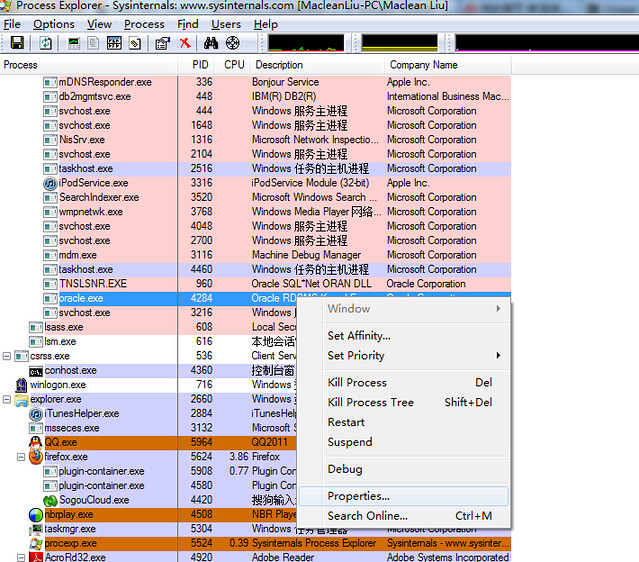
以下SQL脚本可以用于列出数据库最近1分钟的性能度量信息(performance metric):
set linesize 80 pagesize 1400
SELECT /*+ ORDERED USE_MERGE(m) */
TO_CHAR(FROM_TZ(CAST(m.end_time AS TIMESTAMP),
TO_CHAR(systimestamp, 'tzr')) AT TIME ZONE sessiontimezone,
'YYYY-MM-DD HH24:MI:SS'),
SUM(CASE
WHEN a.internal_metric_name = 'transactions_ps' THEN
m.value
ELSE
0
END) transactions_ps,
SUM(CASE
WHEN a.internal_metric_name = 'physreads_ps' THEN
m.value
ELSE
0
END) physreads_ps,
SUM(CASE
WHEN a.internal_metric_name = 'physreads_pt' THEN
m.value
ELSE
0
END) physreads_pt,
SUM(CASE
WHEN a.internal_metric_name = 'physwrites_ps' THEN
m.value
ELSE
0
END) physwrites_ps,
SUM(CASE
WHEN a.internal_metric_name = 'physwrites_pt' THEN
m.value
ELSE
0
END) physwrites_pt,
SUM(CASE
WHEN a.internal_metric_name = 'physreadsdir_ps' THEN
m.value
ELSE
0
END) physreadsdir_ps,
SUM(CASE
WHEN a.internal_metric_name = 'physreadsdir_pt' THEN
m.value
ELSE
0
END) physreadsdir_pt,
SUM(CASE
WHEN a.internal_metric_name = 'physwritesdir_ps' THEN
m.value
ELSE
0
END) physwritesdir_ps,
SUM(CASE
WHEN a.internal_metric_name = 'physwritesdir_pt' THEN
m.value
ELSE
0
END) physwritesdir_pt,
SUM(CASE
WHEN a.internal_metric_name = 'physreadslob_ps' THEN
m.value
ELSE
0
END) physreadslob_ps,
SUM(CASE
WHEN a.internal_metric_name = 'physreadslob_pt' THEN
m.value
ELSE
0
END) physreadslob_pt,
SUM(CASE
WHEN a.internal_metric_name = 'physwriteslob_ps' THEN
m.value
ELSE
0
END) physwriteslob_ps,
SUM(CASE
WHEN a.internal_metric_name = 'physwriteslob_pt' THEN
m.value
ELSE
0
END) physwriteslob_pt,
SUM(CASE
WHEN a.internal_metric_name = 'redosize_ps' THEN
m.value
ELSE
0
END) redosize_ps,
SUM(CASE
WHEN a.internal_metric_name = 'logons_ps' THEN
m.value
ELSE
0
END) logons_ps,
SUM(CASE
WHEN a.internal_metric_name = 'logons_pt' THEN
m.value
ELSE
0
END) logons_pt,
SUM(CASE
WHEN a.internal_metric_name = 'opncurs_ps' THEN
m.value
ELSE
0
END) opncurs_ps,
SUM(CASE
WHEN a.internal_metric_name = 'opncurs_pt' THEN
m.value
ELSE
0
END) opncurs_pt,
SUM(CASE
WHEN a.internal_metric_name = 'commits_ps' THEN
m.value
ELSE
0
END) commits_ps,
SUM(CASE
WHEN a.internal_metric_name = 'commits_pt' THEN
m.value
ELSE
0
END) commits_pt,
SUM(CASE
WHEN a.internal_metric_name = 'rollbacks_ps' THEN
m.value
ELSE
0
END) rollbacks_ps,
SUM(CASE
WHEN a.internal_metric_name = 'rollbacks_pt' THEN
m.value
ELSE
0
END) rollbacks_pt,
SUM(CASE
WHEN a.internal_metric_name = 'usercalls_ps' THEN
m.value
ELSE
0
END) usercalls_ps,
SUM(CASE
WHEN a.internal_metric_name = 'usercalls_pt' THEN
m.value
ELSE
0
END) usercalls_pt,
SUM(CASE
WHEN a.internal_metric_name = 'recurscalls_ps' THEN
m.value
ELSE
0
END) recurscalls_ps,
SUM(CASE
WHEN a.internal_metric_name = 'recurscalls_pt' THEN
m.value
ELSE
0
END) recurscalls_pt,
SUM(CASE
WHEN a.internal_metric_name = 'logreads_ps' THEN
m.value
ELSE
0
END) logreads_ps,
SUM(CASE
WHEN a.internal_metric_name = 'logreads_pt' THEN
m.value
ELSE
0
END) logreads_pt,
SUM(CASE
WHEN a.internal_metric_name = 'dbwrcheckpoints_ps' THEN
m.value
ELSE
0
END) dbwrcheckpoints_ps,
SUM(CASE
WHEN a.internal_metric_name = 'bgcheckpoints_ps' THEN
m.value
ELSE
0
END) bgcheckpoints_ps,
SUM(CASE
WHEN a.internal_metric_name = 'redowrites_ps' THEN
m.value
ELSE
0
END) redowrites_ps,
SUM(CASE
WHEN a.internal_metric_name = 'redowrites_pt' THEN
m.value
ELSE
0
END) redowrites_pt,
SUM(CASE
WHEN a.internal_metric_name = 'tabscanslong_ps' THEN
m.value
ELSE
0
END) tabscanslong_ps,
SUM(CASE
WHEN a.internal_metric_name = 'tabscanslong_pt' THEN
m.value
ELSE
0
END) tabscanslong_pt,
SUM(CASE
WHEN a.internal_metric_name = 'tabscanstotal_ps' THEN
m.value
ELSE
0
END) tabscanstotal_ps,
SUM(CASE
WHEN a.internal_metric_name = 'tabscanstotal_pt' THEN
m.value
ELSE
0
END) tabscanstotal_pt,
SUM(CASE
WHEN a.internal_metric_name = 'indxscansfull_pt' THEN
m.value
ELSE
0
END) indxscansfull_pt,
SUM(CASE
WHEN a.internal_metric_name = 'indxscansfull_ps' THEN
m.value
ELSE
0
END) indxscansfull_ps,
SUM(CASE
WHEN a.internal_metric_name = 'indxscanstotal_ps' THEN
m.value
ELSE
0
END) indxscanstotal_ps,
SUM(CASE
WHEN a.internal_metric_name = 'indxscanstotal_pt' THEN
m.value
ELSE
0
END) indxscanstotal_pt,
SUM(CASE
WHEN a.internal_metric_name = 'parses_ps' THEN
m.value
ELSE
0
END) parses_ps,
SUM(CASE
WHEN a.internal_metric_name = 'parses_pt' THEN
m.value
ELSE
0
END) parses_pt,
SUM(CASE
WHEN a.internal_metric_name = 'hardparses_ps' THEN
m.value
ELSE
0
END) hardparses_ps,
SUM(CASE
WHEN a.internal_metric_name = 'hardparses_pt' THEN
m.value
ELSE
0
END) hardparses_pt,
SUM(CASE
WHEN a.internal_metric_name = 'failedparses_ps' THEN
m.value
ELSE
0
END) failedparses_ps,
SUM(CASE
WHEN a.internal_metric_name = 'failedparses_pt' THEN
m.value
ELSE
0
END) failedparses_pt,
SUM(CASE
WHEN a.internal_metric_name = 'executions_ps' THEN
m.value
ELSE
0
END) executions_ps,
SUM(CASE
WHEN a.internal_metric_name = 'sortsdisk_ps' THEN
m.value
ELSE
0
END) sortsdisk_ps,
SUM(CASE
WHEN a.internal_metric_name = 'sortsdisk_pt' THEN
m.value
ELSE
0
END) sortsdisk_pt,
SUM(CASE
WHEN a.internal_metric_name = 'rows_psort' THEN
m.value
ELSE
0
END) rows_psort,
SUM(CASE
WHEN a.internal_metric_name = 'executeswoparse_pct' THEN
m.value
ELSE
0
END) executeswoparse_pct,
SUM(CASE
WHEN a.internal_metric_name = 'softparse_pct' THEN
m.value
ELSE
0
END) softparse_pct,
SUM(CASE
WHEN a.internal_metric_name = 'usercall_pct' THEN
m.value
ELSE
0
END) usercall_pct,
SUM(CASE
WHEN a.internal_metric_name = 'networkbytes_ps' THEN
m.value
ELSE
0
END) networkbytes_ps,
SUM(CASE
WHEN a.internal_metric_name = 'enqtimeouts_ps' THEN
m.value
ELSE
0
END) enqtimeouts_ps,
SUM(CASE
WHEN a.internal_metric_name = 'enqtimeouts_pt' THEN
m.value
ELSE
0
END) enqtimeouts_pt,
SUM(CASE
WHEN a.internal_metric_name = 'enqwaits_ps' THEN
m.value
ELSE
0
END) enqwaits_ps,
SUM(CASE
WHEN a.internal_metric_name = 'enqwaits_pt' THEN
m.value
ELSE
0
END) enqwaits_pt,
SUM(CASE
WHEN a.internal_metric_name = 'enqdeadlocks_ps' THEN
m.value
ELSE
0
END) enqdeadlocks_ps,
SUM(CASE
WHEN a.internal_metric_name = 'enqdeadlocks_pt' THEN
m.value
ELSE
0
END) enqdeadlocks_pt,
SUM(CASE
WHEN a.internal_metric_name = 'enqreqs_ps' THEN
m.value
ELSE
0
END) enqreqs_ps,
SUM(CASE
WHEN a.internal_metric_name = 'enqreqs_pt' THEN
m.value
ELSE
0
END) enqreqs_pt,
SUM(CASE
WHEN a.internal_metric_name = 'dbblkgets_ps' THEN
m.value
ELSE
0
END) dbblkgets_ps,
SUM(CASE
WHEN a.internal_metric_name = 'dbblkgets_pt' THEN
m.value
ELSE
0
END) dbblkgets_pt,
SUM(CASE
WHEN a.internal_metric_name = 'consistentreadgets_ps' THEN
m.value
ELSE
0
END) consistentreadgets_ps,
SUM(CASE
WHEN a.internal_metric_name = 'consistentreadgets_pt' THEN
m.value
ELSE
0
END) consistentreadgets_pt,
SUM(CASE
WHEN a.internal_metric_name = 'dbblkchanges_ps' THEN
m.value
ELSE
0
END) dbblkchanges_ps,
SUM(CASE
WHEN a.internal_metric_name = 'dbblkchanges_pt' THEN
m.value
ELSE
0
END) dbblkchanges_pt,
SUM(CASE
WHEN a.internal_metric_name = 'consistentreadchanges_ps' THEN
m.value
ELSE
0
END) consistentreadchanges_ps,
SUM(CASE
WHEN a.internal_metric_name = 'consistentreadchanges_pt' THEN
m.value
ELSE
0
END) consistentreadchanges_pt,
SUM(CASE
WHEN a.internal_metric_name = 'crblks_ps' THEN
m.value
ELSE
0
END) crblks_ps,
SUM(CASE
WHEN a.internal_metric_name = 'crblks_pt' THEN
m.value
ELSE
0
END) crblks_pt,
SUM(CASE
WHEN a.internal_metric_name = 'crundorecs_pt' THEN
m.value
ELSE
0
END) crundorecs_pt,
SUM(CASE
WHEN a.internal_metric_name = 'userrollbackundorec_ps' THEN
m.value
ELSE
0
END) userrollbackundorec_ps,
SUM(CASE
WHEN a.internal_metric_name = 'userrollbackundorec_pt' THEN
m.value
ELSE
0
END) userrollbackundorec_pt,
SUM(CASE
WHEN a.internal_metric_name = 'leafnodesplits_ps' THEN
m.value
ELSE
0
END) leafnodesplits_ps,
SUM(CASE
WHEN a.internal_metric_name = 'leafnodesplits_pt' THEN
m.value
ELSE
0
END) leafnodesplits_pt,
SUM(CASE
WHEN a.internal_metric_name = 'branchnodesplits_ps' THEN
m.value
ELSE
0
END) branchnodesplits_ps,
SUM(CASE
WHEN a.internal_metric_name = 'branchnodesplits_pt' THEN
m.value
ELSE
0
END) branchnodesplits_pt,
SUM(CASE
WHEN a.internal_metric_name = 'redosize_pt' THEN
m.value
ELSE
0
END) redosize_pt,
SUM(CASE
WHEN a.internal_metric_name = 'crundorecs_ps' THEN
m.value
ELSE
0
END) crundorecs_ps,
SUM(CASE
WHEN a.internal_metric_name = 'dbtime_ps' THEN
m.value
ELSE
0
END) dbtime_ps,
SUM(CASE
WHEN a.internal_metric_name = 'avg_active_sessions' THEN
m.value
ELSE
0
END) avg_active_sessions,
SUM(CASE
WHEN a.internal_metric_name = 'avg_sync_singleblk_read_latency' THEN
m.value
ELSE
0
END) avg_block_read_latency,
SUM(CASE
WHEN a.internal_metric_name = 'iombs_ps' THEN
m.value
ELSE
0
END) iombs_ps,
SUM(CASE
WHEN a.internal_metric_name = 'iorequests_ps' THEN
m.value
ELSE
0
END) iorequests_ps
FROM v$alert_types a, v$threshold_types t, v$sysmetric m
WHERE a.internal_metric_category = 'instance_throughput'
AND a.reason_id = t.alert_reason_id
AND t.metrics_id = m.metric_id
AND m.group_id = 2
AND m.end_time <= SYSDATE
GROUP BY m.end_time
ORDER BY m.end_time ASC
/
使用方法:
SQL> @metric
TO_CHAR(FROM_TZ(CAS TRANSACTIONS_PS PHYSREADS_PS PHYSREADS_PT PHYSWRITES_PS
------------------- --------------- ------------ ------------ -------------
PHYSWRITES_PT PHYSREADSDIR_PS PHYSREADSDIR_PT PHYSWRITESDIR_PS PHYSWRITESDIR_PT
------------- --------------- --------------- ---------------- ----------------
PHYSREADSLOB_PS PHYSREADSLOB_PT PHYSWRITESLOB_PS PHYSWRITESLOB_PT REDOSIZE_PS
--------------- --------------- ---------------- ---------------- -----------
LOGONS_PS LOGONS_PT OPNCURS_PS OPNCURS_PT COMMITS_PS COMMITS_PT ROLLBACKS_PS
---------- ---------- ---------- ---------- ---------- ---------- ------------
ROLLBACKS_PT USERCALLS_PS USERCALLS_PT RECURSCALLS_PS RECURSCALLS_PT LOGREADS_PS
------------ ------------ ------------ -------------- -------------- -----------
LOGREADS_PT DBWRCHECKPOINTS_PS BGCHECKPOINTS_PS REDOWRITES_PS REDOWRITES_PT
----------- ------------------ ---------------- ------------- -------------
TABSCANSLONG_PS TABSCANSLONG_PT TABSCANSTOTAL_PS TABSCANSTOTAL_PT
--------------- --------------- ---------------- ----------------
INDXSCANSFULL_PT INDXSCANSFULL_PS INDXSCANSTOTAL_PS INDXSCANSTOTAL_PT PARSES_PS
---------------- ---------------- ----------------- ----------------- ----------
PARSES_PT HARDPARSES_PS HARDPARSES_PT FAILEDPARSES_PS FAILEDPARSES_PT
---------- ------------- ------------- --------------- ---------------
EXECUTIONS_PS SORTSDISK_PS SORTSDISK_PT ROWS_PSORT EXECUTESWOPARSE_PCT
------------- ------------ ------------ ---------- -------------------
SOFTPARSE_PCT USERCALL_PCT NETWORKBYTES_PS ENQTIMEOUTS_PS ENQTIMEOUTS_PT
------------- ------------ --------------- -------------- --------------
ENQWAITS_PS ENQWAITS_PT ENQDEADLOCKS_PS ENQDEADLOCKS_PT ENQREQS_PS ENQREQS_PT
----------- ----------- --------------- --------------- ---------- ----------
DBBLKGETS_PS DBBLKGETS_PT CONSISTENTREADGETS_PS CONSISTENTREADGETS_PT
------------ ------------ --------------------- ---------------------
DBBLKCHANGES_PS DBBLKCHANGES_PT CONSISTENTREADCHANGES_PS
--------------- --------------- ------------------------
CONSISTENTREADCHANGES_PT CRBLKS_PS CRBLKS_PT CRUNDORECS_PT
------------------------ ---------- ---------- -------------
USERROLLBACKUNDOREC_PS USERROLLBACKUNDOREC_PT LEAFNODESPLITS_PS
---------------------- ---------------------- -----------------
LEAFNODESPLITS_PT BRANCHNODESPLITS_PS BRANCHNODESPLITS_PT REDOSIZE_PT
----------------- ------------------- ------------------- -----------
CRUNDORECS_PS DBTIME_PS AVG_ACTIVE_SESSIONS AVG_BLOCK_READ_LATENCY IOMBS_PS
------------- ---------- ------------------- ---------------------- ----------
IOREQUESTS_PS
-------------
2011-10-27 20:02:23 .349533955 2.69640479 7.71428571 .116511318
.333333333 .199733688 .571428571 .116511318 .333333333
.116511318 .333333333 .116511318 .333333333 16212.0506
.016644474 .047619048 19.0745672 54.5714286 .349533955 100 0
0 .349533955 1 81.1917443 232.285714 130.54261
373.47619 0 0 .515978695 1.47619048
0 0 .216378162 .619047619
0 0 19.4573901 55.6666667 4.92676431
14.0952381 1.89747004 5.42857143 0 0
20.4560586 0 0 22.026087 75.9153784
61.4864865 .42865891 995.838881 0 0
0 0 0 0 8.9713715 25.6666667
44.9400799 128.571429 85.60253 244.904762
45.1398136 129.142857 .249667111
.714285714 0 0 0
0 0 .199733688
.571428571 0 0 46381.9048
0 .023586884 .000235869 .032960413 3.09587217
195.489348
PS Per Second
PT Per Transaction