS语句,可以接收多个listening point的连接需求。
另外,通过设定多个Oracle listener进程,可以启动。这时,多个Oracle listener中,不能设定同样的listening point。
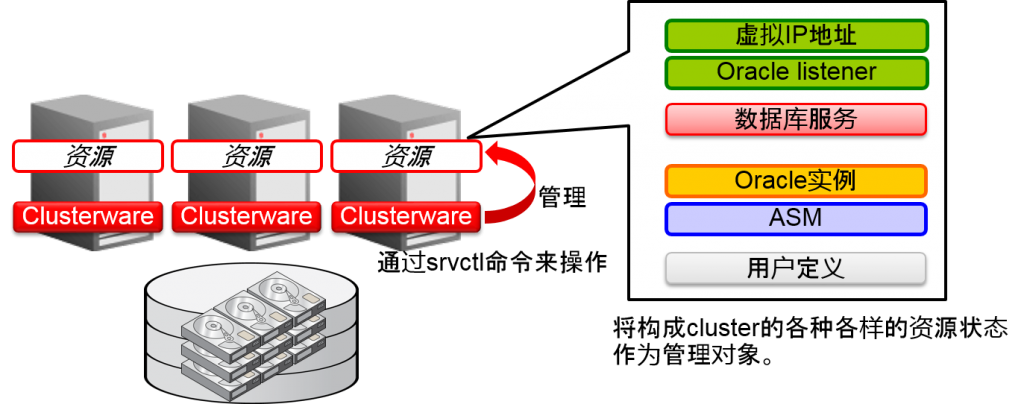
Oracle Real Application Clusters 中
Oracle Real Application Clusters 10g以后,Oracle Clusterware管理Oracle listener。因此,Oracle listener的设定是通过使用Oracle Clusterware来设定的。

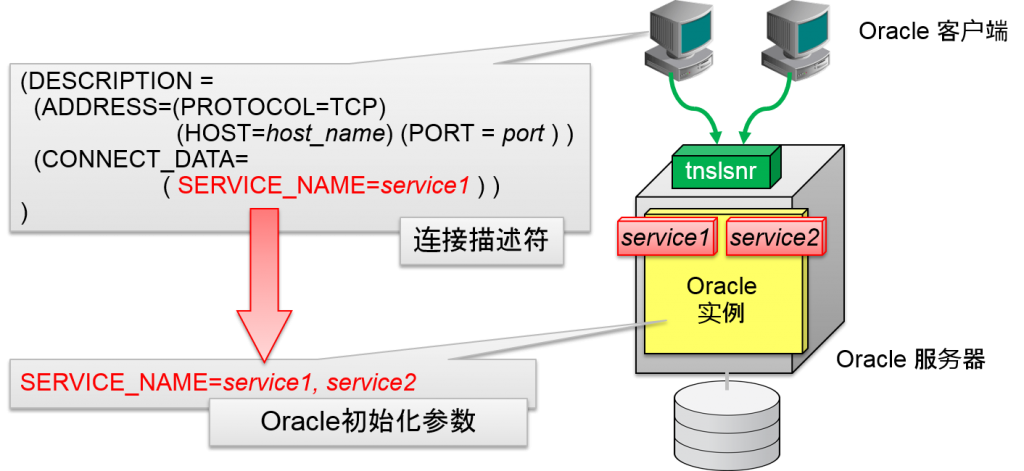
Oracle客户端指定服务名

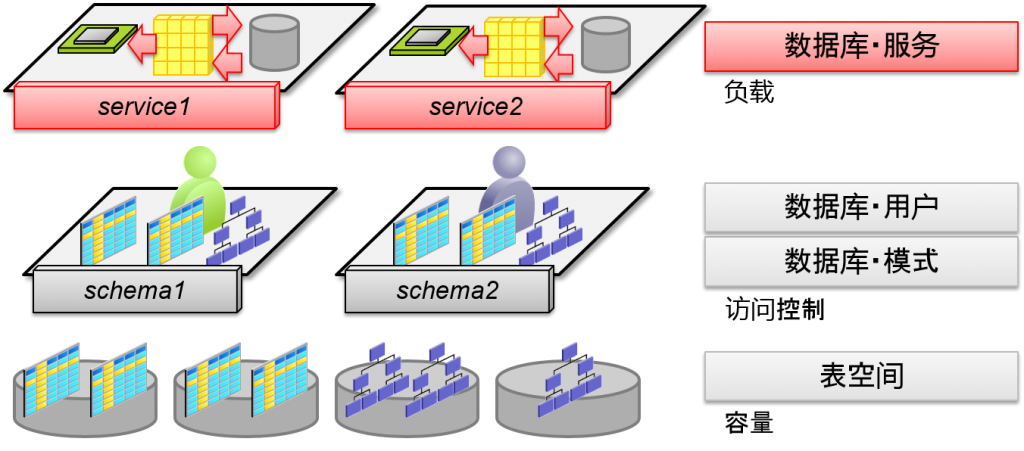
数据库・服务
- Oracle实例拥有的数据库负载理论集合
- 初始化参数SERVICE_NAMES
- 数据・字典
记录Oraclelistener的服务
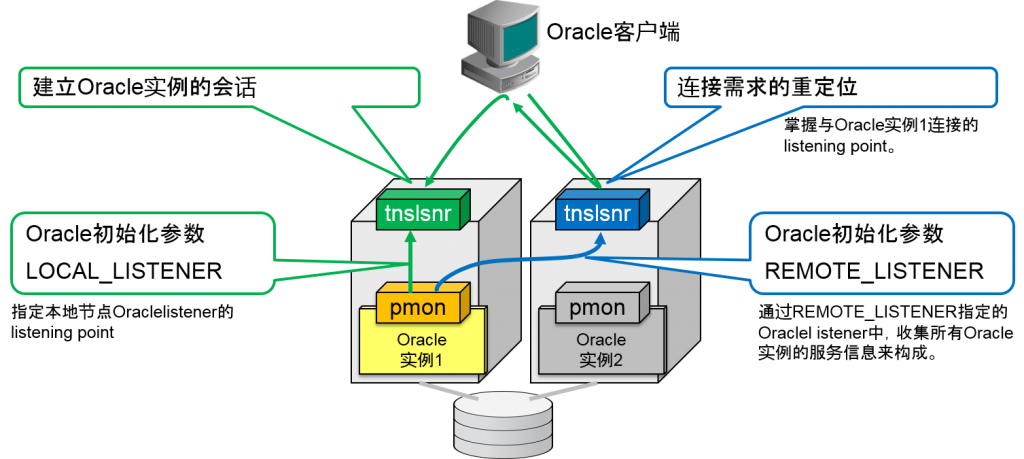
通过Oracle实例的初始化参数SERVICE_NAMES来设定的数据库、服务名会通过Oracle后台进程的PMON进程记录到Oracle listener进程中。
连接应用程序时,Oracle客户端的连接描述符中,指定记录到Oracle listener中的SERVICE_NAMES的数据库服务。
Oracle实例可以动态变更其拥有的数据库服务,这时,通过PMON进程,就可以知道Oracle listener进程中的服务结构。这被称为服务登录。
服务登录时,oracle实例设定(不是oracle listener设定)可以指定数据库服务名。Oracle listener的设定文件中虽然有静态记录服务名的方法,但由于应用连接不正常,只能作为只能管理时可以使用。
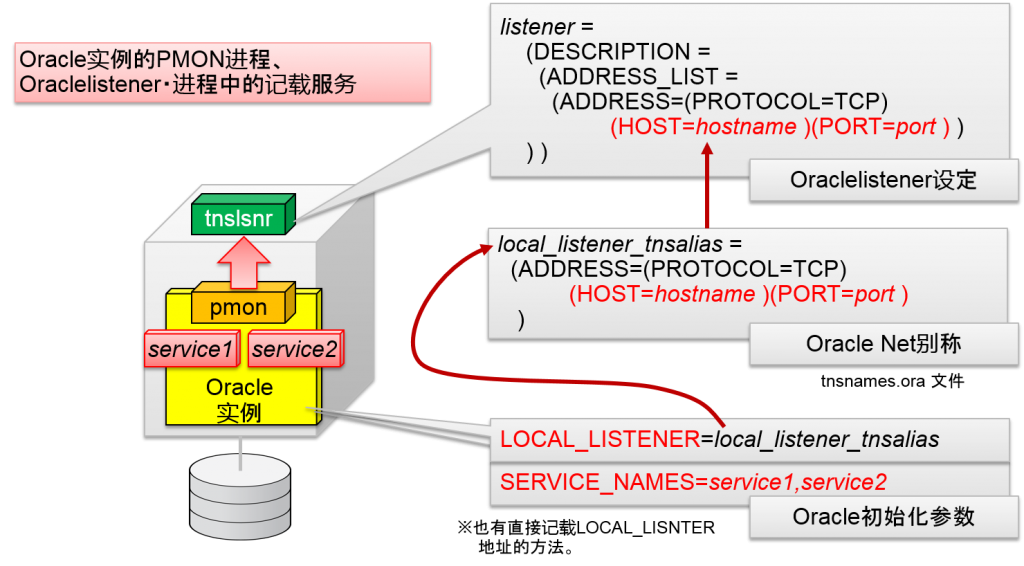
服务登录是,oracle listener的设定是通过Oracle实例的初始化参数LOCAL_LISTENER来执行。用LOCAL_LISTENER指定的网络地址是指Oracle listener进程所监听的listening point连接描述符以及同样的语句(ADDRESS=…)。使用Oracle Database服务器的tnsnames.ora文件所设定的区域也无所谓。
LOCAL_LISTENER没有被设定时的默认值为
(ADDRESS = (PROTOCOL=TCP)(HOST=hostname)(PORT=1521))
Oracle listener的默认TCP port编号为PORT=1521。
Oracle Real Application Clusters 10g以后,LOCAL_LISTENER是通过本地节点的虚拟IP地址(VIP)的listening point来构成的。
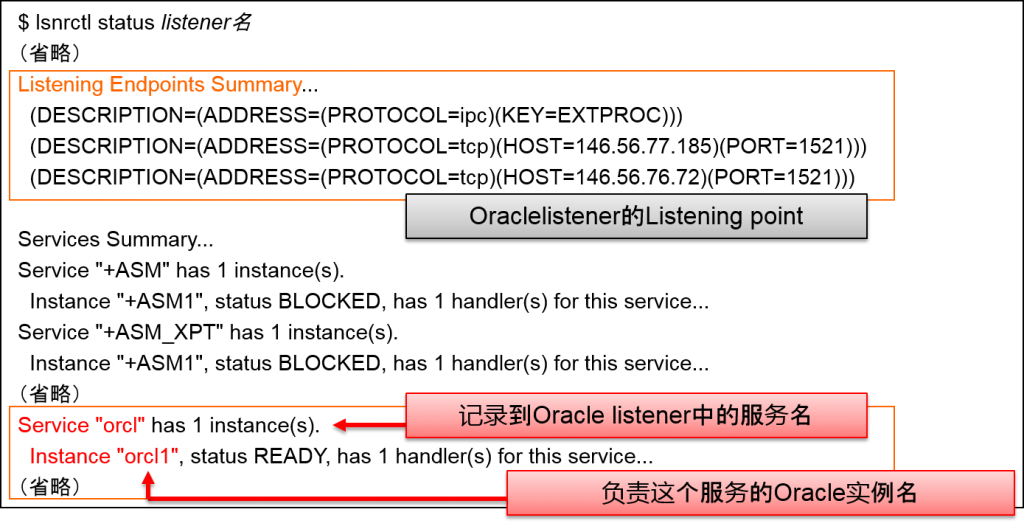
Oracle listener的操作是通过lsnrctl命令来执行的。记录到Oracle listener中的数据库服务的的状态是:用
lsnrctl status listener名
lsnrctl services listener名
来表示的。Status选项表示listening point以及运行时间等信息。Services选项表示各数据库服务的详细结构(服务处理器)。
Oraclelistener名是通过listener.ora来定义的。不指定Oracle listener名的话,就会指定名为LISTENER的Oracle listener。
启动Oracle实例的话,由于服务登录的机制,通过初始化参数SERVICE_NAMES设定的数据库服务名就会被记录到Oracle listener之中。
- ORACLE_HOME/bin/lsnrctl status listener名
- Oracle listener会展示出其中记录的所有服务。
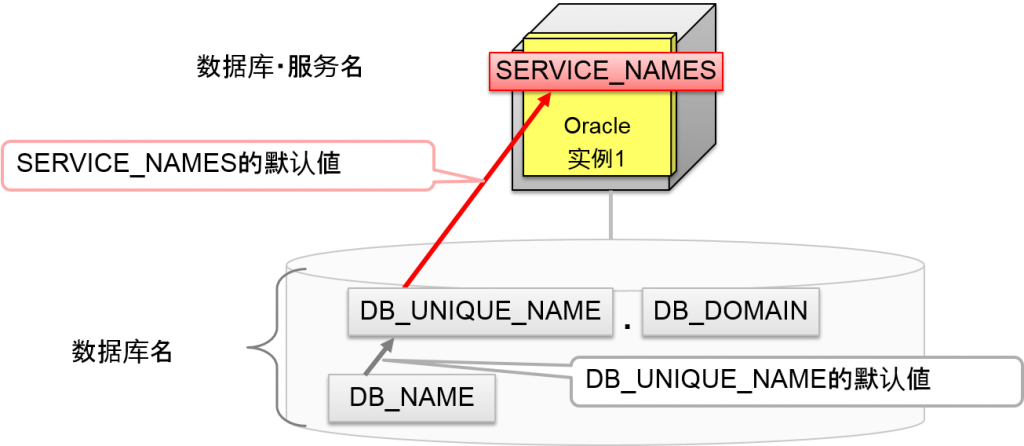
数据库・服务名的默认値
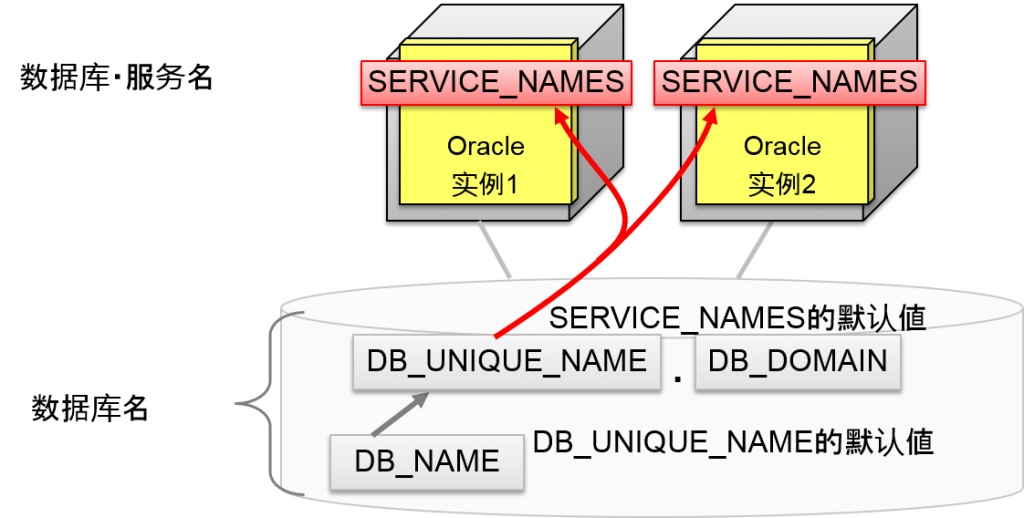
Oracle9i Database 以后,DB_UNIQUE_NAME.DB_DOMAIN就是SERVICE_NAMES 2个的默认値的组合。
DB_UNIQUE_NAME的默认値为DB_NAME,DB_DOMAIN的默认値为“无”。大多数情况下SERVICE_NAMES的默认値与DB_NAME值相同(换言之CREATE DATABASE时指定的数据库名)。
应用的连接中
Oracle实例的SERVICE_NAMES的默认値基于DB_NAME的名字。
Oracle客户端虽然可以指定这个默认的数据库服务名来连接,Oracle Database 10g以后,追加数据库服务来制成会更好。从Oracle Database 10g开始,导入了对每个服务进行资源管理的概念,还预计加入从应用中追加连接资源管理的服务。
但是,这并不是管理者直接变更oracle初始化参数SERVICE_NAMES。数据库服务的操作将在后文中说明。
Oracle初始化参数SERVICE_NAMES是Oracle8i中导入的,Oracle初始化参数DB_UNIQUE_NAME是Oracle9i Database中导入的。
Oracle8i 中,SERVICE_NAMES的默认値为DB_NAME.DB_DOMAIN。DB_DOMAIN因为大都没有被设定,SERVICE_NAMES的默认値经常与DB_NAME(=数据库名)相同。
- 默认値是基于数据库名的値
- DB_UNIQUE_NAME
- DB_NAME
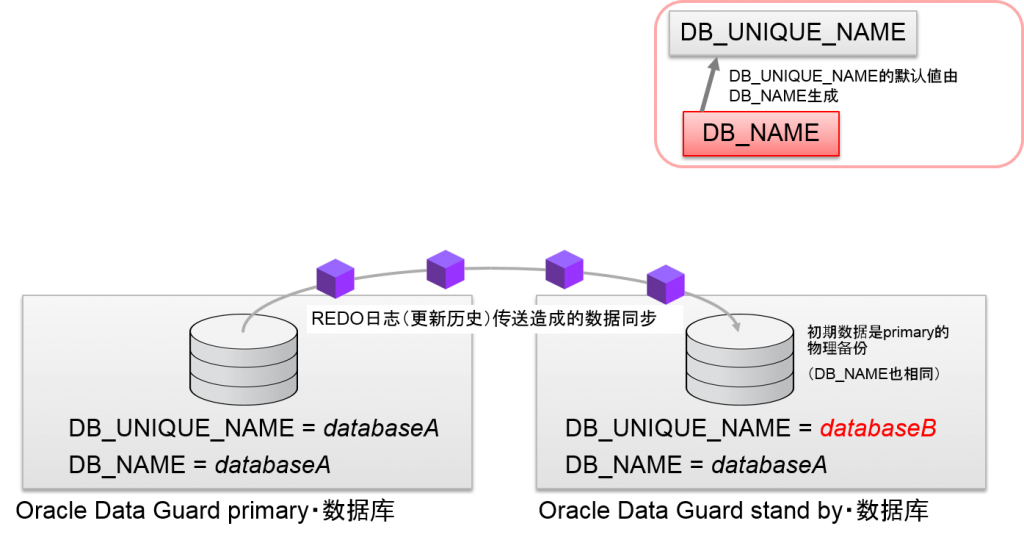
数据库名
有两个oracle初始化参数可以表示数据库名。
DB_NAME
CREATE DATABASE时所指定的名称。这是识别数据库的各种参数的基础值。
内部的可以在CREATE DATABASE时可以生成DBID这个数值。这将嵌入构成数据库的各个文件的beta中。各个文件到底属于哪个数据库可以使用这个DBID来辨别。虽然拥有同样的DB_NAME的数据库很多。
DB_UNIQUE_NAME
Oracle初始化参数DB_UNIQUE_NAME是Oracle9i中与Oracle Data Guard同时导入的。
Oracle Data Guard的physical standby结构将数据库的更新历史——REDO日志的数据传输到远程数据库中,通过在远程数据库中执行恢复来实现数据同步。远程数据库的初始数据就是(stand by数据库)primary数据库的物理备份。
stand by数据库因为将primary数据库的数据文件的备份当成初始数据,所有多个数据库的拷贝中就会拥有同样的DB_NAME(DBID)。通过应用REDO日志,即使数据内容相同,在管理操作上,也需要辨别这些数据库。因此,标识符就是Oracle初始化参数DB_UNIQUE_NAME。
通过Oracle Clusterware的srvclt命令来指定数据库名的数值不仅是DB_NAME还是这些DB_UNIQUE_NAME的値。
DB_UNIQUE_NAME的默认値为DB_NAME。因此,没有构成数据库的拷贝时,DB_UNIQUE_NAME就是变得与DB_NAME的名字相同。
- DB_UNIQUE_NAME
- 管理操作上、区别数据库的复制品的名字
- 指定srvctl 等管理命令
- DB_NAME
- CREATE DATABASE 是指定的名字
- 数据库名相关的参数基础值
在DBCA中制成数据库
- CREATE DATABASE
- 记录Oracle Grid Infrastructure 的资源
Oracle数据库名
这就是初始化参数的DB_NAME.DB_DOMAIN 。
DB_UNIQUE_NAME 的默认値是从DB_NAME制成的。
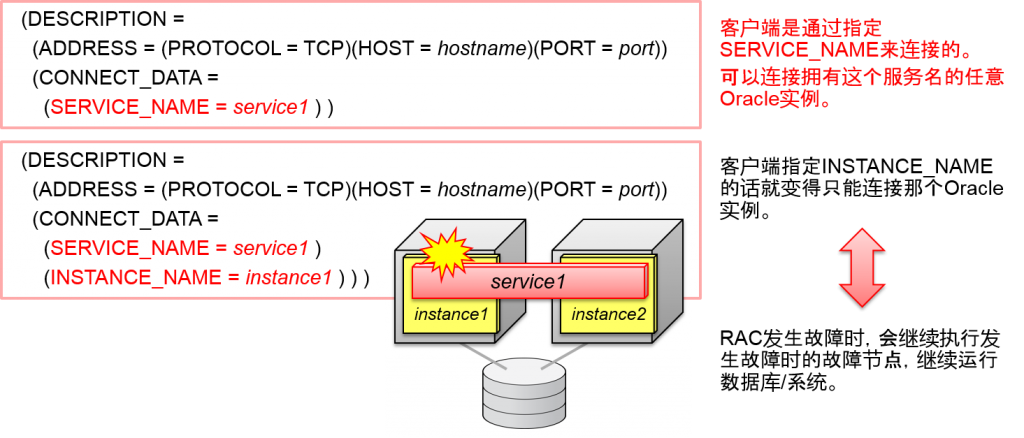
Oracle系统标识符 (Oracle实例名)
这就是SID的字头。 RAC的情况下,会构成多个oracle实例,SID1, SID2, …以及赋予编号的名字。
各个SID是各Oracle实例的初始化参数的INSTANCE_NAME的默认値。
Oracle Database 的连接
Oracle Real Application Clusters 的连接
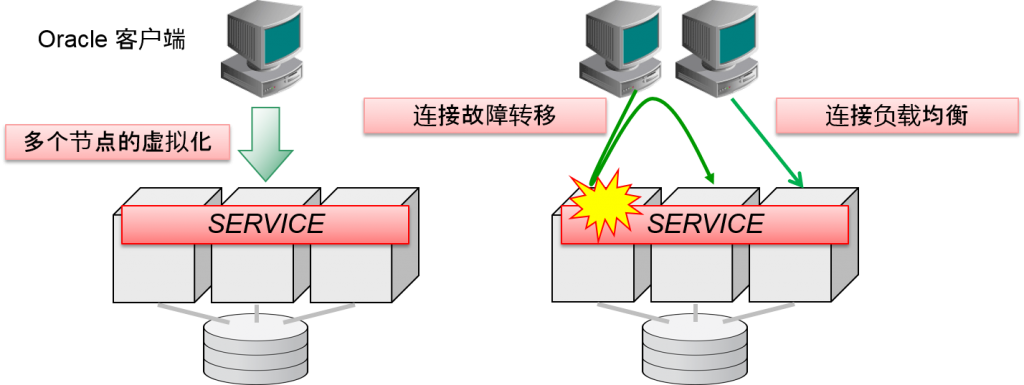
- 无论RAC连接到哪个节点,都可以访问所有数据
- 数据库/服务会将多个节点进行虚拟化
- 需要考虑连接的负载均衡以及故障时的故障转移
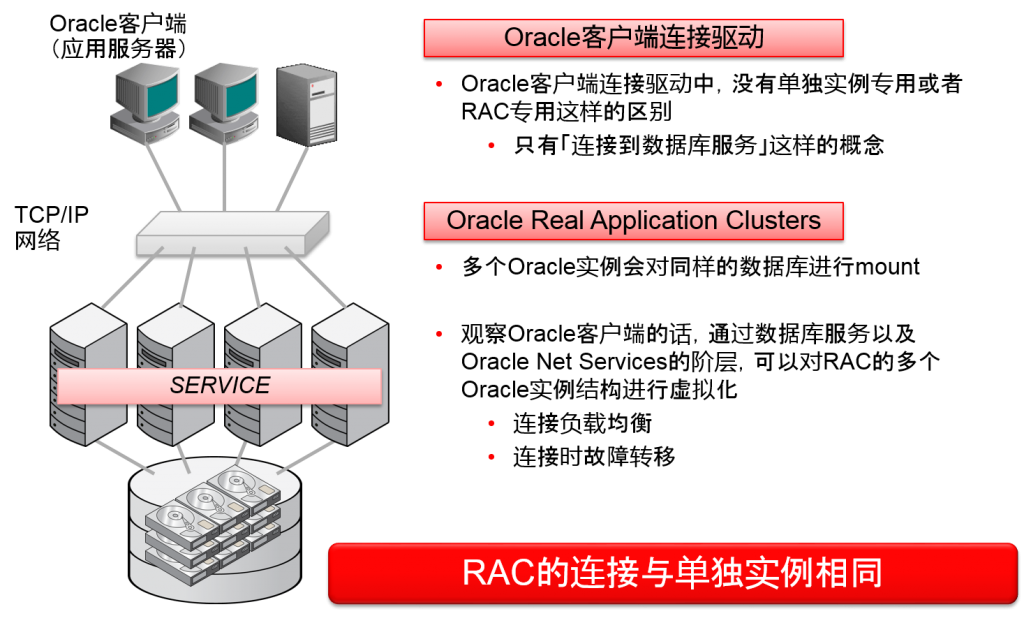
- Oracle客户端连接驱动中,用于RAC的没有区别
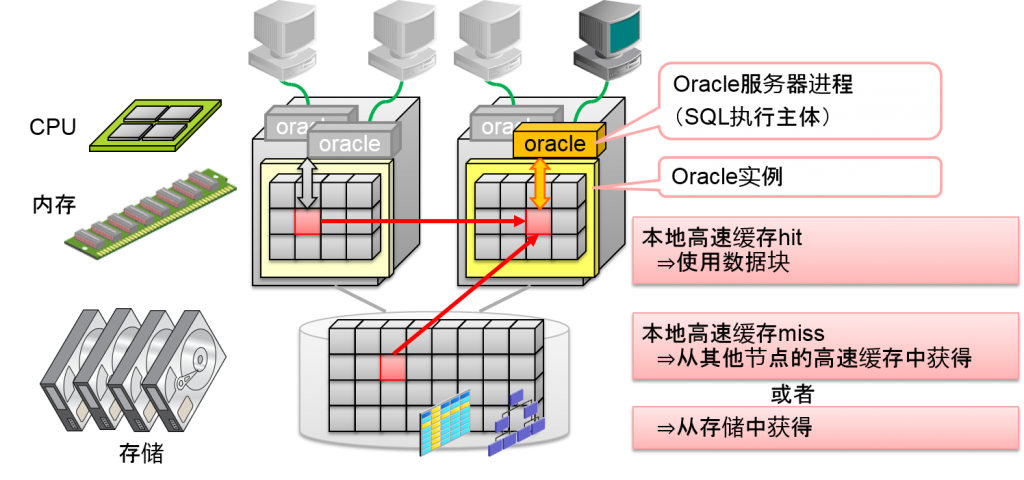
RAC因为是共享磁盘、共享高速内存的架构,无论连接到哪个节点,都可以访问所有数据。
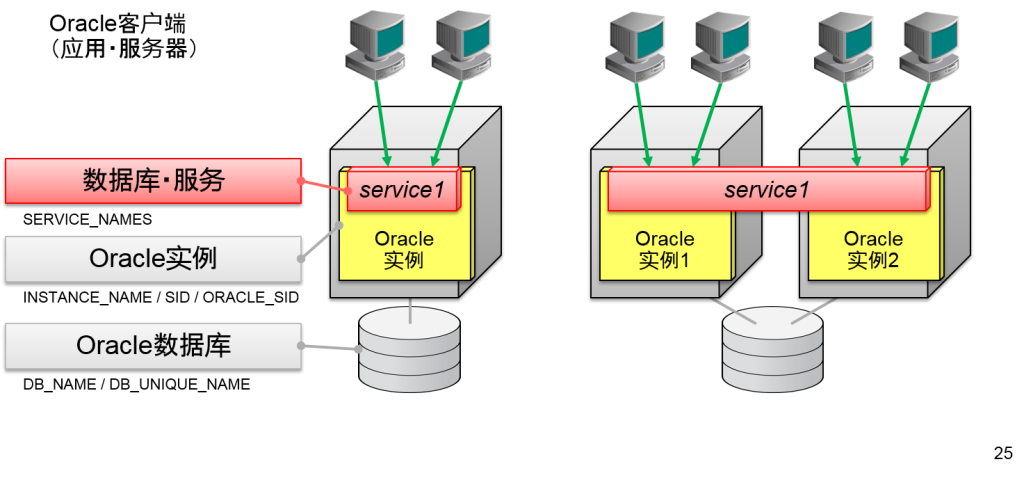
RAC因为是由多个节点构成的,oracle客户端就会作为一个数据库来访问。1个数据库中虚拟化的阶层我们成为“服务”。Oracle客户端是指定数据库服务进行连接的。这与单独实例连接的思路相同。
1个数据库服务可以由多个oracle实例来负责。因此一个数据库服务是通过多个oracle实例来分散负荷的。
另外,某些负责数据库服务的oracle实例发生故障时,其他的oracle实例负责同样的数据库服务的话,oracle客户端就会从其他正常的oracle实例中对连接进行故障转移,继续运行系统。
考虑到单个实例的连接,RAC的连接的功能就是连接的负载均衡以及故障转移。
数据库・服务
- Oracle客户端可以指定一个数据库/服务名来连接
- 单独实例也与RAC相同
- 对RAC的节点数进行虚拟化的也是数据库・服务

- 数据库・负载中理论性的群体
- 从动态性能视图中,分辨出每个服务中的CPU时间以及访问的oracle数据/块数的统计
数据库服务名的默认値
Oracle9i Database 以后,SERVICE_NAMES的默认値就是将2个初始化参数组合起来,即DB_UNIQUE_NAME.DB_DOMAIN。
DB_UNIQUE_NAME的默认値是DB_NAME,DB_DOMAIN没有默认値,所以大部分情况下,SERVICE_NAMES的默认値与DB_NAME相同(指定了CREATE DATABASE的数据名)。
应用的连接中
Oracle实例的SERVICE_NAMES的默认値就是成为DB_NAME基础的名字。
Oracle客户端在连接描述符中指定默认的数据库服务名进行连接,但Oracle Database 10g以后追加了用于应用连接的数据库服务,从Oracle Database 10g开始,导入了在每个服务中管理资源的概念,预计还会加入从应用中追加连接资源的服务。
历史来由
Oracle初始化参数SERVICE_NAMES自Oracle8i开始被导入,Oracle初始化参数DB_UNIQUE_NAME是Oracle9i Database中被导入。
Oracle8i 中SERVICE_NAMES的默认値为DB_NAME.DB_DOMAIN。DB_DOMAIN因为一般不会被设定,所以SERVICE_NAMES的默认値经常DB_NAME(=数据库名)相同。
- RAC是多个Oracle实例对同样的数据库进行mount
- SERVICE_NAMES 的默认値也是相同的
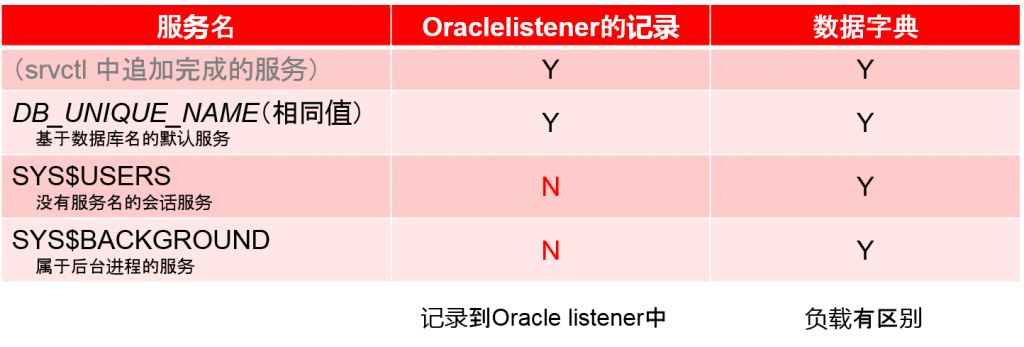
默认存在的服务
Oracle实例会将自身拥有的数据库服务记录到Oracle listener中。Oracle客户端可以指定连接描述符中的数据库服务名进行连接。
执行CREATE DATABASE时,至少存在三个服务。
作为记录到Oracle listener中的数据库服务的默认值,也有基于数据库名的DB_UNIQUE_NAME.DB_DOMAIN。另外,还有基于这个数据库名的,除这个数据库服务以外的一些数据库服务。其中还有仅仅记录到oracle listener中的以及没有记录进去到oracle listener仅仅记录到数据字典中的项目。
另外,通过PL/SQL package DBMS_SERVICE来制成的数据库服务会记录到数据字典中。Oracle Clusterware环境下,为了保持初始化参数SERVICE_NAMES以及数据字典中记录的数据库服务的一致性,要追加服务的话请使用srvctl add命令或者Oracle Enterprise Manager。
SYS$USERS
如果有不指定数据库服务连接到oracle实例的用户会话的话,这个会话所属的数据库服务名就是SYS$USERS。不指定数据库服务名的连接例子会在后文中举出:
$ sqlplus / as SYSDBA
这是Oracle服务器OS末尾进行了log in的状态,因为这是oracle中用SYSDBA特权进行log in的操作。所以这个会话会被识别为SYS$USERS。
SYS$BACKGROUND
Oracle实例会保持几个后台进程,使用CPU来执行内部处理。识别这些后台进程负载的就是名为SYS$BACKGROUND的数据库服务。
- 辨别每个服务中负载的区别
- V$SERVICE_STATS 等
- 与记录到Oracle listener中的服务不同,还有一些内部的服务
- 数据・字典上也有区別
RAC数据库服务的结构
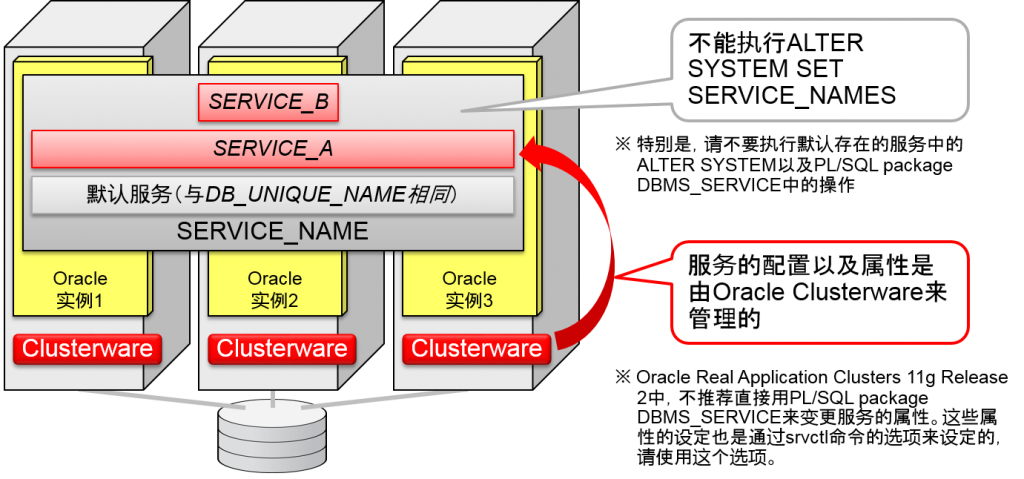
- 在Oracle Clusterware的管理之下
- 想变更服务的属性时,请在已追加的服务中进行
- 通过Srvctl命令或者Oracle Enterprise Manager来进行操作
Oracle客户端开始的连接
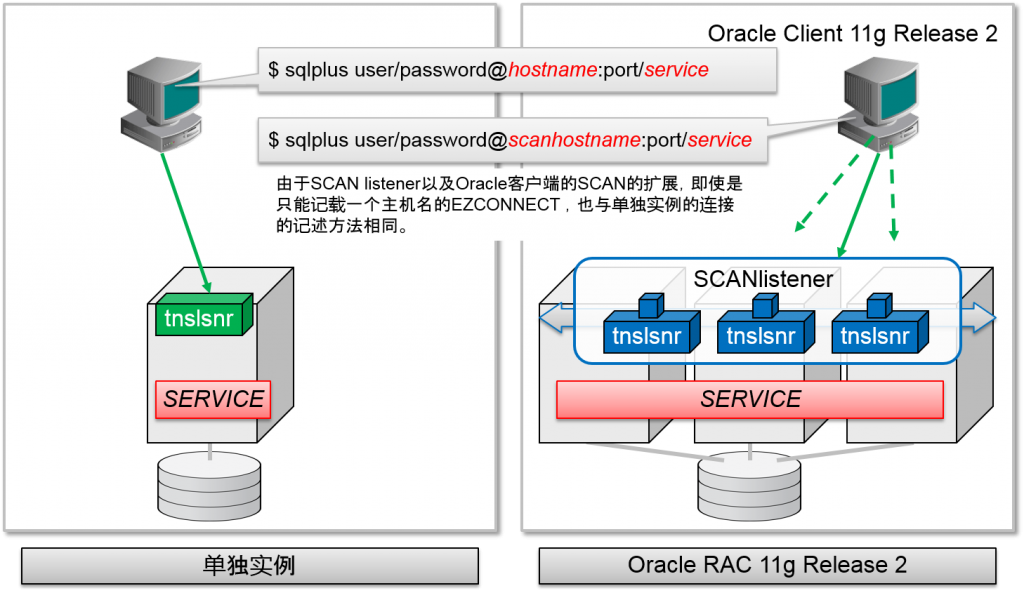
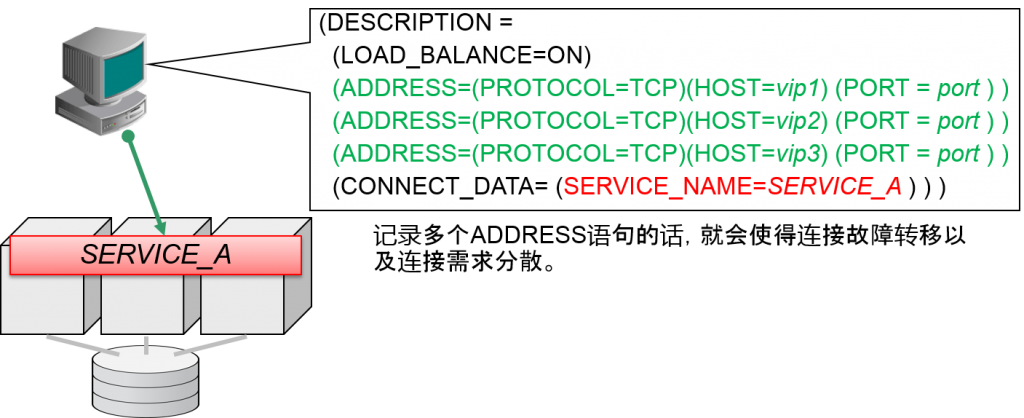
即使是连接到RAC,oracle客户端指定的也是Oracle listener的主机名、port编号以及服务名。这与单个实例相同。
slide的例的连接描述符中ADDRESS句语句值记录了一个节点。但是RAC服务器中的连接如果全部正常运行的话,就业可以进行所有节点的负荷分散。
考虑到RAC的高可用性的方法将在后面讲述。
- 连接到RAC的描述符基本上与连接到单独实例的连接相同
- 指定Oracle listener的主机名以及port编号
- 数据库服务名指定
- 连接的故障转移
- Oracle listener的连接需求如果失败的话就会自动转移到其他的Oracle listener中
- 连接时的故障转移
- 决定连接地址Oracle的实例
- 多个Oracle实例可以负责同样的服务
- 1个连接会连接到一个oracle实例中
- 连接负载平衡
- Oracle Net中实际应用了两种连接故障转移功能
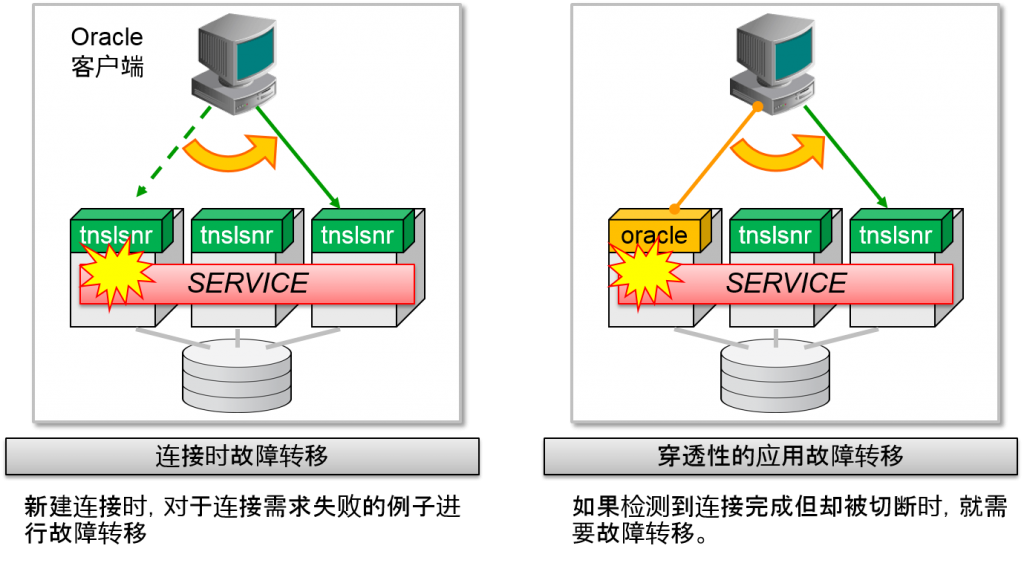
- 连接时的故障转移
- Connect-Time Failover (CTF)
- 新建连接时,对于连接需求失败的例子进行故障转移
- 考虑到高可用性时,需要实际安装的功能
- 穿透性的应用故障转移
- Transparent Application Failover (TAF)
- Oracle Call Interface(OCI) 客户端的機能
- 对于建立完成的连接中检测到切断时进行故障转移
- 不是必要的功能
- 并不是重新执行一次更新事务
连接时故障转移
Oracle客户端生成新的连接时,通过连接描述符的客户端側连接负载均衡的设定(LOAD_BALANCE),可以对ADDRESS句的对立发出连接需求。这个ADDRESS 连接需求成功时就会使用这个连接。
如果这个ADDRESS连接失败,但成功设定了连接故障转移的话,就不会即时返回错误到客户端、应用中。检测到内部连接失败的话,就会直接对其他的ADDRESS发出连接需求。所有的连接地址候补都失败的话,就会将错误返回oracle客户端。
连接描述符的DESCRIPTION语句默认是FAILOVER=ON 。因此,对于多个ADDRESS语句,即使不明确设定FAILOVER=ON,连接时的故障转移也会有效。另外,几乎不会使用DESCRIPTION_LIST语句以及ADDRESS_LIST语句,但默认是FAILOVER=ON。
RAC无论连接到哪个oracle实例都会访问同样的数据。因此,即使oracle实例中发生了故障,oracle客户端只要能连接其他正常的oracle实例的话,系统就能继续运行。为了活用这种高可用性的架构,需要将连接故障转移设为有效。
- 新建连接时,对于连接需求失败的例子进行故障转移
- 连接描述符的设定:FAILOVER=ON (默认ON)
- 连接需求失败的话,就会试行其他ADDRESS语句
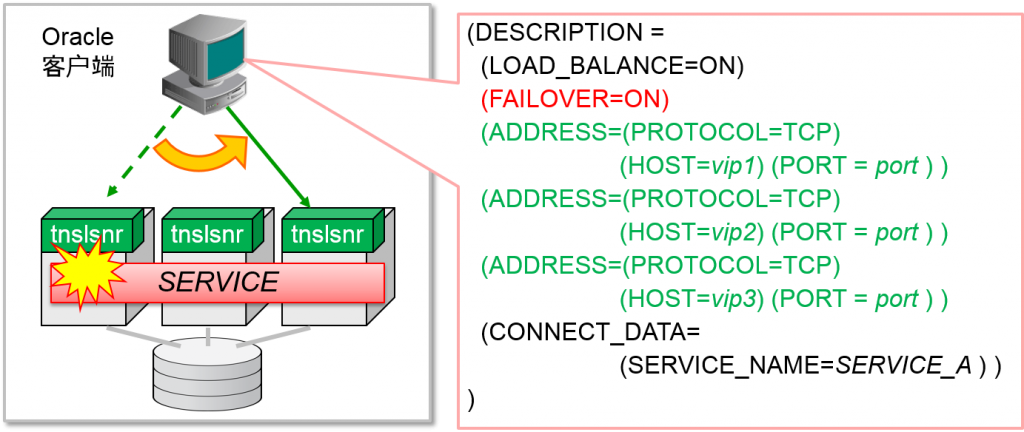
- Oracle客户端在服务中进行连接
- 多个Oracle实例可以拥有一样的服务名(SERVICE_NAME)
- Oracle实例名(INSTANCE_NAME)可以在RAC中指定
连接负载均衡
Oracle客户端生成新的连接时,RAC中会有很多个可以成为连接地址候补的oracle实例。决定连接具体是要连接到哪个oracle实例的连接负载均衡是由两部分构成的。
在设定上也可以设为二者都不使用。
客户端側连接负载均衡
Oracle客户端的连接描述符中,会记录发出连接需求的Oracle listener的网络地址。其中可以记录多个Oracle listener的网络地址。
客户端连接负载均衡对于这些Oracle listener的候补会分散发出连接需求的地址。
服务器側连接负载均衡
服务器连接负载均衡
Oracle listener中会记录构成RAC的oracle实例服务结构。记录的不止是服务的设定,还记录了负荷信息,并且会自动更新。
Oracle listener如果接受Oracle客户端的连接需求的话,请对那个服务进行测试,判断是否需要分散负荷,重新定位到适合的节点中。因此,即使制成了客户端连接负荷均衡,实际上决定连接地址的还是服务器连接负载均衡。
- 在建立新连接时,决定连接实例时,会经过2阶段的连接负载均
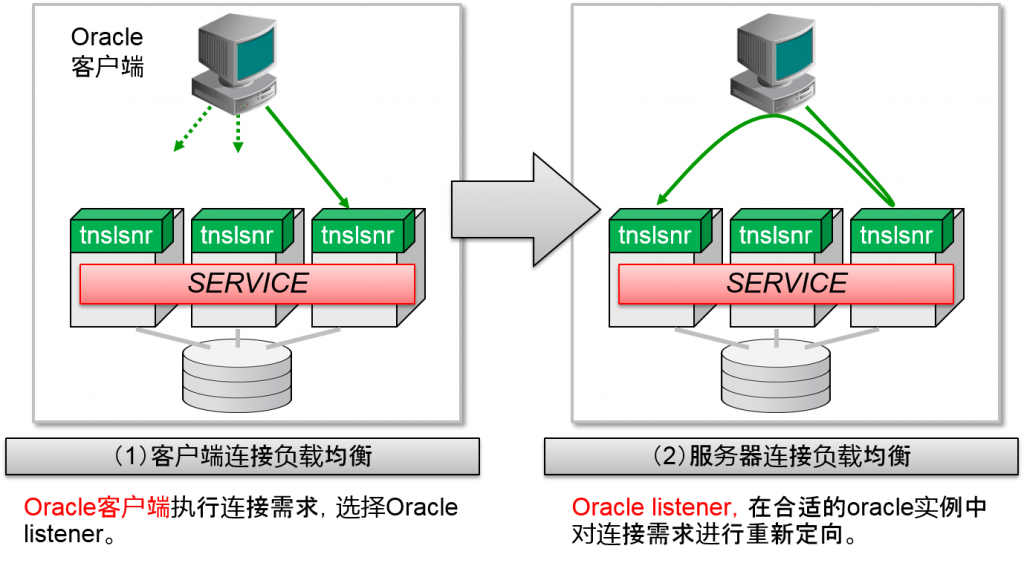
连接负载均衡
决定Oracle客户端到底连接到哪个oracle实例的连接负载均衡是由两个部分构成的。
客户端连接负载均衡
Oracle客户端的连接描述符张记载着Oracle listener的主机名以及IP地址。其中还可以记载多个Oracle listener的网络地址。
客户端连接负载均衡将分散多个Oracle listener的候补所执行的连接需求。
服务器连接负载均衡
Oracle listener中会记录构成RAC的oracle实例服务结构。记录的不止是服务的设定,还记录了负荷信息,并且会自动更新。
Oracle listener如果接受Oracle客户端的连接需求的话,请对那个服务进行测试,判断是否需要分散负荷,重新定位到适合的节点中。因此,即使制成了客户端连接负荷均衡,实际上决定连接地址的还是服务器连接负载均衡。
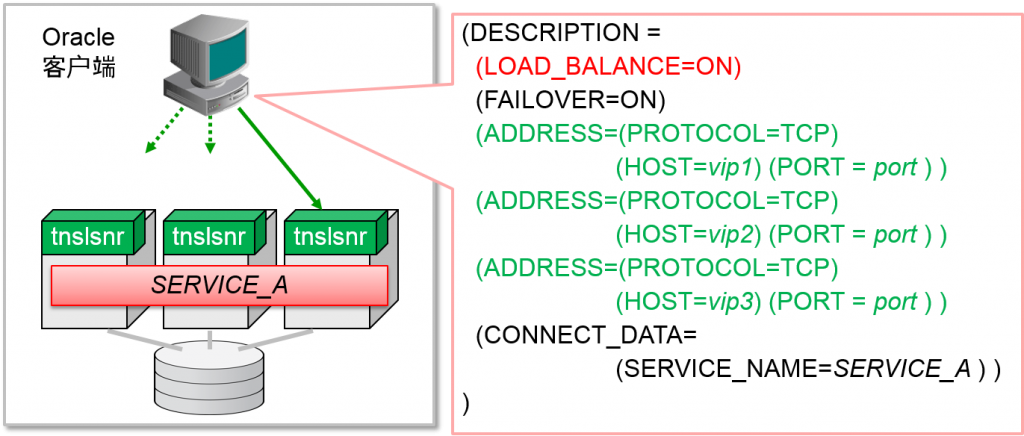
- Oracle客户端使得发生连接需求的Oracle listener分散
- 连接描述符的设定:LOAD_BALANCE=ON
- 从多个ADDRESS语句中随机选择
服务与Oracle实例
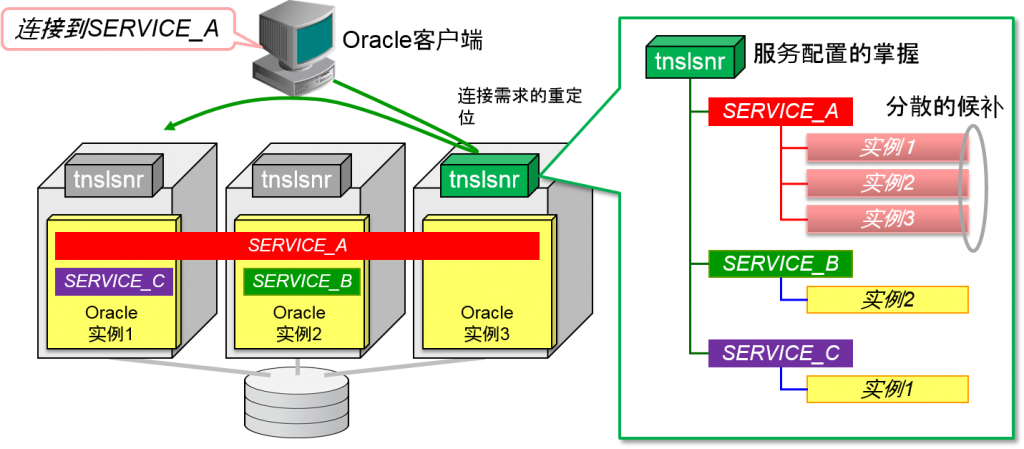
Oracle客户端制定服务名,对Oracle listener发出连接需求。
RAC可以设定为由每个oracle实例各自负责。Oracle listener掌握了cluster整体的服务结构。Oracle listener会对负责oracle客户端指定的oracle实例来对oracle客户端进行重新定位。
实际连接到Oracle客户端的是负责对应服务的oracle实例。多个oracle实例负责1个服务时,会通过多个oracle实例来分散负荷。这时,1个oracle会话连接的就是1个oracle实例。
- Oracle listener认识到实际上是由多个oracle实例负责同样的数据库/服务。
- 默认的分配方法是“会话数量均分化”
- 服务的属性:CLB_GOAL=LONG
- 默认的分配方法是“会话数量均分化”
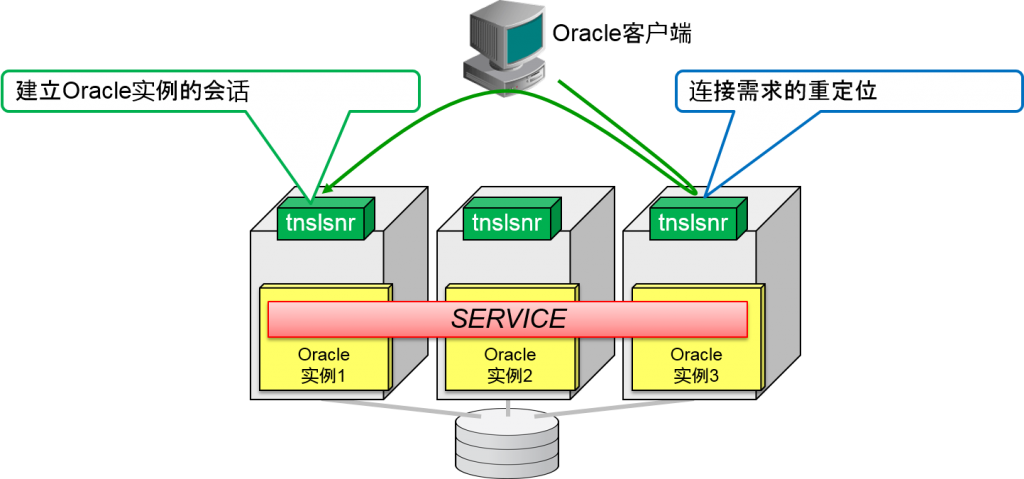
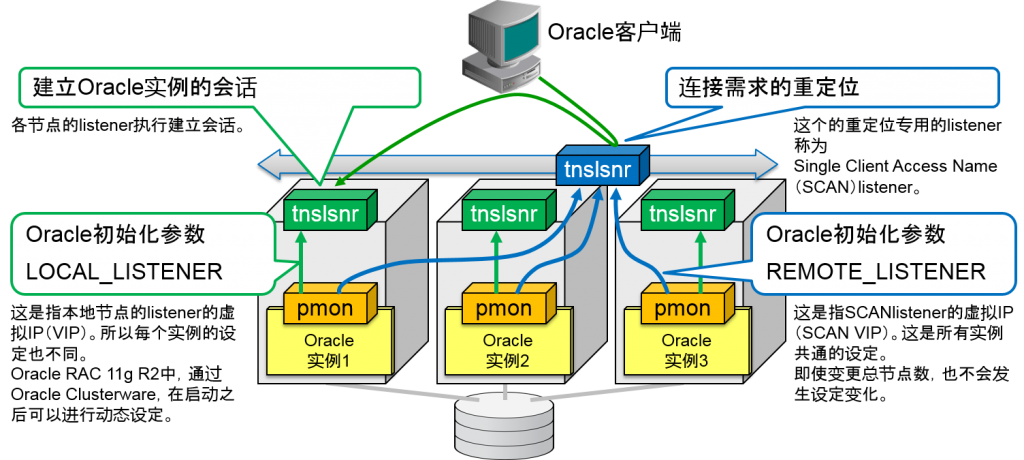
- Oracle listener的两个作用
1.连接需求的重定位
2.建立Oracle实例的会话
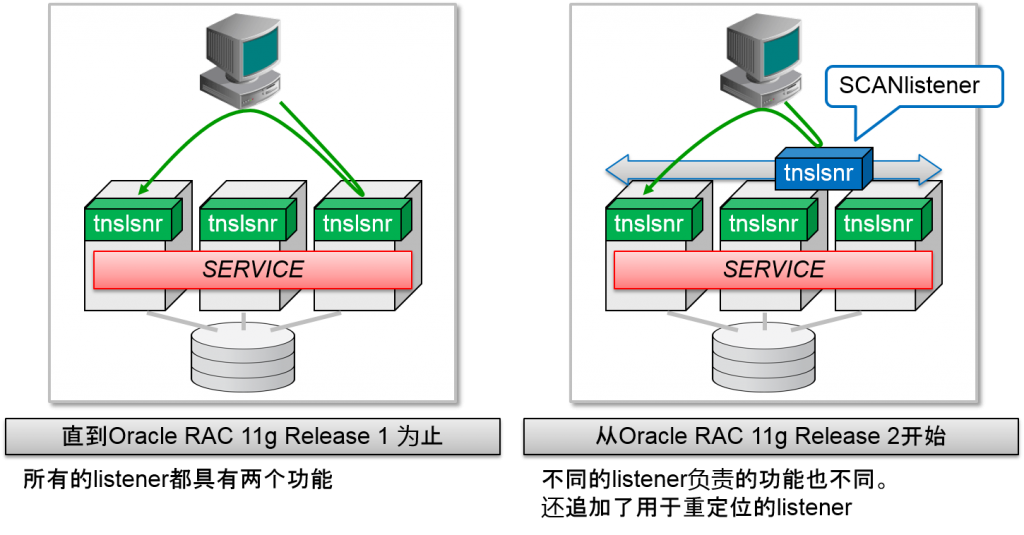
Single Client Access Namelistener
- 将用于重定位的Oraclelistener(SCANlistener)从oracle实例中记录到服务中
- 分为「重定位」以及「建立会话」的功能
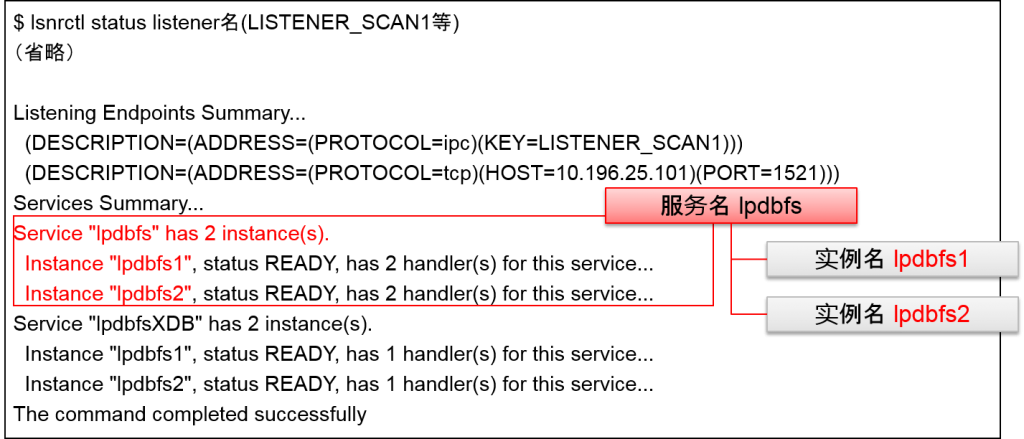
- 在SCAN listener运行的节点中
- ORACLE_HOME/bin/lsnrctl status listener名
※ 从Oracle Grid Infrastructure 11g Release 2开始,Oraclelistener使用Oracle Grid Infrastructure中的项目。此例中,ORACLE_HOME指Oracle Grid Infrastructure的安装目录。
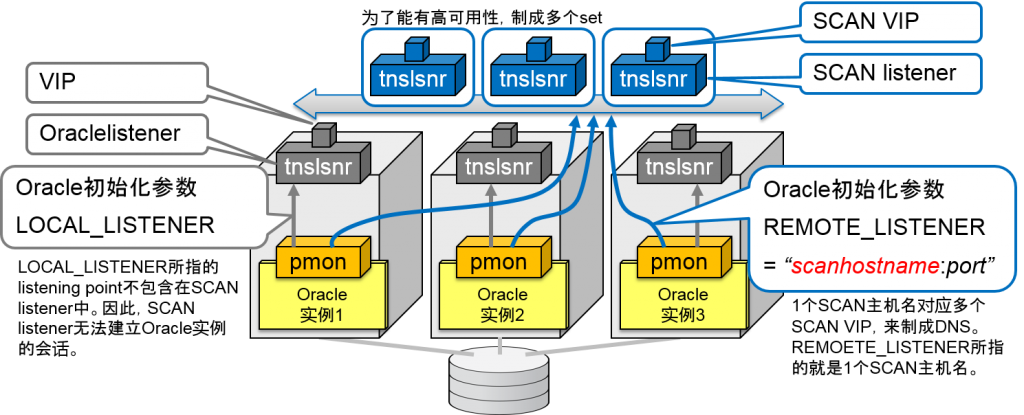
- SCAN listener以及SCAN虚拟IP地址(SCAN VIP)同时启动
- SCAN listener的运行节点中发生故障的话,就会在其他节点中通过SCAN VIP以及set来重启
- 通过DNS使得1个SCAN主机名对应多个SCAN VIP
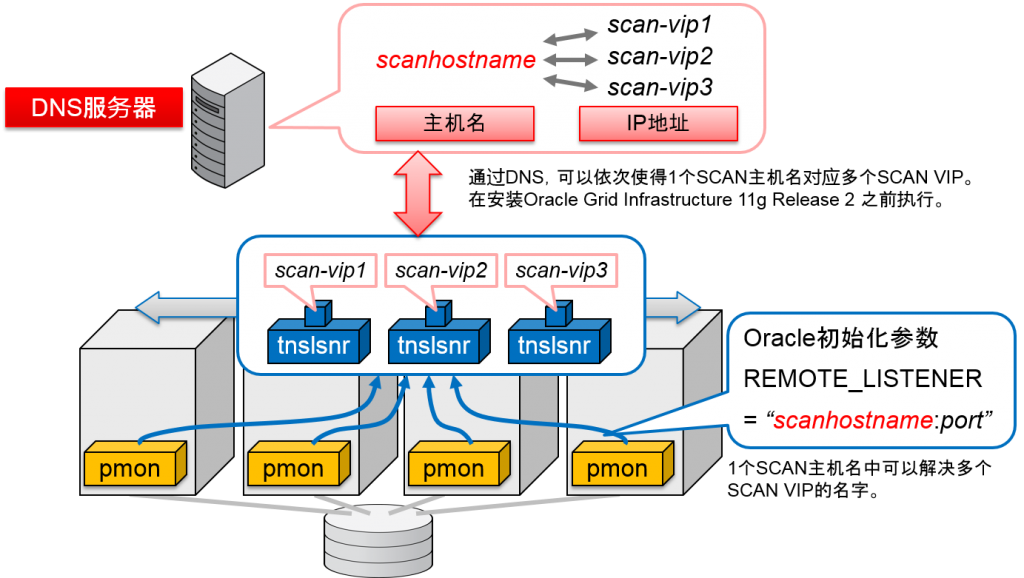
- 从Oracle Client 11g Release 2 开始,1个SCAN主机名会在内部的多个SCAN VIP中展开

Oracle Client 11g R2 以前的客户端
Oracle Client 11g R2会使得1个SCAN主机名在内部的多个SCAN IP地址中展开。
但是,即使是没有SCAN扩展的Oracle Client 11g R1之前的客户端,也可以发起连接到RAC 11g R2的SCANlistener连接需求。通过使用Oracle Client 11g R1之前的连接描述符的记录方法来记录多个ADDRESS语句,可以构成客户端中的连接均衡与连接故障转移。这时记载连接描述符的ADDRESS句的并不是SCAN主机,而是SCAN虚拟IP地址(SCAN VIP)。
连接描述符中记录多个SCAN VIP是为了提高可用性。如果在SCAN listener中执行连接需求的话,就可以通过连接的确立地址来决定连接负载均衡来决定。
- 通过SCAN连接到没有扩展过的以前发行过的SCAN listener中时,会列举SCAN VIP

Oracle Real Application Clusters 的连接