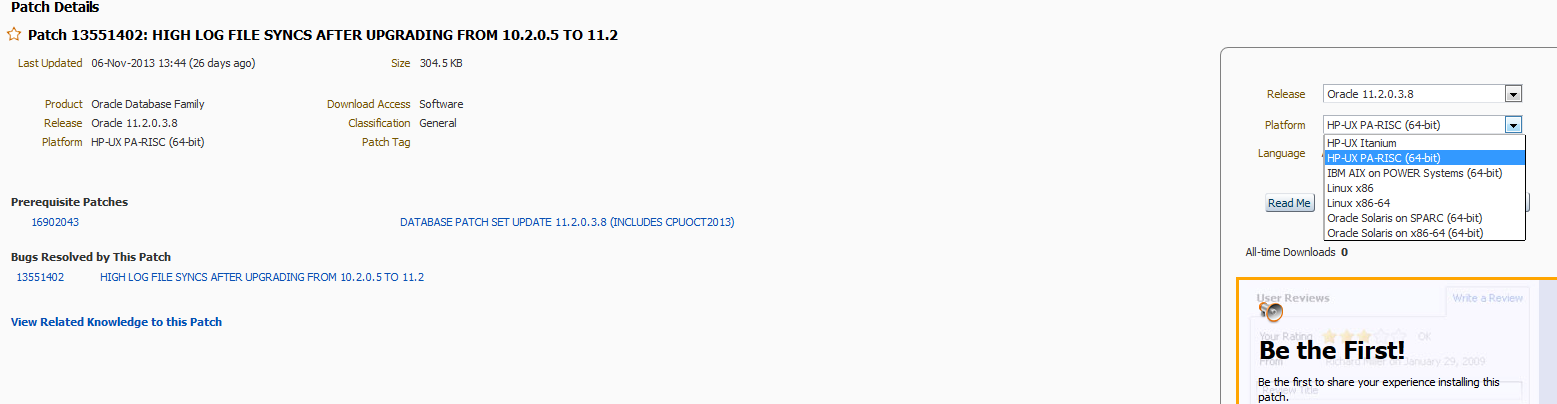
如果 你遇到从10.2.0.5升级到11.2出现LOG FILE SYNCS等待事件显著增长的性能问题,那么有必要读一下这篇文章了。
在以往的经验中如果遇到这种场景 ,那么 优先考虑设置 “_use_adaptive_log_file_sync”=false, adaptive log file sync是 11.2中提出的一个优化重做日志写的新特性, 在11.2.0.3以后默认为TRUE。
有客户在将”_use_adaptive_log_file_sync”=false后,log file sync等待事件的平均等待时间从10ms 下降到 1~2ms的案例。
_use_adaptive_log_file_sync造成性能下降的原因可能是其导致LGWR使用了polling 方式来取代 post/wait,并且polling的间隔是10ms,这个间隔是在代码里写死的。
此外如果使用了Veritas/symantec 的ODM的话也需要特别注意:你可能遇到了Bug 13551402 High “log file parallel write” and “log file sync” after upgrading 11.2 with Veritas/Symantec ODM,这个BUG已经确认在11.2.0.3和11.2.0.2上存在。
对于该bug的内部讨论最后确认是由于 11.2中lgwr的 IO使用了一种批量同步I/O接口,导致当配合Veritas/symantec 的ODM一起使用时会导致性能下降。
目前该BUG已经在多个Unix/Linux平台上提供补丁: