
- 配置 SQL 跟踪工具以收集会话统计信息
- 使用 TRCSESS 实用程序合并 SQL 跟踪文件
- 使用 tkprof 实用程序设置跟踪文件的格式
- 解释 tkprof 命令的输出
端到端应用程序跟踪面临的挑战
- 我要检索 CRM 服务的踪迹。
- 我要检索客户机 C4 的踪迹。
- 我要检索会话 6 的踪迹。
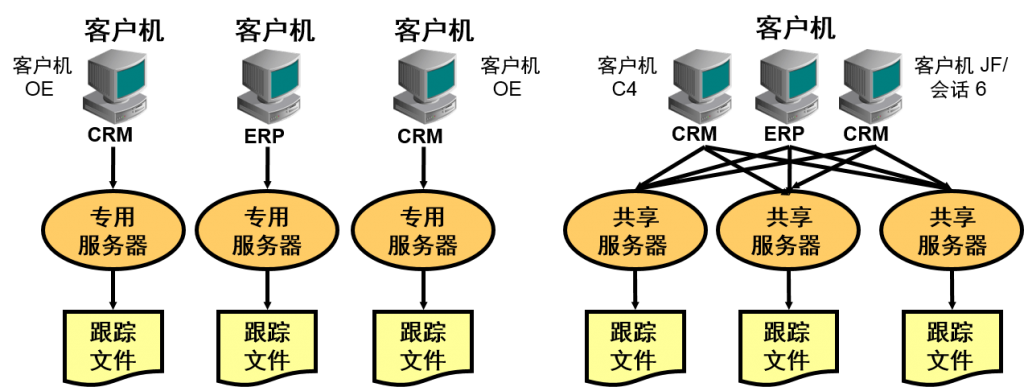
启用跟踪机制后,Oracle DB 通过为每个服务器进程生成跟踪文件来实施跟踪。
在专用服务器模型中,跟踪特定客户机通常不是问题,因为将由一个专用进程在会话生存期内负责会话跟踪。可以从属于负责会话跟踪的专用服务器的跟踪文件中查看该会话的所有跟踪信息。但是,在共享服务器配置中,通常由不同的进程交替为客户机提供服务。与用户会话有关的跟踪信息分散在属于不同进程的不同跟踪文件中,因此很难完整地了解会话在生存期内的踪迹。
而且,有时出于性能或调试目的需要合并特定服务的跟踪信息,又该怎么办呢?因为同时有几个客户机使用同一服务,而每个生成的跟踪文件都属于提供该服务的服务器进程,所以这也很困难。
端到端应用程序跟踪
- 通过将应用程序工作量通知给以下项,可以简化在多层环境中诊断性能问题的过程:
–服务
–模块
–操作
–会话
–客户机
- 端到端应用程序跟踪工具:
–Oracle Enterprise Manager
–DBMS_APPICATION_INFO、DBMS_SERVICE、DBMS_MONITOR、DBMS_SESSION
–SQL 跟踪和 TRCSESS 实用程序
–tkprof
端到端应用程序跟踪简化了在多层环境中诊断性能问题的过程。在多层环境中,来自最终客户机的请求通过中间层路由到不同的数据库会话,这使得跨不同数据库会话跟踪客户机变得较困难。端到端应用程序跟踪使用客户机标识符,经由所有层直到数据库服务器,唯一地跟踪一个特定最终客户机。
可以使用端到端应用程序跟踪确定超常工作量的来源,例如某条高负荷的 SQL 语句。并且,您还可以确定用户的会话在数据库级别所执行的活动,以解决用户性能问题。
端到端应用程序跟踪通过跟踪某项服务中的特定模块和操作,还简化了应用程序工作量的管理工作。端到端应用程序跟踪可以识别下列项的工作量问题:
- 客户机标识符:基于登录 ID 指定一个最终用户,例如 HR。
- 服务:指定一组具有共同属性、服务级别阈值和优先级的应用程序,或单个应用程序。
- 模块:指定应用程序中的一个功能块。
- 操作:指定模块中的一项操作,例如一项 INSERT 或 UPDATE 操作。
- 会话:基于一个给定数据库会话标识符 (SID) 指定一个会话。
端到端应用程序跟踪的主要接口是 Oracle Enterprise Manager。幻灯片中列出的其它工具将在本课的后面部分中讨论。
诊断跟踪的位置
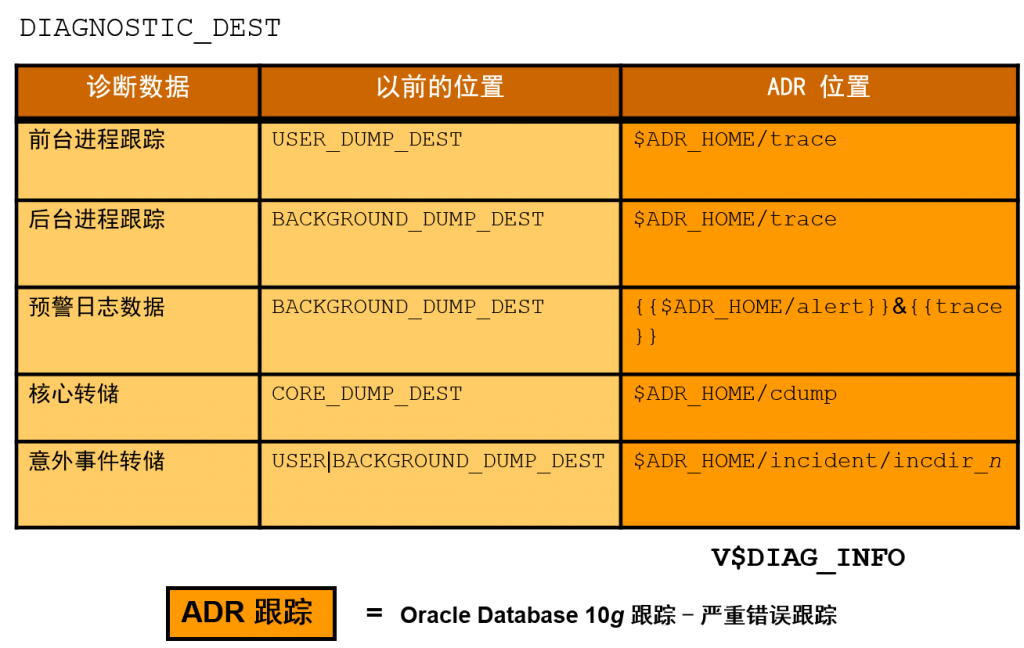
自动诊断资料档案库 (ADR) 是一个基于文件的资料档案库,用于存放数据库诊断数据(如跟踪、意外事件转储和程序包、预警日志、健康监视报告、核心转储等)。
从 Oracle Database 11gR1 开始,忽略传统的 …_DUMP_DEST 初始化参数。ADR 根目录又称为 ADR 基目录,其位置由 DIAGNOSTIC_DEST 初始化参数设置。幻灯片中显示的表说明了 Oracle Database 10g(以及先前版本)与 Oracle Database 11g 中驻留的不同类跟踪数据和转储。对于 Oracle Database 11g,前台和后台跟踪文件之间没有什么区别。这两种类型的文件都会放入 $ADR_HOME/trace 目录中。您可以使用 V$DIAG_INFO 列出一些重要的 ADR 位置。
所有非意外事件跟踪都存储在 TRACE 子目录中。以前的版本会将严重错误信息转储到相应的进程跟踪文件而不是意外事件转储,这就是新旧版本之间的主要区别。从 Oracle Database 11g 开始,意外事件转储将存放到独立于普通进程跟踪文件的文件中。
注:跟踪和转储之间的主要区别在于,跟踪是较为连续的输出(如打开了 SQL 跟踪时),而转储是为了响应事件(如意外事件)而进行的一次性输出。另外,核心是特定于端口的二进制内存转储。
在幻灯片中,$ADR_HOME 表示由 DIAGNOSTIC_DEST 初始化参数定义的 ADR 主目录。但是,不存在名为 ADR_HOME 的正式环境变量。
什么是服务
- 是对执行同一种工作的会话进行分组的一种方式
- 提供单一系统映像,而不提供多实例映像
- 是一种常规管理任务,用于提供服务到实例的动态分配
- 是实现高可用性的连接的基础
- 提供了一个性能优化维度
- 是一个用于捕获跟踪信息的句柄
服务的概念最早是在 Oracle8i 中引进的,当时它是监听程序在集群的节点和实例之间执行连接负载平衡的方式。现在,服务的概念、定义和实施都已经有了巨大的扩展。服务可在数据库内组织工作执行,以使其更便于管理、评估、优化和恢复。一个服务就是数据库内的一组相关任务,这些任务有共同的功能、质量预期值以及相对于其它服务的优先级。服务可提供单一系统映像,用于管理在单个实例内运行的竞争应用程序,以及跨多个实例和数据库运行的竞争应用程序。
使用标准接口、Oracle Enterprise Manager 和 SRVCTL,可将服务作为单个实体进行配置、管理、启用、禁用和度量。
服务提供可用性。服务中断时,会被快速恢复并自动定位到正常运行的实例。
服务提供了一个性能优化维度。有了服务,就可查看和评估工作量。在会话为匿名和共享的大多数系统中,按“服务和 SQL”优化取代了按“会话和 SQL”优化。
从跟踪角度来看,服务提供了一个句柄,无论会话为何,都允许按服务名称捕获跟踪信息。
将服务与客户机应用程序配合使用
ERP=(DESCRIPTION=
(ADDRESS=(PROTOCOL=TCP)(HOST=mynode)(PORT=1521))
(CONNECT_DATA=(SERVICE_NAME=ERP)))
url=”jdbc:oracle:oci:@ERP”
url=”jdbc:oracle:thin:@(DESCRIPTION=
(ADDRESS=(PROTOCOL=TCP)(HOST=mynode)(PORT=1521))
(CONNECT_DATA=(SERVICE_NAME=ERP)))”
应用程序和中间层连接池将使用透明网络基础 (TNS) 连接描述符选择服务。
所选的服务必须与已创建的服务相匹配。
幻灯片中的第一个示例显示了可以用于访问 ERP 服务的 TNS 连接描述符。
第二个示例显示了使用以前定义的 TNS 连接描述符的胖 Java 数据库连接 (JDBC) 连接描述。
第三个示例显示了使用相同 TNS 连接描述符的瘦 JDBC 连接描述。
跟踪服务
- 可以通过以下项进一步限定使用服务的应用程序:
–MODULE
–ACTION
–CLIENT_IDENTIFIER
- 使用下列 PL/SQL 程序包进行设置:
–DBMS_APPLICATION_INFO
–DBMS_SESSION
- 可以在所有级别上进行跟踪:
–CLIENT_IDENTIFIER
–SESSION_ID
–SERVICE_NAMES
–MODULE
–ACTION
–SERVICE_NAME、MODULE、ACTION 的组合
应用程序可以通过 MODULE 和 ACTION 名称限定服务,以标识该服务内的重要事务处理。这使您可以针对已归类的工作量定位性能较差的事务处理。使用连接池或事务处理监视程序监视系统中的性能时,这很重要。在这些系统中,会话是共享的,计算起来非常困难。SERVICE_NAME、MODULE、ACTION、CLIENT_IDENTIFIER 和 SESSION_ID 是 V$SESSION 中的实际列。SERVICE_NAME 是在用户登录时自动设置的。应用程序将使用 DBMS_APPLICATION_INFO PL/SQL 程序包或特殊 Oracle 调用接口 (OCI) 调用设置 MODULE 和 ACTION 的名称。应针对当前执行的程序将 MODULE 设置为用户可识别的名称。同样,应将 ACTION 设置为用户将在模块内执行的特定操作或任务,例如输入新
客户。
SESSION_ID 是在创建会话时由数据库自动设置的,而 CLIENT_IDENTIFIER 可使用 DBMS_SESSION.SET_IDENTIFIER 过程来设置。
跟踪各个会话的传统方法是使用 SQL 命令生成可跨越工作量执行的跟踪文件。这样,就可以通过确定是否命中的方法来诊断有问题的 SQL 了。利用您提供的条件(SERVICE_NAME、MODULE 或 ACTION),可以将特定的跟踪信息捕获到一组跟踪文件中,然后将它们合并到一个输出跟踪文件中。这样,生成的跟踪文件就包含了与特定工作量相关的 SQL。对于 CLIENT_ID 和 SESSION_ID 也可以执行相同的操作。
注:DBA_ENABLED_TRACES 显示有关已启用的跟踪的信息。
使用 Oracle Enterprise Manager 来跟踪服务
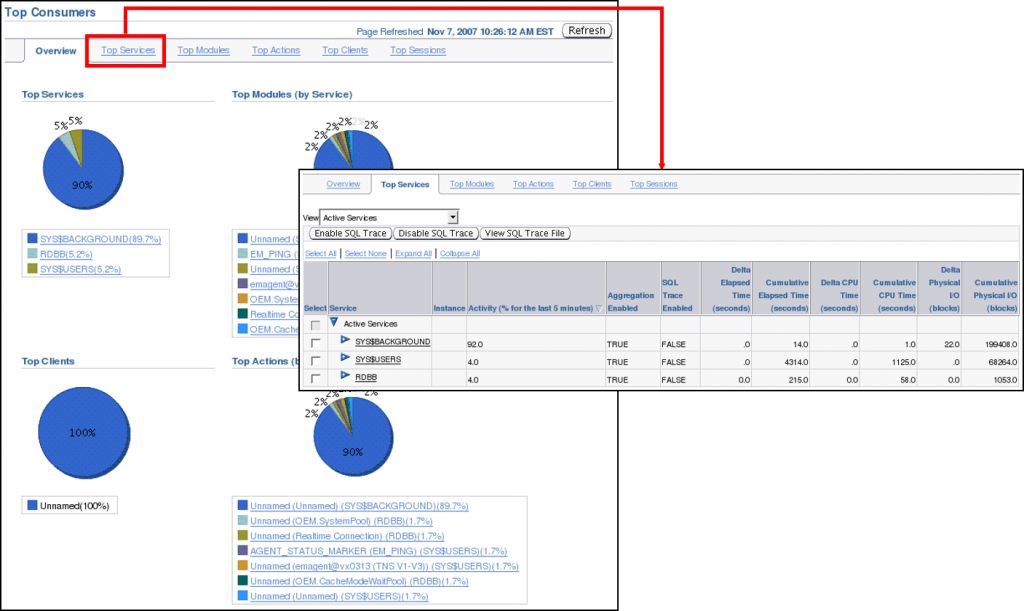
在“Performance(性能)”页中,可以单击“Top Consumers(顶级使用者)”链接。此时将显示“Top Consumers(顶级使用者)”页。
“Top Consumers(顶级使用者)”页包含多个选项卡,将数据库显示为单一系统映像。“Overview(概览)”选项卡式页包含四个饼图:“Top Clients(顶级客户机)”、“Top Services(顶级服务)”、“Top Modules(顶级模块)”和“Top Actions(顶级操作)”。每个图都提供了有关数据库中顶级资源使用者的不同方面。
“Top Services(顶级服务)”选项卡式将显示数据库中定义的服务的性能有关信息。在此页中,您可以在服务级别启用或禁用跟踪。
服务跟踪:示例
- 跟踪服务、模块和操作:
exec DBMS_MONITOR.SERV_MOD_ACT_TRACE_ENABLE(‘AP’);
exec DBMS_MONITOR.SERV_MOD_ACT_TRACE_ENABLE(-
‘AP’, ‘PAYMENTS’, ‘QUERY_DELINQUENT’);
- 跟踪特定客户机标识符:
exec DBMS_MONITOR.CLIENT_ID_TRACE_ENABLE
(client_id=>’C4′, waits => TRUE, binds => FALSE);
在第一个代码框中,将跟踪在 AP 服务下登录的所有会话。无论模块和操作如何变换,都只为使用该服务的每个会话创建一个跟踪文件。为了精确起见,可以只跟踪服务内的特定任务。第二个示例对此操作进行了介绍,该示例对 PAYMENTS 模块内执行 QUERY_DELINQUENT 操作的 AP 服务的所有会话进行跟踪。
通过按服务、模块和操作进行跟踪,可以将精力放在对特定 SQL 的优化上,而不是花费在从不同的程序中筛选包含 SQL 的跟踪文件上。只有定义此任务的 SQL 语句会被记录在跟踪文件中。这是对按服务、模块和操作收集统计信息的一种补充,因为这样可以识别某个操作的相关等待事件。
您还可以启动对某个特定客户机标识符的跟踪,如第三个示例所示。在此例中,C4 是将对其启用 SQL 跟踪的客户机标识符。TRUE 参数指示跟踪文件中存在等待信息。FALSE 参数指示跟踪文件中没有绑定信息。
尽管本幻灯片没有显示,但您可以使用 CLIENT_ID_TRACE_DISABLE 过程为数据库全局禁用对特定客户机标识符的跟踪。对于前面的示例来说,要禁用跟踪,请执行下列命令:
EXECUTE DBMS_MONITOR.CLIENT_ID_TRACE_DISABLE(client_id => ‘C4’);
注: 可以使用 DBMS_SESSION.SET_IDENTIFIER 过程设置 CLIENT_IDENTIFIER。
会话级跟踪:示例
- 对于数据库中的所有会话:
EXEC dbms_monitor.DATABASE_TRACE_ENABLE(TRUE,TRUE);
EXEC dbms_monitor.DATABASE_TRACE_DISABLE();
- 对于特定会话:
EXEC dbms_monitor.SESSION_TRACE_ENABLE(session_id=> 27, serial_num=>60, waits=>TRUE, binds=>FALSE);
EXEC dbms_monitor.SESSION_TRACE_DISABLE(session_id =>27, serial_num=>60);
可以使用跟踪来调试性能问题。启用跟踪的过程已实现为 DBMS_MONITOR 程序包的一部分。这些过程将为数据库启用全局跟踪。
可以使用 DATABASE_TRACE_ENABLE 过程启用整个实例的会话级别 SQL 跟踪。该过程包含下列参数:
- WAITS:指定是否要跟踪等待信息
- BINDS:指定是否要跟踪绑定信息
- INSTANCE_NAME:指定要为其启用跟踪的实例。如果省略了 INSTANCE_NAME,则会为整个数据库启用会话级跟踪。
使用 DATABASE_TRACE_DISABLE 过程可为整个数据库或特定实例禁用 SQL 跟踪。
同样,您可以使用 SESSION_TRACE_ENABLE 过程在本地实例上对给定数据库会话标识符启用跟踪。可以在 V$SESSION 中找到 SERIAL# 和 SID。
使用 SESSION_TRACE_DISABLE 过程可对给定数据库会话标识符和序列号禁用跟踪。
注:SQL 跟踪会产生一些开销,因此通常不倾向在实例级别启用 SQL 跟踪。
跟踪自己的会话
- 启用跟踪:
EXEC DBMS_SESSION.SESSION_TRACE_ENABLE(waits => TRUE, binds => FALSE);
- 禁用跟踪:
EXEC DBMS_SESSION.SESSION_TRACE_DISABLE();
- 轻松标识您的跟踪文件:
alter session set tracefile_identifier=’mytraceid‘;
尽管仅具有 DBA 角色的用户才能调用 DBMS_MONITOR 程序包,但是任何用户都可以使用 DBMS_SESSION 程序包对自己的会话启用 SQL 跟踪。任何用户都可以通过调用 SESSION_TRACE_ENABLE 过程,对自己的会话启用会话级别的 SQL 跟踪。幻灯片中显示了一个示例。
可以使用 DBMS_SESSION.SESSION_TRACE_DISABLE 过程停止转储到跟踪文件。
TRACEFILE_IDENTIFIER 是一个初始化参数,用于指定将作为 Oracle 跟踪文件名称一部分的自定义标识符。使用这样的自定义标识符,您仅根据名称即可识别一个跟踪文件,而不必打开它或查看其内容。每次在会话级别动态修改此参数时,会将下一个跟踪转储写入一个跟踪文件,该文件名称中嵌入了新的参数值。此参数只能用于更改前台进程的跟踪文件的名称;后台进程继续使用以常规格式命名的跟踪文件。对于前台进程,V$PROCESS 视图的 TRACEID 列包含此参数的当前值。设置了此参数值后,跟踪文件名称具有下列格式:sid_ora_pid_traceid.trc
注:SQL_TRACE 初始化参数从 Oracle Database 10g 起被废弃。您可以使用以下语句获取已废弃的参数的完整列表:
SELECT name FROM v$parameter WHERE isdeprecated = ‘TRUE’
trcsess 实用程序
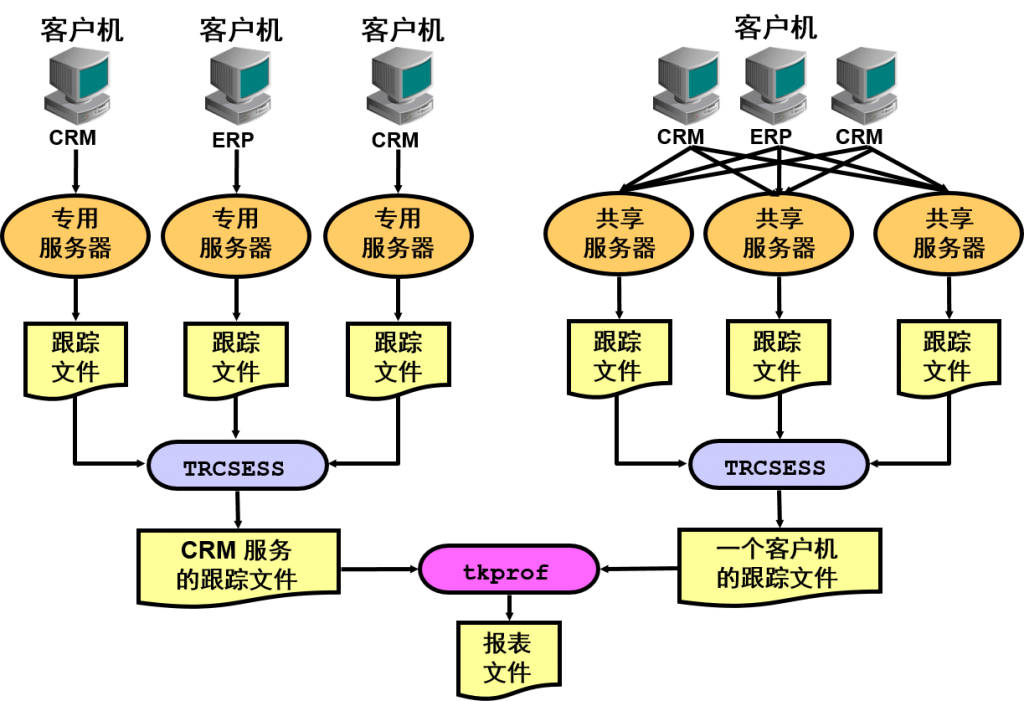
trcsess 实用程序根据下列几个条件合并所选跟踪文件的跟踪输出:会话 ID、客户机标识符、服务名称、操作名称和模块名称。trcsess 将跟踪信息合并到一个输出文件中之后,可以通过 tkprof 处理该输出文件。
使用 DBMS_MONITOR.SERV_MOD_ACT_TRACE_ENABLE 过程时,跟踪信息存在于多个跟踪文件中,必须使用 trcsess 工具将这些信息收集到一个文件中。
出于性能或调试目的合并特定会话或服务的跟踪信息时,trcsess 实用程序非常有用。
在专用服务器模型中,跟踪特定会话通常不是问题,因为将由一个专用进程在会话生存期内负责会话跟踪。可以从属于负责会话跟踪的专用服务器的跟踪文件中查看该会话的所有跟踪信息。但是,即使在专用服务器模型中,跟踪服务也可能是一项复杂的任务。
更不用说在共享服务器配置中了,在该配置中,通常由不同的进程交替为用户会话提供服务。与用户会话有关的跟踪信息分散在属于不同进程的不同跟踪文件中,因此很难完整地了解会话在其生存期内的踪迹。
调用 trcsess 实用程序
trcsess [output=output_file_name]
[session=session_id]
[clientid=client_identifier]
[service=service_name]
[action=action_name]
[module=module_name]
[<trace file names>]
![trcsess [output=output_file_name]](https://www.askmac.cn/wp-content/uploads/2015/12/trcsess-outputoutput_file_name.png)
幻灯片中显示了 trcsess 实用程序的语法,其中:
- output 指定了生成输出的文件。如果没有指定此选项,则将标准输出用作输出。
- session 合并指定会话的跟踪信息。会话标识符是会话索引和会话序列号的组合,例如 21.2371。可以在 V$SESSION 视图中找到这些值。
- clientid 合并给定客户机标识符的跟踪信息。
- service 合并给定服务名称的跟踪信息。
- action 合并给定操作名称的跟踪信息。
- module 合并给定模块名称的跟踪信息。
- <trace file names> 是由空格分隔的所有跟踪文件名称的列表,trcsess 应在其中查找跟踪信息。指定跟踪文件名称时可以使用通配符“*”。如果没有指定跟踪文件,则会将当前目录中的所有文件输入到 trcsess 中。您可以在 ADR 中找到跟踪文件。
注:必须指定 session、clientid、service、action 或 module 选项之一。如果指定了多个选项,则满足所有指定条件的跟踪文件会被合并到输出文件中。
trcsess 实用程序:示例

幻灯片中的示例展示了 trcsess 实用程序的一种可能用法。此示例假设您有三个不同会话:其中有两个会话(左侧会话和右侧会话)被跟踪,另一个会话(中间的会话)可为前两个会话启用或禁用跟踪,并级联前两个会话的跟踪信息。
第一个会话和第二个会话将其客户机标识符设置成“HR session”值。这是使用 DBMS_SESSION 程序包实现的。然后,第三个会话使用 DBMS_MONITOR 程序包为前两个会话启用了跟踪。
此时,ADR 中会生成两个新的跟踪文件;一个会话一个跟踪文件,会话由
“HR session”客户机标识符标识。
现在每个受跟踪的会话都执行自己的 SQL 语句。每条语句都在 ADR 下自己的跟踪文件中生成跟踪信息。
然后,第三个会话使用 DBMS_MONITOR 程序包停止生成跟踪信息,并针对
“HR session”客户机标识符在 mytrace.trc 文件中合并跟踪信息。示例假设在 $ORACLE_BASE/diag/rdbms/orcl/orcl/trace 目录下生成所有跟踪文件,在大多数情况下这是默认设置。
SQL 跟踪文件内容
- 分析、执行和提取计数
- CPU 和所用时间
- 物理读取数和逻辑读取数
- 处理的行数
- 库高速缓存中的未命中数
- 每次分析使用的用户名
- 每次提交和回退
- 每条 SQL 语句的等待事件和绑定数据
- 显示每条 SQL 语句的实际执行计划的行操作
- 一致读取数、物理读取数、物理写入数以及每个行操作所用时间
正如所看到的,SQL 跟踪文件提供有关各条 SQL 语句的性能信息。它为每条语句生成下列统计信息:
- 分析、执行和提取计数
- CPU 和所用时间
- 物理读取数和逻辑读取数
- 处理的行数
- 库高速缓存中的未命中数
- 每次分析使用的用户名
- 每次提交和回退
- 每条 SQL 语句的等待事件数据以及每个跟踪文件的摘要
如果 SQL 语句的游标已关闭,则 SQL 跟踪还提供行源信息,包括以下内容:
- 显示每条 SQL 语句的实际执行计划的行操作
- 行数量、一致读取数、物理读取数、物理写入数以及每项操作所用的时间。只有在 STATISTICS_LEVEL 初始化参数设置为 ALL 时,才可能显示这些信息。
注:使用 SQL 跟踪工具会对性能产生严重影响,可能会增加系统开销和 CPU 使用率,导致磁盘空间不足。
SQL 跟踪文件内容:示例
*** [ Unix process pid: 19687 ] *** 2008-02-25 15:49:19.820 *** 2008-02-25 15:49:19.820 *** 2008-02-25 15:49:19.820 *** 2008-02-25 15:49:19.820 … ==================== PARSING IN CURSOR #4 len=23 dep=0 uid=82 oct=3 lid=82 tim=1203929332521849 hv=4069246757 ad='34b6f730' sqlid='f34thrbt8rjt5' select * from employees END OF STMT PARSE #4:c=49993,e=67123,p=28,cr=403,cu=0,mis=1,r=0,dep=0,og=1,tim=1203929332521845 EXEC #4:c=0,e=16,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=1,tim=1203929332521911 FETCH #4:c=1000,e=581,p=6,cr=6,cu=0,mis=0,r=1,dep=0,og=1,tim=1203929332522553 FETCH #4:c=0,e=45,p=0,cr=1,cu=0,mis=0,r=15,dep=0,og=1,tim=1203929332522936 … FETCH #4:c=0,e=49,p=0,cr=1,cu=0,mis=0,r=1,dep=0,og=1,tim=1203929333649241 STAT #4 id=1 cnt=107 pid=0 pos=1 obj=70272 op='TABLE ACCESS FULL EMPLOYEES (cr=15 pr=6 pw=6 time=0 us cost=3 size=7276 card=107)' *** [ Unix process pid: 19687 ] *** 2008-02-25 15:49:19.820 *** 2008-02-25 15:49:19.820 *** 2008-02-25 15:49:19.820 *** 2008-02-25 15:49:19.820 …
Oracle DB 可以生成多种类型的跟踪文件。本课提到的跟踪文件通常被称为 SQL 跟踪文件。
幻灯片显示了摘自由前面示例生成的 mytrace.trc SQL 跟踪文件的一段示例输出。
在这种类型的跟踪文件中,针对每条被跟踪的语句,您可以找到语句自身以及一些相应的游标详细资料。可以查看语句的以下各个执行阶段的详细统计信息:PARSE、EXEC 和 FETCH。正如您所看到的,取决于查询返回的行数,一个 EXEC 可以有多个 FETCH。
跟踪的最后一部分是包含每个行源的累积统计信息的执行计划。
取决于启用跟踪的方式,您还可以在生成的跟踪文件中获得有关等待事件和绑定变量的
信息。
通常情况下,您不要尝试解释跟踪文件本身。这是因为您对会话执行的操作并没有一个整体概念。例如,一个会话可能在不同时间执行相同语句多次。因此相应跟踪分散在整个跟踪文件中,很难找到它们。
您可以改而使用其它工具(例如 tkprof)来解释原始跟踪信息的内容。
设置 SQL 跟踪文件的格式:概览
使用 tkprof 实用程序设置 SQL 跟踪文件的格式:
- 对原始跟踪文件进行排序以显示顶级 SQL 语句
- 筛选字典语句
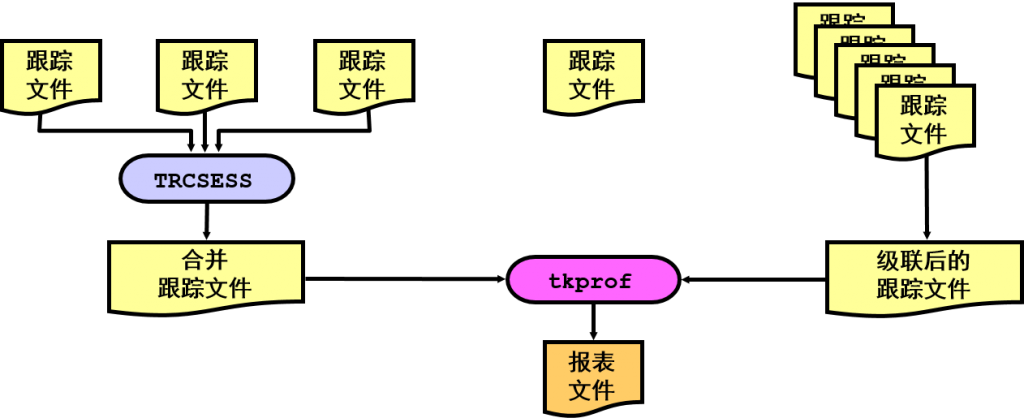
tkprof 是一个可执行文件,它分析 SQL 跟踪文件以生成可读性更好的输出。请记住,可以从原始跟踪文件中获取 tkprof 中的所有信息。可以使用 tkprof 调用许多排序函数。通过在命令提示符下输入 tkprof 可以访问大量排序选项。一个有用的起点是 fchela 排序选项,该选项可按所用的提取时间排序输出。生成的 .prf 文件将最费时的 SQL 语句列在文件的开头。另一个有用的参数是 sys。这可以用于防止显示以 SYS 用户身份运行的 SQL 语句。这会使输出文件变得更短且更易于管理。
在生成一定数量的 SQL 跟踪文件后,可以执行以下操作:
- 对各个跟踪文件运行 tkprof,生成一定数量的已格式化的输出文件,一个会话一个输出文件。
- 级联这些跟踪文件,然后对结果运行 tkprof,以针对整个实例生成一个已格式化的输出文件。
- 运行 trcsess 命令行实用程序,以合并几个跟踪文件的跟踪信息,然后对结果运行 tkprof。
tkprof 不报告跟踪文件中记录的 COMMIT 和 ROLLBACK。
注:跟踪会话时,请将 TIMED_STATISTICS 参数设置为 TRUE,因为不这样做就不能
执行基于时间的比较。在 Oracle Database 11g 中 TRUE 是默认值。
调用 tkprof 实用程序
tkprof inputfile outputfile [waits=yes|no]
[sort=option]
[print=n]
[aggregate=yes|no]
[insert=sqlscritfile]
[sys=yes|no]
[table=schema.table]
[explain=user/password]
[record=statementfile]
[width=n]
输入没有任何参数的 tkprof 命令时,它会生成一个用法消息,以及所有 tkprof 选项的说明。本幻灯片显示了各种参数:
- inputfile:指定 SQL 跟踪输入文件
- outputfile:指定 tkprof 将其已格式化输出写入到的文件
- waits:指定是否为跟踪文件中的任何等待事件记录摘要。值为 YES 或 NO。默认值为 YES。
- sorts:按指定排序选项的降序对跟踪 SQL 语句进行排序,然后将其列到输出文件中。如果指定了多个选项,则输出按排序选项中指定值的总和的降序排序。如果省略此参数,则 tkprof 会按第一次使用的顺序将语句列在输出文件中。
- print:仅列出输出文件中第一批按整数排序的 SQL 语句。如果省略此参数,tkprof 会列出所有受跟踪的 SQL 语句。此参数不影响可选的 SQL 脚本。SQL 脚本始终为所有受跟踪的 SQL 语句生成插入数据。
- aggregate:如果设置为 NO,tkprof 不会对相同 SQL 文本的多个用户进行累计。
- insert:创建一个 SQL 脚本以在数据库中存储跟踪文件统计信息。tkprof 使用您为 sqlscritfile 指定的名称创建此脚本。此脚本会创建一个表,并在此表中为每条受跟踪的 SQL 语句插入一个统计信息行。
- sys:允许或禁止在输出文件中列出由 SYS 用户发出的 SQL 语句,或递归 SQL 语句。默认值为 YES,此值会让 tkprof 列出这些语句。NO 值会让 tkprof 省略这些语句。此参数不影响可选的 SQL 脚本。SQL 脚本始终为所有受跟踪的语句(包括递归 SQL 语句)插入统计信息。
- table:指定在将执行计划写入到输出文件之前,tkprof 在其中临时存放执行计划的方案和表名称。如果指定的表已存在,tkprof 会删除表中的所有行,将该表用于 EXPLAIN PLAN 语句(会在表中写入更多的行),然后删除这些行。如果此表不存在,tkprof 会创建并使用该表,然后删除它。指定的用户必须能够对表发出 INSERT、SELECT 和 DELETE 语句。如果表已不存在,用户也必须能够发出 CREATE TABLE 和 DROP TABLE 语句。此选项允许多个实例在 EXPLAIN 值中使用相同用户同时运行 tkprof。这些实例可以指定不同的 TABLE 值,避免破坏性地干扰彼此之间对临时计划表的处理。如果在没有 TABLE 参数的情况下使用 EXPLAIN 参数,则 tkprof 会使用 EXPLAIN 参数指定的用户方案中的 PROF$PLAN_TABLE 表。如果在没有 EXPLAIN 参数的情况下使用 TABLE 参数,则 tkprof 会忽略 TABLE 参数。如果计划表不存在,tkprof 会创建 PROF$PLAN_TABLE 表,然后在结束时删除它。
- explain:确定跟踪文件中每条 SQL 语句的执行计划,并将这些执行计划写入到输出文件。tkprof 在使用此参数中指定的用户和口令连接到系统后,通过发出 EXPLAIN PLAN 语句确定执行计划。指定的用户必须具有 CREATE SESSION 系统权限。如果使用了 EXPLAIN 选项,则 tkprof 在处理大型跟踪文件时会花费较长的时间。
- record:以指定文件名 statementfile 创建一个 SQL 脚本,使其包含跟踪文件中的所有非递归 SQL 语句。这可以用来重放跟踪文件中的用户事件。
- width:一个整数,用于控制某些 tkprof 输出(例如解释计划)的输出行宽度。此参数对于 tkprof 输出的后处理很有用。
输入和输出文件是唯一的必需参数。
tkprof 排序选项
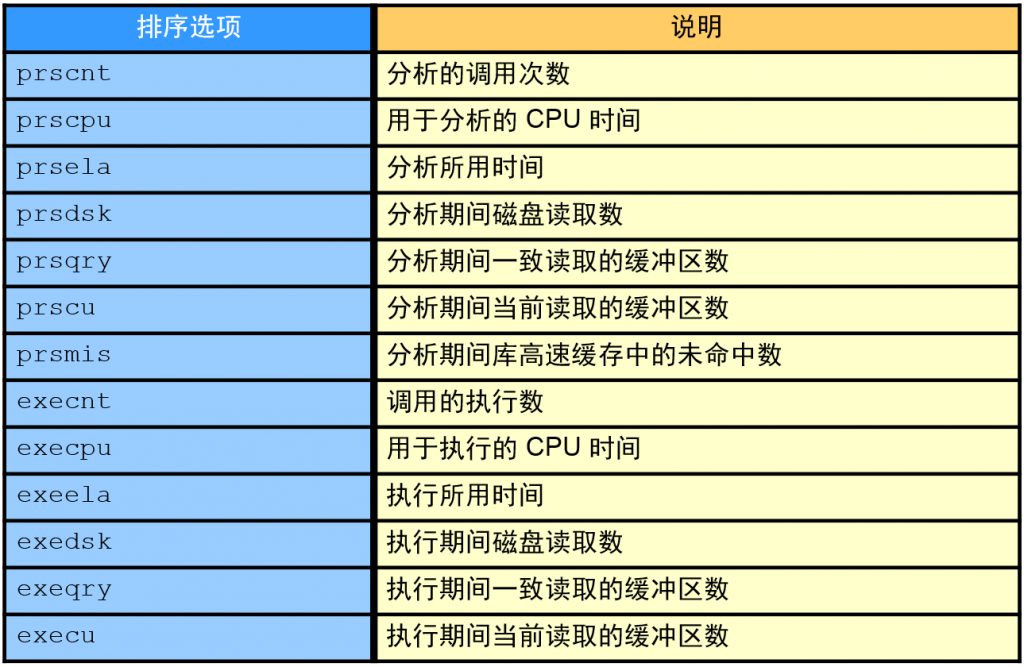
上表列出了可以与 tkprof 的排序参数一起使用的所有排序选项。
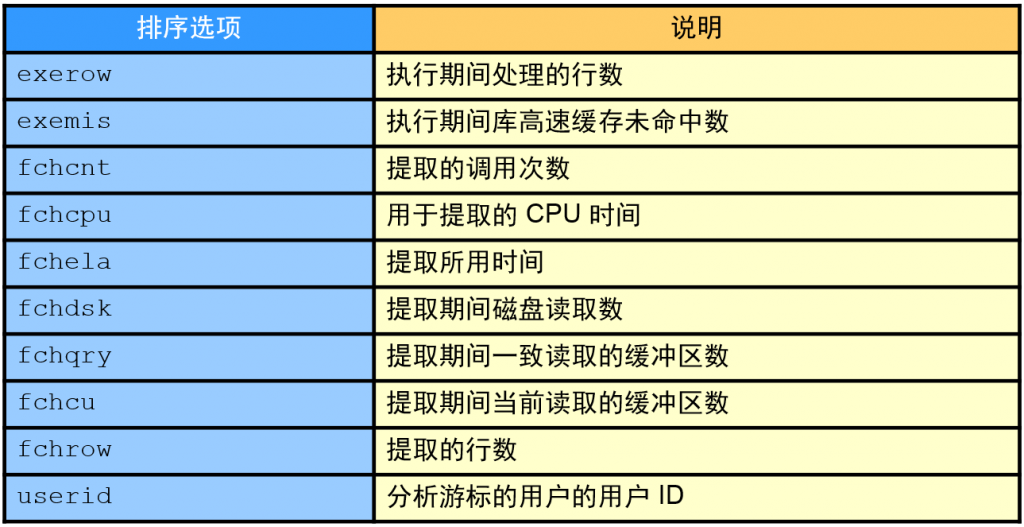
tkprof 命令的输出
- SQL 语句的文本
- 划分为三个 SQL 处理步骤的跟踪统计信息(针对语句和递归调用):

tkprof 命令输出按 SQL 处理步骤列出 SQL 语句的统计信息。
包含统计信息的每个行的步骤由调用列的值标识。
注:PARSE 值包括硬分析和软分析。硬分析是指执行计划的制定(包括优化);它随后会存储在库高速缓存中。软分析意味着向数据库发送 SQL 语句以进行分析,但数据库会在库高速缓存中查找语句,并且仅需要验证一些事项,例如访问权限。硬分析的开销很高,特别是优化。软分析主要在库高速缓存活动方面开销较大。
跟踪统计信息有七种类别:

下一页对输出进行了解释。
示例输出如下所示:
call count cpu elapsed disk query current rows
——- —— ——– ———- ———- ———- ———- —
Parse 1 0.03 0.06 0 0 0 0
Execute 1 0.06 0.30 1 3 0 0
Fetch 2 0.00 0.46 0 0 0 1
——- —— ——– ———- ———- ———- ———- —
total 4 0.09 0.83 1 3 0 1
在 CALL 列旁边,tkprof 为每条语句显示下列统计信息:
- Count:语句的分析次数、执行次数或提取次数(先检查此列的值是否大于 1,然后解释其它列中的统计信息。除非使用了 AGGREGATE = NO 选项,否则 tkprof 会将相同的语句执行累计到一个摘要表中。)
- CPU:所有分析、执行或提取调用花费的总 CPU 时间,以秒为单位
- Elapsed:所有分析、执行或提取调用的所用时间总计,以秒为单位
- Disk:所有分析、执行或提取调用从磁盘的数据文件中物理读取的数据块总数
- Query:所有分析、执行或提取调用在一致模式下检索的缓冲区总数(对于查询,通常在一致模式下检索缓冲区。)
- Current:在当前模式下检索的缓冲区总数(对于数据操纵语言语句,通常在当前模式下检索缓冲区。但是,始终在当前模式下检索段标头块。)
- Rows:SQL 语句处理的行数总计(此总数不包括 SQL 语句的子查询处理的行。对于 SELECT 语句,显示在提取步骤中返回的行数。对于 UPDATE、DELETE 和 INSERT 语句,显示在执行步骤中处理的行数。)
附注
- DISK 等同于 v$sysstat 或 AUTOTRACE 中的 physical reads。
- QUERY 等同于 v$sysstat 或 AUTOTRACE 中的 consistent gets。
- CURRENT 等同于 v$sysstat 或 AUTOTRACE 中的 db block gets。
tkprof 命令的输出
tkprof 输出还包括下列内容:
- 递归 SQL 语句
- 库高速缓存未命中数
- 分析用户 ID
- 执行计划
- 优化程序模式或提示
- 行源操作
…
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 61
Rows Row Source Operation
——- —————————————————
24 TABLE ACCESS BY INDEX ROWID EMPLOYEES (cr=9 pr=0 pw=0 time=129 us)
24 INDEX RANGE SCAN SAL_IDX (cr=3 pr=0 pw=0 time=1554 us)(object id …
递归调用
要执行用户发出的 SQL 语句,Oracle 服务器有时必须发出其它语句。这样的语句称为递归 SQL 语句。例如,如果要在某个表中插入一行,但该表没有足够空间容纳该行,Oracle 服务器就进行递归调用以动态分配空间。当数据字典高速缓存中不包含数据字典信息,必须从磁盘检索时,也会生成递归调用。
如果在 SQL 跟踪工具处于启用状态下发生了递归调用,tkprof 会在输出文件中清晰地将其标记为递归 SQL 语句。通过设置 SYS=NO 命令行参数可以在输出文件中隐藏递归调用列表。请注意,递归 SQL 语句的统计信息始终包括在导致递归调用的 SQL 语句列表中。
库高速缓存未命中数
tkprof 还列出由每条 SQL 语句的分析和执行步骤产生的库高速缓存未命中数。这些统计信息显示在单独的行中,在表格式统计信息之后。
行源运算
提供对行和其它行源信息执行的每个操作处理的行数,例如物理读取数和写入数;
cr = 一致读取数,w = 实际写入数,r = 实际读取数,time = 时间(微秒)。
分析用户 ID
这是最后一位分析语句的用户的 ID。
行源操作
行源操作为 SQL 语句的执行显示数据源。只有在跟踪期间已关闭了游标的情况下才包含此项信息。如果跟踪文件中没有显示行源操作,则可能需要查看 EXPLAIN PLAN。
执行计划
如果在 tkprof 命令行中指定 EXPLAIN 参数,tkprof 使用 EXPLAINPLAN 命令为每条受跟踪的 SQL 语句生成执行计划。tkprof 还显示执行计划的每个步骤所处理的行数。
注:请注意,执行计划是在运行 tkprof 命令时生成的,而不是在生成跟踪文件时生成的。例如,如果自跟踪语句后创建或删除了索引,则可能产生影响。
优化程序模式或提示
指明在执行语句期间使用的优化程序提示。如果没有提示,则显示使用的优化程序模式
无索引时的 tkprof 输出:示例
...
select max(cust_credit_limit)
from customers
where cust_city ='Paris'
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- -------
Parse 1 0.02 0.02 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.10 0.09 1408 1459 0 1
------- ------ -------- ---------- ---------- ---------- ---------- -------
total 4 0.12 0.11 1408 1459 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 61
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1459 pr=1408 pw=0 time=93463 us)
77 TABLE ACCESS FULL CUSTOMERS (cr=1459 pr=1408 pw=0 time=31483 us)
幻灯片中的示例显示了从 CUSTOMERS 表提取的几个执行(行)的累积结果。这需要 0.12 秒的 CPU 提取时间。该语句通过对 CUSTOMERS 表进行全表扫描来执行,在输出的行源操作中可以看到此信息。
必须对此语句进行优化。
注:如果 CPU 或 elapsed 值为 0,则没有设置 timed_statistics。
有索引时的 tkprof 输出:示例
...
select max(cust_credit_limit) from customers
where cust_city ='Paris'
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ---------
Parse 1 0.01 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 77 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ---------total 4 0.01 0.00 0 77 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 61
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=77 pr=0 pw=0 time=732 us)
77 TABLE ACCESS BY INDEX ROWID CUSTOMERS (cr=77 pr=0 pw=0 time=1760 us)
77 INDEX RANGE SCAN CUST_CUST_CITY_IDX (cr=2 pr=0 pw=0 time=100
us)(object id 55097)
幻灯片中显示的结果表明,针对 CUST_CITY 列创建了索引时,CPU 时间减少到 0.01 秒。这些结果可能已实现,因为该语句使用索引来检索数据。另外,由于此示例重复执行相同语句,大多数据块已在内存中。您可以通过有效地编制索引来显著改善性能。使用 SQL 跟踪工具确定需改善的区域。
注:除非必须使用,否则不要构建索引。因为使用索引必须添加、更改或删除对行的引用,因此会减慢 INSERT、UPDATE 和 DELETE 命令的处理速度。未使用的索引应删除。但是,不需要通过 EXPLAIN PLAN 处理所有应用 SQL,您可以使用索引监控来识别和删除任何未使用的索引。

Comment