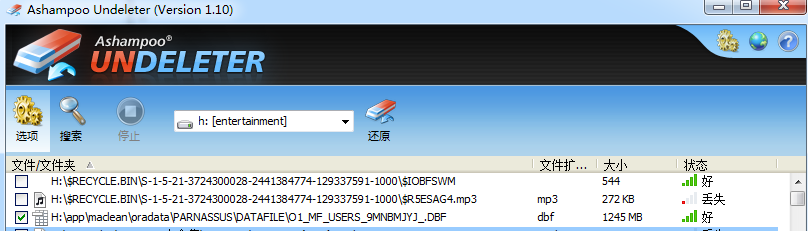
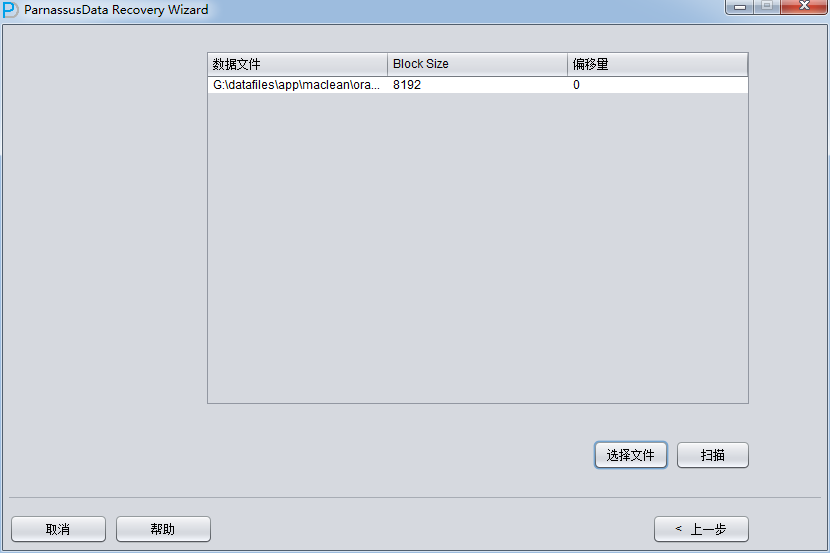
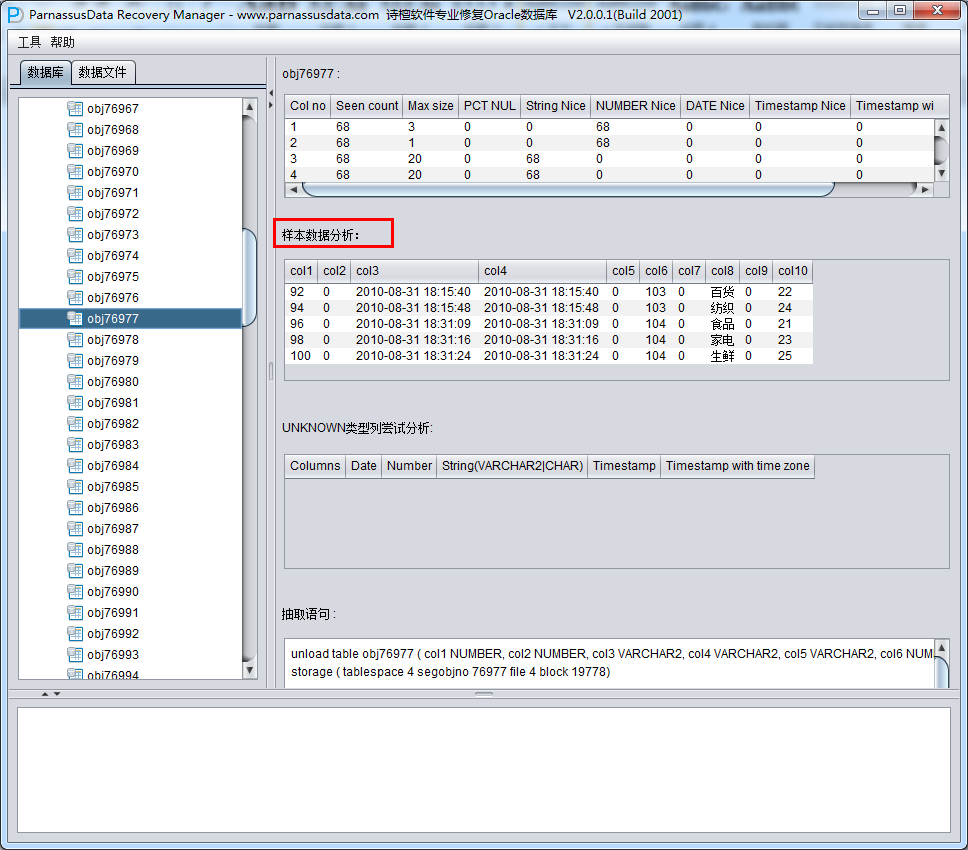
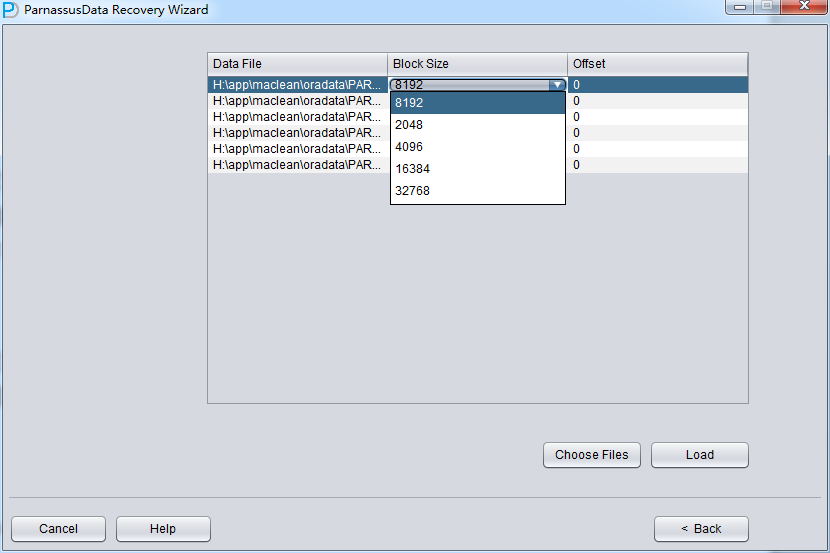
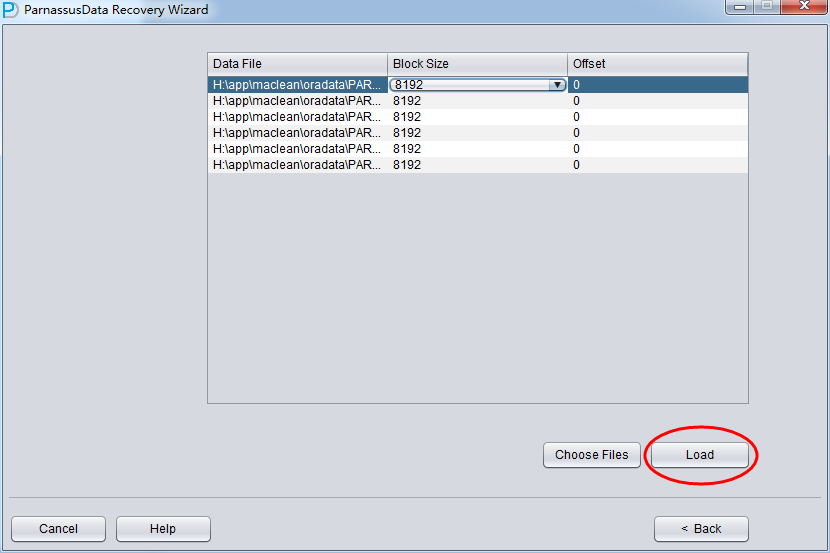
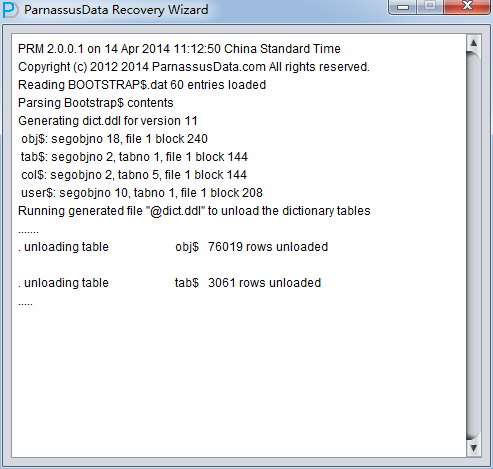
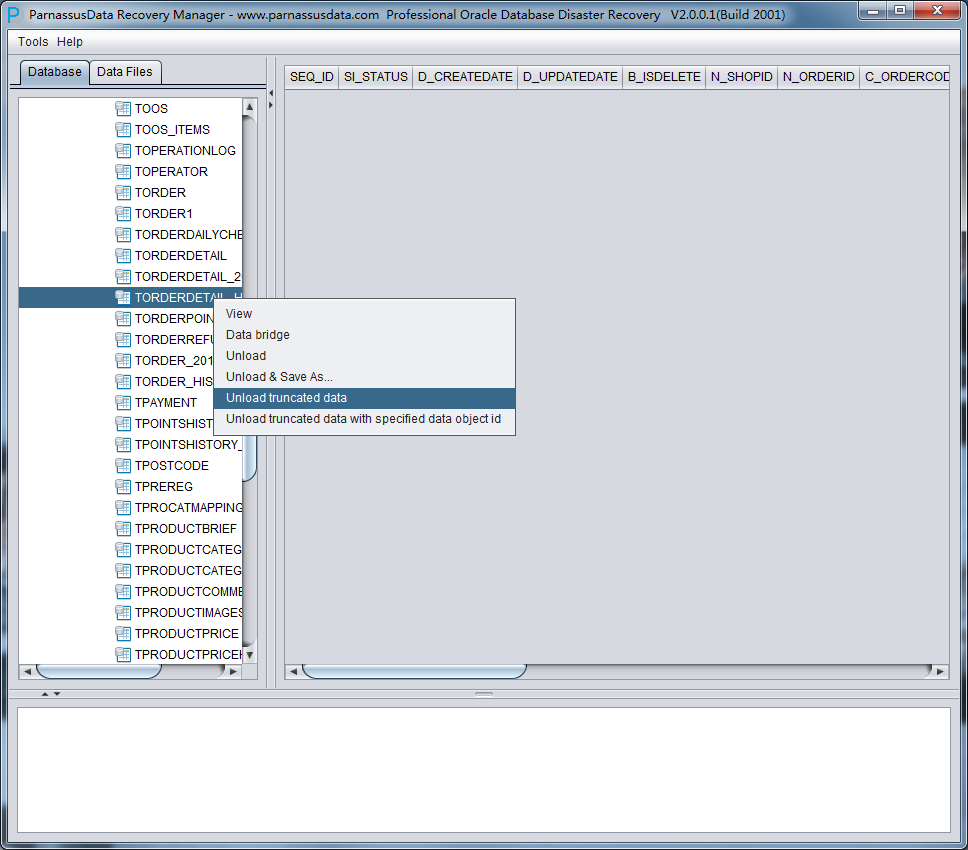
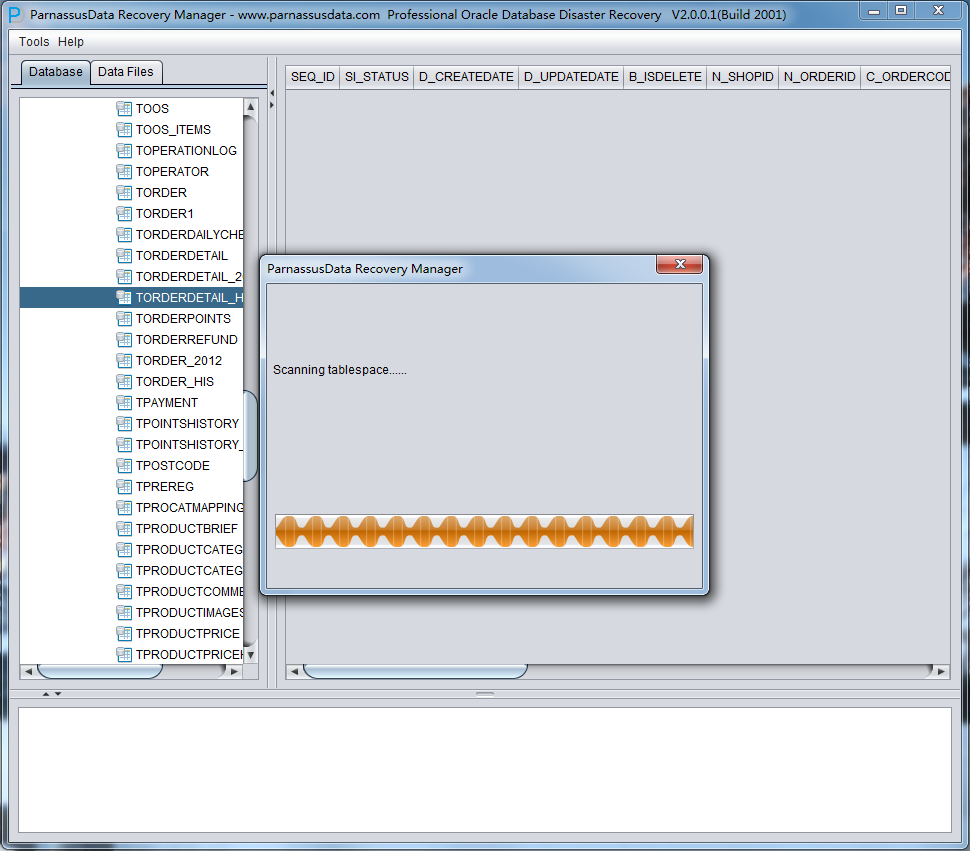
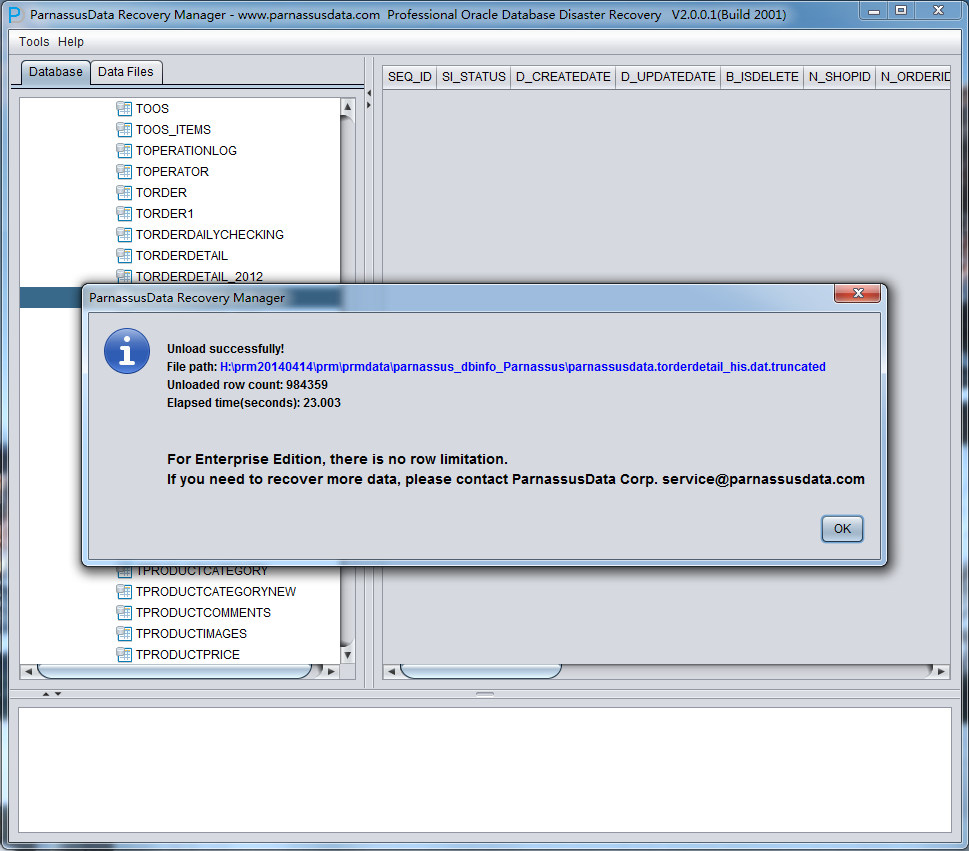
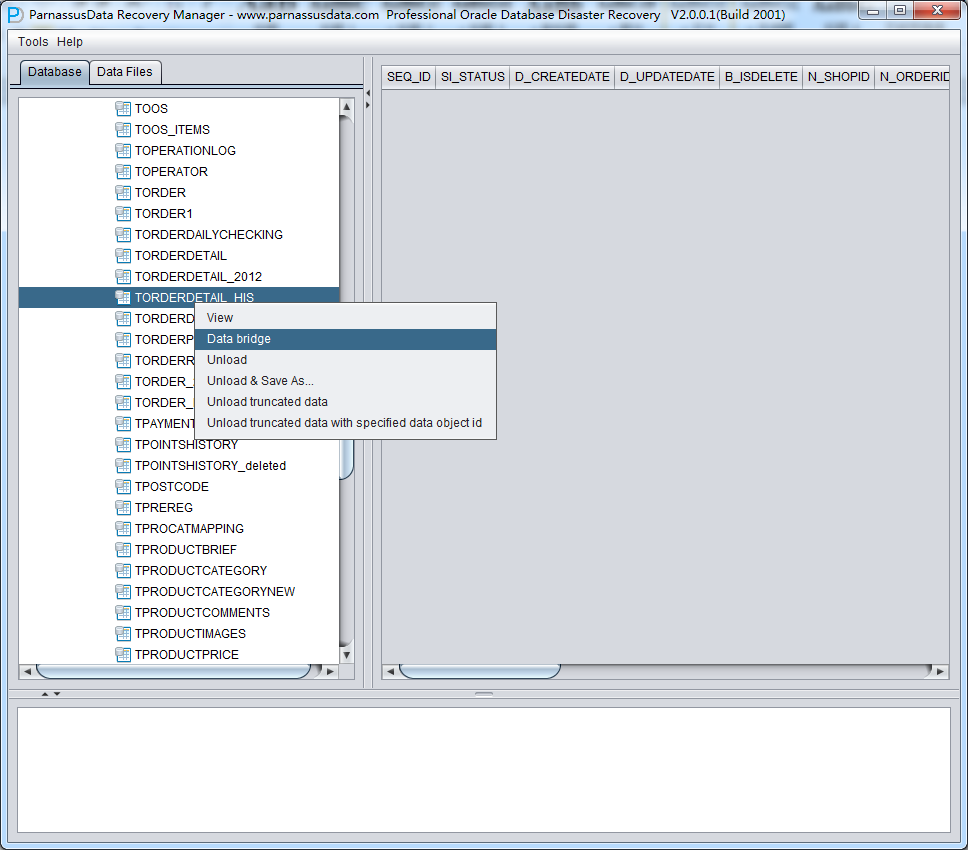
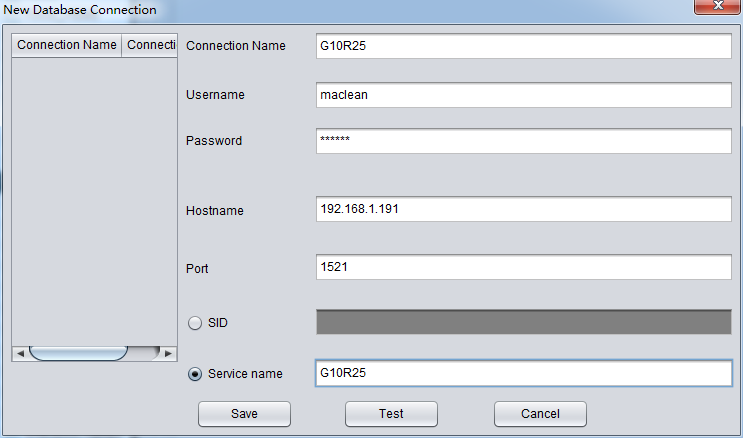
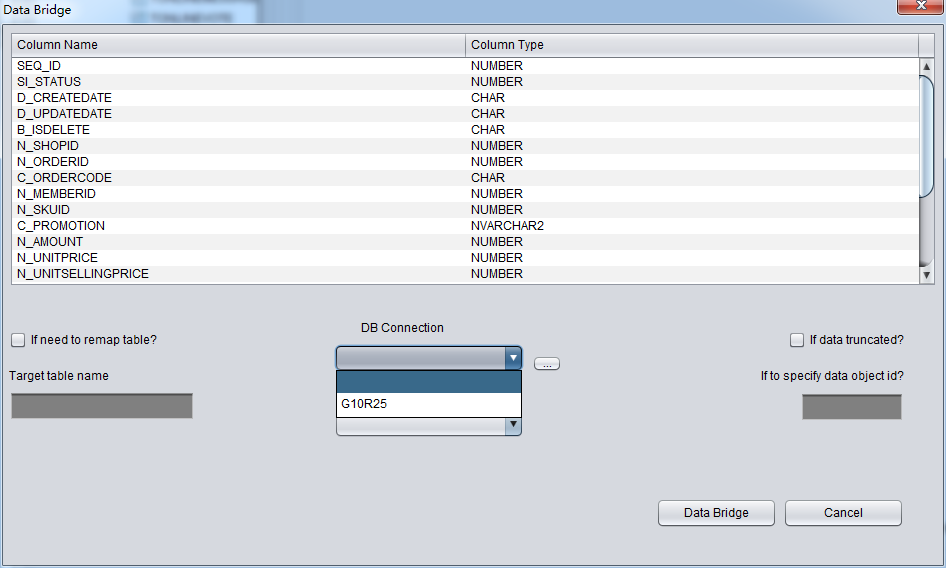
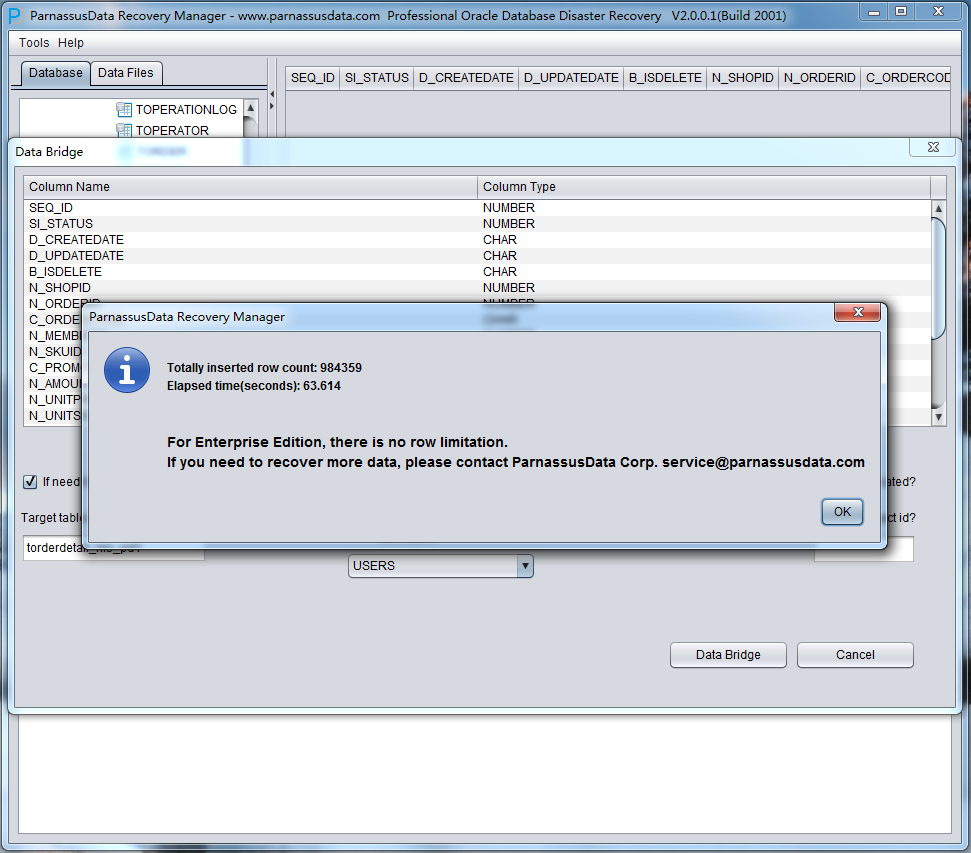
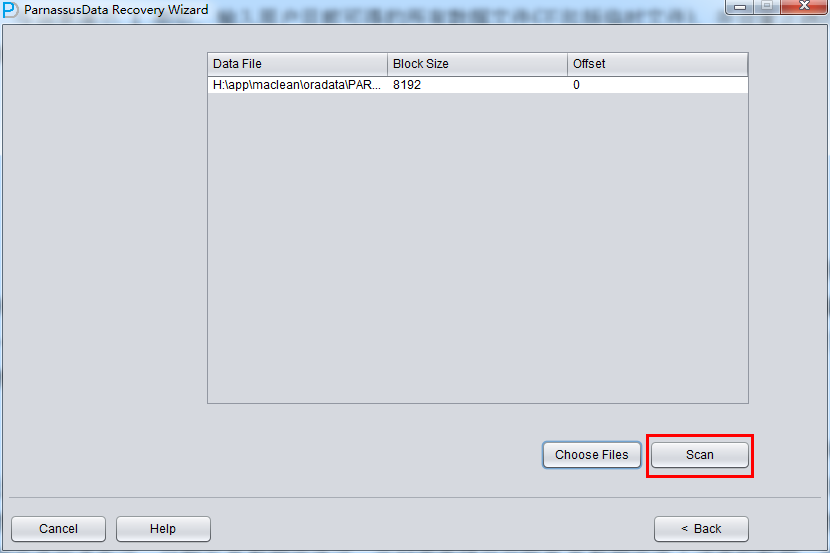
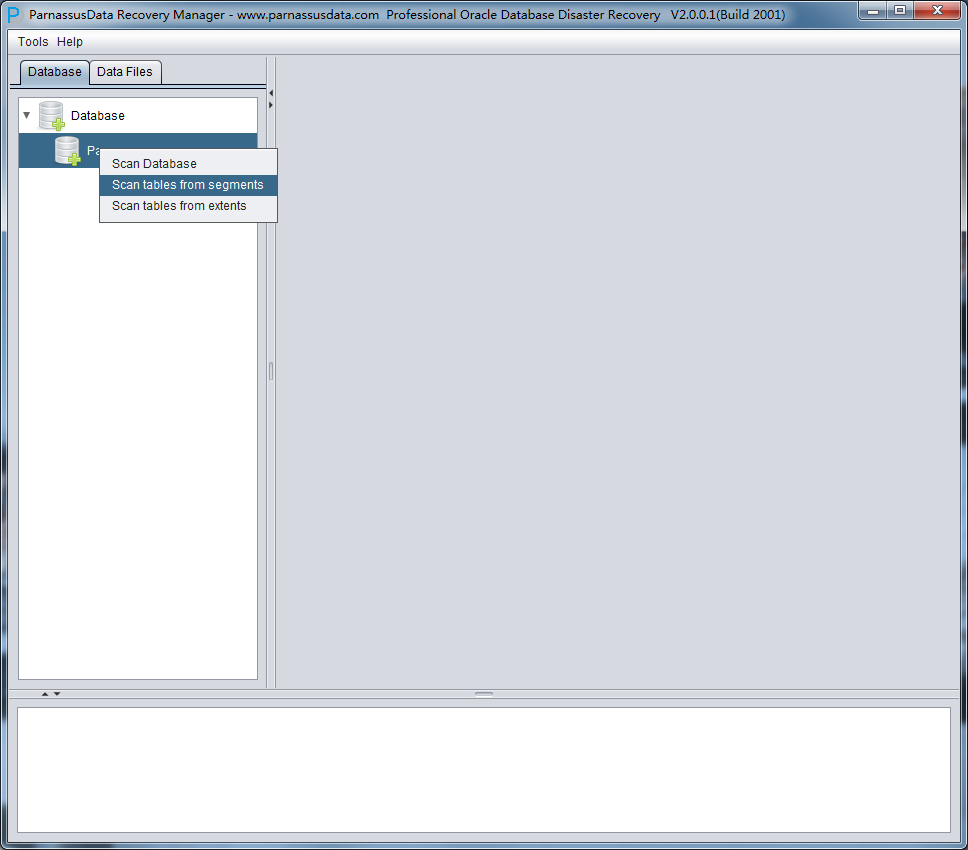
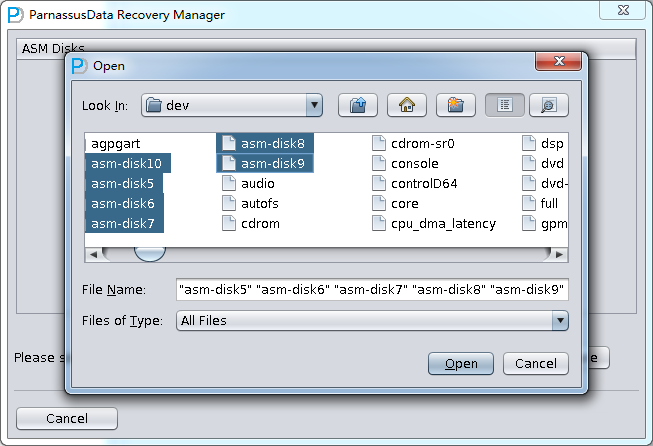
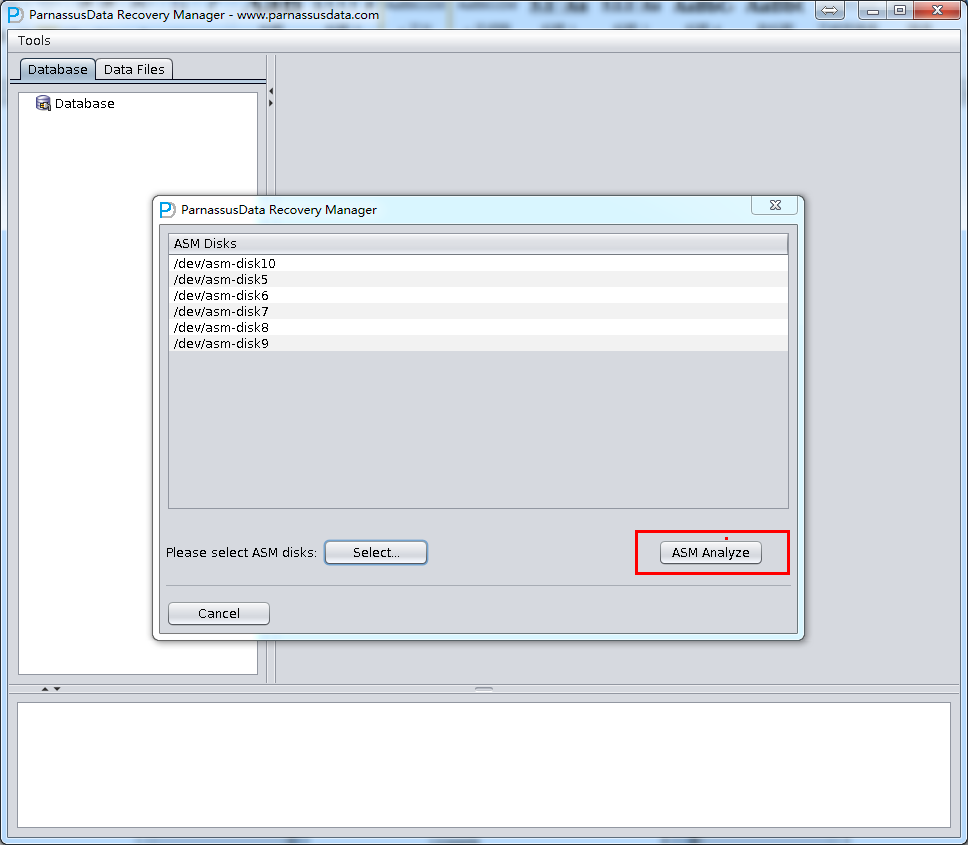
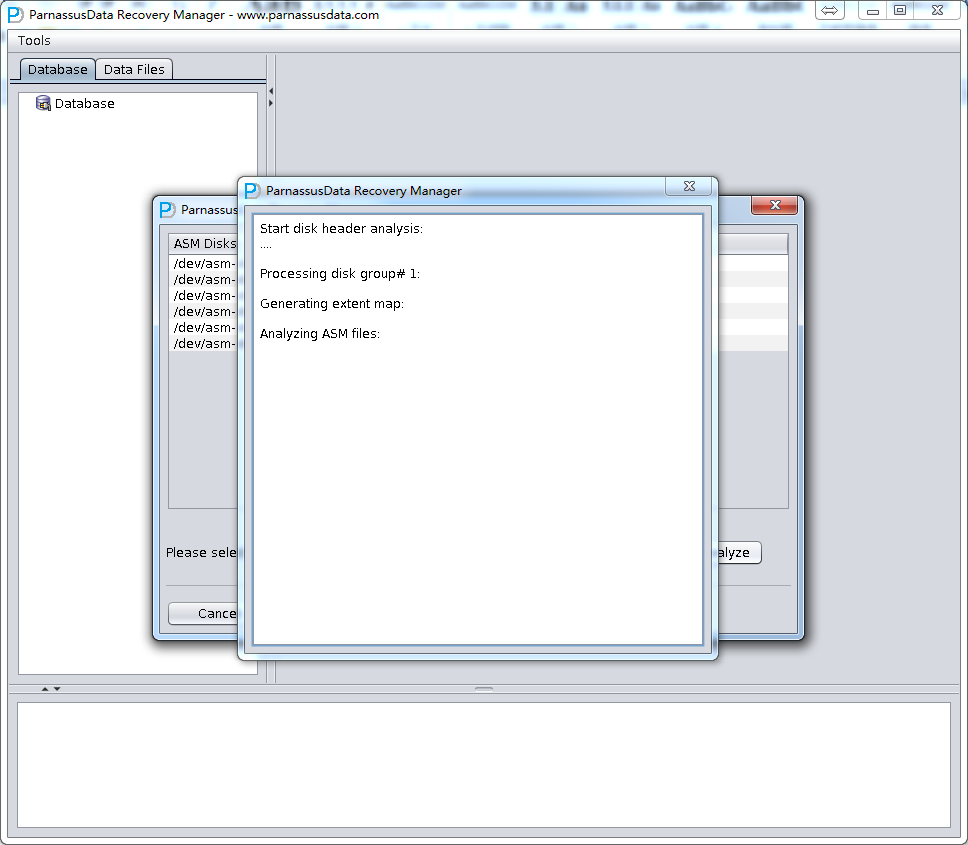
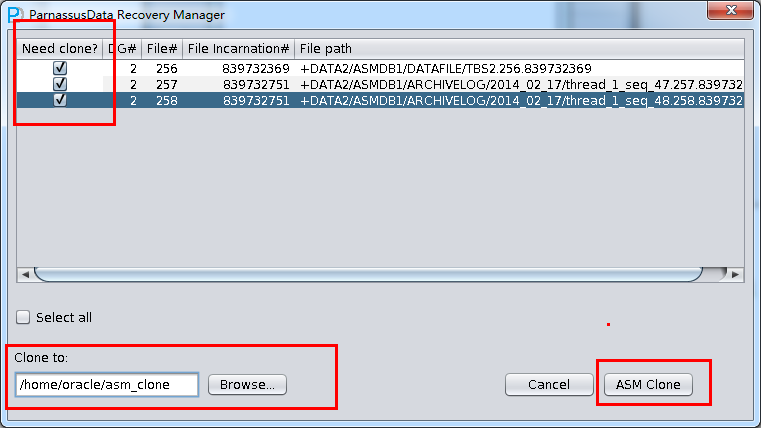
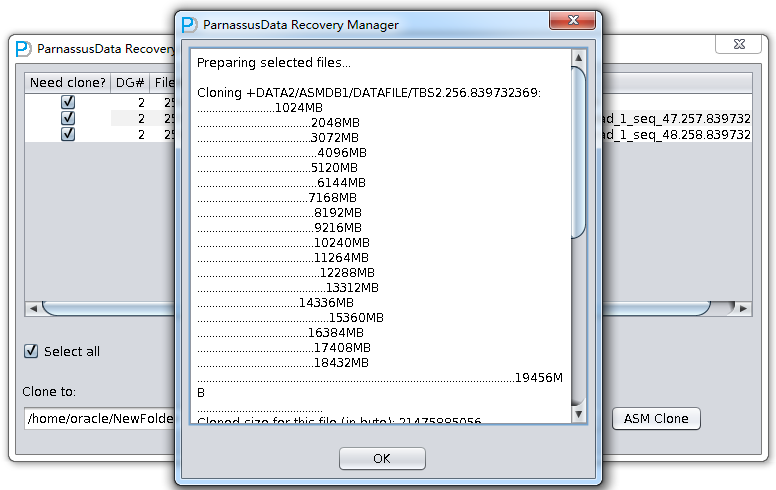
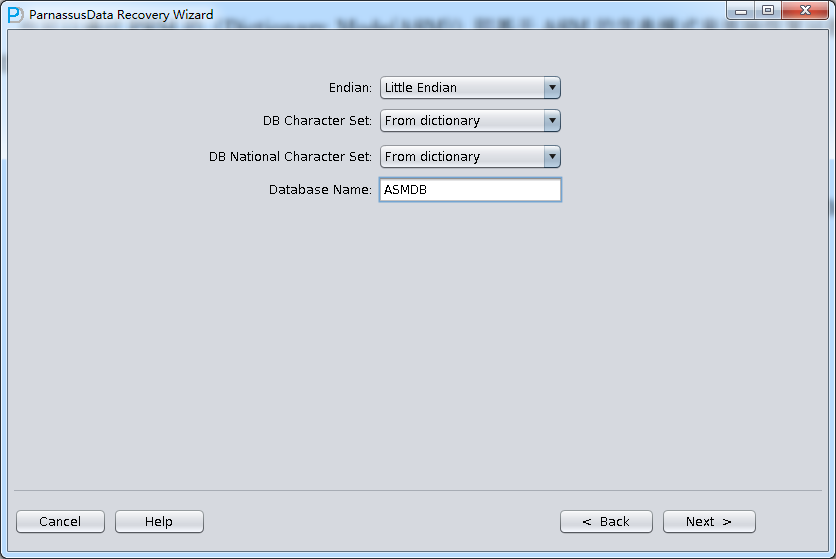
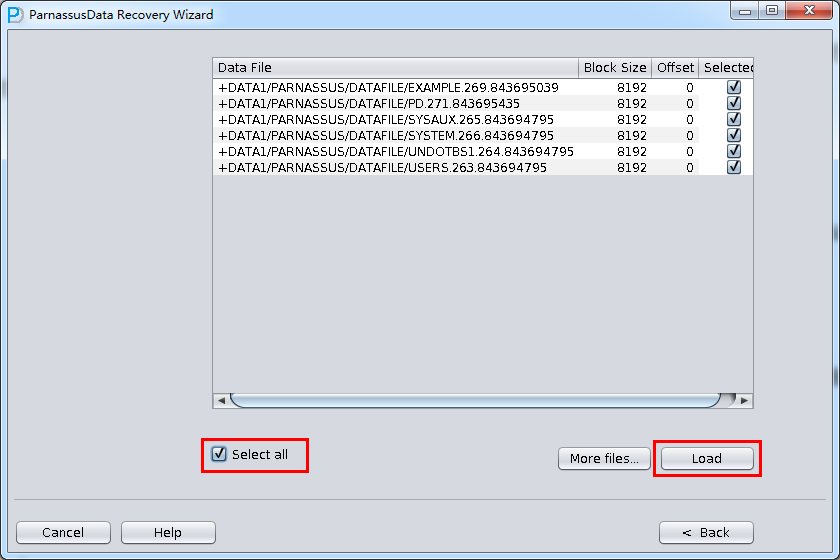
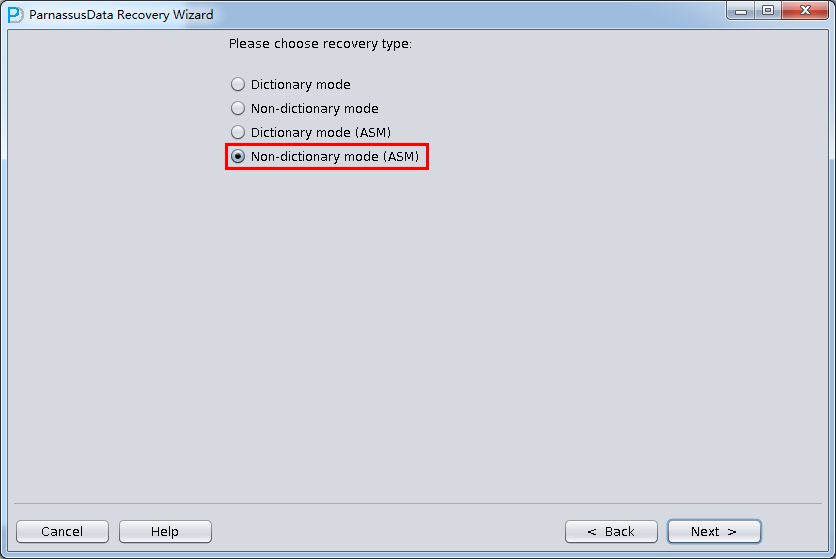
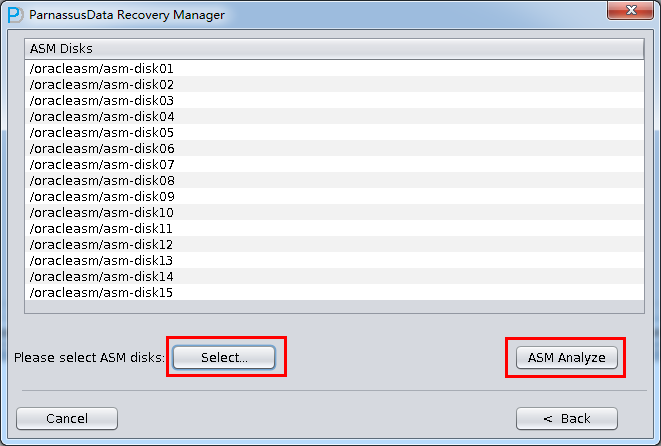
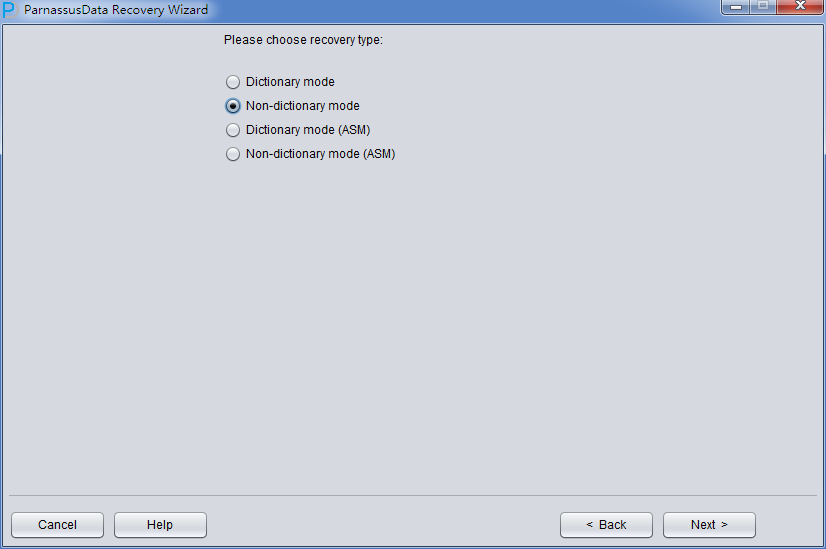
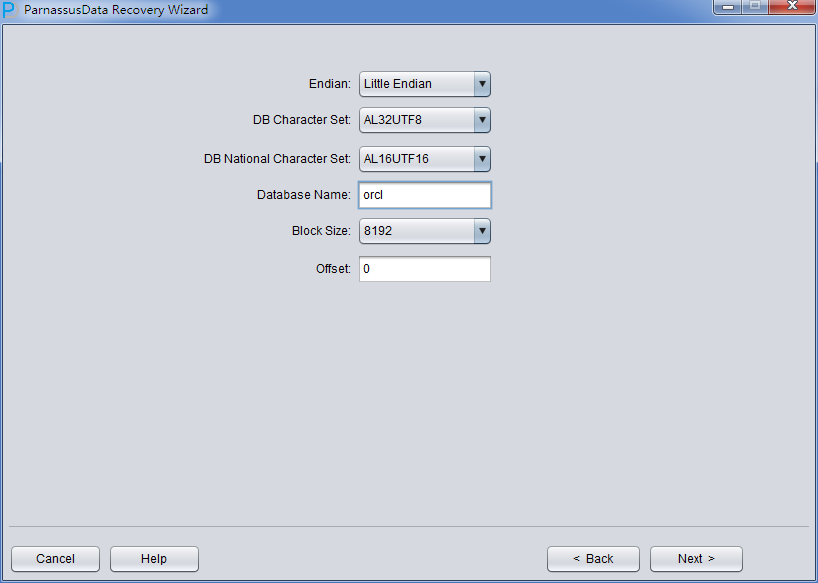
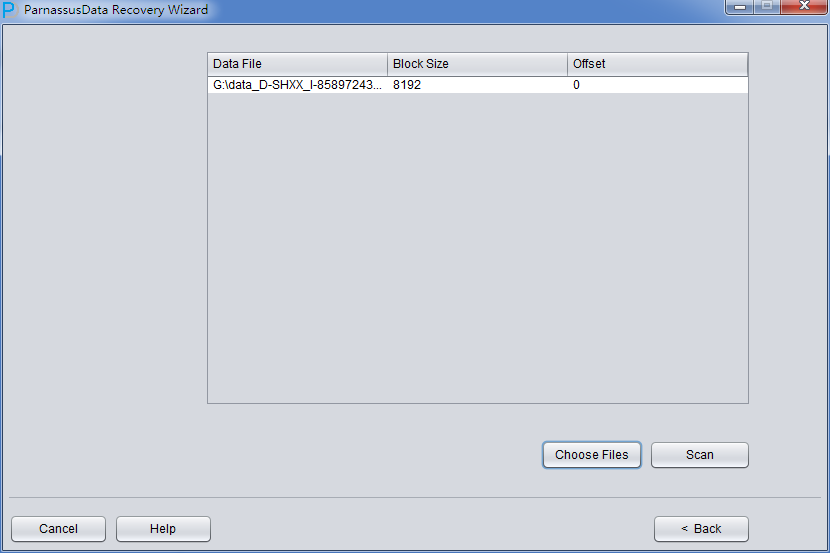
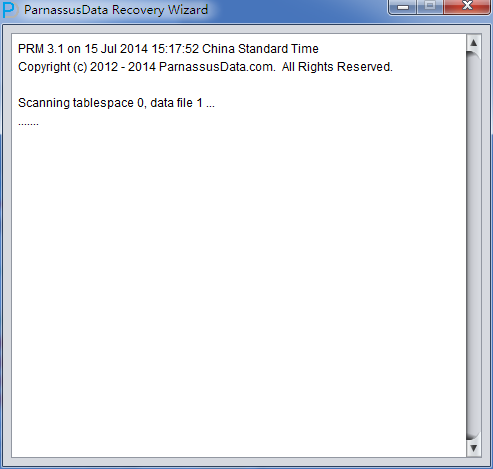
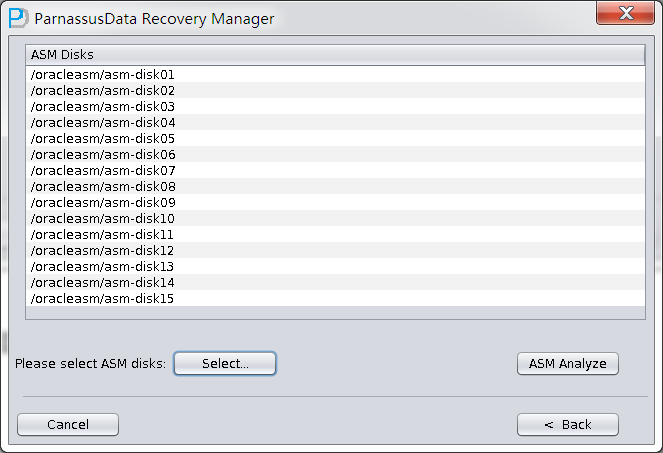
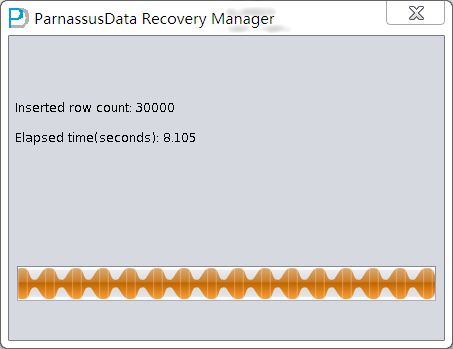
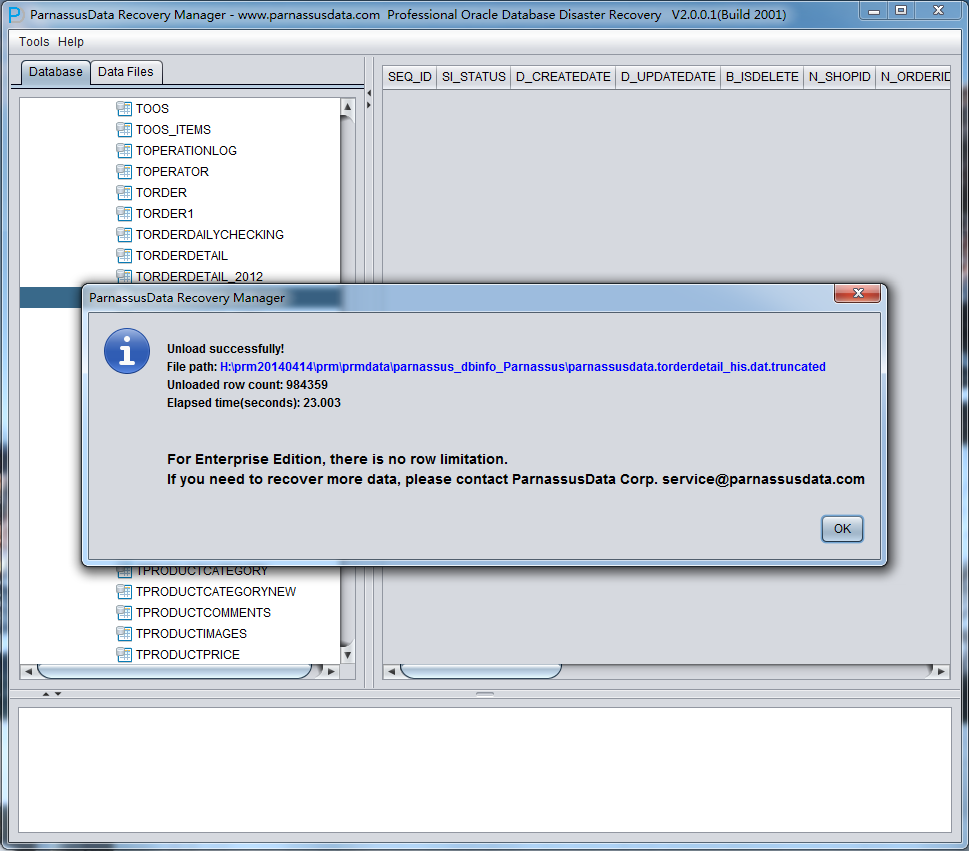
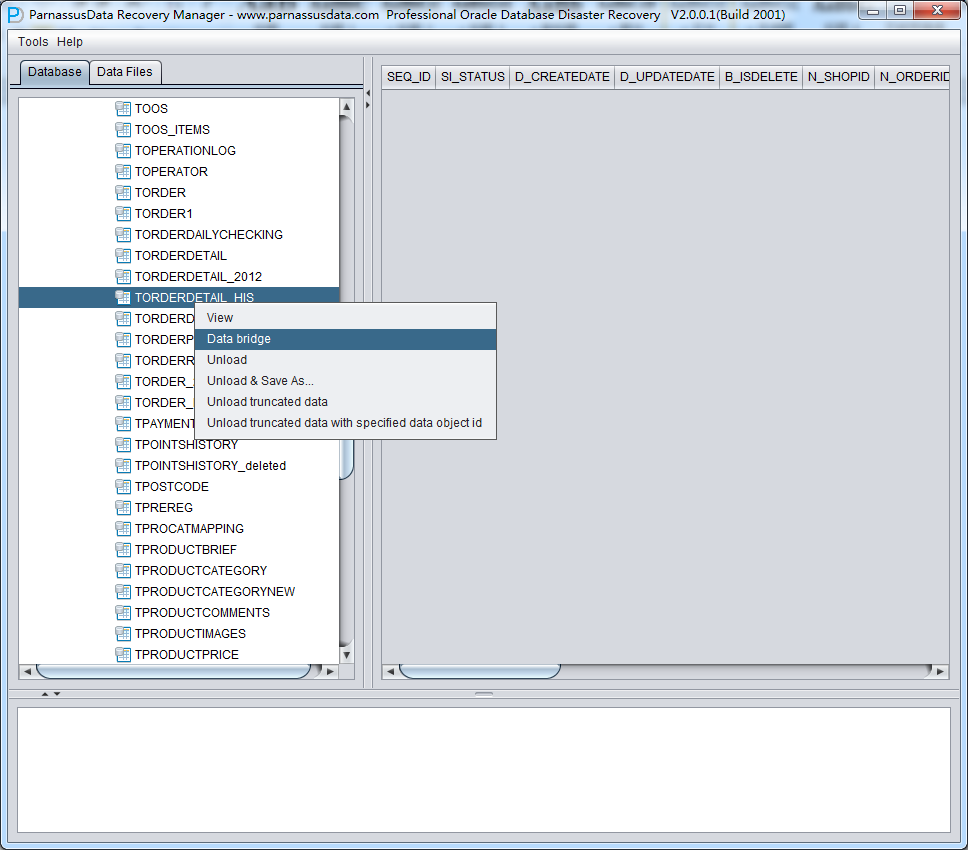
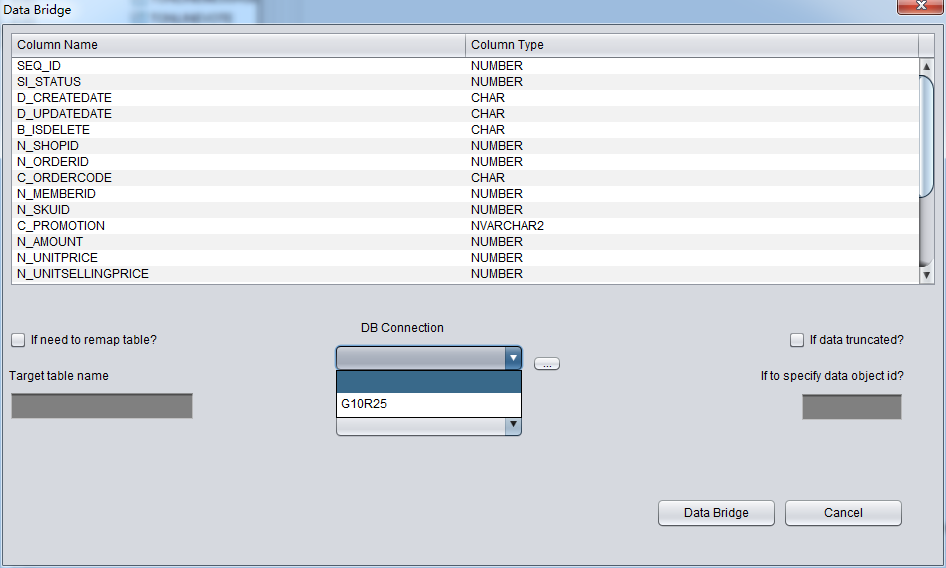
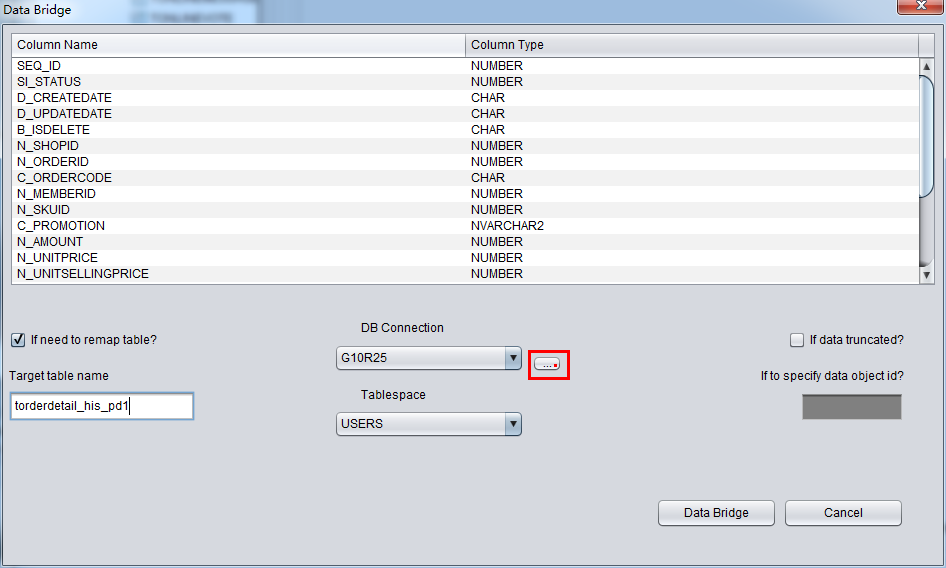
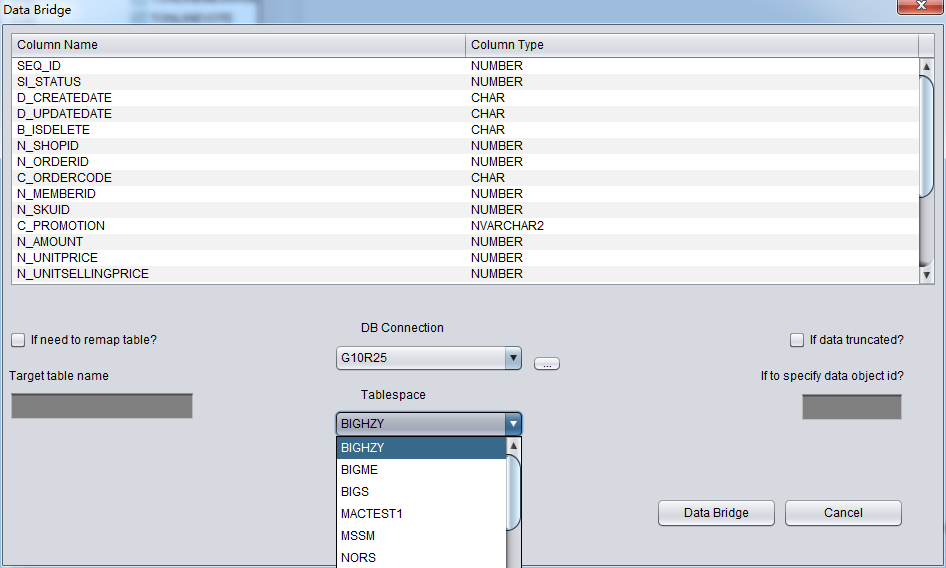
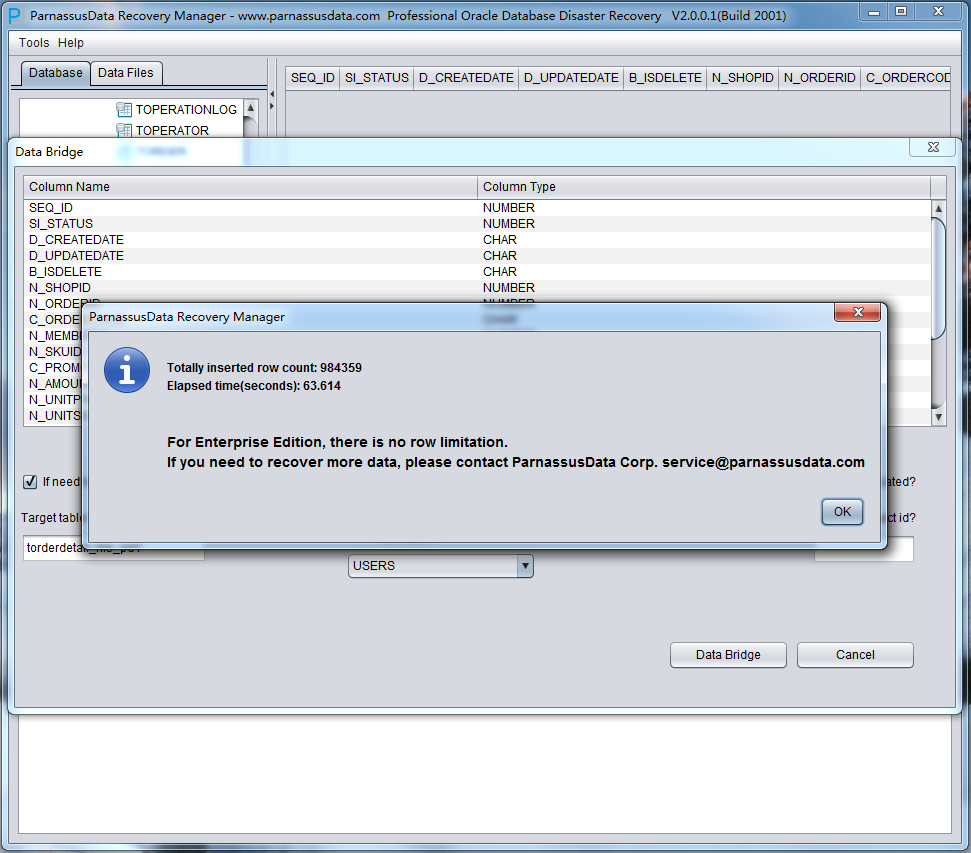
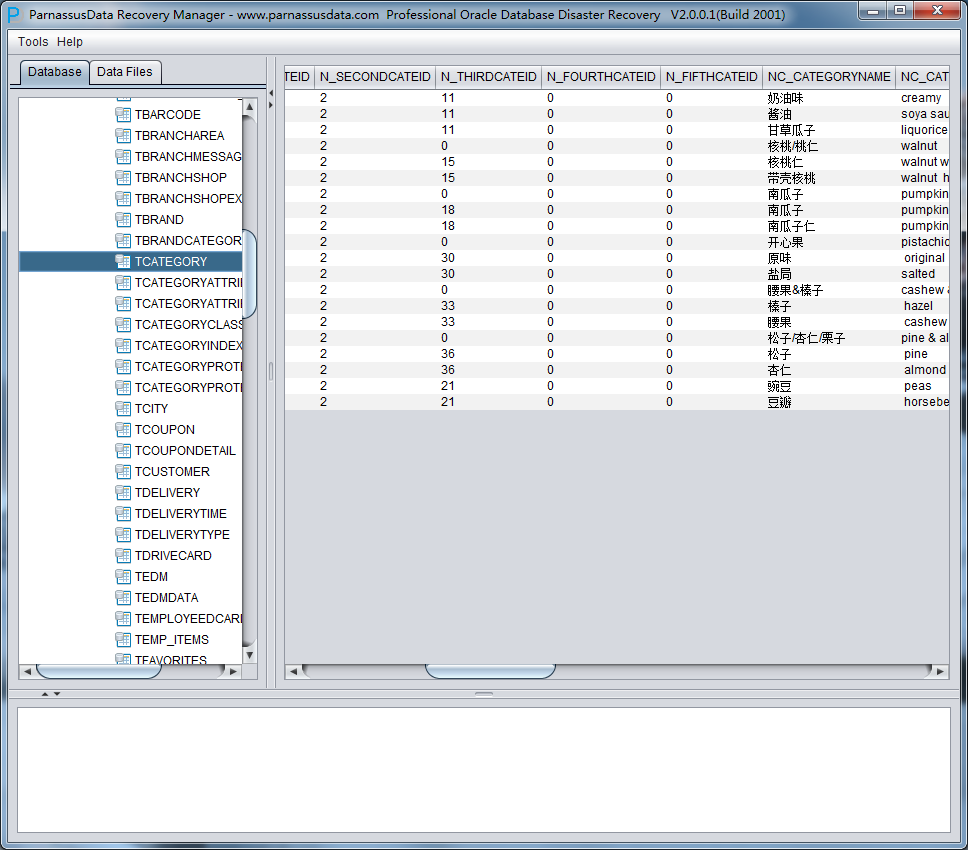
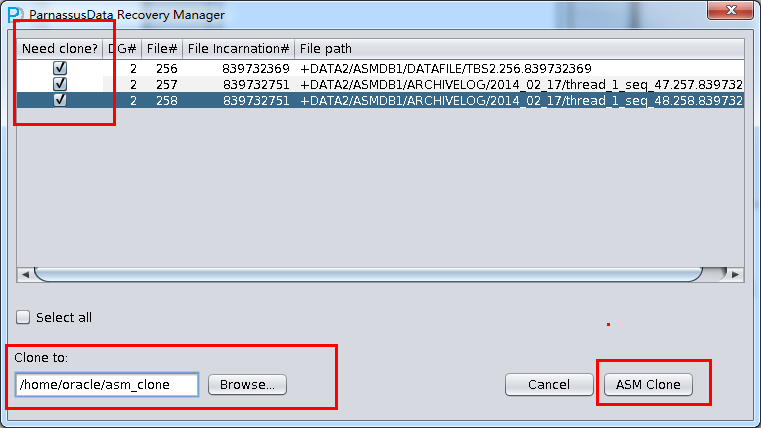
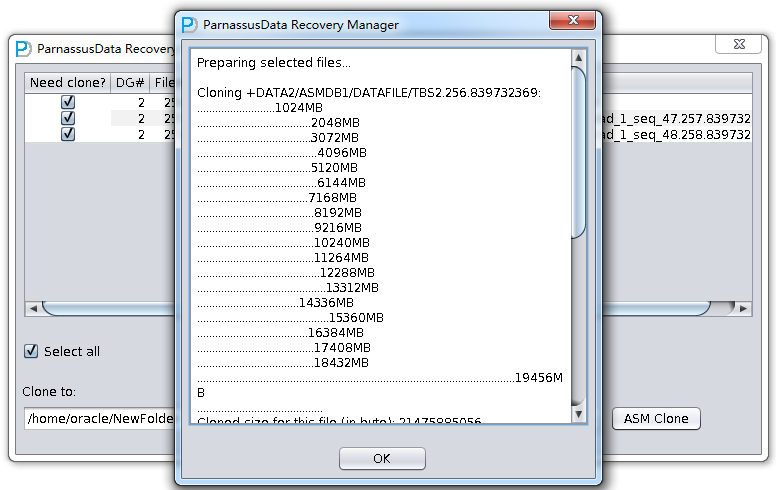
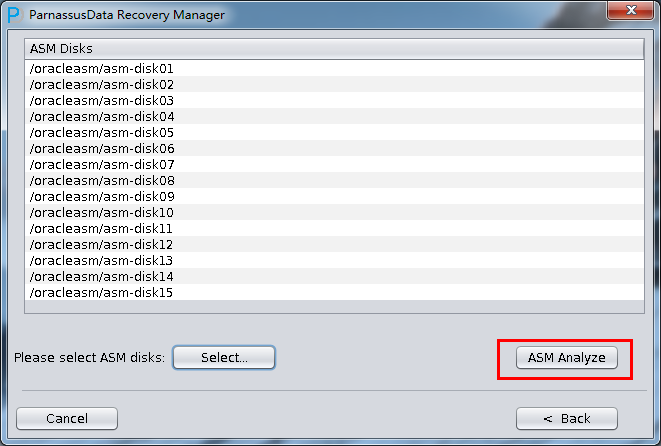
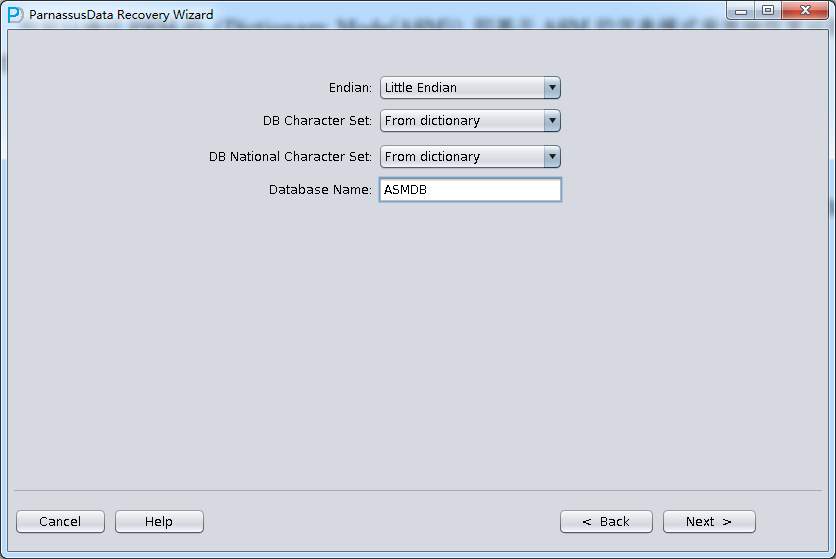
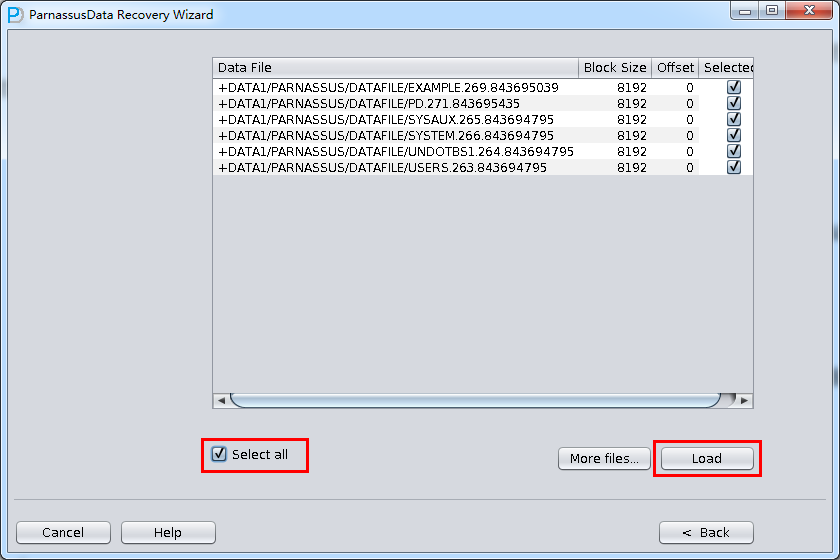
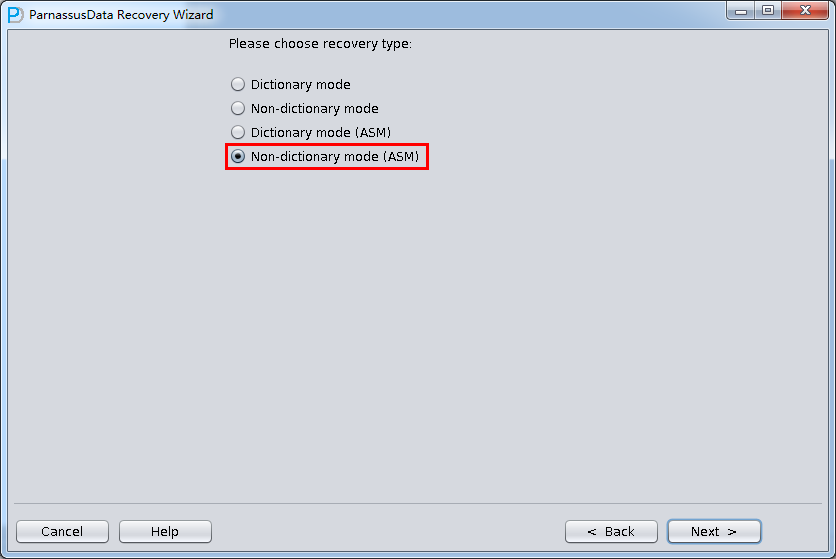
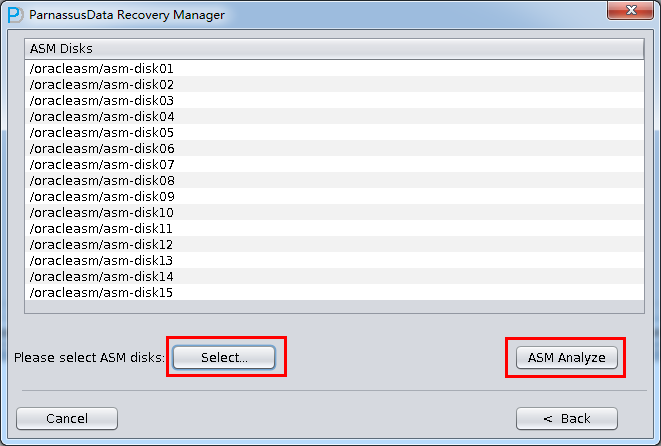
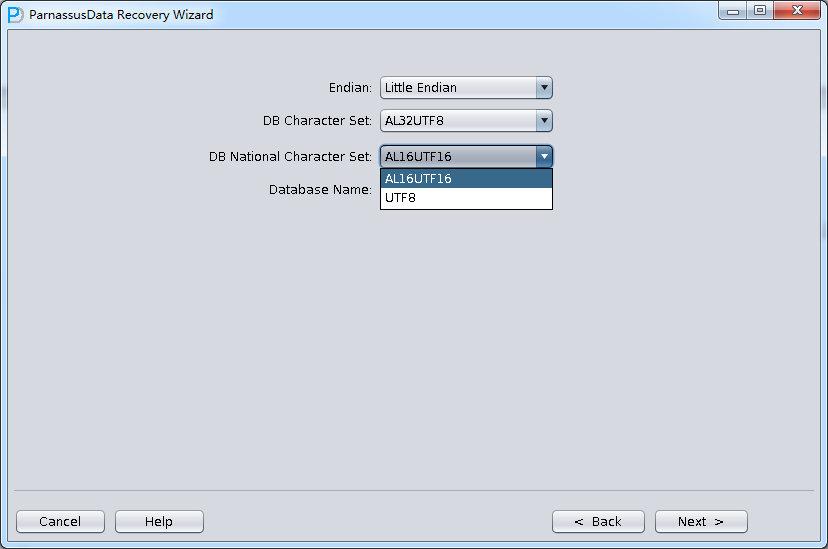
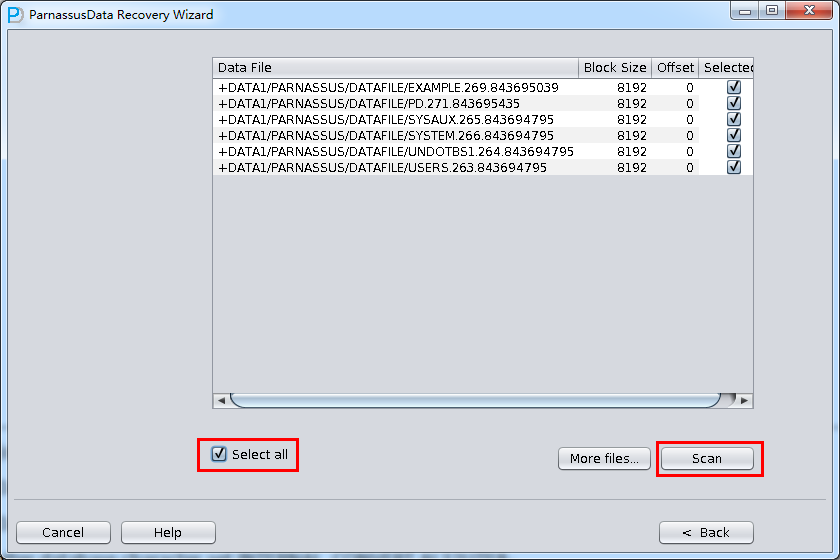
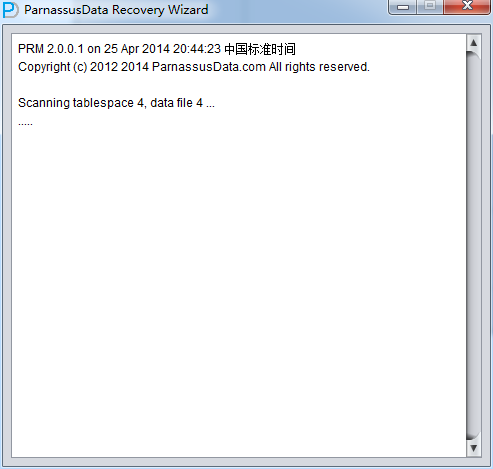
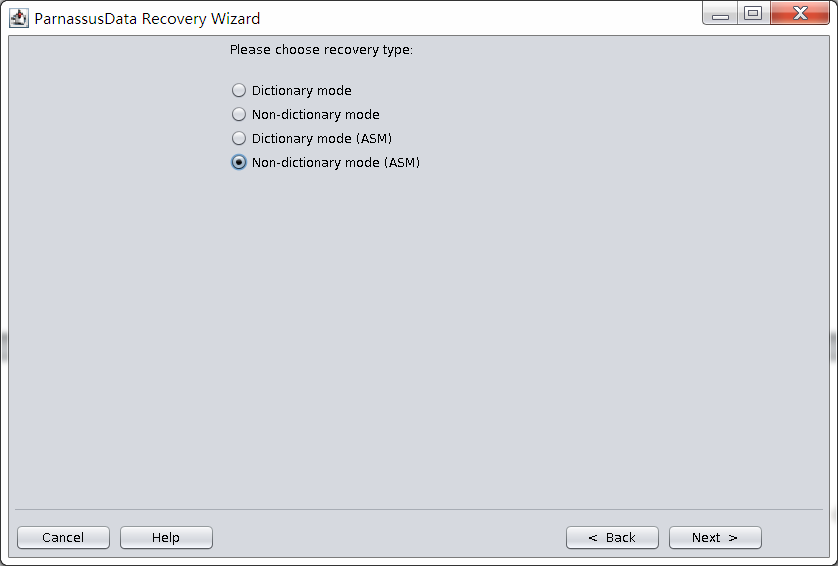
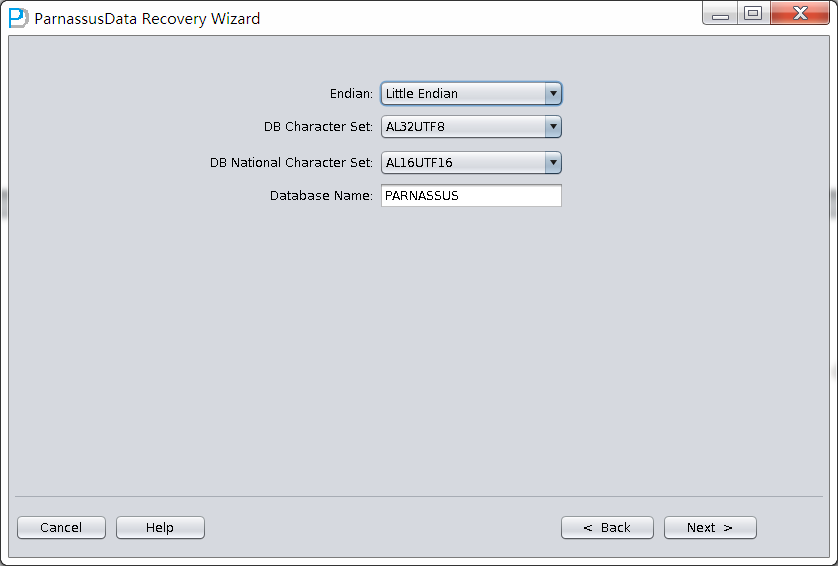
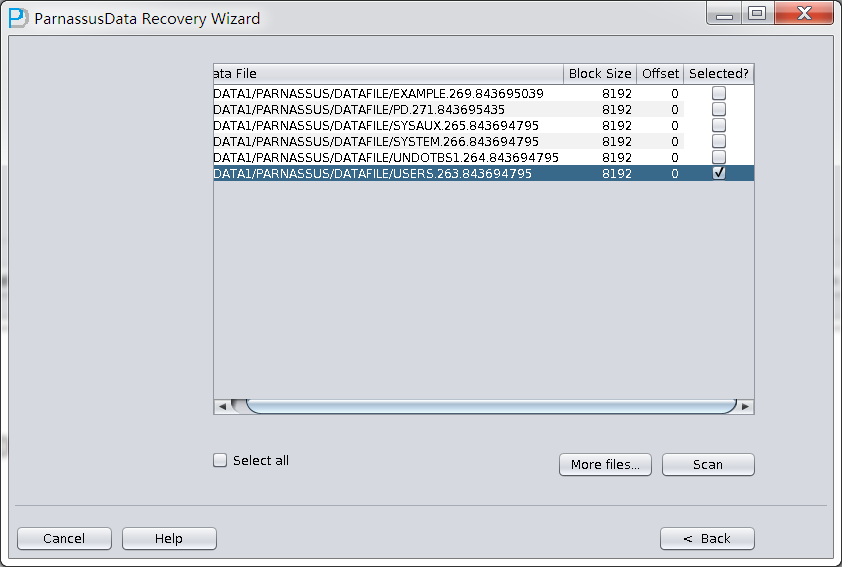
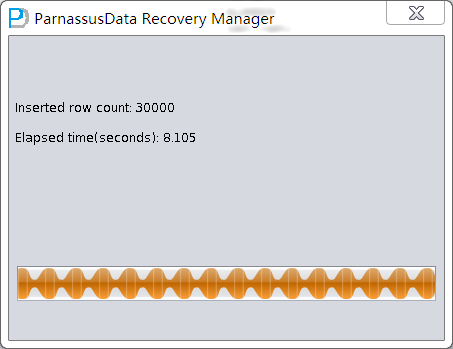
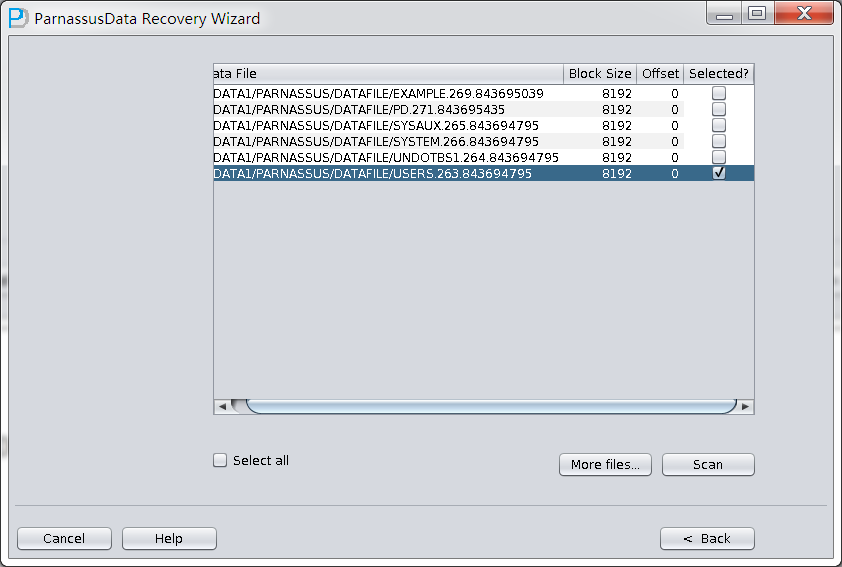
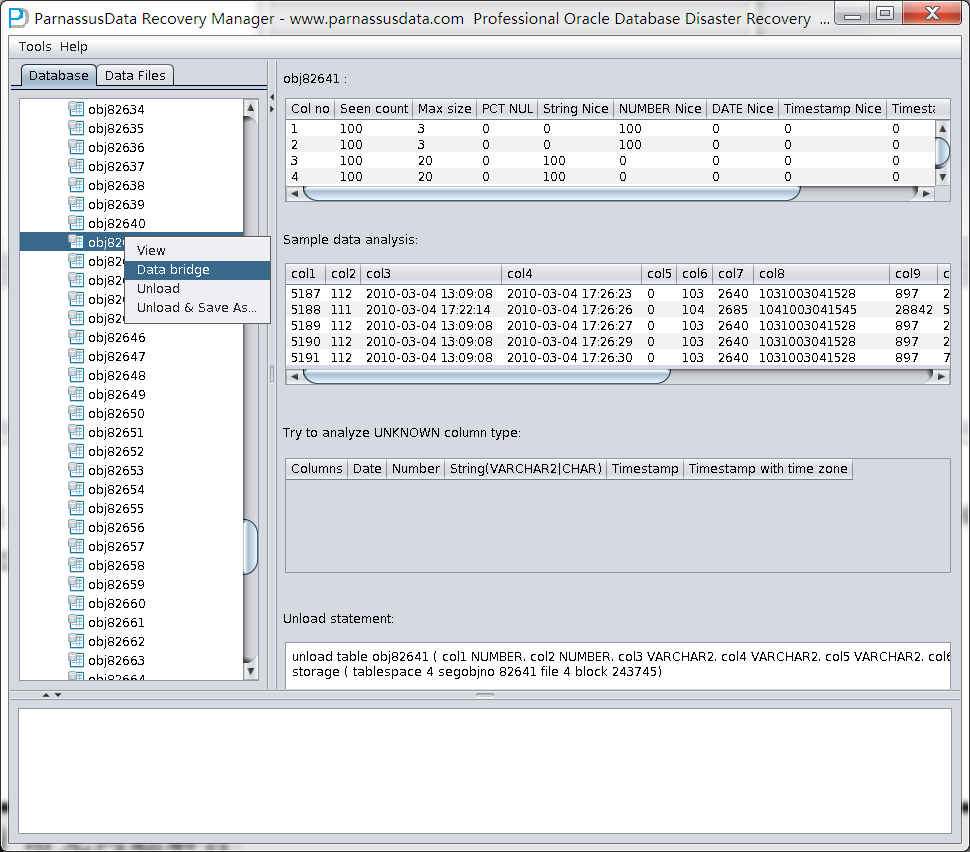
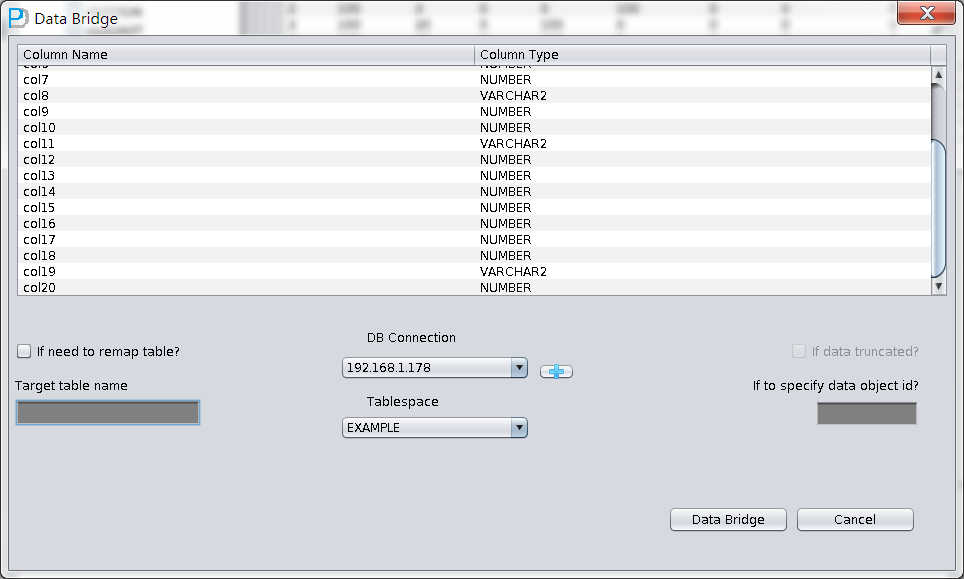
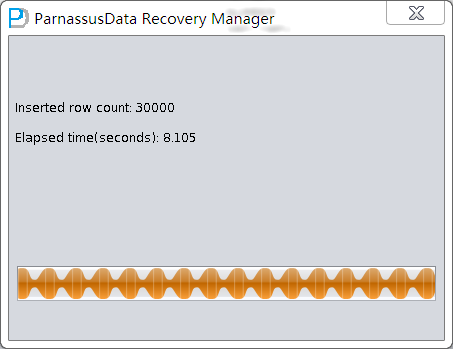
PRM-DUL成功案例:为某电信运营商恢复了误删truncate的一百多张表。东南某电信运营商生产系统数据库部分数据表被误删除的问题,现场工作内容:采用PRM-DUL工具将所需要的共121张表恢复出来。
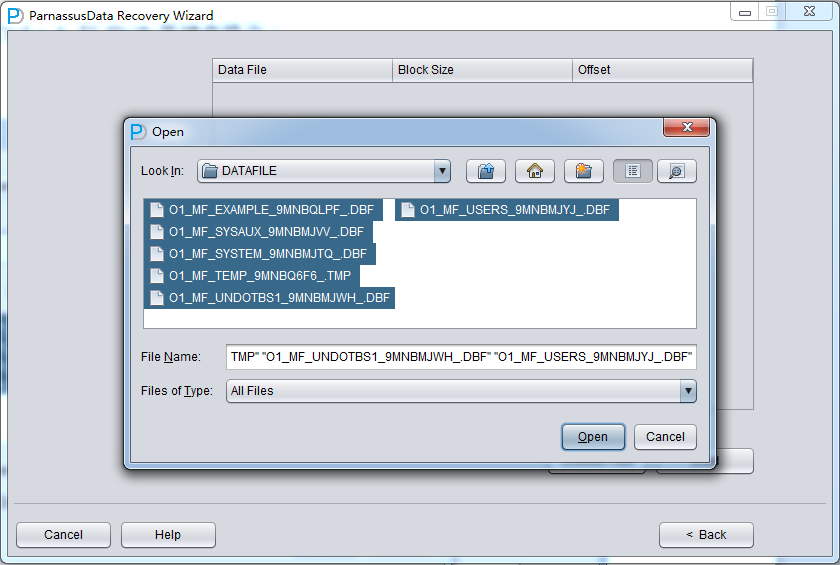
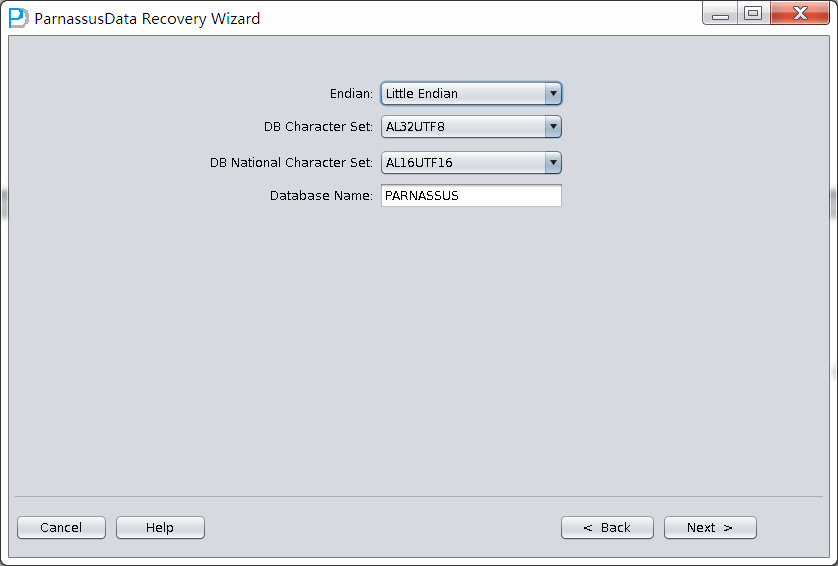
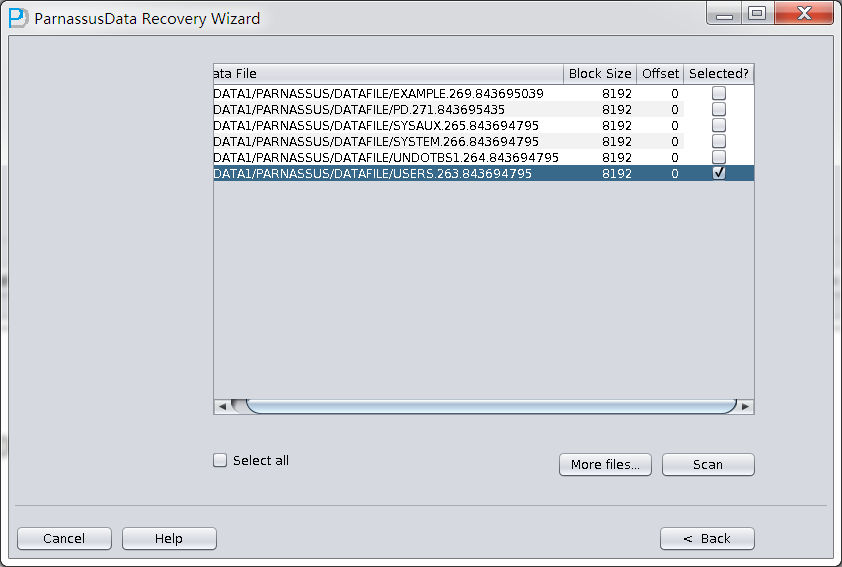
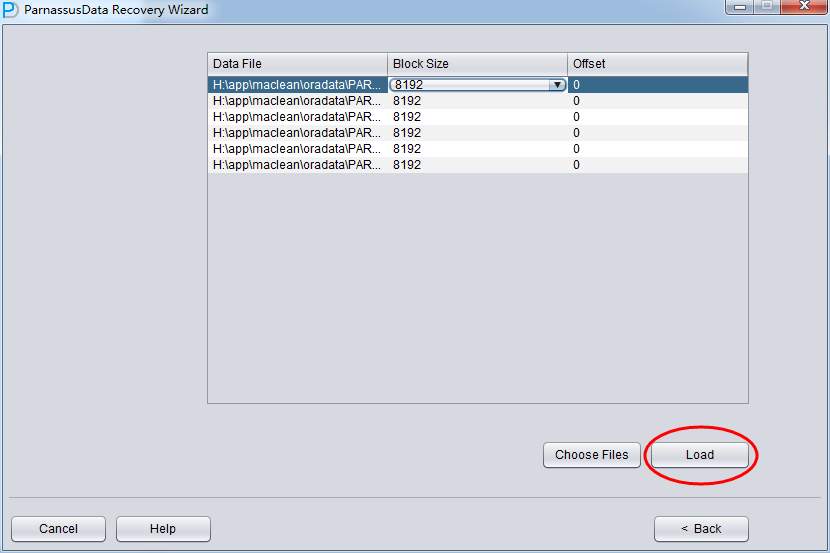
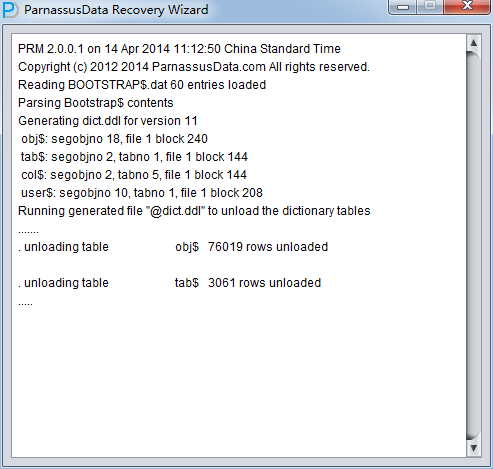
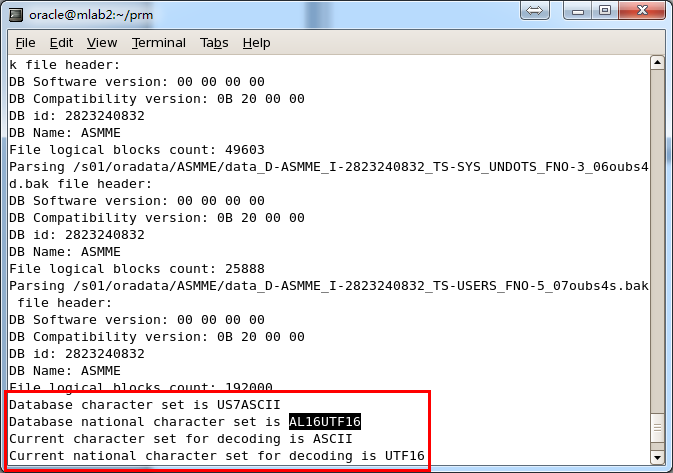
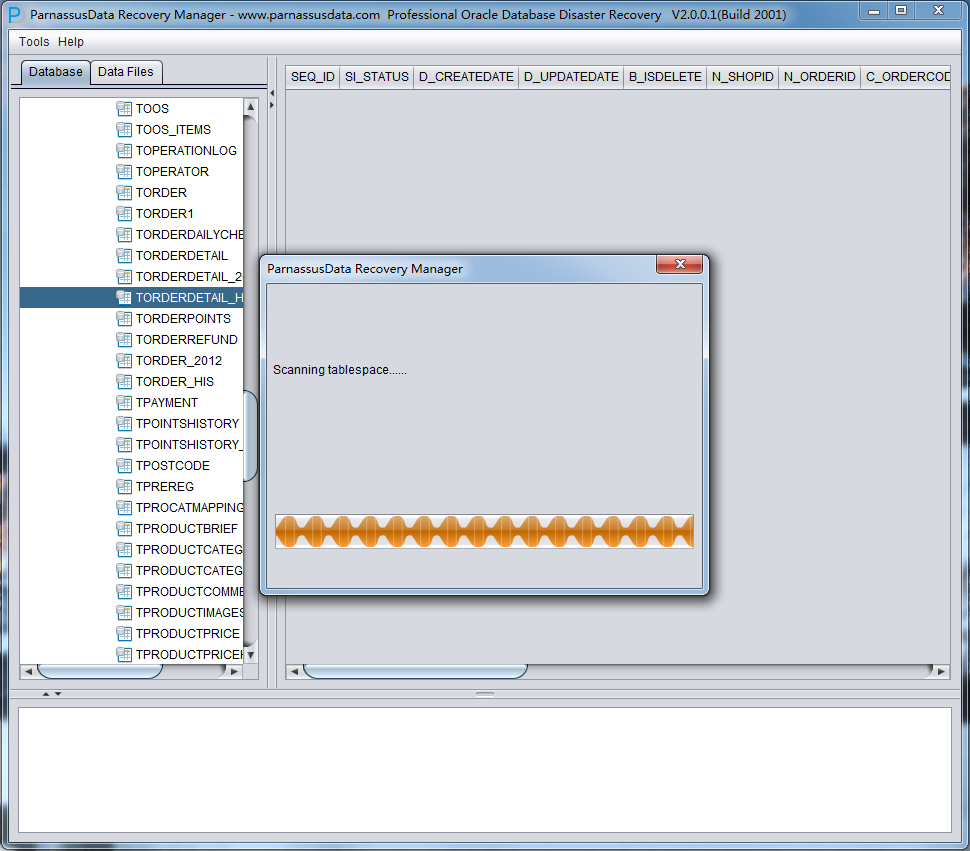
整个数据库大小在25T左右,由于还原的新环境存储空间有限,还原整个数据库不够现实。初步决定还原方案为先还原SYSTEM和data表空间,然后使用PRM-DUL直接读取数据文件,将数据导出。
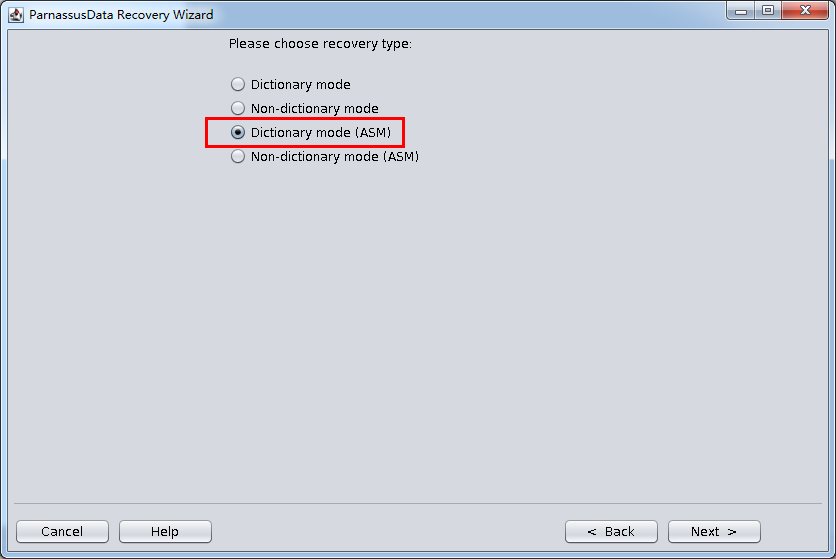
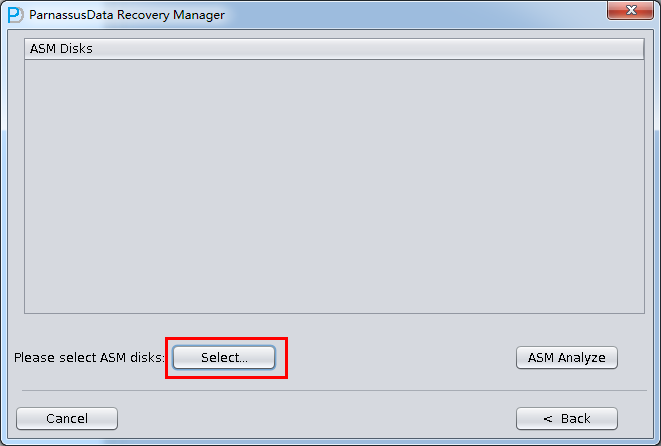
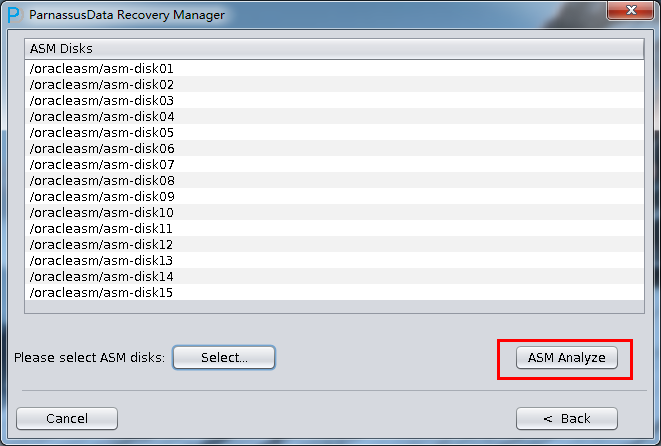
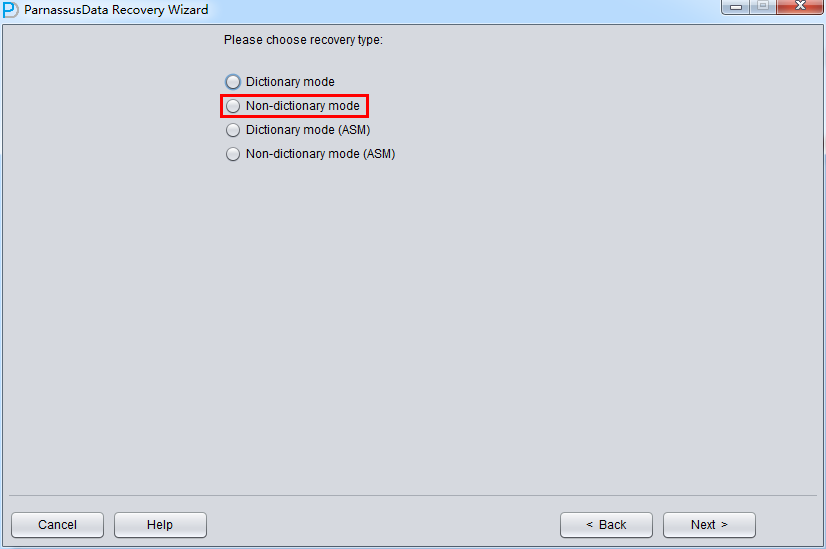
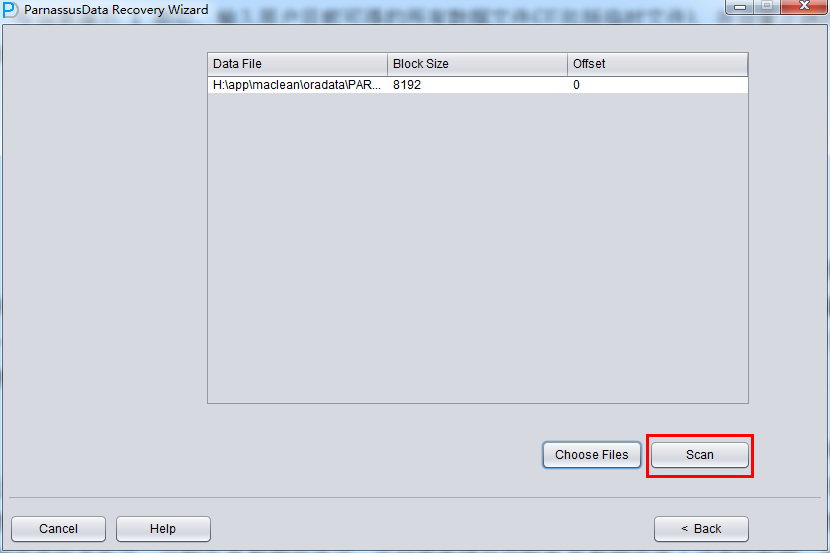
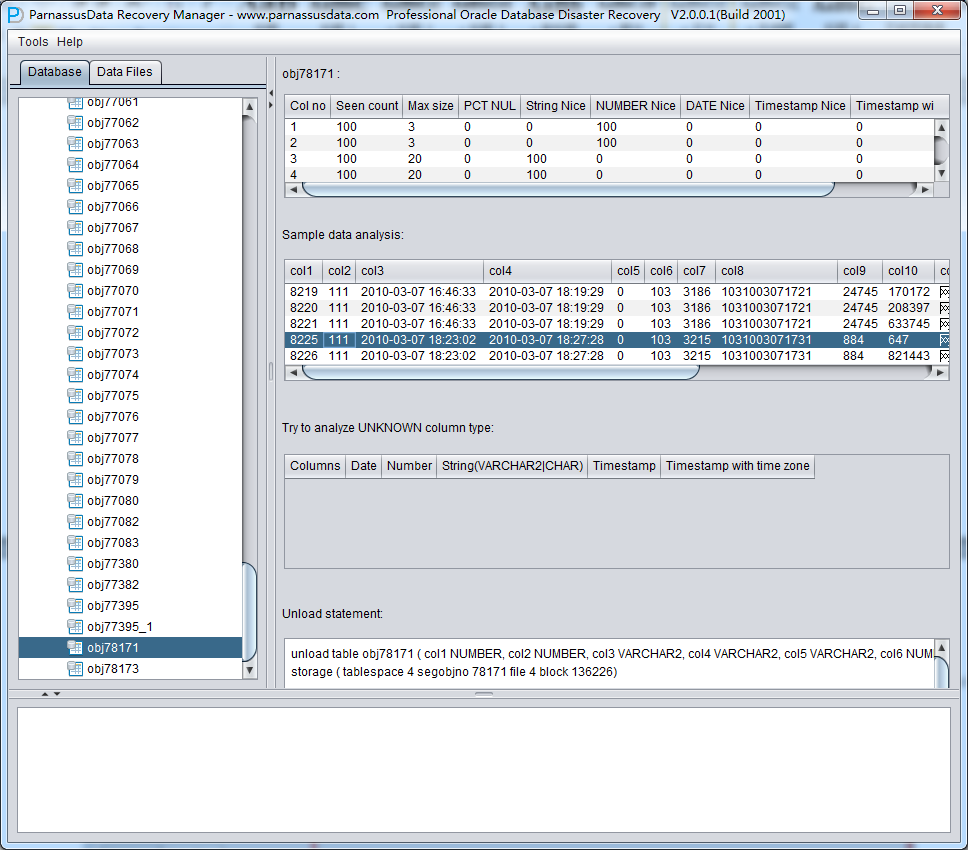
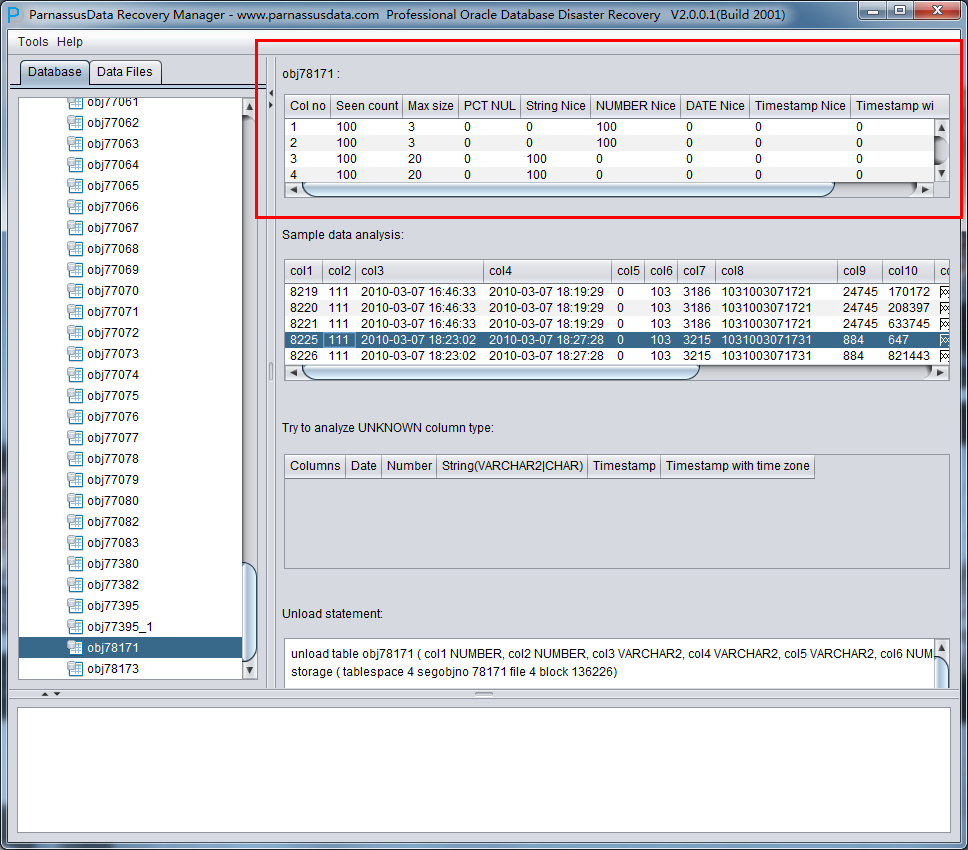
实际这个case用户在带库里是由完整备份和归档的,但是实际情况所制约没有那么多空间和时间去从备份里恢复数据了,如果真的那么做,可能至少需要几天时间,而实际恢复业务要求在1天内。所幸的是业务对这些表的完整性要求不高,而且从后期来看在truncate后插入数据的量很少,所以这个case在协商后使用了PRM-DUL成功scan database字典模式下恢复truncate功能来恢复了。
最新版PRM-DUL下载地址: http://parnassusdata.com/sites/default/files/ParnassusData_PRMForOracle_3206.zip
免费的PRM-DUL License :http://www.parnassusdata.com/zh-hans/node/122


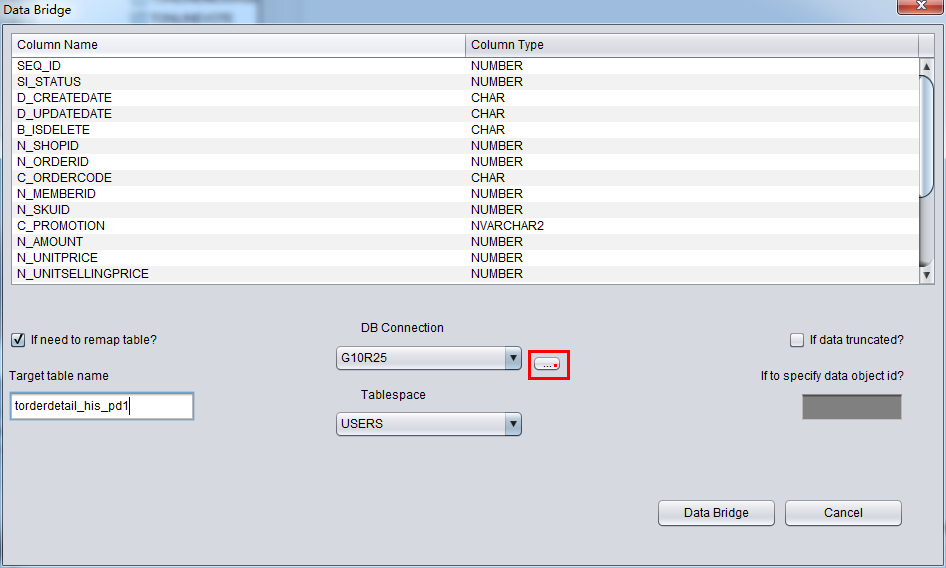
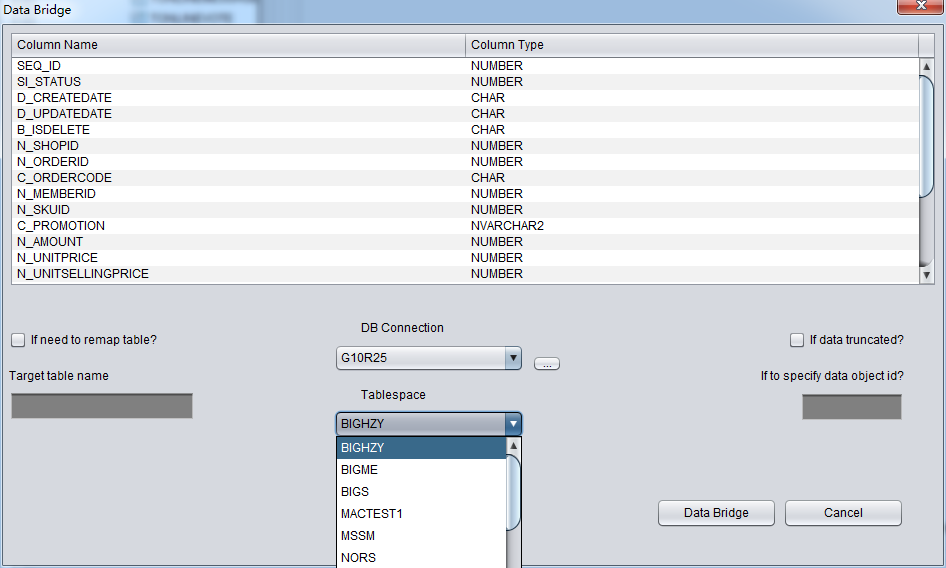
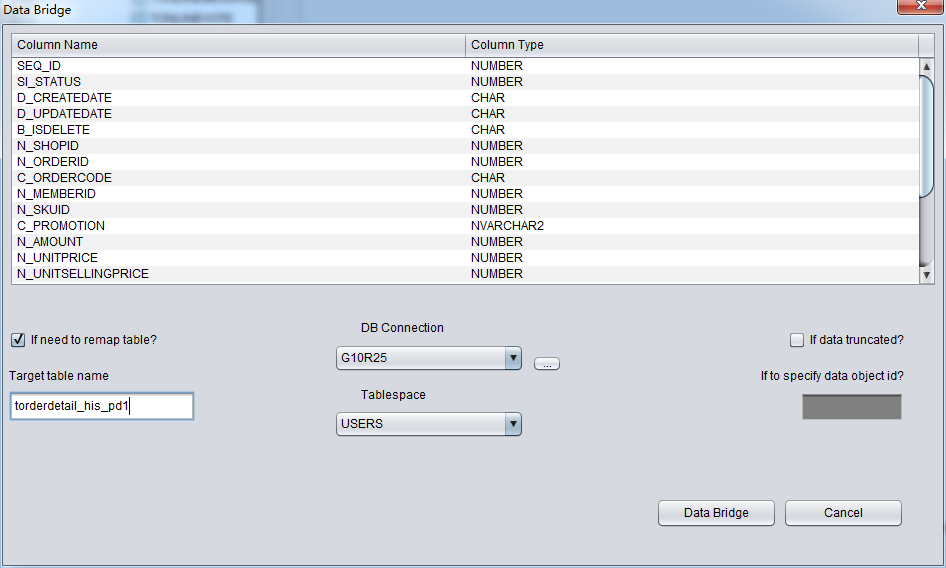
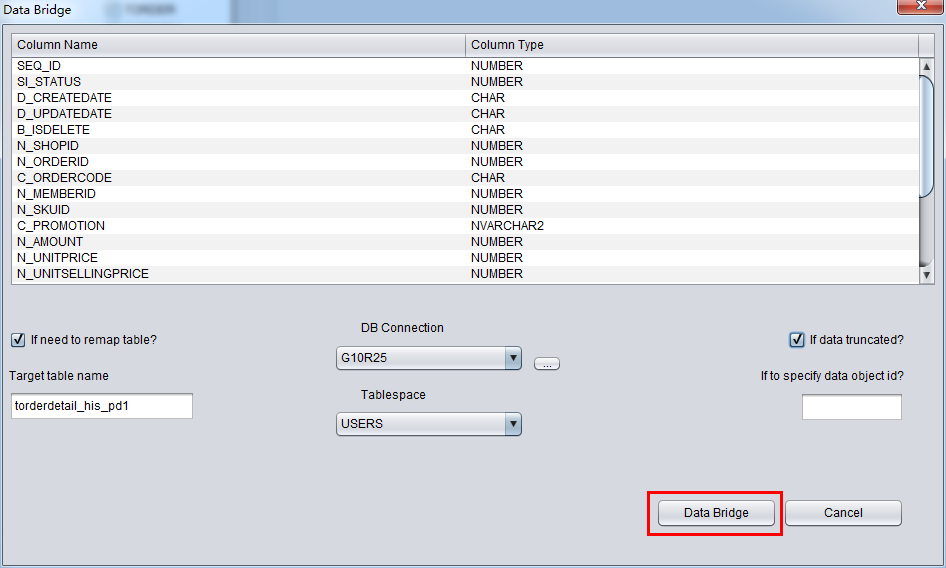
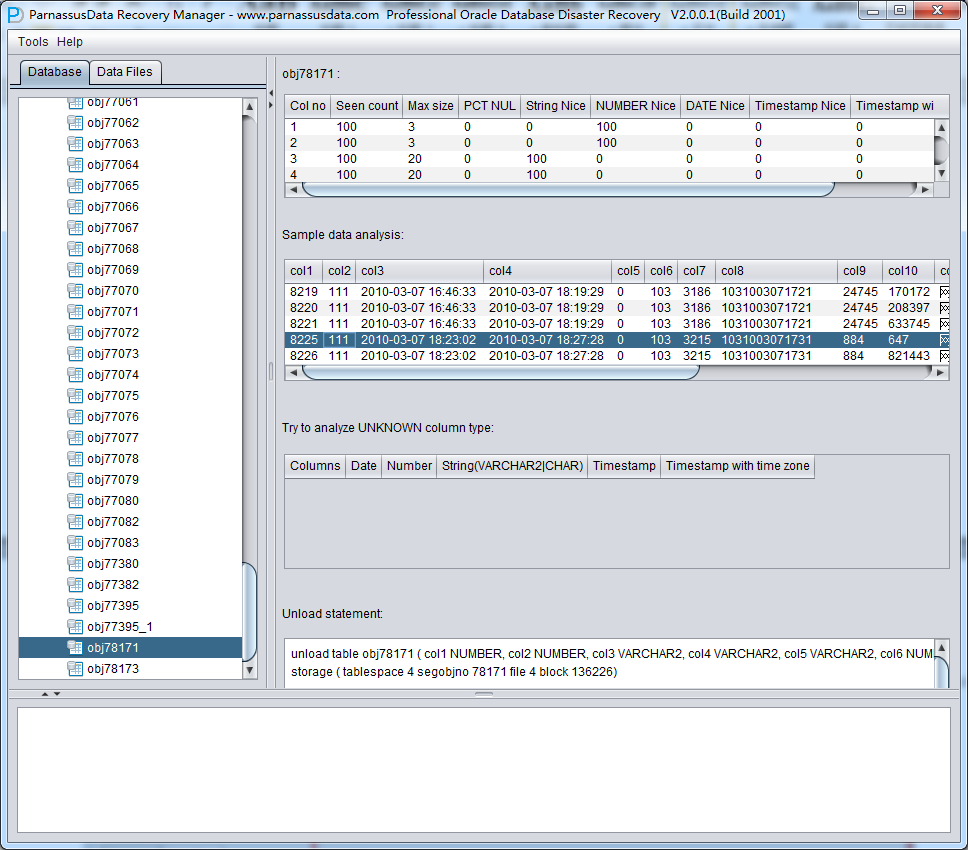
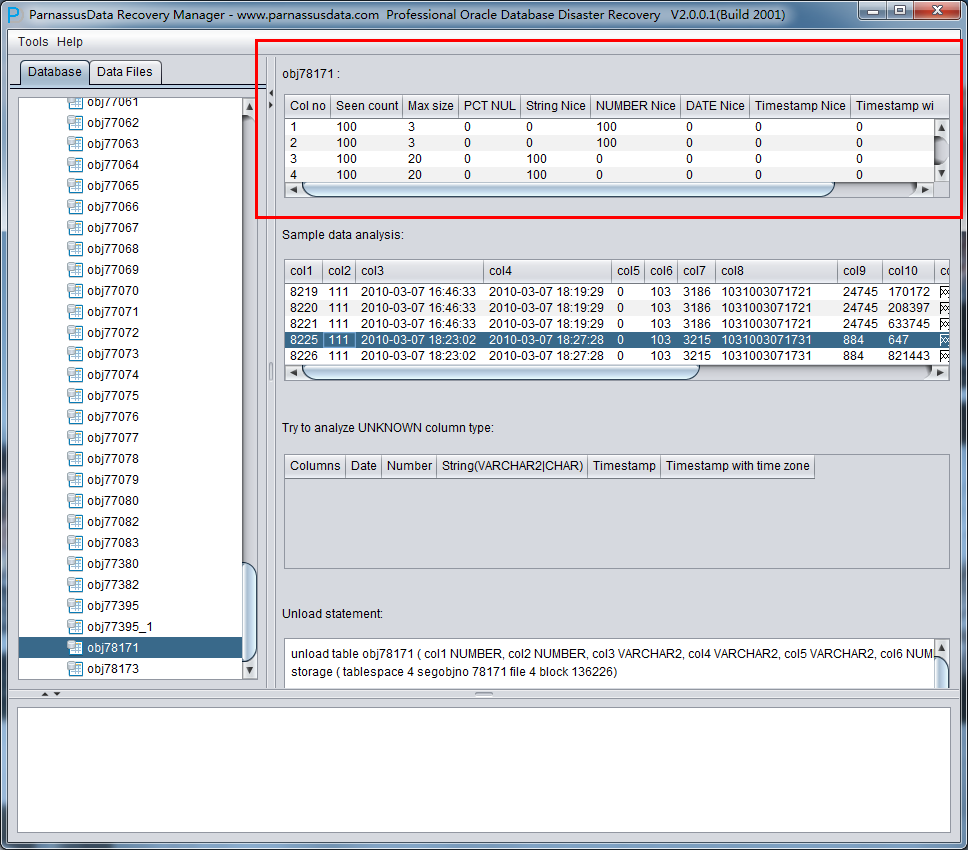
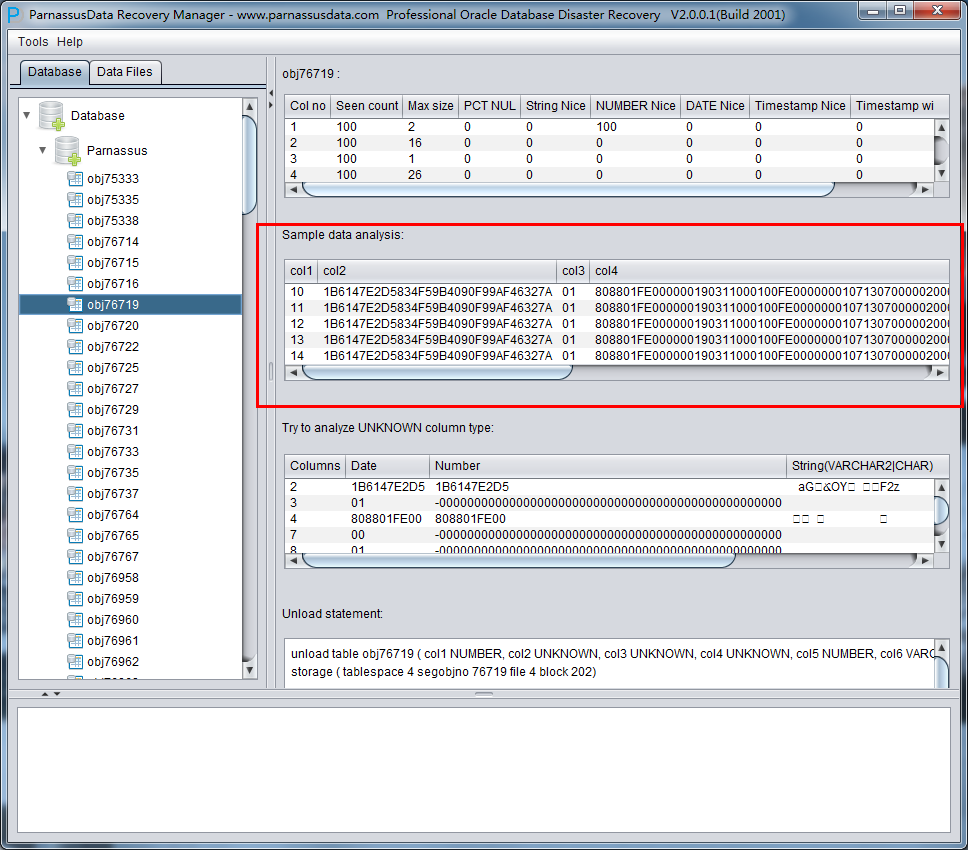
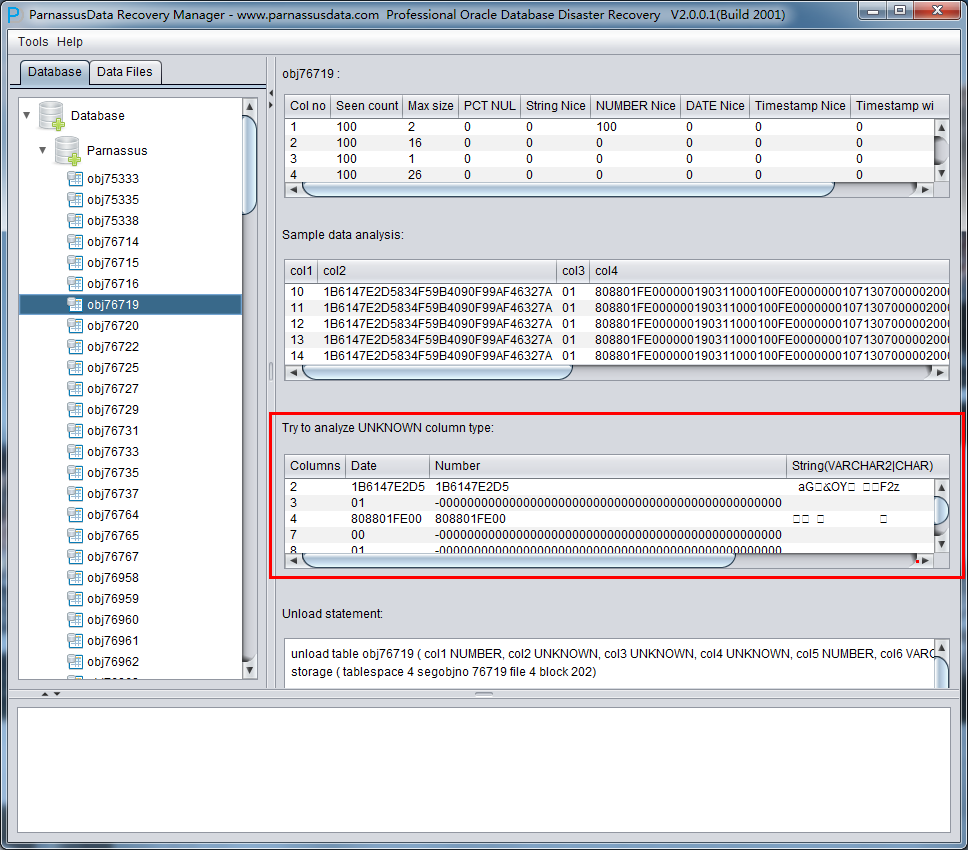
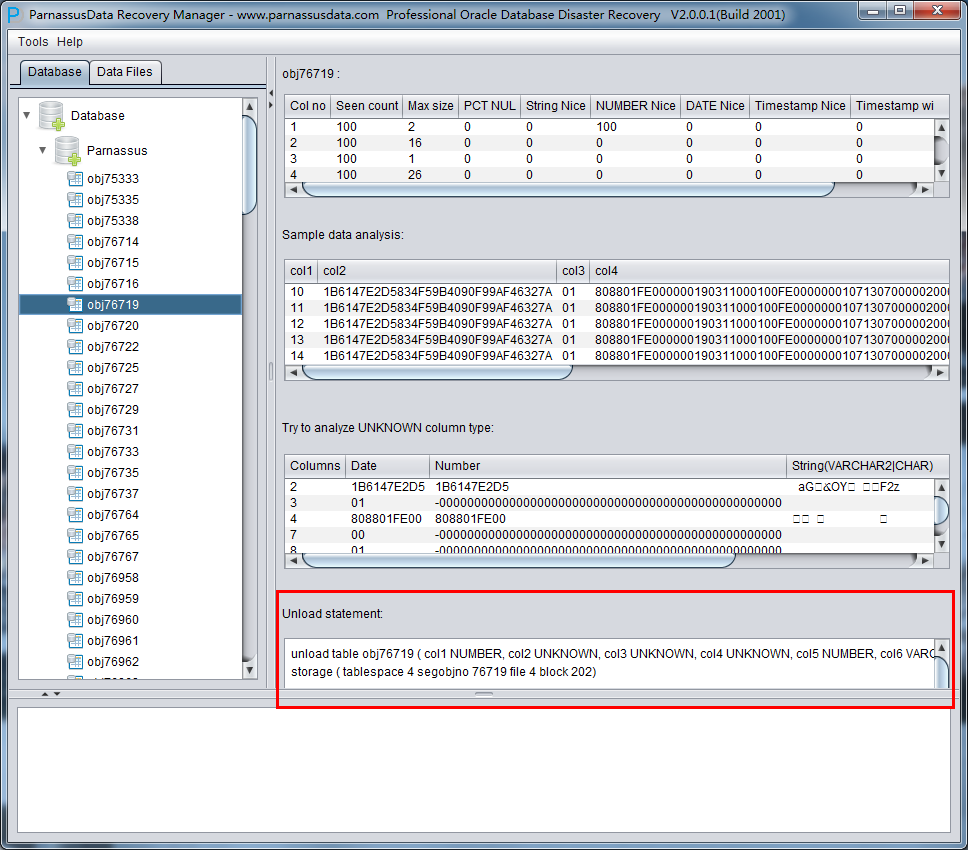
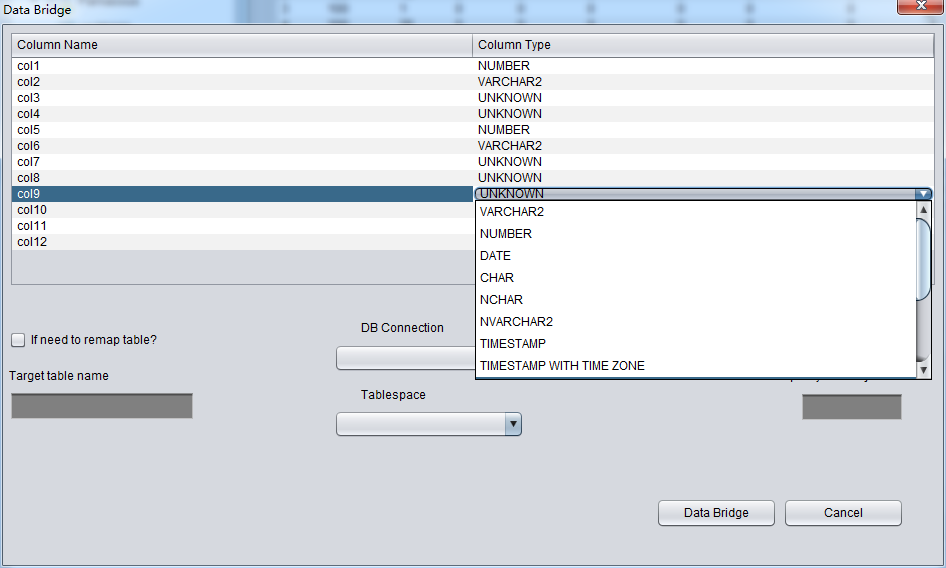
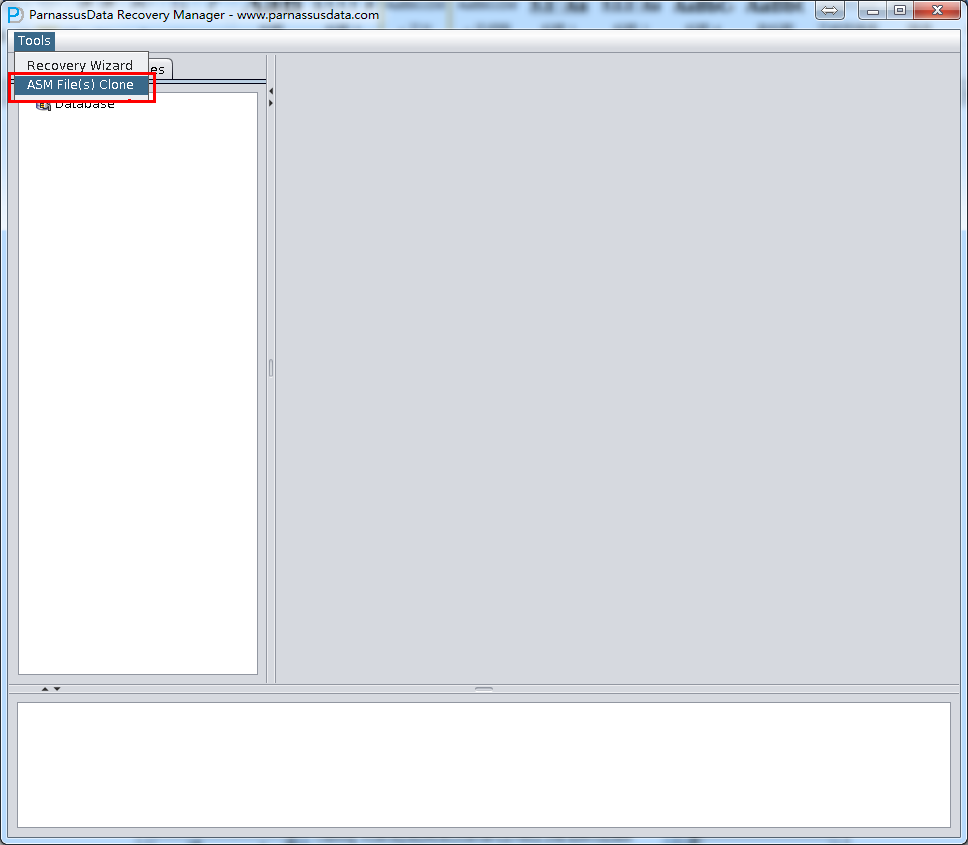
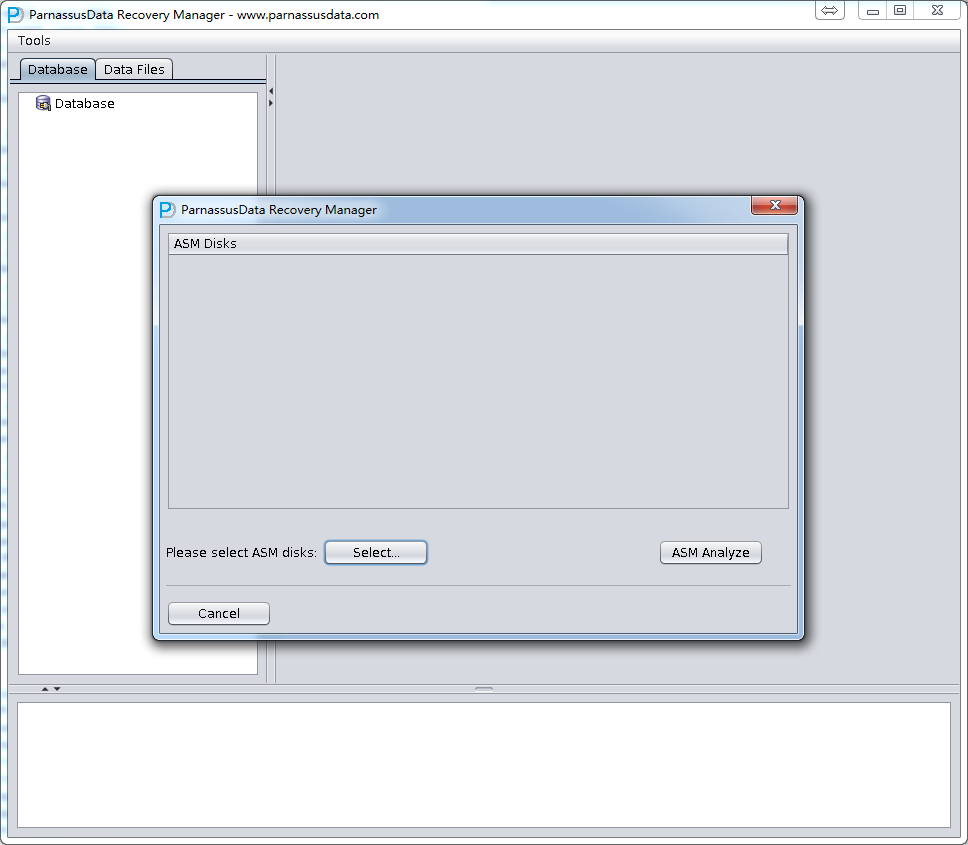








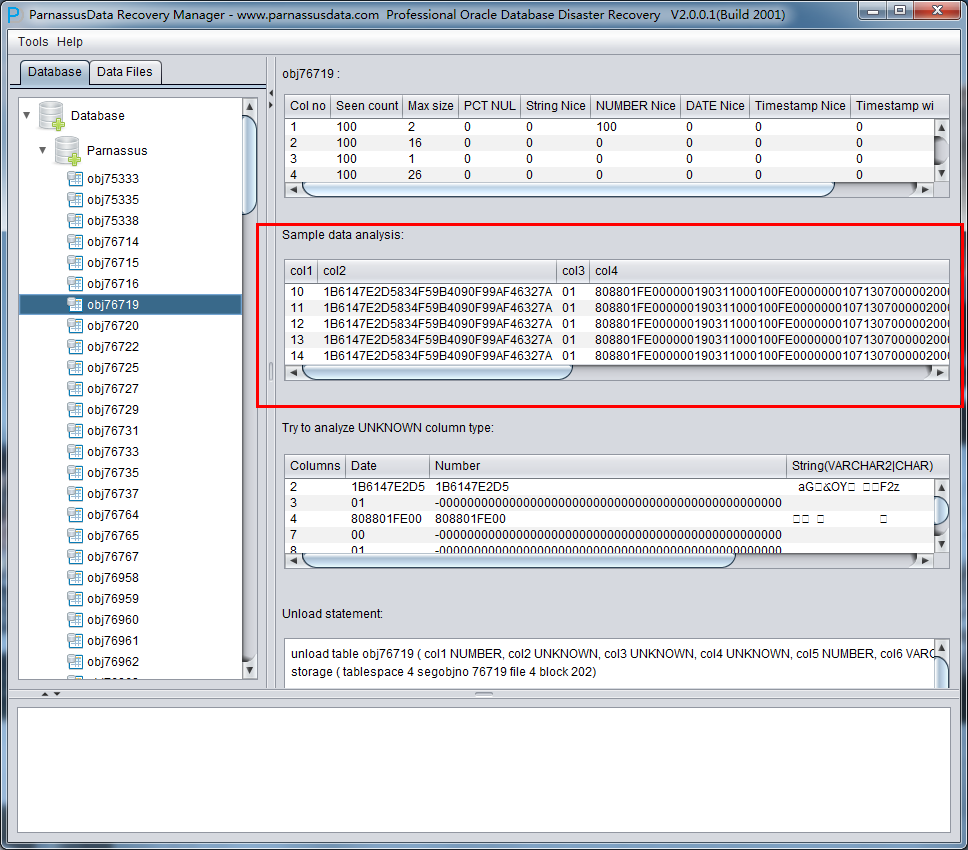

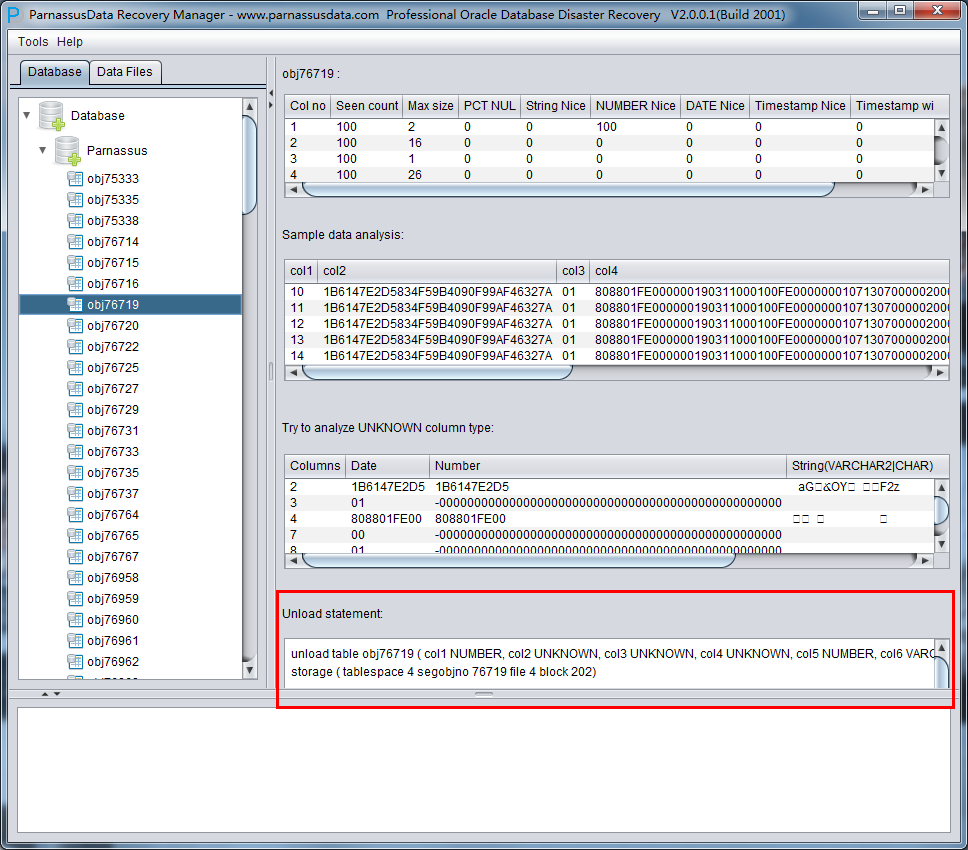
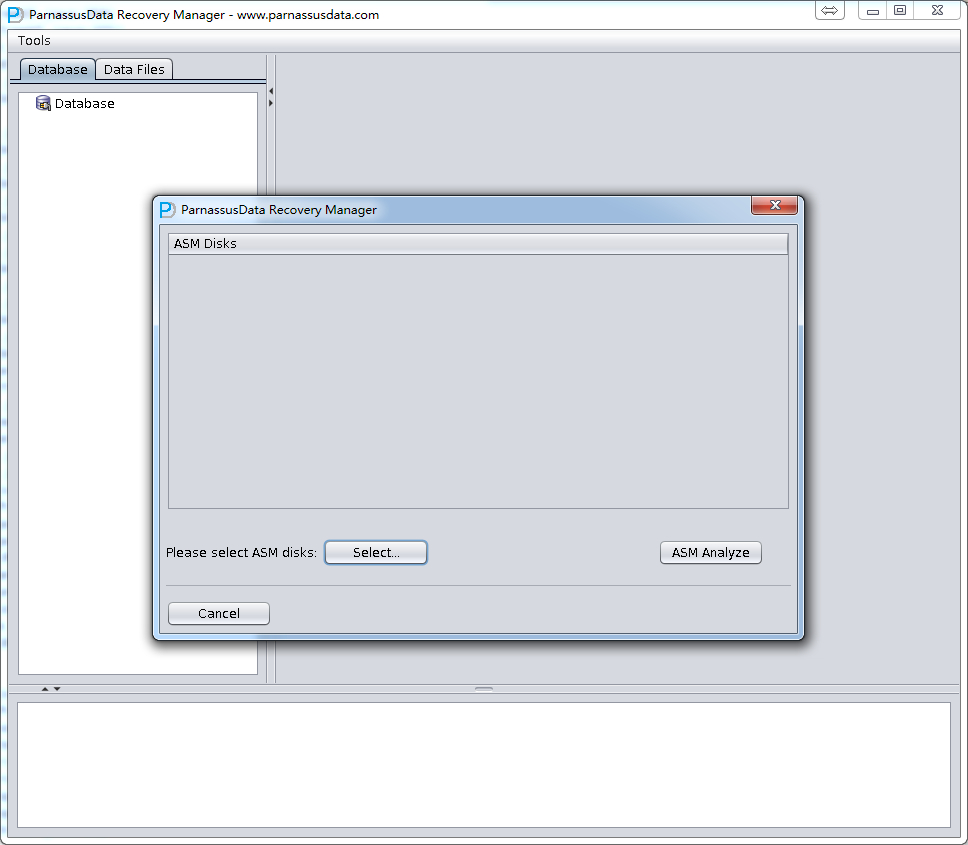
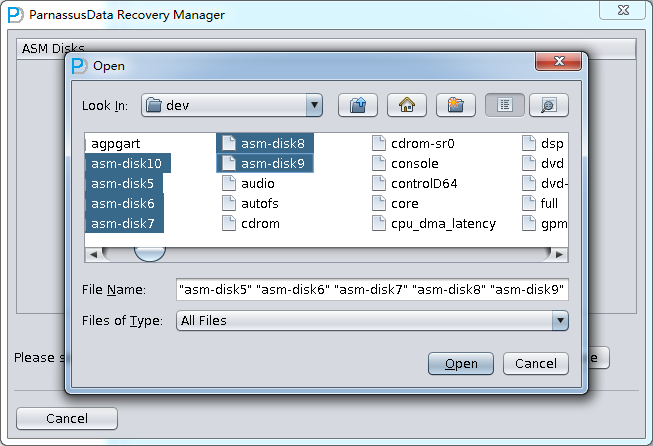
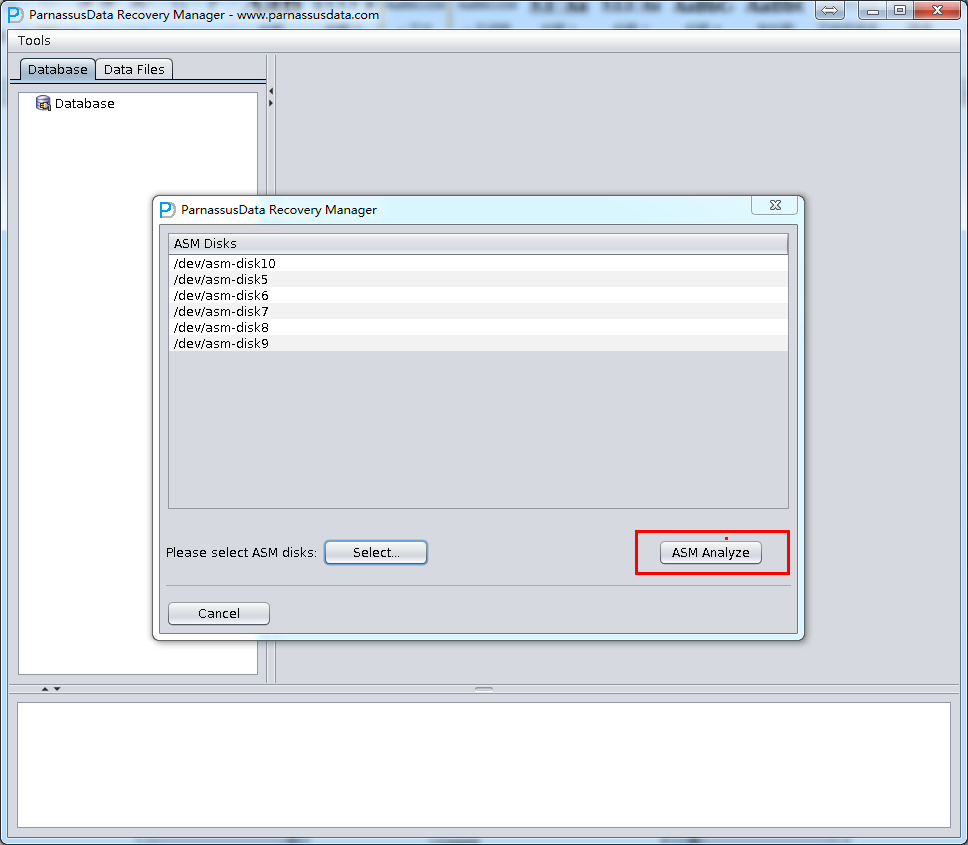
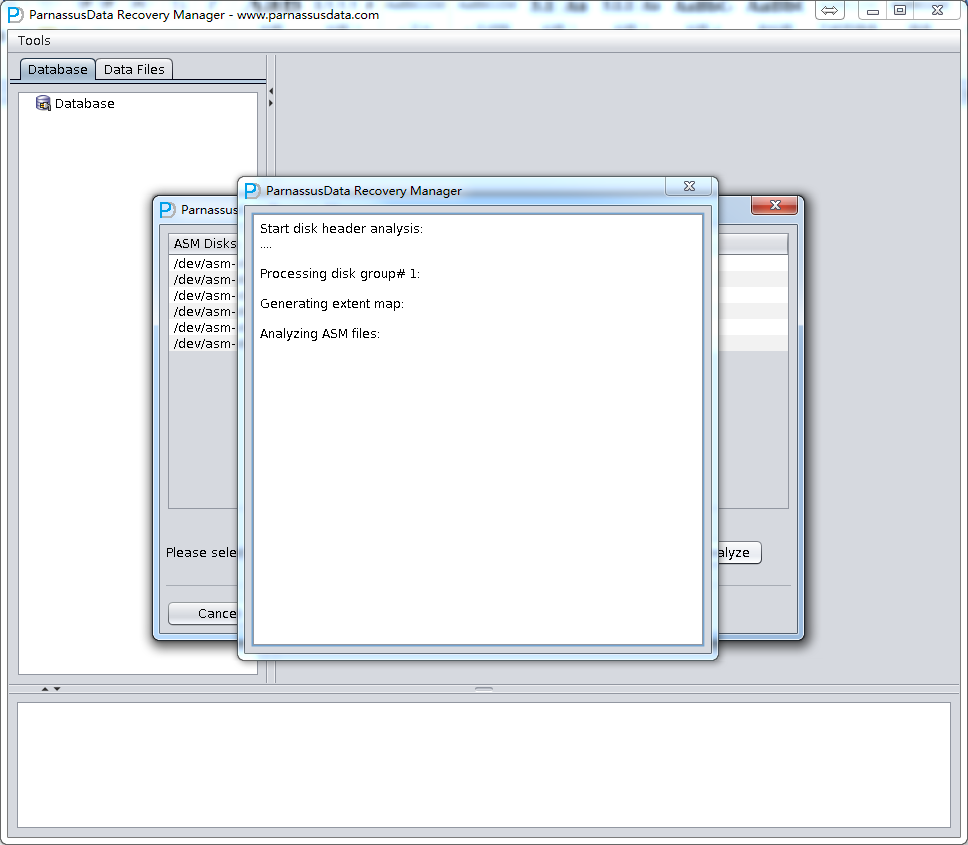











 DUL> scan dump file expdat.dmp;
0: CSET: 1 (US7ASCII) # Character set info from the header
3: SEAL EXPORT:V10.02.01 # the Seal - the exp version tag
20: DBA SYSTEM # exp done as SYSTEM
8461: CONNECT SCOTT # section for user SCOTT
8475: TABLE "EMP"
# complete create table staement
8487: CREATE TABLE "EMP" ("EMPNO" NUMBER(4, 0), "ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9), "MGR" NUMBER(4, 0), "HIREDATE" DATE, "SAL" NUMBER(7, 2),
"COMM" NUMBER(7, 2), "DEPTNO" NUMBER(2, 0)) PCTFREE 10 PCTUSED 40
INITRANS 1 MAXTRANS 255 STORAGE(INITIAL 65536 FREELISTS 1
FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS" LOGGING NOCOMPRESS
# Insert statement
8829: INSERT INTO "EMP" ("EMPNO", "ENAME", "JOB", "MGR", "HIREDATE",
"SAL", "COMM", "DEPTNO") VALUES (:1, :2, :3, :4, :5, :6, :7, :8)
# BIND information
8957: BIND information for 8 columns
col[ 1] type 2 max length 22
col[ 2] type 1 max length 10 cset 31 (WE8ISO8859P1) form 1
col[ 3] type 1 max length 9 cset 31 (WE8ISO8859P1) form 1
col[ 4] type 2 max length 22
col[ 5] type 12 max length 7
col[ 6] type 2 max length 22
col[ 7] type 2 max length 22
col[ 8] type 2 max length 22
Conventional export # Conventional means NOT DIRECT
9003: start of table data # Here begins the first row
现在从create table语句和直接/常规信息和列数据的开头创建unexp语句。
UNEXP TABLE "EMP" ("EMPNO" NUMBER(4, 0), "ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9), "MGR" NUMBER(4, 0), "HIREDATE" DATE, "SAL" NUMBER(7, 2),
"COMM" NUMBER(7, 2), "DEPTNO" NUMBER(2, 0))
dump file expdat.dmp from 9003;
Unloaded 14 rows, end of table marker at 9670 # so we have our famous 14 rows
这将创建普通SQL * Loader文件和匹配的控制文件。在输出文件中一个额外的列被添加,这是与行的状态有关。 AP表示行是部分的,(缺失一些列)R指重新同步,这是一个再同步之后的第一行。 O表示重叠,之前的一行有错误,但新行与另一行部分重叠。
目录
~~~~~~~~~~~~~~~~~
1.简介
2.使用DUL
2.1创建一个适当的init.dul文件
2.2创建control.dul文件
2.3导出对象信息
2.4调用DUL
2.5重建数据库
3.如何重建存储在数据字典的对象定义?
4当段头块被损坏时,如何导出数据?
5. 当文件头块被损坏时,如何导出数据?
6.如何导出数据,而无需系统表空间?
7.附录A:哪里可以找到可执行文件?
8.参考
1.简介
~~~~~~~~~~~~~~~
本文档解释了如何使用DUL,而不是对Bernard的数据导出能力的完整解释。
本文件仅供内部使用,不应在任何时候给予客户,DUL应始终被分析师使用或在分析师监督下使用。
DUL(数据导出)尝试从Oracle数据库中检索无法检索的数据。这不是导出工具或
SQL * Loader的替代选择。该数据库可能被破坏,但一个单独的数据块必须是100%正确的。在所有导出时,块会被检查,以确保块没有损坏且属于正确的段。如果一个损坏的块被DUL检测到,错误信息会被打印到loader文件,并输出到标准输出,但是这不会终止下一行或块的导出。
2.使用DUL
~~~~~~~~~~~~
首先,你必须获得存在于数据块的对象所需的信息,这些统计将被加载到DUL字典以导出数据库对象。
这个信息是从在数据库创建时被创建的USER $,OBJ $,$ TAB和COL $表中检索的
,它们可以基于这一事实:由于SQL,BSQ的刚性性质,对象号在这些表是固定的而被导出。 DUL可以在系统的系统表空间中找到信息,因此,如果(多个)数据文件不存在,(多个)表数据文件必须包含在控制文件中,参见第6章。
2.1创建相应的“init.dul”文件
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
REM平台指定参数(NT)
REM能获取的最常见平台的一列参数。
osd_big_endian_flag=false
osd_dba_file_bits=10
osd_c_struct_alignment=32
osd_file_leader_size=1
osd_word_size = 32
REM DUL字典缓存的大小。如果其中某一个过低,启动将失败。
dc_columns=2000000
dc_tables=10000
dc_objects=1000000
dc_users=400
dc_segments=100000
控制文件的位置和文件名,默认值是control.dul
在当前目录control_file = D:\Dul\control_orcl.dul
数据库块大小,可以在init.ora中的文件中找到,或在服务器管理器中执行“show parameter %db_block_size%” 被检索到
(svrmgr23/ 30 /l)将该参数更改为损坏数据块的块大小。
db_block_size=4096。
当数据需要导出/导入格式,它可以/必须被指定。
这将创建Oracle导入工具适用的文件,虽然生成的文件与由EXP工具生成的表模式导出完全不同。
它是有一个创建表结构语句和表数据的单个表转储文件。
grants,存储子句,触发器不包括在这个转储文件中!
export_mode=true
REM兼容参数可以被指定且可以是6,7或8
compatible=8
该参数是可选的并能在REM不支持的长文件名(e.g. 8.3 DOS)的平台,或当文件格式DUL使用 “owner_name.table_name.ext”不可接受时被指定。
在这里,转储文件会类似dump001.ext,dump002.ext,等。
file = dump
完整的列表可在HTML部分“DUL参数”获取,虽然这init.dul文件在大多数情况可行,且包含所有正确参数以成功完成导出。
2.2 创建“control.dul”文件
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
你需要对有关逻辑表空间和物理数据文件有一定了解,或你可以在数据库被加载时进行以下查询:
Oracle 6, 7
———–
> connect internal
> spool control.DUL
> select * from v$dbfile;
> spool off
Oracle 8
——–
> connect internal
> spool control.DUL
> select ts#, rfile#, name from v$datafile;
> spool off
如果需要的话,编辑spool文件和变化,数据文件的位置和stripe out不必要的信息,如表头,反馈行,等...
示例控制文件像这样:
Edit the spool file and change, if needed, the datafile location and stripe
out unnecessary information like table headers, feedback line, etc…
A sample control file looks something like this :
REM Oracle7 control file
1 D:\DUL\DATAFILE\SYS1ORCL.DBF
3 D:\DUL\DATAFILE\DAT1ORCL.DBF
7 D:\DUL\DATAFILE\USR1ORCL.DBF
REM Oracle8 control file
0 1 D:\DUL\DATAFILE\SYS1ORCL.DBF
1 2 D:\DUL\DATAFILE\USR1ORCL.DBF
1 3 D:\DUL\DATAFILE\USR2ORCL.DBF
2 4 D:\DUL\DATAFILE\DAT1ORCL.DBF
注:每个条目可以包含一个数据文件的一部分,当你需要拆分对于DUL太大的数据文件时,这就有用了,这样每个部分就小于比方说2GB了。 例如 :
REM Oracle8 其中一个数据文件被分割成多部分,每部分小于1GB!
0 1 D:\DUL\DATAFILE\SYS1ORCL.DBF
1 2 D:\DUL\DATAFILE\USR1ORCL.DBF startblock 1 endblock 1000000
1 2 D:\DUL\DATAFILE\USR1ORCL.DBF startblock 1000001 endblock 2000000
1 2 D:\DUL\DATAFILE\USR1ORCL.DBF startblock 2000001 endblock 2550000
2.3 Unload the object information
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
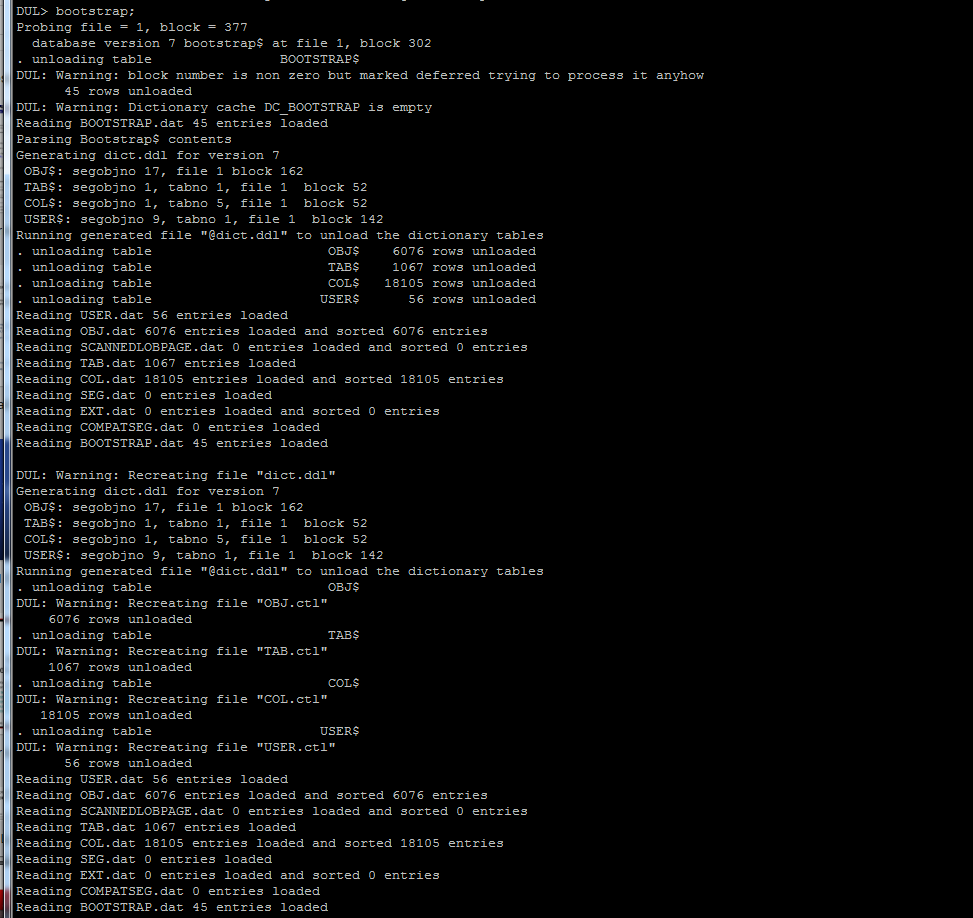
以适当DDL(DUL描述语言)脚本启动BUL工具。由于数据库版本不同,有3个可用脚本来导出USER$,$ OBJ,TAB$和COL$表。
Oracle6 :> dul8.exe dictv6.ddl
Oracle7 :> dul8.exe dictv7.ddl
Oracle8 :> dul8.exe dictv8.ddl
Data UnLoader: Release 8.0.5.3.0 – Internal Use Only – on Tue Jun 22 22:19:
Copyright (c) 1994/1999 Bernard van Duijnen All rights reserved.
Parameter altered
Session altered.
Parameter altered
Session altered.
Parameter altered
Session altered.
Parameter altered
Session altered.
. unloading table OBJ$ 2271 rows unloaded
. unloading table TAB$ 245 rows unloaded
. unloading table COL$ 10489 rows unloaded
. unloading table USER$ 22 rows unloaded
. unloading table TABPART$ 0 rows unloaded
. unloading table IND$ 274 rows unloaded
. unloading table ICOL$ 514 rows unloaded
. unloading table LOB$ 13 rows unloaded
Life is DUL without it
这将 USER$, OBJ$, TAB$ and COl$ 数据字典表的数据导出到 SQL*Loader 文件,这不能被处理到导入格式的转储文件中。 , this can not be manipulated into dump files
of the import format. 参数 export_mode = false 被硬编码到ddl脚本且不能更改为值“true”,因为这会导致DUL产生错误而失败:
. unloading table OBJ$
DUL: Error: Column “DATAOBJ#” actual size(2) greater than length in column
definition(1)
………….etc……………
2.4 调用DUL
~~~~~~~~~~~~~~
在交互模式下启动DUL,你也可以准备一个包含所有ddl命令以导出数据库必要数据的脚本。我会在本文档中描述最常用的命令,但不是完整的可指定参数列表。完整的列表可以在 “DDL描述”部分找到。
DUL> unload database;
=> 这将导出整个数据库表(包括sys'tables)
DUL> unload user ;
=> 这将导出所有特定用户所拥有的表。
DUL> unload table ;
=> 这将卸载由用户名拥有的指定表
DUL> describe ;
=> 将表示表列以及指定用户所拥有的(多个)数据文件的指向。will represent the table columns with there relative pointers to the datafile(s) owned by the specified user.
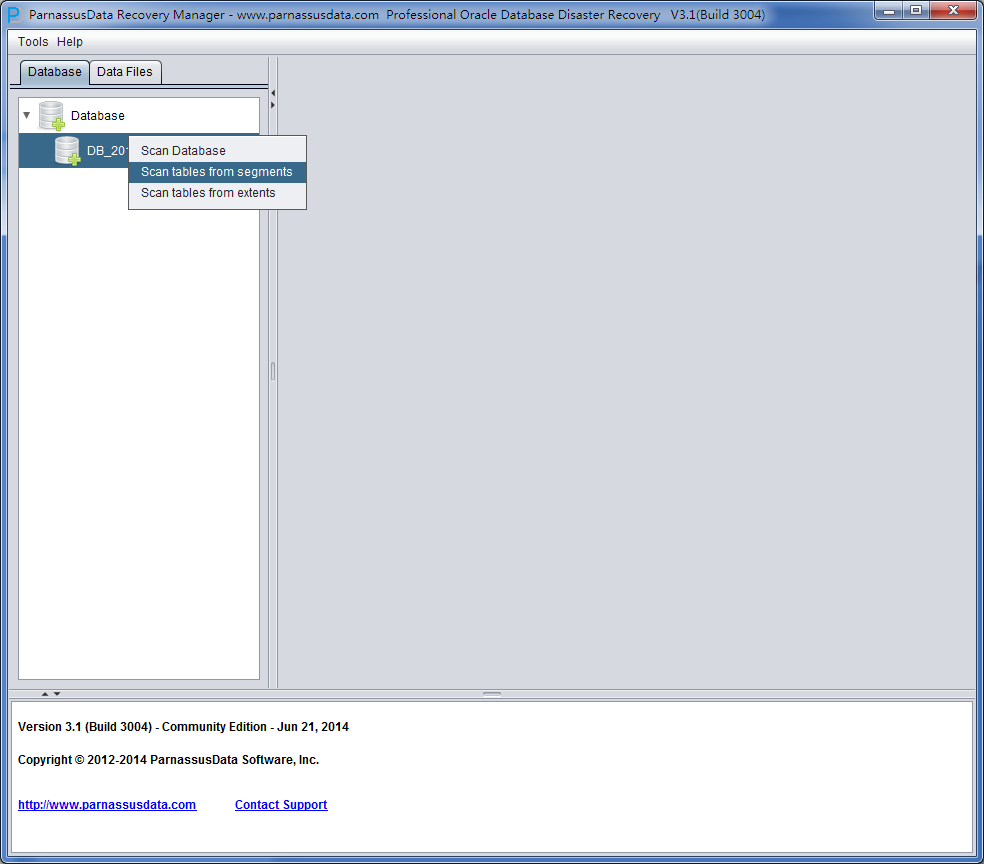
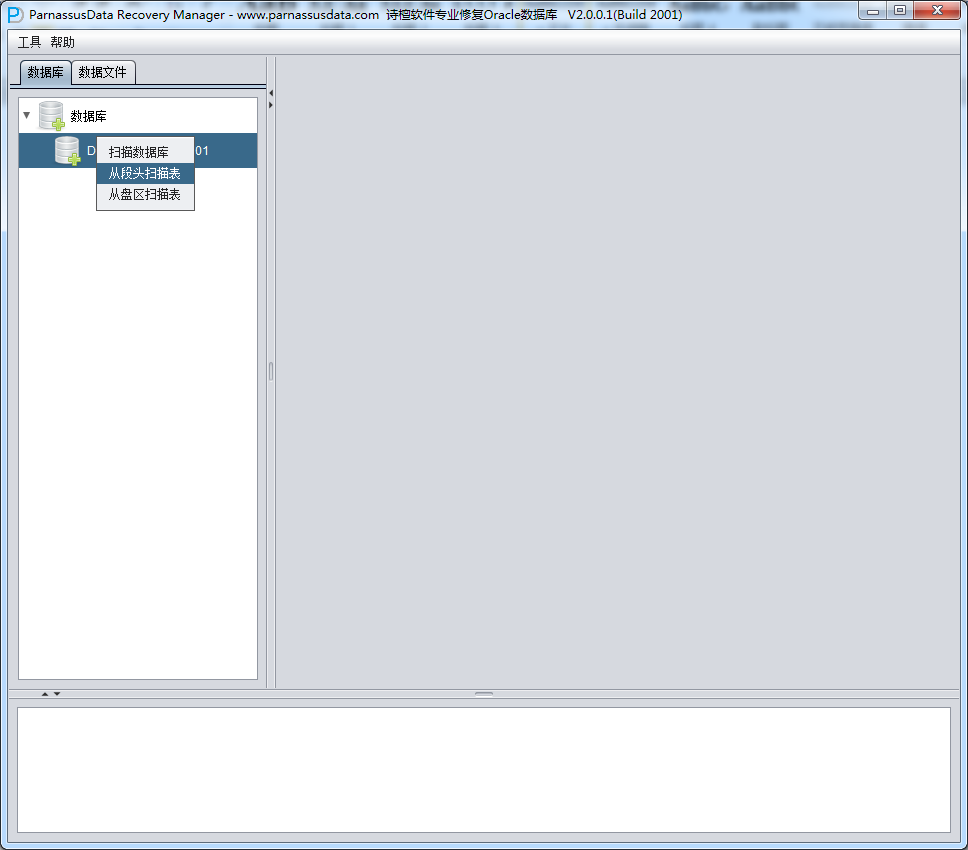
DUL> scan database;
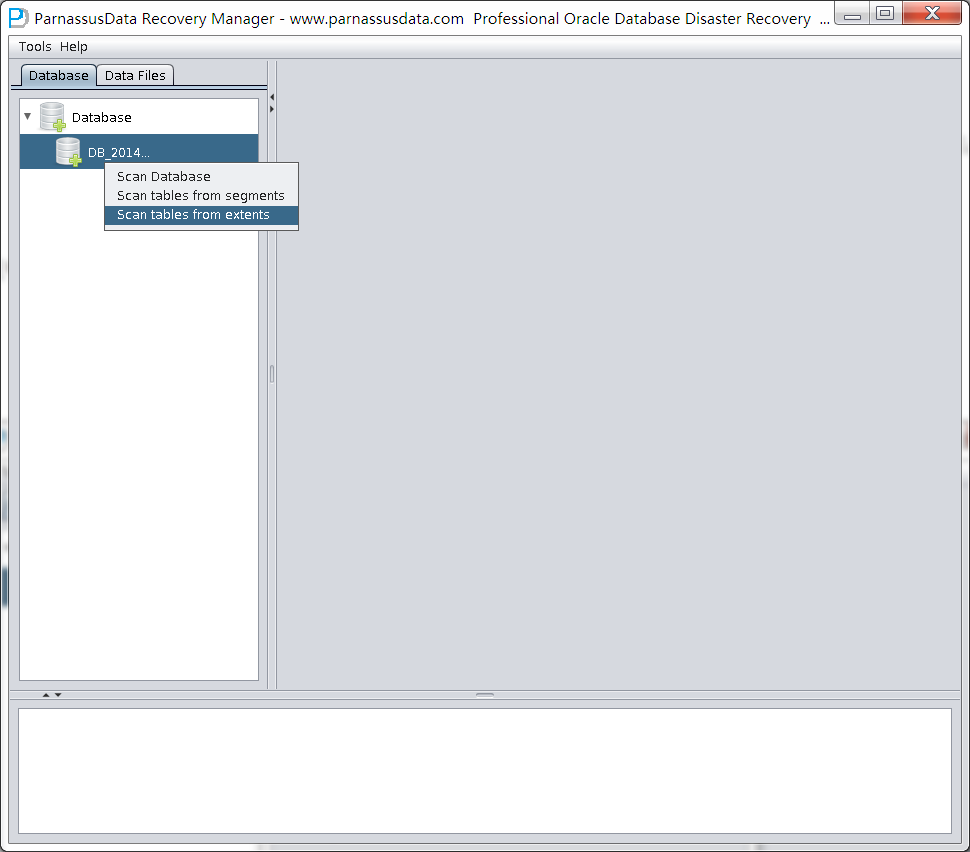
=>扫描所有数据文件的所有块。
生成两个文件:
1:找到的段头的seg.dat信息(索引/集群/表)
(对象ID,文件号和块号)。
2:连续的表/集群的数据块的ext.dat信息。
(对象ID(V7),文件和段头的块号(V6),文件号和第一个块的块号,块的数量,表数量)
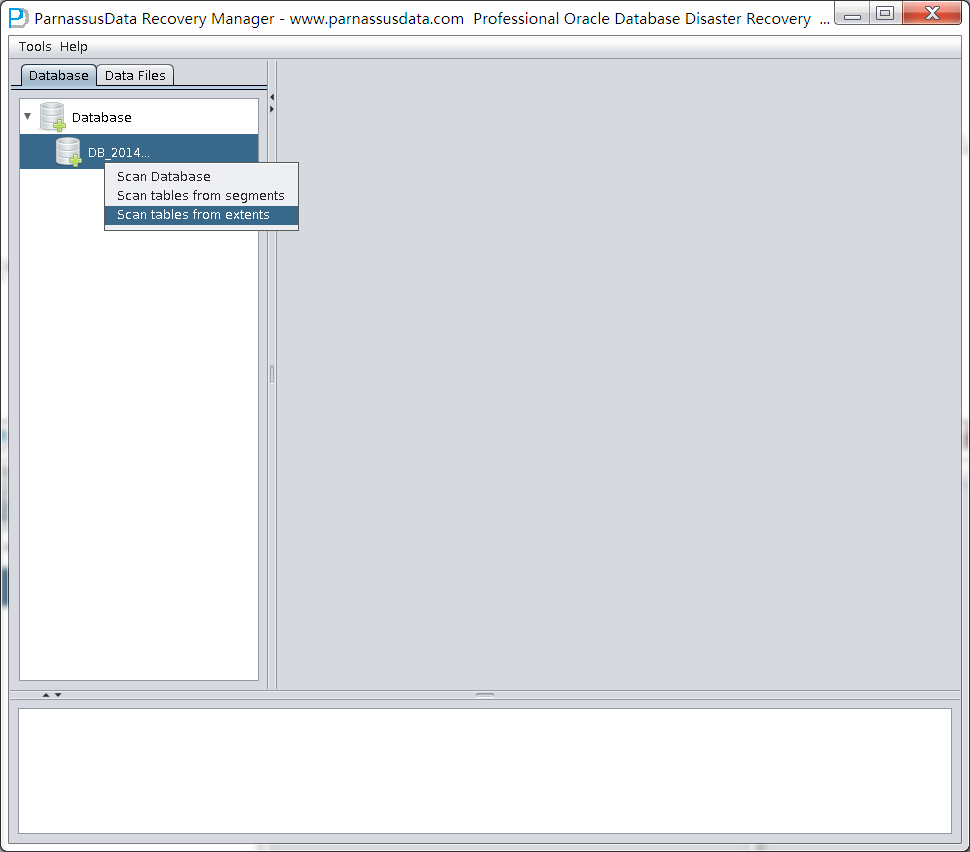
DUL> scan tables;
=>使用seg.dat和ext.dat作为输入。
扫描所有数据段中的所有表(一个头块和至少匹配至少一个表的一个区段)。
2.5重建数据库
~~~~~~~~~~~~~~~~~~~~~~~~
创建新的数据库,并使用导入或SQL * Loader来恢复被DUL检索到的数据。需要注意的是,当你只导出表结构数据时,索引,grants,PL / SQL和触发器将不再在新的数据库中存在。为了获得与之前数据库的完全相同的副本,你需要重新运行表,索引,PL / SQL等的创建脚本。
如果你没有这些脚本,那么你将需要执行在文档第3部分描述的步骤。
3.如何重建存储在数据字典的对象定义
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ~~~~~~~~~~~~~~~~~~~~~~~~~
要通过DUL重建PL / SQL(程序包,过程,函数或触发器),grants,索引,约束或存储子句(旧的表结构)是可以的,但就是有点棘手。您需要使用DUL导出相关的数据字典表,然后加载这些表到一个健康的数据库,一定要使用与SYS或(系统)不同的用户。加载损坏数据库的数据字典表到健康数据库字典可能也会破坏健康的数据库。
示例从损坏的数据库检索pl/sql packages / procedures /functions的详情:
1)按照在“使用DUL”一节中的步骤解释并导出数据字典表“source$”
2)创建一个新的用户登录到一个健康数据库,并指定所需的默认和临时表空间。
3)将连接,资源, imp_full_database授权给新用户。
4)导入/加载表“source$”到新创建的模式:
例如:imp80 userid=newuser/passw file=d:\dul\scott_emp.dmp
log=d:\dul\impemp.txt full=y
5)现在,您可以从表查询以在损坏的数据库中重建pl/sql packages / procedures /functions。在WebIv可以找到产生这样的PL / SQL创建脚本。
相同的步骤可以用于重建索引,约束,和存储参数,或者为相应的用户重新授权。请注意,你总是需要使用某种类型的脚本,可以重建对象并包括损坏的数据库版本的所有功能。例如:当损坏的数据库是7.3.4版本,你有几个位图索引,如果你会使用支持7.3.2版本或之前的脚本,那么你将无法成功重建位图索引!
4. 当段头块被损坏时,如何导出数据
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ~~~~~~~~~~~~~~
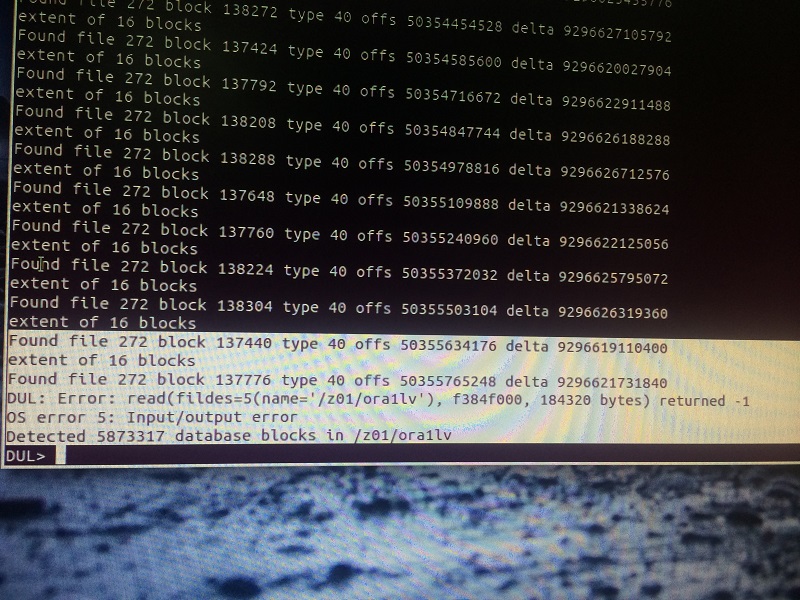
当DUL不能以正常方式检索数据块信息,它可以扫描数据库来创建其自己的段/区段地图。要从数据文件导出数据,扫描数据库的过程是必要的。
(为了说明这个例子,我根据段头块复制一个空块)
1)创建一个适当的“init.dul”(见2.1)和“control.dul”(见2.2)的文件。
2)导出表。这将失败,并指出段头块有损坏:
DUL> unload table scott.emp;
. unloading table EMP
DUL: Warning: Block is never used, block type is zero
DUL: Error: While checking tablespace 6 file 10 block 2
DUL: Error: While processing block ts#=6, file#=10, block#=2
DUL: Error: Could not read/parse segment header
0 rows unloaded
3)运行扫描数据库命令:
DUL> scan database;
tablespace 0, data file 1: 10239 blocks scanned
tablespace 6, data file 10: 2559 blocks scanned
4)向DUL说明它应该使用自己的生成的区段地图,而不是段头信息。
DUL> alter session set use_scanned_extent_map = true;
Parameter altered
Session altered.
DUL> unload table scott.emp;
. unloading table EMP 14 rows unloaded
5. 当数据文件头块损坏时,如何导出数据
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ~~~~~~~~~~~~~~~
在你打开数据库时,数据文件头块的损坏总是会列出。这不像一个头段块的损坏(见第4点),其中的数据库可以成功打开,且当你进行表查询时,损坏会列出。DUL从这种情况中恢复没有问题,尽管有其他恢复这种情况的方法,如为数据文件头块打补丁。
你将收到如下错误:
ORACLE instance started.
Total System Global Area 11739136 bytes
Fixed Size 49152 bytes
Variable Size 7421952 bytes
Database Buffers 4194304 bytes
Redo Buffers 73728 bytes
Database mounted.
ORA-01122: database file 10 failed verification check
ORA-01110: data file 10: ‘D:\DATA\TRGT\DATAFILES\JUR1TRGT.DBF’
ORA-01251: Unknown File Header Version read for file number 10
6.如何卸载数据,而无需系统表空间
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
如果数据文件不能用于系统表空间,导出仍可继续,但对象信息无法从数据字典表USER $,OBJ $,$ TAB和COL $检索。所以所有者名称,表名和列名不会被加载到DUL字典。识别表会是一项艰巨的任务,且这里需要对RDBMS内部有很好的了解。
首先,你需要对你的应用和它的表有很好的了解。
列类型可以有DUL猜测,但表和列名都将丢失。
任何同一个数据库旧的系统表空间(可能是几周前的)可以是很大的帮助!
1)如上述的步骤1和2,创建 “init.dul”文件和“control.dul”文件。在这种情况下,控制文件将包含所有你想要恢复的数据文件,但不需要系统表空间的信息。
2)然后你调用DUL并输入以下命令:
DUL> scan database;
data file 6 1280 blocks scanned
这将创建区段和段地图。也许DUL命令解释程序也将被终止。
3)重新调用DUL命令解释器并执行以下操作:
Data UnLoader: Release 8.0.5.3.0 – Internal Use Only – on Tue Aug 03 13:33:
Copyright (c) 1994/1999 Oracle Corporation, The Netherlands. All rights res
Loaded 4 segments
Loaded 2 extents
Extent map sorted
DUL> alter session set use_scanned_extent_map = true;
DUL> scan tables; (or scan extents;)
Scanning tables with segment header
Oid 1078 fno 6 bno 2 table number 0
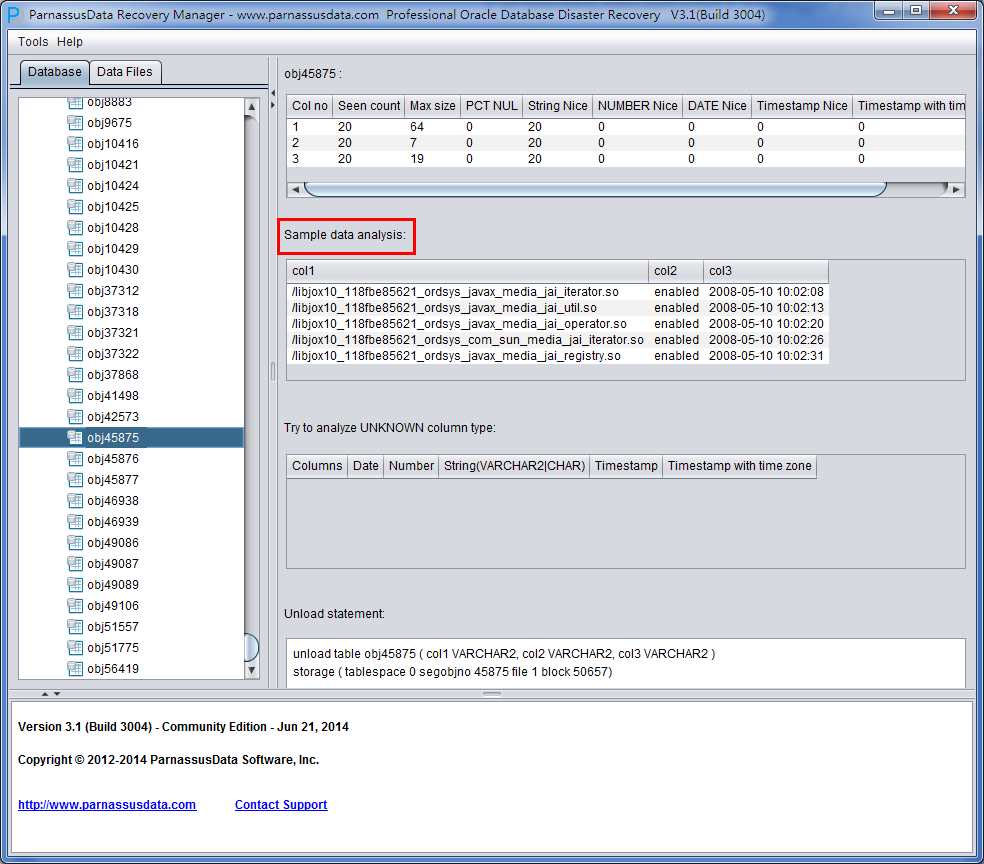
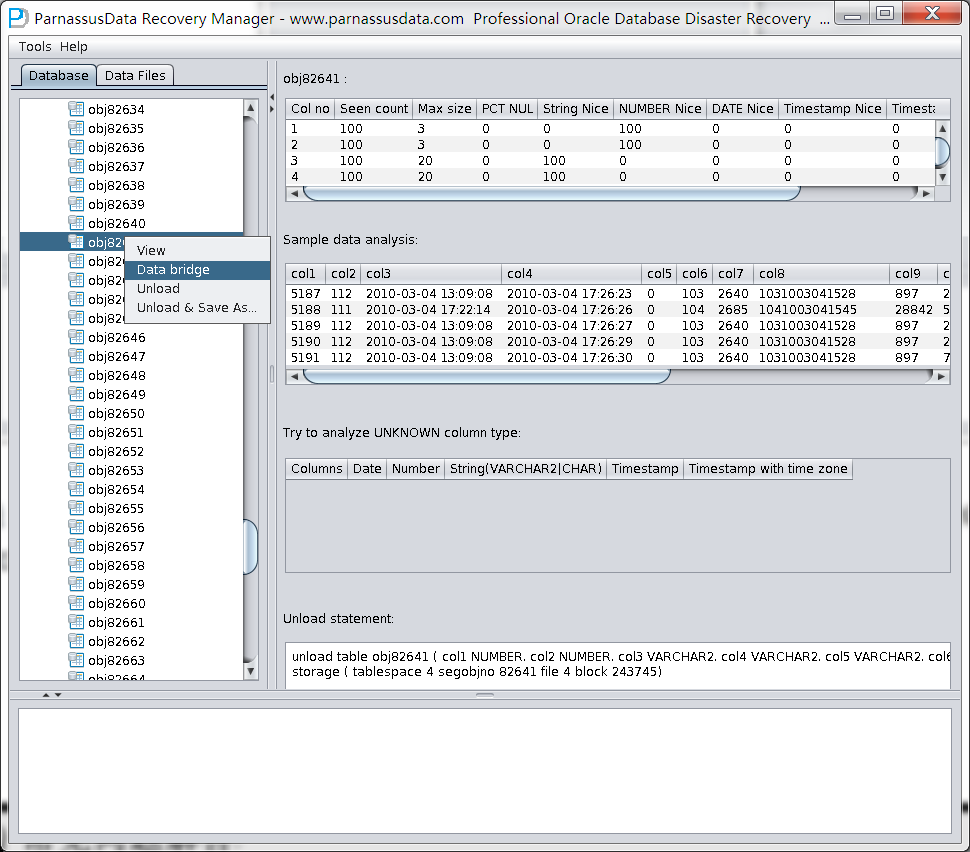
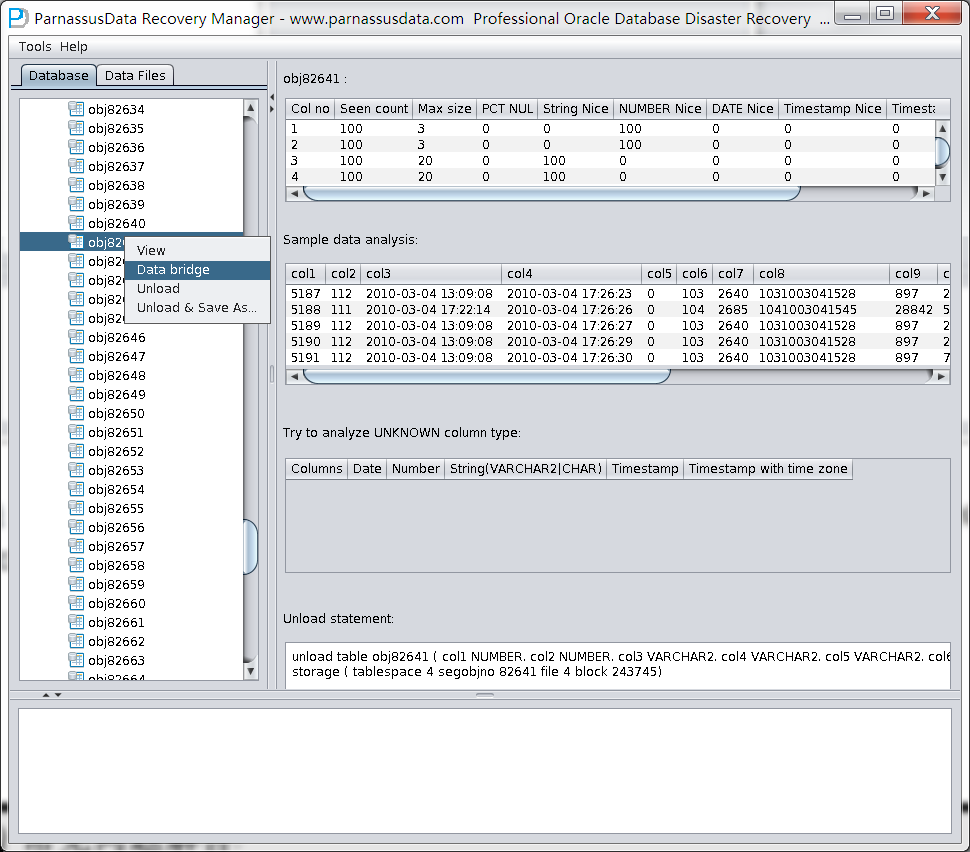
UNLOAD TABLE T_O1078 ( C1 NUMBER, C2 UNKNOWN, C3 UNKNOWN )
STORAGE ( TABNO 0 EXTENTS( FILE 6 BLOCK 2));
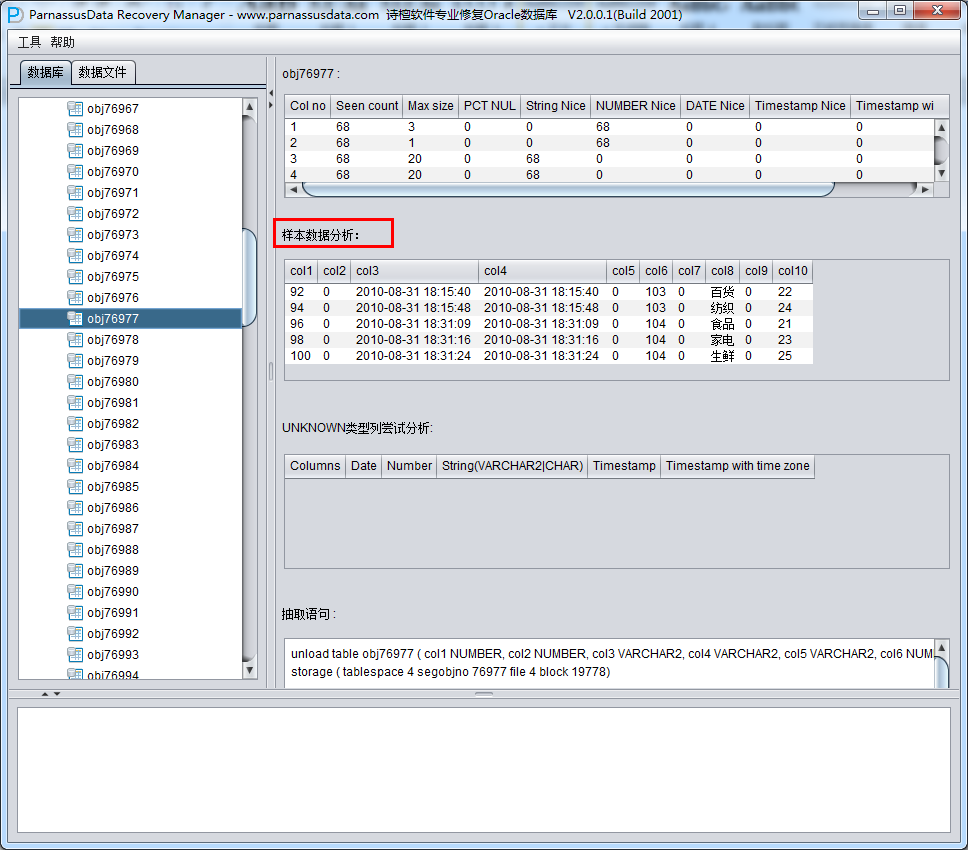
Colno Seen MaxIntSz Null% C75% C100 Num% NiNu% Dat% Rid%
1 4 2 0% 0% 0% 100% 100% 0% 0%
2 4 10 0% 100% 100% 100% 0% 0% 0%
3 4 8 0% 100% 100% 100% 0% 0% 50%
“10” “ACCOUNTING” “NEW YORK”
“20” “RESEARCH” “DALLAS”
“30” “SALES” “CHICAGO”
“40” “OPERATIONS” “BOSTON”
Oid 1080 fno 6 bno 12 table number 0
UNLOAD TABLE T_O1080 ( C1 NUMBER, C2 UNKNOWN, C3 UNKNOWN, C4 NUMBER,
C5 DATE, C6 NUMBER, C7 NUMBER, C8 NUMBER )
STORAGE ( TABNO 0 EXTENTS( FILE 6 BLOCK 12));
Colno Seen MaxIntSz Null% C75% C100 Num% NiNu% Dat% Rid%
1 14 3 0% 0% 0% 100% 100% 0% 0%
2 14 6 0% 100% 100% 100% 0% 0% 21%
3 14 9 0% 100% 100% 100% 0% 0% 0%
4 14 3 7% 0% 0% 100% 100% 0% 0%
5 14 7 0% 0% 0% 0% 0% 100% 0%
6 14 3 0% 0% 0% 100% 100% 0% 0%
7 14 2 71% 0% 0% 100% 100% 0% 0%
8 14 2 0% 0% 0% 100% 100% 0% 0%
“7369” “SMITH” “CLERK” “7902” “17-DEC-1980 AD 00:00:00″ “800” “” “20”
“7499” “ALLEN” “SALESMAN” “7698” “20-FEB-1981 AD 00:00:00″ “1600” “300” “30”
“7521” “WARD” “SALESMAN” “7698” “22-FEB-1981 AD 00:00:00″ “1250” “500” “30”
“7566” “JONES” “MANAGER” “7839” “02-APR-1981 AD 00:00:00″ “2975” “” “20”
“7654” “MARTIN” “SALESMAN” “7698” “28-SEP-1981 AD 00:00:00″ “1250” “1400” “30”
Note : it might be best that you redirect the output to a logfile since
commands like the “scan tables” can produce a lot of output.
On Windows NT you can do the following command :
C:\> dul8 > c:\temp\scan_tables.txt
scan tables;
exit;
4)从步骤3的输出中找到丢失的表;如果你仔细看上面的输出会发现,unload语法已经给出,但表的名称将是格式T_0 ,列名称将是格式的C ;数据类型不会精确匹配之前的数据类型。
特别查找像“Oid 1078 fno 6 bno 2 table number 0”的字符串,其中:
oid = object id, will be used to unload the object 对象id,会被用于导出对象
fno = (data)file number (数据)文件号
bno = block number 块号
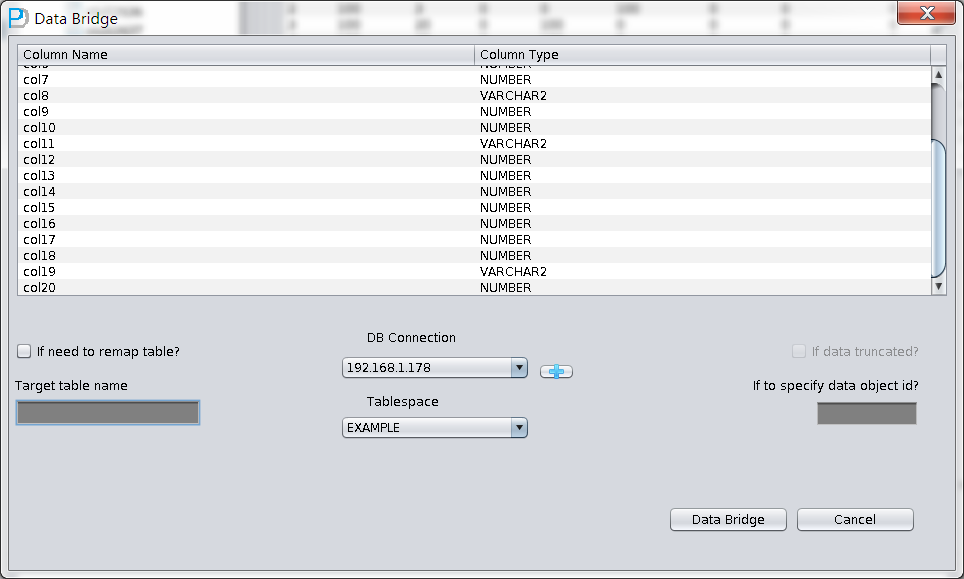
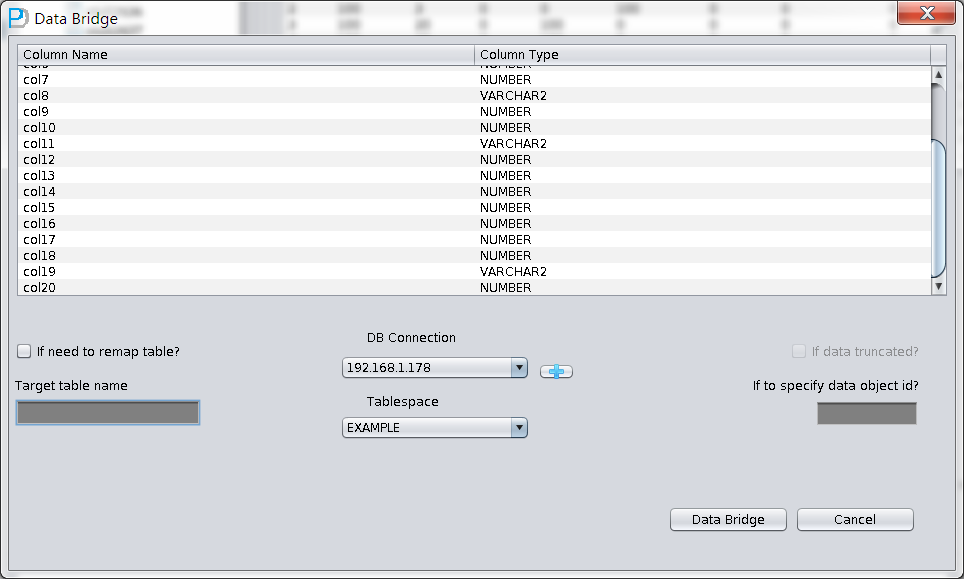
5)使用“unload table”命令导出找出的表:
DUL> unload table dept (deptno number(2), dname varchar2(14),
loc varchar2(13)) storage (OBJNO 1078)
Unloading extent(s) of table DEPT 4 rows.
评论:
DUL盘头副本
盘头副本
盘头副本
最近有ASM磁盘头的额外副本。通过使用kfed与修复选项,此副本可以用来修复真正的头。
位置
此副本被存储为PST的最后一个块。这意味着它在分配单元1的最后一个块(原来是au 0的块0)。分配单位的默认大小为为1M,元数据块的默认大小为4K,这表示每个au中有256块。所以,通常副本在au1 block 254(ASM从零计数,原始的在分配单元0块0)
kfed修复
确定唯一的问题是与丢失/损坏的磁盘头后,该修复程序很简单,只要:
$ kfed repair
如果su大小为非标准的,以上会失败,显示如下:
KFED-00320: Invalid block num1 = [3] , num2 = [1] , error = [type_kfbh]
但这是预料之中的,且没有任何损害。你只需要指定正确的au大小。例如4MB AU的命令是:
$ kfed repair ausz=4194304
DUL
DUL将检查/使用头复制(总是?或者只在主头损坏的情况下?)如果头损坏,但副本是好的,警告使用kfed?
参考
Bug 5061821 OS工具可以摧毁ASM磁盘头fixed 11.2.0.1,11.1.0.7,10.2.0.5和更高。
注意417687.1在现有的一个磁盘头损坏后创建一个新的ASM磁盘头
rdbms/src/client/tools/kfed/kfed.c
DUL导出扫描的lob
我们的想法是直接从LOB段导出LOB。
我们需要弄清楚:
1. 它是CLOB还是BLOB
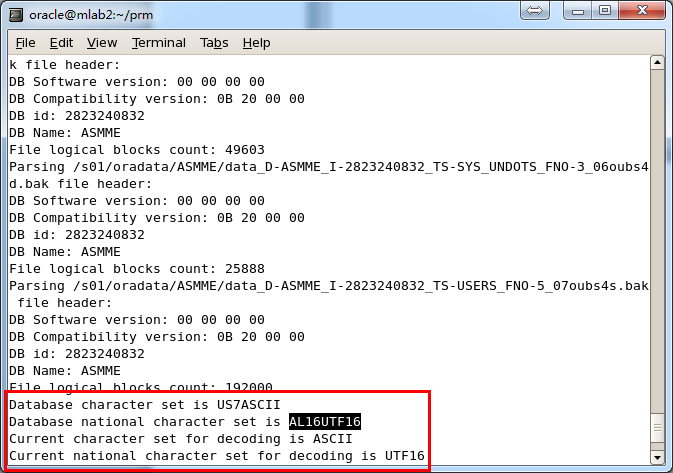
2. 对于CLOB,它的字符集,单字节或UCS16,字节大小
3. 块大小,在头中的lob page#是一个fat page number
4. 缺失页应当被发出为全零
5. 大小未知,只需要剥离trailing zeroes(但对于字节大小)?
实施的变更:
1.添加LOB段ID来扫描lob页面信息,因为大多数属性适用于段。即扫描的lob页缓存的布局是:segid,lobid,fatpageno(chunk#),version wrap, vsn base, ts#, file#, block#
要做的事:
1.导出所有LOB的命令。一个LOB段提供命令中所有的常用属性。
2.从LOB段指定lobid,可选的大小,和可选的DBA列表中导出单个lob的命令
3.分析生成导出LOB段命令的命令
4.分析生成从段中导出每个LOB命令的命令
需要考虑的事项:
1. 更改 file#, block# 为单个dba?pro no calculations, contra more difficult to read?
我正与客户在处理一个数据打捞作业。从DUL网站下载的DUL工具不能正常工作!
dul4x86-linux.tar.gz给出错误:version ‘GLIBC_2.11’ not found
dul4i386-linux.as3.tar.gz给出错误:You need a more recent DUL version for this os.你需要一个较新的版本DUL这个操作系统。
客户端Linux版本:2.6.32-400.33.2.el5uek
请帮忙!!!
Linux有两个版本,这是第二个,被正常启动的。由于内建复制的保护,您必须确保从Bernard的网站上下载最新的版本。如果你确实有最新的下载,那么只有Bernard可以重新编译并重新分配一个新的可执行版本。 DUL大约每45天失效。
我们处在关键时刻,需要DUL从一个production down降数据库中提取数据。
- 数据库在NOARCHIVELOG模式/ Windows 64位平台。
- 由于go life,没有可用的数据库备份
- 数据库较小,但非常重要。
- 从早晨开始有介质故障损坏了除真正客户数据的数据文件之外的所有数据库的数据文件。
- 根据每db验证工具输出,系统表空间100%损坏。
- 任何地方都没有系统表空间的备份,甚至测试系统是作为新的数据库创建的,因此对象ID,rfile号是不一样的。
我们尝试了以下内容:
1. 使用系统数据文件从生产中导出数据(由于系统数据文件被破坏,无法bootstrap)
2. 使用系统数据文件从TEST中导出数据(成功bootstrap,但无法导出,因为不匹配rfile#,TS#,和对象ID ..预想到的结果,但值得一试)
3. 仅使用实际数据的数据文件导出数据,成功生成scaned_tables,并且我们已向客户请求提供表的列表来map,但我不确定他们能否提供清晰信息。
感谢提供任何建议,类似于:
- 有没有什么办法来修复损坏的系统表空间的数据文件,并用它进行数据导出。
- 或者,有没有办法从TEST使用系统数据文件(不同的数据库作为新安装),其中rfile#, ts#,和对象id的错配。
DUL> scan dump file expdat.dmp;
0: CSET: 1 (US7ASCII) # Character set info from the header
3: SEAL EXPORT:V10.02.01 # the Seal - the exp version tag
20: DBA SYSTEM # exp done as SYSTEM
8461: CONNECT SCOTT # section for user SCOTT
8475: TABLE "EMP"
# complete create table staement
8487: CREATE TABLE "EMP" ("EMPNO" NUMBER(4, 0), "ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9), "MGR" NUMBER(4, 0), "HIREDATE" DATE, "SAL" NUMBER(7, 2),
"COMM" NUMBER(7, 2), "DEPTNO" NUMBER(2, 0)) PCTFREE 10 PCTUSED 40
INITRANS 1 MAXTRANS 255 STORAGE(INITIAL 65536 FREELISTS 1
FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS" LOGGING NOCOMPRESS
# Insert statement
8829: INSERT INTO "EMP" ("EMPNO", "ENAME", "JOB", "MGR", "HIREDATE",
"SAL", "COMM", "DEPTNO") VALUES (:1, :2, :3, :4, :5, :6, :7, :8)
# BIND information
8957: BIND information for 8 columns
col[ 1] type 2 max length 22
col[ 2] type 1 max length 10 cset 31 (WE8ISO8859P1) form 1
col[ 3] type 1 max length 9 cset 31 (WE8ISO8859P1) form 1
col[ 4] type 2 max length 22
col[ 5] type 12 max length 7
col[ 6] type 2 max length 22
col[ 7] type 2 max length 22
col[ 8] type 2 max length 22
Conventional export # Conventional means NOT DIRECT
9003: start of table data # Here begins the first row
现在从create table语句和直接/常规信息和列数据的开头创建unexp语句。
UNEXP TABLE "EMP" ("EMPNO" NUMBER(4, 0), "ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9), "MGR" NUMBER(4, 0), "HIREDATE" DATE, "SAL" NUMBER(7, 2),
"COMM" NUMBER(7, 2), "DEPTNO" NUMBER(2, 0))
dump file expdat.dmp from 9003;
Unloaded 14 rows, end of table marker at 9670 # so we have our famous 14 rows
这将创建普通SQL * Loader文件和匹配的控制文件。在输出文件中一个额外的列被添加,这是与行的状态有关。 AP表示行是部分的,(缺失一些列)R指重新同步,这是一个再同步之后的第一行。 O表示重叠,之前的一行有错误,但新行与另一行部分重叠。
目录
~~~~~~~~~~~~~~~~~
1.简介
2.使用DUL
2.1创建一个适当的init.dul文件
2.2创建control.dul文件
2.3导出对象信息
2.4调用DUL
2.5重建数据库
3.如何重建存储在数据字典的对象定义?
4当段头块被损坏时,如何导出数据?
5. 当文件头块被损坏时,如何导出数据?
6.如何导出数据,而无需系统表空间?
7.附录A:哪里可以找到可执行文件?
8.参考
1.简介
~~~~~~~~~~~~~~~
本文档解释了如何使用DUL,而不是对Bernard的数据导出能力的完整解释。
本文件仅供内部使用,不应在任何时候给予客户,DUL应始终被分析师使用或在分析师监督下使用。
DUL(数据导出)尝试从Oracle数据库中检索无法检索的数据。这不是导出工具或
SQL * Loader的替代选择。该数据库可能被破坏,但一个单独的数据块必须是100%正确的。在所有导出时,块会被检查,以确保块没有损坏且属于正确的段。如果一个损坏的块被DUL检测到,错误信息会被打印到loader文件,并输出到标准输出,但是这不会终止下一行或块的导出。
2.使用DUL
~~~~~~~~~~~~
首先,你必须获得存在于数据块的对象所需的信息,这些统计将被加载到DUL字典以导出数据库对象。
这个信息是从在数据库创建时被创建的USER $,OBJ $,$ TAB和COL $表中检索的
,它们可以基于这一事实:由于SQL,BSQ的刚性性质,对象号在这些表是固定的而被导出。 DUL可以在系统的系统表空间中找到信息,因此,如果(多个)数据文件不存在,(多个)表数据文件必须包含在控制文件中,参见第6章。
2.1创建相应的“init.dul”文件
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
REM平台指定参数(NT)
REM能获取的最常见平台的一列参数。
osd_big_endian_flag=false
osd_dba_file_bits=10
osd_c_struct_alignment=32
osd_file_leader_size=1
osd_word_size = 32
REM DUL字典缓存的大小。如果其中某一个过低,启动将失败。
dc_columns=2000000
dc_tables=10000
dc_objects=1000000
dc_users=400
dc_segments=100000
控制文件的位置和文件名,默认值是control.dul
在当前目录control_file = D:\Dul\control_orcl.dul
数据库块大小,可以在init.ora中的文件中找到,或在服务器管理器中执行“show parameter %db_block_size%” 被检索到
(svrmgr23/ 30 /l)将该参数更改为损坏数据块的块大小。
db_block_size=4096。
当数据需要导出/导入格式,它可以/必须被指定。
这将创建Oracle导入工具适用的文件,虽然生成的文件与由EXP工具生成的表模式导出完全不同。
它是有一个创建表结构语句和表数据的单个表转储文件。
grants,存储子句,触发器不包括在这个转储文件中!
export_mode=true
REM兼容参数可以被指定且可以是6,7或8
compatible=8
该参数是可选的并能在REM不支持的长文件名(e.g. 8.3 DOS)的平台,或当文件格式DUL使用 “owner_name.table_name.ext”不可接受时被指定。
在这里,转储文件会类似dump001.ext,dump002.ext,等。
file = dump
完整的列表可在HTML部分“DUL参数”获取,虽然这init.dul文件在大多数情况可行,且包含所有正确参数以成功完成导出。
2.2 创建“control.dul”文件
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
你需要对有关逻辑表空间和物理数据文件有一定了解,或你可以在数据库被加载时进行以下查询:
Oracle 6, 7
———–
> connect internal
> spool control.DUL
> select * from v$dbfile;
> spool off
Oracle 8
——–
> connect internal
> spool control.DUL
> select ts#, rfile#, name from v$datafile;
> spool off
如果需要的话,编辑spool文件和变化,数据文件的位置和stripe out不必要的信息,如表头,反馈行,等...
示例控制文件像这样:
Edit the spool file and change, if needed, the datafile location and stripe
out unnecessary information like table headers, feedback line, etc…
A sample control file looks something like this :
REM Oracle7 control file
1 D:\DUL\DATAFILE\SYS1ORCL.DBF
3 D:\DUL\DATAFILE\DAT1ORCL.DBF
7 D:\DUL\DATAFILE\USR1ORCL.DBF
REM Oracle8 control file
0 1 D:\DUL\DATAFILE\SYS1ORCL.DBF
1 2 D:\DUL\DATAFILE\USR1ORCL.DBF
1 3 D:\DUL\DATAFILE\USR2ORCL.DBF
2 4 D:\DUL\DATAFILE\DAT1ORCL.DBF
注:每个条目可以包含一个数据文件的一部分,当你需要拆分对于DUL太大的数据文件时,这就有用了,这样每个部分就小于比方说2GB了。 例如 :
REM Oracle8 其中一个数据文件被分割成多部分,每部分小于1GB!
0 1 D:\DUL\DATAFILE\SYS1ORCL.DBF
1 2 D:\DUL\DATAFILE\USR1ORCL.DBF startblock 1 endblock 1000000
1 2 D:\DUL\DATAFILE\USR1ORCL.DBF startblock 1000001 endblock 2000000
1 2 D:\DUL\DATAFILE\USR1ORCL.DBF startblock 2000001 endblock 2550000
2.3 Unload the object information
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
以适当DDL(DUL描述语言)脚本启动BUL工具。由于数据库版本不同,有3个可用脚本来导出USER$,$ OBJ,TAB$和COL$表。
Oracle6 :> dul8.exe dictv6.ddl
Oracle7 :> dul8.exe dictv7.ddl
Oracle8 :> dul8.exe dictv8.ddl
Data UnLoader: Release 8.0.5.3.0 – Internal Use Only – on Tue Jun 22 22:19:
Copyright (c) 1994/1999 Bernard van Duijnen All rights reserved.
Parameter altered
Session altered.
Parameter altered
Session altered.
Parameter altered
Session altered.
Parameter altered
Session altered.
. unloading table OBJ$ 2271 rows unloaded
. unloading table TAB$ 245 rows unloaded
. unloading table COL$ 10489 rows unloaded
. unloading table USER$ 22 rows unloaded
. unloading table TABPART$ 0 rows unloaded
. unloading table IND$ 274 rows unloaded
. unloading table ICOL$ 514 rows unloaded
. unloading table LOB$ 13 rows unloaded
Life is DUL without it
这将 USER$, OBJ$, TAB$ and COl$ 数据字典表的数据导出到 SQL*Loader 文件,这不能被处理到导入格式的转储文件中。 , this can not be manipulated into dump files
of the import format. 参数 export_mode = false 被硬编码到ddl脚本且不能更改为值“true”,因为这会导致DUL产生错误而失败:
. unloading table OBJ$
DUL: Error: Column “DATAOBJ#” actual size(2) greater than length in column
definition(1)
………….etc……………
2.4 调用DUL
~~~~~~~~~~~~~~
在交互模式下启动DUL,你也可以准备一个包含所有ddl命令以导出数据库必要数据的脚本。我会在本文档中描述最常用的命令,但不是完整的可指定参数列表。完整的列表可以在 “DDL描述”部分找到。
DUL> unload database;
=> 这将导出整个数据库表(包括sys'tables)
DUL> unload user ;
=> 这将导出所有特定用户所拥有的表。
DUL> unload table ;
=> 这将卸载由用户名拥有的指定表
DUL> describe ;
=> 将表示表列以及指定用户所拥有的(多个)数据文件的指向。will represent the table columns with there relative pointers to the datafile(s) owned by the specified user.
DUL> scan database;
=>扫描所有数据文件的所有块。
生成两个文件:
1:找到的段头的seg.dat信息(索引/集群/表)
(对象ID,文件号和块号)。
2:连续的表/集群的数据块的ext.dat信息。
(对象ID(V7),文件和段头的块号(V6),文件号和第一个块的块号,块的数量,表数量)
DUL> scan tables;
=>使用seg.dat和ext.dat作为输入。
扫描所有数据段中的所有表(一个头块和至少匹配至少一个表的一个区段)。
2.5重建数据库
~~~~~~~~~~~~~~~~~~~~~~~~
创建新的数据库,并使用导入或SQL * Loader来恢复被DUL检索到的数据。需要注意的是,当你只导出表结构数据时,索引,grants,PL / SQL和触发器将不再在新的数据库中存在。为了获得与之前数据库的完全相同的副本,你需要重新运行表,索引,PL / SQL等的创建脚本。
如果你没有这些脚本,那么你将需要执行在文档第3部分描述的步骤。
3.如何重建存储在数据字典的对象定义
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ~~~~~~~~~~~~~~~~~~~~~~~~~
要通过DUL重建PL / SQL(程序包,过程,函数或触发器),grants,索引,约束或存储子句(旧的表结构)是可以的,但就是有点棘手。您需要使用DUL导出相关的数据字典表,然后加载这些表到一个健康的数据库,一定要使用与SYS或(系统)不同的用户。加载损坏数据库的数据字典表到健康数据库字典可能也会破坏健康的数据库。
示例从损坏的数据库检索pl/sql packages / procedures /functions的详情:
1)按照在“使用DUL”一节中的步骤解释并导出数据字典表“source$”
2)创建一个新的用户登录到一个健康数据库,并指定所需的默认和临时表空间。
3)将连接,资源, imp_full_database授权给新用户。
4)导入/加载表“source$”到新创建的模式:
例如:imp80 userid=newuser/passw file=d:\dul\scott_emp.dmp
log=d:\dul\impemp.txt full=y
5)现在,您可以从表查询以在损坏的数据库中重建pl/sql packages / procedures /functions。在WebIv可以找到产生这样的PL / SQL创建脚本。
相同的步骤可以用于重建索引,约束,和存储参数,或者为相应的用户重新授权。请注意,你总是需要使用某种类型的脚本,可以重建对象并包括损坏的数据库版本的所有功能。例如:当损坏的数据库是7.3.4版本,你有几个位图索引,如果你会使用支持7.3.2版本或之前的脚本,那么你将无法成功重建位图索引!
4. 当段头块被损坏时,如何导出数据
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ~~~~~~~~~~~~~~
当DUL不能以正常方式检索数据块信息,它可以扫描数据库来创建其自己的段/区段地图。要从数据文件导出数据,扫描数据库的过程是必要的。
(为了说明这个例子,我根据段头块复制一个空块)
1)创建一个适当的“init.dul”(见2.1)和“control.dul”(见2.2)的文件。
2)导出表。这将失败,并指出段头块有损坏:
DUL> unload table scott.emp;
. unloading table EMP
DUL: Warning: Block is never used, block type is zero
DUL: Error: While checking tablespace 6 file 10 block 2
DUL: Error: While processing block ts#=6, file#=10, block#=2
DUL: Error: Could not read/parse segment header
0 rows unloaded
3)运行扫描数据库命令:
DUL> scan database;
tablespace 0, data file 1: 10239 blocks scanned
tablespace 6, data file 10: 2559 blocks scanned
4)向DUL说明它应该使用自己的生成的区段地图,而不是段头信息。
DUL> alter session set use_scanned_extent_map = true;
Parameter altered
Session altered.
DUL> unload table scott.emp;
. unloading table EMP 14 rows unloaded
5. 当数据文件头块损坏时,如何导出数据
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ~~~~~~~~~~~~~~~
在你打开数据库时,数据文件头块的损坏总是会列出。这不像一个头段块的损坏(见第4点),其中的数据库可以成功打开,且当你进行表查询时,损坏会列出。DUL从这种情况中恢复没有问题,尽管有其他恢复这种情况的方法,如为数据文件头块打补丁。
你将收到如下错误:
ORACLE instance started.
Total System Global Area 11739136 bytes
Fixed Size 49152 bytes
Variable Size 7421952 bytes
Database Buffers 4194304 bytes
Redo Buffers 73728 bytes
Database mounted.
ORA-01122: database file 10 failed verification check
ORA-01110: data file 10: ‘D:\DATA\TRGT\DATAFILES\JUR1TRGT.DBF’
ORA-01251: Unknown File Header Version read for file number 10
6.如何卸载数据,而无需系统表空间
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
如果数据文件不能用于系统表空间,导出仍可继续,但对象信息无法从数据字典表USER $,OBJ $,$ TAB和COL $检索。所以所有者名称,表名和列名不会被加载到DUL字典。识别表会是一项艰巨的任务,且这里需要对RDBMS内部有很好的了解。
首先,你需要对你的应用和它的表有很好的了解。
列类型可以有DUL猜测,但表和列名都将丢失。
任何同一个数据库旧的系统表空间(可能是几周前的)可以是很大的帮助!
1)如上述的步骤1和2,创建 “init.dul”文件和“control.dul”文件。在这种情况下,控制文件将包含所有你想要恢复的数据文件,但不需要系统表空间的信息。
2)然后你调用DUL并输入以下命令:
DUL> scan database;
data file 6 1280 blocks scanned
这将创建区段和段地图。也许DUL命令解释程序也将被终止。
3)重新调用DUL命令解释器并执行以下操作:
Data UnLoader: Release 8.0.5.3.0 – Internal Use Only – on Tue Aug 03 13:33:
Copyright (c) 1994/1999 Oracle Corporation, The Netherlands. All rights res
Loaded 4 segments
Loaded 2 extents
Extent map sorted
DUL> alter session set use_scanned_extent_map = true;
DUL> scan tables; (or scan extents;)
Scanning tables with segment header
Oid 1078 fno 6 bno 2 table number 0
UNLOAD TABLE T_O1078 ( C1 NUMBER, C2 UNKNOWN, C3 UNKNOWN )
STORAGE ( TABNO 0 EXTENTS( FILE 6 BLOCK 2));
Colno Seen MaxIntSz Null% C75% C100 Num% NiNu% Dat% Rid%
1 4 2 0% 0% 0% 100% 100% 0% 0%
2 4 10 0% 100% 100% 100% 0% 0% 0%
3 4 8 0% 100% 100% 100% 0% 0% 50%
“10” “ACCOUNTING” “NEW YORK”
“20” “RESEARCH” “DALLAS”
“30” “SALES” “CHICAGO”
“40” “OPERATIONS” “BOSTON”
Oid 1080 fno 6 bno 12 table number 0
UNLOAD TABLE T_O1080 ( C1 NUMBER, C2 UNKNOWN, C3 UNKNOWN, C4 NUMBER,
C5 DATE, C6 NUMBER, C7 NUMBER, C8 NUMBER )
STORAGE ( TABNO 0 EXTENTS( FILE 6 BLOCK 12));
Colno Seen MaxIntSz Null% C75% C100 Num% NiNu% Dat% Rid%
1 14 3 0% 0% 0% 100% 100% 0% 0%
2 14 6 0% 100% 100% 100% 0% 0% 21%
3 14 9 0% 100% 100% 100% 0% 0% 0%
4 14 3 7% 0% 0% 100% 100% 0% 0%
5 14 7 0% 0% 0% 0% 0% 100% 0%
6 14 3 0% 0% 0% 100% 100% 0% 0%
7 14 2 71% 0% 0% 100% 100% 0% 0%
8 14 2 0% 0% 0% 100% 100% 0% 0%
“7369” “SMITH” “CLERK” “7902” “17-DEC-1980 AD 00:00:00″ “800” “” “20”
“7499” “ALLEN” “SALESMAN” “7698” “20-FEB-1981 AD 00:00:00″ “1600” “300” “30”
“7521” “WARD” “SALESMAN” “7698” “22-FEB-1981 AD 00:00:00″ “1250” “500” “30”
“7566” “JONES” “MANAGER” “7839” “02-APR-1981 AD 00:00:00″ “2975” “” “20”
“7654” “MARTIN” “SALESMAN” “7698” “28-SEP-1981 AD 00:00:00″ “1250” “1400” “30”
Note : it might be best that you redirect the output to a logfile since
commands like the “scan tables” can produce a lot of output.
On Windows NT you can do the following command :
C:\> dul8 > c:\temp\scan_tables.txt
scan tables;
exit;
4)从步骤3的输出中找到丢失的表;如果你仔细看上面的输出会发现,unload语法已经给出,但表的名称将是格式T_0 ,列名称将是格式的C ;数据类型不会精确匹配之前的数据类型。
特别查找像“Oid 1078 fno 6 bno 2 table number 0”的字符串,其中:
oid = object id, will be used to unload the object 对象id,会被用于导出对象
fno = (data)file number (数据)文件号
bno = block number 块号
5)使用“unload table”命令导出找出的表:
DUL> unload table dept (deptno number(2), dname varchar2(14),
loc varchar2(13)) storage (OBJNO 1078)
Unloading extent(s) of table DEPT 4 rows.
评论:
DUL盘头副本
盘头副本
盘头副本
最近有ASM磁盘头的额外副本。通过使用kfed与修复选项,此副本可以用来修复真正的头。
位置
此副本被存储为PST的最后一个块。这意味着它在分配单元1的最后一个块(原来是au 0的块0)。分配单位的默认大小为为1M,元数据块的默认大小为4K,这表示每个au中有256块。所以,通常副本在au1 block 254(ASM从零计数,原始的在分配单元0块0)
kfed修复
确定唯一的问题是与丢失/损坏的磁盘头后,该修复程序很简单,只要:
$ kfed repair
如果su大小为非标准的,以上会失败,显示如下:
KFED-00320: Invalid block num1 = [3] , num2 = [1] , error = [type_kfbh]
但这是预料之中的,且没有任何损害。你只需要指定正确的au大小。例如4MB AU的命令是:
$ kfed repair ausz=4194304
DUL
DUL将检查/使用头复制(总是?或者只在主头损坏的情况下?)如果头损坏,但副本是好的,警告使用kfed?
参考
Bug 5061821 OS工具可以摧毁ASM磁盘头fixed 11.2.0.1,11.1.0.7,10.2.0.5和更高。
注意417687.1在现有的一个磁盘头损坏后创建一个新的ASM磁盘头
rdbms/src/client/tools/kfed/kfed.c
DUL导出扫描的lob
我们的想法是直接从LOB段导出LOB。
我们需要弄清楚:
1. 它是CLOB还是BLOB
2. 对于CLOB,它的字符集,单字节或UCS16,字节大小
3. 块大小,在头中的lob page#是一个fat page number
4. 缺失页应当被发出为全零
5. 大小未知,只需要剥离trailing zeroes(但对于字节大小)?
实施的变更:
1.添加LOB段ID来扫描lob页面信息,因为大多数属性适用于段。即扫描的lob页缓存的布局是:segid,lobid,fatpageno(chunk#),version wrap, vsn base, ts#, file#, block#
要做的事:
1.导出所有LOB的命令。一个LOB段提供命令中所有的常用属性。
2.从LOB段指定lobid,可选的大小,和可选的DBA列表中导出单个lob的命令
3.分析生成导出LOB段命令的命令
4.分析生成从段中导出每个LOB命令的命令
需要考虑的事项:
1. 更改 file#, block# 为单个dba?pro no calculations, contra more difficult to read?
我正与客户在处理一个数据打捞作业。从DUL网站下载的DUL工具不能正常工作!
dul4x86-linux.tar.gz给出错误:version ‘GLIBC_2.11’ not found
dul4i386-linux.as3.tar.gz给出错误:You need a more recent DUL version for this os.你需要一个较新的版本DUL这个操作系统。
客户端Linux版本:2.6.32-400.33.2.el5uek
请帮忙!!!
Linux有两个版本,这是第二个,被正常启动的。由于内建复制的保护,您必须确保从Bernard的网站上下载最新的版本。如果你确实有最新的下载,那么只有Bernard可以重新编译并重新分配一个新的可执行版本。 DUL大约每45天失效。
我们处在关键时刻,需要DUL从一个production down降数据库中提取数据。
- 数据库在NOARCHIVELOG模式/ Windows 64位平台。
- 由于go life,没有可用的数据库备份
- 数据库较小,但非常重要。
- 从早晨开始有介质故障损坏了除真正客户数据的数据文件之外的所有数据库的数据文件。
- 根据每db验证工具输出,系统表空间100%损坏。
- 任何地方都没有系统表空间的备份,甚至测试系统是作为新的数据库创建的,因此对象ID,rfile号是不一样的。
我们尝试了以下内容:
1. 使用系统数据文件从生产中导出数据(由于系统数据文件被破坏,无法bootstrap)
2. 使用系统数据文件从TEST中导出数据(成功bootstrap,但无法导出,因为不匹配rfile#,TS#,和对象ID ..预想到的结果,但值得一试)
3. 仅使用实际数据的数据文件导出数据,成功生成scaned_tables,并且我们已向客户请求提供表的列表来map,但我不确定他们能否提供清晰信息。
感谢提供任何建议,类似于:
- 有没有什么办法来修复损坏的系统表空间的数据文件,并用它进行数据导出。
- 或者,有没有办法从TEST使用系统数据文件(不同的数据库作为新安装),其中rfile#, ts#,和对象id的错配。
