Cardinality Feedback基数反馈是版本11.2中引入的关于SQL 性能优化的新特性,该特性主要针对 统计信息陈旧、无直方图或虽然有直方图但仍基数计算不准确的情况, Cardinality基数的计算直接影响到后续的JOIN COST等重要的成本计算评估,造成CBO选择不当的执行计划。以上是Cardinality Feedback特性引入的初衷。
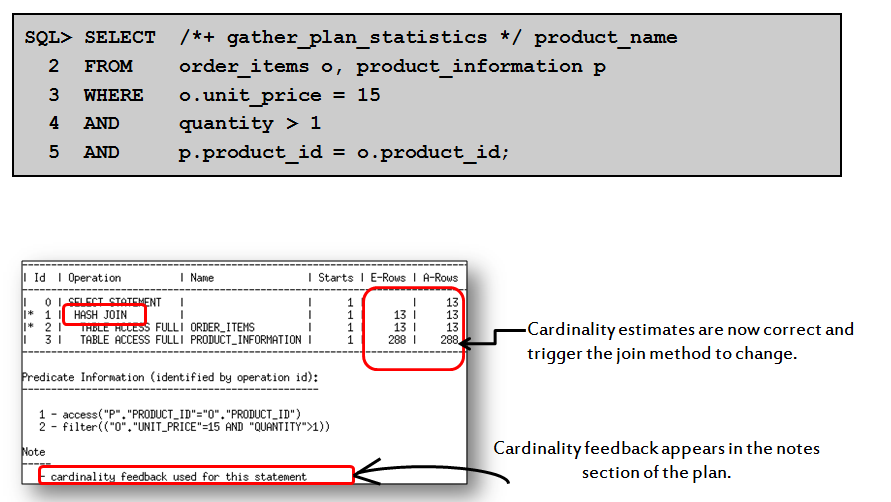
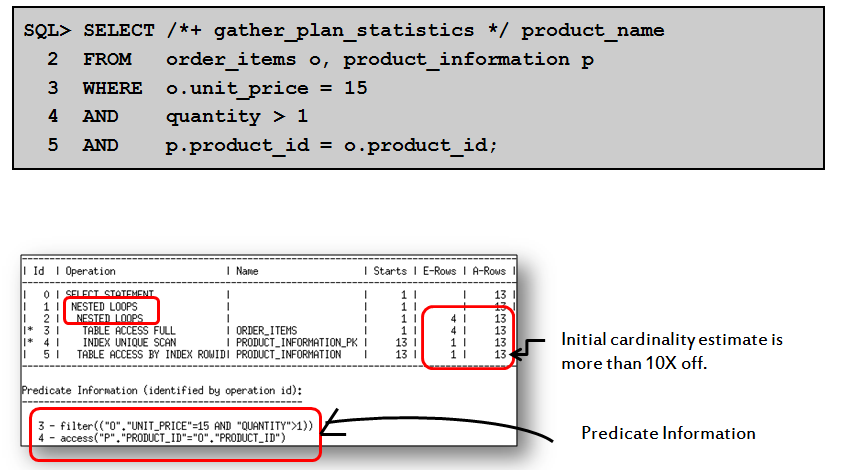
但是每一个Oracle新版本引入的新特性 都被一些老外DBA称之为buggy ,Cardinality Feedback基数反馈多少也造成了一些麻烦,典型的情况是测试语句性能时,第一次的性能最好,之后再运行其性能变差。
我们来看一下 Cardinality Feedback基数反馈是如何作用的:
注意使用普通用户来测试Cardinality Feedback,sys用户被默认禁用该特性
Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> conn maclean/oracle
已连接。
SQL> show parameter dynamic
NAME TYPE VALUE
------------------------------------ ---------------------- ------------------------------
optimizer_dynamic_sampling integer 0
SQL> create table test as select * from dba_tables;
表已创建。
SQL> select /*+ gather_plan_statistics */ count(*) from test;
COUNT(*)
----------
2873
SQL> select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------
SQL_ID 0p4u1wqwg6t9z, child number 0
-------------------------------------
select /*+ gather_plan_statistics */ count(*) from test
Plan hash value: 1950795681
-------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 104 |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 104 |
| 2 | TABLE ACCESS FULL| TEST | 1 | 8904 | 2873 |00:00:00.01 | 104 |
-------------------------------------------------------------------------------------
已选择14行。
SQL> select /*+ gather_plan_statistics */ count(*) from test;
COUNT(*)
----------
2873
SQL> select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------
SQL_ID 0p4u1wqwg6t9z, child number 1
-------------------------------------
select /*+ gather_plan_statistics */ count(*) from test
Plan hash value: 1950795681
-------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 104 |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 104 |
| 2 | TABLE ACCESS FULL| TEST | 1 | 2873 | 2873 |00:00:00.01 | 104 |
-------------------------------------------------------------------------------------
Note
-----
- cardinality feedback used for this statement
已选择18行。
上例中第一次运行时,由于未收集表上的统计信息且optimizer_dynamic_sampling=0 关闭了动态采样所以基数评估值(1)和实际值(2873)有着较大的差距。
cardinality feedback used for this statement这个信息说明第二次执行时使用了Cardinality Feedback基数反馈,且其基数评估也十分精确了,这是因为第二次执行时考虑到第一次执行时的基数反馈,我们来看看Oracle到底是如何做到的:
SQL> alter system flush shared_pool;
系统已更改。
SQL>
SQL> alter session set events '10053 trace name context forever, level 1';
会话已更改。
SQL> select /*+ gather_plan_statistics */ count(*) from test;
COUNT(*)
----------
2873
SQL> select /*+ gather_plan_statistics */ count(*) from test;
COUNT(*)
----------
2873
10053 trace:
第一次执行:
sql= select /*+ gather_plan_statistics */ count(*) from test
----- Explain Plan Dump -----
----- Plan Table -----
============
Plan Table
============
--------------------------------------+-----------------------------------+
| Id | Operation | Name | Rows | Bytes | Cost | Time |
--------------------------------------+-----------------------------------+
| 0 | SELECT STATEMENT | | | | 31 | |
| 1 | SORT AGGREGATE | | 1 | | | |
| 2 | TABLE ACCESS FULL | TEST | 8904 | | 31 | 00:00:01 |
--------------------------------------+-----------------------------------+
SELECT /*+ OPT_ESTIMATE (TABLE "TEST" ROWS=2873.000000 ) */ COUNT(*) "COUNT(*)" FROM "MACLEAN"."TEST" "TEST"
SINGLE TABLE ACCESS PATH
Single Table Cardinality Estimation for TEST[TEST]
Table: TEST Alias: TEST
Card: Original: 8904.000000 >> Single Tab Card adjusted from:8904.000000 to:2873.000000
Rounded: 2873 Computed: 2873.00 Non Adjusted: 8904.00
Access Path: TableScan
Cost: 31.10 Resp: 31.10 Degree: 0
Cost_io: 31.00 Cost_cpu: 1991217
Resp_io: 31.00 Resp_cpu: 1991217
Best:: AccessPath: TableScan
Cost: 31.10 Degree: 1 Resp: 31.10 Card: 2873.00 Bytes: 0
sql= select /*+ gather_plan_statistics */ count(*) from test
----- Explain Plan Dump -----
----- Plan Table -----
============
Plan Table
============
--------------------------------------+-----------------------------------+
| Id | Operation | Name | Rows | Bytes | Cost | Time |
--------------------------------------+-----------------------------------+
| 0 | SELECT STATEMENT | | | | 31 | |
| 1 | SORT AGGREGATE | | 1 | | | |
| 2 | TABLE ACCESS FULL | TEST | 2873 | | 31 | 00:00:01 |
--------------------------------------+-----------------------------------+
可以看到第二次执行时SQL最终转换加入了 OPT_ESTIMATE (TABLE “TEST” ROWS=2873.000000 )的HINT ,OPT_ESTIMATE HINT一般由 kestsaFinalRound()内核函数生成。该HINT用以纠正各种类型的优化器评估,例如某表上的基数或某个列的最大、最小值。反应出优化的不足或者BUG。
可以通过V$SQL_SHARED_CURSOR和来找出现有系统shared pool中仍存在的 使用了Cardinality Feedback基数反馈的子游标:
SQL> select sql_ID,USE_FEEDBACK_STATS FROM V$SQL_SHARED_CURSOR where USE_FEEDBACK_STATS ='Y'; SQL_ID US -------------------------- -- 159sjt1f6khp2 Y
还可以使用cardinality HINT来强制使用Cardinality Feedback 。
select /*+ cardinality(test, 1) */ count(*) from test;
如何禁用Cardinality Feedback基数反馈
对于这些”惹火”特性,为了stable,往往考虑关闭该特性。
可以通过多种方法禁用该特性
1. 使用 _optimizer_use_feedback 隐藏参数
session 级别
SQL> alter session set “_optimizer_use_feedback”=false;
会话已更改。
system级别
SQL> alter system set “_optimizer_use_feedback”=false;
系统已更改。
2. 使用opt_param(‘_optimizer_use_feedback’ ‘false’) HINT
例如:
select /*+ opt_param(‘_optimizer_use_feedback’ ‘false’) cardinality(test,1) */ count(*) from test;


