
本文永久地址: https://www.askmac.cn/archives/实践oracle-性能调优-从诊断到解决.html
前言
- 本资料中,包含oracle数据库的系统中产生性能问题时,将对调查原因到完成调优为止,进行指导。
- 本资料面向对数据库具有基相关知识的人士。
- 因此,发生性能问题时的对策,仅仅讲解确认数据库是否有性能问题的方法,最多讲解处理性能问题的1个方法,但这也不是绝对的
- 请作为系统发生性能问题时的参考资料来灵活使用
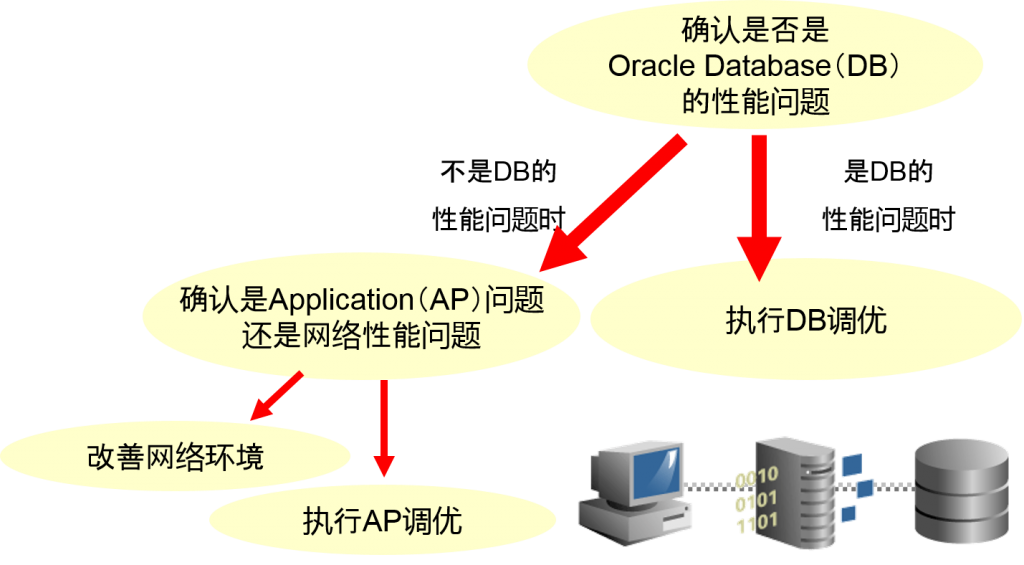
发生了系统性能问题

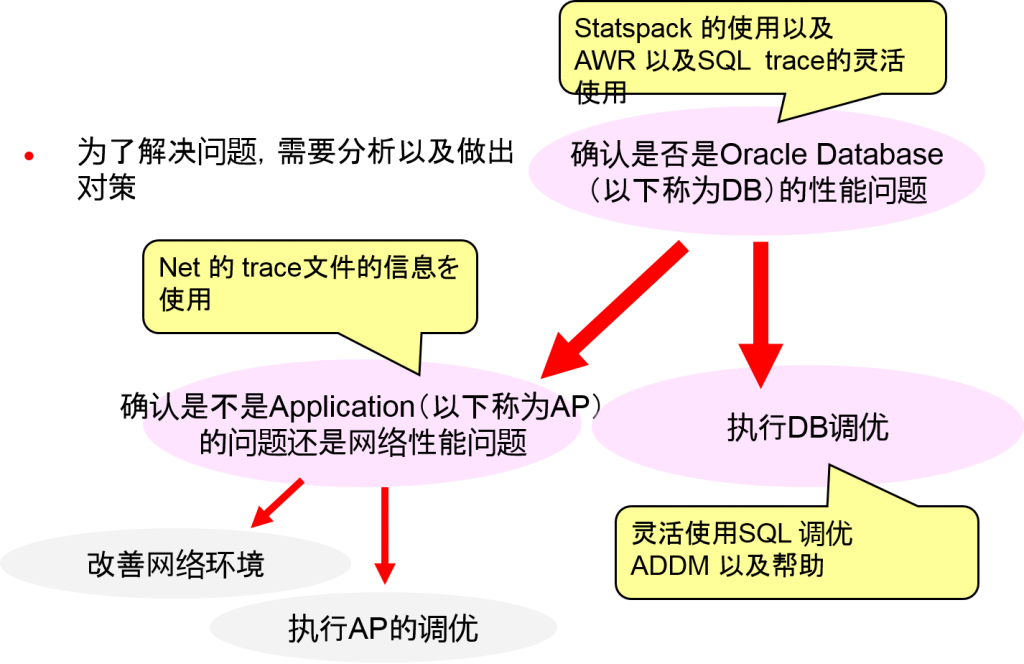
解决的顺序
为了解决问题,需要处理与考虑方法
- 指定出现性能问题的地方
- 执行调优
确认DB的性能问题
获得DB内部的统计信息,确认其是否发生了性能问题
DB内部的统计信息是指
性能统计信息(ex. 资源使用情况以及发生待机的信息)
执行各SQL时的详细信息
<方法>
Statspack(8i~)
AWR报告(10g~)
※Enterprise Edition中需要Diagnostic Pack选项
SQL 追踪(主要在测试环境中使用)
<参考>其他的推荐事先获得的信息
OS统计信息
-CPU统计信息
-磁盘统计信息
-内存统计信息
-网络统计信息
-运行进程统计信息
OS中的统计信息因为含有包含oracle以外的部分的服务器整体的资源信息
所以即使原因可能出在DB中,也可以获得

在分析之前需要了解Statspack是什么
在使用DB内部的统计信息进行分析之前,先需要获得统计信息
理解各个方法的概要
<方法>
Statspack(8i~)
AWR报告(10g~)
※Enterprise Edition中需要Diagnostic Pack选项
SQL追踪(主要在测试环境中使用)
Statspack(Statistics Package)
Statspack 的意思是
从Oracle 8i 安装的oracle标准的性能分析工具
使用Statspack 的话
某段期间内,还可以确认oracle的运行情况
基本的Statspack使用流程
- 安装之后,可以定期获得统计信息
- 发生问题时,会将累积的统计信息生成报告
- 比较现有的报告(必要的话还可以同时比较过去的报告)进行分析
确认Statspack 的的信息,确认在执行SQL时,到底是什么原因导致了性能恶化
Statspack的机制
Statspack是两个不同时点分别作为snapshot来记录,仅仅从差异中输出报告
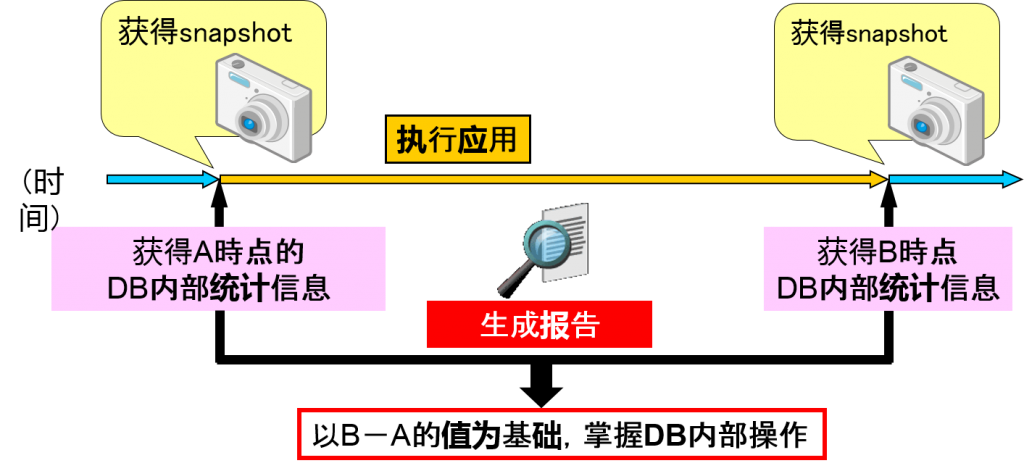
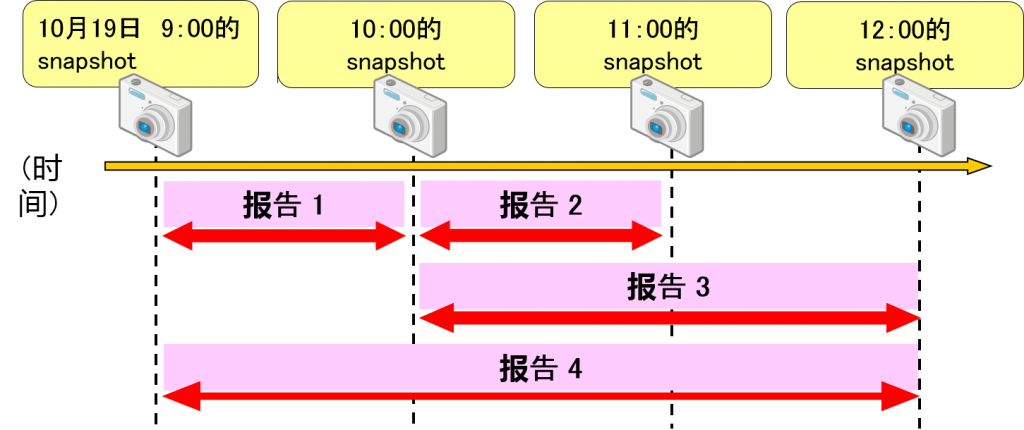
灵活地输出报告
输出报告时,可以指定使用任何snapshot,可以灵活地变更输出范围
<参考>通过Statspack获得的信息(9iR2,10g,11g)
leve水平(获得的信息详细程度)设定参考基准
一般正常运行时默认为Level 5,如果感觉到“最近变得有点慢了”的时候,可以遵循oracle技术支持的意见调整为Level 6 、Level 7、或者Level 10(高负荷)
| Snapshot level | 收集数据 | |||||
| 基本统计信息 | 建议信息 | SQL统计信息 | SQL详细信息 | 段信息 | latch详细信息 | |
| Level 0 | ○ | ○ | ||||
| Level 5 | ○ | ○ | ○ | |||
| Level 6 | ○ | ○ | ○ | ○ | ||
| Level 7 | ○ | ○ | ○ | ○ | ○ | |
| Level 10 | ○ | ○ | ○ | ○ | ○ | ○ |
Statspack 使用顺序
Statspack的使用顺序如下所示
Step1 安装・设定
首次使用Statspack时,可以创建执行用的用户,同时可以设定密码与表空间
Step2 获得snapshot
根据情况不同自动获得snapshot level,或者调整snapshot level
Step3 创建报告
选择开始与终止的snapshot 输入文件名
使用了Statspack的脚本已经在导入了DB的环境中准备好了,只要连接到DB,就可以执行脚本
执行安装脚本
Statspack相关的操作全部都是通过执行用用户(PERFSTAT)来执行的,所以需要创建执行安装脚本的PERFSTAT用户
1.通过SQL*Plus,作为拥有SYSDBA权限的用户来连接DB
2.执行安装脚本(spcreate.sql)
# 以SYSDBA权限连接到SQL*Plus
SQL> connect sqlplus / as sysdba
# 执行安装・脚本
SQL> @$ORACLE_HOME/rdbms/admin/spcreate.sql
设定密码与表空间
设定PERFSTAT 用户的密码、在Statspack中所使用的默认表空间以及临时表空间
1.执行脚本,PERFSTAT用户的密码,默认表空间,临时表空间
# 设定执行用户的密码
在perfstat_password中输入值:<输入password>
# 设定默认表空间
在default_tablespace中输入值:<输入表空间名>
# 设定临时表空间
在temporary_tablespace中输入值:<输入表空间名>
默认表空间推荐多设定300MB的冗余
获得snapshot
用PERFSTAT用户连接到DB,通过snapshot来获得统计信息
1.通过PERDSTAT用户执行statspack.snap
2.必要的话可以通过i_snap_level => 来设定获得信息的详细程度(level)(用户没有指定level时,以默认值的level5来获得)
#获得 snapshot
SQL> execute statspack.snap(I_snap_level => 6);
l记录重复snapshot,通过在某个时间点的snapshot,作为报告来输出,可以获得特定期间内的DB统计信息
报告的创建
1.通过PERDSTAT用户来执行spreport.sql
SQL> @?/rdbms/admin/spreport.sql # 创建报告脚本を执行
・
・
~省略~ Snap
Instance DB Name Snap Id Snap Started Level Comment
———— ————— ———– —————————— ——— —————
orcl1 ORCL 1 17 10月 2008 12:17 5
11 20 10月 2008 09:29 5
・
・
Specify the Begin and End Snapshot Ids
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
在begin_snap中输入值:
输入snapshot ID
指定开始、终止获得统计信息范围的时间点的snapshot ID,输出报告
1.参考Snap Id,输入起始snapshot以及终止snapshot ID
2.输入报告名
Specify the Begin and End Snapshot Ids
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# 输入起始snapshot ID
请在begin_snap中输入值: <输入Snap Id 例:1>
# 输入终止snapshot ID
请在end_snap中输入值: <输入Snap Id 例:11>
#输入 报告名
请在report_name中输入值: <输入报告名>
删除snapshot
获得的性能统计信息只要不明确地删除,无论何时都会被保留,根据不同情况可能会挤压储存区域
因此,请删除不需要的统计信息
1.通过PERFSTAT用户来执行sppurge.sql
2.指定想删除的范围的起始于终止时点,指定snapshot ID
SQL> @?/rdbms/admin/sppurge.sql #执行删除的脚本
Specify the Lo Snap Id and Hi Snap Id range to purge
Statspack 实际的报告输入例
STATSPACK report for
Database DB Id Instance Inst Num Startup Time Release RAC
~~~~~~~~ -------------- ------------ ------------- ----------------------- --------------
1196126054 orcl1 1 17-10月-08 11:40 11.1.0.7.0 YES
Host Name Platform CPUs Cores Sockets Memory (G)
~~~~ ------------------------- ---------------------- ----- ----- --------- ------------ -----------------
jpintl005.jp.ora Linux IA (32-bit) 8 8 2 4.0
Snapshot Snap Id Snap Time Sessions Curs/Sess Comment
~~~~~~~~ ---------- ---------------------------------- ------------- --------- ------------------
Begin Snap: 36 21-10月-08 19:46:15 38 1.0
End Snap: 37 21-10月-08 19:47:51 38 1.0
Elapsed: 1.60 (mins) Av Act Sess: 0.4
・
・
・
・
・
・
SQL ordered by Elapsed time for DB: ORCL Instance: orcl1 Snaps: 36 -37
-> Total DB Time (s): 42
-> Captured SQL accounts for 195.5% of Total DB Time
-> SQL reported below exceeded 1.0% of Total DB Time
Elapsed Elap per CPU Old
Time (s) Executions Exec (s) %Total Time (s) Physical Reads Hash Value
---------- ------------ ---------- ------ ---------- --------------- ----------
40.69 1 40.69 95.9 40.67 0 3417014992
Module: SQL*Plus
declare v_num number; begin for i in 1..10000 loop selec
t c1 into v_num from t1 where c1 = 100; end loop; end;
40.48 10,000 0.00 95.4 40.46 0 2968801179
Module: SQL*Plus
AWR报告是指什么
AWR(自动负载库)
从Oracle 10g开始会自动获得DB内部的统计信息(snapshot)
AWR是使得Statspack进化的功能
- 与Statspack相同,可以经常观察到以低负荷来创建各种报告
- 通过Enterprise Manager(EM),可以变更、查看设定内容
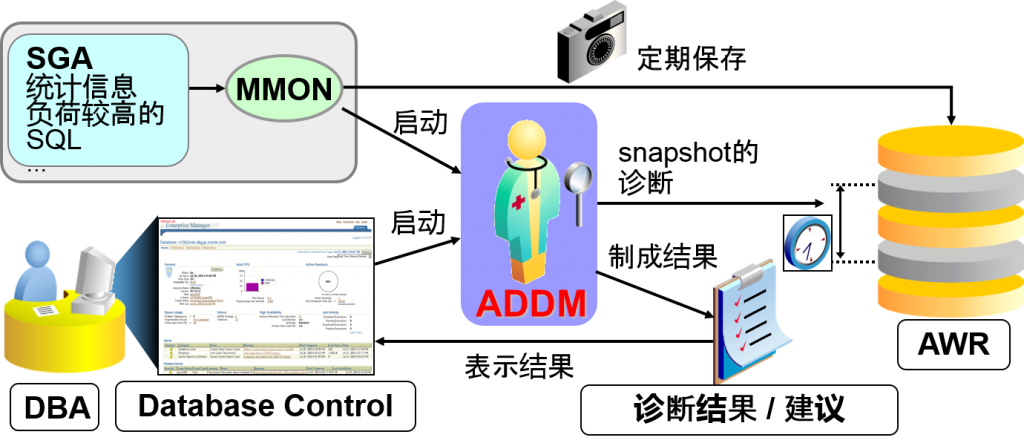
- 可以通过ADDM来自动进行性能减少/诊断
AWR在创建DB时,也会在SYSAUX表空间中创建 -不需要安装
MMON(Memory Monitor)会定期获得SGA的信息
-默认1小时内保存1次snapshot(11g中是8天)
-想查看、变更设定内容的话,需要Oracle EM可以使用
执行自动删除旧数据
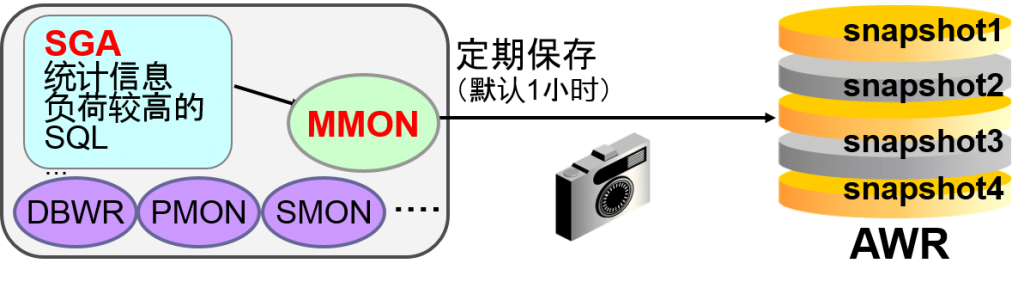
比较Statspack与AWR的报告

Statspack 报告的分析
分析点
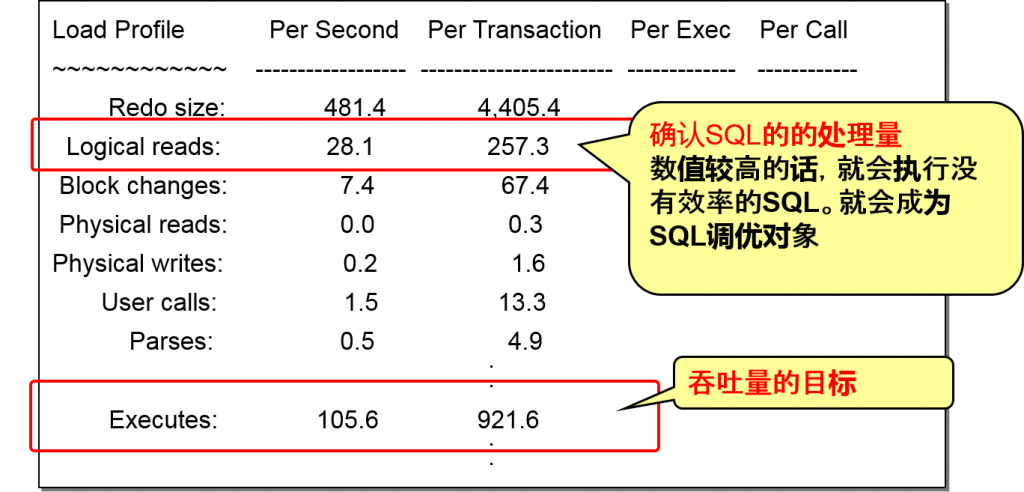
- 吞吐量与负荷(Load Profile)
- 实例效率(Instance Efficiency)
- 待机 项目(Top-5 Timed Events)
- SQL的详细信息(SQL ordered by ~)
特别是在正式环境中使用时,根据业务内容与时间段不同,所收集到的统计信息也会不同,所以我们推荐多多比较多个报告
Load Profile 负荷状況的读取
伴随着磁盘访问,我们需要着眼于是否会有数据的读入、写入,在DB的处理中,找出容易成为瓶颈的物理I/O
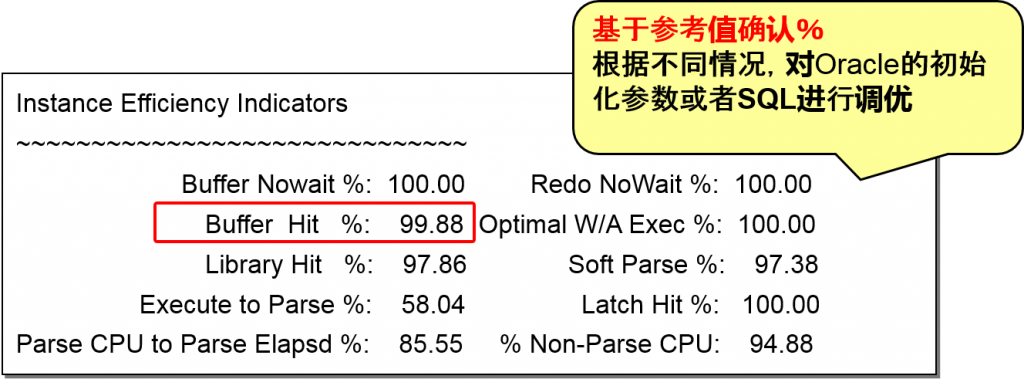
Instance Efficiency 实例效率.
确认DB缓冲区高速缓存命中率,确认实例是否高效运行
越接近100%就越好
参考値大于80%-% Non-Parse CPU
90%以上-Buffer Hit%、Optimal W/A Exec%、Sort Parse%
95%以上-Library Hit%、Redo Nowait%、Buffer Nowait%
100%以上-Latch Hit%
| 参数名 | 説明 |
| Buffer Hit% | 高速缓存中所拥有的需要的数据的比例 |
| Library Hit % | Library cache中所拥有的需要的数据的比例 |
| Soft Parse % | 所有解析中可以重复利用的比例 |
| In-Memory Sort% | Sort在内存中执行的比例 |
| Latch Hit% | 所有latch的命中率 |
| Parse CPU to Parse Elapsed % | 解析CPU时间/ 解析的总计时间 |
| Execute to Parse% | 因为执行SQL而没执行解析的比例 |
| %non-parse CPU | 解析之外所使用的CPU时间的比例 |
| Buffer Nowait% | 高速缓冲区中提出需求时,可以马上应用的比例 |
| Redo Nowait% | 对redo log提出需求时,可以马上应用的比例 |
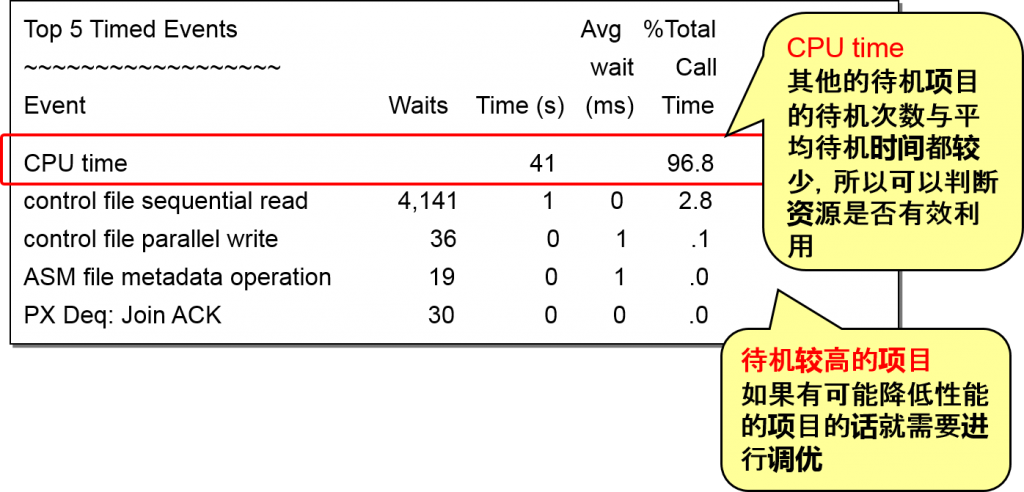
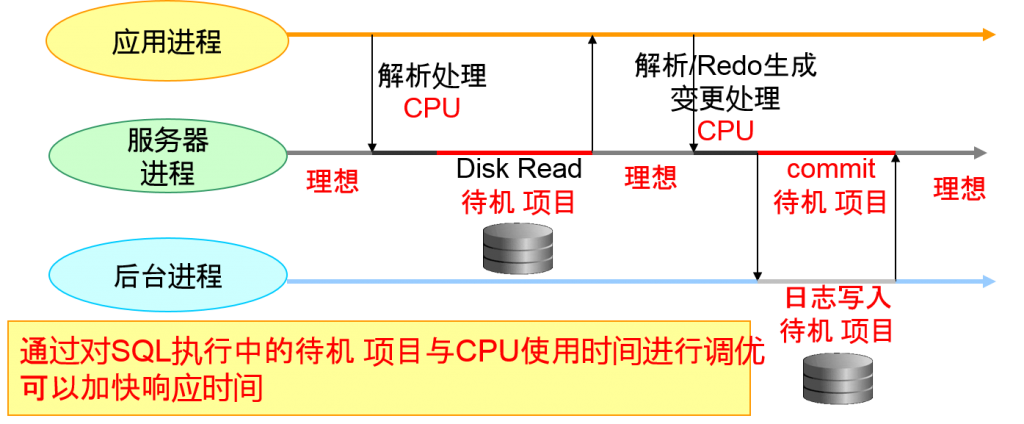
Top-5 Timed Events 待机 项目
检查实例level中待机时间前五的项目,确认监视对象的实例性能是否降低
Waits :项目待机的总次数
Time(s) :项目总计待机时间以及总计CPU时间(秒)
Avg wait(ms) : 项目平均待机时间
% Total Call Time: time for each timed event / total call time Total call time total CPU time + total wait time for non-idle events
等待事件是什么?
- 进程没有使用CPU的时间
- 理想待机 项目(SQL的需求等待)
- 有瓶颈时,意味着原因并不是DB资源
- 其他待机 项目(SQL执行中)
- DB资源(缓冲区竞争、I/O竞争、latch竞争等等)相关的待机时间
通过对SQL执行中的待机 项目与CPU使用时间进行调优 可以加快响应时间
SQL ordered by ~ SQL的处理信息
确认各SQL读入的缓冲区数以及磁盘的访问次数,确认是否使用了资源使用量较高的SQL

SQL trace是什么?
使用SQL trace的话就可以获得比执行SQL执行时更详细的信息通过分析刚刚获得的信息,就可以指定出现问题的SQL
SQL trace的获得方法如下所示
1. 获得所有会话信息的方法
2. 获得指定的会话信息的方法
获得的信息中,各个SQL包含以下信息
- 语句的分析、执行,fetch的执行次数
- CPU时间、消耗时间
- 物理读入(Physical read)、理论读入(Logical read)
- 处理的行数
SQL trace使用顺序
获得所有会话信息时
1. 设定初始化参数SQL_TRACE为TRUE
2. 重启Oracle
重启之后需要重新设定为FALSE,在重启期间,每次开始会话就都会创建追踪文件,就会输出各个会话的所有信息
仅仅获得指定应用的追踪方法
对应用中想开始SQL trace的point追加以下SQL语句
ALTER SESSION SET SQL_TRACE=TRUE;
这时,获得 trace期间,可以设定终止应用或者将SQL_TRACE设定为 FALSE
通过TKPROF进行的格式化
lSQL trace的输出结果通过使用TKPROF,可以以更加简明的形式来进行格式化
<UNIX/Linux环境中执行TKPROF的例>
TKPROF命令中orcl1_ora_12059.trc 这个trace文件,对 tkprof_1.prf进行格式化
$ tkprof orcl1_ora_12059.trc tkprof_1.prf
※ TKPROF的执行Module名由于环境不同而不同,具体请参考手册
TKPROF的输出例

弄清楚是应用程序的问题还是网络问题
判断DB中的性能问题时需要调查到底是AP问题还是网络问题
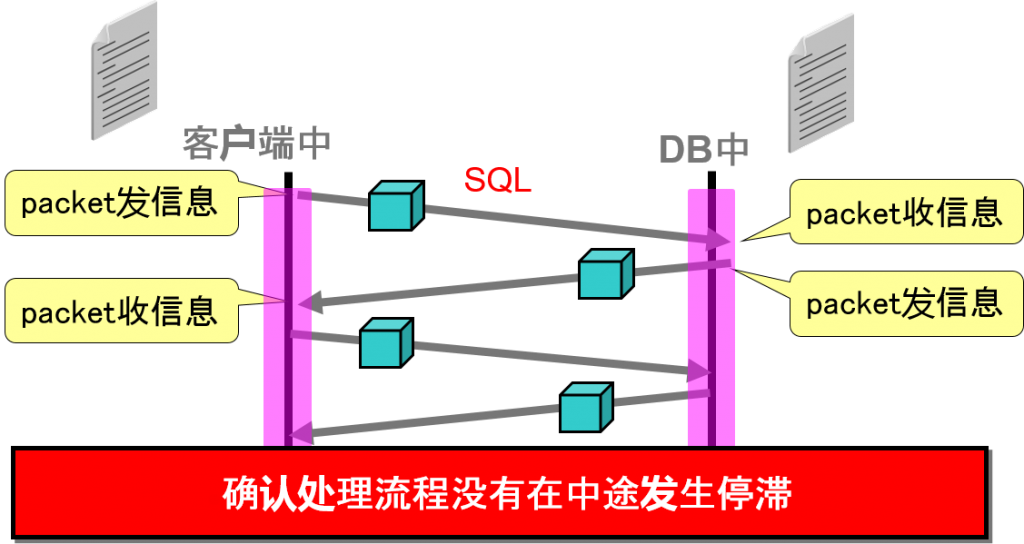
Net 的 trace文件:确认通信(packet)的处理信息
Net的 trace文件是指什么?
每个网络组成(listener・客户端・服务器等等)都可以在信息交换是,生成 trace信息
获得网络通信时的 trace信息,指定获得的信息交换中可能产生性能问题的地方
※listener与服务器的 trace每次连接与启动时,都会创建得比客户端量要更多的
首先我们推荐检查客户端(可能的话请检查服务器)的 trace

使用trace时需要考虑的问题
1.需要充分确保磁盘空间
trace以及日志可能使用大量磁盘空间
另外,通常使得设定无效。或者定期删除日志文件,尽量不对进程增加负荷
2.输出地址文件的位置 我们不推荐所有用户来写入的swap space
3.输出地址是否具有对目录的写入权限 连接用户、oracle软件拥有者、listener启动用户来写入
注意: trace功能中,因为使用了大量磁盘区域,可能造成系统 性能大幅降低。所以只有在必要时才能使用trace
客户端中的 trace设定方法
<设定方法>
l通过客户端系统的sqlnet.ora文件来设定以下参数
TRACE_LEVEL_CLIENT
TRACE_DIRECTORY_CLIENT
TRACE_UNIQUE_CLIENT
8.0.6 以后会记录以下参数
TRACE_TIMESTAMP_CLIENT
通过上述设定之后,客户端每次新建连接时都会在指定目录中生成trace文件
XXX.trc 这个文件,只要在 trace子目录中输出了的话就成功了
获得客户端的 trace相关的注意事项
<获得方法>
通过Oracle Net Services 11g (11.1.0) 将默认的 trace输出地址设定为Automatic Diagnostic Repository (ADR)
为了在通过TRACE_DIRECTORY_CLIENT指定的目录中输出,可以指定以下参数
默认为$ORACLE_HOME/log/diag
sqlnet.ora
DIAG_ADR_ENABLED=OFF
<参考>服务器的 trace也与客户端的情况相同 listener的 trace的情况如下所示
listener.ora
DIAG_ADR_ENABLED_<listener名>=OFF
tracelevel
设定通过TRACE_LEVEL_CLIENT获得的信息
正常运行时,一般为0或者OFF(默认),参考下列表,根据需求变更level
| trace level | 収集数据 |
| 0或者OFF | 没有trace的输出 |
| 4或者USER | 用户・ trace信息 |
| 10或者ADMIN | 管理 trace信息 |
| 16或者SUPPORT | Cluster 支持・ trace信息 |
客户端的 trace文件获得例
XXX.trc 这个文件是在trace子目录中输出了的话就成功
| [21-JUN-2006 10:58:29:081] nscon: doing connect handshake…
[21-JUN-2006 10:58:29:081] nscon: sending NSPTCN packet [21-JUN-2006 10:58:29:081] nspsend: entry [21-JUN-2006 10:58:29:081] nspsend: plen=242, type=1 [21-JUN-2006 10:58:29:081] nttwr: entry [21-JUN-2006 10:58:29:081] nttwr: socket 288 had bytes written=242 [21-JUN-2006 10:58:29:081] nttwr: exit [21-JUN-2006 10:58:29:081] nspsend: 242 bytes to transport [21-JUN-2006 10:58:29:081] nspsend: packet dump [21-JUN-2006 10:58:30:081] nsprecv: 00 CD 00 00 06 00 00 00 |……..| [21-JUN-2006 10:58:30:081] nsprecv: 00 00 08 00 01 00 00 00 |……..| [21-JUN-2006 10:58:30:082] nsprecv: 0C 0C 41 55 54 48 5F 53 |..AUTH_S| [21-JUN-2006 10:58:30:082] nsprecv: 45 53 53 4B 45 59 00 00 |ESSKEY..| [21-JUN-2006 10:58:30:082] nsprecv: 32 37 46 32 45 38 39 36 |27F2E896| ・ ・ |
分析的基本思路
[21-JUN-2006 10:58:30:081] nsprecv: 00 CD 00 00 06 00 00 00 |……..|
分析数据・packet的收发信息所花费的时间
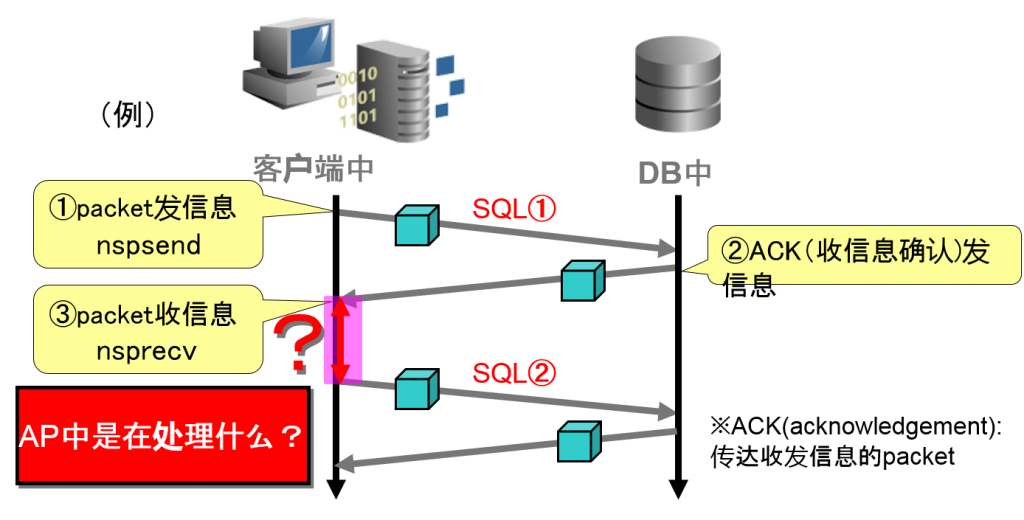
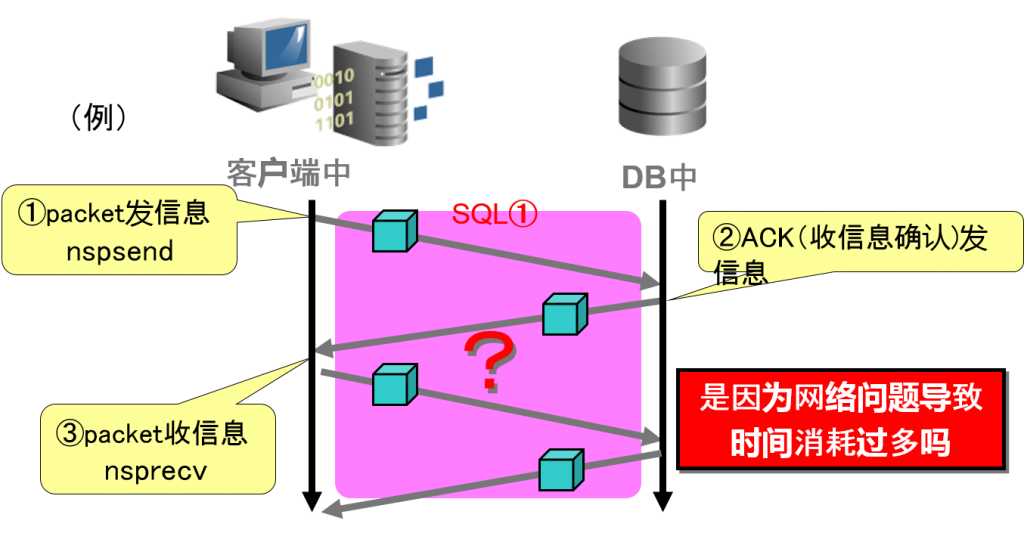
性能问题的区分①应用程序的问题例
客户端中的nsprecv(收信息)到nspsend(发信息)所花费的时间
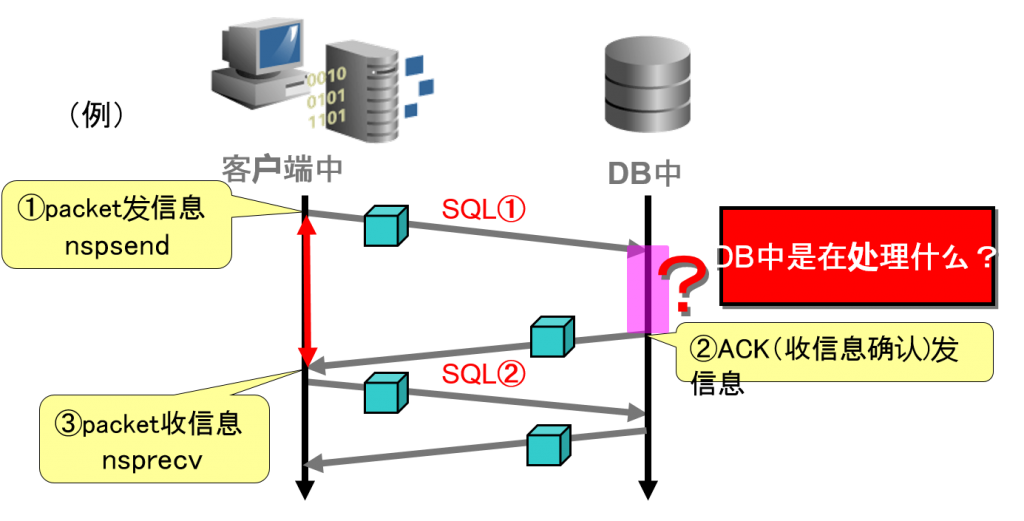
性能问题的区分②DB中的问题例
客户端中的nspsend(发信息)到nsprecv(收信息)所花费的时间
性能问题的区分例③N/W的问题例
客户端中的nspsend(发信息)到nsprecv(收信息)为止,似乎没有等待时机,考虑到处理内容,收发信息的时间也花费太多了。
数据库调优
参考分析中使用过的信息,执行合适的调优
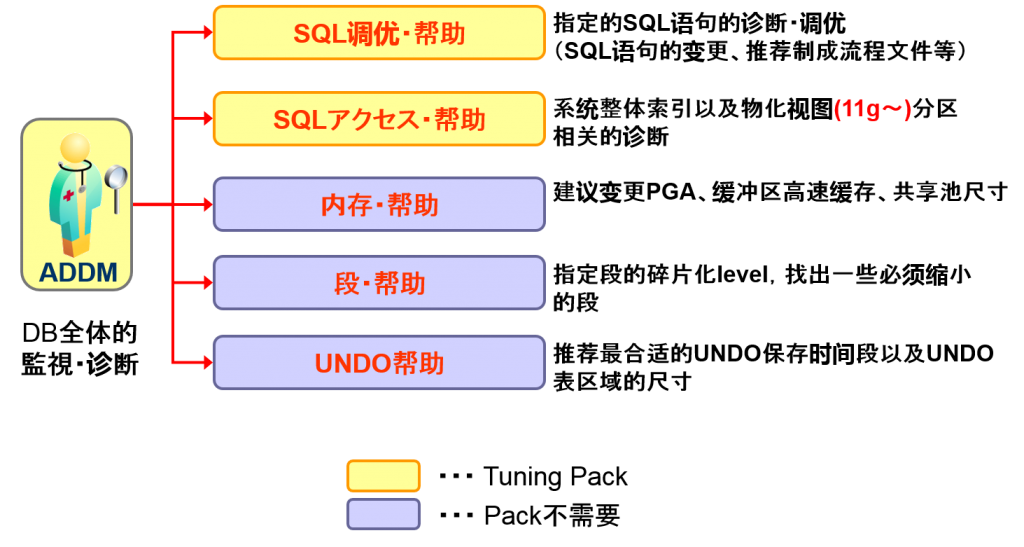
- SQL调优
- 索引
- 提示HINT
- 使用ADDM的调优
- 使用各个建议的调优
- 确认效果
- 确认使用了AUTOTRACE的调优效果
索引调优 例
Statspack的SQL ordered by Gets的确认

索引的创建与删除
索引的创建
SQL> create index c1_index on t1(c1);
索引的删除
SQL> drop index c1_index;
即使建索引了,也会在下列情况中进行全表扫描,请大家注意
- 搜索NULL值
- 计算索引列
- 隐秘地变更数据类型
- 使用LIKE语句的中间一致、后方一致搜索
- 使用!=和<>
索引的效果

提示HINT的使用
- 通过使用提示HINT,就会用到指定的访问路径,可以在优化中进行指定
<例>
- 指定使用合适的索引(Index)
- 指定合适的表结合方法以及结合顺序
- 指定CBO的目标(重视吞吐量或者面向 OLTP等) etc.
- 提示HINT的使用例 ( 在/*+ 与 */之间指定提示HINT、直接嵌入到SQL中 )
(例)就会使用表t1的c1列中附加的c1_indx这个Index
SQL>select /*+INDEX(t1 c1_index) */ * from where c1=100;
ADDM 自动数据库检测监视器
(Automatic Database Diagnostics Monitor)
- 基于AWR中所示收集的统计信息,定期监视、诊断性能的,面向DB管理者(DBA)的功能
帮助功能
SQL调优・帮助
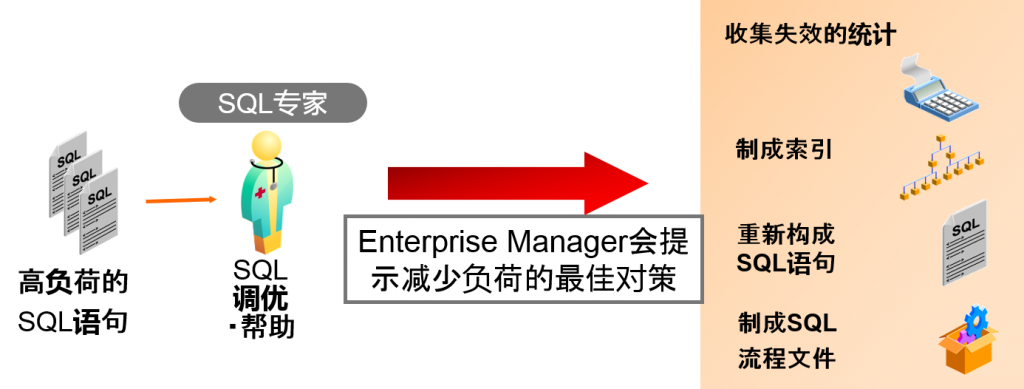
- 诊断因为高负荷而发生问题的SQL语句以及执行计划
- 以诊断为基础给予建议
调优的流程

确认调优效果
随着SQL语句变得复杂,调优方法也越来越多,可能为了达到目标效果需要
反复调优,如果使用SQL*Plus的AUTOTRACE功能的话就能当即确认效果了
l要使用AUTOTRACE的话需要确认一下几条项目
- lSQL*Plus中执行的SQL语句
- 执行计划的结果
- 统计信息
-物理读入 -論理读入
-REDO尺寸 -内存sort 尺寸
-处理件数 -磁盘sort 尺寸
AUTOTRACE功能的设定顺序
lAUTOTRACE的设定顺序如下所示
Step1 创建PLUSTRACE 角色(仅限首次)
SQL> connect sqlplus / as sysdba
SQL> @$ORACLE_HOME/sqlplus/admin/plustrce.sql
Step2 对使用用户赋予已创建的PLUSTRACE角色
SQL> grant plustrace to <用户名>
Step3 通过使用用户创建AUTOTRACE功能将要使用的工作用的表
SQL> @$ORACLE_HOME/sqlplus/admin/utlxplan.sql
每个想使用AUTOTRACE功能的用户都需要重复Step2与Step3
AUTOTRACE的获得
1.通过使用用户执行SET AUTOTRACE命令
SQL> set autotrace on
2.SQL执行
SQL> select * from t1 where c1 = 100;
※想终止AUTOTRACE功能时
SQL> set autotrace off
AUTOTRACE的获得的例子

总结

Comment