
本文永久地址: https://www.askmac.cn/archives/oracle-12c-rac-stack探究.html
The New Oracle RAC 12c
通过Oracle RAC 12c 可以实现的内容:
- 更优秀的业务持续性以及 高可用性(HA)
- 最优化的灵活性以及敏捷性
- 对于费用,可以进行效果较好的负载管理
通过Oracle RAC 12c 可以实现的功能:
- 更优秀的业务持续性以及 高可用性(HA)
- 最优化的灵活性以及敏捷性
- 对于费用,可以进行效果较好的负载管理
- 进一步使得Cluster环境的资源的Deployment以及管理方式标准化
- 可以使用大家熟练使用的,技术成熟的HA stack
Oracle Automatic Storage Management 12c 新功能
ASM : 进化的背景
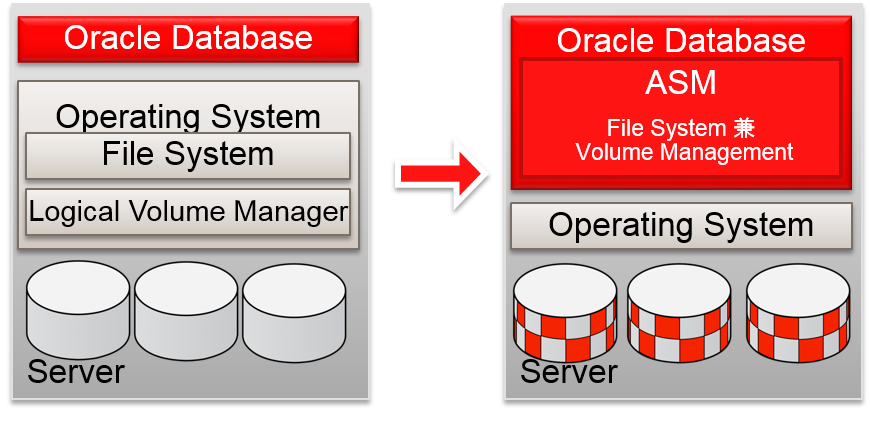
Why Oracle Developed ASM
- 在Oracle Database 10g中安装 ASM
–通过NFS Filer,可以简单地管理存储
–与RAW device相等的性能
Oracle Database 11g R2 以前
- 数据库实例会连接到本地ASM实例
Oracle ASM 12c :标准的ASM 结构
- 支持11g R2 之前相同的结构
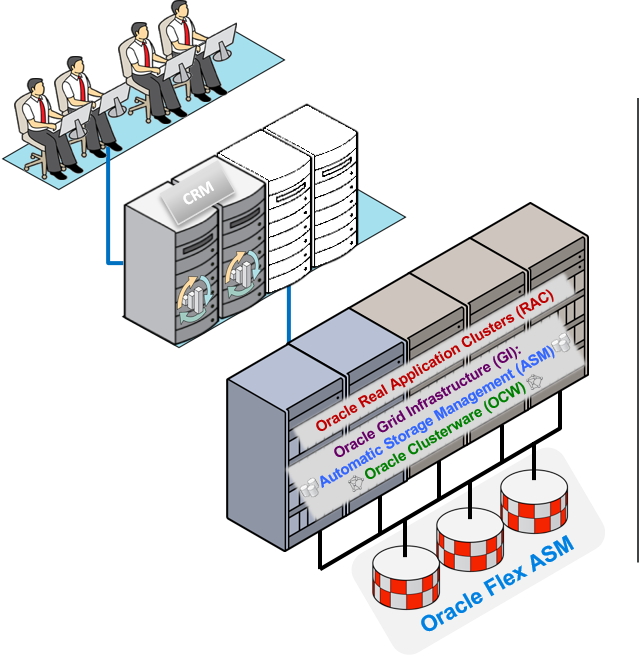
Oracle Flex ASM
排除1 to 1 映射以及实现高可用性
- Oracle ASM 12c中实际使用新结构
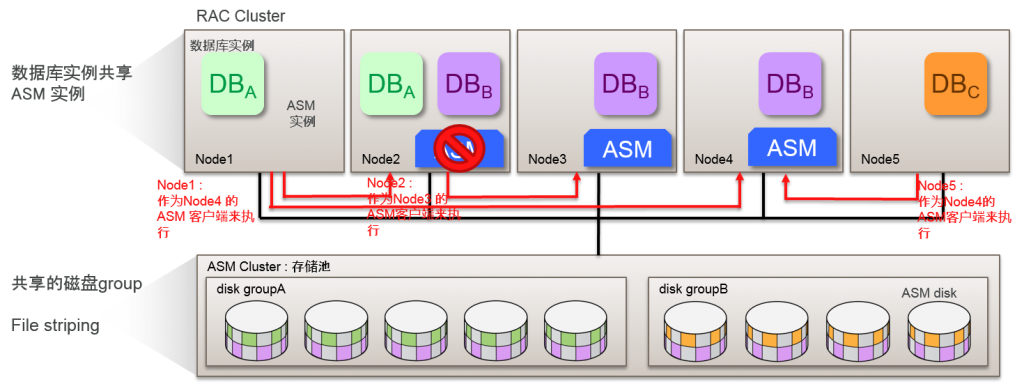
通过ASM 的灵活结构来提高可用性
- 将ASM实例与运行数据库实例的数据库分离来运行
–数据库实例通过网络连接到ASM实例
–Cluster整体默认启动3个ASM实例
–Cluster运行时,可以变更 ASM 实例数
–在Cluster整体中减少由于ASM产生的资源使用量(内存、CPU、网络等)
–减少故障点
- 发生ASM 实例故障时,对其他的ASM实例进行故障转移
–ASM 实例的依存性,提高数据库服务的可用性
–可以切换手动连接的ASM实例
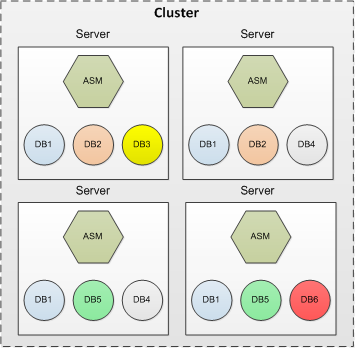
比较传统的 ASM 结构与 Flex ASM 结构
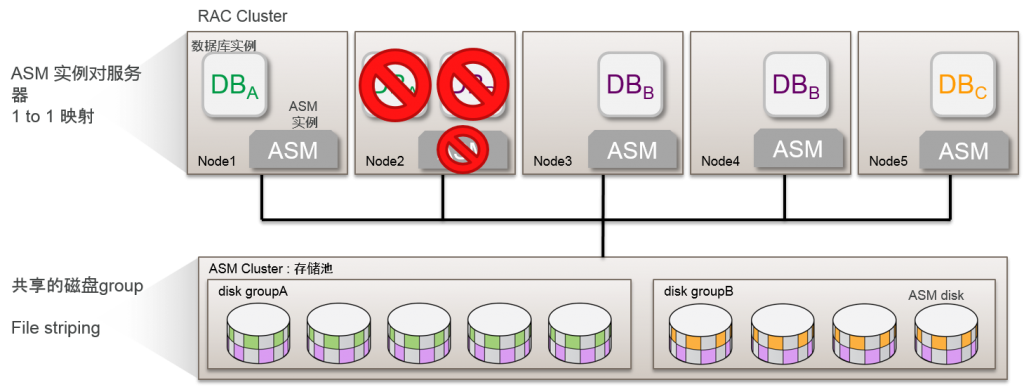
传统的 ASM 结构
数据库实例依赖于 ASM 实例
增加Cluster 的规模的话,ASM的过载也会增加
Cluster内的服务器越多cluster重构频率也就越高
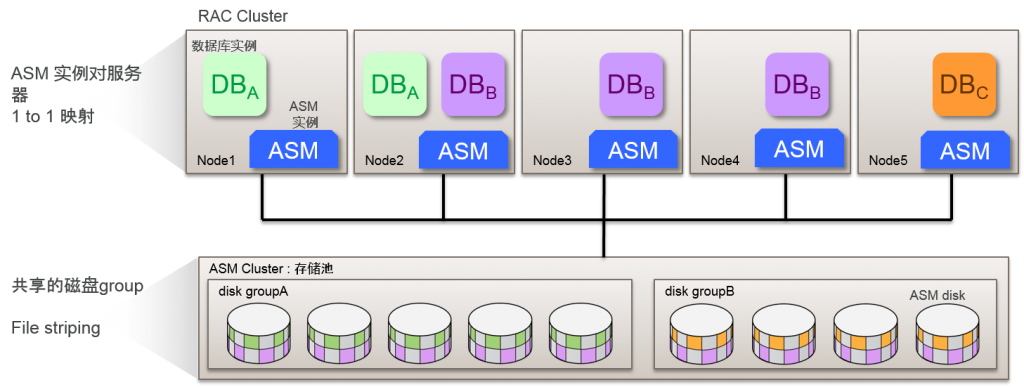
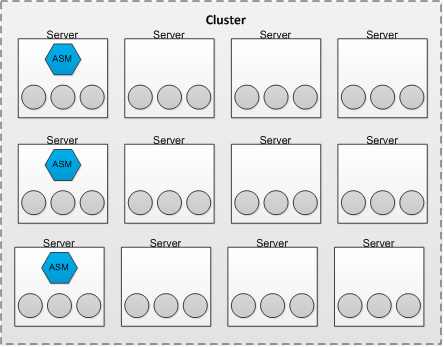
Flex ASM 结构
数据库实例连接到cluster中的ASM实例
指定ASM 实例的Cardinality (默认3)
Oracle Clusterware维持ASM 的Cardinality
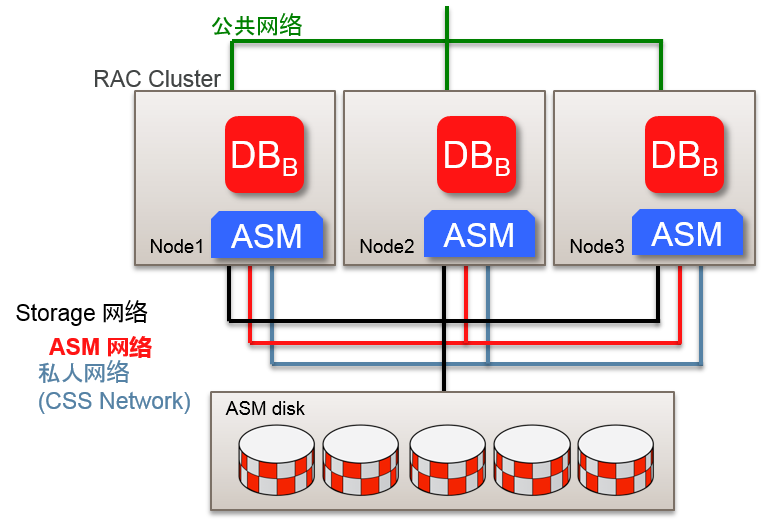
- 传统的 CSS cluster环境 :
–客户端访问的公共网络
–包含了用于ASM traffic的Interconnect的多个私人网络
- Flex ASM 结构中可以指定用于ASM的网络
–可以共享私人网络
- 作为ASM 用的网络,可以指定多个网络段
–对每个网络段制成ora.ASMNET<NETNUM>LSNR_ASM.lsnr 资源
- 确认是否构成Flex ASM
[grid@node01 ~]$ asmcmd showclustermode
ASM cluster : Flex mode enabled
- 确认ASM 实例的运行状况
[grid@node01 ~]$ srvctl status asm -detail
ASM在node01,node02,node04中显示正在执行
ASM是有效的。
- 确认ASM 的结构以及 ASM 实例数
[grid@node01 ~]$ srvctl config asm
ASM home: /u01/app/12.1.0/grid
密码文件: +DATA/orapwASM
ASM listener: LISTENER
ASM实例数: 3
clusterASM listener : ASMNET1LSNR_ASM,ASMNET2LSNR_ASM
- ASM 实例数的变更
[grid@node01 ~]$ srvctl modify asm -count 4
[grid@node01 ~]$ srvctl config asm
…
ASM实例数: 4
…
- 查看ASM 资源
[grid@node01 ~]$ crsctl status resource -t -w “NAME co asm”
Name Target State Server State details
ora.asm
1 ONLINE ONLINE node01 STABLE
2 ONLINE ONLINE node02 STABLE
3 ONLINE ONLINE node04 STABLE
4 OFFLINE OFFLINE STABLE
- 查看ASM 客户端
[grid@node01 ~]$ sqlplus sys/password as sysasm
SQL> select instance_name, db_name, status from v$asm_client;
INSTANCE_NAME DB_NAME STATUS
————— ——– ————
+ASM1 +ASM CONNECTED
orcl_1 orcl CONNECTED
orcl_2 orcl CONNECTED
- 重新配置ASM 客户端
[grid@node01 ~]$ sqlplus sys/password as sysasm
SQL> ALTER SYSTEM RELOCATE CLIENT ‘orcl_1:orcl‘;
与传统 DB 共存
为了获得本地ASM结构,指定Cardinality ALL
- 通过“srvctl modify asm -count ALL” 在所有节点中运行ASM实例

- 可以使用ASMCA ,从标准ASM变更为 Flex ASM 结构
–安装了Oracle Grid Infrastructure 12c 以上的环境
- 11g R2 以前的版本更新时,一旦完成了标准ASM结构更新后,就执行变更工作
- Oracle Restart 环境是例外
–指定ASM 网络以及listener的端口编号
- 无法从Flex ASM中变更标准ASM
- 使用ASM 的密码文件管理
- 磁盘再同步的功能扩展
- Rebalancing处理的功能扩展
- 修正Oracle ASM 的disk
- 其他的功能扩展
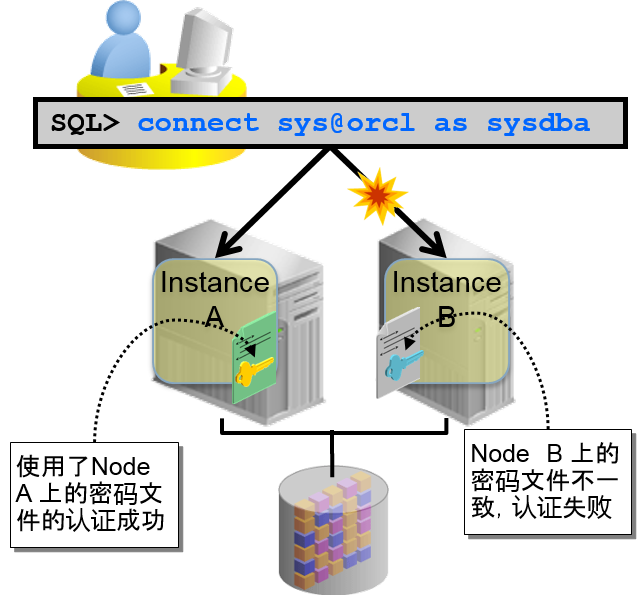
使用ASM 管理密码文件
- 在各节点的 $ORACLE_HOME/dbs 地址下配置
–一般的对各个节点执行个别管理
–cluster内中可能出现根据节点不同,密码也不同的情况
- 处理密码文件处理中指定节点终止的情况
–为了保持密码文件的一致性,需要认真维护
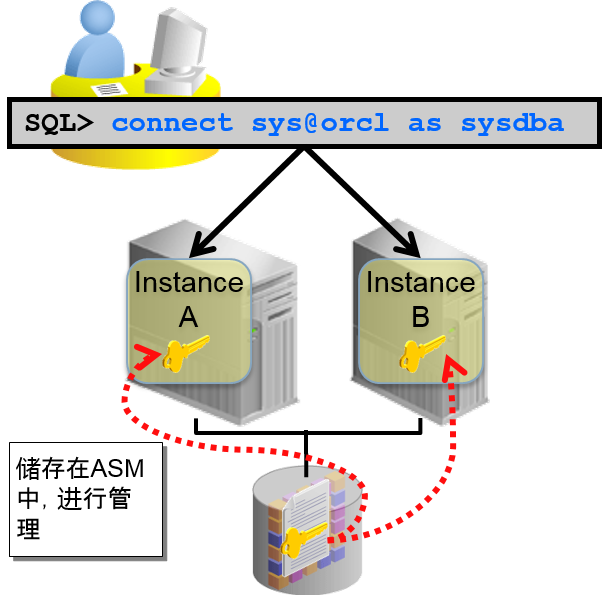
- 在ASM disk group中储存密码文件,可以在cluster中共享
–不需要每个节点中管理密码文件
–使用ASM 时默认的的结构
–追加数据库与 ASM 资源的密码文件相关属性
[grid@node01 ~]$ srvctl config database -d orcl
…
密码文件: +DATA/orcl/orapworcl
–ASM 实例的启动时使用 OS认证
Disk再次同步的功能扩展
通过指定Power Limit ,使得再次同步高效化
- 为了能够高速执行disk group的再同步处理,可以通过Power Limit,任意设定分配给再同步处理的资源量
- Power Limit中可以从1到 1024任意指定(默认指定为1)
- 与rebalance处理安装相同
–11.2.0.2 以后,可以将rebalance的并行度从设定为1024
- 可以设定disk group整体或者各个disk
SQL> ALTER DISKGROUP DATA ONLINE ALL POWER 50;
SQL> ALTER DISKGROUP DATA ONLINE DISK DATA_001 POWER 30;
更加高效得更换磁盘
- 发生disk故障,可以用一个部件更换磁盘
- 安装ALTER DISKGROUP <disk_group> REPLACE DISK 语句
–不需要删除更换完成的disk (需要OFFLINE)
- 以前的版本中,需要删除交换完成的磁盘,之后需要追加新的磁盘
–需要更换的磁盘中,以镜像数据为基础配置数据
- 规避不必要的rebalance处理,可以高效执行更换磁盘
–以同样的名字将新磁盘追加到原来的磁盘中。原来的磁盘以及相同的故障group就会被分配
SQL> ALTER DISKGROUP DATA REPLACE DISK DATA_001 with ‘/dev/sdz‘;
估计所有的再同步处理,重新开始处理
- 重新同步的处理的各个操作的估计的详细内容可以通过 V$ASM_OPERATION 查看
SQL> SELECT PASS, STATE, EST_MINUTES FROM V$ASM_OPERATION;
PASS STAT EST_MINUTES
——— —- ———–
RESYNC RUN 1
REBALANCE WAIT 1
COMPACT WAIT 1
- 追加PASS 列,可以确认处理内容
–传统版本是使用 Operation 列
- 重新同步处理执行时,会在内部执行检查点,中途终止时就会自动重新展开检测点
rebalance的功能扩展 优先顺序与同时处理
- 在重要的文件中按照顺序执行rebalance处理
–优先控制文件以及REDO日志文件来处理rebalance处理
–以前的版本中,按file顺序来执行
- 可以同时执行多个rebalance处理
–减少完成rebalance处理的时间
–以前的版本中,串行执行rebalance处理,对于多个disk group,同时需求rebalance处理时,之后需求的处理就会在队列中待机
- rebalance处理中,可以在内部进行理论检测来设定
–检测到破损时,就会自动修复镜像数据
–设定Disk group的 content.check 属性
rebalance的详细估计
- 通过rebalance处理可以估计 AU 的数量
–使用EXPLAIN WORK 命令,生成 work plan
–work plan 通过 STATEMENT_ID 来识别
SQL> EXPLAIN WORK SET STATEMENT_ID=’Drop DATA_001‘
2 FOR ALTER DISKGROUP DATA DROP DISK DATA_001;
Explained.
- 通过V$ASM_ESTIMATE队列查看估计完成 AU 的数量
SQL> SELECT EST_WORK FROM V$ASM_ESTIMATE
2 WHERE STATEMENT_ID= ‘Drop DATA_001‘;
EST_WORK
———–
279
Oracle ASM 的disk修正
- 作为后台任务来检查理论破损
–检测到破损的话,使用镜像数据来进行自动修正
–请尽量不影响应用的I/O来进行设定
- 仅在系统整体的 I/O 较低时执行
–后台进程 SCRB管理 Scrubbing 处理
- 可以使用ALTER DISKGROUP <disk_group> SCRUB 语句来执行
- rebalance中也可以执行内部执行disk修正处理
- 控制文件以及REDO日志文件,OCRhi更加频繁得执行Scrubbing 处理
其他的功能扩展
- disk group的平均读取
–传统版本中,通过ASM 使用冗长结构的情况的话,一般会参考primary数据,但12.1中,基于磁盘参考频率,对所有的disk进行均等的读取处理
- 导入FAILGROUP_REPAIR_TIME 属性
–故障 group整体失败的话,在判断时所使用的修复时间
–默认値为24小时
- 增加disk group数的最大値
–增加到511
- 传统的最大値为63
- 增加可以支持的容量
–在12.1以上的版本设定COMPATIBLE.ASM disk group属性的情况
- 每个ASM disk最大为 32PB
- 对于存储系统最大为 320EB
Oracle ASM Cluster File System (ACFS) 新功能
- 支持所有的数据库文件的 ACFS
- ACFS snapshot的功能扩展
- Oracle ACFS 监察
- Oracle ACFS 插件
- 高可用性 NFS
- Oracle ASM Proxy 实例
- ACFS 功能的Platform matrix
支持所有的数据库文件的 ACFS
- 可以在ACFS中配置所有的 Oracle Database 文件类型
–设置以下项目
- ASM/ADVM 兼容性
ASM 兼容性 : 12.1
ADVM 兼容性 : 12.1
ADVM stripe列 : 1
- 初始化参数 (DB 实例)
FILESYSTEMIO_OPTIONS : SETALL
DB_BLOCK_SIZE : 4k 或者以上
–Oracle Restart (单一实例) 结构中不支持
- 对于在ACFS中配置数据库的文件,也可以使用 “snapshot、 Tagging, security” 功能
–Oracle ACFS 复制、不支持加密
ACFS snapshot的功能扩展 从现有snapshot中制成snapshot
- 可以以现有的snapshot为基础获得新的snapshot
- 对应Read-Only / Read-Write 的组合
- ACFS 文件系统内,最多可以获得 63个 snapshot
–包含以现有snapshot为基础重新制成的snapshot
- 可以在12.1以上设定ADVM disk group的兼容性属性
# acfsutil snap create [-w|-r] \ –p <parent_snap_name> <snap_name> <mountpoint>
ACFS snapshot的功能扩展
snapshot的 Read-Only / Read-Write 的变更
- 可以读取专用以及读取、写入形式之间变换
- 可以将已获得的snapshot任意变换为Read-Only / Read-Write
- 可以在12.1以上设定ADVM disk group的兼容性属性
# acfsutil snap convert –w|-r <snap_name> <mountpoint>
- 从acfsutil snap info 命令以及snapshot,可以查看详细信息
# acfsutil snap info /u01/app/grid/acfsmnt
snapshot名: snap1
Rosnapshot或者RWsnapshot: RO
母的名字: /u01/app/grid/acfsmnt
snapshot作成时刻: Mon May 27 15:54:21 2013
snapshot名: snap1-a
Rosnapshot或者RWsnapshot: RW
母的名字: snap1
snapshot作成时刻: Mon May 27 15:55:44 2013
snapshot数: 2
snapshot的区域使用量: 151552
收集ACFS/ADVM 相关OS metric信息
- 用户区域应用,从 OS中,可以及时收集 Oracle ACFS 文件以及 Oracle ADVM volume的详细metric信息
- 通过acfsutil plugin 命令,指定收集对象的 ACFS 区域、类型、标签、获得间隔,通过Oracle ACFS 插件的 API,收集metric
# acfsutil [-h] plugin enable -m metrictype [-t tagname,…] \
> [-i <interval>[s|m]] <mount_point>
例) # acfsutil plugin enable -m acfsmetric1 -t HRDATA -i 5m /acfs
- Oracle ACFS 文件metric
–读取数 / 写入数 — 平均读取尺寸 / 平均写入尺寸
–最小读取尺寸 / 最大读取尺寸 — 最小写入尺寸 / 最大写入尺寸
–读取Cache hit / 读取cache miss
ACFS 区域的监视功能
- 对于Oracle ACFS 的安全性以及加密化,提供监视功能
- 每个ACFS 的文件系统可以分别设定
- 在Oracle Audit Vault 中可以输入Oracle ACFS 监视数据
- 监视源: Oracle ACFS 安全性、Oracle ACFS 加密操作项目
- 监视文件 : <Mount Point>/.Security/audit/acfs-audit-<Hostname>.log
- Oracle ACFS 监视的初始化、有效化、 purge、监视信息的表示等操作需要在 acfsutil audit 命令中设定
# acfsutil audit init –M <Audit Manager Group> –A <Auditor Group>
$ acfsutil audit enable –m <Mount Point> -s [sec | encr]
| 监视Record Field | 意思 |
| Timestamp | Event发生的时间 |
| Event code | 识别event类型的代码 |
| Source | Oracle ACFS |
| 识别用户User | 触发event的用户 |
| group识别(Group) | 触发event用户的primary group |
| 进程识别(Process) | 現在的进程 ID |
| 主机名(Host) | 记录event的主机 |
| 应用名(Application) | 現在进程用的应用名 |
| realm名(Realm) | 违反/认可/保护的realm名 |
| 文件名(File) | 用户访问过的文件名 |
| 评价結果(Evaluation Result) | 执行完成的命令结果相关信息 |
| 文件系统ID (FileSystem-ID) | |
| Message | 被执行的命令的结果 |
- 监视文件的例
Timestamp: 06/08/12 11:00:37:616 UTC Event: ACFS_AUDIT_READ_OP Source: Oracle_ACFS User: 0 Group: 0 Process: 1234 Host: slc01hug Application: cat Realm: MedicalDataRealm File: f2.txt Evaluation Result: ACFS_AUDIT_REALM_VIOLATION FileSystem-ID: 1079529531 Message: Realm authorization failed for file ops READ
高可用性 NFS
- Grid Infrastructure 的功能以及合作,提供高可用性 NFS (HANFS)
–NFS输出ACFS。提供NFS V2/V3服务
- 必须启动NFS服务器
–对于High Availability VIPs (HAVIP) ,执行NFS 输出、Oracle Clusterware Agent执行监视
- 仅限IPv4 (无法处理IPv6)
–可以在除Windows 以外所有可以使用 ACFS的平台上构成
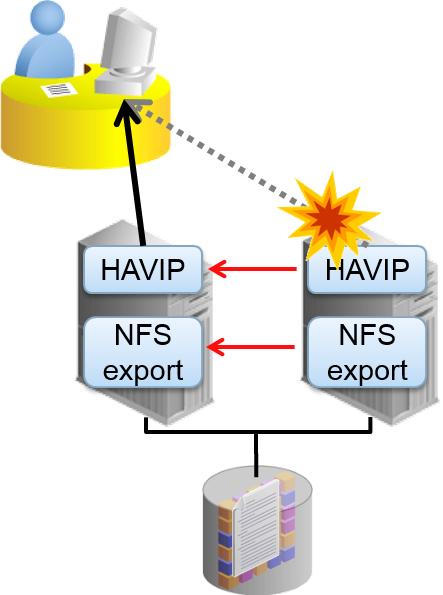
- 确认NFS 服务正在运行
- 制成ASFS后执行以下内容
–作为cluster资源登录ACFS 文件系统
# srvctl add filesystem –d /dev/asm/vol1-201 –v VOL1 –g DATA –m /mnt/acfsmounts/acfs1
–在所有节点中mount ACFS 文件系统
# srvctl start filesystem –device /dev/asm/vol1-201
制成HAVIP 资源,作为cluster资源来登录
# srvctl add havip –address c01vip –id havip1
- 制成ASFS 之后执行以下操作
–将ACFS 文件系统输出作为cluster资源来登录
# srvctl add exportfs –id havip1 -path /mnt/acfsmounts/acfs1 -name export1 –options rw –clients *.example.com
–ACFS 文件系统的输出
# srvctl start exportfs –name export1
–HAVIP/HANAS 资源的运行确认
$ srvctl status havip –id havip1
$ srvctl status exportfs –name export1
对应Flex ASM 结构
- Flex ASM 环境中,为了使用 ACFS/ADVM 功能的新类型的实例
–对ACFS/ADVM 内核模块提供 ASM 服务
- 在各节点中启动并连接在cluster内的 ASM 实例
–失去连接中的ASM实例以及连接时,进行故障转移连接到不同的ASM
- 无法作为RAC启动,简单的Footprint
- 作为CRS 资源管理,在启动cluster时自动启动
–SID : +APX<node_number>
–追踪信息 : $ORACLE_BASE/diag/APX
ACFS 功能的Platform matrix
| Release | Snaps | Repl | Tagging | Security | Encrypt |
| 11.2.0.1 | L/W – RO | ||||
| 11.2.0.2 | ALL – RO | L | L | L | L |
| 11.2.0.3. | ALL – RW | L/W | L/W | L/W | L/W |
| 12.1 | ALL – RW | ALL | ALL | L/W/S | L/W/S |
Legend: Linux(L), Windows(W), Solaris(S), AIX(A),
ALL=L/W/S/A Read Only (RO), Read & Write (RW)
- 请查看MOS NOTE确认每个最新的 OS的许可状况
ACFS Support On OS Platforms (Certification Matrix). [ID 1369107.1]
Oracle Clusterware 12c
新功能
基于定义完成的对策,在发生event时,进行资源分配
- 根据需要,处理资源不足
- 为了迎合业务需求 :
- 处理持续多日的peak的情况
- 系统维护 :
- 执行自动管理的情况
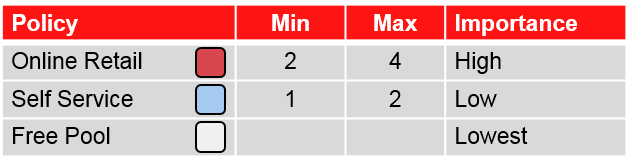
通过对策管理提高可用性
- 需要追加服务器资源的案例中,选择重要性较低的服务器group
- 对应发生2 重故障 / 3 重故障的情况
- 在进行有计划的维护工作时,也可以高效使用备份服务器
注意服务器规格差异来设计的服务器池结构
- Oracle RAC 12.1
- 比起传统的追加节点方法 (addNode) 要简单
- 将尺寸不同的资源的服务器作为cluster来构造,从而高效使用
- 理解cluster内的服务器之间的差异,可以通过服务器池管理服务器 :
- 在每个服务器中保存服务器属性
- 使用服务器的category化构造服务器池
- 服务器以category为基础,配置服务器池
- 将验证用的设备配置在一个服务器池中,根据需要,可以对其他池配置服务器
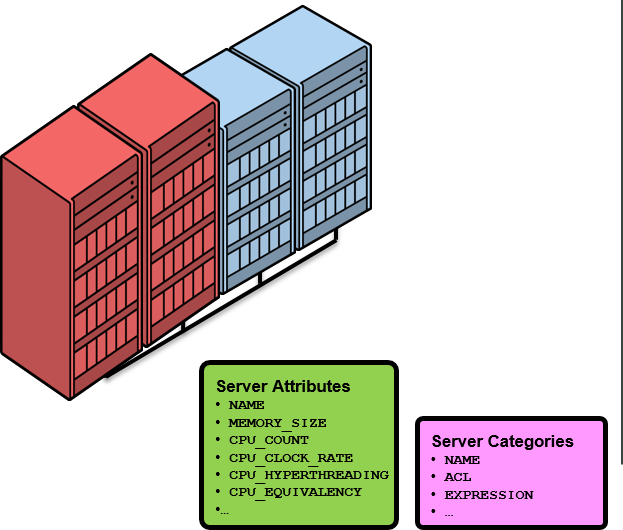
将服务器根据其属性不同作为category来分类
- Oracle Clusterware 12c 中导入了新的category (Server Category)
- 根据通过Oracle Clusterware来管理的服务器属性来分类 (Server Attribute)
–CPU 数、CPU clock数、内存尺寸等物理属性
–通过Oracle Clusterware自动获得
–通过将category与服务器池关联,可以在又特定属性的服务器中,构造服务器池
–服务器池的属性中重新追加了SERVER_CATEGORY
- Category中,基于服务器属性的値,可以任意定义固有属性(Expression)
服务器的category化
category以及相关属性
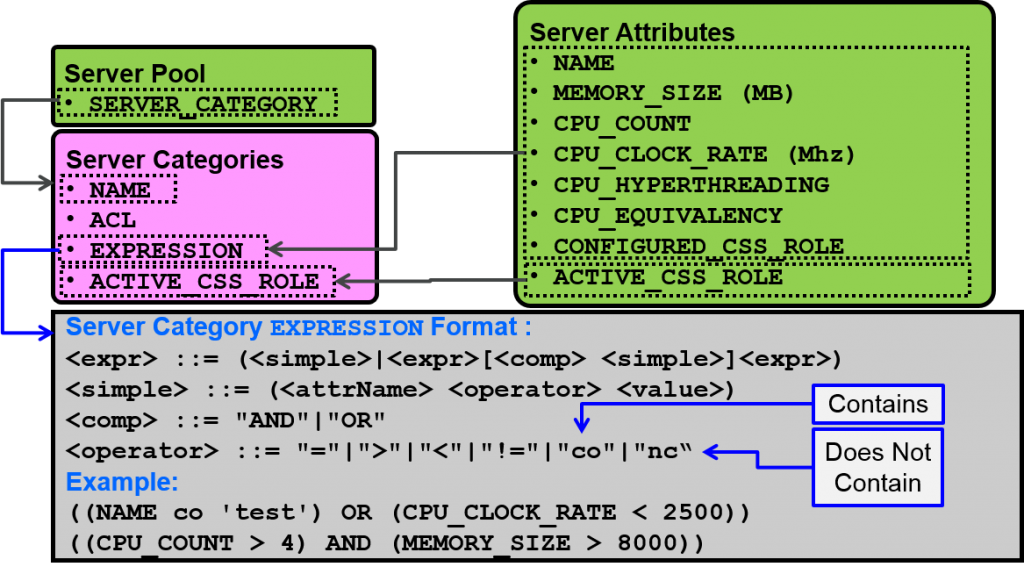
- 设定的属性值可以通过 crsctl status server 命令来查看
$ crsctl status server <ServerName> -f $ crsctl status server node01 -f NAME=node01 MEMORY_SIZE=4006 CPU_COUNT=4 CPU_CLOCK_RATE=10390 CPU_HYPERTHREADING=0 CPU_EQUIVALENCY=1000 DEPLOYMENT=other ...
-
新建category
$ crsctl add category <catName> -attr "<attrName>=<value>[,...]" $ crsctl add category small_server -attr "EXPRESSION='(CPU_COUNT < 4)'"
-
制作完成category的修正
$ crsctl modify category <catName> -attr "<attrName>=<value>[,...]" $ crsctl modify category small_server -attr "ACTIVE_CSS_ROLE='hub'"
-
查看category
$ crsctl status category <catName> $ crsctl status category small_server NAME=small_server ACL=owner:root:rwx,pgrp:root:r-x,other::r-- ACTIVE_CSS_ROLE=hub EXPRESSION=(CPU_COUNT < 4)
What-If 命令评价
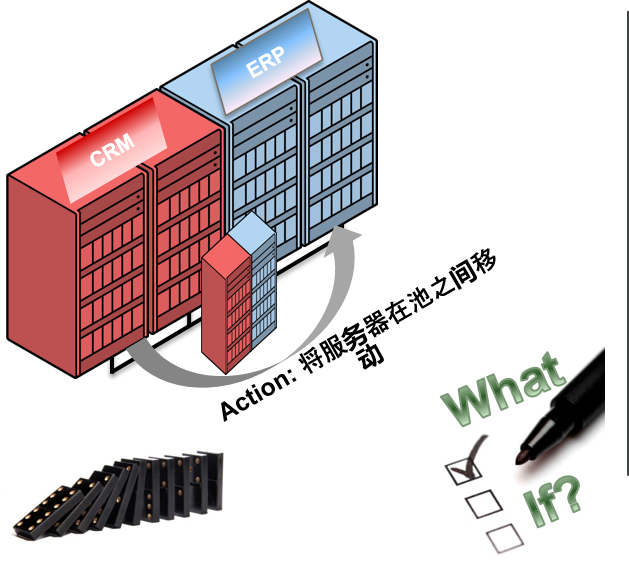
可以预测结构复杂的cluster的管理操作
- 评价Oracle RAC 12c
What-If 命令 - 在构成时的技术支持以及验证设定完成的对策时有效
- 对终止时制定对策有效
- 事先分析Impact
- 建立灵活的cluster操作
- 通过What-If 命令评价可以实现以下项目:
- 制定有效的对策
- 服务器池、服务器、资源的变更工作
- 例) 追加、重新配置、删除
- 发生故障时查看操作
What-If 命令评价
- 执行cluster管理操作时,为了回顾,提供命令
–实际操作之前,可以查看到底会产生怎样的影响
受支持的event
- 资源 (start/stop/relocate/add/modify/fail)
- 服务器池 (add/modify/delete)
- 服务器 (add/relocate/delete)
- 对策 (activate policy)
What-If 命令评价
cluster管理者的视图
通过crsctl 评价
- 使用crsctl eval 命令的执行例
$ crsctl eval {start|stop|relocate|modify|add|fail} resource
$ crsctl eval start resoruce my_resource –n my_server
STAGE_GROUP 1:
--------------------------------------------------------------------------------
STAGE_NUMBER REQUIRED ACTION
--------------------------------------------------------------------------------
1 Y 资源‘my_dep_res1’ (1/1) 为状態[ONLINE]
(服务器变成[my_server])
N 资源 ‘my_dep_res2’ (1/1) 为状態[ONLINE|INTERMEDIATE]
(服务器变成[my_server])
2 Y 资源‘ my_resource’ (1/1) 为状態[ONLINE|INTERMEDIATE]
(服务器变成[my_server])
--------------------------------------------------------------------------------
DBA 的视图
通过srvctl 评价
- 使用srvctl -eval 命令的执行例
$ srvctl {start|stop|modify|relocate} database … -eval
$ srvctl start database -db orcl -eval
将LISTENER_SCAN1在节点node01上启动
将LISTENER_SCAN2在节点node02上启动
将LISTENER_SCAN3在节点node03上启动
将数据库orcl在节点node01,node02,node03上启动
$
Oracle Flex Cluster
提供灵活性以及高可用性的新cluster链接类型
- Oracle Flex Cluster:
–Oracle Clusterware 的新cluster结构
- 灵活使用2 类的cluster节点:
–Hub节点
- 与网络、存储紧密相关的节点群中、为了执行集中产生I/O 的负载的节点
- 执行数据库实例
–Leaf节点
- 少量stack的新类型节点
- 不直接访问存储
- 执行以processing处理为中心的负载(应用)
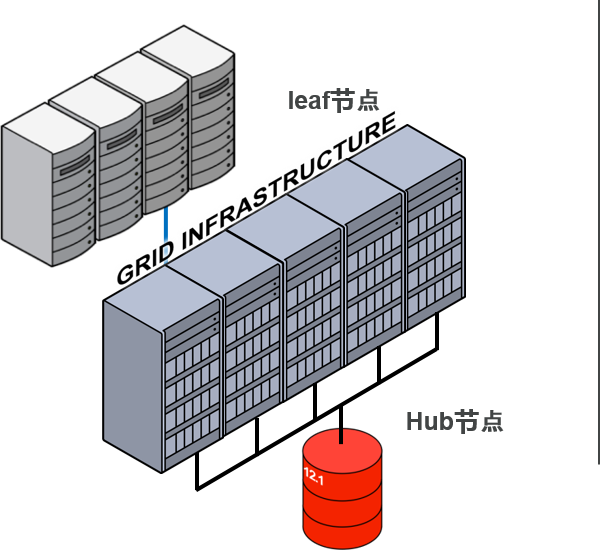
- Oracle Flex Cluster:
–通过两层结构,可以实现高可用性以及便利的资源管理性
- leaf节点中,运行少量的cluster stack,将独立的heartbeat设定与故障隔离
- 在Leaf节点上运行的应用,可以作为cluster资源来管理。
–应用标准化管理
- global资源的配置以及依存关系
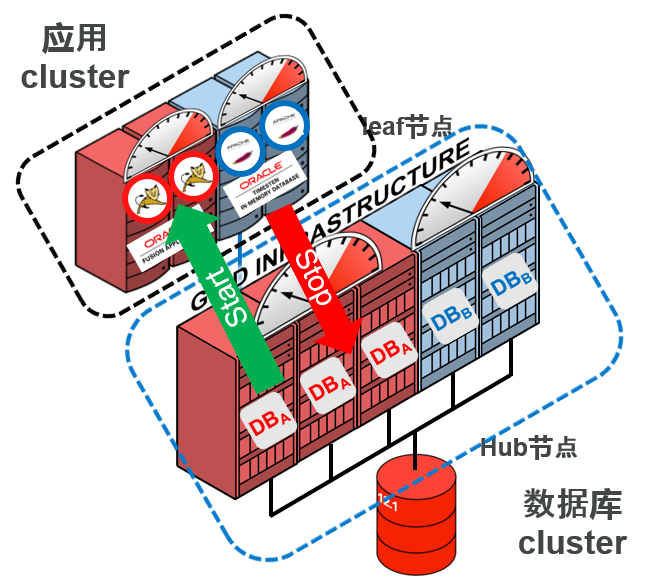
Hub节点以及leaf节点的连接
- Flex Cluster 环境中节点通过role(hub/leaf)来管理
- leaf节点连接到任何一个Hub节点,执行网络heartbeat,使用独立的hearbeat值,执行Hub节点以及疏通确认
–leaf节点之间,不会产生网络heartbeat
–仅限leaf节点才能在cluster中存在
–Hub节点的 CSSD 明确终止时,连接的leaf节点就会切换到cluster内的其他Hub节点切换运行
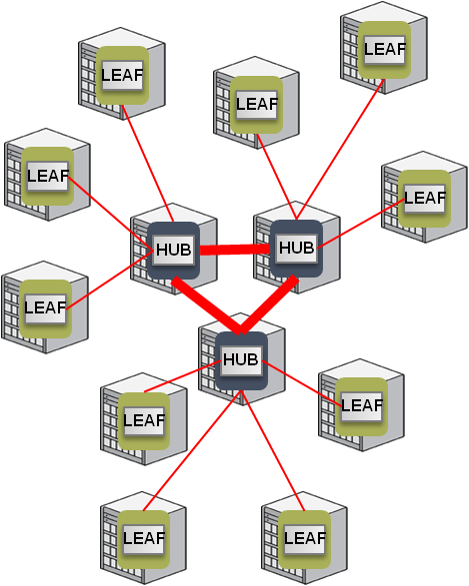
ASM 结构以及cluster结构的配合与变更
- Oracle ASM 12c : 两种的类型
–标准的 ASM 结构(本地ASM)、Oracle Flex ASM
- Oracle Clusterware 12c : 两种的类型
–标准cluster、Oracle Flex Cluster
- 可以构成的组合
| 标准cluster | Oracle Flex Cluster | |
| 本地ASM | ○ | × |
| Oracle Flex ASM | ○ | ○ |
- 标准cluster变更成 Oracle Flex Cluster 的结构
–不能从Oracle Flex Cluster 变更为标准cluster

Cluster Health Monitor 功能扩展
- 可以作为Cluster Health Monitor (CHM) 的数据储存地址,在cluster内中制成 Grid Infrastructure 管理repository
- 作为管理repository、使用单独实例的 Oracle Database EE
- 作为Oracle Clusterware 的资源追加以下两类
$ crsctl stat res -t -w "(NAME co mgmt) OR (NAME co MGMT)" -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- ora.MGMTLSNR 1 ONLINE ONLINE node01 192.168.100.254,STAB LE ora.mgmtdb 1 ONLINE ONLINE node01 Open,STABLE --------------------------------------------------------------------------------
mgmtdb / MGMTLSNR
- mgmtdb
–DB Name = “_MGMTDB”
–SID = “-MGMTDB”
–资源名 : ora.mgmtdb
–EE 的单独实例
–仅限使用OS认证的本地SYSDBA 中才可以登录
- MGMTLSNR
–mgmtdb 用的listener
–资源名 : ora.MGMTLSNR
–在mgmtdb 以及同一节点上运行
–监听私人网络上的HAIP
- Grid Infrastructure 安装是,选择是否制成mgmtdb
–安装之后不可以构造mgmtdb/MGMTLSNR
多cluster环境的共享 GNS
- 传统的版本的GNS,需要对Oracle Grid Infrastructure 都构成专用的 GNS
- Oracle Clusterware 12c 中,在多个cluster中,可以共享 GNS 服务器来使用
–名字管理的简单化
- 通过GNS 资格证明数据,可以设定GNS服务的客户端——cluster、服务器的cluster之间的关系
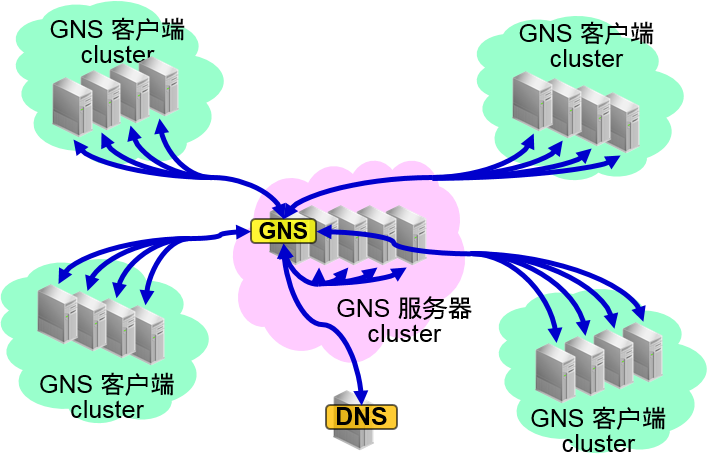
网络相关的功能扩展
- 支持多个sub net中的扫描
–cluster上可以进行多个扫描
–可以区分的sub net中,仅限一个
- 支持基于IPv6 的IP地址
–可以使用IPv4或者IPv6 来构造cluster
–构成cluster之后,可以从IPv4迁移到IPv6(反之也可行)
- 通过检查无效节点,可以限制listener的服务登录
–可以指定接受SCAN listener登录的节点以及sub net
Oracle Clusterware 管理功能的扩展
- 可以选择是否输出cluster启动处理以及处理結果的的信息
-wait : 输出CRSD + OHASD资源的启动处理以及处理结果
-waithas : 输出OHASD 资源的启动处理以及处理结果
-noautostart : 仅仅输出OHASD 的启动结果

- 理解SRVCTL utility的选项进行变更
$ srvctl start scan -help 启动指定的扫描VIP。 使用方法: srvctl start scan [-scannumber <ordinal_number>] [-node <node_name>] -netnum <net_num> 网络编号(默认编号为1) -scannumber <scan_ordinal_number> IP地址的讯号 -node <node_name> 节点名 -help 展示使用方法
–传统的版本的 1 个字符的选项也可以继续使用
安装时的自动执行构成脚本
- Oracle Grid Infrastructure 12c安装时,可以设定为自动执行构成脚本(root.sh)
- 选择执行方法
–自动执行
- 使用root 用户的资格证明
- sudo 的使用
–手动执行
- 与传统方法相同
- 需要确认自动执行处理
Oracle Grid Infrastructure Bundled Agents (XAG)
- 将下列应用作为 Oracle Clusterware 的资源来管理提供HA framework的Oracle Grid Infrastructure 组件
–Apache Tomcat
–Apache Webserver
–Oracle GoldenGate
–Oracle Siebel Gateway
–Oracle Siebel Server
- 在应用资源名中
赋予XAG进行识别 - 事先定义依存关系,可以简单地登录cluster的资源
- 11g R2 环境中也可以通过 OTN 来下载安装

Oracle Grid Infrastructure Bundled Agents
- 使用agctl 的srvctl 相同的Utility Tools可以登录、管理应用
# Usage: agctl <verb> <object> [<options>]
verbs:add | check | config | disable | enable | modify |
relocate | remove | start | status |stop
objects:apache_tomcat | apache_webserver | goldengate |
siebel_gateway | siebel_server
- Oracle GoldenGate 向cluster登录的例子
# agctl add goldengate <name>
–gg_home /u01/app/gg –oracle_home /u01/app/11.2.0/db
–db_services <list of services> –vip_name <exiting VIP>
–filesystems ora.ggh.acfs,ora.ggtr.acfs
–monitor_extracts <extracts list> –monitor_replicats <replicats list>
应用的管理方法 <启动、停止、确认、重新配置、删除>
- Oracle GoldenGate 的启动
# agctl start goldengate <name>
- Oracle GoldenGate 的停止
# agctl stop goldengate <name>
- 确认Oracle GoldenGate 的status
# agctl status goldengate <name>
- 重新配置Oracle GoldenGate
# agctl relocate goldengate <name>
- Oracle GoldenGate 的删除
# agctl remove goldengate <name>
泛用性的应用
- 资源类型 : generic_application 通过Oracle Clusterware 12c 追加
- 因为高可用性是必须的,所以制成操作脚本是,可以将不需要的应用模型化来使用
- 启动、终止、clean up应用时,包括选项,指定将要进行的操作,登录到oracle Clusterware 中
–START_PROGRAM / STOP_PROGRAM / CLEAN_PROGRAM
- <例> 指定generic_application 类型,登录Samba 服务器的情况
$ crsctl add resource samba1 -type generic_application -attr "START_PROGRAM='/etc/init.d/smb start', STOP_PROGRAM='/etc/init.d/smb stop', CLEAN_PROGRAM='/etc/init.d/smb stop', PID_FILES='/var/run/smbd.pid,/var/run/nmbd.pid'"
Oracle Real Application Clusters (RAC) 12c :Multi-tenant architecture
处理Multi-tenant architecture
包括Pluggable数据库,提供数据库整体的可用性
- 对策管理或者管理者管理类型的 RAC 数据库中也可以处理Multi-tenant architecture
- 提供将传统的数据库服务于PDB相联系,可以提高RAC环境中的管理性
- 推荐使用了服务器管理 (SRVCTL) utility的服务器管理
–对策管理 RAC 数据库上,与PDB相联系,制成服务的情况
$ srvctl add service -db <DBNAME> -service <SERVICE_NAME> –pdb <PDB_NAME> -g <>
Oracle RAC:处理Multi-tenant architecture
- 单独实例 / non-CDB
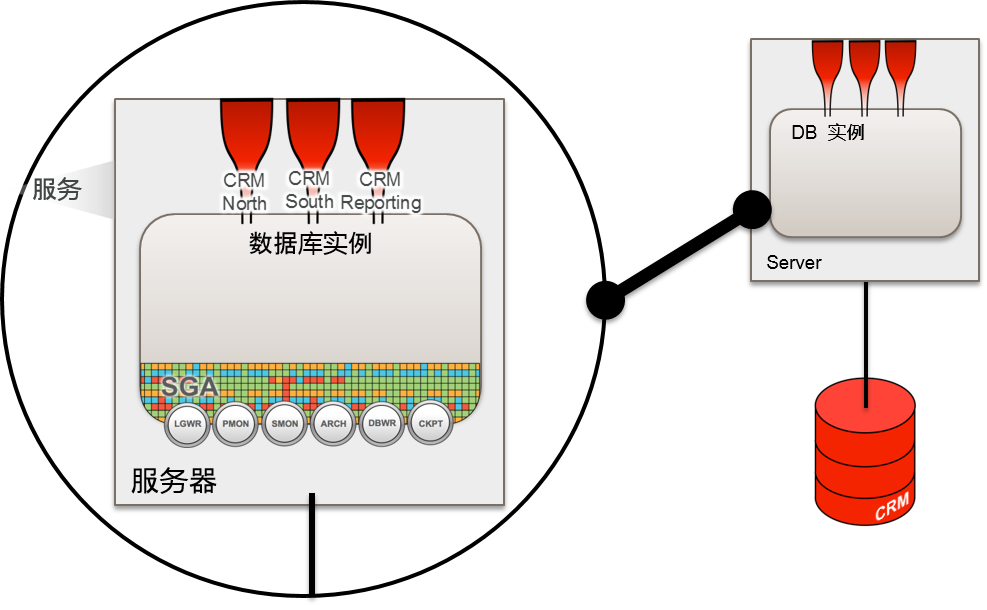
- RAC 的变更 / non-CDB
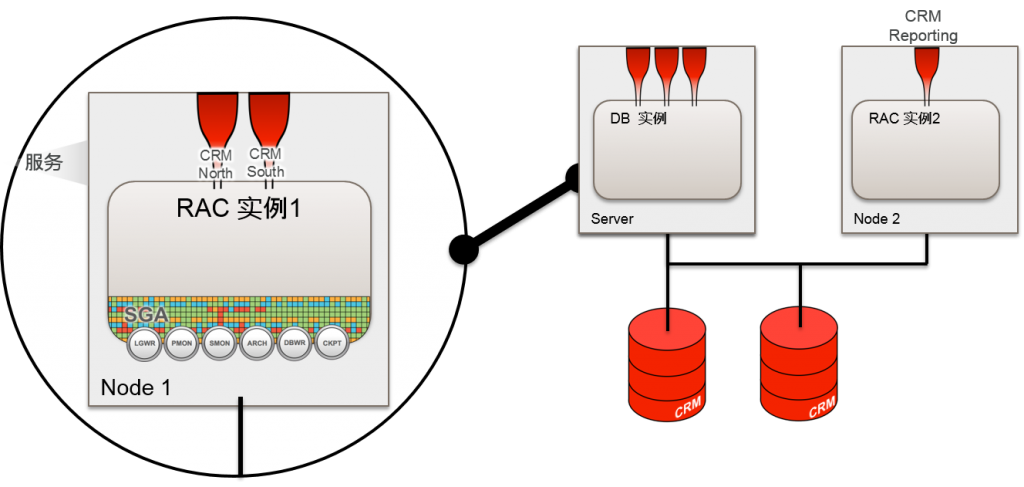
- 变更为CDB
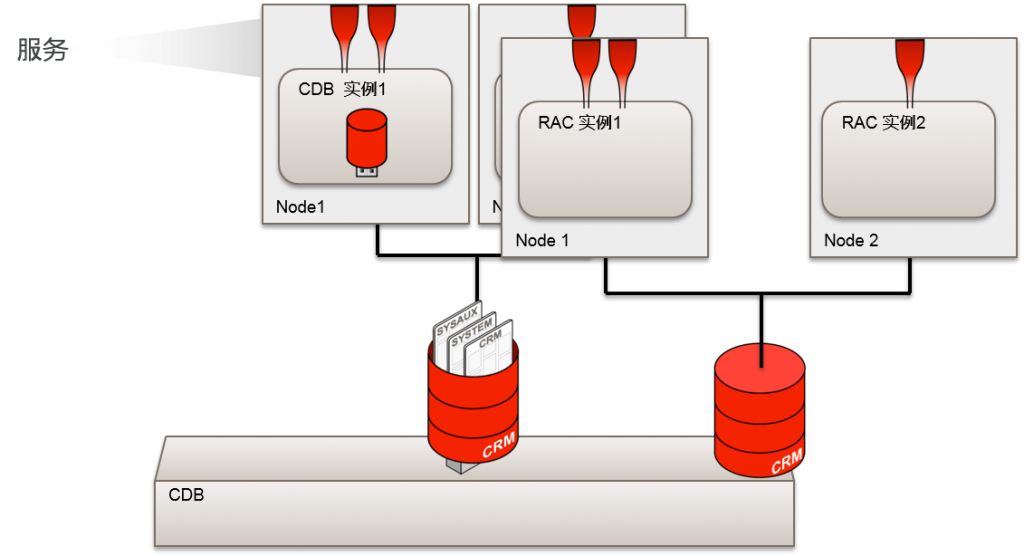
- 在cluster上灵活扩展Consolidation model
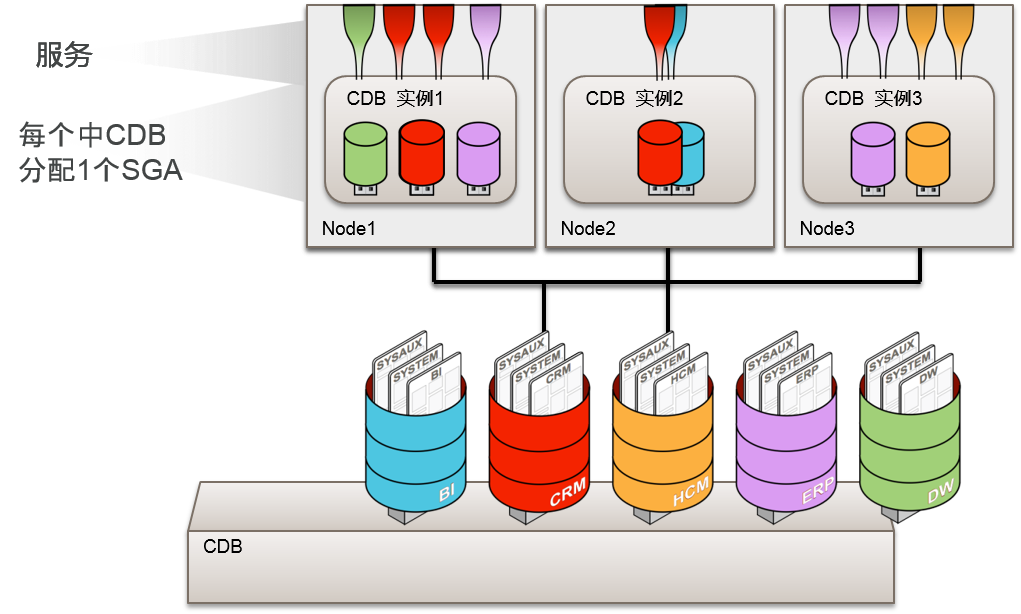
- 在RAC 环境中灵活合并PDB


Comment