OraGlance是免费的,你可以安心使用它。
OraGlance is free software , use it as you like.
下载地址URL:https://zcdn.askmac.cn/OraGlance2103.zip
2021-03-04: 现在可以 针对任意SQL_ID查看SQL Detail了
OraGlance的目标
- 完全免费
- 一键即运行的图形化Oracle数据库性能监控软件
- 无需安装、部署,不占用服务器资源
- 支持从Oracle 11.2.0.1开始的所有版本
- 支持Oracle RAC
- 非植入式,对Oracle只读,不在数据库内创建任何对象
- 资源占用极低,内存使用在50MB左右,CPU占用率极低
- 可回溯历史性能数据,可以观察到过往时间的性能问题
- 提供SQL历史运行情况历史
- 提供SQL优化接口
- 无需外网访问权限,纯本地程序,不上传任何数据到任何服务器
产品比较
| OraGlance | Enterprise Manager | 其他第三方监控软件 | |
| 价格 | 完全免费 | 费用包含在db license中 | 基于license或订阅收费 |
| 性能指标 | 追求精简 | 12c以后的express版精简,12c以前较为全面 | 追求全面 |
| 性能负载 | 极低,内存小于50MB,cpu在1%左右 | 基于java,内存和cpu使用略高 | B/S架构情况下普遍负载略高 |
| 响应速度 | 极快 | 正常情况下较快 | 正常情况下较快 |
| 部署情况 | 无需部署,一键使用 | 需要少量部署维护 | 一般需要单独部署 |
| 是否需要AGENT | 完全不需要 | cloud control需要安装agent | 可能需要 |
| 是否在库内创建对象和写数据 | 完全不创建 | 原生存在部分对象,例如sysman | 大部分需要 |
| 是否最小权限 | 只需要几个视图的查询权限 | 需要比较高的权限 | 可能需要读写权限 |
| 是否往需要访问外网 | 完全不需要 | 常规使用下完全不需要 | 可能需要访问外网获得完整功能 |
| 是否可以回溯监控历史 | 可以 | 部分可以 | 可能可以 |
| 当数据库hang时是否能监控 | 只要连接未被中断,除非极端情况,否则一直可监控性能;例如AWR快照已经无法写入的情况,则仍可以收集到丢失的AWR数据 | 可能完全卡死 | 可能完全卡死 |
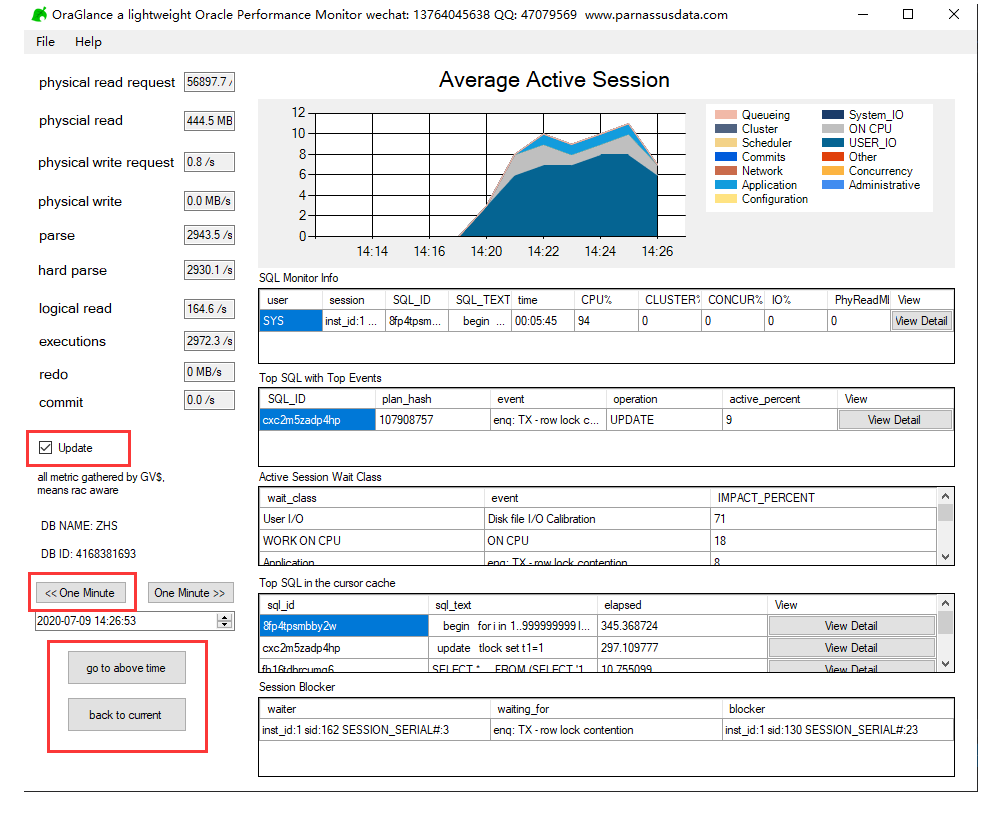
OraGlance的使用技巧
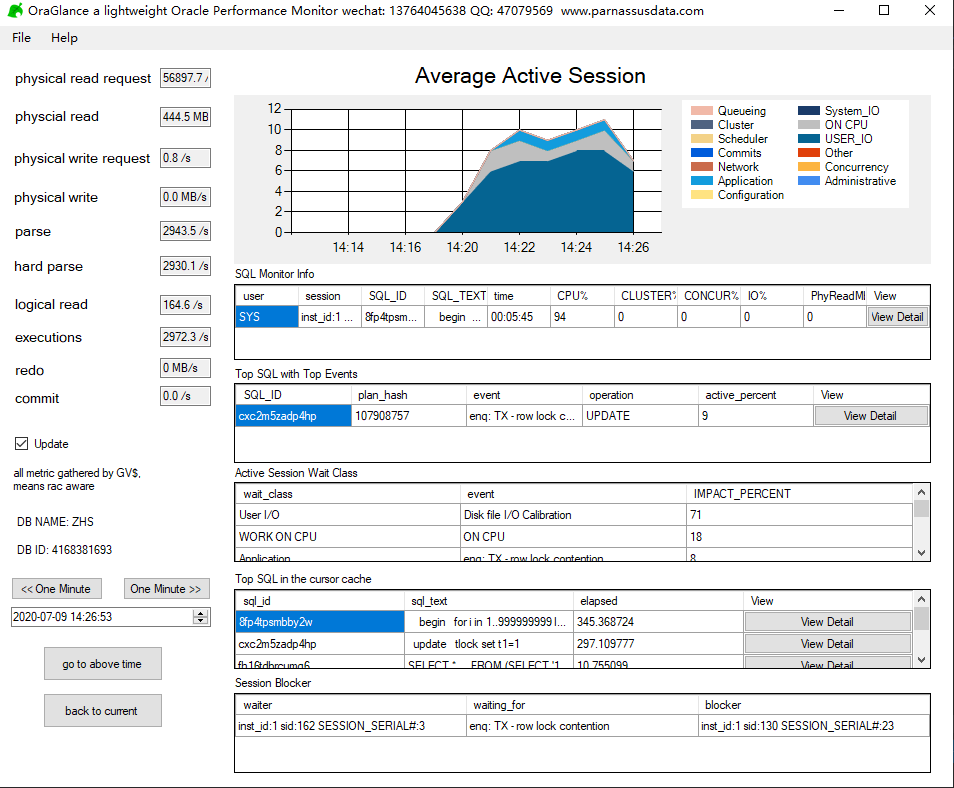
- 主面板每10秒钟自动刷新一次,可以通过左侧面板的Update够选项,临时关闭面板刷新;关闭面板刷新后仍会每10秒钟更新后台数据
- “<< ONE Minute”按钮可以让主面板数据回溯到之前的时间,回溯后主面板将停止更新,直到使用”backup to current”回到当前时间
- 可以在左侧时间栏中指定时间,并按下”go to above time”按钮来回溯到过去某个时间点;如果对应时间点不可用则会报错
- 支持托盘运行,可以监控桌面上后台运行,不打扰用户
- 例如18:00用户反应出现大量应用程序等待,则可以回溯到该时间点来观察TOP SQL和阻塞情况。
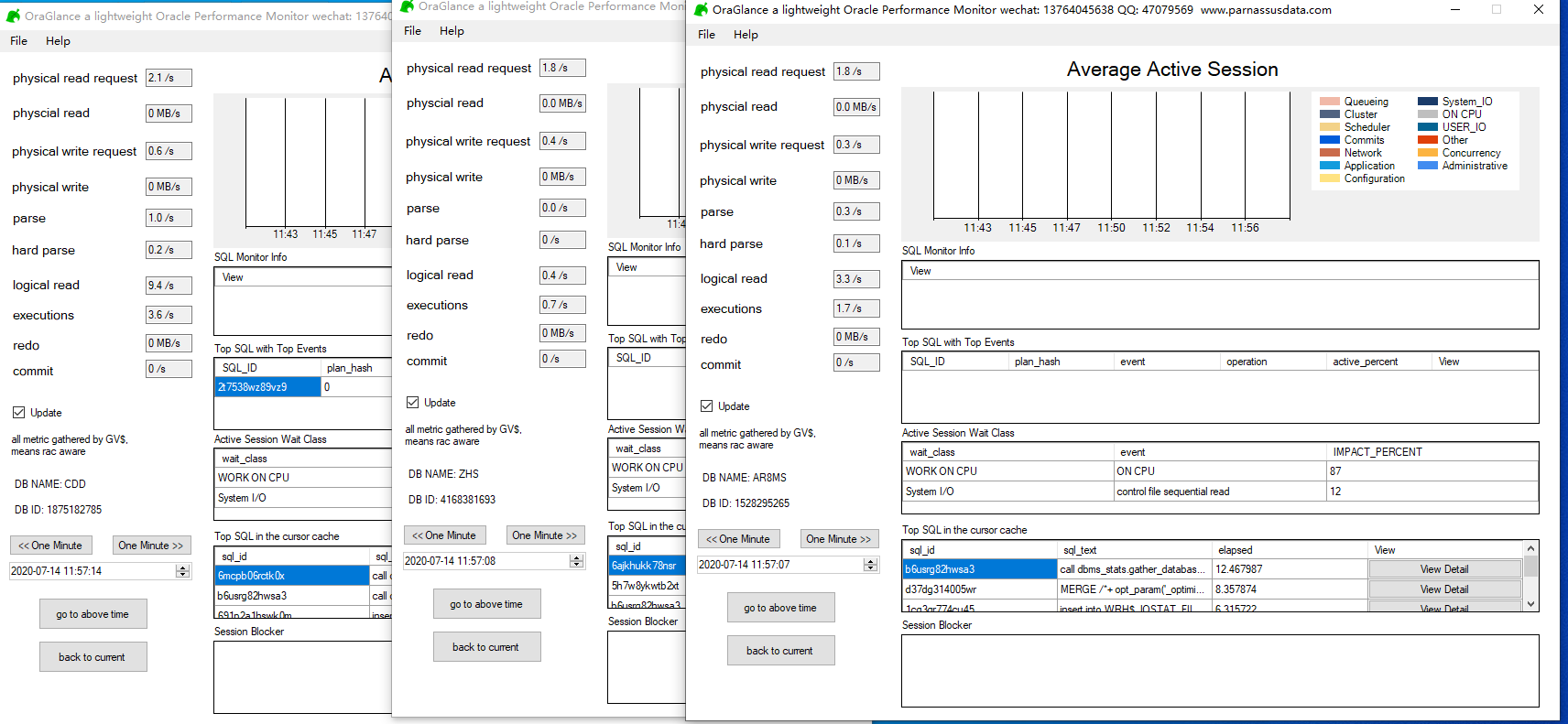
同时支持多开程序,可以在同一台pc上多开监控多个数据库:
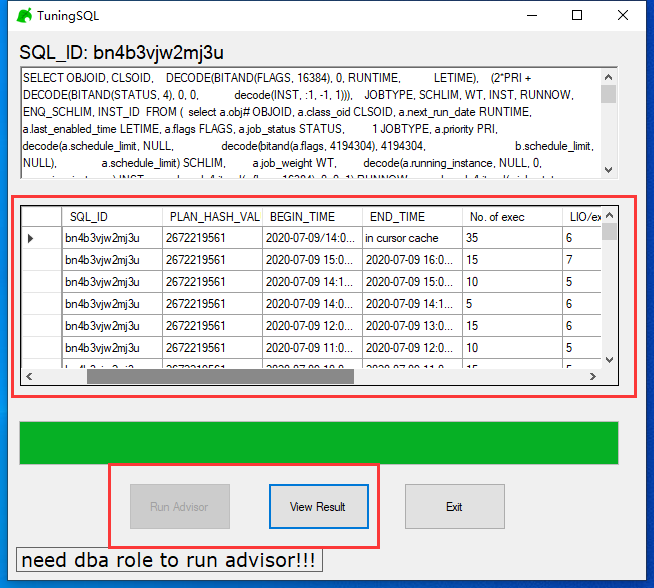
SQL优化接口
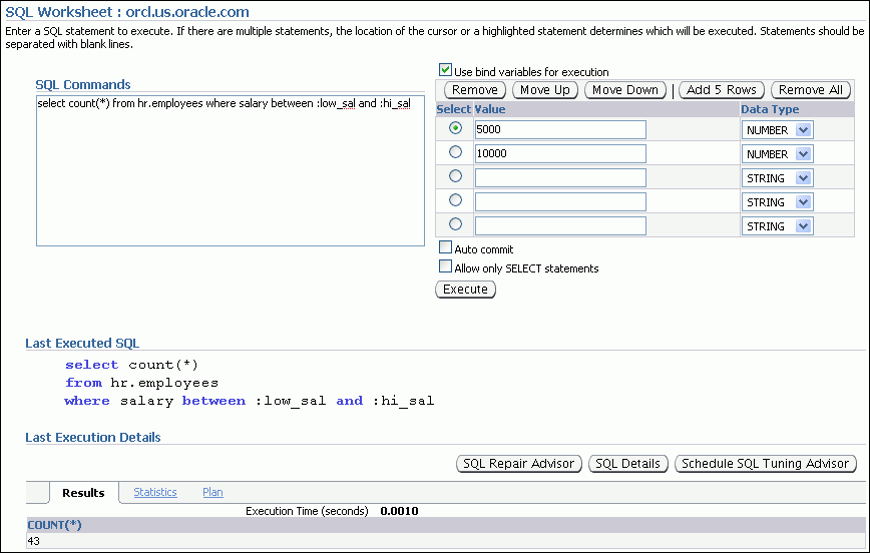
- 在主面板上点击View Detail按钮,可以进入对应SQL的优化界面
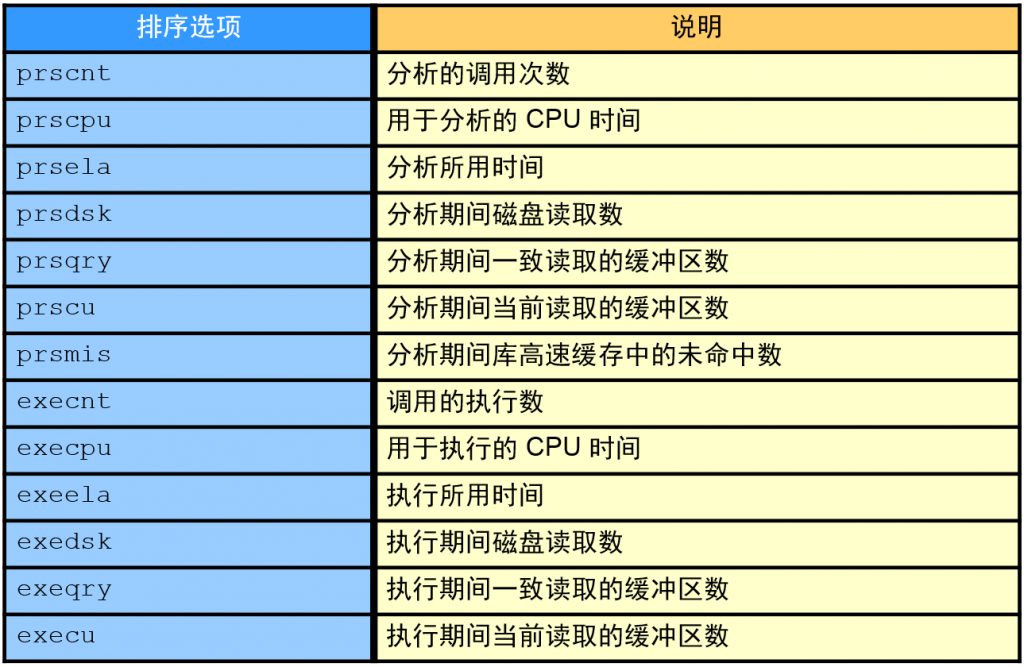
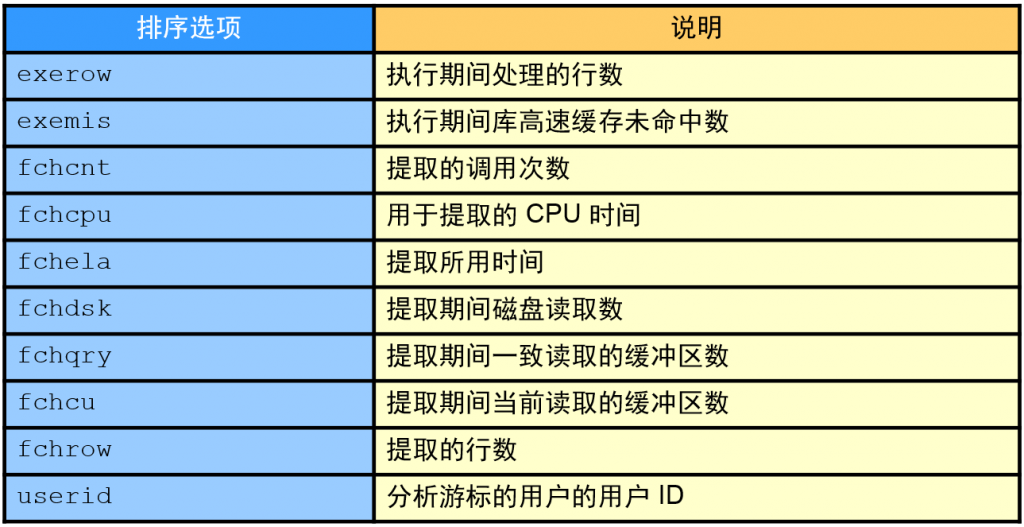
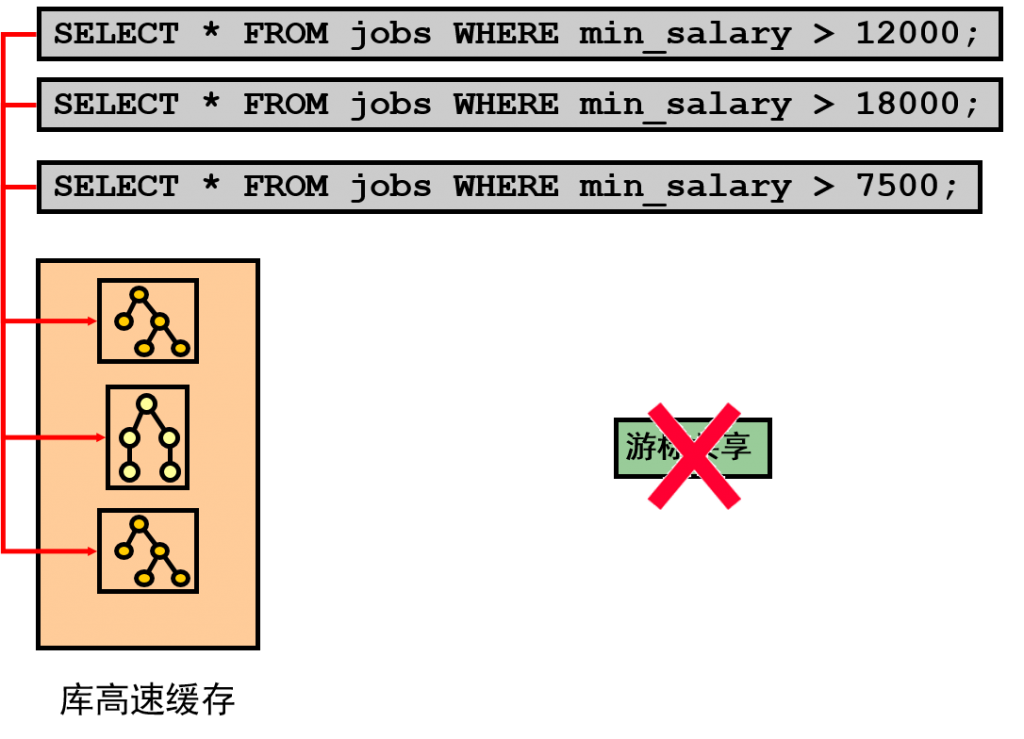
- 优化界面中显示了SQL的历史运行情况,包括逻辑读、物理读、运行时间,执行计划HASH等
- 点击Run Advisor按钮可以对该SQL执行SQL Tuning Task优化作业
- 之后点击View Result可以查看优化建议结果,以下为可能的几种结果:
–建议重写该SQL
–建议收集对应的统计信息
–给出SQL Profile以改善执行计划
–建议添加对应的索引
–无建议

OraGlance是一个轻量级的图形化Oracle性能监控工具。由诗檀软件开发,它致力于提供简单有效的几个指标来监控Oracle数据库,而不提供过多的指标。
它是绿色的,非植入式的;你可以直接运行它,而基本不需要做任何准备工作。
不需要在Oracle数据库内创建任何对象,其只需要以下几个查询权限:
OraGlance is a lightweight oracle performance monitor tool , developed by parnassusdata.com . It will only focus on most important metric .
you can easily run it without any prerequisite. It will ask for below permission:
supports oracle version: 11gR2 12c
grant create session to pd1; grant select on gv_$active_session_history to pd1; grant select on gv_$SQL to pd1; grant select on gv_$SQL_MONITOR to pd1; grant select on gv_$SQLSTATS to pd1; grant select on v_$database to pd1; grant select on gv_$instance to pd1; grant select on gv_$statname to pd1; grant select on gv_$sysstat to pd1; grant select on gv_$osstat to pd1; grant select on gv_$dlm_misc to pd1; grant select on gv_$session_blockers to pd1; grant select on dba_hist_sqltext to pd1; grant select on dba_hist_sqlstat to pd1; grant select on dba_hist_snapshot to pd1; grant select on dba_advisor_sqlstats to pd1; grant select on dba_sqlset_statements to pd1; 如果要运行SQL Tuning Advisor 则需要授予dba权限 grant dba to pd1;
update log:
适配了12c,增加了登录界面保存,增加了托盘功能,优化了界面, 为sqlite中的表增加了索引。
build 2020-07-01 : https://zcdn.askmac.cn/OraGlance200701.zip
2020-07-08:
- 现在oraglance支持最老的版本是11.2.0.1了 ,
- 现在支持对top sql的历史执行情况查看了
- 可以在查看SQL情况页面 调用sql tuning advisor 优化SQL语句 并给出建议了
build 2020-07-08: https://zcdn.parnassusdata.com/OraGlance200708.zip
2020-07-09:
现在登陆密码会以密文形式存放了


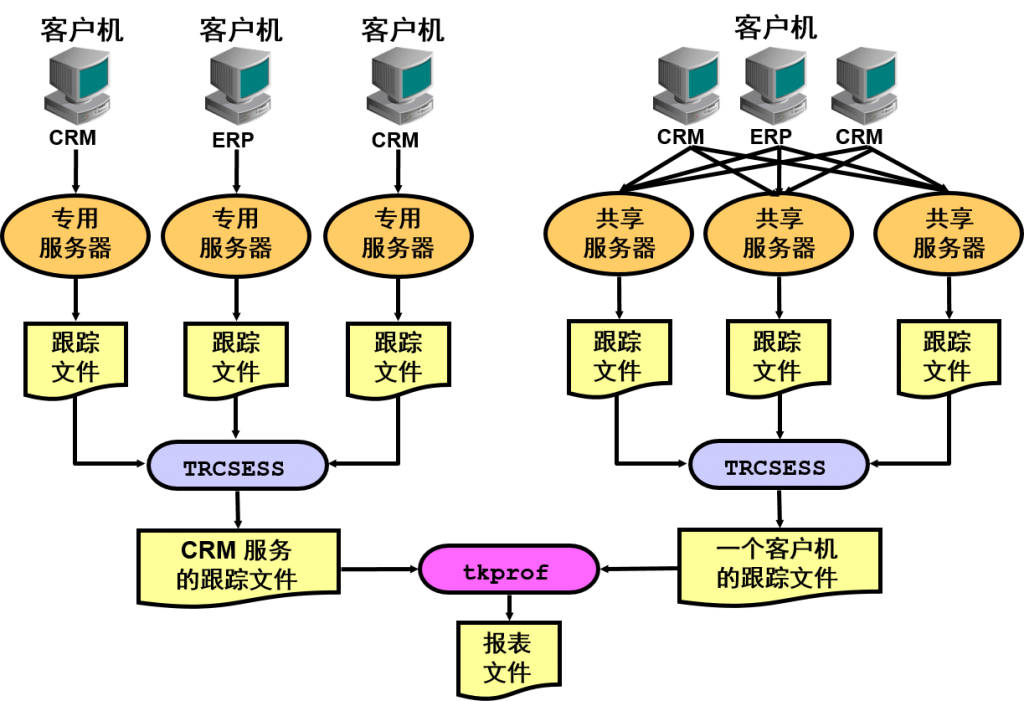
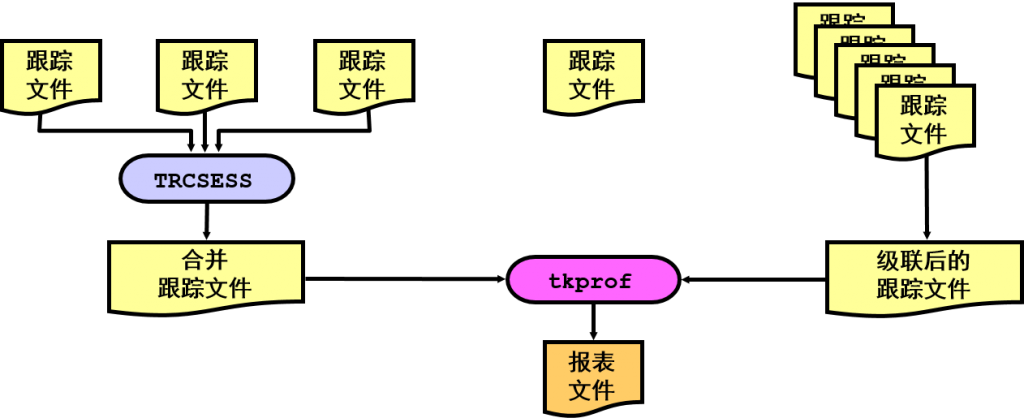
![trcsess [output=output_file_name]](https://www.askmac.cn/wp-content/uploads/2015/12/trcsess-outputoutput_file_name.png)