从今天起正式学习perl,立帖为证。。。
启蒙教育是小骆驼书,perl的上下文好搞哦!

我们知道hostid作为一台主机的唯一标示符(hostname本身可能重复),而许多付费软件通过鉴别hostid发给相关的license.
hostname的修改较为简单,只需要修改/etc/sysconfig/network中的hostname并重启即可。
hostid的修改就不那么方便了,下面介绍一种方法:
编辑一个c文件,是的之后你还需要修改它,就叫做host.c吧!
#include <stdio.h>
#include <unistd.h>
int main() {
long id,res;
// get real (default) hostid
id = gethostid();
printf("current hostid is: %x\n",id);
// set new hostid if is superuser
res = sethostid(0xa090d01); //括号内填入你想要的hostid
if (res == 0) printf("if result is zero - success! (%d) \n",res);
// check if it is changed....
id = gethostid();
printf("current hostid is: %x ;-PPPppppp\n",id);
}
之后我们需要编译它
[root@pmsora ~]# cc host.c [root@pmsora ~]# ./a.out //编译后运行 current hostid is: a090d01 if result is zero - success! (0) current hostid is: a090d01 ;-PPPppppp [root@pmsora ~]# hostid 0a090d01 //hostid正确修改了
注意运行编译好的目标文件时必须使用root用户。
在版本10.2.0.4未打上相关one-off补丁的情况下,分别对ASSM和MSSM管理模式表空间进行索引分裂测试,经过测试的结论如下:
l 在10gr2版本中MSSM方式是不能避免索引分裂引起交易超时问题;
l 10.2.0.4上的one-off补丁因为目前仅存在Linux版本,可以考虑声请补丁后具体测试(因目前没有补丁所以处于未知状态)。
l 合并索引是目前最具可行性的解决方案(alter index coalesce)。
l 最新的11gr2中经测试仍存在该问题。
具体测试过程如下:
1. 自动段管理模式下的索引块分裂
| SQL> drop tablespace idx1 including contents and datafiles;
Tablespace dropped. SQL> create tablespace idx1 datafile ‘?/dbs/idx1.dbf’ size 500M 2 segment space management AUTO 3 extent management local uniform size 10M; —创建自动段管理的表空间 Tablespace created. SQL> create table idx1(a number) tablespace idx1; Table created. create index idx1_idx on idx1 (a) tablespace idx1 pctfree 0; Index created. — 创建实验对象表及索引
SQL> insert into idx1 select rownum from all_objects, all_objects where rownum <= 250000; — 插入25万条记录 250000 rows created. SQL> commit; Commit complete. SQL>create table idx2 tablespace idx1 as select * from idx1 where 1=2; Table created. insert into idx2 select * from idx1 where rowid in (select rid from (select rid, rownum rn from (select rowid rid from idx1 where a between 10127 and 243625 order by a) —取出后端部分记录,即每250条取一条 ) where mod(rn, 250) = 0 ) / 933 rows created. SQL> commit; Commit complete. SQL> analyze index idx1_idx validate structure; —分析原索引 select blocks,lf_blks,del_lf_rows from index_stats; Index analyzed. SQL> BLOCKS LF_BLKS DEL_LF_ROWS ———- ———- ———– 1280 499 0 — 未删除情况下499个叶块
SQL> delete from idx1 where a between 10127 and 243625; — 大量删除 commit; 233499 rows deleted. SQL> SQL> Commit complete. SQL> analyze index idx1_idx validate structure; select blocks,lf_blks,del_lf_rows from index_stats; Index analyzed. SQL> BLOCKS LF_BLKS DEL_LF_ROWS ———- ———- ———– 1280 499 233499 — 删除后叶块数量不变
SQL> insert into idx1 select * from idx2; — 令那些empty块 不再empty,但每个块中只有一到二条记录,空闲率仍为75-100% commit; 933 rows created. Commit complete. SQL> insert into idx1 select 250000+rownum from all_objects where rownum <= 126; — 造成leaf块分裂前提
SQL> select ss.value,sy.name from v$sesstat ss ,v$sysstat sy where ss.statistic#=sy.statistic# and name like ‘%split%’ and sid=(select distinct sid from v$mystat); VALUE NAME ———- —————————————————————- 997 leaf node splits 997 leaf node 90-10 splits 0 branch node splits 0 queue splits —找出当前会话目前的叶块分裂次数
SQL>insert into idx1 values (251000); — 此处确实叶块分裂 1 row created. SQL> commit; Commit complete. SQL> select ss.value,sy.name from v$sesstat ss ,v$sysstat sy where ss.statistic#=sy.statistic# and name like ‘%split%’ and sid=(select distinct sid from v$mystat); VALUE NAME ———- —————————————————————- 998 leaf node splits 998 leaf node 90-10 splits 0 branch node splits 0 queue splits — 可以看到对比之前的查询多了一个叶块分裂 SQL> set linesize 200 pagesize 1500; SQL> select executions, buffer_gets, disk_reads, cpu_time, elapsed_time, rows_processed, sql_text from v$sql 2 where sql_text like ‘%insert%idx1%’ and sql_text not like ‘%v$sql%’; EXECUTIONS BUFFER_GETS DISK_READS CPU_TIME ELAPSED_TIME ROWS_PROCESSED ———- ———– ———- ———- ———— ————– SQL_TEXT ——————————————————————————————————————————————————————————————————– 1 1603 0 271601 271601 933 insert into idx2 select * from idx1 where rowid in (select rid from (select rid, rownum rn from (select rowid rid from idx1 where a between 10127 and 243625 order by a) ) where mod(rn, 250) = 0 ) 1 156 0 82803 82803 126 insert into idx1 select 250000+rownum from all_objects where rownum <= 126 1 177 0 3728 3728 1 insert into idx1 values (251000) — 读了那些实际不空的块,较多buffer_get 1 1409 0 40293 40293 933 insert into idx1 select * from idx2 1 240842 0 3478341 3478341 250000 SQL> insert into idx1 values (251001); — 不分裂的插入 1 row created. SQL> commit; Commit complete. SQL> select executions, buffer_gets, disk_reads, cpu_time, elapsed_time, rows_processed, sql_text from v$sql 2 where sql_text like ‘%insert%idx1%’ and sql_text not like ‘%v$sql%’; EXECUTIONS BUFFER_GETS DISK_READS CPU_TIME ELAPSED_TIME ROWS_PROCESSED ———- ———– ———- ———- ———— ————– SQL_TEXT ——————————————————————————————————————————————————————————————————– 1 1603 0 271601 271601 933 insert into idx2 select * from idx1 where rowid in (select rid from (select rid, rownum rn from (select rowid rid from idx1 where a between 10127 and 243625 order by a) ) where mod(rn, 250) = 0 ) 1 156 0 82803 82803 126 insert into idx1 select 250000+rownum from all_objects where rownum <= 126 1 9 0 1640 1640 1 insert into idx1 values (251001) —不分裂的插入,少量buffer_gets 1 177 0 3728 3728 1 insert into idx1 values (251000) 1 1409 0 40293 40293 933 insert into idx1 select * from idx2 1 240842 0 3478341 3478341 250000 insert into idx1 select rownum from all_objects, all_objects where rownum <= 250000 |
如演示1所示,在自动段管理模式下大量删除后插入造成许多块为75%-100%空闲率且不完全为空,此后叶块分裂时将引起插入操作的相关前台进程扫描大量“空块“,若这些块不在内存中(引发物理读)且可能需要延迟块清除等原因时,减缓了该扫描操作的速度,造成叶块分裂缓慢,最终导致了其他insert操作被split操作所阻塞,出现enq:tx index contention等待事件。
2. 手动段管理模式下的索引块分裂
| SQL> drop tablespace idx1 including contents and datafiles;
Tablespace dropped. SQL> create tablespace idx1 datafile ‘?/dbs/idx1.dbf’ size 500M 2 segment space management MANUAL — MSSM的情况 3 extent management local uniform size 10M; Tablespace created. SQL> create table idx1(a number) tablespace idx1; create index idx1_idx on idx1 (a) tablespace idx1 pctfree 0; Table created. SQL> SQL> insert into idx1 select rownum from all_objects, all_objects where rownum <= 250 Index created. SQL> SQL> 000; commit; create table idx2 tablespace idx1 as select * from idx1 where 1=2; insert into idx2 select * from idx1 where rowid in (select rid from (select rid, rownum rn from (select rowid rid from idx1 where a between 10127 and 243625 order by a) ) where mod(rn, 250) = 0 ) / commit; 250000 rows created. SQL> SQL> Commit complete. SQL> SQL> Table created. SQL> SQL> 2 3 4 5 6 7 8 9 933 rows created. SQL> SQL> Commit complete. SQL> analyze index idx1_idx validate structure; select blocks,lf_blks,del_lf_rows from index_stats; Index analyzed. SQL> BLOCKS LF_BLKS DEL_LF_ROWS ———- ———- ———– 1280 499 0 SQL> delete from idx1 where a between 10127 and 243625; 233499 rows deleted. SQL> commit; Commit complete. SQL> insert into idx1 select * from idx2; commit; 933 rows created. SQL> SQL> Commit complete. SQL> SQL> insert into idx1 select 250000+rownum from all_objects where rownum <= 126; commit; 126 rows created. SQL> SQL> Commit complete. SQL> SQL> select ss.value,sy.name from v$sesstat ss ,v$sysstat sy where ss.statistic#=sy.statistic# and name like ‘%split%’ and sid=(select distinct sid from v$mystat); VALUE NAME ———- —————————————————————- 1496 leaf node splits 1496 leaf node 90-10 splits 0 branch node splits 0 queue splits SQL> insert into idx1 values (251000); — 确实分裂 1 row created. SQL> commit; Commit complete. SQL> select ss.value,sy.name from v$sesstat ss ,v$sysstat sy where ss.statistic#=sy.statistic# and name like ‘%split%’ and sid=(select distinct sid from v$mystat); VALUE NAME ———- —————————————————————- 1497 leaf node splits 1497 leaf node 90-10 splits 0 branch node splits 0 queue splits — 以上与ASSM时完全一致 SQL> select executions, buffer_gets, disk_reads, cpu_time, elapsed_time, rows_processed, sql_text from v$sql 2 where sql_text like ‘%insert%idx1%’ and sql_text not like ‘%v$sql%’; EXECUTIONS BUFFER_GETS DISK_READS CPU_TIME ELAPSED_TIME ROWS_PROCESSED ———- ———– ———- ———- ———— ————– SQL_TEXT ——————————————————————————————————————————————————————————————————– 1 1553 0 283301 283301 933 insert into idx2 select * from idx1 where rowid in (select rid from (select rid, rownum rn from (select rowid rid from idx1 where a between 10127 and 243625 order by a) ) where mod(rn, 250) = 0 ) 1 153 0 78465 78465 126 insert into idx1 select 250000+rownum from all_objects where rownum <= 126 1 963 0 10422 10422 1 — 比ASSM模式下更大量的“空块”读 insert into idx1 values (251000) 1 984 0 35615 35615 933 insert into idx1 select * from idx2 1 238579 0 3468326 3469984 250000 insert into idx1 select rownum from all_objects, all_objects where rownum <= 250000 SQL> insert into idx1 values (251001); 1 row created. SQL> commit; Commit complete. SQL> select executions, buffer_gets, disk_reads, cpu_time, elapsed_time, rows_processed, sql_text from v$sql 2 where sql_text like ‘%insert%idx1%’ and sql_text not like ‘%v$sql%’; EXECUTIONS BUFFER_GETS DISK_READS CPU_TIME ELAPSED_TIME ROWS_PROCESSED ———- ———– ———- ———- ———— ————– SQL_TEXT ——————————————————————————————————————————————————————————————————– 1 1553 0 283301 283301 933 insert into idx2 select * from idx1 where rowid in (select rid from (select rid, rownum rn from (select rowid rid from idx1 where a between 10127 and 243625 order by a) ) where mod(rn, 250) = 0 ) 1 153 0 78465 78465 126 insert into idx1 select 250000+rownum from all_objects where rownum <= 126 1 7 0 1476 1476 1 insert into idx1 values (251001) —不分裂的情况与ASSM时一致 1 963 0 10422 10422 1 insert into idx1 values (251000) 1 984 0 35615 35615 933 insert into idx1 select * from idx2 1 238579 0 3468326 3469984 250000 insert into idx1 select rownum from all_objects, all_objects where rownum <= 250000 6 rows selected. |
如演示2所示,MSSM情况下叶块分裂读取了比ASSM模式下更多的“空块“;MSSM并不能解决大量删除后叶块分裂需要扫描大量非空块的问题,实际上可能更糟糕。从理论上讲MSSM的freelist只能指出那些未达到pctfree和曾经到达pctfree后来删除记录后使用空间下降到pctused的块(doc:A free list is a list of free data blocks that usually includes blocks existing in a number of different extents within the segment. Free lists are composed of blocks in which free space has not yet reached PCTFREE or used space has shrunk below PCTUSED.),换而言之MSSM模式下”空块“会更多。
3. 自动段管理模式下coalesce后的索引块分裂
| SQL> drop tablespace idx1 including contents and datafiles;
Tablespace dropped. SQL> create tablespace idx1 datafile ‘?/dbs/idx1.dbf’ size 500M 2 segment space management AUTO — ASSM 下 coalesce情况 3 extent management local uniform size 10M; Tablespace created. SQL> create table idx1(a number) tablespace idx1; create index idx1_idx on idx1 (a) tablespace idx1 pctfree 0; Table created. SQL> SQL> Index created. SQL> SQL> insert into idx1 select rownum from all_objects, all_objects where rownum <= 250000; commit; create table idx2 tablespace idx1 as select * from idx1 where 1=2; insert into idx2 select * from idx1 where rowid in (select rid from (select rid, rownum rn from (select rowid rid from idx1 where a between 10127 and 243625 order by a) ) where mod(rn, 250) = 0 ) / commit; 250000 rows created. SQL> SQL> Commit complete. SQL> SQL> Table created. SQL> SQL> 2 3 4 5 6 7 8 9 933 rows created. SQL> SQL> Commit complete. SQL> SQL> SQL> SQL> SQL> analyze index idx1_idx validate structure; select blocks,lf_blks,del_lf_rows from index_stats; Index analyzed. SQL> BLOCKS LF_BLKS DEL_LF_ROWS ———- ———- ———– 1280 499 0 SQL> delete from idx1 where a between 10127 and 243625; commit; 233499 rows deleted. SQL> SQL> Commit complete. SQL> alter index idx1_idx coalesce; Index altered. SQL> analyze index idx1_idx validate structure; select blocks,lf_blks,del_lf_rows from index_stats; Index analyzed.
SQL>
BLOCKS LF_BLKS DEL_LF_ROWS ———- ———- ———– 1280 33 0 — coalesc后 lf块合并了 SQL> insert into idx1 select * from idx2; 933 rows created. SQL> SQL> commit; Commit complete. SQL> SQL> insert into idx1 select 250000+rownum from all_objects where rownum <= 126; commit; 126 rows created. SQL> SQL> Commit complete. SQL> select ss.value,sy.name from v$sesstat ss ,v$sysstat sy where ss.statistic#=sy.statistic# and name like ‘%split%’ and sid=(select distinct sid from v$mystat); VALUE NAME ———- —————————————————————- 1999 leaf node splits 1995 leaf node 90-10 splits 0 branch node splits 0 queue splits SQL> insert into idx1 values (251000); — 确实分裂 1 row created. SQL> commit; Commit complete. SQL> select ss.value,sy.name from v$sesstat ss ,v$sysstat sy where ss.statistic#=sy.statistic# and name like ‘%split%’ and sid=(select distinct sid from v$mystat); VALUE NAME ———- —————————————————————- 2000 leaf node splits 1996 leaf node 90-10 splits 0 branch node splits 0 queue splits SQL> select executions, buffer_gets, disk_reads, cpu_time, elapsed_time, rows_processed, sql_text from v$sql 2 where sql_text like ‘%insert%idx1%’ and sql_text not like ‘%v$sql%’; EXECUTIONS BUFFER_GETS DISK_READS CPU_TIME ELAPSED_TIME ROWS_PROCESSED ———- ———– ———- ———- ———— ————– SQL_TEXT ——————————————————————————————————————————————————————————————————– 1 1603 0 268924 268924 933 insert into idx2 select * from idx1 where rowid in (select rid from (select rid, rownum rn from (select rowid rid from idx1 where a between 10127 and 243625 order by a) ) where mod(rn, 250) = 0 ) 1 156 0 78349 78349 126 insert into idx1 select 250000+rownum from all_objects where rownum <= 126 1 23 0 2218 2218 1 —少量buffer gets insert into idx1 values (251000) 1 191 0 15596 15596 933 insert into idx1 select * from idx2 1 240852 0 3206130 3206130 250000 insert into idx1 select rownum from all_objects, all_objects where rownum <= 250000 SQL> insert into idx1 values (251001); 1 row created. SQL> commit; Commit complete. SQL> select executions, buffer_gets, disk_reads, cpu_time, elapsed_time, rows_processed, sql_text from v$sql 2 where sql_text like ‘%insert%idx1%’ and sql_text not like ‘%v$sql%’; EXECUTIONS BUFFER_GETS DISK_READS CPU_TIME ELAPSED_TIME ROWS_PROCESSED ———- ———– ———- ———- ———— ————– SQL_TEXT ——————————————————————————————————————————————————————————————————– 1 1603 0 268924 268924 933 insert into idx2 select * from idx1 where rowid in (select rid from (select rid, rownum rn from (select rowid rid from idx1 where a between 10127 and 243625 order by a) ) where mod(rn, 250) = 0 ) 1 156 0 78349 78349 126 insert into idx1 select 250000+rownum from all_objects where rownum <= 126 1 9 0 1574 1574 1 insert into idx1 values (251001) 1 23 0 2218 2218 1 insert into idx1 values (251000) 1 191 0 15596 15596 933 insert into idx1 select * from idx2 1 240852 0 3206130 3206130 250000 insert into idx1 select rownum from all_objects, all_objects where rownum <= 250000 6 rows selected. |
如演示三所示在删除后进行coalesce操作,合并操作将大量空块分离出了索引结构(move empty out of index structure),之后的叶块分裂仅读取了少量必要的块。
4. 手动段管理模式下coalesce后的索引块分裂
| SQL> drop tablespace idx1 including contents and datafiles;
Tablespace dropped. SQL> create tablespace idx1 datafile ‘?/dbs/idx1.dbf’ size 500M 2 segment space management MANUAL — mssm情况下 coalesce 3 extent management local uniform size 10M; Tablespace created. SQL> create table idx1(a number) tablespace idx1; create index idx1_idx on idx1 (a) tablespace idx1 pctfree 0; Table created. SQL> SQL> insert into idx1 select rownum from all_objects, all_objects where rownum <= 250 Index created. SQL> SQL> 000; commit; create table idx2 tablespace idx1 as select * from idx1 where 1=2; insert into idx2 select * from idx1 where rowid in (select rid from (select rid, rownum rn from (select rowid rid from idx1 where a between 10127 and 243625 order by a) ) where mod(rn, 250) = 0 ) / commit; 250000 rows created. SQL> SQL> Commit complete. SQL> SQL> Table created. SQL> SQL> 2 3 4 5 6 7 8 9 933 rows created. SQL> SQL> Commit complete. SQL> SQL> SQL> SQL> SQL> analyze index idx1_idx validate structure; select blocks,lf_blks,del_lf_rows from index_stats; Index analyzed. SQL> BLOCKS LF_BLKS DEL_LF_ROWS ———- ———- ———– 1280 499 0 SQL> delete from idx1 where a between 10127 and 243625; commit; 233499 rows deleted. SQL> SQL> Commit complete. SQL> analyze index idx1_idx validate structure; select blocks,lf_blks,del_lf_rows from index_stats; Index analyzed. SQL> BLOCKS LF_BLKS DEL_LF_ROWS ———- ———- ———– 1280 499 233499 SQL> alter index idx1_idx coalesce; Index altered. SQL> analyze index idx1_idx validate structure; select blocks,lf_blks,del_lf_rows from index_stats; Index analyzed. SQL> BLOCKS LF_BLKS DEL_LF_ROWS ———- ———- ———– 1280 33 0 SQL> insert into idx1 select * from idx2; 933 rows created. SQL> SQL> commit; Commit complete. SQL> SQL> insert into idx1 select 250000+rownum from all_objects where rownum <= 126; commit; 126 rows created. SQL> SQL> Commit complete. SQL> select ss.value,sy.name from v$sesstat ss ,v$sysstat sy where ss.statistic#=sy.statistic# and name like ‘%split%’ and sid=(select distinct sid from v$mystat); VALUE NAME ———- —————————————————————- 2502 leaf node splits 2494 leaf node 90-10 splits 0 branch node splits 0 queue splits SQL> insert into idx1 values (251000); — 确实分裂 1 row created. SQL> commit; Commit complete. SQL> select ss.value,sy.name from v$sesstat ss ,v$sysstat sy where ss.statistic#=sy.statistic# and name like ‘%split%’ and sid=(select distinct sid from v$mystat); VALUE NAME ———- —————————————————————- 2503 leaf node splits 2495 leaf node 90-10 splits 0 branch node splits 0 queue splits SQL> select executions, buffer_gets, disk_reads, cpu_time, elapsed_time, rows_processed, sql_text from v$sql 2 where sql_text like ‘%insert%idx1%’ and sql_text not like ‘%v$sql%’; EXECUTIONS BUFFER_GETS DISK_READS CPU_TIME ELAPSED_TIME ROWS_PROCESSED ———- ———– ———- ———- ———— ————– SQL_TEXT ——————————————————————————————————————————————————————————————————– 1 1553 0 281059 281059 933 insert into idx2 select * from idx1 where rowid in (select rid from (select rid, rownum rn from (select rowid rid from idx1 where a between 10127 and 243625 order by a) ) where mod(rn, 250) = 0 ) 1 153 0 77817 77817 126 insert into idx1 select 250000+rownum from all_objects where rownum <= 126 1 19 0 2010 2010 1 — 少量buffer get insert into idx1 values (251000) 1 126 0 15364 15364 933 insert into idx1 select * from idx2 1 238644 0 3229737 3230569 250000 insert into idx1 select rownum from all_objects, all_objects where rownum <= 250000 SQL> insert into idx1 values (251001); 1 row created. SQL> commit; Commit complete. SQL> select executions, buffer_gets, disk_reads, cpu_time, elapsed_time, rows_processed, sql_text from v$sql 2 where sql_text like ‘%insert%idx1%’ and sql_text not like ‘%v$sql%’; EXECUTIONS BUFFER_GETS DISK_READS CPU_TIME ELAPSED_TIME ROWS_PROCESSED ———- ———– ———- ———- ———— ————– SQL_TEXT ——————————————————————————————————————————————————————————————————– 1 1553 0 281059 281059 933 insert into idx2 select * from idx1 where rowid in (select rid from (select rid, rownum rn from (select rowid rid from idx1 where a between 10127 and 243625 order by a) ) where mod(rn, 250) = 0 ) 1 153 0 77817 77817 126 insert into idx1 select 250000+rownum from all_objects where rownum <= 126 1 7 0 1460 1460 1 insert into idx1 values (251001) 1 19 0 2010 2010 1 insert into idx1 values (251000) 1 126 0 15364 15364 933 insert into idx1 select * from idx2 1 238644 0 3229737 3230569 250000 insert into idx1 select rownum from all_objects, all_objects where rownum <= 250000 6 rows selected. |
如演示4所示,MSSM模式下合并操作与ASSM情况下大致一样,合并操作可以有效解决该问题。
5. Coalesce合并操作的锁影响
| SQL> create table coal (t1 int);
Table created. SQL> create index pk_t1 on coal(t1); Index created. SQL> begin 2 for i in 1..3000 loop 3 insert into coal values(i); 4 commit; 5 end loop; 6 end; 7 / PL/SQL procedure successfully completed. SQL> delete coal where t1>500; 2500 rows deleted. SQL> commit; Commit complete. SQL> analyze index pk_t1 validate structure; Index analyzed. — 注意analyze validate操作会block一切dml操作 SQL> select blocks,lf_blks,del_lf_rows from index_stats; BLOCKS LF_BLKS DEL_LF_ROWS ———- ———- ———– 8 6 2500 — 删除后的状态 此时另开一个会话,开始dml操作: SQL> update coal set t1=t1+1; 500 rows updated. — 回到原会话 SQL> alter index pk_T1 coalesce; — coalesce 未被阻塞 Index altered. — 在另一个会话中commit,以便执行validate structure
SQL> analyze index pk_t1 validate structure;
Index analyzed.
SQL> select blocks,lf_blks,del_lf_rows from index_stats;
BLOCKS LF_BLKS DEL_LF_ROWS ———- ———- ———– 8 3 500 — 显然coalesce的操作没有涉及有dml操作的块 在没有dml操作的情况下: SQL> truncate table coal; Table truncated. SQL> begin 2 for i in 1..3000 loop 3 insert into coal values(i); 4 commit; 5 end loop; 6 end; 7 / PL/SQL procedure successfully completed. SQL> analyze index pk_t1 validate structure; Index analyzed. SQL> select blocks,lf_blks,del_lf_rows from index_stats; BLOCKS LF_BLKS DEL_LF_ROWS ———- ———- ———– 8 6 0 SQL> delete coal where t1>500; 2500 rows deleted. SQL> commit; Commit complete. SQL> analyze index pk_t1 validate structure; Index analyzed. SQL> select blocks,lf_blks,del_lf_rows from index_stats; BLOCKS LF_BLKS DEL_LF_ROWS ———- ———- ———– 8 6 2500 SQL> alter index pk_t1 coalesce; Index altered. SQL> analyze index pk_t1 validate structure; Index analyzed. SQL> select blocks,lf_blks,del_lf_rows from index_stats; BLOCKS LF_BLKS DEL_LF_ROWS ———- ———- ———– 8 1 0 —没有dml时,coalesce 操作涉及了所有块 |
如演示5所示coalesce会避开dml操作涉及的块,但在coalesec的短暂间歇出现在索引上有事务的块不会太多。且coalesce操作不会降低索引高度。
附件是关于rebuild及coalesce索引操作的详细描述:
6. Coalesce操作总结
优点:
l 是一种快速的操作,对整体性能影响最小(not performance sensitive)。
l 不会锁表,绕过有事务的索引块。
l 可以有效解决现有的问题。
l 不会降低索引高度,引起再次的root split
缺点:
l 需要针对个别对象,定期执行合并操作;无法一劳永逸地全局地解决该问题。
7. Linux 10.2.0.4上相关补丁的技术交流
Metalink bug 8286901 note中叙述了一位用户遇到相同的问题并提交了SR,当时oracle support给出了one-off补丁,但该用户在apply了该补丁后仍未解决问题。
以下为note 原文:
| It is similar to bug8286901, but after applied patch8286901, still see enq tx contentiona with high “failed probes on index block reclamation” Issue encountered by customer and Oracle developer (Stefan Pommerenk). He describes is thus: "Space search performed by the index splitter can't find space in neighboring blocks, and then instead of allocating new space, we go and continue to search for space elsewhere, which manifests itself in block reads from disk, block cleanouts, and subsequent blocks written due to aggressive MTTR setting." "To clarify: the cleanouts are not the problem per se. The culprit seems to be that the space search performed by the index splitter can't find space in neighboring blocks, and then instead of allocating new space, we go and continue to search for space elsewhere, which manifests itself in block reads from disk, block cleanouts, and subsequent blocks written due to aggressive MTTR setting. This action has caused other sessions to get blocked on TX enqueue contention, blocked on the splitting session. Advice was to set 10224 trace event for the splitter for a short time only in order to get diagnostics as to why the space search rejected most blocks. > A secondary symptom are the bitmap level 1 block updates, which may or may not be related to the space search; I've not seen them before, maybe because I didn't really pay attention :P , but the symptoms seen in the ASH trace indicate it's the same problem. Someone in space mgmt has to look at it to confirm it is the same problem." |
与该用户进行了mail私下交流,他的回复:
| I still have a case open with Oracle. I believe that this is a bug in the Oracle code. The problem is that it has been difficult to create a reproducible test case for Oracle support. My specific issue was basically put on hold pending the results of another customer’s service request that appeared to have had the same issue, (9034788). Unfortunately they couldn’t reproduce the issue in that case either.
I believe that there is a correlation between the enq TX – index contention wait event and a spike in the number of ‘failed probes on index block reclamation. I have specifically asked Oracle to explain why there is a spike in the ‘failed probes on index block reclamation’ during the same time frame as the enq TX index contention wait event, but they have not answered my question. I was hoping that some investigation by Oracle Support into the failed probes metric might get someone on the right track to discovering the bug. That hasn’t happened though. Hi , Thanks for your sharing . The bug (or specific ktsp behave) is fatal in response time sensitive OLTP env. I would like to ask my customer to coalesce those index where massive deleted regularly. Thanks for your help again! Yes, I saw that. I have applied patch 8286901 and set the event for version 10.2.0.4, but the problem still occurs periodically. And as I mentioned before, we see a correlation between enq TX waits and the failed probes on index block reclamation. Which is why I still think that it is a bug. I agree that trying to rebuild or coalesce the indexes are simply attempts to workaround the issue and not solve the root cause. Early on when I started on this issue I did do some index dumps and could clearly see that we had lots of blocks with only 1 or 2 records after our mass delete jobs. I have provided Oracle Support with this information as well as oradump files while the problem is occurring, but they don’t seem to be able to find anything wrong so far. If you are interested in seeing if you are experiencing a high ‘failed probes on index block reclamation’ event run the query below. select SS.snap_id, |
|
—在最新的11gr2中进行了测试,仍可以重现该问题(如图单条insert引起了6675的buffer_gets,这是在更大量数据的情况下)。 |
我们可以猜测Oracle提供的one-off补丁中可能是为叶块分裂所会扫描的“空块”附加了一个上限,在未达到上限的情况下扫描仍会发生。而在主流的公开的发行版本中Oracle不会引入该补丁的内容。尝试在没有缓存的情况下引起分裂问题,分裂引起了大约4000个块的物理读,但该操作仍在0.12秒(有缓存是0.02秒,如图)内完成了(该测试使用普通ata硬盘,读取速度在100MB/S: Timing buffered disk reads: 306 MB in 3.00 seconds = 101.93 MB/sec);从1月21日的ash视图中可以看到引起split的260会话处于单块读等待(db file sequential read)中,且已等待了43950us约等于44ms;这与良好io的经验值10ms左右有较大出入;我们可以确信io性能问题也是引发此叶块分裂延迟如此显性的一个重要因素。
综上所述,在之前讨论的几个方案中,MSSM方式是不能避免索引分裂引起交易超时问题的;不删除数据的方案在许多对象上不可行;10.2.0.4上的one-off补丁因为目前仅存在Linux版本,可以考虑声请补丁后具体测试(因目前没有补丁所以处于未知状态)。Coalesce合并索引是目前既有的最具可操作性且无副作用的解决方案。
Oracle 10g 中引入了v$osstat 视图方便了dba了解主机负载情况,同时也可以通过oem网页观察到一段时间内主机上负载较高的进程;但如果db未开启oem管理界面,则无法了解过去时段内高负载服务进程的相关信息。以下脚本可以给予一定的帮助。
CREATE TABLE "SYS"."HIGHLOAD_HISTORY" ( "SAMPLE_TIME" DATE, "SPID" NUMBER(10,0), "LOAD" VARCHAR2(7 BYTE), "SID" VARCHAR2(30 BYTE), "USERNAME" VARCHAR2(40 BYTE), "MACHINE" VARCHAR2(64 BYTE), "PROGRAM" VARCHAR2(48 BYTE), "SQL_ID" VARCHAR2(13 BYTE), "SQL_FULLTEXT" CLOB, "INST_ID" NUMBER(2,0), "STATUS" VARCHAR2(8 BYTE) ) --建立记录高负载进程信息的表,内容包括了cpu使用率,及sql(并不十分准确,因为获取spid后需要进行查询)
ps aux|grep $ORACLE_SID|awk '{ if($3>=0.3) print "insert into highload_history select sysdate rec_time,"$2,","$3"%",", ss.sid,ss.username,ss.machine,ss.program,ss.sql_id,(select sql_fulltext from v$sqlarea sq where sq.sql_id=ss.sql_id),(select instance_number from v$instance),ss.status from v$session ss,v$process pr where pr.addr=ss.paddr and pr.spid=",$2";"}' | sqlplus / as sysdba --直接运行即可
set parameter _in_memory_undo = FALSE to disable IMU
Workaround: Disable IMU (set _in_memory_undo=FALSE)
PLEASE NOTE: This bug applies to single instance databases and not RAC as IMU is not enabled in RAC.
注意在RAC系统中IMU是不可用的,所以也就不必要去设置_in_memory_undo=FALSE
The workaround will prevent the problem, but will not fix it.
Note: _in_memory_undo is a dynamic parameter for 10g with values of TRUE or FALSE. It specifies whether there should be in memory undo for transactions. Setting this value to FALSE will disable this feature. This will cause excess redo generation.
_in_memory_undo is applicable when
compatibility >= 10.0
undo_management = AUTO
cluster_database = FALSE
Running IMU transactions may generate out-of-order redo records
Disabling in memory undo (_in_memory_undo=false)
can help to eliminate “In memory undo latch” contention
but there may still be “undo global data” latch contention
as that latch is used regardless of the setting of
_in_memory_undo. The fix for this bug can help reduce
contention on both latches.
The NOLOGGING clause doesn’t prevent redo on all operations, but rather only on a subset. I searched the documentation for examples of this…
http://st-doc.us.oracle.com/11/112/server.112/e16541/parallel007.htm?term=nologging+generate+redo#VLDBG1536
[NO]LOGGING Clause
The [NO]LOGGING clause applies to tables, partitions, tablespaces, and indexes. Virtually no log is generated for certain operations (such as direct-path INSERT) if the NOLOGGING clause is used. The NOLOGGING attribute is not specified at the INSERT statement level but is
instead specified when using the ALTER or CREATE statement for a table, partition, index, or tablespace.
When a table or index has NOLOGGING set, neither parallel nor serial direct-path INSERT operations generate redo logs. Processes running with the NOLOGGING option set run faster because no redo is generated. However, after a NOLOGGING operation against a table,
partition, or index, if a media failure occurs before a backup is performed, then all tables, partitions, and indexes that have been modified might be corrupted.
Direct-path INSERT operations (except for dictionary updates) never generate redo logs if the NOLOGGING clause is used. The NOLOGGING attribute does not affect undo, only redo. To be precise, NOLOGGING allows the direct-path INSERT operation to generate a negligible
amount of redo (range-invalidation redo, as opposed to full image redo).
But I did find an Ask Tom article which is more explicit about what operations generate redo despite the NOLOGGING clause:
http://asktom.oracle.com/pls/asktom/f?p=100:11:0::::P11_QUESTION_ID:5280714813869
This has a nice table of operations with either No/Archive and No/Logging specified, and you can see redo is generated most of the time.
So to sum up the NOLOGGING clause only works with certain operations and we cannot expect all REDO to be completely halted.
Another item to consider is whether the Indexes on the tables were created with NOLOGGING or not… This is covered in Index generates high redo, although it is in NOLOGGING (Doc ID 1235234.1), so please reveiw that note to see if there are some indexes that can be recreated to reduce redo further.
Question:
在RAC环境中节点之间的OS操作系统时钟一致是clusterware能够稳定运行的重要因素之一,但是如果我们确实有调整OS时间的需求,那么是否真的会影响到RAC的正常运行呢? 具体的影响是如何的呢? 又需要注意哪些方面的因素呢?
Answer:
RAC: Frequently Asked Questions (Doc ID 220970.1)
Does Oracle RAC work with NTP (Network Time Protocol)?
YES! NTP and Oracle RAC are compatible, as a matter of fact, it is recommended to setup NTP in an Oracle RAC cluster, for Oracle 9i Database, Oracle Database 10g, and Oracle Database 11g Release 1.
…
Keep the following points in mind:
# Minor changes in time (in the seconds range) are harmless for Oracle RAC and the Oracle Clusterware. If you intend on making large time changes it is best to shutdown the instances and the entire Oracle Clusterware stack on that node to avoid a false eviction, especially if you are using the Oracle RAC 10g low-brownout patches, which allow really low misscount settings.
# Backup/recovery aspect of large time changes are documented in Note: 77370.1, basically you can’t use RECOVER DATABASE UNTIL TIME to reach the second recovery point, It is possible to overcome with RECOVER DATABASE UNTIL CANCEL or UNTIL CHANGE. If you are doing complete recovery (most of the times) then this is not an issue since the Oracle recovery code uses SCN (System Change Numbers) to advance in the redo/archive logs. The SCN numbers never go back in time (unless a reset-logs operation is performed), there is always an association of an SCN to a human readable timestamp (which may change forward or backwards), hence the issue with recovery until point in time vs. until SCN/Cancel.
# If DBMS_SCHEDULER is in usage it will be affected by time changes, as it’s using actual clock rather than SCN.
# On platforms with OPROCD get fix for <> “OPROCD REBOOTS NODE WHEN TIME IS SET BACK BY XNTPD”
# If NTP is not configured correctly (using -x flag), and diagwait not set to 13 Note: 559365.1 10.2/11.1 RAC systems can be rebooted due to OPROCD, during a leap second event, see Note: 759143.1.
# Daylight saving time adjustments do not affect the system clock, only the displayed time, hence have no impact on the Oracle software.
Apart from these issues, the Oracle RDBMS server is immuned to time changes, i.e. will not affect transaction/read consistency operations.
Also please refer to note:
Dates & Calendars – Frequently Asked Questions (Doc ID 227334.1)
So please perform time changes in small amount using date command only. Doing it precisely will be difficult manually. Therefore using ntpd with -x option could be better solution for this case as well.
In general step in not more than 3 seconds when tuning time backward should be fine.
Can you kindly define and explain of lock_sga parameter?each flatform(HP, IBM, SUN) recommended value of both parameter
and why it is recommended like that value.
LOCK_SGA locks the entire SGA into physical memory. It is usually advisable to lock the SGA into real (physical) memory, especially if the use of virtual memory would include storing some of the SGA using disk space. This parameter is ignored on platforms that do not support it.
Each platform has its own recommendations and support over the parameter value. Hence you would see differences in the recommendations.
+ lock_sga Only locks the entire SGA into physical memory.
+ It can be set to TRUE as long as you want to lock the entire SGA in the physical memeory and your OS supports it. As for as i know it works in all the platforms.
LOCK_SGA locks the entire SGA into physical memory. It is usually advisable to lock the SGA into real (physical) memory, especially if the use of virtual memory would include storing some of the SGA using disk space.
NOTE:: This parameter is ignored on platforms that do not support it.
+ Windows For sure doesn’t support this parameter.
+ AIX Supports it.
+ LOCK_SGA is not supported on Solaris.
+ On Hp-UX if you have mlock (OS privilege) then LOCK_SGA is not required
+ Linux also supports this parameter
You can also review
Note 577898.1 – ORA-27102 Received At Startup When LOCK_SGA Is Set Although Enough Memory Is Available.
lock_sga: Default value: false.
If set to true, the entire SGA will be locked into physical memory (preventing it from being paged out). This may cause problems on systems with insufficient physical memory.
The parameters (and recommendations) are Unix generic.
The lock_sga parameter (which default AND recommended value is false): If you have sufficient memory on the server, you may consider setting it to true. (Forcing the SGA to be locked in physical memory).
On the other hand, if lock_sga is set to true, and you do not have suffficient memory, the SGA will stay in memory, and force other processe, like server processes to swap, and hence cause performance degradation.
For both the hidden and normal configuration parameters, we do not recommend deviations from the default values, without having detailed information on your specific configruation.
If you look at all Oracle products, options, features and parameters, there are billions of combinations. We do not have a complete catalog over each recommended values for each combiantion.
Can you kindly define and explain of this parameter?
_os_sched_high_priority
Regarding _os_sched_high_priority :
Setting LMS priority automatically via _os_sched_high_priority
It has been proven that performance is increased when LMS processes are running in the real time priority class, as opposed to the timesharing class. The parameter _os_sched_high_priority was introduced in Oracle 10g Release 2, and it allows LMS processes to be automatically configured in the real time priority class at instance startup. This feature basically obsoletes the need to manually set the real time priority for the LMS processes using a C program or the renice command.
On Unix platforms, process priority changes are normally executed under the root privilege, and the LMS process priority changes are implemented through an executable � oradism � owned by root with the setuid bit set.
The default value for _os_sched_high_priority in 10.2.0.1 is 1. With _os_sched_high_priority = 1, it means that all LMS processes are set to priority 1 in the real time class. We suggest to always set _os_sched_high_priority=1 in the init.ora, regardless of the default, and only toggle the behavior by restoring the original privileges and permissions on the oradism executable. Other possible values for this parameter are:
� If set to 0, LMS processes are not prioritized at startup, they are kept at the timesharing class as in earlier releases.
� Values higher than 1 give LMS higher priority in the real time class. Those settings are not recommended because they might cause starvation for other Oracle processes, leading to performance degradation.
If LMS processes remain in the timesharing class at instance startup, despite _os_sched_high_priority set to 1, then ownership and/or privileges for oradism may not have been set properly. To correct / verify these settings:
$ ls -l oradism
-rwsr-sr-x 1 root dba 15871 Jun 13 10:32 oradism
# chown root:dba oradism
# chmod 6755 oradism
Note about Linux process priorities:
SCHED_OTHER
static prio 0 : shows dynamic priorities with ‘ps’, ranging from 59-99
SCHED_RR / SCHED_FIFO
static prio 1 -> shows as priority 58 with ‘ps’
static prio 11 -> shows as priority 48 with ‘ps’
static prio 59 -> shows as priority 0 with ‘ps’
static prio 60 -> shows as priority -1 with ‘ps’
static prio 99 -> shows as priority -40 with ‘ps’ (highest RT priority)
On Linux, the LMS process priority can be seen via �ps �efl | grep lms�:
$ ps -efl|grep lms
0 S spommere 2201 1 0 58 0 – 285308 schedu 14:39 ? 00:00:00 ora_lms0_appsu01
0 S spommere 2205 1 0 58 0 – 285308 schedu 14:39 ? 00:00:00 ora_lms1_appsu01
In the above example, the LMS processes are running in the real-time class.
In the example below, the change in process prioritization failed, and the process priority remained at 75, because the permissions on the oradism executable were incorrectly set.
$ ps -efl | grep lms
0 S spommere 2002 1 1 75 0 – 285307 schedu 14:38 ? 00:00:00 ora_lms0_appsu01
0 S spommere 2006 1 1 75 0 – 285308 schedu 14:38 ? 00:00:00 ora_lms1_appsu01
Reference: internal Note 341974.1
Unpublished note 433105.1: ‘LMS Real Time Priority in RAC 10g Release 2 – Things to Consider Before Changing’.
_os_sched_high_priority: Default value is 1.
Setting it to 0 means that all scheduling class manipulation will be disabled.
The parameter is mainly ised in RAC systems, where you may want specific procecces like LMS to run at a higher priority.
Any underscore (hidden) parameters (like _os_sched_high_priority) should not be set unless specificly instructed by Support either via a Service Request or via a MetaLink Note. In all other cases, it’s default value should be used.
(You may see examples of notes by querying in MetaLink with the word _os_sched_high_priority).
v$lock是常用的enqueue lock队列锁动态性能视图,不管是用户自己部署的监控脚本也好、还是enterprise manager都多少会使用到该V$LOCK视图, 但是在10g中遇到了v$lock查询缓慢的问题, 例如下面的查询会等待较多direct path write temp等待事件:
select count(*) from v$lock;
COUNT(*)
----------
163
Elapsed: 00:00:60.90
Execution Plan
----------------------------------------------------------
Plan hash value: 2384831130
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 50 | 1 (100)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 50 | | |
|* 2 | HASH JOIN | | 1 | 50 | 1 (100)| 00:00:01 |
| 3 | MERGE JOIN CARTESIAN | | 100 | 3800 | 0 (0)| 00:00:01 |
|* 4 | FIXED TABLE FULL | X$KSUSE | 1 | 19 | 0 (0)| 00:00:01 |
| 5 | BUFFER SORT | | 100 | 1900 | 0 (0)| 00:00:01 |
| 6 | FIXED TABLE FULL | X$KSQRS | 100 | 1900 | 0 (0)| 00:00:01 |
| 7 | VIEW | GV$_LOCK | 10 | 120 | 0 (0)| 00:00:01 |
| 8 | UNION-ALL | | | | | |
|* 9 | FILTER | | | | | |
| 10 | VIEW | GV$_LOCK1 | 2 | 24 | 0 (0)| 00:00:01 |
| 11 | UNION-ALL | | | | | |
|* 12 | FIXED TABLE FULL| X$KDNSSF | 1 | 64 | 0 (0)| 00:00:01 |
|* 13 | FIXED TABLE FULL| X$KSQEQ | 1 | 64 | 0 (0)| 00:00:01 |
|* 14 | FIXED TABLE FULL | X$KTADM | 1 | 64 | 0 (0)| 00:00:01 |
|* 15 | FIXED TABLE FULL | X$KTATRFIL | 1 | 64 | 0 (0)| 00:00:01 |
|* 16 | FIXED TABLE FULL | X$KTATRFSL | 1 | 64 | 0 (0)| 00:00:01 |
|* 17 | FIXED TABLE FULL | X$KTATL | 1 | 64 | 0 (0)| 00:00:01 |
|* 18 | FIXED TABLE FULL | X$KTSTUSC | 1 | 64 | 0 (0)| 00:00:01 |
|* 19 | FIXED TABLE FULL | X$KTSTUSS | 1 | 64 | 0 (0)| 00:00:01 |
|* 20 | FIXED TABLE FULL | X$KTSTUSG | 1 | 64 | 0 (0)| 00:00:01 |
|* 21 | FIXED TABLE FULL | X$KTCXB | 1 | 64 | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
direct path write temp
direct path write temp
direct path write temp
................
显然仅返回100多条记录的v$LOCK视图的查询不该这么慢,也不该由SORT或HASH造成大量的临时空间使用, 究其根本还是FIXED TABLE即X$的内部表上的统计信息不准确导致的执行计划使用,通过使用RULE HINT可以马上获得较好的性能:
select /*+ RULE */ count(*) from v$LOCK;
COUNT(*)
----------
190
Elapsed: 00:00:00.18
Execution Plan
----------------------------------------------------------
Plan hash value: 2026431807
-------------------------------------------------
| Id | Operation | Name |
-------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | SORT AGGREGATE | |
| 2 | MERGE JOIN | |
| 3 | SORT JOIN | |
| 4 | MERGE JOIN | |
| 5 | SORT JOIN | |
| 6 | FIXED TABLE FULL | X$KSQRS |
|* 7 | SORT JOIN | |
| 8 | VIEW | GV$_LOCK |
| 9 | UNION-ALL | |
|* 10 | FILTER | |
| 11 | VIEW | GV$_LOCK1 |
| 12 | UNION-ALL | |
|* 13 | FIXED TABLE FULL| X$KDNSSF |
|* 14 | FIXED TABLE FULL| X$KSQEQ |
|* 15 | FIXED TABLE FULL | X$KTADM |
|* 16 | FIXED TABLE FULL | X$KTATRFIL |
|* 17 | FIXED TABLE FULL | X$KTATRFSL |
|* 18 | FIXED TABLE FULL | X$KTATL |
|* 19 | FIXED TABLE FULL | X$KTSTUSC |
|* 20 | FIXED TABLE FULL | X$KTSTUSS |
|* 21 | FIXED TABLE FULL | X$KTSTUSG |
|* 22 | FIXED TABLE FULL | X$KTCXB |
|* 23 | SORT JOIN | |
|* 24 | FIXED TABLE FULL | X$KSUSE |
-------------------------------------------------
针对上述问题考虑为FIXED TABLE收集统计信息,可以使用DBMS_STATS.GATHER_FIXED_OBJECTS_STATS标准存储过程,特别是对于版本升级上来的数据库,特别需要考虑执行该存储过程更新FIXED TABLE STATISTICS:
SQL> set timing on; SQL> exec DBMS_STATS.GATHER_FIXED_OBJECTS_STATS; PL/SQL procedure successfully completed. Elapsed: 00:01:24.87
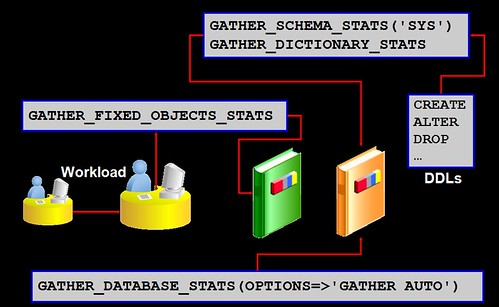
Create fixed table statistics
Directly after catupgrd.sql has been completed
This will speed up processing for recompilation with utlrp.sql
Create fixed table statistics again after a week with regular production workload
This task should be done only a few times per year
