SELECT *
FROM (SELECT '1.v$sql'||'实例号:'||GV$SQL.inst_id source,
SQL_ID,
plan_hash_value,
TO_CHAR (FIRST_LOAD_TIME) begin_time,
'在cursor cache中' end_time,
executions "No. of exec",
(buffer_gets / executions) "LIO/exec",
(cpu_time / executions / 1000000) "CPUTIM/exec",
(elapsed_time / executions / 1000000) "ETIME/exec",
(disk_reads / executions) "PIO/exec",
(ROWS_PROCESSED / executions) "ROWs/exec"
FROM Gv$SQL
WHERE sql_id = '&A'
UNION ALL
SELECT '2.sqltuning set' source,
sql_id,
plan_hash_value,
'JUST SQLSET NO DATE' begin_time,
'JUST SQLSET NO DATE' end_time,
EXECUTIONS "No. of exec",
(buffer_gets / executions) "LIO/exec",
(cpu_time / executions / 1000000) "CPUTIM/exec",
(elapsed_time / executions / 1000000) "ETIME/exec",
(disk_reads / executions) "PIO/exec",
(ROWS_PROCESSED / executions) "ROWs/exec"
FROM dba_sqlset_statements
WHERE SQL_ID = '&A'
UNION ALL
SELECT '3.dba_advisor_sqlstats' source,
sql_id,
plan_hash_value,
'JUST SQLSET NO DATE' begin_time,
'JUST SQLSET NO DATE' end_time,
EXECUTIONS "No. of exec",
(buffer_gets / executions) "LIO/exec",
(cpu_time / executions / 1000000) "CPUTIM/exec",
(elapsed_time / executions / 1000000) "ETIME/exec",
(disk_reads / executions) "PIO/exec",
(ROWS_PROCESSED / executions) "ROWs/exec"
FROM dba_sqlset_statements
WHERE SQL_ID = '&A'
UNION ALL
SELECT DISTINCT
'4.dba_hist_sqlstat' || '实例号:' || SQL.INSTANCE_NUMBER
source,
sql_id,
PLAN_HASH_VALUE,
TO_CHAR (s.BEGIN_INTERVAL_TIME ,'YYYY-MM-DD hh24:mi:ss') begin_time,
TO_CHAR (s.END_INTERVAL_TIME,'YYYY-MM-DD hh24:mi:ss') end_time,
SQL.executions_delta,
SQL.buffer_gets_delta
/ DECODE (NVL (SQL.executions_delta, 0),
0, 1,
SQL.executions_delta)
"LIO/exec",
(SQL.cpu_time_delta / 1000000)
/ DECODE (NVL (SQL.executions_delta, 0),
0, 1,
SQL.executions_delta)
"CPUTIM/exec",
(SQL.elapsed_time_delta / 1000000)
/ DECODE (NVL (SQL.executions_delta, 0),
0, 1,
SQL.executions_delta)
"ETIME/exec",
SQL.DISK_READS_DELTA
/ DECODE (NVL (SQL.executions_delta, 0),
0, 1,
SQL.executions_delta)
"PIO/exec",
SQL.ROWS_PROCESSED_DELTA
/ DECODE (NVL (SQL.executions_delta, 0),
0, 1,
SQL.executions_delta)
"ROWs/exec"
FROM dba_hist_sqlstat SQL, dba_hist_snapshot s
WHERE SQL.INSTANCE_NUMBER = s.INSTANCE_NUMBER
AND SQL.dbid = (SELECT dbid FROM v$database)
AND s.snap_id = SQL.snap_id
AND sql_id IN ('&A'))
ORDER BY source, begin_time DESC;
SQL ID HISTORY
2013/07/03 by Leave a Comment
【Maclean技术分享】Oracle数据库优化经验- ADDM DBA
2013/06/24 by Leave a Comment
【Maclean技术分享】Oracle数据库优化经验- ADDM DBA
本次技术共享文档已上传,下载地址如下:
 Maclean技术分享Oracle数据库优化经验- ADDM DBA.pdf (1.32 MB, 下载次数: 669)
Maclean技术分享Oracle数据库优化经验- ADDM DBA.pdf (1.32 MB, 下载次数: 669)
【性能优化】optimizer statistics统计信息管理技巧
2013/05/25 by Leave a Comment
视图 DBA_OPTSTAT_OPERATIONS 记录了详细的DBMS_STATS操作历史,可以看到 包括 gather_database_stats (auto) 、gather_table_stats(到表级别)、copy_table_stats(到表级别)。其数据来源于 WRI$_OPTSTAT_OPR
SQL> select distinct operation from DBA_OPTSTAT_OPERATIONS;
OPERATION
—————————————————————-
copy_table_stats
gather_database_stats
gather_table_stats
lock_table_stats
unlock_table_stats
purge_stats
gather_database_stats (auto)
SQL> select dbms_stats.get_stats_history_availability from dual;
GET_STATS_HISTORY_AVAILABILITY
—————————————————————————
24-APR-13 08.31.36.886874000 AM +00:00
==》最早可用的历史统计信息
SQL> select dbms_stats.get_stats_history_retention from dual;
GET_STATS_HISTORY_RETENTION
—————————
31
==> 统计信息的保留期
exec dbms_stats.alter_stats_history_retention(10);
==》修改统计信息保留期
select * from dba_tab_stats_history
==》查询某张表的 统计信息历史情况, 但是注意dba_tab_stats_history 并不记录实际的历史统计信息数据
function diff_table_stats_in_history(
ownname varchar2,
tabname varchar2,
time1 timestamp with time zone,
time2 timestamp with time zone default null,
pctthreshold number default 10)
return clob;
diff_table_stats_in_history 用以列出 统计信息历史差异
SQL> select to_char(sysdate,’YYYY-MM-DD hh24:mi:ss’) from dual;
TO_CHAR(SYSDATE,’YY
——————-
2013-05-25 09:01:46
SQL> insert into opt_test select rownum from dual connect by level <=10000;
10000 rows created.
SQL> commit;
Commit complete.
SQL> exec dbms_stats.gather_table_stats(user,’OPT_TEST’);
PL/SQL procedure successfully completed.
SQL> set long 999999999
select report, maxdiffpct from table(dbms_stats.diff_table_stats_in_history(‘SYS’,’OPT_TEST’,to_timestamp(‘2013-05-25 09:01:46′,’YYYY-MM-DD hh24:mi:ss’)));
/
SQL> select table_name from dba_tables where table_name like ‘%OPTSTAT%’;
TABLE_NAME
——————————————————————————————————————————–
WRI$_OPTSTAT_SYNOPSIS$
WRI$_OPTSTAT_HISTHEAD_HISTORY
WRI$_OPTSTAT_HISTGRM_HISTORY
WRI$_OPTSTAT_SYNOPSIS_HEAD$
WRI$_OPTSTAT_SYNOPSIS_PARTGRP
OPTSTAT_USER_PREFS$
OPTSTAT_HIST_CONTROL$
WRI$_OPTSTAT_OPR_TASKS
WRI$_OPTSTAT_OPR
WRI$_OPTSTAT_AUX_HISTORY
WRI$_OPTSTAT_IND_HISTORY
WRI$_OPTSTAT_TAB_HISTORY
SQL> desc WRI$_OPTSTAT_TAB_HISTORY ==》 实际存放了表的历史统计信息
Name Null? Type
—————————————– ——– —————————-
OBJ# NOT NULL NUMBER
SAVTIME TIMESTAMP(6) WITH TIME ZONE
FLAGS NUMBER
ROWCNT NUMBER
BLKCNT NUMBER
AVGRLN NUMBER
SAMPLESIZE NUMBER
ANALYZETIME DATE
CACHEDBLK NUMBER
CACHEHIT NUMBER
LOGICALREAD NUMBER
SPARE1 NUMBER
SPARE2 NUMBER
SPARE3 NUMBER
SPARE4 VARCHAR2(1000)
SPARE5 VARCHAR2(1000)
SPARE6 TIMESTAMP(6) WITH TIME ZONE
–Tables – wri$_optstat_tab_history
–Indexes – wri$_optstat_ind_history
–Columns – wri$_optstat_histhead_history
–Histograms – wri$_optstat_histgrm_history
Old statistics reside in SYSAUX
WRI$_OPTSTAT_TAB_HISTORY – for table [partition] stats
WRI$_OPTSTAT_IND_HISTORY – for index [partition] stats
WRI$_OPTSTAT_HISTHEAD_HISTORY – for column stats
WRI$_OPTSTAT_HISTGRM_HISTORY – for histograms
WRI$_OPTSTAT_AUX_HISTORY – for system stats
OPTSTAT_HIST_CONTROL$ – stats history settings
【Maclean Liu技术分享】拨开Oracle优化器迷雾探究Histogram之秘
2013/05/13 by Leave a Comment
【Maclean Liu技术分享】拨开Oracle CBO 优化器迷雾, 探究Histogram直方图之秘,讲座文档正式版已上传
http://t.askmac.cn/thread-2172-1-1.html
预计时长: 1.5个小时
适合参与成员: 对于性能调优和CBO优化器有兴趣的同学,或急于提升SQL调优技能的同学。
教学视频已上传 , 收看请猛击下面的地址:
【Maclean Liu技术分享】Histogram直方图技术演示脚本如下:
 【Maclean Liu技术分享】Histogram直方图技术演示脚本.txt (9.93 KB, 下载次数: 65)
【Maclean Liu技术分享】Histogram直方图技术演示脚本.txt (9.93 KB, 下载次数: 65)
讲座材料presentation 当前正式版本下载:
【Maclean Liu技术分享】拨开Oracle CBO优化器迷雾,探究Histogram直方图之秘 20130429.pdf (1.11 MB, 下载次数: 3646)
Oracle BYPASS_UJVC HINT提示说明
2013/05/02 by Leave a Comment
本文地址:https://www.askmac.cn/archives/bypass_ujvc.html
- 本资料中设计到的 BYPASS_UJVC 提示是没有在oracle公司的语句件中记载的提示语语句。
- 不支持使用BYPASS_UJVC提示,或者不能从安全性的角度来使用。
- 指定BYPASS_UJVC 提示,发生了不太恰当的操作时,也无法执行修正。
- 使用BYPASS_UJVC提示时,需要参考本资料,将其变更为不使用提示语语句的处理。
- 为了删除BYPASS_UJVC提示,需要在实际环境中进行充分的验证。
可以更新的结合视图与ORA-1779
[参考] 样本数据
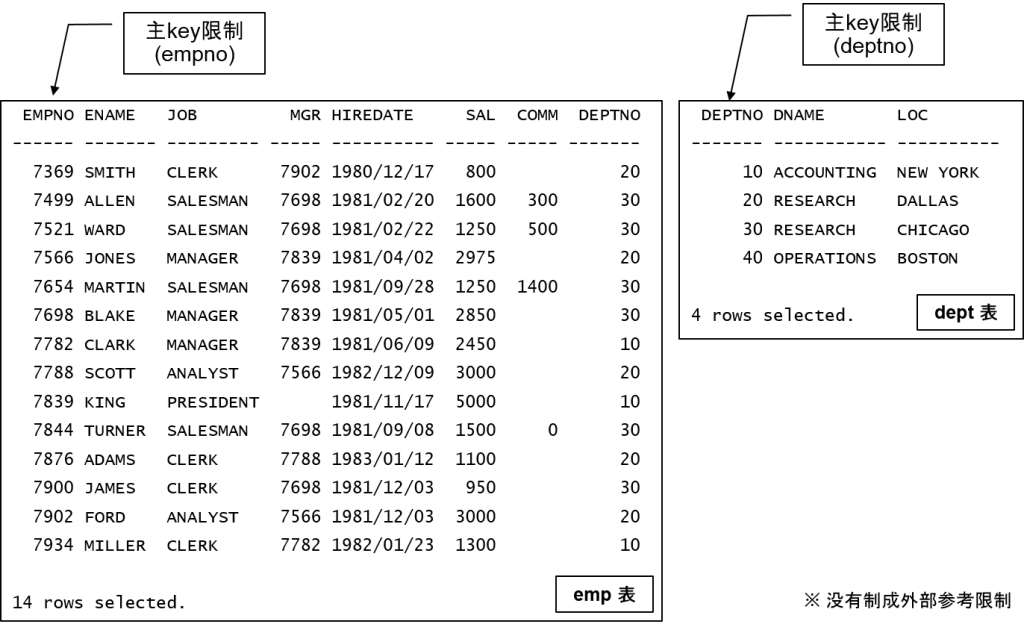
create or replace view sample_v1 as
select empno,ename,d.deptno,dname,loc
from emp e,dept d
where e.deptno = d.deptno (+)
order by 1;

可以更新的结合视图 (Updatable Join View)
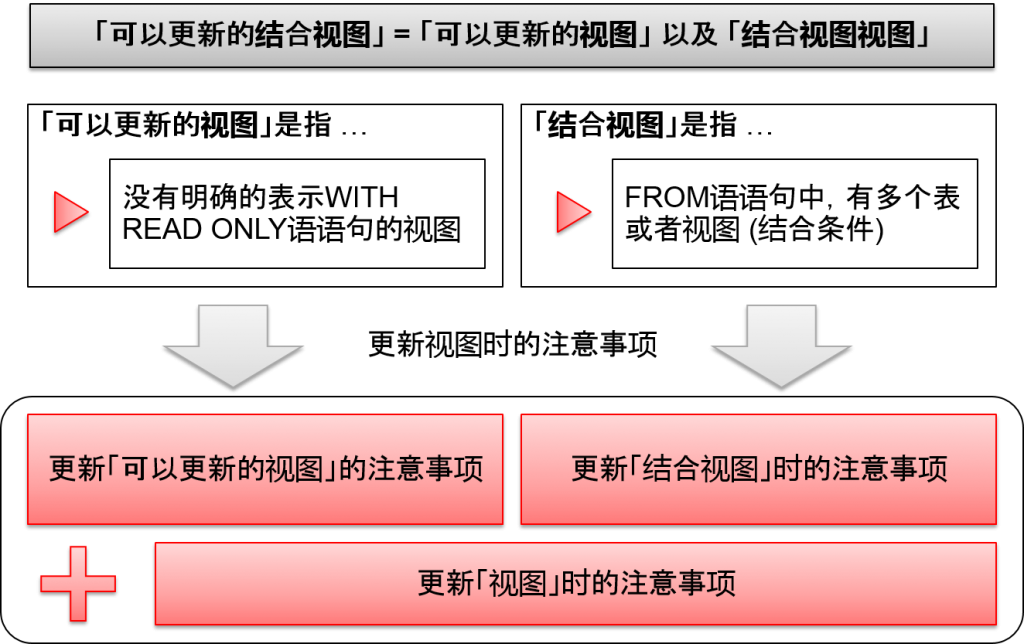
更新视图时的注意事项
- 对于视图的DML操作的限制中,应用如下基准。
- 视图的定义中使用包含SET或者DISTINCT运算符、GROUP BY语句或者group函数查询时,无法对其视图的实际表插入、更新、或者删除行。
- 视图的定义中使用了WITH CHECK OPTION,从实际表中无法选择行时,无法通过视图对实际表的行进行插入或者更新。
- 没有DEFAULT语句的NOT NULL列会在视图中被省略,无法通过视图对实际表的行进行插入或者更新。
- 制成视图时如果使用DECODE(deptno, 10, “SALES”, …)类似式子的话,就无法通过视图对实际表的行进行插入或者更新。
更新可以更新的视图时的注意事项
- 视图的各列需要映射单一表的列。
- 视图中,不能包含以下内容。
- 集合运算符
- DISTINCT运算符
- 总计功能或者分析功能
- GROUP BY、ORDER BY、MODEL、CONNECT BY或者START WITH语句
- SELECT列表中的收集式
- SELECT列表中的副查询
- WITH READ ONLY指定的副查询
- 结合 (有例外 … <下章会谈到>)
- 可以更新的视图包含疑似的列或者式子时,使用参考这些疑似列或者式子的更新语句时,无法更新实际环境中的表的行。
- DELETE语句中,通过结合,制成保存多个key的表的话,不管视图是否指定WITH CHECK OPTION来制成,都会从FROM语句中所指定的最开始的表中删除。
通过结合视图更新时的注意事项
- DML语句仅仅会影响结合基础的1个表。
- UPDATE语句
- 所以可以更新的结合视图的列都需要对保存key的表的列进行映射。
- 在视图的定义中,使用WITH CHECK OPTION语句时,所有的结合列以及重复表的列都无法更新。
- DELETE语句
- 结合中保存key的表只有一个时,无法在结合视图中删除行。
- 这个保存可以的表可以使用FROM语句来重复。
- 视图的定义中,使用了WITH CHECK OPTION语句,重复保存key表示,无法从视图中删除行。
- INSERT语句
- INSERT语句中,请不要参考没有保存key的表。
- 结合视图的定义中,使用WITH CHECK OPTION语句时,无法使用INSERT语句
可以更新的结合视图的确认方法
SQL> select table_name,column_name,updatable,insertable,deletable 2 from user_updatable_columns, user_views 3 where view_name = table_name; TABLE_NAME COLUMN_NAME UPD INS DEL ------------------------------ ------------------------------ --- --- --- SAMPLE_V1 EMPNO YES YES YES SAMPLE_V1 ENAME YES YES YES SAMPLE_V1 DEPTNO NO NO NO SAMPLE_V1 DNAME NO NO NO SAMPLE_V1 LOC NO NO NO

ORA-01779
ORA-01779
[JP] 无法对没有保存key的表的列进行映射。
[EN] cannot modify a column which maps to a non key-preserved table
结合的结果
- 可以更新保存key的表的列
- 对于不是保存key的表的列进行更新时,就会发生ORA-01779
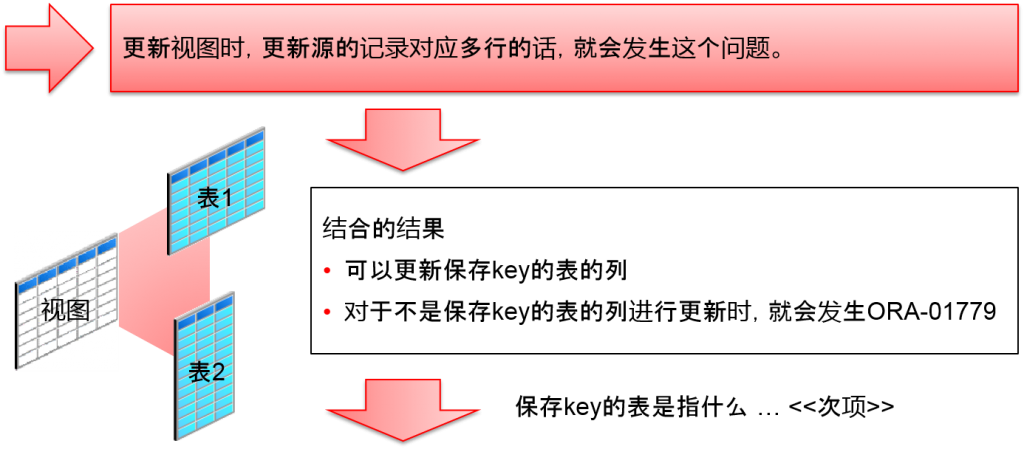
保存key的表 (Key-Preserved Table)
保存key的表是指什么 ….
所有表的key都是结合的结果key时,其表就会变成保存key的表。换言之,保存key的表就是指结合之后依旧保存了key的表。
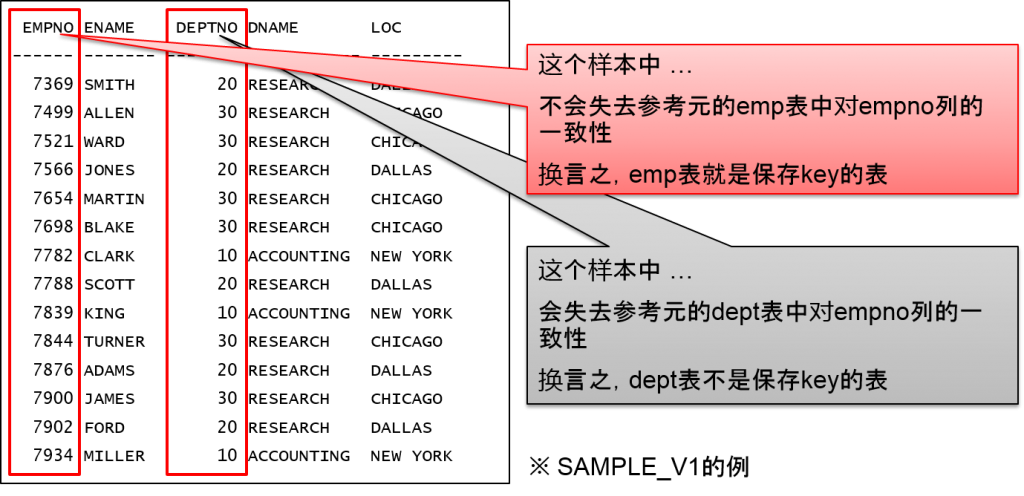
样本 #1

样本 #2

样本 #3

样本#4:UPDATE语句内的子查询
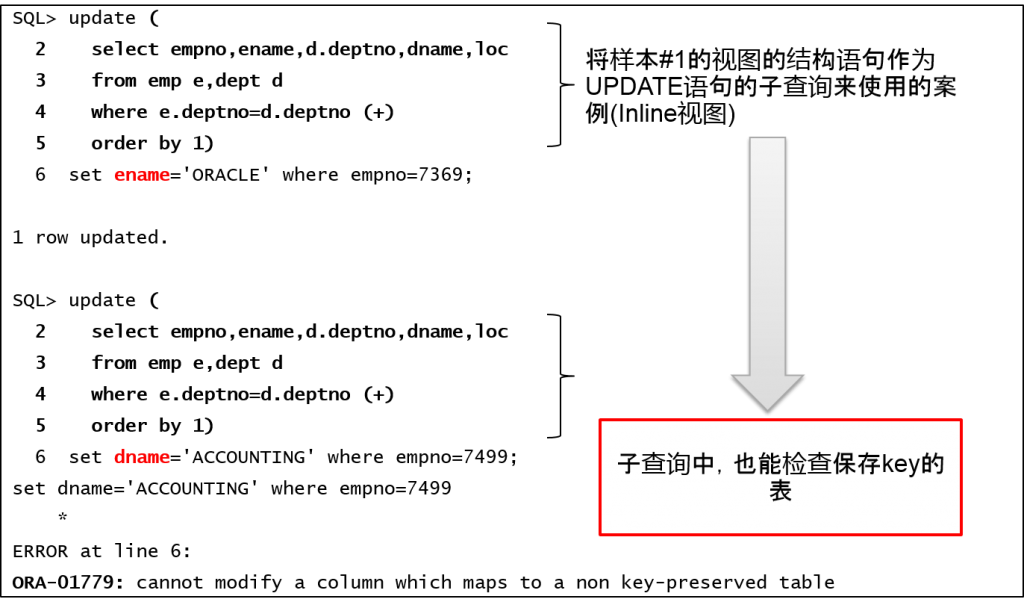
[参考] 样本#4的event 10046
Update (
select empno,ename,d.deptno,dname,loc from emp e,dept d where e.deptno=d.deptno (+) order by 1)
set ename='ORACLE' where empno=7369
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.01 0.00 0 3 3 1
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 2 0.01 0.00 0 3 3 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 58 (SCOTT)
Rows Row Source Operation
------- ---------------------------------------------------
0 UPDATE EMP (cr=3 pr=0 pw=0 time=595 us)
1 NESTED LOOPS OUTER (cr=3 pr=0 pw=0 time=154 us)
1 TABLE ACCESS BY INDEX ROWID EMP (cr=2 pr=0 pw=0 time=113 us)
1 INDEX UNIQUE SCAN PK_EMPNO (cr=1 pr=0 pw=0 time=56 us)(object id 51936)
1 INDEX UNIQUE SCAN PK_DEPT (cr=1 pr=0 pw=0 time=27 us)(object id 51934)
update /*+ BYPASS_UJVC */ (
select empno,ename,d.deptno,dname,loc from emp e,dept d where e.deptno=d.deptno (+) order by 1)
set dname='ACCOUNTING' where empno=7499
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 3 1 1
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 2 0.00 0.00 0 3 1 1
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: 58 (SCOTT)
Rows Row Source Operation
------- ---------------------------------------------------
0 UPDATE DEPT (cr=3 pr=0 pw=0 time=199 us)
1 NESTED LOOPS OUTER (cr=3 pr=0 pw=0 time=59 us)
1 TABLE ACCESS BY INDEX ROWID EMP (cr=2 pr=0 pw=0 time=35 us)
1 INDEX UNIQUE SCAN PK_EMPNO (cr=1 pr=0 pw=0 time=20 us)(object id 51936)
1 INDEX UNIQUE SCAN PK_DEPT (cr=1 pr=0 pw=0 time=10 us)(object id 51934)
本文地址:https://www.askmac.cn/archives/bypass_ujvc.html
[参考] ORA-01779以外的ORA错误
- ORA-01732
- [JP] 这个视图中数据操作无效
- [EN] data manipulation operation not legal on this view
- INSERTABLE是对NO表执行INSERT语句时发生的错误
- 即使指定列,也无法插入NULL
- ORA-01752
- [JP] 无法从多个表的视图中删除
- [EN] cannot delete from view without exactly one key-preserved table
- DELETABLE是对NO表执行DELETE语句时发生的错误
BYPASS_UJVC提示
制成优化的执行计划时,对UJVC(Updatable Join View) 的测试进行bypass的提示语句

BYPASS_UJVC 提示的利用的悬念点
- 没有document化的提示语句
- 不支持对象
- 更新的对象行数不同
- 基于对象行数的处理中,可能会产生业务逻辑错误
- 更新了意料之外的数据
- 由于视图化,可能会更新之前隐藏的数据
更新的对象行数不同

[参考] event 10046 的结果
update /*+ BYPASS_UJVC */ sample_v1 set loc = 'BOSTON‘ where deptno = 20 call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.01 0.00 0 3 0 0 Execute 1 0.00 0.00 0 8 7 5 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 2 0.01 0.00 0 11 7 5 Misses in library cache during parse: 1 Optimizer mode: ALL_ROWS Parsing user id: 58 (SCOTT) Rows Row Source Operation ------- --------------------------------------------------- 0 UPDATE DEPT (cr=8 pr=0 pw=0 time=2301 us) 5 SORT ORDER BY (cr=8 pr=0 pw=0 time=1600 us) 5 HASH JOIN OUTER (cr=8 pr=0 pw=0 time=1437 us) 5 TABLE ACCESS FULL EMP (cr=7 pr=0 pw=0 time=218 us) 1 INDEX UNIQUE SCAN PK_DEPT (cr=1 pr=0 pw=0 time=24 us)(object id 51934)
本文地址:https://www.askmac.cn/archives/bypass_ujvc.html
更新了意料之外的数据

面向废止BYPASS_UJVC提示的指导线
【简介】 迁移的指导线
- 指定对应地址
- 在每个批量处理的模型中执行
- à高效使用 Real Application Testing
- 改写对应地址
1.◎ 使用MERGE语句
- 将从源表中搜索到数据结果记录在USING语句中,通过在ON语句中记录这个结果的结合条件就可以不使用UJV来记录
2.使用○ WHERE EXISTS语句
- 通过在WHERE EXISTS语句中记录结合条件,就可以改写不使用视图以及inline视图的SQL语句
- 比MERGE语句的SQL语句稍微复杂一点
3.使用△Instead of 触发器
Oracle Real Application Testing 概要
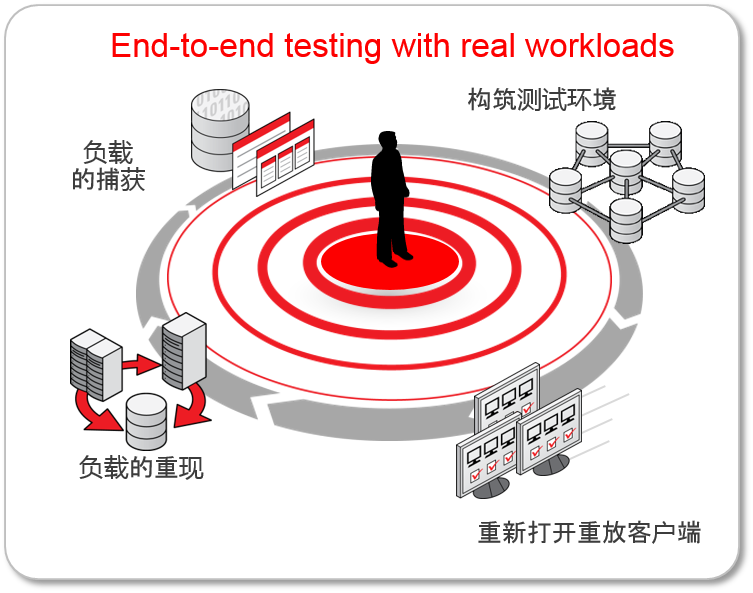
- Database Replay
- 吞吐量的性能测试
- 修正应用同时执行性的问题
- SQL Performance Analyzer
- SQL的响应时间测试
- 指定SQL重定向以及调优
本文地址:https://www.askmac.cn/archives/bypass_ujvc.html
Database Replay概要
- 利用正式数据库的负载进行性能测试
- 维持正式环境中特有的时机以及事务的依赖性、思考时间
- 测量与测试事务的吞吐量
- 指定应用的可扩展性,新功能的并行性
- 执行Oracle Database 9iR2以及10gR2更新
BYPASS_UJVC改写对应地址
| 方法 | 内容 | 平均 | 是否推荐 | |
| 案1 | 使用MERGE语句 | 将从源表中搜索到的结果记录在USING语句中,将这个见过的结合条件记录在ON语句中,就可以不使用UJV来记录 | 直观上来说,便于理解,并且可以改写成简单的SQL语句 | ◎ |
| 案2 | 使用WHERE EXISTS语句 | 通过在WHERE EXISTS语句记录结合条件,就可以不使用视图以及inline视图来改写SQL语句 | SQL语句比MERGE语句要复杂 | ○ |
| 案3 | 使用Instead of 触发器 | 使用BEFORE触发器更新 | 使用起来太复杂,不现实 | △ |
使用MERGE语句
MERGE语句
从源表中搜索数据,根据条件不同,可以在一个SQL语句中对对象表执行插入与更新
MERGE INTO 表名1 USING 表名2 |副查询 ON ( 结合条件 ) WHEN MATCHED THEN UPDATE SET 列名1 = 值1, 列名2 = 值2, ・・・ WHEN NOT MATCHED THEN INSERT [( 列名1, 列名2, ・・・ )] VALUES ( 值1, 值2, ・・・ );
MERGE语句的注意事项
- 无法成为Fine-grained access control的对象
- 使用INTO语句的话,就可以在更新或者插入对象的表、视图中进行指定。对视图映射数据时,需要更新视图。
- 必须保证ON语句的对象列的一致性
使用MERGE语句 (样本)

[参考] event 10046 的结果
使用了结合视图的BYPASS_UJVC 提示的更新
update /*+ BYPASS_UJVC */ ( select empno,ename,d.deptno,dname,loc from emp e,dept d where e.deptno=d.deptno) set loc = 'BOSTON' where ename = 'SMITH' call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 0 0 Execute 1 0.00 0.00 0 8 3 1 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 2 0.00 0.00 0 8 3 1 Rows Row Source Operation ------- --------------------------------------------------- 0 UPDATE DEPT (cr=8 pr=0 pw=0 time=899 us) 1 NESTED LOOPS (cr=8 pr=0 pw=0 time=366 us) 1 TABLE ACCESS FULL EMP (cr=7 pr=0 pw=0 time=306 us) 1 INDEX UNIQUE SCAN PK_DEPT (cr=1 pr=0 pw=0 time=46 us)(object id 53317)
使用了MERGE语句 的更新
merge into dept d using (select deptno from emp where ename = 'SMITH' ) v on ( v.deptno = d.deptno) when matched then update set loc='BOSTON' call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.03 0.03 0 0 0 0 Execute 1 0.00 0.00 0 9 2 1 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 2 0.03 0.03 0 9 2 1 Rows Row Source Operation ------- --------------------------------------------------- 0 MERGE DEPT (cr=9 pr=0 pw=0 time=0 us) 1 VIEW (cr=9 pr=0 pw=0 time=0 us) 1 NESTED LOOPS (cr=9 pr=0 pw=0 time=0 us) 1 NESTED LOOPS (cr=8 pr=0 pw=0 time=0 us cost=5 size=29 card=1) 1 TABLE ACCESS FULL EMP (cr=7 pr=0 pw=0 time=0 us cost=4 size=9 card=1) 1 INDEX UNIQUE SCAN PK_DEPT (cr=1 pr=0 pw=0 time=0 us cost=0 size=0 card=1)(object id 83537) 1 TABLE ACCESS BY INDEX ROWID DEPT (cr=1 pr=0 pw=0 time=0 us cost=1 size=20 card=1)
所有WHERE EXISTS语句 (样本)
使用了结合视图的BYPASS_UJVC 提示的更新
SQL> update /*+ BYPASS_UJVC */ 2 ( 3 select empno,ename,d.deptno,dname,loc from emp e,dept d 4 where e.deptno=d.deptno) 5 set loc = 'BOSTON' where ename = 'SMITH'; 1 row updated.
通过WHERE EXISTS语句的改写
SQL> update dept d 2 set loc = 'BOSTON' 3 where exists ( 4 select * from emp e 5 where e.deptno=d.deptno and e.ename = 'SMITH') 6 ; 1 row updated.
通过WHERE EXISTS语句进行的改写
update dept d
set loc = 'BOSTON'
where exists (
select * from emp e
where e.deptno=d.deptno and e.ename = 'SMITH')
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.05 0.05 0 0 0 0
Execute 1 0.00 0.00 0 8 2 1
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 2 0.05 0.06 0 8 2 1
Rows Row Source Operation
------- ---------------------------------------------------
0 UPDATE DEPT (cr=8 pr=0 pw=0 time=0 us)
1 NESTED LOOPS (cr=8 pr=0 pw=0 time=0 us cost=6 size=20 card=1)
1 SORT UNIQUE (cr=7 pr=0 pw=0 time=0 us cost=4 size=9 card=1)
1 TABLE ACCESS FULL EMP (cr=7 pr=0 pw=0 time=0 us cost=4 size=9 card=1)
1 INDEX UNIQUE SCAN PK_DEPT (cr=1 pr=0 pw=0 time=0 us cost=0 size=11 card=1)(object id 83537)
其他改写 例
 总结
总结
- BYPASS_UJVC提示语句
- BYPASS_UJVC提示是没有被文件化的提示语句。
- 因为存在安全性的风险,所以尽可能不要使用这个来修正应用会比较好。
- 11g无视了这个提示语句,导致了ORA-01779错误发生。
- ORA-1779错误
- 对于不是保存key的表的列进行更新时发生
- 可以利用Real Application Testing (付费Option)进行高效指定对应SQL语句。
- 回避BYPASS_UJVC提示
- 使用MERGE语句
- 使用WHERE EXISTS语句
- (使用Instead of 触发器)
【CBO Optimizer优化器】IX_SEL索引选择率
2013/04/29 by 5 Comments
ix_sel – Index selectivity 索引选择率是Oracle中CBO 基于成本优化器重要的参考指标 ,反应了符合谓词条件 通过索引主导列访问表上数据行的比例。(ix_sel – Index selectivity. Fraction of the table rows accessed by the indexes leading column in order to meet the predicate supplied. (10053)。
注意仅仅leading column即索引的主导列用作计算ix_sel
举一个简单的计算ix_sel的例子:
SQL> create index ind_maclean on sh.sales( prod_id,CUST_ID,TIME_ID);
Index created.
SQL> exec dbms_stats.gather_table_stats(‘SH’,’SALES’,cascade=>true,method_opt=>’FOR ALL COLUMNS SIZE 1′);
PL/SQL procedure successfully completed.
SQL> oradebug setmypid
Statement processed.
SQL> oradebug event 10053 trace name context forever ,level 1;
Statement processed.
SQL> explain plan for select * from sh.sales where prod_id=13 and CUST_ID=987;
Explained.
BEGIN Single Table Cardinality Estimation
—————————————–
Column (#1): PROD_ID(NUMBER)
AvgLen: 4.00 NDV: 72 Nulls: 0 Density: 0.013889 Min: 13 Max: 148
Column (#2): CUST_ID(NUMBER)
AvgLen: 5.00 NDV: 5828 Nulls: 0 Density: 1.7159e-04 Min: 2 Max: 100989
Table: SALES Alias: SALES
Card: Original: 924076 Rounded: 2 Computed: 2.20 Non Adjusted: 2.20
—————————————–
END Single Table Cardinality Estimation
—————————————–
Access Path: TableScan
Cost: 414.20 Resp: 414.20 Degree: 0
Cost_io: 389.00 Cost_cpu: 215902675
Resp_io: 389.00 Resp_cpu: 215902675
www.askmac.cn
Access Path: index (RangeScan)
Index: IND_MACLEAN
resc_io: 5.00 resc_cpu: 37017
ix_sel: 2.3831e-06 ix_sel_with_filters: 2.3831e-06
Cost: 5.00 Resp: 5.00 Degree: 1
ix_sel= 1/ (72*5828)=2.3831e-06
对于 Equality predicates 且变量可见(硬绑定或 绑定可窥视) IX_SEL=1 / (NDV1* NDV2*..)
同样变量可见情况下>、<开放范围 IX_SEL=(MAX- 代入的范围值) / (MAX-MIN)
而变量不可见(cursor_sharing=FORCE、_optim_peek_user_binds=false)的情况:
1、Equality predicates 等式谓词情况下,IX_SEL一般等于列的Density
2、 对于> <大于、小于的开放范围谓词 ix_sel一般恒等于0.009, 对于 (object_id>:i and object_id<:b;)的闭包则恒等于 0.0045
例如:
select count(*) from test where object_id>:i
Access Path: index (IndexOnly)
Index: TEST_IDX
resc_io: 3.00 resc_cpu: 160764
ix_sel: 0.009 ix_sel_with_filters: 0.009
Cost: 3.02 Resp: 3.02 Degree: 1
Best:: AccessPath: IndexRange Index: TEST_IDX
Cost: 3.02 Degree: 1 Resp: 3.02 Card: 3869.30 Bytes: 0
select count(*) from test where object_id>:i and object_id<:b
Access Path: index (IndexOnly)
Index: TEST_IDX
resc_io: 2.00 resc_cpu: 84043
ix_sel: 0.0045 ix_sel_with_filters: 0.0045
Cost: 2.01 Resp: 2.01 Degree: 1
Best:: AccessPath: IndexRange Index: TEST_IDX
Cost: 2.01 Degree: 1 Resp: 2.01 Card: 193.47 Bytes: 0
ix_sel的 0.009和0.0045 都是写死在代码里的常数值,具体可以参考下表:
/* defaults */
/* Default selectivities are set low to
keep cost values low for future resource limiter use
keep cost values low for permutation cutoff in kko
Defaults are used for bind variables, general expressions and
unanalyzed tables, except for equality where defaults are not
needed for bind variables.
*/
#define KKEDSREL 0.05 /* default selectivity for < <= > >= */
#define KKEDSEQ 0.01 /* default selectivity for = */
#define KKEDSNE 0.05 /* default selectivity for != */
#define KKEDSDF 0.05 /* default selectivity for all other ops */
#define KKEDSIRL 0.009 /* default selectivity for relation on indexed col */
#define KKEDSBRL 0.009 /* def sel for relation with bind var on index col*/
#define KKEDSIEQ 0.004 /* default selectivity for = on indexed col */
#define KKEDMBR 8 /* default multiblock read factor */
#define KKEDMBW 8 /* default multiblock write factor */
#define KKEDFNR 100.0 /* default – fixed table cardinality */
#define KKEDFRL 20 /* default – fixed table row length */
#define KKEDDNR 2000.0 /* default – remote table cardinality */
#define KKEDDRL 100 /* default – remote table avg row length */
#define KKEDDNB 100 /* default – default # of blocks */
#define KKEDDSC 13.0 /* default – default scan cost */
#define KKEDILV 1 /* default – default index levels */
#define KKEDILB 25 /* default – number of index leaf blocks */
#define KKEDLBK 1 /* default – number leaf blocks/key */
#define KKEDDBK 1 /* default – number of data blocks/key */
#define KKEDKEY 100 /* default – number of distinct keys */
#define KKEDCLF (KKEDDNB*8) /* default – clustering factor */
#define KKECRI 1.5 /* remote table access cost increase factor */
#define KKECFSC 1.0 /* fixed table scan cost */
#define KKECFNB 0 /* fixed table number of blocks */
#define KKECMXB 15 /* maximum byte length for normalization */
#define KKECBBS 256.0 /* base for byte sequence normalization */
#define KKECSPC ‘ ‘ /* space byte value */
#define KKECSPD 86400.0 /* seconds per day */
#define KKESROH 10.0 /* sort per row overhead in bytes */
#define KKESAUT 0.75 /* sort area utilization */
#define KKESROP 0.10 /* sort row overhead percent */
#define KKESRML 2.0 /* sort run multiple */
#define KKESTP 0x01 /* single table predicate */
#define KKETEQ 0x02 /* equi join */
#define KKETBCPJ 0x04 /* Cartesian product join */
#define KKESOK 0x08 /* input swap ok */
#define KKESWP 0x10 /* inputs swapped */
#define KKEEQP 0x20 /* equipartitioned */
#define KKELKNWC 0x01 /* LIKE no wild card */
#define KKELKTWC 0x02 /* LIKE trailing wild card */
#define KKELKEWC 0x04 /* LIKE embedded wild card */
#define KKELKLWC 0x08 /* LIKE leading wild card */
#define KKELKOWC 0x10 /* LIKE only wild card */
实践Oracle 性能调优-从诊断到解决
2013/04/14 by Leave a Comment
本文永久地址: https://www.askmac.cn/archives/实践oracle-性能调优-从诊断到解决.html
前言
- 本资料中,包含oracle数据库的系统中产生性能问题时,将对调查原因到完成调优为止,进行指导。
- 本资料面向对数据库具有基相关知识的人士。
- 因此,发生性能问题时的对策,仅仅讲解确认数据库是否有性能问题的方法,最多讲解处理性能问题的1个方法,但这也不是绝对的
- 请作为系统发生性能问题时的参考资料来灵活使用
发生了系统性能问题

解决的顺序
为了解决问题,需要处理与考虑方法
- 指定出现性能问题的地方
- 执行调优
确认DB的性能问题
获得DB内部的统计信息,确认其是否发生了性能问题
DB内部的统计信息是指
性能统计信息(ex. 资源使用情况以及发生待机的信息)
执行各SQL时的详细信息
<方法>
Statspack(8i~)
AWR报告(10g~)
※Enterprise Edition中需要Diagnostic Pack选项
SQL 追踪(主要在测试环境中使用)
<参考>其他的推荐事先获得的信息
OS统计信息
-CPU统计信息
-磁盘统计信息
-内存统计信息
-网络统计信息
-运行进程统计信息
OS中的统计信息因为含有包含oracle以外的部分的服务器整体的资源信息
所以即使原因可能出在DB中,也可以获得

在分析之前需要了解Statspack是什么
在使用DB内部的统计信息进行分析之前,先需要获得统计信息
理解各个方法的概要
<方法>
Statspack(8i~)
AWR报告(10g~)
※Enterprise Edition中需要Diagnostic Pack选项
SQL追踪(主要在测试环境中使用)
Statspack(Statistics Package)
Statspack 的意思是
从Oracle 8i 安装的oracle标准的性能分析工具
使用Statspack 的话
某段期间内,还可以确认oracle的运行情况
基本的Statspack使用流程
- 安装之后,可以定期获得统计信息
- 发生问题时,会将累积的统计信息生成报告
- 比较现有的报告(必要的话还可以同时比较过去的报告)进行分析
确认Statspack 的的信息,确认在执行SQL时,到底是什么原因导致了性能恶化
Statspack的机制
Statspack是两个不同时点分别作为snapshot来记录,仅仅从差异中输出报告
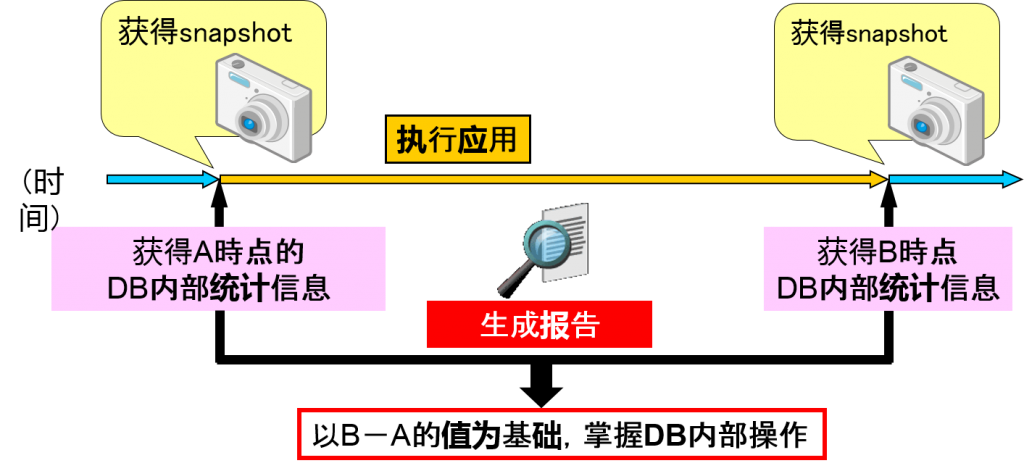
灵活地输出报告
输出报告时,可以指定使用任何snapshot,可以灵活地变更输出范围
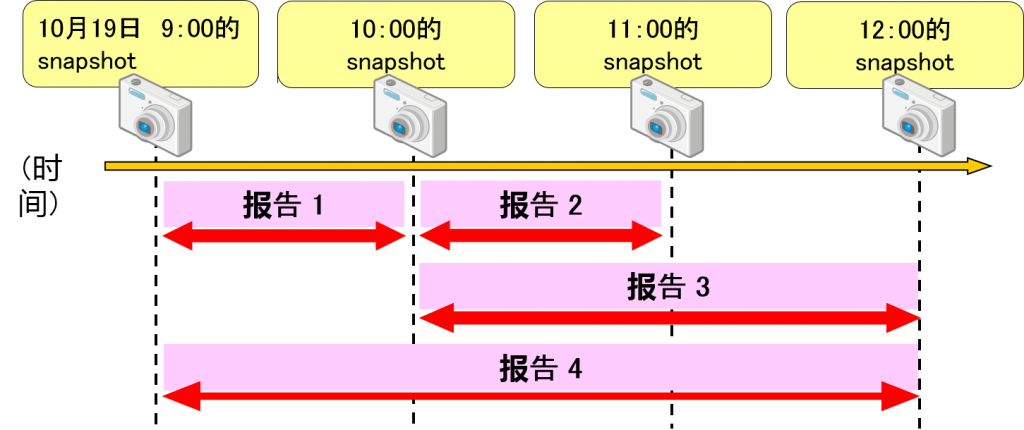
<参考>通过Statspack获得的信息(9iR2,10g,11g)
leve水平(获得的信息详细程度)设定参考基准
一般正常运行时默认为Level 5,如果感觉到“最近变得有点慢了”的时候,可以遵循oracle技术支持的意见调整为Level 6 、Level 7、或者Level 10(高负荷)
| Snapshot level | 收集数据 | |||||
| 基本统计信息 | 建议信息 | SQL统计信息 | SQL详细信息 | 段信息 | latch详细信息 | |
| Level 0 | ○ | ○ | ||||
| Level 5 | ○ | ○ | ○ | |||
| Level 6 | ○ | ○ | ○ | ○ | ||
| Level 7 | ○ | ○ | ○ | ○ | ○ | |
| Level 10 | ○ | ○ | ○ | ○ | ○ | ○ |
Statspack 使用顺序
Statspack的使用顺序如下所示
Step1 安装・设定
首次使用Statspack时,可以创建执行用的用户,同时可以设定密码与表空间
Step2 获得snapshot
根据情况不同自动获得snapshot level,或者调整snapshot level
Step3 创建报告
选择开始与终止的snapshot 输入文件名
使用了Statspack的脚本已经在导入了DB的环境中准备好了,只要连接到DB,就可以执行脚本
执行安装脚本
Statspack相关的操作全部都是通过执行用用户(PERFSTAT)来执行的,所以需要创建执行安装脚本的PERFSTAT用户
1.通过SQL*Plus,作为拥有SYSDBA权限的用户来连接DB
2.执行安装脚本(spcreate.sql)
# 以SYSDBA权限连接到SQL*Plus
SQL> connect sqlplus / as sysdba
# 执行安装・脚本
SQL> @$ORACLE_HOME/rdbms/admin/spcreate.sql
设定密码与表空间
设定PERFSTAT 用户的密码、在Statspack中所使用的默认表空间以及临时表空间
1.执行脚本,PERFSTAT用户的密码,默认表空间,临时表空间
# 设定执行用户的密码
在perfstat_password中输入值:<输入password>
# 设定默认表空间
在default_tablespace中输入值:<输入表空间名>
# 设定临时表空间
在temporary_tablespace中输入值:<输入表空间名>
默认表空间推荐多设定300MB的冗余
获得snapshot
用PERFSTAT用户连接到DB,通过snapshot来获得统计信息
1.通过PERDSTAT用户执行statspack.snap
2.必要的话可以通过i_snap_level => 来设定获得信息的详细程度(level)(用户没有指定level时,以默认值的level5来获得)
#获得 snapshot
SQL> execute statspack.snap(I_snap_level => 6);
l记录重复snapshot,通过在某个时间点的snapshot,作为报告来输出,可以获得特定期间内的DB统计信息
报告的创建
1.通过PERDSTAT用户来执行spreport.sql
SQL> @?/rdbms/admin/spreport.sql # 创建报告脚本を执行
・
・
~省略~ Snap
Instance DB Name Snap Id Snap Started Level Comment
———— ————— ———– —————————— ——— —————
orcl1 ORCL 1 17 10月 2008 12:17 5
11 20 10月 2008 09:29 5
・
・
Specify the Begin and End Snapshot Ids
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
在begin_snap中输入值:
输入snapshot ID
指定开始、终止获得统计信息范围的时间点的snapshot ID,输出报告
1.参考Snap Id,输入起始snapshot以及终止snapshot ID
2.输入报告名
Specify the Begin and End Snapshot Ids
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# 输入起始snapshot ID
请在begin_snap中输入值: <输入Snap Id 例:1>
# 输入终止snapshot ID
请在end_snap中输入值: <输入Snap Id 例:11>
#输入 报告名
请在report_name中输入值: <输入报告名>
删除snapshot
获得的性能统计信息只要不明确地删除,无论何时都会被保留,根据不同情况可能会挤压储存区域
因此,请删除不需要的统计信息
1.通过PERFSTAT用户来执行sppurge.sql
2.指定想删除的范围的起始于终止时点,指定snapshot ID
SQL> @?/rdbms/admin/sppurge.sql #执行删除的脚本
Specify the Lo Snap Id and Hi Snap Id range to purge
Statspack 实际的报告输入例
STATSPACK report for
Database DB Id Instance Inst Num Startup Time Release RAC
~~~~~~~~ -------------- ------------ ------------- ----------------------- --------------
1196126054 orcl1 1 17-10月-08 11:40 11.1.0.7.0 YES
Host Name Platform CPUs Cores Sockets Memory (G)
~~~~ ------------------------- ---------------------- ----- ----- --------- ------------ -----------------
jpintl005.jp.ora Linux IA (32-bit) 8 8 2 4.0
Snapshot Snap Id Snap Time Sessions Curs/Sess Comment
~~~~~~~~ ---------- ---------------------------------- ------------- --------- ------------------
Begin Snap: 36 21-10月-08 19:46:15 38 1.0
End Snap: 37 21-10月-08 19:47:51 38 1.0
Elapsed: 1.60 (mins) Av Act Sess: 0.4
・
・
・
・
・
・
SQL ordered by Elapsed time for DB: ORCL Instance: orcl1 Snaps: 36 -37
-> Total DB Time (s): 42
-> Captured SQL accounts for 195.5% of Total DB Time
-> SQL reported below exceeded 1.0% of Total DB Time
Elapsed Elap per CPU Old
Time (s) Executions Exec (s) %Total Time (s) Physical Reads Hash Value
---------- ------------ ---------- ------ ---------- --------------- ----------
40.69 1 40.69 95.9 40.67 0 3417014992
Module: SQL*Plus
declare v_num number; begin for i in 1..10000 loop selec
t c1 into v_num from t1 where c1 = 100; end loop; end;
40.48 10,000 0.00 95.4 40.46 0 2968801179
Module: SQL*Plus
AWR报告是指什么
AWR(自动负载库)
从Oracle 10g开始会自动获得DB内部的统计信息(snapshot)
AWR是使得Statspack进化的功能
- 与Statspack相同,可以经常观察到以低负荷来创建各种报告
- 通过Enterprise Manager(EM),可以变更、查看设定内容
- 可以通过ADDM来自动进行性能减少/诊断
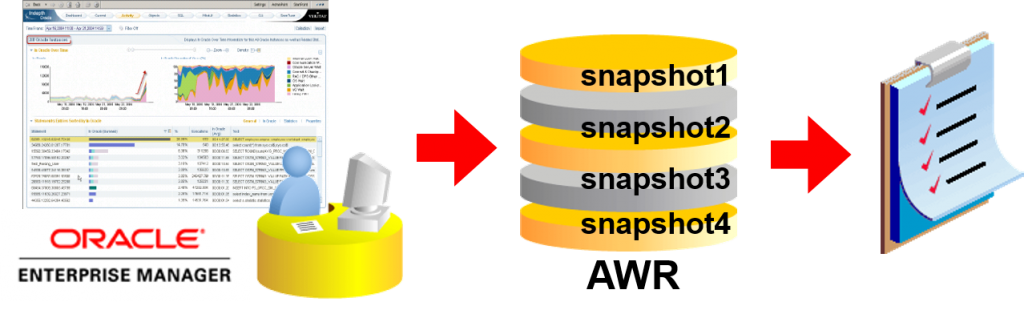
AWR在创建DB时,也会在SYSAUX表空间中创建 -不需要安装
MMON(Memory Monitor)会定期获得SGA的信息
-默认1小时内保存1次snapshot(11g中是8天)
-想查看、变更设定内容的话,需要Oracle EM可以使用
执行自动删除旧数据
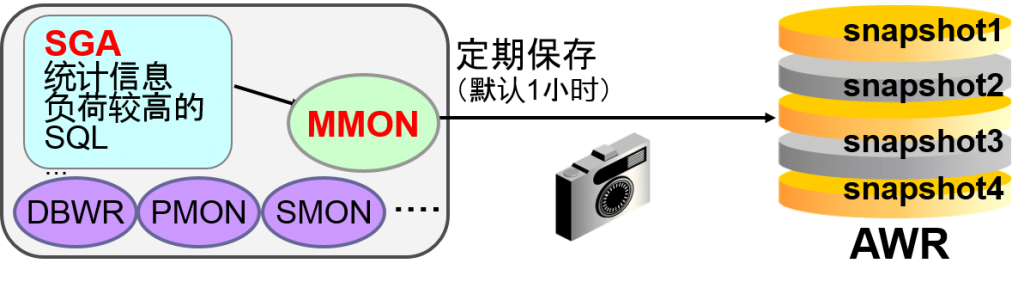
比较Statspack与AWR的报告

Statspack 报告的分析
分析点
- 吞吐量与负荷(Load Profile)
- 实例效率(Instance Efficiency)
- 待机 项目(Top-5 Timed Events)
- SQL的详细信息(SQL ordered by ~)
特别是在正式环境中使用时,根据业务内容与时间段不同,所收集到的统计信息也会不同,所以我们推荐多多比较多个报告
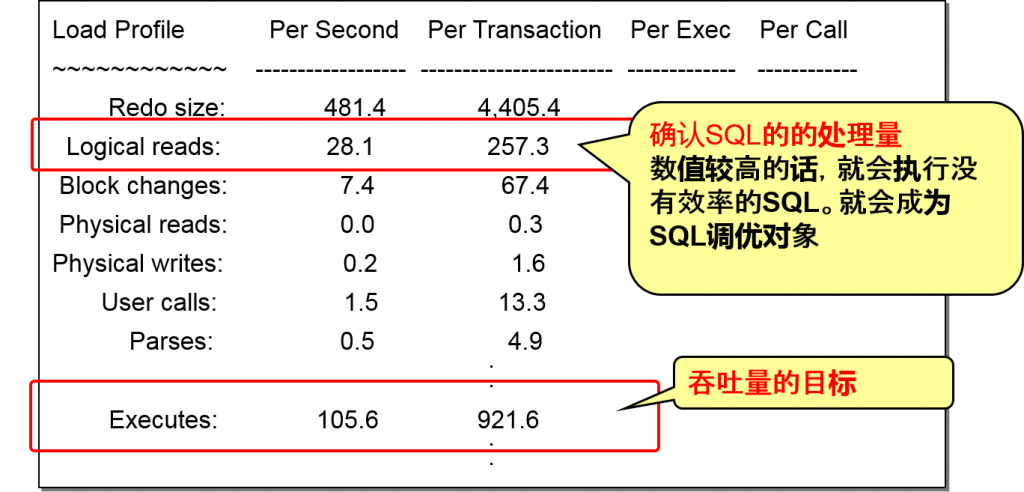
Load Profile 负荷状況的读取
伴随着磁盘访问,我们需要着眼于是否会有数据的读入、写入,在DB的处理中,找出容易成为瓶颈的物理I/O
Instance Efficiency 实例效率.
确认DB缓冲区高速缓存命中率,确认实例是否高效运行
越接近100%就越好
参考値大于80%-% Non-Parse CPU
90%以上-Buffer Hit%、Optimal W/A Exec%、Sort Parse%
95%以上-Library Hit%、Redo Nowait%、Buffer Nowait%
100%以上-Latch Hit%
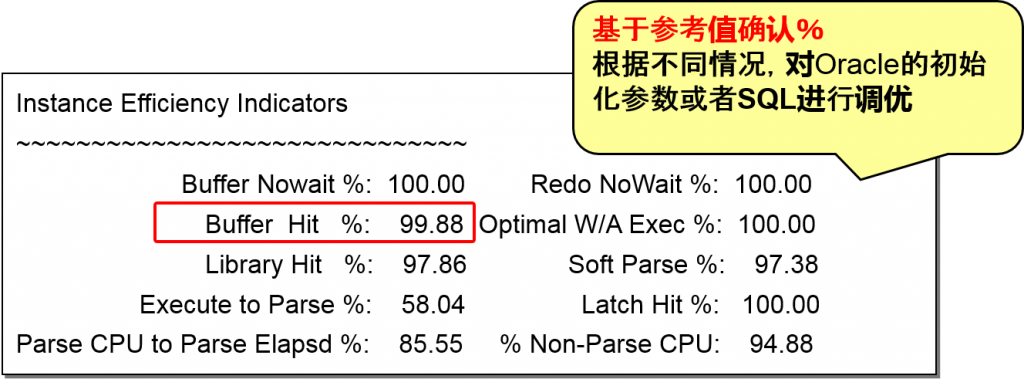
| 参数名 | 説明 |
| Buffer Hit% | 高速缓存中所拥有的需要的数据的比例 |
| Library Hit % | Library cache中所拥有的需要的数据的比例 |
| Soft Parse % | 所有解析中可以重复利用的比例 |
| In-Memory Sort% | Sort在内存中执行的比例 |
| Latch Hit% | 所有latch的命中率 |
| Parse CPU to Parse Elapsed % | 解析CPU时间/ 解析的总计时间 |
| Execute to Parse% | 因为执行SQL而没执行解析的比例 |
| %non-parse CPU | 解析之外所使用的CPU时间的比例 |
| Buffer Nowait% | 高速缓冲区中提出需求时,可以马上应用的比例 |
| Redo Nowait% | 对redo log提出需求时,可以马上应用的比例 |
Top-5 Timed Events 待机 项目
检查实例level中待机时间前五的项目,确认监视对象的实例性能是否降低
Waits :项目待机的总次数
Time(s) :项目总计待机时间以及总计CPU时间(秒)
Avg wait(ms) : 项目平均待机时间
% Total Call Time: time for each timed event / total call time Total call time total CPU time + total wait time for non-idle events
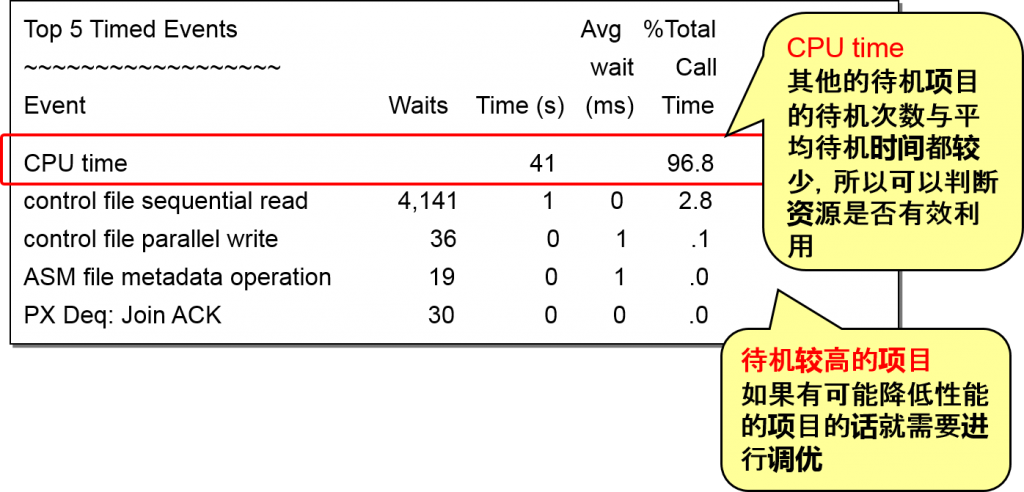
等待事件是什么?
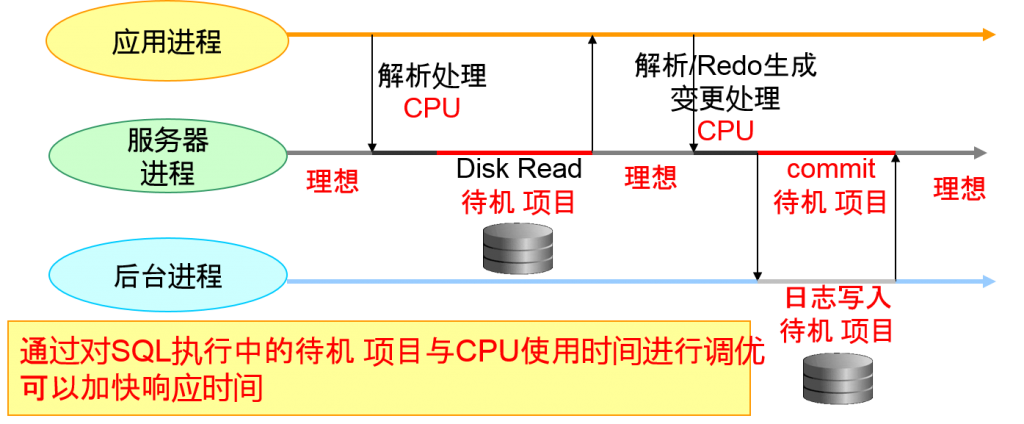
- 进程没有使用CPU的时间
- 理想待机 项目(SQL的需求等待)
- 有瓶颈时,意味着原因并不是DB资源
- 其他待机 项目(SQL执行中)
- DB资源(缓冲区竞争、I/O竞争、latch竞争等等)相关的待机时间
通过对SQL执行中的待机 项目与CPU使用时间进行调优 可以加快响应时间
SQL ordered by ~ SQL的处理信息
确认各SQL读入的缓冲区数以及磁盘的访问次数,确认是否使用了资源使用量较高的SQL

SQL trace是什么?
使用SQL trace的话就可以获得比执行SQL执行时更详细的信息通过分析刚刚获得的信息,就可以指定出现问题的SQL
SQL trace的获得方法如下所示
1. 获得所有会话信息的方法
2. 获得指定的会话信息的方法
获得的信息中,各个SQL包含以下信息
- 语句的分析、执行,fetch的执行次数
- CPU时间、消耗时间
- 物理读入(Physical read)、理论读入(Logical read)
- 处理的行数
SQL trace使用顺序
获得所有会话信息时
1. 设定初始化参数SQL_TRACE为TRUE
2. 重启Oracle
重启之后需要重新设定为FALSE,在重启期间,每次开始会话就都会创建追踪文件,就会输出各个会话的所有信息
仅仅获得指定应用的追踪方法
对应用中想开始SQL trace的point追加以下SQL语句
ALTER SESSION SET SQL_TRACE=TRUE;
这时,获得 trace期间,可以设定终止应用或者将SQL_TRACE设定为 FALSE
通过TKPROF进行的格式化
lSQL trace的输出结果通过使用TKPROF,可以以更加简明的形式来进行格式化
<UNIX/Linux环境中执行TKPROF的例>
TKPROF命令中orcl1_ora_12059.trc 这个trace文件,对 tkprof_1.prf进行格式化
$ tkprof orcl1_ora_12059.trc tkprof_1.prf
※ TKPROF的执行Module名由于环境不同而不同,具体请参考手册
TKPROF的输出例

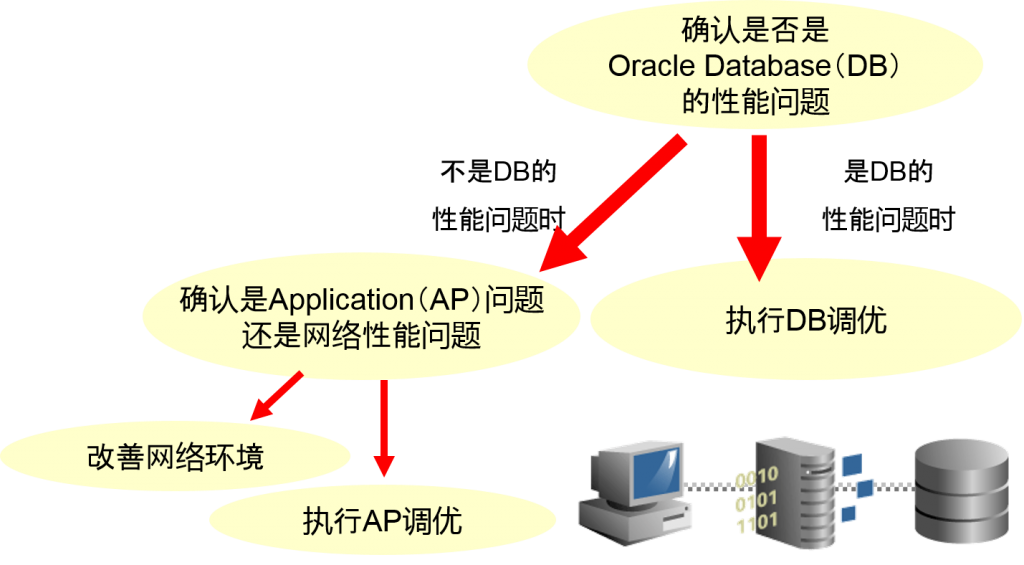
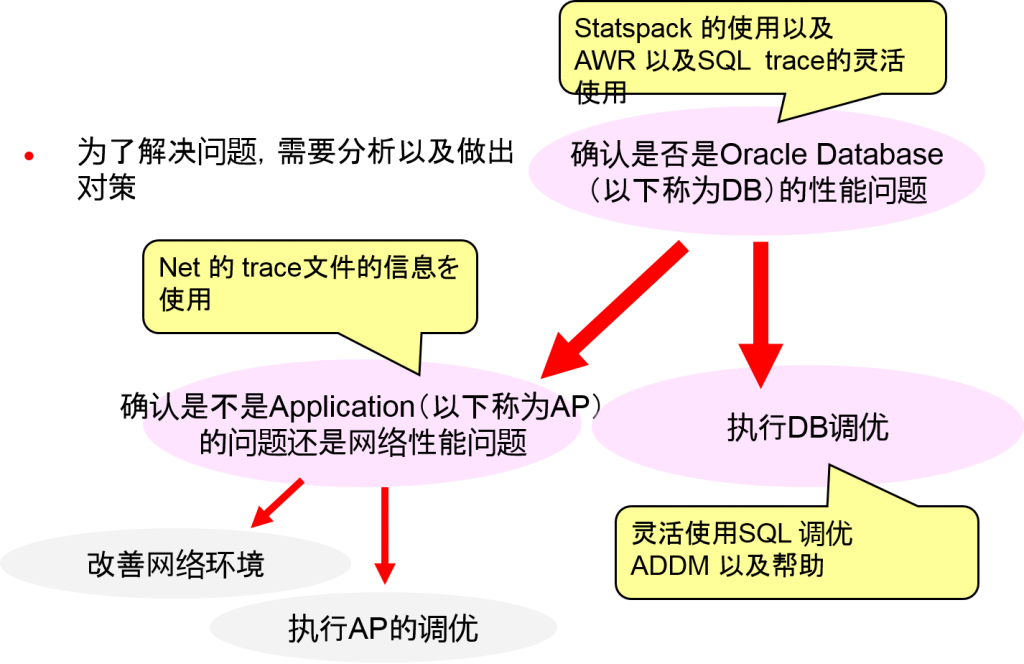
弄清楚是应用程序的问题还是网络问题
判断DB中的性能问题时需要调查到底是AP问题还是网络问题
Net 的 trace文件:确认通信(packet)的处理信息
Net的 trace文件是指什么?
每个网络组成(listener・客户端・服务器等等)都可以在信息交换是,生成 trace信息
获得网络通信时的 trace信息,指定获得的信息交换中可能产生性能问题的地方
※listener与服务器的 trace每次连接与启动时,都会创建得比客户端量要更多的
首先我们推荐检查客户端(可能的话请检查服务器)的 trace

使用trace时需要考虑的问题
1.需要充分确保磁盘空间
trace以及日志可能使用大量磁盘空间
另外,通常使得设定无效。或者定期删除日志文件,尽量不对进程增加负荷
2.输出地址文件的位置 我们不推荐所有用户来写入的swap space
3.输出地址是否具有对目录的写入权限 连接用户、oracle软件拥有者、listener启动用户来写入
注意: trace功能中,因为使用了大量磁盘区域,可能造成系统 性能大幅降低。所以只有在必要时才能使用trace
客户端中的 trace设定方法
<设定方法>
l通过客户端系统的sqlnet.ora文件来设定以下参数
TRACE_LEVEL_CLIENT
TRACE_DIRECTORY_CLIENT
TRACE_UNIQUE_CLIENT
8.0.6 以后会记录以下参数
TRACE_TIMESTAMP_CLIENT
通过上述设定之后,客户端每次新建连接时都会在指定目录中生成trace文件
XXX.trc 这个文件,只要在 trace子目录中输出了的话就成功了
获得客户端的 trace相关的注意事项
<获得方法>
通过Oracle Net Services 11g (11.1.0) 将默认的 trace输出地址设定为Automatic Diagnostic Repository (ADR)
为了在通过TRACE_DIRECTORY_CLIENT指定的目录中输出,可以指定以下参数
默认为$ORACLE_HOME/log/diag
sqlnet.ora
DIAG_ADR_ENABLED=OFF
<参考>服务器的 trace也与客户端的情况相同 listener的 trace的情况如下所示
listener.ora
DIAG_ADR_ENABLED_<listener名>=OFF
tracelevel
设定通过TRACE_LEVEL_CLIENT获得的信息
正常运行时,一般为0或者OFF(默认),参考下列表,根据需求变更level
| trace level | 収集数据 |
| 0或者OFF | 没有trace的输出 |
| 4或者USER | 用户・ trace信息 |
| 10或者ADMIN | 管理 trace信息 |
| 16或者SUPPORT | Cluster 支持・ trace信息 |
客户端的 trace文件获得例
XXX.trc 这个文件是在trace子目录中输出了的话就成功
| [21-JUN-2006 10:58:29:081] nscon: doing connect handshake…
[21-JUN-2006 10:58:29:081] nscon: sending NSPTCN packet [21-JUN-2006 10:58:29:081] nspsend: entry [21-JUN-2006 10:58:29:081] nspsend: plen=242, type=1 [21-JUN-2006 10:58:29:081] nttwr: entry [21-JUN-2006 10:58:29:081] nttwr: socket 288 had bytes written=242 [21-JUN-2006 10:58:29:081] nttwr: exit [21-JUN-2006 10:58:29:081] nspsend: 242 bytes to transport [21-JUN-2006 10:58:29:081] nspsend: packet dump [21-JUN-2006 10:58:30:081] nsprecv: 00 CD 00 00 06 00 00 00 |……..| [21-JUN-2006 10:58:30:081] nsprecv: 00 00 08 00 01 00 00 00 |……..| [21-JUN-2006 10:58:30:082] nsprecv: 0C 0C 41 55 54 48 5F 53 |..AUTH_S| [21-JUN-2006 10:58:30:082] nsprecv: 45 53 53 4B 45 59 00 00 |ESSKEY..| [21-JUN-2006 10:58:30:082] nsprecv: 32 37 46 32 45 38 39 36 |27F2E896| ・ ・ |
分析的基本思路
[21-JUN-2006 10:58:30:081] nsprecv: 00 CD 00 00 06 00 00 00 |……..|
分析数据・packet的收发信息所花费的时间
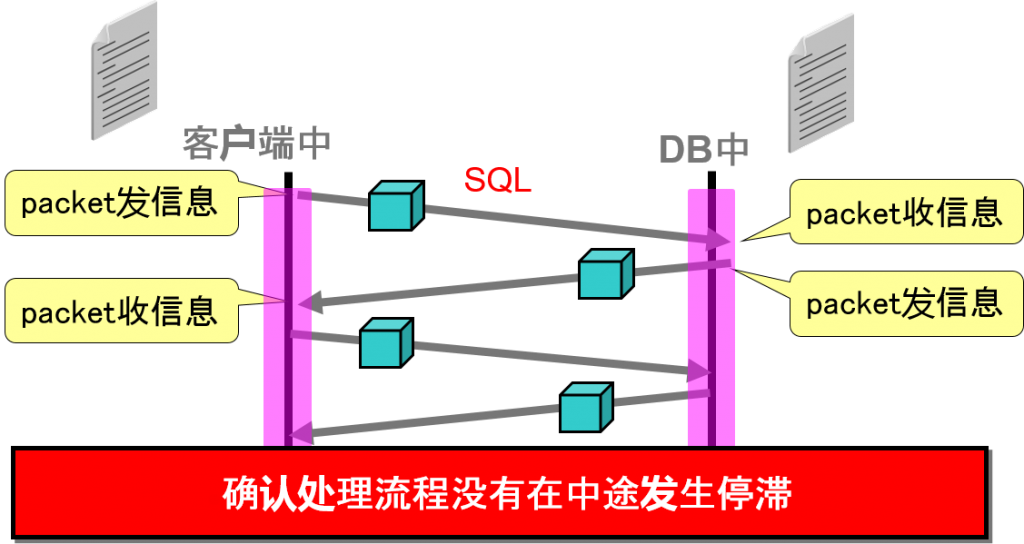
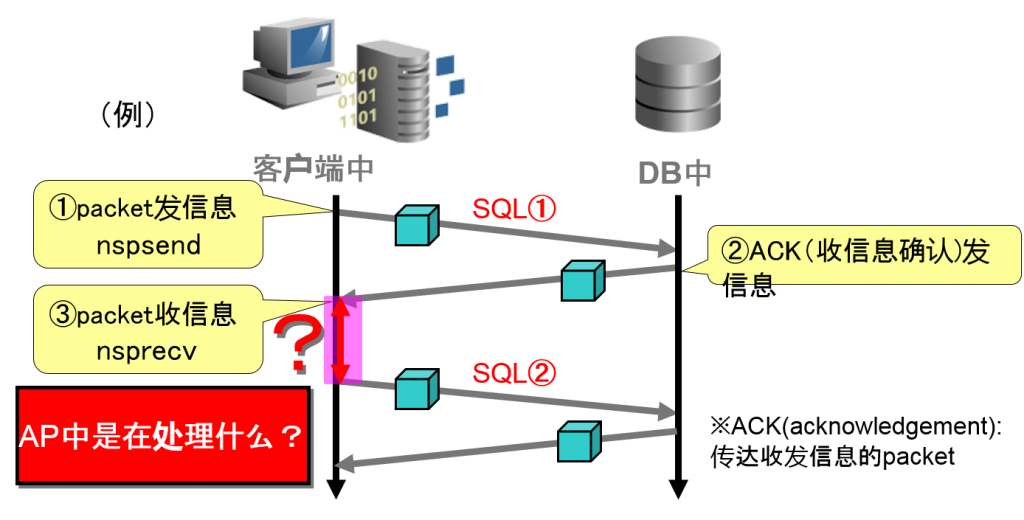
性能问题的区分①应用程序的问题例
客户端中的nsprecv(收信息)到nspsend(发信息)所花费的时间
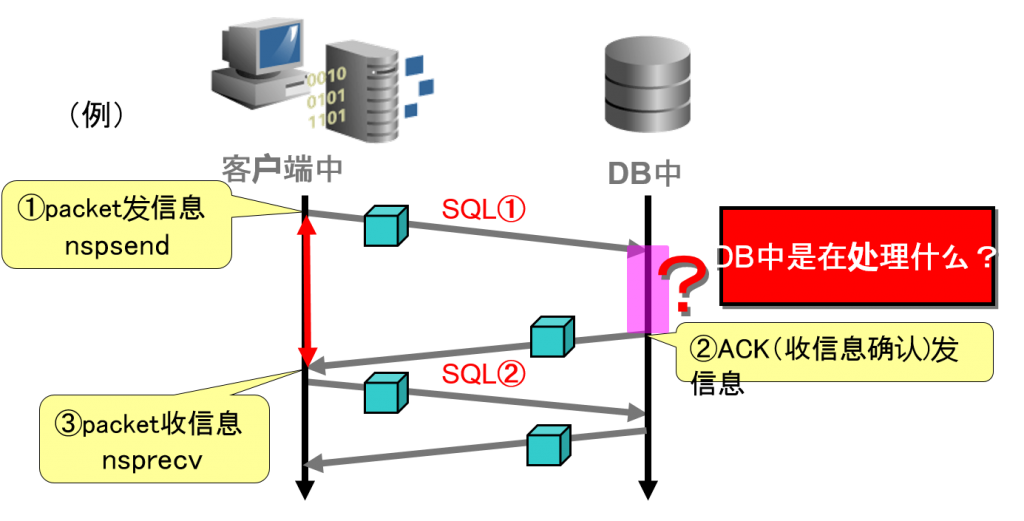
性能问题的区分②DB中的问题例
客户端中的nspsend(发信息)到nsprecv(收信息)所花费的时间
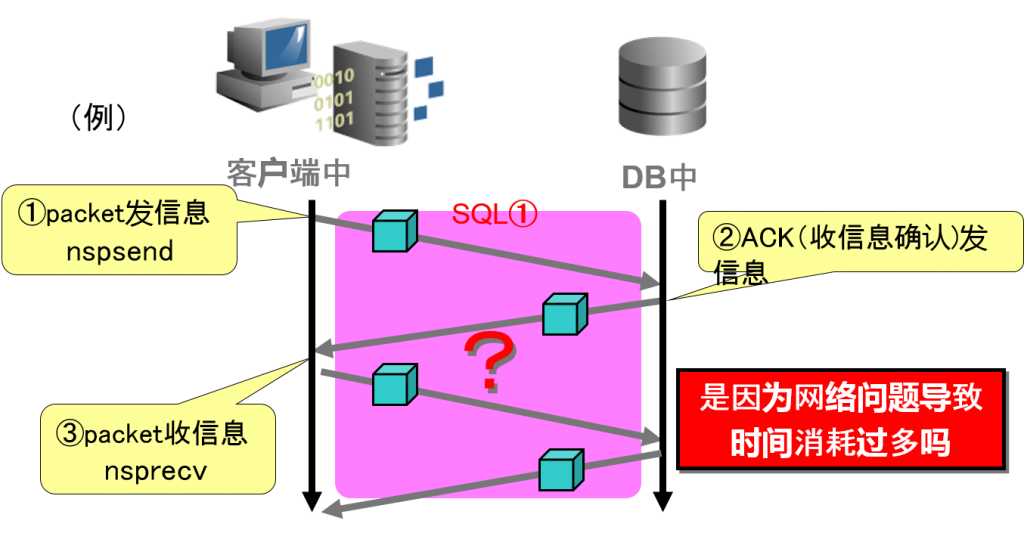
性能问题的区分例③N/W的问题例
客户端中的nspsend(发信息)到nsprecv(收信息)为止,似乎没有等待时机,考虑到处理内容,收发信息的时间也花费太多了。
数据库调优
参考分析中使用过的信息,执行合适的调优
- SQL调优
- 索引
- 提示HINT
- 使用ADDM的调优
- 使用各个建议的调优
- 确认效果
- 确认使用了AUTOTRACE的调优效果
索引调优 例
Statspack的SQL ordered by Gets的确认

索引的创建与删除
索引的创建
SQL> create index c1_index on t1(c1);
索引的删除
SQL> drop index c1_index;
即使建索引了,也会在下列情况中进行全表扫描,请大家注意
- 搜索NULL值
- 计算索引列
- 隐秘地变更数据类型
- 使用LIKE语句的中间一致、后方一致搜索
- 使用!=和<>
索引的效果

提示HINT的使用
- 通过使用提示HINT,就会用到指定的访问路径,可以在优化中进行指定
<例>
- 指定使用合适的索引(Index)
- 指定合适的表结合方法以及结合顺序
- 指定CBO的目标(重视吞吐量或者面向 OLTP等) etc.
- 提示HINT的使用例 ( 在/*+ 与 */之间指定提示HINT、直接嵌入到SQL中 )
(例)就会使用表t1的c1列中附加的c1_indx这个Index
SQL>select /*+INDEX(t1 c1_index) */ * from where c1=100;
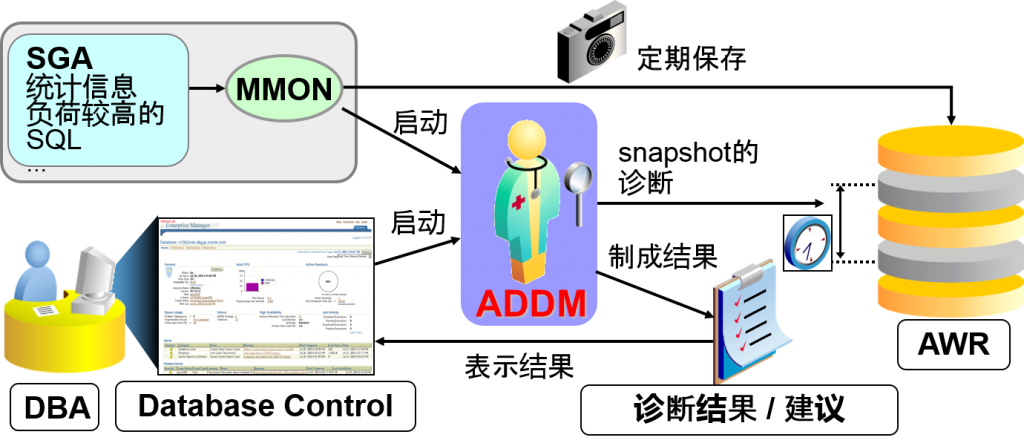
ADDM 自动数据库检测监视器
(Automatic Database Diagnostics Monitor)
- 基于AWR中所示收集的统计信息,定期监视、诊断性能的,面向DB管理者(DBA)的功能
帮助功能
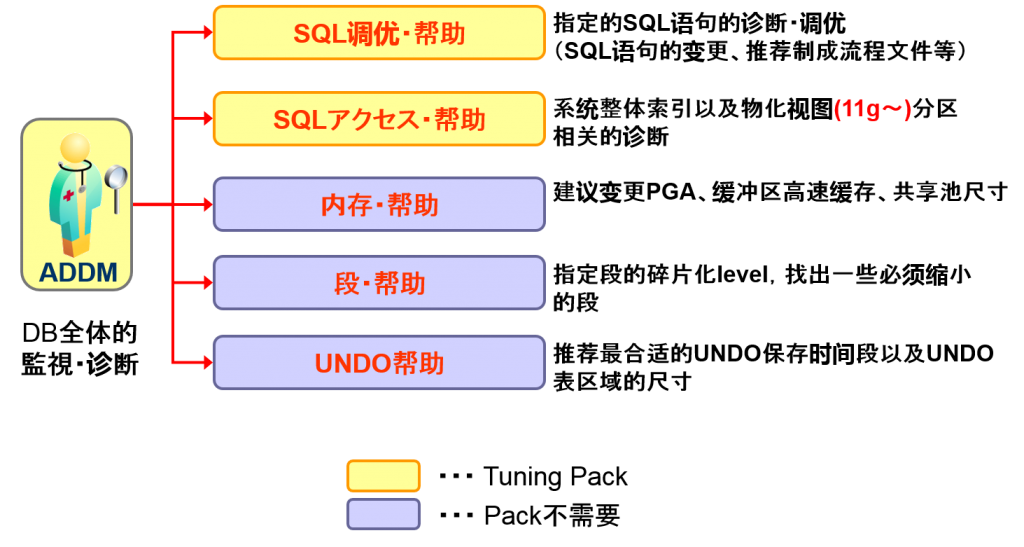
SQL调优・帮助
- 诊断因为高负荷而发生问题的SQL语句以及执行计划
- 以诊断为基础给予建议
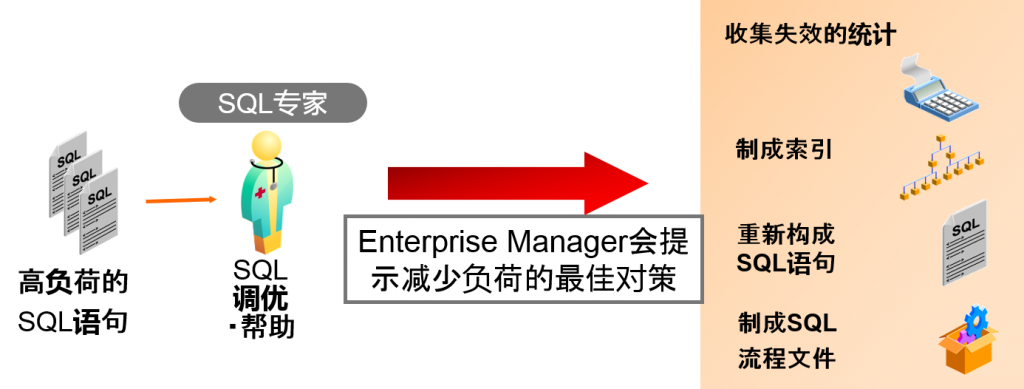
调优的流程

确认调优效果
随着SQL语句变得复杂,调优方法也越来越多,可能为了达到目标效果需要
反复调优,如果使用SQL*Plus的AUTOTRACE功能的话就能当即确认效果了
l要使用AUTOTRACE的话需要确认一下几条项目
- lSQL*Plus中执行的SQL语句
- 执行计划的结果
- 统计信息
-物理读入 -論理读入
-REDO尺寸 -内存sort 尺寸
-处理件数 -磁盘sort 尺寸
AUTOTRACE功能的设定顺序
lAUTOTRACE的设定顺序如下所示
Step1 创建PLUSTRACE 角色(仅限首次)
SQL> connect sqlplus / as sysdba
SQL> @$ORACLE_HOME/sqlplus/admin/plustrce.sql
Step2 对使用用户赋予已创建的PLUSTRACE角色
SQL> grant plustrace to <用户名>
Step3 通过使用用户创建AUTOTRACE功能将要使用的工作用的表
SQL> @$ORACLE_HOME/sqlplus/admin/utlxplan.sql
每个想使用AUTOTRACE功能的用户都需要重复Step2与Step3
AUTOTRACE的获得
1.通过使用用户执行SET AUTOTRACE命令
SQL> set autotrace on
2.SQL执行
SQL> select * from t1 where c1 = 100;
※想终止AUTOTRACE功能时
SQL> set autotrace off
AUTOTRACE的获得的例子

总结
【Maclean技术分享】开Oracle调优鹰眼,深入理解AWR性能报告 第二讲
2013/04/10 by 11 Comments
Oracle调优鹰眼系列只有2讲,对AWR感兴趣的同学更多指标可以参考 【性能调优】Oracle AWR报告指标全解析 https://www.askmac.cn/archives/performance-tuning-oracle-awr.html
【技术分享】开Oracle调优鹰眼,深入理解AWR性能报告 第二讲
涉及性能优化教学知识:Host CPU、Instance CPU、Wait Class、SQL Statistics、AWR FOR RAC集群特定调优 https://zcdn.askmac.cn/oracle%20awr%20hawk%202.mp4
适合的学员: 对性能优化有兴趣,或给予提升自己Oracle调优技能的同学
预计时长: 2个小时左右
本次公开教学的视频地址:
正式版文档材料已上传:
【Maclean Liu技术分享】开Oracle调优鹰眼,深入理解AWR性能报告 第二讲 正式版 20130.pdf (2.27 MB, 下载次数: 30699)
适合参与成员: 对性能优化有兴趣或急于提升自己oracle技术水平的学员
讲座材料presentation 当前版本下载:
【Maclean Liu技术分享】开Oracle调优鹰眼,深入理解AWR性能报告_20130303版.pdf.pdf (1.79 MB, 下载次数: 32641)
GATHER_STATS_JOB: Stopped by Scheduler. Consider increasing the maintenance window duration if this happens frequently.
2013/04/05 by Leave a Comment
《Does GATHER_STATS_JOB gather all objects’ stats every time?》一文中 , 我们详细介绍了GATHER_STATS_JOB的一些特点,例如数据库一直打开的情况下,GATHER_STATS_JOB会伴随维护窗口一起被启动,默认情况下如果到维护窗口关闭该JOB仍未结束则将被终止(这取决于该JOB的属性stop_on_window_close),剩下的有待收集信息的对象将在下一个维护窗口中得到处理。
在版本10gR2中对于那些需要收集而在维护窗口中没来及收集的对象,会由执行收集作业的J00x作业子进程写出哪些没能来得及收集对象的名单,例如:
GATHER_STATS_JOB: Stopped by Scheduler.
Consider increasing the maintenance window duration if this happens frequently.
The following objects/segments were not analyzed due to timeout:
TABLE: “MACLEAN”.”HANA”.”ORACLE”
……………………
error 1013 in job queue process
ORA-01013: user requested cancel of current operation
对于统计信息收集在版本12c中得到进一步的加强的dbms_stats.REPORT_GATHER_AUTO_STATS可以告知用户其将自动收集哪些对象。
已经几乎不需要修正应用了! 划时代的SQL调优方法
2013/04/01 by Leave a Comment
https://www.askmac.cn/archives/sqltuning-sql-profile.html
- 以前的SQL调优
- SQL Profile是什么
- 调优执行顺序
- 经常被问到的问题
- 总结
<一般而言SQL的调优流程>
- 诊断/指定瓶颈
- 执行合适的调优
- 检查效果
- 根据需要进一步调优
・Automatic Database Diagnostic Monitor(ADDM)
ADDM是监视/诊断数据库性能的功能。
发现内存不足以及I/O问题、性能较差的SQL、Real Application Clusters(RAC)相关的问题等等各种问题,给数据库管理者提供建议。
那时,会为数据库管理者提供解决问题所需要进行的操作提出建议,数据库管理者就可以高效解决问题。
ADDM与其他建议相同都可以手动启动来诊断数据库,但一般而言是定期性地自动启动,监视数据库是否有性能问题。
ADDM自动启动的时机是在取得AWR的snapshot时,通过取得了snapshot的MMON进程来自动启动
手动启动ADDM的情况下,可以诊断过去任一时间点的数据库。
ADDM是从两个snapshot中取得数据库的负荷信息,进行诊断。
自动启动的情况下,使用最新取得的snapshot以及1个之前的snapshot,手动启动的情况下,用户可以指定任意两个snapshot。
要使用这个功能的话,需要将STATISTICS_LEVEL 初始化参数设定为TYPICAL(默认)或者ALL。
SQL较慢的时候,首先要寻找原因!
以前的SQL调优
<一般而言SQL的调优流程>
- 诊断/指定瓶颈
- STATSPACK:
与DB整体的统计一起收集SQL统计 - EXPLAIN PLAN:
在每个SQL中表示执行计划 - SQL TRACE与TKPROF:
收集以session等单位来执行的SQL执行的统计信息,并且
总结结果报告。
- SQL*Plus的AUTOTRACE機能:
在每个SQL中表示执行计划以及性能统计
2.执行合适的调优
- 优化的选择<到Oracle 9i 为止>
- RBO ( Rule-based optimizer )<到Oracle 9i 为止>
- 重新检查物理設計(Index相关)
- SQL的改写 etc..
- CBO ( cost-based optimizer )
- 取得合适的对象的统计信息
- 使用优化提示 不知所措时一定要使用这个功能!
- 检查Partitioning导入
- 并行处理的检验 etc..
3.检查效果 =》 根据需要进一步调优
优化提示
- 通过使用提示、可以指示优化使用特定的访问路径
<例>
- 指定使用合适的index
- 指定合适的表结合方法与结合顺序
- 指定CBO的目标(重视吞吐量 or面向 OLTP 等) etc.
- 在使用RULE提示以外的情况下,就会自动执行CBP的最优化
- 提示的使用例子( /*+ 与*/ 之间指定提示、直接嵌入到SQL中 )
- 使其使用附着与sales表的customer_id列的cust_id_indx这个index。
SELECT /*+ INDEX(sales cust_id_indx) */ sales_date , sales_amount
FROM sales WHERE customer_id=‘ABE’;
SELECT /*+ USE_HASH(s c) LEADING(c s) */ *
FROM sales s , customers c
WHERE s.customer_id=c.customer_id AND s.sales_amount > 1000;
以前的SQL调优的缺点
HINT提示的缺点
- 每个SQL都需要自定义
- 要求高度的知识存量与技巧
- 性能恶化时,需要修正应用
某些SQL语句可以高速嵌入提示,但这就不得不对应用进行修正。
在package应用中无法使用提示!
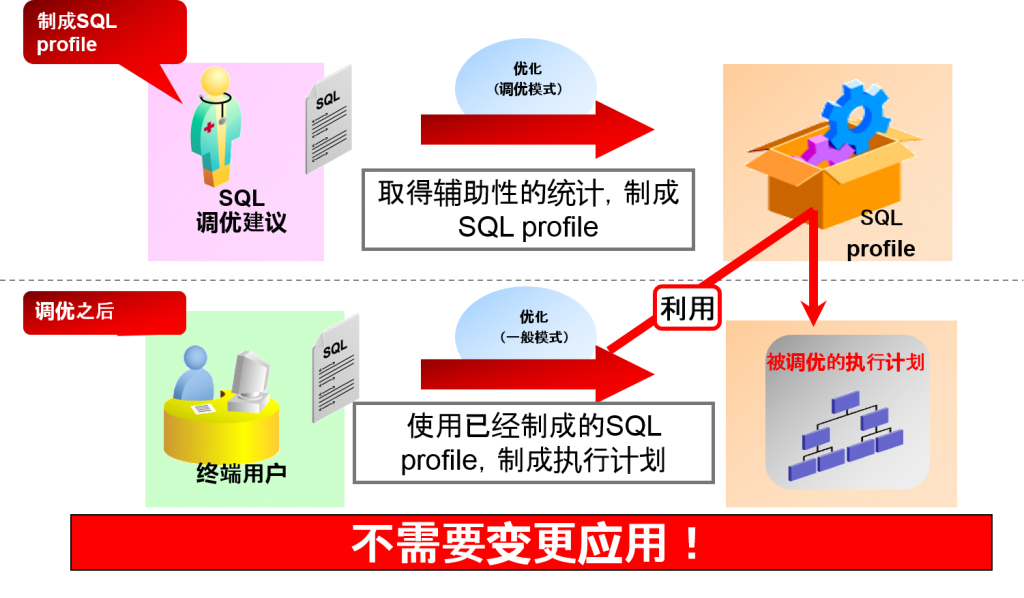
SQL Profile是什么
每个SQL中取得的固有的辅助性的统计信息
SQL Profile直到被删除或者被重新制作为止,都在数据库中保持原样
优化需要用到SQL Profile以及现存的优化统计两方面才能制成执行计划
Oracle Database 10g 开始,追加 SQL调优建议,从这里开始生成
简而言之
制成服从建议的SQL profile的话,执行计划也会最优化。 =》 原因是 数据库有如提示一样可以改善执行计划的统计信息!=》
如果使用SQL profile的话、、就可以不修正应用,但又能实现与提示同样的效果!!
SQL profile的制成与使用
(实际应用SQL profile之后,会说明直到Active session降低为止所需要等待的时间)
SQL profile是指SQLTuning Advisor,收集的辅助统计信息。
通过接受被提示的SQL profile,就可以不加工SQL就控制执行计划。
<追加>
SQL profile是在10g中得到强化的功能之一,特征是不全面变更应用就可以进行调优。
SQL调优建议
- 在高负荷背景下诊断有问题的SQL语句以及执行计划
- 诊断结果是?
- 寻找SQL语句的问题点,SQL语句的修正方法
- 建议制成必要的索引
- 制成SQL profile
一般而言,SQL调优建议等一系列的自动调优功能是从GUI的管理工具
Oracle Enterprise Manager 10g开始执行的。

SQL profile:经常出现的问题
Q1. 制作一个SQL profile的话、能够加速多个SQL吗?

Q2. 执行SQL调优建议时,可以明确指定制成SQLprofile吗?
A2. 不可以。
SQL调优建议是在分析SQL的时候,为了改善性能,做出最合适的建议的功能。在手动调优中,比起使用提示进行调优,制成index的效果更好的情况下,请选择制成index。与此相同在只要制成index就可以明显改善性能的情况下,不会建议制成SQL profile。
Q3. 可以确认SQL profile的内容吗?
A3. 无法确认SQL profile的内容。(SQL profile的列表可以通过搜索DBA_SQL_PROFILES视图来进行确认。)
Q4. SQL profile是随着数据量的增加而动态更新吗?
A4.因为SQLprofile是静态的信息,所以不会自动更新。 因此,使用时, 因为数据量的变化,SQL profile就会变旧,就可能使得性能恶化。
(已经产生恶化的情况下,可以再次制成SQL profile)
Q5. 我们已经明白了SQL profile的效果有多好了,那要制成性能更好的执 行计划的话,为什么不使用默认的优化呢?
A5. 制成SQL profile比一般的CBO需要花费的时间更多。如果,默认中,对于所有SQL,都检验SQL profile的话,就可能影响到整体的性能,所以现实中不采用那种架构。
Q6. 能将开发环境下制成的SQL profile移动到正式环境中使用吗?
A6. 如果是Oracle Database 10g R2的话就可以。
<顺序>
・在开发环境中、
- 执行 dbms_sqltune.create_stgtab_sqlprof,然后制成暂时储存SQL profile Staging表。
- 执行dbms_sqltune.pack_stgtab_sqlprof,将SQL profile储存在Staging表中。
- 使用 DataPump以及Export,在dump文件中取出Staging表。
・在正式环境中
4.使用在开发环境中制成的dump文件使用Data Pump进行import。
5. 执行dbms_sqltune.unpack_stgtab_sqlprof,从Staging表表中取出SQL profile,反应在正式环境中 Oracle Database 10g R1中无法将SQL profile移动到其他数据库中 (比如,制成index时,在开发环境下,可以将通过建议制成的项目用Export / Import 等移动到正式环境中,SQL profile不需要在正式环境中用别的途径来制成)
Q7. 有确认是否使用了 SQL profile的方法吗?
A7. 确认有两种方法。
①灵活使用SQL*Plus的Autotrace功能
1. 设定Autotrace为ON
SQL> set autotrace on
2. 每次执行SQL语句时,以下的note就都会被表示出来,使用了SQL profile的情况下,
是表示出SQLprofile的名字
Note
—–
– SQL profile “SYS_SQLPROF_014564deb351c000“ used for this statement
②灵活使用Explain Plan
1. 对于SQL执行Explain Plan
(例)
SQL> EXPLAIN PLAN FOR SELECT * FROM emp;
2. 执行下述SQL的话,就会得到与①同样的结果
SQL> select plan_table_output from table(dbms_xplan.display());
要使用SQL调优建议需要什么!?
- 仅限Oracle Database 10g Enterprise Edition或以上版本
- 需要购买以下两个Option
Database Diagnostics Pack
- 可以使用的功能
- AWR (Automatic Workload Repository)
- ADDM (Automatic Database Diagnostic Monitor)
- 性能监视(数据库以及主机)
- 项目通知:
通知method、规定、以及日程 - 项目历史以及Metric历史
(数据库以及主机)
Database Tuning Pack
- 可以使用的功能
- SQL Access Advisor
- SQL Tuning Advisor
- SQL Tuning Sets
- 重新编辑对象
总结
- SQL profile非常有效!
- 克服了一直以来提示调优的弱点!
- 不需要修正应用就可以完成类似于提示的调优!
- 总结了US oracle的咨询的调优与窍门
- 即使没有技能与经验也能完成高度的SQL调优!
灵活使用Oracle Database 10g Enterprise Edition+ Option 非常重要!
灵活使用SQL调优建议
由建议开始制成SQL profile
