- 收集优化程序统计信息
- 收集系统统计信息
- 设置统计信息首选项
- 使用动态采样
- 处理优化程序统计信息
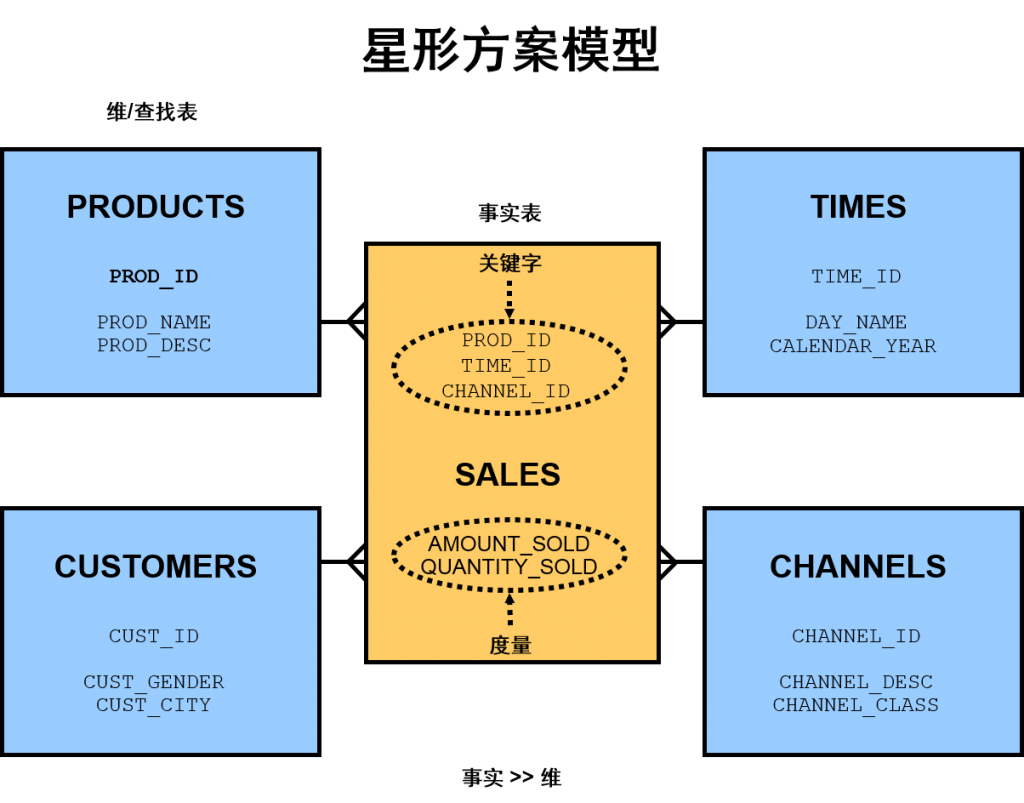
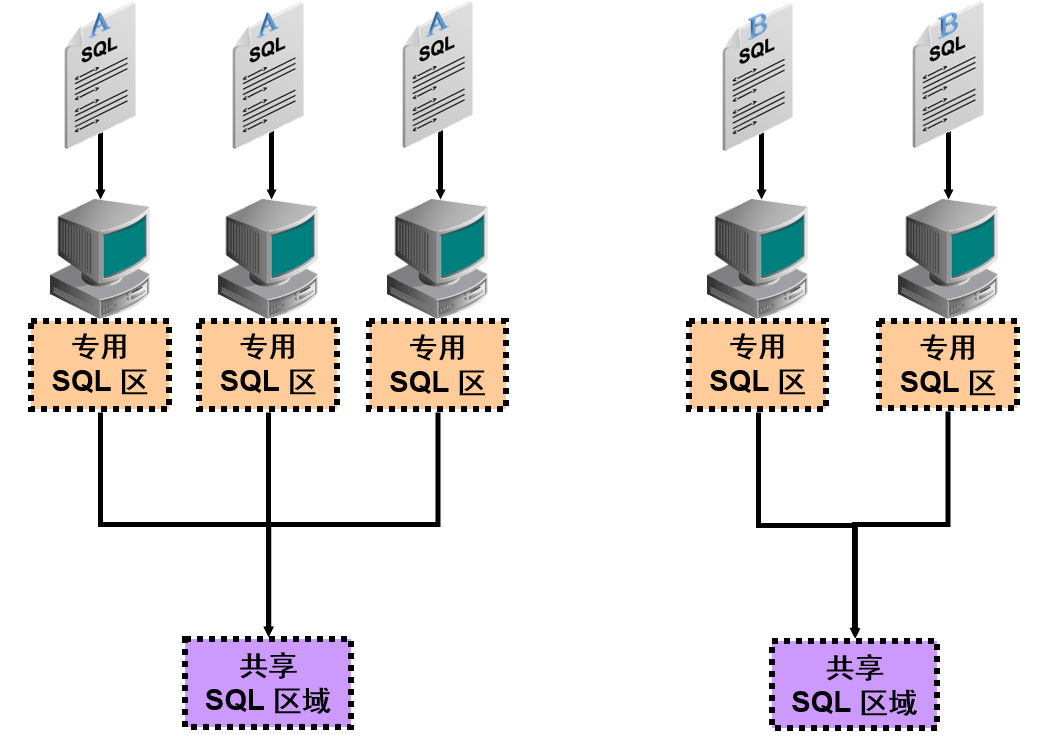
SQL CBO 优化器/优化程序 统计信息
优化程序统计信息描述有关数据库及其中对象的详细资料。查询优化程序使用这些统计信息,为每个 SQL 语句选择最佳的执行计划。
由于数据库中的对象经常发生更改,所以必须定期更新统计信息,以使它们能够准确地描述这些数据库对象。统计信息由 Oracle DB 自动进行维护,您也可以使用 DBMS_STATS 程序包手动维护优化程序统计信息。
- 描述数据库以及数据库中的对象
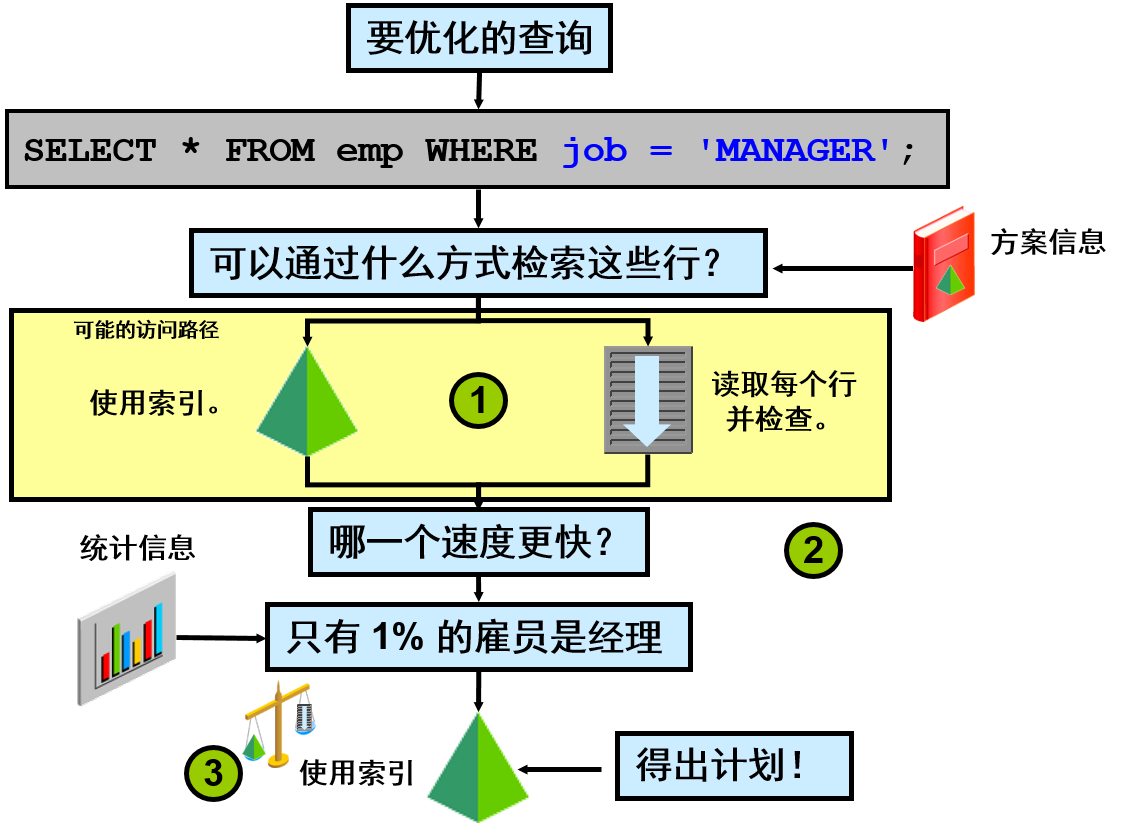
- 查询优化程序使用以下信息进行评估:
–谓词的选择性
–每个执行计划的成本
–访问方法、联接顺序和联接方法
–CPU 和输入/输出 (I/O) 成本
- 与收集优化程序统计信息相比,对过时的统计信息进行刷新同样重要。
–由系统自动收集
–用户使用 DBMS_STATS 手动收集
优化程序统计信息的类型
- 表统计信息:
–行数
–块数
–平均行长度
- 索引统计信息:
–B* 树级别
–唯一键
–叶块数量
–聚簇因子
- 系统统计信息:
–I/O 性能及利用率
–CPU 性能及利用率
- 列统计信息:
–基本统计信息:相异值数量、空值数量、平均长度、最小值、最大值
–直方图(列数据有偏差时的数据分布)
–扩展的统计信息
幻灯片中列出了大多数优化程序统计信息。
自 Oracle Database 10g 开始,在创建或重建索引时会自动收集索引统计信息。
注:此幻灯片提及的统计信息是优化程序统计信息,是为查询优化创建的,存储在数据字典中。不应将此类统计信息与 V$ 视图中显示的性能统计信息相混淆。
表统计信息 (DBA_TAB_STATISTICS)
NUM_ROWS
这是基数计算的基础。如果表是嵌套循环联接的驱动表,则行计数尤为重要,因为它定义了内部表被探测多少次。
BLOCKS
已使用数据块的数量。块计数与 DB_FILE_MULTIBLOCK_READ_COUNT 组合在一起给出了基表访问成本。
EMPTY_BLOCKS
表中空的(从未使用的)数据块数量。这是已使用数据块和高水位标记之间的块。
AVG_SPACE
分配给表的数据块中空闲空间的平均数量(以字节为单位)。
CHAIN_CNT
这是表中从一个数据块链接到另一个数据块、或者移植到了新块,且需要用链接来保留原有 ROWID 的行的数量。
AVG_ROW_LEN
表中行的平均长度(以字节为单位)。
STALE_STATS
指明统计信息在相应表中是否有效。
- 用于确定以下项:
–表访问成本
–联接基数
–联接顺序
- 收集的一些统计信息包括:
–行计数 (NUM_ROWS)
–块计数 (BLOCKS) 精确值
–空块数 (EMPTY_BLOCKS) 精确值
–每个块的平均空闲空间 (AVG_SPACE)
–链接行的数量 (CHAIN_CNT)
–平均行长度 (AVG_ROW_LEN)
–统计信息状态 (STALE_STATS)
索引统计信息 (DBA_IND_STATISTICS)
- 用于确定以下项:
–全表扫描与索引扫描
- 收集的统计信息包括:
–B* 树级别 (BLEVEL) 精确值
–叶块计数 (LEAF_BLOCKS)
–聚簇因子 (CLUSTERING_FACTOR)
–唯一键 (DISTINCT_KEYS)
–它指明索引中的每个相异值平均出现在多少个叶块中 (AVG_LEAF_BLOCKS_PER_KEY)
–索引中的每个相异值所指向的表数据块的平均数量 (AVG_DATA_BLOCKS_PER_KEY)
–索引中的行数 (NUM_ROWS)
一般来说,要选择索引访问,优化程序要求针对索引列的前缀使用一个谓词。但是,如果没有谓词,并且查询中引用的所有列都存在于索引中,则优化程序会考虑使用完全索引扫描,而不是全表扫描。
BLEVEL
该信息用于计算叶块查找成本。它指明索引从根块到叶块的深度。深度为“0”表明根块和叶块是相同的。
LEAF_BLOCKS
该信息用于计算完全索引扫描成本。
CLUSTERING_FACTOR
它基于索引的值测量表中行的顺序。如果该值接近块数量,则表明表的顺序良好。在这种情况下,一个叶块中的索引项通常指向同一数据块中的行。如果该值接近行数量,则表明表的顺序是随机的。在这种情况下,同一叶块中的索引项可能没有指向同一数据块中的行。
STALE_STATS
指明统计信息在相应索引中是否有效。
DISTINCT_KEYS
相异索引值的数量。对于强制执行 UNIQUE 和 PRIMARY KEY 约束条件的索引,此值等于表行数。
AVG_LEAF_BLOCKS_PER_KEY
它指明索引中的每个相异值平均出现在几个叶块中,该值舍入到最近的整数。对于强制执行 UNIQUE 和 PRIMARY KEY 约束条件的索引,此值始终等于一 (1)。
AVG_DATA_BLOCKS_PER_KEY
索引中的每个相异值所指向的表数据块的平均数量,舍入到最近的整数。对于每个给定的索引列值,该统计信息表示其行中包含该值的数据块的平均数量。
NUM_ROWS
索引中的行数。
索引聚簇因子
系统按块执行输入/输出 (I/O)。所以,优化程序是否使用全表扫描取决于所访问的块的百分比,而不是行百分比。这称作索引聚簇因子。如果每个块都包含单个行,则访问的行数和访问的块数是相同的。
但是,大多数表在每个块中都包含多个行。因此,所需数量的行可能聚集在几个块中,也可能散布在大量块中。除 B* 树级别,叶块数量以及索引选择性之类的信息之外,索引范围扫描的成本公式还包括聚簇因子。这是因为较小的聚簇因子表示行集中在表中的少量块中。较大的聚簇因子表示行随机分布在表中各个块之间。所以,较大的聚簇因子意味着使用索引范围扫描按 ROWID 获取行会花费较多的成本,因为需要访问表中较多的块才能返回数据。在实际环境中,因为叶块数量和 B* 树高度与聚簇因子和表选择性相比,相对较小,所以聚簇因子在决定索引范围扫描的成本方面似乎起着重要作用。
注:如果某个表有多个索引,则一个索引的聚簇因子可能较小,而同时另一个索引的聚簇因子可能较大。如果尝试重新组织此表以改进一个索引的聚簇因子,则可能会导致另一个索引的聚簇因子性能降低。
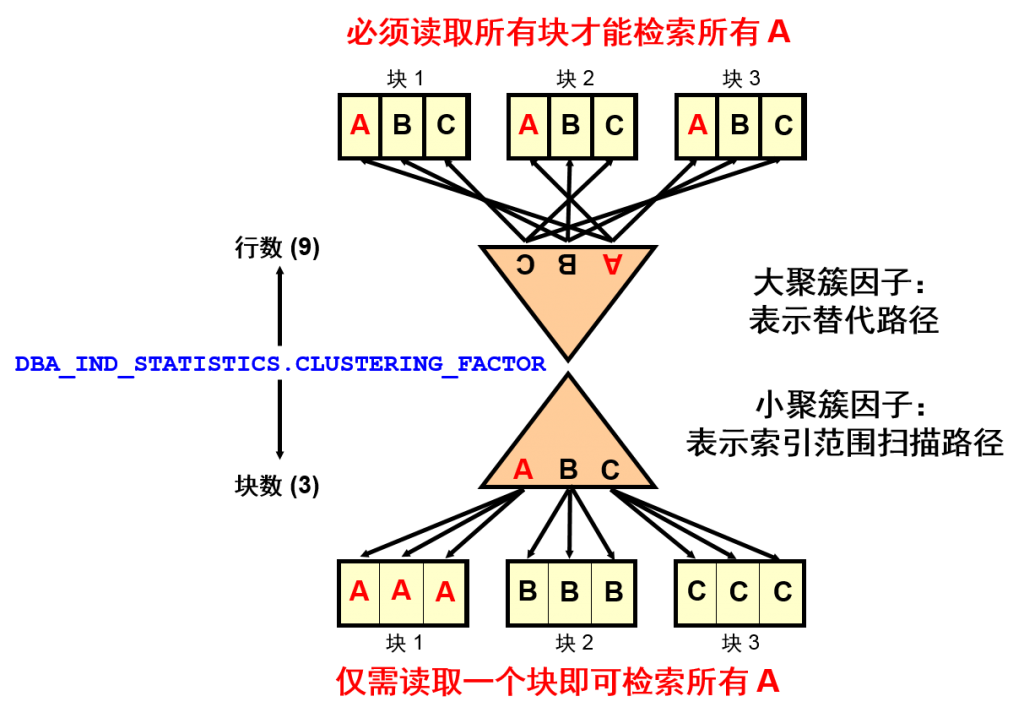
在收集索引的统计信息时,系统会在 DBA_INDEXES 视图的 CLUSTERING_FACTOR 列中计算聚簇因子。计算方式相对来讲比较简单。从左到右读取索引,对于每个索引项,如果相应行所在的块不同于上一行所在的块,将聚簇因子加一。基于此算法,聚簇因子最小可能值是块数量,最大可能值是行数量。
幻灯片中的示例说明了聚簇因子如何影响成本。假设存在下列情况:有一个表包含 9 行,在此表的 col1 上有一个非唯一索引,c1 列当前存储的值为 A、B 和 C,此表仅有三个 Oracle 块。
- 情形 1:如果组织表中的行,使索引值分散在各个表块中(而不是并列排置),则索引聚簇因子较高。
- 情形 2:如果将具有相同值的行并列排置在相同的块中,则这些行的索引聚簇因子
较低。
注:对于位图索引,聚簇因子不适用,因而不会使用。
列统计信息 (DBA_TAB_COL_STATISTICS)
- 列的相异值计数 (NUM_DISTINCT)
- 下限值 (LOW_VALUE) 精确值
- 上限值 (HIGH_VALUE) 精确值
- 空值数量 (NUM_NULLS)
- 非常用值的选择性估计 (DENSITY)
- 直方图存储桶数量 (NUM_BUCKETS)
- 直方图类型 (HISTOGRAM)
NUM_DISTINCT 用在选择性计算中,例如,1/NDV
LOW_VALUE 和 HIGH_VALUE:基于成本的优化程序 (CBO) 假定所有数据类型的值在下限值和上限值之间是均匀分布的。这些值用于确定范围选择性。
NUM_NULLS 对可为空值的列以及 IS NULL 和 IS NOT NULL 谓词的选择性很有帮助。
DENSITY 仅与直方图相关。它可用作非常用值的选择性估计。可以将其视为在此列中发现某个特殊值的概率。它的计算取决于列是否有一个直方图以及直方图的类型。
NUM_BUCKETS 是列直方图中存储桶的数量。
HISTOGRAM 表明直方图是否存在或直方图类型:NONE、FREQUENCY、HEIGHT BALANCED
直方图
- 优化程序假定数据均匀分布;当数据有偏差时,这可能会导致访问计划不太理想。
- 直方图:
–存储其它列分布信息
–在数据分布不均匀的情况下给出更准确的选择性估计。
- 使用无限的资源,您可以存储每个不同的值以及与该值对应的行数量。
- 如果相异值很多,这会变得难以管理,此时应使用其它
方法:
–频率直方图(#相异值 ≤ #存储桶)
–高度平衡直方图(#存储桶 < #相异值)
- 它们存储在 DBA_TAB_HISTOGRAMS 中。
直方图捕获列中不同值的分布情况,因此会生成更准确的选择性估计。如果列包含有偏差的数据,或包含在重复数量上有很大变化的值,则针对这类列创建直方图可以帮助查询优化程序生成准确的选择性估计,并针对索引使用、联接顺序、联接方法等等做出更好的
决定。
如果没有直方图,则假定数据均匀分布。如果某个列的直方图可用,则评估人员会使用该图,而不使用相异值数量。
创建直方图时,Oracle DB 使用两种不同类型的直方图表示方法,具体取决于在相应列中找到的相异值数量。如果您的数据集包含的相异值少于 254 个,并且没有指定直方图存储桶数量,则系统会创建频率直方图。如果相异值数量大于所需的直方图存储桶数量,则系统会创建高度平衡直方图。
在以下字典视图中可以找到有关直方图的信息:DBA_TAB_HISTOGRAMS、DBA_PART_HISTOGRAMS 和 DBA_SUBPART_HISTOGRAMS
注: 在统计信息收集方面,收集直方图统计信息是一项最耗费资源的操作。
频率直方图
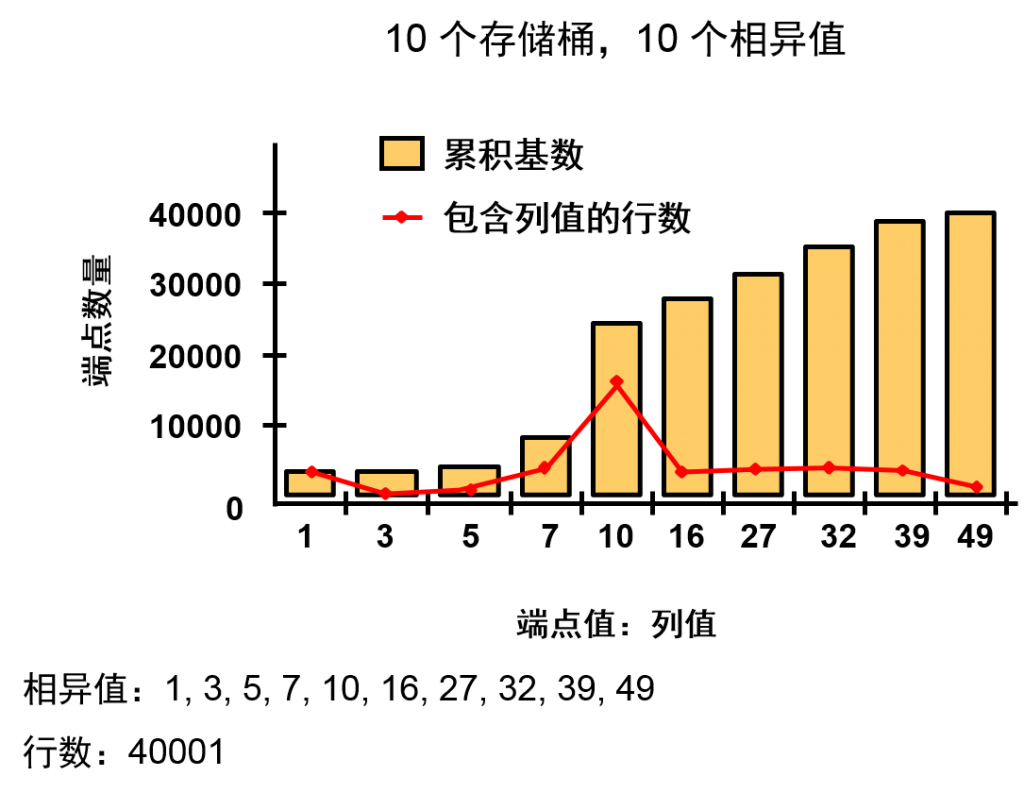
频率直方图在幻灯片的示例中,假定您有一个包含 40,001 个数字的列,但相异值只有 10 个:1、3、5、7、10、16、27、32、39 和 49。值 10 是最常用的值,出现了 16,293 次。
当请求的存储桶数量等于(或大于)相异值数量时,您可以存储每个不同的值并记录精确的基数统计信息。在这种情况下,在 DBA_TAB_HISTOGRAMS 中,ENDPOINT_VALUE 列存储列值,ENDPOINT_NUMBER 列存储该列值的行计数。
该行计数以累积形式进行存储,这样范围扫描可以减少一些计算。为了清楚起见,幻灯片中使用曲线显示行计数的实际数量;仅 ENDPOINT_VALUE 和 ENDPOINT_NUMBER 列存储在数据字典中。
查看频率直方图
幻灯片中的示例显示了查看频率直方图的方法。由于 INVENTORIES 表的 WAREHOUSE_ID 列中相异值的数量为 9,并且请求的存储桶数量为 20,所以系统会自动创建一个具有 9 个存储桶的频率直方图。可以在 USER_TAB_COL_STATISTICS 视图中查看此信息。
要查看直方图本身,可以查询 USER_HISTOGRAMS 视图。您可以看到 ENDPOINT_NUMBER 和 ENDPOINT_VALUE,前者对应着相应 ENDPOINT_VALUE 的累积频率,后者在本例中代表列数据的实际值。
注:本课稍后将对 DBMS_STATS 程序包进行介绍。
BEGIN
DBMS_STATS.gather_table_STATS (OWNNAME=>'OE', TABNAME=>'INVENTORIES',
METHOD_OPT => 'FOR COLUMNS SIZE 20 warehouse_id');
END;
SELECT column_name, num_distinct, num_buckets, histogram
FROM USER_TAB_COL_STATISTICS
WHERE table_name = 'INVENTORIES' AND
column_name = 'WAREHOUSE_ID';
COLUMN_NAME NUM_DISTINCT NUM_BUCKETS HISTOGRAM
------------ ------------ ----------- ---------
WAREHOUSE_ID 9 9 FREQUENCY
SELECT endpoint_number, endpoint_value
FROM USER_HISTOGRAMS
WHERE table_name = 'INVENTORIES' and column_name = 'WAREHOUSE_ID'
ORDER BY endpoint_number;
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
36 1
213 2
261 3
…
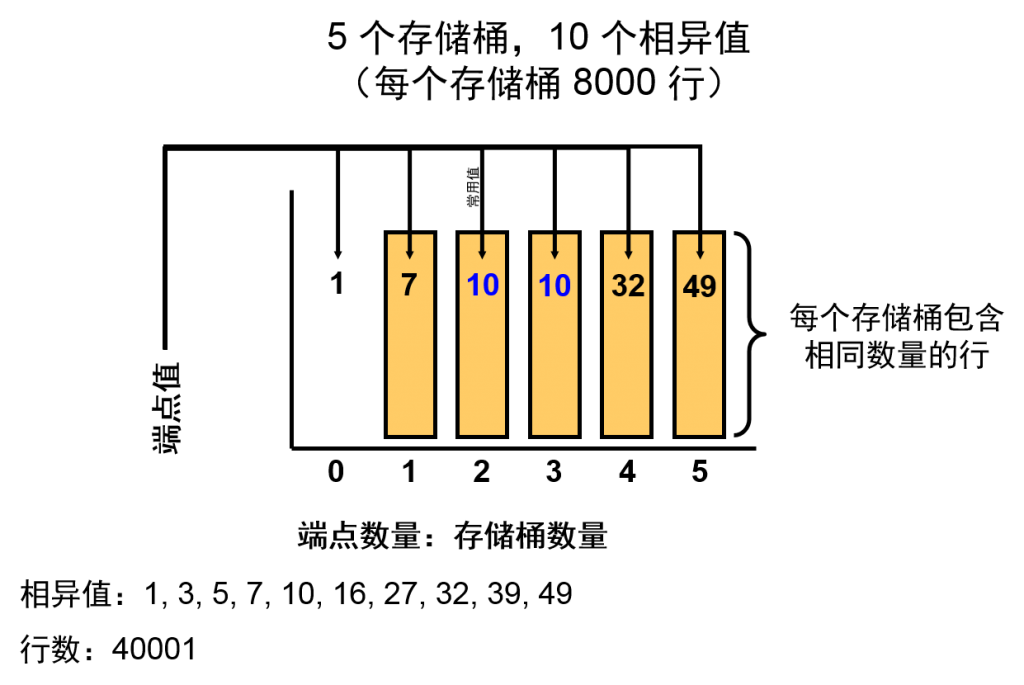
高度平衡直方图
在高度平衡直方图中,列值被分成若干段,每个段包含的行数几乎相同。直方图可表明在值范围中端点终止的位置。在幻灯片示例中,假定您有一个包含 40,001 个数字的列。但相异值只有 10 个:1、3、5、7、10、16、27、32、39 和 49。值 10 是最常用的值,出现了 16,293 次。如果存储桶数量少于相异值数量,则 ENDPOINT_NUMBER 记录存储桶数量,而 ENDPOINT_VALUE 记录与此端点对应的列值。在示例中,每个存储桶包含的行数是总行数的五分之一,即 8000。
根据此假设,值 10 的出现次数在 8000 和 24000 之间。因此您确定值 10 是一个常用值。
此类型的直方图适用于常用值的等式谓词和范围谓词。
不记录每个存储桶的行数,因为这可以从值的总数以及所有存储桶都包含相同数量的值这一事实推导出来。在本例中,值 10 是一个常用值,因为它跨越了多个端点值。为了节约空间,直方图不实际存储重复的存储桶。由于此原因,在幻灯片的示例中,不会在 DBA_TAB_HISTOGRAMS 中记录存储桶 2(端点值为 10)。
注:本例中的密度统计值将为 1/9 x 4/5 = 0.088 或 8.8%(9=#NPV 和 4=#NPB)。此值将用于非常用值的选择性计算。
幻灯片中的示例显示了查看高度平衡直方图的方法。由于 INVENTORIES 表的 QUANTITY_ON_HAND 列中相异值的数量为 237,并且请求的存储桶数量为 10,所以系统会自动创建一个具有 10 个存储桶的高度平衡直方图。可以在 USER_TAB_COL_STATISTICS 视图中查看此信息。
要查看直方图本身,可以查询 USER_HISTOGRAMS 视图。您可以看到与存储桶数量对应的 ENDPOINT_NUMBER,以及与端点的末端值对应的 ENDPOINT_VALUE。
注:本课稍后将对 DBMS_STATS 程序包进行介绍。
BEGIN
DBMS_STATS.gather_table_STATS(OWNNAME =>'OE', TABNAME=>'INVENTORIES',
METHOD_OPT => 'FOR COLUMNS SIZE 10 quantity_on_hand');
END;
SELECT column_name, num_distinct, num_buckets, histogram
FROM USER_TAB_COL_STATISTICS
WHERE table_name = 'INVENTORIES' AND column_name = 'QUANTITY_ON_HAND';
COLUMN_NAME NUM_DISTINCT NUM_BUCKETS HISTOGRAM
------------------------------ ------------ ----------- ---------------
QUANTITY_ON_HAND 237 10 HEIGHT BALANCED
SELECT endpoint_number, endpoint_value
FROM USER_HISTOGRAMS
WHERE table_name = 'INVENTORIES' and column_name = 'QUANTITY_ON_HAND'
ORDER BY endpoint_number;
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
0 0
1 27
2 42
3 57
…
直方图注意事项
- 如果列的数据分布有大幅偏差,则直方图很有用。
- 对于以下情况,直方图没有太大用处:
–列没有出现在 WHERE 或 JOIN 子句中
–列的数据分布较均匀
–对唯一性列使用了等式谓词
- 存储桶的最大数量等于 254 和相异值数量这两者之中的最小值。
- 除非直方图能够显著改善性能,否则不要使用直方图。
直方图只有在能够反映给定列的当前数据分布时才是有用的。在数据分布保持不变的情况下,列中的数据可能会更改。如果列的数据分布频繁发生变化,您必须频繁地重新计算其直方图。
如果您要为其创建直方图的列包含有高度偏差的数据,则直方图很有用。
然而,对于没有出现在 SQL 语句的 WHERE 子句中的列,没有必要为其创建直方图。同样,也没有必要为数据分布较均匀的列创建直方图。
另外,直方图对声明为 UNIQUE 的列也没有用处,因为此时选择性是显而易见的。此外,存储桶的最大数量为 254,可能更低,具体取决于相异列值的实际数量。直方图会影响性能,只有在直方图能够显著改善查询计划时,才应使用它们。如果数据分布很均匀,则优化程序不使用直方图就可以相当准确地估算出执行一个特殊语句所需的成本。
注:字符列有一些不同的行为,因为对于任何字符串只有前 32 个字节被存储为直方图
数据。
多列统计信息:概览
使用 Oracle Database 10g,在以下有限的情况下,查询优化程序在计算多个谓词的选择性时,将考虑列之间的相互关系:
- 如果连接谓词的所有列与级联索引关键字的所有列匹配,并且谓词是等值联接中使用的等式,则优化程序将使用索引中的唯一键 (NDK) 的数量来估计选择性 (1/NDK)。
- 如果将 DYNAMIC_SAMPLING 设置为级别 4,则查询优化程序将使用动态采样来评估涉及同一个表中多个列的复杂谓词的选择性。但是,样本的大小很小,并且分析时间有所增加。因此,从统计学的角度来看样本可能不准确,并且可能会弊大于利。
在其它所有情况下,优化程序将假定复杂谓词中所用的列的值互不相关。优化程序会通过将各个谓词的选择性相乘来估计连接谓词的选择性。如果列之间存在相关性,则此方法会低估选择性。为了避免此问题,Oracle Database 11g 允许您收集、存储并使用以下统计信息来捕获两个或更多列(也称为列组)之间的功能相关性:相异值的数量、空值的数量、频率直方图和密度。
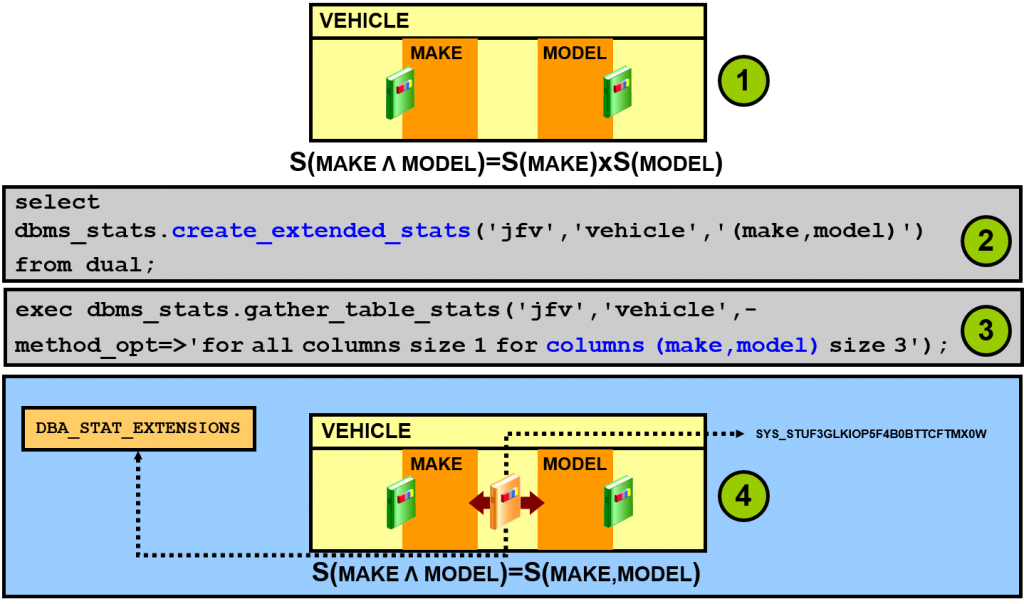
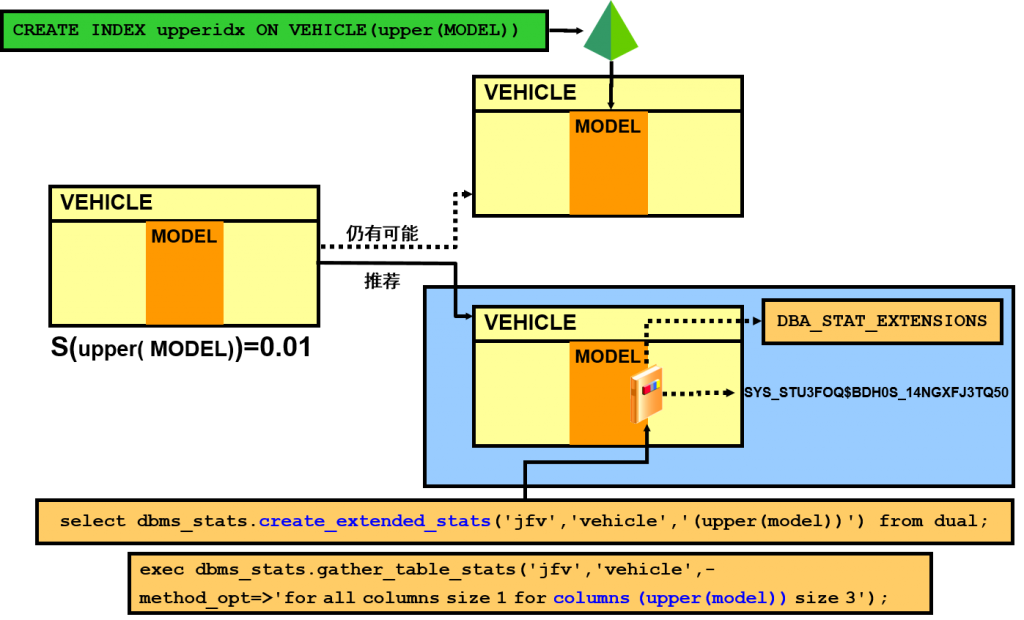
例如,假定有一个 VEHICLE 表,其中存储了有关汽车的信息。MAKE 和 MODEL 列是高度相关的,因为 MODEL 决定 MAKE。这是一种强依赖关系,优化程序应将这两个列看成是高度相关的两个列。可以使用 CREATE_EXTENDED_STATS 函数将该关系传送给优化程序(如幻灯片上的示例所示),然后计算所有列的统计信息(包括创建的相关组的统计
数据)。
优化程序仅对等式谓词使用多列统计信息。
附注
- CREATE_EXTENDED_STATS 函数会返回一个虚拟的隐藏列名称,如 SYS_STUW_5RHLX443AN1ZCLPE_GLE4。
- 根据幻灯片中的示例,可以使用以下 SQL 确定名称:
select dbms_stats.show_extended_stats_name(‘jfv’,’vehicle’,'(make,model)’) from dual - 创建统计信息扩展名之后,可以通过使用 ALL|DBA|USER_STAT_EXTENSIONS 视图检索它们。
表达式统计信息:概览
与列表达式相关的谓词是查询优化程序的一个重要的问题。计算 function(Column) = constant 形式的谓词的选择性时,优化程序将假定静态选择性值为 1%。此方法是错误的,因为这会导致优化程序生成不太理想的计划。
查询优化程序已得到了扩展,可以在有限的几种情况下更好地处理此类谓词。在这些情况下,函数保留列的数据分布特征,因而允许优化程序使用列统计信息。例如,TO_NUMBER 就是此类函数之一。
此外,还对相应功能做了进一步增强,可在查询优化过程中对内置函数求值,以便使用动态采样来获得更高的选择性。最后,优化程序收集所创建的虚拟列的统计信息以支持基于函数的索引。
但是,这些解决方案或者局限于特定的函数类,或者仅适合于用于创建基于函数的索引的表达式。通过使用 Oracle Database 11g 中的表达式统计信息,您可以使用更加通用的解决方案;这些解决方案包括了用户定义的任意函数,并且与是否存在基于函数的索引无关。如幻灯片中的示例所示,此功能将依靠虚拟列基础结构来创建列表达式的统计信息。
收集系统统计信息
- 通过系统统计信息,CBO 可以使用 CPU 和 I/O 特征。
- 必须定期收集系统统计信息;这不会使所缓存的计划失效。
- 收集系统统计信息等同于分析一个指定期间内的系统活动:
- 过程:
–DBMS_STATS.GATHER_SYSTEM_STATS
–DBMS_STATS.SET_SYSTEM_STATS
–DBMS_STATS.GET_SYSTEM_STATS
- GATHERING_MODE:
–NOWORKLOAD|INTERVAL
–START|STOP
使用系统统计信息,优化程序可以考虑系统的 I/O 和 CPU 性能以及利用情况。针对每个候选计划,优化程序计算 I/O 和 CPU 成本的估计值。要选择最高效的、I/O 和 CPU 成本达到最佳比例的计划,需要了解系统特征,这一点很重要。系统 CPU 和 I/O 特征并不总是保持不变,它们与许多因素相关。使用系统统计信息管理例程,可以捕获系统在最常见工作量下运行时一定时间间隔内的统计信息。例如,数据库应用程序可以在白天处理联机事务处理 (OLTP) 事务,在晚上运行 OLAP 报表。这两种状态的统计信息您都可以收集,并且可以根据需要激活适当的 OLTP 或 OLAP 统计信息。这样优化程序便可以针对可用的系统资源计划生成相关的成本。系统生成系统统计信息时,会分析指定期间内的系统活动。与表、索引或列统计信息不同,系统统计信息更新后,系统不会使已分析的 SQL 语句失效。所有新的 SQL 语句都使用新的统计信息进行解析。
我们强烈建议您收集系统统计信息。可以使用 DBMS_STATS.GATHER_SYSTEM_STATS 例程在用户定义的时间段内收集系统统计信息。也可以使用 DBMS_STATS.SET_SYSTEM_STATS 显式设置系统统计信息值。可使用 DBMS_STATS.GET_SYSTEM_STATS 验证系统统计信息。
使用 GATHER_SYSTEM_STATS 过程时,应指定 GATHERING_MODE 参数:
- NOWORKLOAD:这是默认设置。此模式可捕获 I/O 系统的特征。收集统计信息可能会花费几分钟的时间,具体取决于数据库大小。在此期间系统会估算 I/O 系统的平均读取寻道时间和传输速度。此模式适用于所有工作量。建议您在创建数据库和表空间后运行 GATHER_SYSTEM_STATS (‘noworkload’)。
- INTERVAL:捕获指定间隔内的系统活动。此参数与指定捕获时间量的 interval 参数组合在一起发挥作用。您应提供一个以分钟为单位的间隔值,之后系统会在字典或登台表中创建或更新系统统计信息。可以使用 GATHER_SYSTEM_STATS (gathering_mode=>’STOP’) 提前停止收集信息。
- START | STOP:获取指定开始时间和停止时间之间的系统活动,用该过去时间段内的统计信息刷新字典或登台表。
注:自 Oracle Database 10gR2 开始,系统会在启动时自动收集重要的系统统计信息。
收集系统统计信息:示例
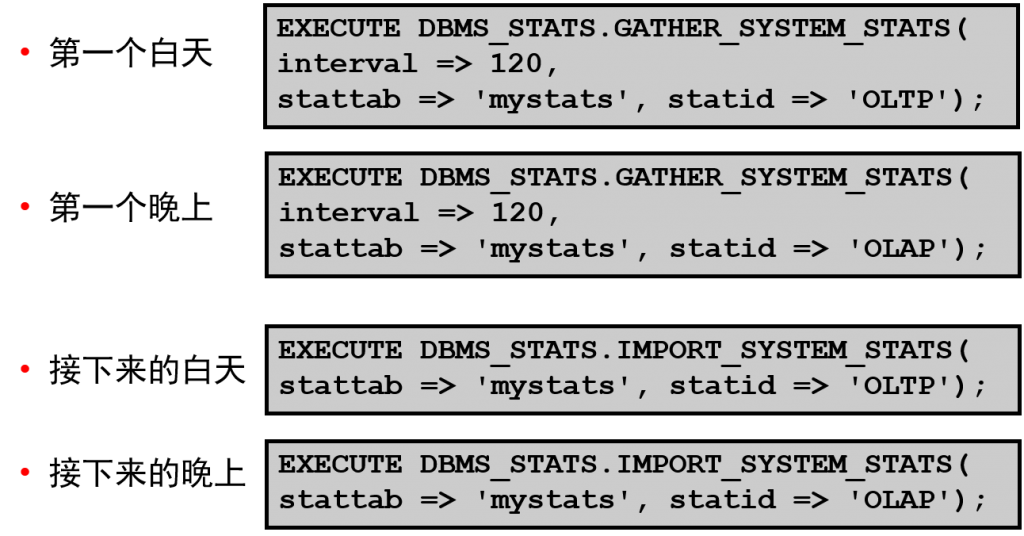
幻灯片中的示例显示了在白天处理 OLTP 事务、在晚上运行报表的数据库应用程序。
首先,必须在白天收集系统统计信息。在本例中,收集过程在 120 分钟后结束,统计信息存储在 mystats 表中。
然后在晚上收集系统统计信息。收集过程在 120 分钟后结束,统计信息存储在 mystats 表中。
通常,收集系统统计信息时使用幻灯片中的语法。在调用指定了 INTERVAL 参数的 GATHER_SYSTEM_STATS 过程之前,必须使用 SQL> alter system set job_queue_processes = 1; 之类的命令激活作业进程。也可以调用具有不同参数的相同过程来启用手动收集,而不使用作业。
适当的时候,可以在收集的统计信息之间进行切换。请注意,可以通过提交一个作业用正确的统计信息更新字典,使此过程自动化。在白天,可使用一个作业导入 OLTP 统计信息用于白天的运行,在晚上,可使用另一个作业导入联机分析处理 (OLAP) 统计信息用于晚上的运行。
- 手动在数据字典中启动系统统计信息收集:
SQL> EXECUTE DBMS_STATS.GATHER_SYSTEM_STATS( –
2 gathering_mode => ‘START’);
- 生成工作量。
- 结束收集系统统计信息:
SQL> EXECUTE DBMS_STATS.GATHER_SYSTEM_STATS( –
2 gathering_mode => ‘STOP’);
上一幻灯片中的示例显示了如何通过 DBMS_STATS.GATHER_SYSTEM_STATS 过程的内部参数使用作业收集系统统计信息。要手动收集系统统计信息,可以使用此过程的另一个参数,如幻灯片中所示。
首先,必须启动系统统计信息的收集过程,在确定实例中已生成了具有代表性的工作量后,可以随时结束收集过程。
本示例直接在数据字典中收集系统统计信息。
用于收集统计信息的机制
- 自动统计信息收集
–gather_stats_prog 自动化任务
- 手动统计信息收集
–DBMS_STATS 程序包
- 动态采样
- 缺少统计信息时:

Oracle DB 提供了几种机制来收集统计信息。这些机制将在后面的幻灯片中详细讲述。建议您为对象使用自动统计信息收集功能。
注:当系统发现表缺少统计信息时,它会动态收集优化程序所需要的必需统计信息。但是,对于某些类型的表,它不会执行动态采样,其中包括远程表和外部表。在这些情况下以及动态采样被禁用时,优化程序将使用默认的统计信息值。
统计信息首选项:概览
自动统计信息收集功能是在 Oracle Database 10gR1 中引入的,用于减轻优化程序统计信息的维护工作。但是,在有些情况下,必须禁用该功能,并运行自己的脚本。其中的一个原因是缺少对象级别的控制。只要发现一小部分对象的默认收集统计信息选项的效果不佳,就必须锁定统计信息,并使用您自己的选项单独对其进行分析。例如,如果列包含频率偏差很大的数据,则尝试针对这些列自动确定合适样本大小的功能 (ESTIMATE_PERCENT=AUTO_SAMPLE_SIZE) 不会有很好的效果。解决此问题的唯一方法就是用自己的脚本手动指定样本大小。
Oracle Database 11g 中的统计信息首选项功能具有一定的灵活性,因此,在有些对象需要不同于数据库默认设置的设置时,也可以较灵活地使用自动统计信息收集功能来维护优化程序统计信息。
通过此功能,您可以在对象级别或方案级别,将覆盖 GATHER_*_STATS 过程的默认行为的统计信息收集选项与自动优化程序统计信息收集任务关联起来。可以使用 DBMS_STATS 程序包管理幻灯片中显示的收集统计信息选项。
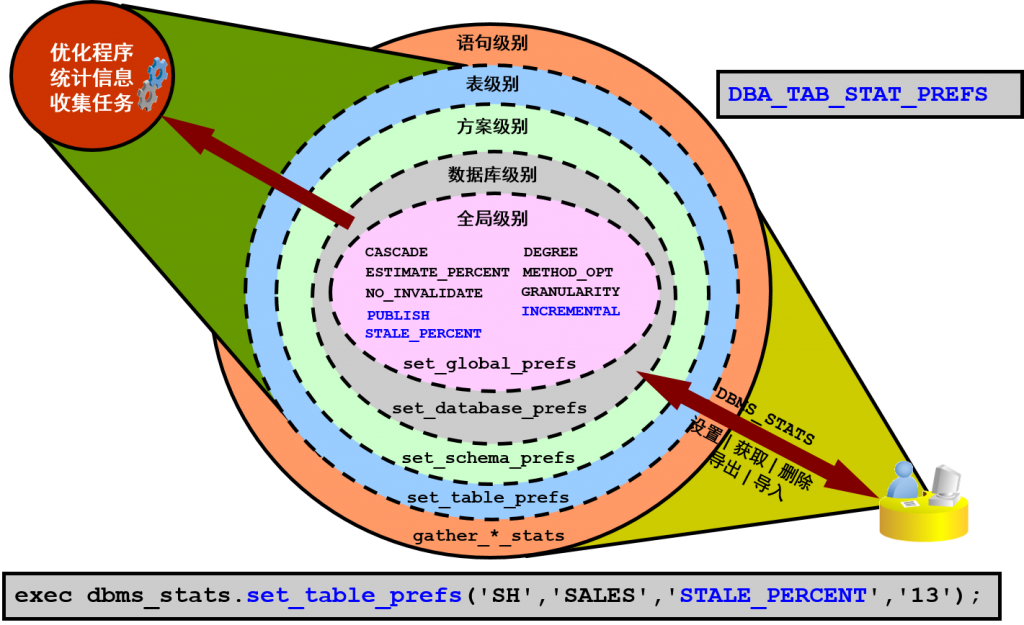
可以在表级、方案级、数据库级和全局级设置、获取、删除、导出和导入这些首选项。全局首选项用于没有首选项的表,而数据库首选项则用于设置针对所有表的首选项。以各种方式指定的首选项值的优先顺序为从外圈到内圈(如幻灯片中所示)。
在幻灯片的图形中,最后三个突出显示的选项是 Oracle Database 11gR1 中新增的选项:
- CASCADE 还收集索引统计信息。索引统计信息收集不是一个并行化操作。
- ESTIMATE_PERCENT 是用于计算统计信息的行的估计百分比(空值代表所有行):有效范围是 [0.000001,100]。使用常量 DBMS_STATS.AUTO_SAMPLE_SIZE 可让系统自己决定适当的采样范围以获得准确的统计信息。这是推荐的默认值。
- NO_INVALIDATE 可能会使也可能不会使从属游标失效。如果将其设置为 TRUE,则不会使从属游标失效。如果将其设置为 FALSE,则此过程会立即使从属游标失效。使用 DBMS_STATS.AUTO_INVALIDATE 可让系统自己决定何时使从属游标失效。这是默认设置。
- PUBLISH 用于确定是将统计信息发布到字典还是先将其存储在临时等待区中。
- STALE_PERCENT 用于确定阈值级别,达到该级别时将认为对象具有过时统计信息。该值是上次收集统计信息以来修改过的行数的百分比。示例仅将 SH.SALES 的值从默认值 10% 更改为 13%。
- DEGREE 决定用于计算统计信息的并行度。并行度的默认值为空值,这表示使用由 CREATE TABLE 或 ALTER TABLE 语句的 DEGREE 子句指定的表默认值。使用常量 DBMS_STATS.DEFAULT_DEGREE 将基于初始化参数指定默认值。AUTO_DEGREE 值可自动决定并行度。此值可能是 1(串行执行),也可能是 DEFAULT_DEGREE(基于 CPU 数量和初始化参数的系统默认值),具体取决于对象大小。
- METHOD_OPT 是一个 SQL 字符串,用于收集直方图统计信息。默认值为 FOR ALL COLUMNS SIZE AUTO。
- GRANULARITY 是用于为分区表收集统计信息的粒度。
- INCREMENTAL 用于以增量方式收集分区表中的全局统计信息。
请注意,您可以使用 DBMS_STATS.SET_PARAM 过程更改上述参数的默认值,这一点很重要。
注:可以使用 DBA_TAB_STAT_PREFS 视图说明所有相关表的全部有效统计信息首选项设置。
何时手动收集统计信息
- 主要依赖自动统计信息收集:
–更改自动统计信息收集频率来满足您的需要。
–请记住,应将 STATISTICS_LEVEL 设置为 TYPICAL 或 ALL,自动统计信息收集功能才能正常运行。
- 对于下列对象,请手动收集统计信息:
–易失对象
–在批处理操作中修改的对象
–外部表、系统统计信息、修复的对象
–在批处理操作中修改的对象:在批处理操作过程中收集统计信息。
–新建对象:在对象创建之后收集统计信息。
自动统计信息收集机制可使所有统计信息保持为最新。确定新统计信息的收集时间和收集频率非常重要。默认的收集间隔是晚上,但是您可以更改此间隔以适应您的业务需要。可以通过更改维护窗口的特征来达到此目的。但是,在某些情况下可能需要手动收集统计信息。例如,如果白天对表进行了大幅修改,则表的统计信息可能会过时。这样的对象一般有两种类型:
- 在白天受到大幅修改的易失表
- 经过大型批量装载的对象,在两个统计信息收集间隔之间该对象的总大小增加了 10% 或更多
对于外部表,系统不会在 GATHER_SCHEMA_STATS、GATHER_DATABASE_STATS 和自动优化程序统计信息收集处理期间收集其统计信息。但是,您可以使用 GATHER_TABLE_STATS 收集单个外部表的统计信息。不支持对外部表进行采样,因此应显式将 ESTIMATE_PERCENT 选项设置为空值。因为不允许对外部表执行数据处理,所以只在相应文件发生更改时分析外部表就足够了。需要手动收集其中统计信息的其它区域是系统统计信息和修复的对象,如动态性能表。系统不会自动收集这些统计信息。
手动统计信息收集
可以使用 Oracle Enterprise Manager 和 DBMS_STATS 程序包来完成以下任务:
- 生成并管理统计信息,以供优化程序使用:
–收集/修改
–查看/命名
–导出/导入
–删除/锁定
- 收集下列项的统计信息:
–索引、表、列、分区
–对象、方案或数据库
- 串行或并行收集统计信息
- 收集/设置系统统计信息(当前在 EM 中尚无法实现)
使用 Oracle Enterprise Manager 和 DBMS_STATS 程序包,都可以为优化程序手动生成和管理统计信息。可以使用 DBMS_STATS 程序包收集、修改、查看、导出、导入、锁定和删除统计信息。还可以使用此程序包标识(或命名)收集的统计信息。您可以按多种粒度收集索引、表、列和分区的统计信息:对象、方案和数据库级别。
DBMS_STATS 仅收集优化所需的统计信息,而不收集其它统计信息。例如,DBMS_STATS 收集的表统计信息包括行数、当前包含数据的块数量和平均行长度,但不包括链接行数、平均空闲空间或未使用的数据块数量。
注:不要使用 ANALYZE 语句的 COMPUTE 和 ESTIMATE 子句收集优化程序统计信息。仅仅是为了实现向后兼容才支持这些子句,在以后的版本中可能会将其删除。DBMS_STATS 程序包可收集更广泛、更准确的统计信息集,并且收集效率更高。对于与优化程序统计信息收集无关的其它用途,您可以继续使用 ANALYZE 语句:
- 使用 VALIDATE 或 LIST CHAINED ROWS 子句
- 收集空闲列表块的信息
手动统计信息收集:因素
- 监控 DML 的对象。
- 确定正确的样本大小。
- 确定并行度。
- 确定是否应使用直方图。
- 确定索引的级联影响。
- 在 DBMS_STATS 中使用的过程:
–GATHER_INDEX_STATS
–GATHER_TABLE_STATS
–GATHER_SCHEMA_STATS
–GATHER_DICTIONARY_STATS
–GATHER_DATABASE_STATS
–GATHER_SYSTEM_STATS
手动收集优化程序统计信息时,必须特别注意下列因素:
- 监控成批数据操纵语言 (DML) 操作的对象,必要时收集统计信息
- 确定正确的样本大小
- 确定并行度以加快对大型对象的查询速度
- 确定是否对包含有偏差数据的列创建直方图
- 确定对象的更改是否级联到任何从属索引
管理统计信息收集:示例
dbms_stats.gather_table_stats
('sh' -- schema
,'customers' -- table
, null -- partition
, 20 -- sample size(%)
, false -- block sample?
,'for all columns' -- column spec
, 4 -- degree of parallelism
,'default' -- granularity
, true ); -- cascade to indexes
dbms_stats.set_param('CASCADE',
'DBMS_STATS.AUTO_CASCADE');
dbms_stats.set_param('ESTIMATE_PERCENT','5');
dbms_stats.set_param('DEGREE','NULL');
第一个示例使用 DBMS_STATS 程序包收集 SH 方案的 CUSTOMERS 表的统计信息。它使用前面幻灯片中讨论的某些选项。
设置参数默认值
可以使用 DBMS_STATS 中的 SET_PARAM 过程为所有 DBMS_STATS 过程的参数设置默认值。幻灯片中的第二个示例演示了这种用法。也可以使用 GET_PARAM 函数获取参数的当前默认值。
注:只有表是分区表时,才需要考虑要收集的统计信息的粒度。此参数决定应在哪一级别收集统计信息。级别可以是分区、子分区或表。
优化程序动态采样:概览
- 对于符合以下特征的表和索引,可以执行动态采样:
–没有统计信息
–其统计信息不可信
- 在评估时用于确定更准确的统计信息:
–表基数
–谓词选择性
- 此功能由以下项控制:
–OPTIMIZER_DYNAMIC_SAMPLING 参数
–OPTIMIZER_FEATURES_ENABLE 参数
–DYNAMIC_SAMPLING 提示
–DYNAMIC_SAMPLING_EST_CDN 提示
动态采样可确定更准确的选择性和基数估计值,这样优化程序便可生成更有效的执行计划,因而提高了服务器性能。例如,虽然建议您收集所有表的统计信息以供 CBO 使用,但您可能不会收集临时表和用于临时数据处理的工作表的统计信息。在此类情况下,CBO 通过一个简单算法提供一个值,这可能会导致不太理想的执行计划。可以使用动态采样完成下列任务:
- 当收集到的统计信息无法使用或可能会导致重大估计错误时,估计单表的谓词选择性
- 为没有统计信息的表和相关索引,或者其统计信息太旧已不再可信的表估计表基数
可以使用 OPTIMIZER_DYNAMIC_SAMPLING 初始化参数控制动态采样。可使用 DYNAMIC_SAMPLING 和 DYNAMIC_SAMPLING_EST_CDN 提示进一步控制动态采样。
注:如果设置为 9.2 之前的版本,OPTIMIZER_FEATURES_ENABLE 初始化参数将关闭动态采样。
优化程序动态采样的工作方式
- 采样在编译时完成。
- 如果查询受益于动态采样:
–执行递归 SQL 语句对数据进行采样
–被采样的块数量取决于 OPTIMIZER_DYNAMIC_SAMPLING 初始化参数
- 在动态采样期间,将对样本应用谓词,以确定选择性。
- 在以下情况下使用动态采样:
–采样时间只占执行时间的一小部分
–查询被执行多次
–您认为会找到更好的计划
主要的性能属性是编译时间。系统在编译时将确定查询是否会从动态采样受益。如果能从动态采样受益,则发出递归 SQL 语句扫描表块的一个小型随机样本,并应用相关的单个表谓词估计谓词选择性。
动态采样查询会读取一定数量的块,具体数量取决于 OPTIMIZER_DYNAMIC_SAMPLING 初始化参数的值。
对于通常可快速完成的查询(在不到几秒钟的时间内即可完成),您不需要费力地去执行动态采样。但是,动态采样在下列任一条件下是有益的:
- 使用动态采样可找到更好的计划。
- 采样时间只占查询总执行时间的一小部分。
- 查询被执行多次。
注:动态采样可以应用于单个表的谓词子集,并可与未执行动态采样的谓词标准选择性估计值组合在一起。
OPTIMIZER_DYNAMIC_SAMPLING
- 动态会话或系统参数
- 可以设置为 0 到 10 之间的值
- 值为 0 时会关闭动态采样
- 值为 1 时对所有未分析的表进行采样,前提是未分析的表满足下列条件:
–联接至另一个表,或出现在子查询或不可合并的视图中
–没有索引
–包含的块超过 32 个
- 值为 2 时对所有未分析的表进行采样
- 值越高,就越积极地应用采样
- 如果没有更新活动,动态采样可重复进行
可通过将 OPTIMIZER_DYNAMIC_SAMPLING 参数设置为 0 到 10 之间的值来控制动态采样。值为 0 时表示不执行动态采样。
值为 1(默认值)时表示对所有满足下列条件的未分析的表执行动态采样:
- 查询中至少有一个未分析的表。
- 此未分析的表联接至另一个表,或出现在子查询或不可合并的视图中。
- 此未分析的表没有索引。
- 此未分析的表包含的块数多于对此表进行动态采样可使用的默认块数。此默认数量
是 32。
如果 OPTIMIZER_FEATURES_ENABLE 设置为 10.0.0 或更高,则默认值为 2。在此级别,系统会对所有未分析的表应用动态采样。采样的块数量是动态采样的默认块数量 (32) 的两倍。
提高该参数值会导致更积极地应用动态采样,这表现在采样的表类型(分析或未分析)以及在采样上花费的 I/O 量这两方面。
注:如果自上次采样操作后没有在进行采样的表中插入、删除或更新任何行,则动态采样可重复进行。
锁定统计信息
- 防止自动收集
- 主要用于易失表:
–不带统计信息锁定意味着要进行动态抽样。
BEGIN
DBMS_STATS.DELETE_TABLE_STATS(‘OE’,’ORDERS’);
DBMS_STATS.LOCK_TABLE_STATS(‘OE’,’ORDERS’);
END;
–带统计信息锁定可获得典型值。
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(‘OE’,’ORDERS’);
DBMS_STATS.LOCK_TABLE_STATS(‘OE’,’ORDERS’);
END;
- FORCE 参数可覆盖统计信息锁定。
SELECT stattype_locked FROM dba_tab_statistics;
自 Oracle Database 10g 开始,您可以使用 DBMS_STATS 程序包的 LOCK_TABLE_STATS 过程锁定指定表的统计信息。可以锁定没有统计信息的表的统计信息,或使用 DELETE_*_STATS 过程将其设置为 NULL,以防止自动收集统计信息,这样便可以对没有统计信息的易失表使用动态采样。易失表填满时,可以锁定该表的统计信息,这样该表的统计信息就会成为具有代表性的表填充。
也可以通过使用 LOCK_SCHEMA_STATS 过程在方案级别锁定统计信息。可以查询 {USER | ALL | DBA}_TAB_STATISTICS 视图中的 STATTYPE_LOCKED 列,以确定表的统计信息是否已锁定。
可以使用 UNLOCK_TABLE_STATS 过程取消对指定表统计信息的锁定。
即使统计信息处于锁定状态,也可以将 FORCE 参数的值设置为 TRUE 来覆盖它们。FORCE 参数在下列 DBMS_STATS 过程中:DELETE_*_STATS、IMPORT_*_STATS、RESTORE_*_STATS 和 SET_*_STATS。
注:锁定表的统计信息后,所有从属统计信息都被认为处于锁定状态。这包括表统计信息、列统计信息、直方图和从属索引统计信息。