PRMSCAN oracle恢复碎片扫描合并工具的适用场景
PRMSCAN oracle恢复碎片扫描合并工具的适用场景
prmscan 是诗檀软件独立研发的ORACLE数据块碎片扫描合并工具,其适用于以下的场景:
Oracle数据恢复、碎片重组就是当出现误GHOST,硬盘坏道,误分区,误删除,误格式化,黑客入侵,目录丢失,硬盘分区表损坏等造成Oracle数据库表空间DBF或ORA文件丢失以后,使用常规数据恢复软件无法恢复,或恢复后Oracle数据库无法启动的情况,
1、ORACLE数据库无法启动或无法正常工作
2、ORACLE ASM存储破坏
3、ORACLE数据文件丢失
4、ORACLE数据文件部分损坏
一、适用的灾难情况:
(1)ORACLE数据库文件被误删除
(2)存储重新分区、格式化导致ORACLE数据库文件丢失
(3)存储突然断电、文件系统故障、fsck导致ORACLE数据库文件丢失
(4)ASM存储故障导致ORACLE数据库文件丢失
二、支持的文件系统特性:
(1)支持的文件系统类型:
NTFS/EXT3/EXT4/REISERFS/REISER4/XFS/HTFS/UFS1/UFS2/JFS1/JFS2/VXFS/ASM
(2)支持的文件系统平台:Little Endian/Big Endian
(3)支持的文件系统块大小:512 Bytes/1 KB/2 KB/4 KB/8 KB/16 KB/32 KB
PRMSCAN ORACLE碎片扫描合并工具
prmscan 是诗檀软件独立研发的ORACLE数据块碎片扫描合并工具,其适用于以下的场景:
- 误手动删除了文件系统(任意文件系统 NTFS、FAT、EXT、UFS、JFS等)或ASM上的数据文件
- 文件系统损坏,导致数据文件大小变成0 bytes即数据文件被清零
- 文件系统损坏,导致文件系统无法MOUNT加载
- ASM存储元数据损坏,导致diskgroup无法mount加载
- 文件系统或ASM其中的LV或PV被物理破坏或丢失
以上场景均可以利用prmscan直接扫描文件系统或ASM对应的 PV、LV 中的残余未被覆盖的oracle block,来实现对这些oracle数据块的合并重组,以达到数据恢复的目的。
PRMSCAN是基于JAVA语言开发的,可以跨一切支持JDK 1.6以后操作系统,包括Windows、Linux、Solaris、AIX、HP-UX。
prmscan 是诗檀软件独立研发的ORACLE数据块碎片扫描合并工具,目前该产品不独立销售,可以联系诗檀软件(13764045638)以服务形式提供恢复服务。
例如下面的例子中/dev/sdb1为ext4文件系统的分区,但是由于ext4文件系统损坏,导致SDB1无法被MOUNT,但该文件系统上存放了一套oracle数据库的数据文件,若无法MOUNT文件系统则oracle数据库也将无法使用。
这里我们使用prmscan的扫描oracle数据文件块和合并功能,从损坏的文件系统中直接将数据文件都重组出来。
- 扫描整个磁盘
[oracle@dbdao01 ~]$ java -jar PRMScan.jar –scan /dev/sdb1 –guess 8k
–scan 选项代表扫描 /dev/sdb1 设备,并指定Oracle blocksize 为8k
[oracle@dbdao01 ~]$ java -jar PRMScan.jar –outputsh ./8kfull.txt
–outputsh 代表写出一个可以合并已扫描到信息的SHELL文件 即这里的8kfull.txt
[oracle@dbdao01 ~]$ sh 8kfull.txt
执行8kfull.txt即可以 在当前目录下生成所有需要合并的数据文件
如下
[oracle@dbdao01 ~]$ ls -ll PD*
-rw-r–r– 1 oracle oinstall 295428096 Jul 28 00:37 PD_DBF1.dbf
-rw-r–r– 1 oracle oinstall 83427328 Jul 28 00:37 PD_DBF2.dbf
-rw-r–r– 1 oracle oinstall 220266496 Jul 28 00:37 PD_DBF3.dbf
-rw-r–r– 1 oracle oinstall 1324482560 Jul 28 00:38 PD_DBF4.dbf
使用PRM-DUL扫描这些数据文件
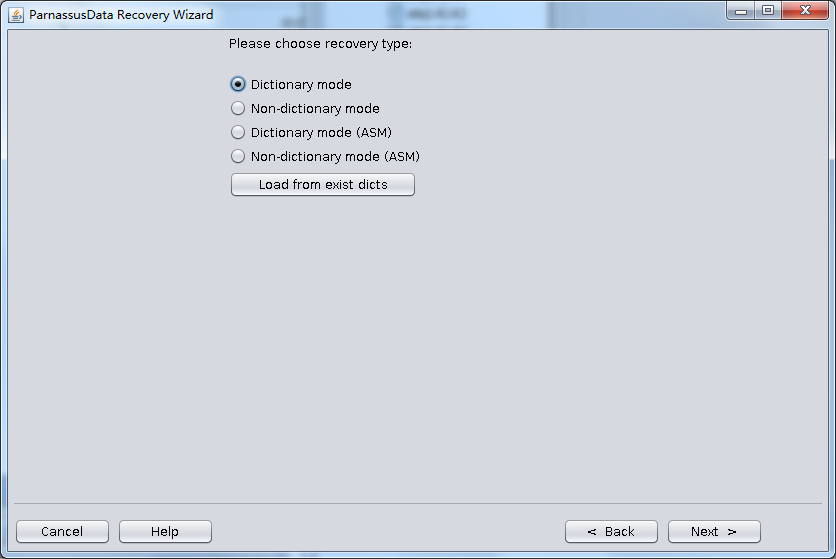

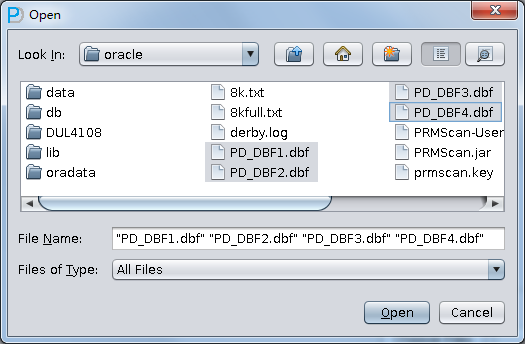
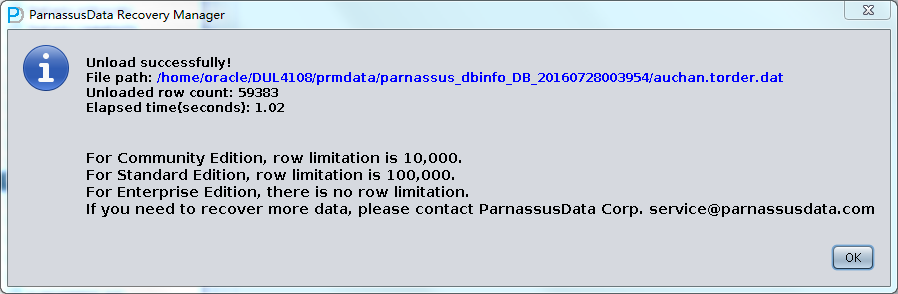
核对数据量
Parnassus Data诗檀软件成为Solix 大数据合作伙伴
![]()
http://www.prweb.com/releases/2016/03/prweb13280231.htm
加利福尼亚州圣克拉拉市。 2016年3月21日
Solix Technologies, Inc., 美商Solix科技公司是信息生命周期管理软件(Information Lifecycle Management (ILM))领域的领导者,其提供面向Apache hadoop的整体解决方案。 Solix近日宣布中国地区的数据库服务商Parnassus Data诗檀软件选择Solix Big data 大数据方案,作为其面向客户的数据归档、应用程序退休和基于apache hadoop高级分析的交付主要产品。
Apache hadoop是ILM 信息生命周期管理的理想平台,源于其所提供的高可扩展性、低成本、以及对企业数据的海量存储。Parnassus Data诗檀软件将提供基于Solix 大数据套件的软件销售和服务以帮助用户改善应用性能,降低成本,满足政府要求和风险控制。作为一个企业的常规数据平台,Solix大数据套件提供面向大数据集(包括结构化数据和非架构化数据)的高级分析功能。
“作为一个常规数据平台,Apache hadoop 针对高级企业分析和ILM应用是十分理想的,” Solix科技的执行高管John Ottman 告诉我们。”我们尝试与Parnassus Data诗檀软件在大中华市场深层合作!“
“Solix是当前唯一能针对所有企业数据提供综合Information Lifecycle Management (ILM) 的供应商。我们很高兴能在国际上有这样一个给力的合作伙伴。” 诗檀软件的CEO 刘相兵说道。
关于Solix 索利克斯科技
Solix Technologies, Inc., 美商Solix科技公司是信息生命周期管理软件(Information Lifecycle Management (ILM))领域的领导者,其提供面向Apache hadoop的整体解决方案。Solix致力于帮助资方采用优化后的架构来组织企业内部信息。Solix Big Data大数据套件是一个ILM 应用解决方案框架包括企业归档和企业数据湖(data lake),应用程序退役,和测试数据管理(database subsetting)和 数据脱敏(data masking)。Solix 科技,总部位于加利福尼亚圣克拉拉市,拥有分布全球的经销商和集成商。 如欲了解更多,可以访问http://www.solix.com.
关于 Parnassus Data 诗檀软件
Parnassus Data 诗檀软件是总部位于中国上海的数据库服务公司,提供数据库部署、应用、管理和紧急救助、灾难恢复服务。Parnassus Data诗檀软件精于数据优化、监控、分析和开发。Parnassus Data诗檀软件独立开发了自主产权的Oracle 数据库恢复软件PRM-DUL。 如欲了解更多,可以访问http://www.parnassusdata.com/
MACOS OSX苹果操作系统上的Oracle
oracle server software针对MACOS OSX已经多年未提供更新,其服务器版一直停留在10.2.0.4版本。目前版本的MACOS 例如 Yosemite基本是装不上这个版本的Oracle DB SERVER软件的。
虽然oracle不提供Server software给MACOS了,但还是提供Instant Client的,下载地址在这里: http://www.oracle.com/technetwork/topics/intel-macsoft-096467.html
这意味着你没法直接在MACOS 上运行oracle数据库实例了,但还是能把你的mac本子当做客户端的, 你也可以只用sqldeveloper和sqlcl这些基于jdbc的客户端,不需要安装Instant Client。
所以对于目前版本的macos ,如果你实在想要能运行oracle instance的话:
- 基于例如virtualbox 这样的虚拟机安装linux然后运行oracle db
- 回退MACOS到比较老的版本(不太可能,也不推荐)
Hadoop fair Scheduler(公平调度)
本文固定链接:https://www.askmac.cn/archives/hadoop-fair-scheduler.html
原文地址:http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
1.目的
这个文档是描述 FairScheduler,一个Hadoop中可拔插的调度,允许YARN应用程序在大型的集群中公平的共享资源。
2.介绍
公平调度是给应用程序分配资源的方法,这样随着时间的推移,所有的应用程序都会得到一个相同的共享资源。Hadoop NextGen 能够调度多个资源类型。默认情况下,Fair Scheduler基于内存进行公平调度。其也可以被配置调度内存和CPU,使用Ghodsi等人开发的Dominant Resource Fairness概念。当只有一个应用程序运行时,那个应用程序使用整个集群。当其他应用程序被提交,空闲的资源被分配给新的应用程序,这样每个应用程序最终获得大致相同的资源量。不用于默认的Hadoop调度,默认的调度是一个应用程序的队列,这可以让短因此程序在合理的时间内完成,而不是饥饿的长期应用程序。其也是一个合理的方式来在一些用户之间共享集群。最后,公平共享也可以以应用程序优先级工作-优先级被作为权重来确定每个应用程序应该获得的资源分数。
Oracle 甲骨文数据库云技术大会
本文永久地址:https://www.askmac.cn/archives/oracle-甲骨文数据库云技术大会.html

2016年7月22在上海市虹口区三至喜来登酒店召开了甲骨文数据库云技术大会,此次大会的主题为活力、创新、引领,由oracle与intel共同举办。大会开展了主题技术大会、项目展会、主题分会包括“数据为本-创新无止境”、“腾云甲舞-开拓新未来”、“智能超群-信息全掌控”。
上午的技术大会由甲骨文公司副总裁及中国华东区总经理何文江开场致词,对甲骨文云战略核心、Oracle SaaS的市场表现做了大致陈述,并在中国企业中,为响应互联网+与腾讯合作,联合为中国企业提供完整、集成、安全的云服务。以强大的研发实力为基础,践行云计算的创新。
 来自甲骨文公司的副总裁及中国区技术产品事业部总经理吴承杨联手中国技术咨询部高级总监李珈的“P+”组合为我们带来“从数据库到云——Oracle持续创新成就市场领导力”。混合云已经是普遍模式,尤其是企业客户。Oracle提供了灵活的混合云的部署方案Oracle IaaS &PaaS ,让云服务从“毛胚房到精装修”的阶段。企业级混合云目的在于创造稳定与创新的平衡点,解决私有云、公有云之间不同标准、不同架构、不同产品、不同技能的难题,能在私有云和公有云之间透明移动负载、无缝切换。混合云的关键能力之一在于“两步上云”的操作简单化及统一化管理。Oracle IaaS作为企业级IaaS增强了基础架构和数据管理云的能力。在数据库方面,12c已然成熟,同时推出了MAA这一最高可用性架构,Oracle Key Vault作为专属密钥保险柜,并真正做到了芯片上的数据库,利用硬件优势实现性能加速。做到了引领创新并展现出高度的市场活力。
来自甲骨文公司的副总裁及中国区技术产品事业部总经理吴承杨联手中国技术咨询部高级总监李珈的“P+”组合为我们带来“从数据库到云——Oracle持续创新成就市场领导力”。混合云已经是普遍模式,尤其是企业客户。Oracle提供了灵活的混合云的部署方案Oracle IaaS &PaaS ,让云服务从“毛胚房到精装修”的阶段。企业级混合云目的在于创造稳定与创新的平衡点,解决私有云、公有云之间不同标准、不同架构、不同产品、不同技能的难题,能在私有云和公有云之间透明移动负载、无缝切换。混合云的关键能力之一在于“两步上云”的操作简单化及统一化管理。Oracle IaaS作为企业级IaaS增强了基础架构和数据管理云的能力。在数据库方面,12c已然成熟,同时推出了MAA这一最高可用性架构,Oracle Key Vault作为专属密钥保险柜,并真正做到了芯片上的数据库,利用硬件优势实现性能加速。做到了引领创新并展现出高度的市场活力。


浙江移动业务支撑中心副总经理王晓征对浙江移动云化迁移之路做了介绍。就选择12C、X86的原因、浙江移动高可用灾备体系架构、立足实战的容灾管理、迁移方案的选择优化及经典步骤等不同方面做了简单的阐述,并提出现今面临的运维方面的挑战及部分措施。他认为,强大的运维体系是核心数据库持续更新换代,持续创新的有力保障。
 王震作为华为IT产品线关键业务服务器领域的总经理,介绍了Oracle&华为携手应对企业转型挑战所做的措施。提到了传统小型机已经难以支撑企业核心系统的快速发展,KunLun和Oracle Database两者强强联手,联合了数据库加速和数据仓库、多数据库整合等技术。
王震作为华为IT产品线关键业务服务器领域的总经理,介绍了Oracle&华为携手应对企业转型挑战所做的措施。提到了传统小型机已经难以支撑企业核心系统的快速发展,KunLun和Oracle Database两者强强联手,联合了数据库加速和数据仓库、多数据库整合等技术。
海勃物流市场部的经理冯梅就信息技术技术助力港口价值提升做了介绍,将信息技术用于增大港口吞吐量,优化提升生产和管理效率减少成本,从而通过物流信息流的整合变革成为高效率的全球港口企业。并介绍了在此过程中,面临的挑战,所以应用的系统及解决方案等


此次大会众英云集,介绍了Oracle一年的发展,交流最新的技术及各方案例,引领中国企业数据库,为市场带来新的活力,走在创新的道路上。
Hadoop Capacity Scheduler
本文固定链接:https://www.askmac.cn/archives/hadoop-capacity-scheduler.html
原文地址:http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
1.目的
这个文档描述CapacityScheduler,在hadoop中一个可拔插的调度,允许多个租户安全的共享一个大的集群,这样他们的应用程序可以在分配能力的约束下,及时分配资源。
2.概述
CapacityScheduler 被设计用来共享的运行Hadoop 应用程序,以友好操作方式进行多租户集群,同时最大化吞吐量和集群的利用率。(www.askmac.cn)
传统的,每个组织有其私有的计算资源集,有足够的能力满足在峰值或者接近峰值条件下的SLA。这通常会导致较差的平均利用率和管理多个独立的集群,每一个组织管理开销。在组织之间共享集群时一个有效的运行大hadoop的方式。因为这个可以让它们获得更好的规模效益而不用创建私人的集群。但是,这些组织关系共享集群的使用,因为它们担心它们的SLAs的重要资源。
CapacityScheduler 被设计用来允许共享一个大的集群,同时给予各组织能力保证。其中的中心思想是,Hadoop集群中的可用资源被多个组织共享,基于它们的需求计算。这里有一个额外的好处是,一个组织可以访问任何多余的不被其他人使用的容量。这为组织提供了具有成本效益的弹性方式。 [Read more…]
LGWR写redo的伪代码
本文地址:https://www.askmac.cn/archives/fast-path-redo-algorithms.html
LGWR写redo的伪代码
while(1)
{
/* The RBA can be stored into rba_pga; The pic keeps meta-data
corresponding to each write. */
Read RBA corresponding to end of last write issued and store into rba_pga;
for (each strand)
{
/* Start address for the write and is a pointer within the
strand buffer up to which the last write went to disk.
The LGWR then does a dirty read of the pointer within the
strand buffer where the latest redo block is being allocated.
The range of redo from the start address to the dirty read is
referred to as the "potential range" because it will most
likely make it to disk. The final range within each strand that
together forms a consistent set of redo will be determined by
the "extend" range step under the redo alloc latch (RAL). */
Pick potential range within strand that will go into the next
write issued to the logfile;
kcrfa[strand#].potential_end = ptr to latest redo;
}
/* Bumping the SCN after picking the range in the above step makes it
unnecessary to contract the range in the "extend" step below.
Range expansion is easy because strand meta-data points to the
start of a LWN. */
Bump SCN and store into scn_pga;
for (each strand)
{
/* Get redo alloc latch for strand */
Get RAL[strand#];
kcrfa[strand#].rba = rba_pga;
kcrfa[strand#].scn = scn_pga;
/* This uses kcrfa[strand#].potential_end as an optimized starting
point to traverse the forward redo block allocation links including all blocks of redo with SCN less than scn_pga. */
Extend strand write range to include all redo with SCN less than
scn_pga;
/* Free redo alloc latch for strand */
Free RAL[strand#];
}
Issue write to logfile;
}
Oracle中的历史公案之翻案:dead transaction到底是谁做recover的?
本文地址:https://www.askmac.cn/archives/ga1.html
作者: Maclean 刘相兵 ,非授权禁止转载!
很多同学在学习ORACLE OCP的过程中遇到如下的问题:
In the middle of a transaction,a user session was abnormally terminated but the instance is still up and the database is open. Which two statements are true in the scenario(方案)? (Choose two). A. Event viewer gives more details on the failure. B. The alert log file gives detailed information about the failure. C. PMON rolls back the transaction and releases the locks. D. SMON rolls back the transaction and releases the locks. E. The transaction is rolled backup by the next session that refers to any of the blocks updated by the failed transaction. F. Data modified by the transaction up to the last commit before the abnormal termination is retained in the database.
标准答案为:C F , 也就是说ocp教材对于会话异常终止锁导致的事务回滚这个情况,认为是由PMON进程做回滚和释放锁的。
但如果我们去实际做个试验看看呢,在这个实验中我们模拟一个会话在做了一个较大的DELETE后被KILL掉,此时DELETE相关的事务需要被回滚,到底是不是PMON出手呢?
SQL> select * from v$version; BANNER ---------------------------------------------------------------- Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bi PL/SQL Release 10.2.0.4.0 - Production CORE 10.2.0.4.0 Production TNS for Linux: Version 10.2.0.4.0 - Production NLSRTL Version 10.2.0.4.0 - Production SQL> select * from global_name; GLOBAL_NAME -------------------------------------------------------------------------------- www.askmac.cn SQL>alter system set fast_start_parallel_rollback=false; System altered. 设置10500,10046事件以跟踪SMON进程的行为 SQL> alter system set events '10500 trace name context forever,level 8'; System altered. SQL> oradebug setospid 4424 Oracle pid: 8, Unix process pid: 4424, image: oracle@rh2.oracle.com (SMON) SQL> oradebug event 10046 trace name context forever,level 8; Statement processed. 在一个新的terminal中执行大批量的删除语句,在执行一段时间后使用操作系统命令将执行该删除操作的 服务进程kill掉,模拟一个大的dead transaction的场景 SQL> delete large_rb; delete large_rb [oracle@rh2 bdump]$ kill -9 4535 等待几秒后pmon进程会找出dead process: [claim lock for dead process][lp 0x7000003c70ceff0][p 0x7000003ca63dad8.1290666][hist x9a514951] 在x$ktube内部视图中出现ktuxecfl(Transaction flags)标记为DEAD的记录: SQL> select sum(distinct(ktuxesiz)) from x$ktuxe where ktuxecfl = 'DEAD'; SUM(DISTINCT(KTUXESIZ)) ----------------------- 29386 SQL> / SUM(DISTINCT(KTUXESIZ)) ----------------------- 28816 以上KTUXESIZ代表事务所使用的undo块总数(number of undo blocks used by the transaction) ==================smon trace content================== SMON: system monitor process posted WAIT #0: nam='log file switch completion' ela= 0 p1=0 p2=0 p3=0 obj#=1 tim=1278243332801935 WAIT #0: nam='log file switch completion' ela= 0 p1=0 p2=0 p3=0 obj#=1 tim=1278243332815568 WAIT #0: nam='latch: row cache objects' ela= 95 address=2979418792 number=200 tries=1 obj#=1 tim=1278243333332734 WAIT #0: nam='latch: row cache objects' ela= 83 address=2979418792 number=200 tries=1 obj#=1 tim=1278243333356173 WAIT #0: nam='latch: undo global data' ela= 104 address=3066991984 number=187 tries=1 obj#=1 tim=1278243347987705 WAIT #0: nam='latch: object queue header operation' ela= 89 address=3094817048 number=131 tries=0 obj#=1 tim=1278243362468042 WAIT #0: nam='log file switch (checkpoint incomplete)' ela= 0 p1=0 p2=0 p3=0 obj#=1 tim=1278243419588202 Dead transaction 0x00c2.008.0000006d recovered by SMON ===================== PARSING IN CURSOR #3 len=358 dep=1 uid=0 oct=3 lid=0 tim=1278243423594568 hv=3186851936 ad='ae82c1b8' select smontabv.cnt, smontab.time_mp, smontab.scn, smontab.num_mappings, smontab.tim_scn_map, smontab.orig_thread from smon_scn_time smontab, (select max(scn) scnmax, count(*) + sum(NVL2(TIM_SCN_MAP, NUM_MAPPINGS, 0)) cnt from smon_scn_time where thread = 0) smontabv where smontab.scn = smontabv.scnmax and thread = 0 END OF STMT PARSE #3:c=0,e=1354526,p=0,cr=0,cu=0,mis=1,r=0,dep=1,og=4,tim=1278243423594556 EXEC #3:c=0,e=106,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=1278243423603269 FETCH #3:c=0,e=47065,p=0,cr=319,cu=0,mis=0,r=1,dep=1,og=4,tim=1278243423650375 *** 2011-06-24 21:19:25.899 WAIT #0: nam='smon timer' ela= 299999999 sleep time=300 failed=0 p3=0 obj#=1 tim=1278243716699171 kglScanDependencyHandles4Unpin(): cumscan=3 cumupin=4 time=776 upinned=0
通过一个10500 trace level 8可以很容易让SMON开口,如上的试验给出了2个最重要的信息:
等待几秒后pmon进程会找出dead process: [claim lock for dead process][lp 0x7000003c70ceff0][p 0x7000003ca63dad8.1290666][hist x9a514951] Dead transaction 0x00c2.008.0000006d recovered by SMON
即负责找出dead process异常终止进程的当然是PMON, 但实际这个dead transaction 是由SMON做recover的。
如果完全按照试验的结论可以发现,OCP教材上对于此题的答案其实是错误的,即选项C (C. PMON rolls back the transaction and releases the locks.)是错误的,
实际做rollback transaction的是SMON,SMON还会在回滚过程中必要的释放row lock行锁,当然其他内存锁资源还需要PMON去释放。
- 这是最终的事实吗? OCP教材误导了学生好多年?
- 不完全是,其实这里受到隐藏参数_rollback_cleanup_entries 的影响,其大致算法如下:
- PMON会负责找到dead transaction 的state object临时对象
- 如果dead transaction 涉及到的undo记录未超过隐藏参数_rollback_cleanup_entries(默认为100),则PMON将负责回滚
- 否则PMON将post SMON,让SMON完成超过_rollback_cleanup_entries的部分
- SMON 可以发起并行SLAVE帮助它一起完成rollback
分析ORACLE 源代码Undo事务管理头文件 ktucts.h – Kernel Transaction Undo Compile Time Services 可以看到:
2904 /* Starting with 8.1.3, cleanup_rollback_entries is an underscore parameter */
2905 KSPPAR_OBSOLETE("cleanup_rollback_entries", KSPPARM_MADE_UNDERSCORE)
2906
2907 #define ktunud KSPPARDN(ktunud_)
2908 KSPPARDV("_cleanup_rollback_entries", ktunud_, ktunud_s, ktunud_l, ktunud_p,
2909 LCCMDINT,
2910 0, NULLP(const text), 100, KSPLS1(NULLP(text)), KSPLS1(UB4MAXVAL), 0,
2911 KSPLS1(NULLP(sword)),
2912 "no. of undo entries to apply per transaction cleanup")
cleanup_rollback_entries参数是从版本8.1.3开始变成隐藏参数的,显然ORACLE当时已经认识到 小的dead事务直接让PMON回滚,如果事务较大那么让PMON直接委托SMON来做,同时黄金的比例就是cleanup_rollback_entries=100的经典值。
由于OCP作为入门教材并不过分强调学习者对ORACLE内部原理的理解,所以只需要大众记住由PMON负责做dead transaction recover即可。
但如果我们更进一步地去观察ORACLE就会发现并不是那么回事。 所以在过去20多年中对于到底是SMON还是PMON做dead transaction的rollback有着无休止的讨论,因为教材与实际的表现有着较大的差异。
在某些特殊的情况下ORACLE Support会建议你将_cleanup_rollback_entries设置为400或1000,这种情况并不多见,主要是为了调试一些性能问题。
通过这篇文章或许可以为此ORACLE历史公案小小的翻一下案,让幕后功臣SMON的默默功绩不至于彻底埋没。
