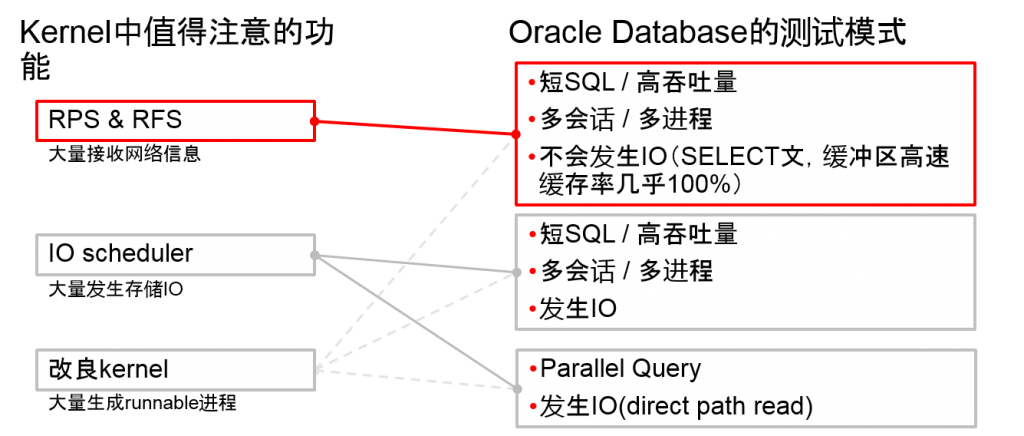
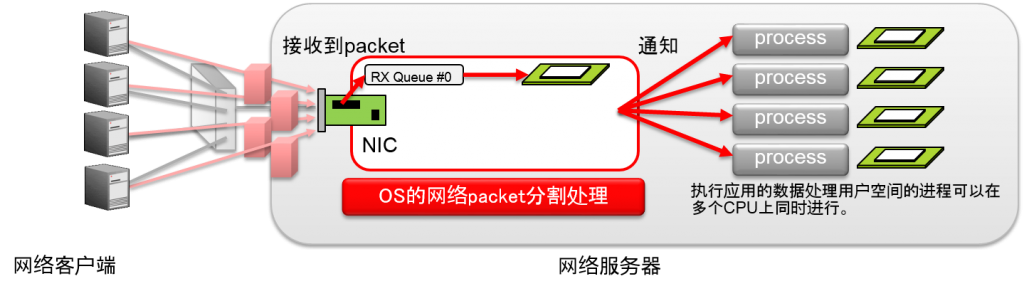
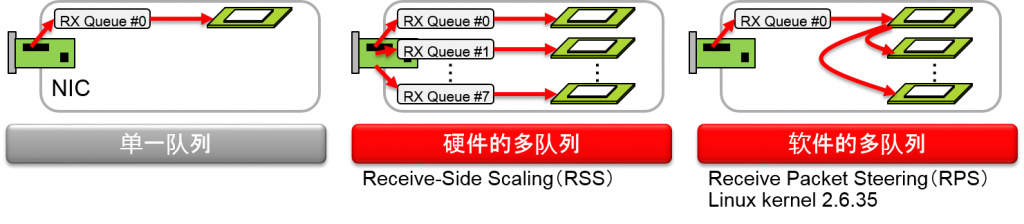
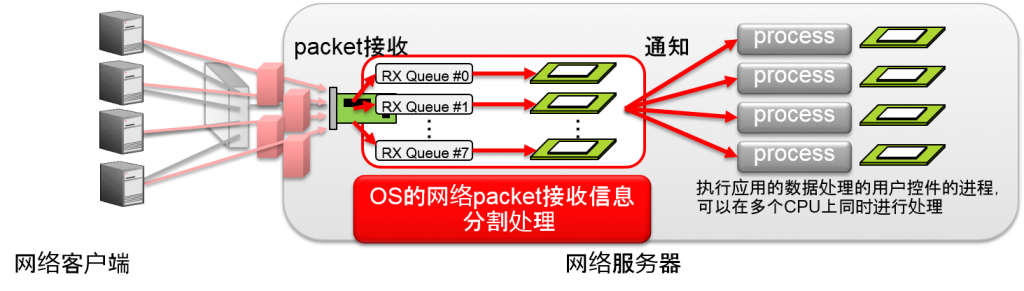
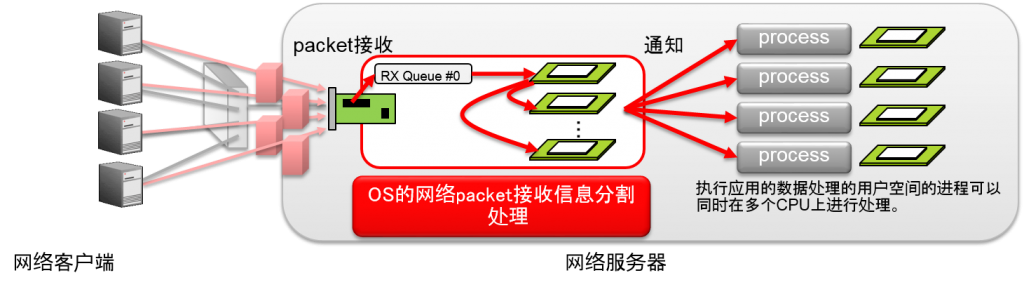
介绍
当我在浏览网页关注一些我定期访问网站的更新时,我发现Tom Hayden的一篇很酷的文章,使用Amazon Elastic Map Reduce(EMR)和mrjob,以计算从millionbase archive下载的象棋游戏的输赢率,慢慢地从中发现乐趣。由于数据量仅约为1.75GB,含200万左右的国际象棋游戏,我不确定他为何使用Hadoop,但我能理解他的目标,从mrjob和EMR中学习并获得乐趣。既然问题基本上只是看每个文件的resultl lines和汇总不同的结果,似乎非常适合shell命令的流处理。我试着用相同的数据量处理,我的笔记本电脑得到结果只需12秒左右(处理速度约为270MB /秒),而Hadoop处理了约26分钟(处理速度约1.14MB /秒)。
在报告用7 c1. machine在集群中处理数据所需要的时间为26分钟,汤姆写到:“这可能比在我的机器上按顺序运行快,但如果我做了一些聪明的本地多线程应用程序可能更好。”