MySQLサーバのMyISAMテーブルをこわれた原因はなんでしょうか?
適用範囲:
MySQLサーバー – バージョン:4.0〜5.5 – リリース:5.5
MySQLサーバ – バージョン:4.0 – リリース:4.0
MySQLサーバー – バージョン:4.0〜5.5 – リリース:4.0〜5.5
すべてのプラットフォーム
目標
MyISAMテーブルがこわれた具体的な原因を説明する。
解決策
MyISAM ストレージエンジンは非常に頼りになる。もしMyISAMテーブルがよく壊れることがあれば、それについての原因を考えてください。データを検索するときに、以下のエラが現れたとはテーブルがこわれたと意味する:
Error 1034 Incorrect key file for table: ‘…’. Try to repair it
あるいは以下のエラ番号を含んだ情報:
Error 126 = Index file is crashed
Error 127 = Record-file is crashed
Error 134 = Record was already deleted (or record file crashed)
Error 144 / Error 1195 = Table is crashed and last repair failed
Error 145 / Error 1194 = Table was marked as crashed and should be repaired
当查询本该查找到在表中的行但没有找到,或当一个查询返回不完整的数据,也可以假定发生了损坏。你可以使用CHECK TABLE 语句来验证MyISAM 表是否损坏。テーブルにあるはずの行が検出されないときあるいは不完全なデータが返されたときに、こわれたと推定してもいいと思う。また、CHECK TABLE文でMyISAMテーブルがこわれたかを確認できる。
MyISAMをこわれた原因はいろいろあるが、可能性大きいから小さいまでの順で、以下の通り:
- サーバシャットダウンあるいはハードウェアエラによる損害:
- 書き込む途中で、mysqldプロセスが閉められるあるいは壊れる。
- 電源エラでMySQLを運用するサーバ閉められて、壊れるかもしれない。
- ハードウェアエラによるもの可能性もある。例えば、サーバのトラブル。
- RAMの損害;ディスクを再起動して解決できる。操作システムのメモリーに壊れたデータがあれば、時に再起動して解決できる。これは極めてレアなトラブルが、ハードウェアにトラブルがあれば、起こる頻度が上がる。
サーバが再起動するときに、自動リカバリがこのトラブルを解決するが、時にはREPAIR TABLE SQL文あるいはより高等なテストオプションを使う必要がある。テーブルが巨大で、サーバがアウトラインより早いリカバリオプションがある場合にmyisamchkを使ってください。いろんなCPUコールがあって、それにテーブルにインディクスがいっぱいある場合に、より速くなるために、myisamchkオプションででマルチスレッドを使ってください。このオプションが失敗するときに報告されるから、見つけ出したが、一つのスレッドを使っているという状況はあまりないです。
2.ほかのプログラムによる損害
- Myisamchkのような外部プログラムを使うと、サーバが運用する途中に変更されるから、よくこわされる。
- 一部のアンチウイルスソフトウェアも損害を及ぼす、ときに古いテーブルをリカバリしたあるいは必要なファイルをテストしたから、損害を及ぼした。
これらの状況を解決する根本的な策は、どんなファイルを変更されたかを見つけ出す。テーブルをリカバリするのは一時的な方法である。
- bugによる損害
- 2007の夏前のバーションサーバ構造を使ってください。2006年から2007までMySQLはシステムテストを実行して、レアでコピしにくいMyISAM損害bugを探し出した・おおよそ2007の夏で、bugに関連するトラブルはほぼ全部は古いバーションにある。リカバリ機能が強いバーションはあまり影響されていないから、バーションをアップグレードしてください。
- もしbugがまだ損害を及ぼすなら、まずは最近に導入したサーバ機能を確認してください。
最近再起動したmysqldを検索して、テーブルの損害はサーバシャットダウンによるものかを確認できる。何のエラ情報もない、それに損害が正常なオペレーション期間に起こっているであればbugが原因かもしれない。コピできるテストを作成してトラブルを探し出す。My Oracle SupportでSupport Requestを使って、トラブルを報告してください。Mysqldを運用されていない場合に、myisamchkコマンドでテーブルをテストしてリカバリできる。
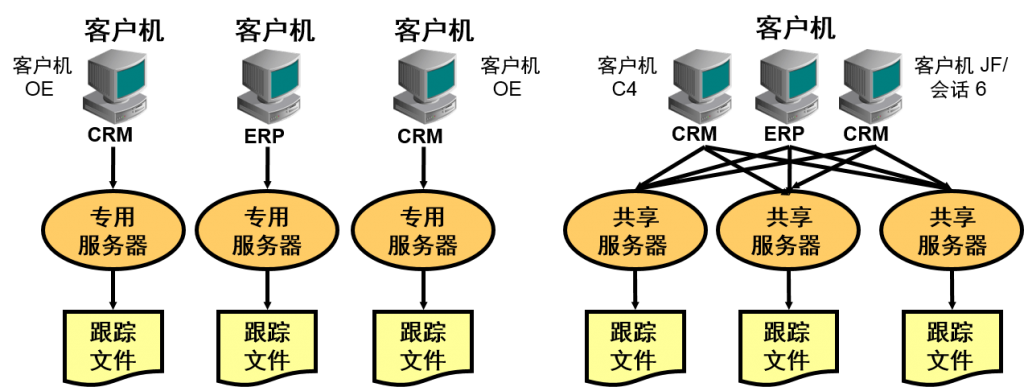
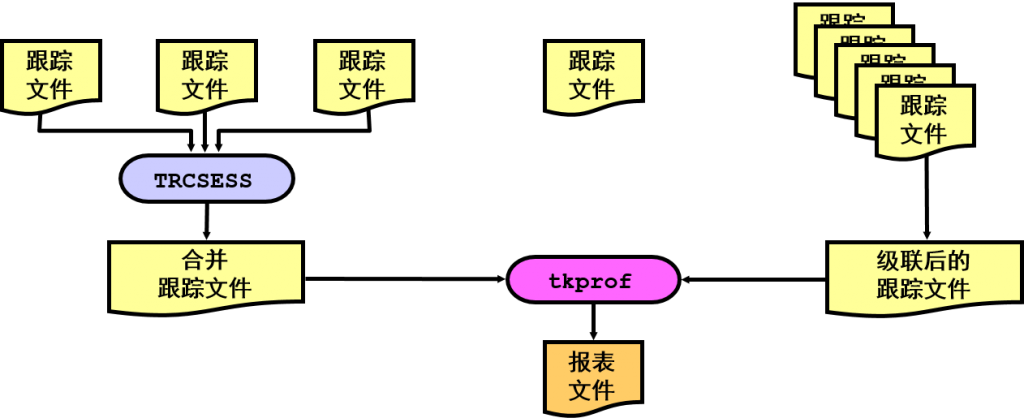
![trcsess [output=output_file_name]](https://www.askmac.cn/wp-content/uploads/2015/12/trcsess-outputoutput_file_name.png)