ORACLE RAC中最主要存在2种clusterware集群件心跳 & RAC超时机制分析:
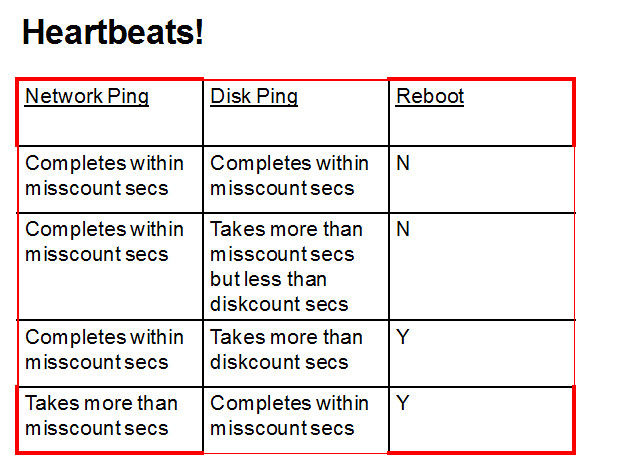
1、Network Heartbeat 网络心跳 每秒发生一次; 10.2.0.4以后网络心跳超时misscount为60s,;11.2以后网络心跳超时misscount为30s。
2、Disk Heartbeat 磁盘心跳 每秒发生一次; 10.2.0.4以后 磁盘心跳超时DiskTimeout为200s。
注意不管是磁盘心跳还是网络心跳都依赖于cssd.bin进程来实施这些操作,在真实世界中任何造成cssd.bin这个普通用户进程无法正常工作的原因均可能造成上述2种心跳超时, 原因包括但不局限于 CPU无法分配足够的时间片、内存不足、SWAP、网络问题、Votedisk IO问题、本次磁盘IO问题等等(askmac.cn)。
此外在使用ASM的情况下,DB作为ASM实例的Client客户; ASM实例会对DB实例的ASMB等进程进行监控, 以保证DB与ASM之间通信正常。 若DB的ASMB进程长期无响应(大约为200s)则ASM实例将考虑KILL DB的ASMB进程,由于ASMB是关键后台进程所以将导致DB实例重启。
也存在其他可能的情况,例如由于ASMB 被某些latch block, 会阻塞其他进程,导致PMON进行强制清理。
综上所述不管是Clusterware的 cssd.bin进程还是ASMB进程,他们都是OS上的普通用户进程,OS本身出现的问题、超时、延迟均可能造成它们无法正常工作导致。建议在确认对造成OS长时间的网络、IO延时的维护操作,考虑先停止节点上的Clusterware后再实施。
另可以考虑修改misscount、Disktimeout等 心跳超时机制为更大值,但修改这些值并不能保证就可以不触发Node Evication。
关于RAC /CRS对于本地盘的问题,详见如下的SR回复:
Does RAC/CRS monitor Local Disk IO ?
Oracle software use local ORACLE_HOME / GRID_HOME library files for main process operations.
There are some socket files under /tmp or /var/tmp needed for CRS communication.
Also, the init processes are all depending on the /etc directory to spawn the child processes.
Again, this is a complicated design for a cluster software which mainly rely on the OS stability including local file system.
Any changes to storage / OS are all recommended to stop CRS services since those are out of our release Q/A tests.
由于10.2的环境已经超出我们开发的支持服务期限,建议考虑升级到11.2.0.3来获得更全面的技术支持。