支援金蝶EAS客户案例:
案例一:某粮企easdba数据库断电异常恢复
晚上18:00接到哈尔滨分公司电话,说是某粮企的数据库由于异常断电不能启动。
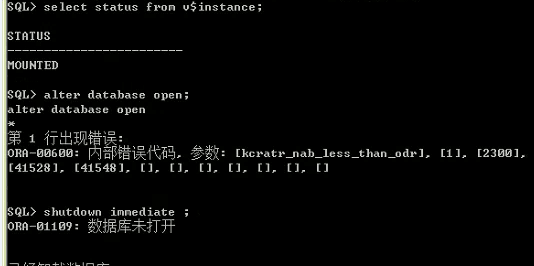
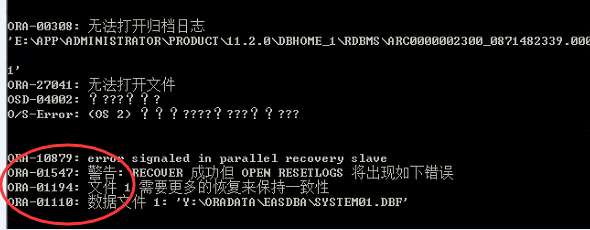
经过验证诊断,分析发现是数据库由于异常断电,数据块有损坏,oracle启动异常保护机制,不能常规启动数据库,报错ORA-600,ORA-01109,ORA-01194,ORA-01110等相关内部错误,而且指明损坏的块位于oracle的核心数据文件system(见下图)。
经过判断此类问题需要特殊恢复,本着负责任的态度,某粮企的客户去寻找上海诗檀这家专业的技术公司来解决此问题。成功帮客户恢复了数据,挽回了损失,数据回复率到达99%。
案例二:XX集团oracle ASM异常导致不能读到存储
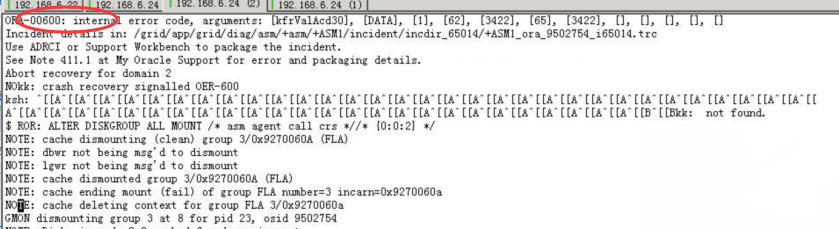
2016/3/22,接到分公司反馈,XX集团的数据库AIX服务器,重启之后,数据库不能启动,ASM实例不能读取到存储卷的信息。报错ora-600,报错的原因是asm控制文件的文件头冲突,导致文件不一致性导致,此类问题是属于oracle核心内部的文件不一致性导致,需要修改底层逻辑文件头为正确的值。常规手段不能解决,金蝶也不能为客户解决此问题。
经过推荐,让客户联系了上海诗檀这家公司,这家公司有能力解决这个问题,现在和的客户正处于合同洽谈阶段。
Parnassusdata 诗檀软件公司介绍
专业性
ORACLE ACE
原服务于Oracle原厂的数据库专家组成
独特性
除Oracle原厂服务团队ACS之外,中国大陆市场上,真正有能力进行底层级别的维护公司不超过2家
诗檀软件专家有能力为客户提供最终保证
业务范围
数据库恢复业务,灾难恢复
数据库性能乃至整体架构的调优
7*24数据库紧急求助服务等
磁盘掉电引起的大量坏块导致数据库无法启动.
公司介绍
公司网站:http://www.parnassusdata.com/oracle-recovery-landing/index.html
公司地址: 上海市共和新路1988号10座610室(为商务写字楼,门口在大宁路上)
服务咨询热线: 13764045638
港澳台热线: +86 13764045638
service@parnassusdata.com(技术支持首选)