PRM-DUL ORACLE 数据恢复软件总贴PRM-DUL 是一个基于JAVA语言编写的DUL类软件,其引入了图形化界面GUI和DataBridge特性。 全程GUI使得用户无需大量时间去学习命令行操作,直接可操作PRM-DUL从受损的ORACLE数据库中抽取数据。 DataBridge特性让抽取到的受损数据库的数据可以直接导入到目标库中,像DBLINK一样简单,而不需要使用sqlldr 或者 exp/imp来操作。PRM-DUL目前有2个版本: 社区版: 在完全免费的社区版中,数据抽取和数据搭桥的行数限制是一万行。ASM文件克隆功能在社区版中全面可用。企业版: 购买企业版意味在一套数据库(一个license对应一套数据库)内完全使用PRM的所有功能,没有任何限制购买PRM-DUL,请联系我们:国内热线号码: 13764045638 备用电话:13764045638 ORACLE技术专家服务邮箱: service@parnassusdata.com PRM-DUL 最新版本下载地址:
PRM-DUL 中文版用户手册: PRM-DUL For Oracle Database中文介绍: PRM-DUL FOr Oracle Database 英文版使用手册: PRM-DUL成功案例:
PRM ORACLE数据恢复视频教学:
prm dul恢复oracle数据库最简模式 http://zcdn.parnassusdata.com/prm%20dul%20recover%20oracle%20database%20easiest%20way.mp4
|
PRM-DUL ORACLE 数据恢复软件总贴
ORACLE数据字典受损导致数据库无法打开的恢复 PRM-DUL
D 公司的DBA由于误操作删除了TS$数据字典基表导致数据库无法启动
| Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 – 64bit Production
With the Partitioning, Automatic Storage Management, OLAP, Data Mining and Real Application Testing options
INSTANCE_NAME —————- ASMME
SQL> SQL> SQL> select count(*) from sys.ts$;
COUNT(*) ———- 5
SQL> delete ts$;
5 rows deleted.
SQL> commit;
Commit complete.
SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut down.
Database mounted. ORA-01092: ORACLE instance terminated. Disconnection forced ORA-01405: fetched column value is NULL Process ID: 5270 Session ID: 10 Serial number: 3
Undo initialization errored: err:1405 serial:0 start:3126020954 end:3126020954 diff:0 (0 seconds) Errors in file /s01/diag/rdbms/asmme/ASMME/trace/ASMME_ora_5270.trc: ORA-01405: fetched column value is NULL Errors in file /s01/diag/rdbms/asmme/ASMME/trace/ASMME_ora_5270.trc: ORA-01405: fetched column value is NULL Error 1405 happened during db open, shutting down database USER (ospid: 5270): terminating the instance due to error 1405 Instance terminated by USER, pid = 5270 ORA-1092 signalled during: ALTER DATABASE OPEN… opiodr aborting process unknown ospid (5270) as a result of ORA-1092
|
此场景中由于数据字典已经损坏,所以想要正常打开数据库是十分困难的。
此时则可以使用PRM来抽取数据库中的数据。具体步骤与场景1中的相似,用户仅仅需要输入该数据库的所有数据文件即可,其简要步骤如下:
- Recovery Wizard
- 选择字典模式 Dictionary Mode
- 合理选择Big或者Little Endian
- 加入数据文件并点击Load
- 根据实际需求恢复表中的数据
Undelete MySQL如何从InnoDB表空间恢复被删除的行
在我以前的文章中,我解释了它如何在某些特定情况下,从一个完整备份恢复单个表,以节省时间,使恢复过程更简单。现在的情况更糟糕,因为我们没有备份或备份恢复过程不起作用。我如何恢复已删除的行?
我们将根据之前帖子中相同的例子,所以我们需要从表“salaries”中删除员工10008的记录。“意外”删除行之后,你应该停止MySQL,获取salaries.ibd的副本,并再次启动它。稍后,我们将从ibd文件提取这些被删除的行,并导入到数据库中。删除行和数据库停止之间的时间是至关重要的。如果页被重用,你无法恢复数据。
我要通过四个步骤解释全过程,以便更清晰明了:
从表空间提取所有InnoDB页:
首先我们需要下载Percona数据恢复工具并使用“make”命令编译所有工具。在本例中,我要在/root/recovery-tool文件夹安装工具,数据如表空间和被恢复行在/root/recovery-tool/data。
编译后,我们需要将salaries.ibd表空间复制到恢复工具的数据目录。为了提取的所有页,我们将使用page_parser工具。该工具会找到并将表空间的所有页提取到输出目录。我们只需要指定行格式(-5),以及表空间位置(-f)
The row format can be -4 (REDUNDANT) or -5 (COMPACT). From 5.0.3 the default format is COMPACT. More information about row format on the following link: 行格式可以是-4(冗余)或-5(COMPACT)。从5.0.3起,默认格式是COMPACT。
你也能从Information Schema获取表行格式:
mysql (information_schema) > SELECT ROW_FORMAT from TABLES WHERE TABLE_SCHEMA='employees' AND TABLE_NAME='salaries'; +------------+ | ROW_FORMAT | +------------+ | Compact | +------------+ ~/recovery-tool# ./page_parser -5 -f data/salaries.ibd Opening file: data/salaries.ibd: [...] 71.43% done. 2012-02-14 13:10:08 ETA(in 00:00 hours). Processing speed: 104857600 B/sec
所有页都储存在单个目录,其中有一些子目录,一页对应表中一个索引:
~/recovery-tool# ls pages-1329221407/FIL_PAGE_INDEX/ 0-26 0-27
在这种情况下,ID 0-26和0-27有两个索引。 InnoDB有聚集主键,即数据与主键一起组织。因此,如果我们要提取行数据,我们需要确定哪两个索引是主键。这是我们的下一步。
标识主键
有不同的方法来找到正确索引,在这里我要解释其中三个:
INNODB_SYS_INDEXES
Percona Server 在INFORMATION_SCHEMA 有一些额外的表,可以帮助我们找到不同的索引和类型。
mysql (information_schema) > select i.INDEX_ID, i.NAME FROM INNODB_SYS_INDEXES as i INNER JOIN INNODB_SYS_TABLES as t USING(TABLE_ID) WHERE t.NAME='salaries'; +----------+---------+ | INDEX_ID | NAME | +----------+---------+ | 26 | PRIMARY | | 27 | emp_no | +----------+---------+
InnoDB Table Monitor表监视器
索引信息也可以直接从MySQL获取,使用 InnoDB Tablespace Monitor。这个监视器将与表和索引(与它们的ID)相关所有信息写入错误日志中。
mysql (employees) > CREATE TABLE innodb_table_monitor (id int) ENGINE=InnoDB; TABLE: name employees/salaries, id 18, flags 1, columns 7, indexes 2, appr.rows 2844513 [...] INDEX: name PRIMARY, id 26, fields 2/6, uniq 2, type 3 root page 3, appr.key vals 2844513, leaf pages 6078, size pages 6120 FIELDS: emp_no from_date DB_TRX_ID DB_ROLL_PTR salary to_date INDEX: name emp_no, id 27, fields 1/2, uniq 2, type 0 root page 4, appr.key vals 306195, leaf pages 2189, size pages 2212 FIELDS: emp_no from_date [...]
第二个方法得到相同的结果, 0-26 是我们的主键。标识主键后,不要忘了删除innodb_table_monitor。
检查磁盘上每个索引的大小
这非常依赖表模式,但通常主键在磁盘上更大,因为它也存储行本身的。
~/recovery-tool/pages-1329221407/FIL_PAGE_INDEX# du -hs 0-26/ 96M 0-26/ ~/recovery-tool/pages-1329221407/FIL_PAGE_INDEX# du -hs 0-27/ 35M 0-27/
在我们的例子中,0-26 看上去是主键。
提取行
我们知道了数据在哪个索引,所以下一步显然是从中提取行。要完成这个任务,我们要使用constraint_parser命令。为了使用它,工具需要知道表schema结构,即列的类型,名称和属性。这个信息需要在头文件 recovery-tools/include/table_defs.h可用。所以重新编译工具将是必要的。
要将schema定义转换为C头文件,可以使用名为create_defs.pl的工具。它会连接到数据库,以便检查表并创建table_defs.h内容。
~/recovery-tool# ./create_defs.pl –host 127.0.0.1 –port 5520 –user root –password msandbox –db employees –table salaries > include/table_defs.h
有关table_defs.h格式的详细信息在以下链接: https://www.percona.com/docs/wiki/innodb-data-recovery-tool:mysql-data-recovery:generating_a_table_definition
有了table_defs.h表定义,我们就要用“make”命令重新编译所有的工具。编译后,我们可以使用constraints_parser将行恢复为人类可读格式。
~/recovery-tool# ./constraints_parser -5 -D -f pages-1329221407/FIL_PAGE_INDEX/0-26/ > data/salaries.recovery
通过 -D 选项,我们请求 constraints_parser 只恢复被删除的页。-5 和 -f 是我们在page_parser之前使用的相同选项。
你能在salaries.recovery 中找到许多被删除的行,不仅是意外删除的行。你应当收到找出需要恢复的行并将它储存在其他文件中。这是例子的输出
~/data-recovery# cat data/salaries.recovery salaries 10008 "1998-03-11" 46671 "1999-03-11" salaries 10008 "1999-03-11" 48584 "2000-03-10" salaries 10008 "2000-03-10" 52668 "2000-07-31"
导入行
有了这些数据,最后一步就是将它们导入到数据库:
mysql (employees) > LOAD DATA INFILE '/root/recovery-tool/data/salaries.recovery' REPLACE INTO TABLE `salaries` FIELDS TERMINATED BY '\t' OPTIONALLY ENCLOSED BY '"' LINES STARTING BY 'salaries\t' (emp_no, from_date, salary, to_date); Query OK, 3 rows affected (0.01 sec) Records: 3 Deleted: 0 Skipped: 0 Warnings: 0 mysql (employees) > select * from salaries where emp_no=10008; +--------+--------+------------+------------+ | emp_no | salary | from_date | to_date | +--------+--------+------------+------------+ | 10008 | 46671 | 1998-03-11 | 1999-03-11 | | 10008 | 48584 | 1999-03-11 | 2000-03-10 | | 10008 | 52668 | 2000-03-10 | 2000-07-31 | +--------+--------+------------+------------+
数据恢复成功!10008 再次恢复了它的工资。
结论
通过InnoDB,被删除的行没有丢失。你可以从原始表空间恢复,或者如果你有二进制备份,也能从ibd文件中恢复它们。只需使用constraint_parser不加-D选项(被删除),你就能恢复所有在表空间中的数据。
如果自己搞不定可以找诗檀软件专业ORACLE/MySQL数据库修复团队成员帮您恢复!
诗檀软件专业数据库修复团队
服务热线 : 13764045638 QQ号:47079569 邮箱:service@parnassusdata.com
MySQL中恢复/修复InnoDB数据字典
c_parser 是工具包中的一个命令行工具,它能读取 InnoDB 页面并从中获取记录。虽然它可以扫描任何字节流,但恢复质量比你将属于表的PRIMARY索引的页面提供给 c_parser 更高。所有InnoDB索引有自己的标识符,又名index_id。InnoDB字典储存表名和index_id之间的对应关系。这是第一个原因。
另一个原因是InnoDB字典能恢复表结构。当一个表被删除,MySQL删除相应的.frm文件。如果你既没有备份,又没有表schema,恢复该表结构就有相当大的困难。这个话题需要我哪天再写一篇单独的文章来讲。
假设你对以上足够确信,我们就能继续InnoDB字典的恢复了。
拆分 ibdata1
InnoDB 字段储存在 ibdata1中,所以我们需要分析它并获取存放字典记录的页面。使用 stream_parser 。
# ./stream_parser -f /var/lib/mysql/ibdata1 ... Size to process: 79691776 (76.000 MiB) All workers finished in 1 sec
stream_parser 找出在ibdata1 中的InnoDB 页面,将它们以页面类型(FIL_PAGE_INDEX 或FIL_PAGE_TYPE_BLOB) , index_id.的顺序储存。
索引如下:
SYS_TABLES [root@twindb-dev undrop-for-innodb]# ll pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page -rw-r--r-- 1 root root 16384 Jun 24 00:50 pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page SYS_INDEXES [root@twindb-dev undrop-for-innodb]# ll pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page -rw-r--r-- 1 root root 16384 Jun 24 00:50 pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page SYS_COLUMNS [root@twindb-dev undrop-for-innodb]# ll pages-ibdata1/FIL_PAGE_INDEX/0000000000000002.page -rw-r--r-- 1 root root 49152 Jun 24 00:50 pages-ibdata1/FIL_PAGE_INDEX/0000000000000002.page 和 SYS_FIELDS [root@twindb-dev undrop-for-innodb]# ll pages-ibdata1/FIL_PAGE_INDEX/0000000000000004.page -rw-r--r-- 1 root root 16384 Jun 24 00:50 pages-ibdata1/FIL_PAGE_INDEX/0000000000000004.page
可以看到字典较小,每个索引只有一页。
从 SYS_TABLES 和 SYS_INDEXES转储(dump)记录
要从索引页提取记录,你需要使用 c_parser。但首先,我们来创建转储的目录:
[root@twindb-dev undrop-for-innodb]# mkdir -p dumps/default [root@twindb-dev undrop-for-innodb]#
InnoDB 字典总是 REDUNDANT 格式,所以选项 -4 是强制的:
[root@twindb-dev undrop-for-innodb]# ./c_parser -4f pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page -t dictionary/SYS_TABLES.sql > dumps/default/SYS_TABLES 2> dumps/default/SYS_TABLES.sql [root@twindb-dev undrop-for-innodb]#
这是我们的sakila 表:
[root@twindb-dev undrop-for-innodb]# grep sakila dumps/default/SYS_TABLES | head -5 0000000052D5 D9000002380110 SYS_TABLES "sakila/actor" 753 4 1 0 80 "" 739 0000000052D8 DC0000014F0110 SYS_TABLES "sakila/address" 754 8 1 0 80 "" 740 0000000052DB DF000002CA0110 SYS_TABLES "sakila/category" 755 3 1 0 80 "" 741 0000000052DE E2000002F80110 SYS_TABLES "sakila/city" 756 4 1 0 80 "" 742 0000000052E1 E5000002C50110 SYS_TABLES "sakila/country" 757 3 1 0 80 "" 743 [root@twindb-dev undrop-for-innodb]#
dumps/default/SYS_TABLES 是符合 LOAD DATA INFILE命令的表转储。具体命令 c_parsers 打印到标准错误输出。我将它保存在dumps/default/SYS_TABLES.sql
[root@twindb-dev undrop-for-innodb]# cat dumps/default/SYS_TABLES.sql SET FOREIGN_KEY_CHECKS=0; LOAD DATA INFILE '/root/tmp/undrop-for-innodb/dumps/default/SYS_TABLES' REPLACE INTO TABLE `SYS_TABLES` FIELDS TERMINATED BY '\t' OPTIONALLY ENCLOSED BY '"' LINES STARTING BY 'SYS_TABLES\t' (`NAME`, `ID`, `N_COLS`, `TYPE`, `MIX_ID`, `MIX_LEN`, `CLUSTER_NAME`, `SPACE`); [root@twindb-dev undrop-for-innodb]# 我们以相同方式转储 SYS_INDEXES: [root@twindb-dev undrop-for-innodb]# ./c_parser -4f pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page -t dictionary/SYS_INDEXES.sql > dumps/default/SYS_INDEXES 2> dumps/default/SYS_INDEXES.sql [root@twindb-dev undrop-for-innodb]# [root@twindb-dev undrop-for-innodb]# head -5 dumps/default/SYS_INDEXES -- Page id: 11, Format: REDUNDANT, Records list: Valid, Expected records: (153 153) 000000000300 800000012D0177 SYS_INDEXES 11 11 "ID\_IND" 1 3 0 302 000000000300 800000012D01A5 SYS_INDEXES 11 12 "FOR\_IND" 1 0 0 303 000000000300 800000012D01D3 SYS_INDEXES 11 13 "REF\_IND" 1 0 0 304 000000000300 800000012D026D SYS_INDEXES 12 14 "ID\_IND" 2 3 0 305 [root@twindb-dev undrop-for-innodb]# head -5 dumps/default/SYS_INDEXES.sql SET FOREIGN_KEY_CHECKS=0; LOAD DATA INFILE '/root/tmp/undrop-for-innodb/dumps/default/SYS_INDEXES' REPLACE INTO TABLE `SYS_INDEXES` FIELDS TERMINATED BY '\t' OPTIONALLY ENCLOSED BY '"' LINES STARTING BY 'SYS_INDEXES\t' (`TABLE_ID`, `ID`, `NAME`, `N_FIELDS`, `TYPE`, `SPACE`, `PAGE_NO`); [root@twindb-dev undrop-for-innodb]#
现在用字典操作了,如果表在MySQL中会更方便。
将字典表加载到 MySQL中
SYS_TABLES 和 SYS_INDEXES 的主要用途是根据表名获取 index_id。运行两个 greps是可能的。SYS_TABLES 和 SYS_INDEXES 在MySQL中会使操作更简便。
Before we can process let’s make sure mysql user can read from the root’s home directory. Maybe it’s not wise from security standpoint. If it’s your concern create whole recovery environment somewhere in /tmp. 在操作之前,我们要确保MySQL用户可以从root的主目录中读取。从安全角度来看,这也许不太明智。如果你对此有所顾虑,你可以在/ tmp目录某处创建整个恢复环境。
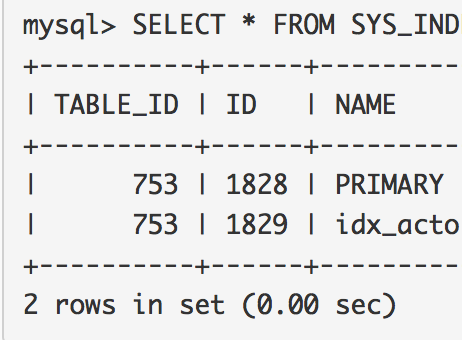
[root@twindb-dev undrop-for-innodb]# chmod 711 /root/ [root@twindb-dev undrop-for-innodb]# 在某些数据库中创建空字典表(例: test) [root@twindb-dev undrop-for-innodb]# mysql test < dictionary/SYS_TABLES.sql 在某些数据库中创建空字典表(例: test) [root@twindb-dev undrop-for-innodb]# mysql test < dictionary/SYS_TABLES.sql 并加载转储数据: [root@twindb-dev undrop-for-innodb]# mysql test < dumps/default/SYS_TABLES.sql [root@twindb-dev undrop-for-innodb]# mysql test < dumps/default/SYS_INDEXES.sql [root@twindb-dev undrop-for-innodb]# 现在InnoDB 字典在MySQL 中,我们能以在任何其他MySQL表中的方式查询它: mysql> SELECT * FROM SYS_TABLES WHERE NAME = 'sakila/actor'; +--------------+-----+--------+------+--------+---------+--------------+-------+ | NAME | ID | N_COLS | TYPE | MIX_ID | MIX_LEN | CLUSTER_NAME | SPACE | +--------------+-----+--------+------+--------+---------+--------------+-------+ | sakila/actor | 753 | 4 | 1 | 0 | 80 | | 739 | +--------------+-----+--------+------+--------+---------+--------------+-------+ 1 row in set (0.00 sec) mysql> SELECT * FROM SYS_INDEXES WHERE TABLE_ID = 753; +----------+------+---------------------+----------+------+-------+---------+ | TABLE_ID | ID | NAME | N_FIELDS | TYPE | SPACE | PAGE_NO | +----------+------+---------------------+----------+------+-------+---------+ | 753 | 1828 | PRIMARY | 1 | 3 | 739 | 3 | | 753 | 1829 | idx_actor_last_name | 1 | 0 | 739 | 4 | +----------+------+---------------------+----------+------+-------+---------+ 2 rows in set (0.00 sec)
我们看到sakila.actor 有两个索引: PRIMARY 和idx_actor_last_name。index_id 分别是1828 和1829。
如果自己搞不定可以找诗檀软件专业ORACLE/MySQL数据库修复团队成员帮您恢复!
诗檀软件专业数据库修复团队
服务热线 : 13764045638 QQ号:47079569 邮箱:service@parnassusdata.com
Undrop MySQL InnoDB 中恢复被drop的表,当 innodb_file_per_table=off时
人为错误是不可避免的。错误的 “DROP DATABASE” 或 “DROP TABLE” 可能会破坏MySQL 服务器上的重要数据。备份是有帮助的,但不总是可用。这种情况是可怕的,但不至于没有希望的。在许多情况下,恢复几乎所有在数据库或表中的数据是有可能的。
我们来看看如何能做到这一点。恢复计划取决于InnoDB将所有数据储存在单个ibdata1还是每个表都有自己的表空间。在这篇文章中,我们考虑innodb_file_per_table= OFF的情况下。此参数假定所有表都保存在一个公共文件中,通常位于位于/var/lib/mysql/ibdata1。
错误操作 – 表删除
在这个情况下,我们使用测试数据库sakila 以及附带的工具。
假设我们错误删除了表actor:
mysql> SELECT * FROM actor LIMIT 10; +----------+------------+--------------+---------------------+ | actor_id | first_name | last_name | last_update | +----------+------------+--------------+---------------------+ | 1 | PENELOPE | GUINESS | 2006-02-15 04:34:33 | | 2 | NICK | WAHLBERG | 2006-02-15 04:34:33 | | 3 | ED | CHASE | 2006-02-15 04:34:33 | | 4 | JENNIFER | DAVIS | 2006-02-15 04:34:33 | | 5 | JOHNNY | LOLLOBRIGIDA | 2006-02-15 04:34:33 | | 6 | BETTE | NICHOLSON | 2006-02-15 04:34:33 | | 7 | GRACE | MOSTEL | 2006-02-15 04:34:33 | | 8 | MATTHEW | JOHANSSON | 2006-02-15 04:34:33 | | 9 | JOE | SWANK | 2006-02-15 04:34:33 | | 10 | CHRISTIAN | GABLE | 2006-02-15 04:34:33 | +----------+------------+--------------+---------------------+ 10 rows in set (0.00 sec) mysql> CHECKSUM TABLE actor; +--------------+------------+ | Table | Checksum | +--------------+------------+ | sakila.actor | 3596356558 | +--------------+------------+ 1 row in set (0.00 sec) mysql> SET foreign_key_checks=OFF mysql> DROP TABLE actor; Query OK, 0 rows affected (0.00 sec) mysql>
从ibdata1中DROP TABLE后进行恢复
解析 InnoDB 表空间
InnoDB 将所有数据储存在B+tree 索引。一个表有一个集群索引PRIMARY,所有键都储存在其中。如果表有secondary 键,那每个键都有一个索引。每个索引由index_id标识。
如果我们要恢复表,必须找到属于特定index_id的所有页。
stream_parser 读取 InnoDB 表空间并根据类型和index_id排序InnoDB 页。
root@test:~/undrop-for-innodb# ./stream_parser -f /var/lib/mysql/ibdata1 Opening file: /var/lib/mysql/ibdata1 File information: ID of device containing file: 64768 inode number: 1190268 protection: 100660 (regular file) number of hard links: 1 user ID of owner: 106 group ID of owner: 114 device ID (if special file): 0 blocksize for filesystem I/O: 4096 number of blocks allocated: 69632 time of last access: 1404842312 Tue Jul 8 13:58:32 2014 time of last modification: 1404842478 Tue Jul 8 14:01:18 2014 time of last status change: 1404842478 Tue Jul 8 14:01:18 2014 total size, in bytes: 35651584 (34.000 MiB) Size to process: 35651584 (34.000 MiB) All workers finished in 0 sec root@test: ~/undrop-for-innodb#
数据库页的数据被stream_parser 储存在文件夹pages-ibdata1:
root@test:~/undrop-for-innodb/pages-ibdata1/FIL_PAGE_INDEX# ls 0000000000000001.page 0000000000000121.page 0000000000000382.page 0000000000000395.page 0000000000000408.page 0000000000000421.page 0000000000000434.page 0000000000000447.page 0000000000000002.page ... 0000000000000406.page 0000000000000419.page 0000000000000432.page 0000000000000445.page 0000000000000120.page 0000000000000381.page 0000000000000394.page 0000000000000407.page 0000000000000420.page 0000000000000433.page 0000000000000446.page root@test: ~/undrop-for-innodb/pages-ibdata1/FIL_PAGE_INDEX
Now each index_id from InnoDB tablespace is saved in a separate file. We can use c_parser to fetch records from the pages. But we need to know what index_id corresponds to table sakila/actor. That information we can acquire from the dictionary – SYS_TABLES and SYS_INDEXES. 现在InnoDB表空间的每个index_id被保存在单独的文件中。我们可以使用c_parser从页中提取记录。但是,我们需要知道什么index_id对应表中的Sakila/actor。我们可以从字典- SYS_TABLES SYS_INDEXES中获得这些信息。
SYS_TABLES 总是储存在文件 index_id 1中,即文件页-ibdata1/FIL_PAGE_INDEX./0000000000000001.page
我们来查找sakila/actor的table_id。如果MySQL 有足够时间将更改刷到磁盘,那添加 -D 参数表示“查找已删除记录”。字典总是REDUNDANT 格式,所以我们指定参数-4:
root@test:~/undrop-for-innodb# ./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page -t dictionary/SYS_TABLES.sql | grep sakila/actor 000000000B28 2A000001430D4D SYS_TABLES "sakila/actor" 158 4 1 0 0 "" 0 000000000B28 2A000001430D4D SYS_TABLES "sakila/actor" 158 4 1 0 0 "" 0
注意就在表名后的号码 158 。这就是table_id。
接下来是查找表actor的PRIMARY索引的索引id。为此,我们将从文件0000000000000003.page (该表包含index_id 和table_id的信息)获取SYS_INDEXES 的记录。SYS_INDEXES的结构由-t选项传递。 The structure of SYS_INDEXES is passed with -t option.
root@test:~/undrop-for-innodb$ ./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page -t dictionary/SYS_INDEXES.sql | grep 158 000000000B28 2A000001430BCA SYS_INDEXES 158 376 "PRIMARY" 1 3 0 4294967295 000000000B28 2A000001430C3C SYS_INDEXES 158 377 "idx\_actor\_last\_name" 1 0 0 4294967295 000000000B28 2A000001430BCA SYS_INDEXES 158 376 "PRIMARY" 1 3 0 4294967295 000000000B28 2A000001430C3C SYS_INDEXES 158 377 "idx\_actor\_last\_name" 1 0 0 4294967295
你能从输出中发现,必要的index_id 是376。因此我们要查找文件 0000000000000376.page中的actor数据。
root@test:~/undrop-for-innodb# ./c_parser -6f pages-ibdata1/FIL_PAGE_INDEX/0000000000000376.page -t sakila/actor.sql | head -5 -- Page id: 895, Format: COMPACT, Records list: Valid, Expected records: (200 200) 000000000AA0 B60000035D0110 actor 1 "PENELOPE" "GUINESS" "2006-02-15 04:34:33" 000000000AA0 B60000035D011B actor 2 "NICK" "WAHLBERG" "2006-02-15 04:34:33" 000000000AA0 B60000035D0126 actor 3 "ED" "CHASE" "2006-02-15 04:34:33" 000000000AA0 B60000035D0131 actor 4 "JENNIFER" "DAVIS" "2006-02-15 04:34:33" root@test:~/undrop-for-innodb#
结果输出看上去正确,我们将转储数据储存到一个文件。要简化加载,c_parser 输出LOAD DATA INFILE 命令到标准错误输出。
我们使用该文件的默认位置:dump/default
root@test:~/undrop-for-innodb# mkdir -p dumps/default root@test:~/undrop-for-innodb# ./c_parser -6f pages-ibdata1/FIL_PAGE_INDEX/0000000000000376.page -t sakila/actor.sql > dumps/default/actor 2> dumps/default/actor_load.sql
这是加载表的命令。
root@test:~/undrop-for-innodb# cat dumps/default/actor_load.sql SET FOREIGN_KEY_CHECKS=0; LOAD DATA LOCAL INFILE '/home/asterix/undrop-for-innodb/dumps/default/actor' REPLACE INTO TABLE `actor` FIELDS TERMINATED BY '\t' OPTIONALLY ENCLOSED BY '"' LINES STARTING BY 'actor\t' (`actor_id`, `first_name`, `last_name`, `last_update`); root@test:~/undrop-for-innodb#
将数据加载回数据库
现在我们要将数据恢复到数据库中了。在加载转储数据之前,我们需要创建表actor的空结构:
mysql> source sakila/actor.sql
mysql> show create table actor\G
*************************** 1. row ***************************
Table: actor
Create Table: CREATE TABLE `actor` (
`actor_id` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql>
现在,表actor被创建了。我们能在恢复后载入数据。
root@test:~/undrop-for-innodb# mysql --local-infile -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. ... mysql> USE sakila; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> source dumps/default/actor_load.sql Query OK, 0 rows affected (0.00 sec) Query OK, 600 rows affected (0.01 sec) Records: 400 Deleted: 200 Skipped: 0 Warnings: 0 mysql>
检查恢复的数据
最后的步骤是– 查看数据质量。我们会看到记录的总数,预览一些记录并计算校验。
mysql> SELECT COUNT(*) FROM actor; +----------+ | COUNT(*) | +----------+ | 200 | +----------+ 1 row in set (0.00 sec) mysql> SELECT * FROM actor LIMIT 5; +----------+------------+--------------+---------------------+ | actor_id | first_name | last_name | last_update | +----------+------------+--------------+---------------------+ | 1 | PENELOPE | GUINESS | 2006-02-15 04:34:33 | | 2 | NICK | WAHLBERG | 2006-02-15 04:34:33 | | 3 | ED | CHASE | 2006-02-15 04:34:33 | | 4 | JENNIFER | DAVIS | 2006-02-15 04:34:33 | | 5 | JOHNNY | LOLLOBRIGIDA | 2006-02-15 04:34:33 | +----------+------------+--------------+---------------------+ 5 rows in set (0.00 sec) mysql> CHECKSUM TABLE actor; +--------------+------------+ | Table | Checksum | +--------------+------------+ | sakila.actor | 3596356558 | +--------------+------------+ 1 row in set (0.00 sec) mysql>
你能看到恢复后的校验是3596356558,与意外删除表之前的检验相等。因此,我们能确认数据被正确恢复了。
在下一篇文章中会讲到其他恢复的情况。
如果自己搞不定可以找诗檀软件专业ORACLE/MySQL数据库修复团队成员帮您恢复!
诗檀软件专业数据库修复团队
服务热线 : 13764045638 QQ号:47079569 邮箱:service@parnassusdata.com
Undrop MySQL InnoDB 中恢复被drop的表,当 innodb_file_per_table=on时
我们介绍了在innodb_file_per_table 设为OFF,意外删除了表时,使用恢复工具包进行恢复的情况。
在这篇文章中,我们将展示在innodb_file_per_table 开启的情况下如何恢复 MySQL 表或数据库。假设mysql 服务器的设置为innodb_file_per_table=ON,这个参数告诉InnoDB 将用户表储存在单独的数据文件中。
在恢复测试中我们使用与之前文章中相同的数据库sakila。
root@test:/var/lib/mysql/sakila# ll total 23468 drwx------ 2 mysql mysql 4096 Jul 15 04:26 ./ drwx------ 6 mysql mysql 4096 Jul 15 04:26 ../ -rw-rw---- 1 mysql mysql 8694 Jul 15 04:26 actor.frm -rw-rw---- 1 mysql mysql 114688 Jul 15 04:26 actor.ibd -rw-rw---- 1 mysql mysql 2871 Jul 15 04:26 actor_info.frm -rw-rw---- 1 mysql mysql 8840 Jul 15 04:26 address.frm -rw-rw---- 1 mysql mysql 163840 Jul 15 04:26 address.ibd -rw-rw---- 1 mysql mysql 8648 Jul 15 04:26 category.frm -rw-rw---- 1 mysql mysql 98304 Jul 15 04:26 category.ibd -rw-rw---- 1 mysql mysql 8682 Jul 15 04:26 city.frm -rw-rw---- 1 mysql mysql 114688 Jul 15 04:26 city.ibd -rw-rw---- 1 mysql mysql 8652 Jul 15 04:26 country.frm -rw-rw---- 1 mysql mysql 98304 Jul 15 04:26 country.ibd ... -rw-rw---- 1 mysql mysql 36 Jul 15 04:26 upd_film.TRN root@test:/var/lib/mysql/sakila#
注意与表country相关的两个文件: country.frm, country.ibd。
我们将删除这个表并尝试恢复它。首先,我们进行校验,预览在这个表中包含的记录:
Database changed mysql> SELECT * FROM country LIMIT 10; +------------+----------------+---------------------+ | country_id | country | last_update | +------------+----------------+---------------------+ | 1 | Afghanistan | 2006-02-15 04:44:00 | | 2 | Algeria | 2006-02-15 04:44:00 | | 3 | American Samoa | 2006-02-15 04:44:00 | | 4 | Angola | 2006-02-15 04:44:00 | | 5 | Anguilla | 2006-02-15 04:44:00 | | 6 | Argentina | 2006-02-15 04:44:00 | | 7 | Armenia | 2006-02-15 04:44:00 | | 8 | Australia | 2006-02-15 04:44:00 | | 9 | Austria | 2006-02-15 04:44:00 | | 10 | Azerbaijan | 2006-02-15 04:44:00 | +------------+----------------+---------------------+ 10 rows in set (0.00 sec) mysql> CHECKSUM TABLE country; +----------------+------------+ | Table | Checksum | +----------------+------------+ | sakila.country | 3658016321 | +----------------+------------+ 1 row in set (0.00 sec) mysql> SELECT COUNT(*) FROM country; +----------+ | COUNT(*) | +----------+ | 109 | +----------+ 1 row in set (0.00 sec) mysql>
意外删除
现在我们删除表并查找表相关的文件。你能从列表中看到,有 country 表数据的文件丢失了:
mysql> SET foreign_key_checks=OFF; Query OK, 0 rows affected (0.00 sec) mysql> DROP TABLE country; Query OK, 0 rows affected (0.00 sec) mysql> mysql> exit Bye root@test:~# cd /var/lib/mysql/sakila/ root@test:/var/lib/mysql/sakila# ll total 23360 drwx------ 2 mysql mysql 4096 Jul 15 04:33 ./ drwx------ 6 mysql mysql 4096 Jul 15 04:26 ../ -rw-rw---- 1 mysql mysql 8694 Jul 15 04:26 actor.frm -rw-rw---- 1 mysql mysql 114688 Jul 15 04:26 actor.ibd -rw-rw---- 1 mysql mysql 2871 Jul 15 04:26 actor_info.frm -rw-rw---- 1 mysql mysql 8840 Jul 15 04:26 address.frm -rw-rw---- 1 mysql mysql 163840 Jul 15 04:26 address.ibd -rw-rw---- 1 mysql mysql 8648 Jul 15 04:26 category.frm -rw-rw---- 1 mysql mysql 98304 Jul 15 04:26 category.ibd -rw-rw---- 1 mysql mysql 8682 Jul 15 04:26 city.frm -rw-rw---- 1 mysql mysql 114688 Jul 15 04:26 city.ibd -rw-rw---- 1 mysql mysql 40 Jul 15 04:26 customer_create_date.TRN -rw-rw---- 1 mysql mysql 8890 Jul 15 04:26 customer.frm -rw-rw---- 1 mysql mysql 196608 Jul 15 04:26 customer.ibd -rw-rw---- 1 mysql mysql 1900 Jul 15 04:26 customer_list.frm -rw-rw---- 1 mysql mysql 297 Jul 15 04:26 customer.TRG -rw-rw---- 1 mysql mysql 65 Jul 15 04:26 db.opt ... -rw-rw---- 1 mysql mysql 36 Jul 15 04:26 upd_film.TRN root@ALtestTwinDB:/var/lib/mysql/sakila#
DROP TABLE后的恢复
因为我们需要恢复已删除的文件。如果数据库服务器与磁盘上的数据再有写入,有可能被删除的文件会被其他数据重写。因此,停止服务器并挂载该分区只读是很重要的。但在测试中我们将只停止mysql服务,并继续恢复。
root@test:/var/lib/mysql/sakila# service mysql stop mysql stop/waiting
尽管用户数据被存储各表独立的文件中,数据字典仍然存储在ibdata1文件中。这是我们要对/var/lib/mysql/ibdata1使用 stream_parser 的原因。
为了找到 country表的table_id 和 index_id ,我们要使用储存在SYS_TABLES 和 SYS_INDEXES 中的字典。我们将从ibdata1 文件中获取数据。数据字典总是REDUNDANT 格式,因此我们指定选项 -4。假设mysql服务器已将更改刷到磁盘,所以我们添加选项 -D ,表示“查找已删除的记录”。 SYS_TABLES 信息储存在index_id=1 的文件中,即文件页-ibdata1/FIL_PAGE_INDEX./0000000000000001.page:
root@test:~/undrop-for-innodb# ./c_parser -4Df ./pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page -t ./dictionary/SYS_TABLES.sql | grep country 000000000CDC 62000001960684 SYS_TABLES "sakila/country" 228 3 1 0 0 "" 88 000000000CDC 62000001960684 SYS_TABLES "sakila/country" 228 3 1 0 0 "" 88 SET FOREIGN_KEY_CHECKS=0; LOAD DATA LOCAL INFILE '/home/asterix/undrop-for-innodb/dumps/default/SYS_TABLES' REPLACE INTO TABLE `SYS_TABLES` FIELDS TERMINATED BY '\t' OPTIONALLY ENCLOSED BY '"' LINES STARTING BY 'SYS_TABLES\t' (`NAME`, `ID`, `N_COLS`, `TYPE`, `MIX_ID`, `MIX_LEN`, `CLUSTER_NAME`, `SPACE`); root@test:~/undrop-for-innodb#
我们能看到country table 表有table_id=228。下一步,我们将查找表country的PRIMARY索引。为此,我们从文件0000000000000003.page (SYS_INDEXES 表包含table_id 和 index_id之间的映射)获取SYS_INDEXES 表的记录。SYS_INDEXES 结构通过-t选项被添加到工具。
root@test:~/undrop-for-innodb# ./c_parser -4Df ./pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page -t ./dictionary/SYS_INDEXES.sql | grep 228 000000000CDC 620000019605A8 SYS_INDEXES 228 547 "PRIMARY" 1 3 88 4294967295 000000000CDC 620000019605A8 SYS_INDEXES 228 547 "PRIMARY" 1 3 88 4294967295 SET FOREIGN_KEY_CHECKS=0; LOAD DATA LOCAL INFILE '/home/asterix/undrop-for-innodb/dumps/default/SYS_INDEXES' REPLACE INTO TABLE `SYS_INDEXES` FIELDS TERMINATED BY '\t' OPTIONALLY ENCLOSED BY '"' LINES STARTING BY 'SYS_INDEXES\t' (`TABLE_ID`, `ID`, `NAME`, `N_FIELDS`, `TYPE`, `SPACE`, `PAGE_NO`); root@test:~/undrop-for-innodb#
我们能看到已删除表country的 index_id 是547。以下步骤与之前在 innodb_file_per_table=OFF的情况不同。由于没有可用数据的文件,我们要扫描所有存储设备作为裸设备并查找符合数据库页预期结构的数据。顺便收一下,这个方法能应用于数据文件损坏的情况。如果一些数据被损坏,恢复工具能进行部分数据恢复。在工具参数中,我们指定设备名称和设备尺寸(可以是大概的)。
root@test:~/undrop-for-innodb#./stream_parser -f /dev/vda -t 20000000k Opening file: /dev/vda File information: ID of device containing file: 5 inode number: 6411 protection: 60660 (block device) number of hard links: 1 user ID of owner: 0 group ID of owner: 6 device ID (if special file): 64768 blocksize for filesystem I/O: 4096 number of blocks allocated: 0 time of last access: 1405411377 Tue Jul 15 04:02:57 2014 time of last modification: 1404625158 Sun Jul 6 01:39:18 2014 time of last status change: 1404625158 Sun Jul 6 01:39:18 2014 total size, in bytes: 0 (0.000 exp(+0)) Size to process: 20480000000 (19.073 GiB) Worker(0): 1.06% done. 2014-07-15 04:57:37 ETA(in 00:01:36). Processing speed: 199.848 MiB/sec Worker(0): 2.09% done. 2014-07-15 04:57:37 ETA(in 00:01:35). Processing speed: 199.610 MiB/sec Worker(0): 3.11% done. 2014-07-15 04:59:13 ETA(in 00:03:09). Processing speed: 99.805 MiB/sec ... Worker(0): 97.33% done. 2014-07-15 04:57:15 ETA(in 00:00:05). Processing speed: 99.828 MiB/sec Worker(0): 98.35% done. 2014-07-15 04:57:20 ETA(in 00:00:06). Processing speed: 49.941 MiB/sec Worker(0): 99.38% done. 2014-07-15 04:57:17 ETA(in 00:00:01). Processing speed: 99.961 MiB/sec All workers finished in 77 sec root@test:~/undrop-for-innodb#
流解析器将结果文件储存在文件夹页 pages-vda (根据设备标题命名)。我们能看到必要索引显示在文件中。
root@test:~/undrop-for-innodb/pages-vda/FIL_PAGE_INDEX# ll | grep 547 -rw-r--r-- 1 root root 32768 Jul 15 04:57 0000000000000547.page root@test:~/undrop-for-innodb/pages-vda/FIL_PAGE_INDEX#
我们来查找在文件0000000000000547.page中的数据。工具 c_parser 根据预期表结构,通过-t选项为我们提供信息。utility c parser provide us information according to expected table structure, supplied with -t option.
root@test:~/undrop-for-innodb# ./c_parser -6f pages-vda/FIL_PAGE_INDEX/0000000000000547.page -t sakila/country.sql | head -5 -- Page id: 3, Format: COMPACT, Records list: Valid, Expected records: (109 109) 000000000C4B F30000038C0110 country 1 "Afghanistan" "2006-02-15 04:44:00" 000000000C4B F30000038C011B country 2 "Algeria" "2006-02-15 04:44:00" 000000000C4B F30000038C0126 country 3 "American Samoa" "2006-02-15 04:44:00" 000000000C4B F30000038C0131 country 4 "Angola" "2006-02-15 04:44:00" root@test:~/undrop-for-innodb#
结果看起来有效,所以我们要准备加载数据回数据库的文件。附带必要参数的LOAD DATA INFILE命令被发送到标准错误设备。
root@test:~/undrop-for-innodb# ./c_parser -6f pages-vda/FIL_PAGE_INDEX/0000000000000547.page -t sakila/country.sql > dumps/default/country 2> dumps/default/country_load.sql root@test:
将数据加载回数据库
我们要将数据加载到数据库中。在加载数据之前,我们创建表country的空结构:
root@test:~/undrop-for-innodb# service mysql start
mysql start/running, process 31035
root@test:~/undrop-for-innodb# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 37
Server version: 5.5.37-0ubuntu0.14.04.1 (Ubuntu)
Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
mysql> use sakila;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> source sakila/country.sql
Query OK, 0 rows affected (0.00 sec)
...
Query OK, 0 rows affected (0.00 sec)
mysql>
mysql> show create table country\G
*************************** 1. row ***************************
Table: country
Create Table: CREATE TABLE `country` (
`country_id` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`country` varchar(50) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`country_id`)
) ENGINE=InnoDB AUTO_INCREMENT=110 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql>
现在我们加载数据本身。
root@testB:~/undrop-for-innodb# mysql --local-infile -uroot -p Enter password: ... mysql> USE sakila; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> source dumps/default/country_load.sql Query OK, 0 rows affected (0.00 sec) Query OK, 327 rows affected (0.00 sec) Records: 218 Deleted: 109 Skipped: 0 Warnings: 0 mysql>
检查数据质量
剩下的最后一件事就是检查被恢复数据的质量。我们将预览一些记录,计算出记录和校验的总数。
mysql> SELECT COUNT(*) FROM country; +----------+ | COUNT(*) | +----------+ | 109 | +----------+ 1 row in set (0.00 sec) mysql> SELECT * FROM country LIMIT 5; +------------+----------------+---------------------+ | country_id | country | last_update | +------------+----------------+---------------------+ | 1 | Afghanistan | 2006-02-15 04:44:00 | | 2 | Algeria | 2006-02-15 04:44:00 | | 3 | American Samoa | 2006-02-15 04:44:00 | | 4 | Angola | 2006-02-15 04:44:00 | | 5 | Anguilla | 2006-02-15 04:44:00 | +------------+----------------+---------------------+ 5 rows in set (0.00 sec) mysql> CHECKSUM TABLE country; +----------------+------------+ | Table | Checksum | +----------------+------------+ | sakila.country | 3658016321 | +----------------+------------+ 1 row in set (0.00 sec) mysql>
我们很幸运。尽管我们对mysql数据了使用系统卷(不建议的操作),并且我们没有重新载入分区作为只读(其他操作继续写入磁盘),我们还是成功恢复了所有记录。计算出的恢复后检验 (3658016321) 等于删除前的检验(3658016321)。
如果自己搞不定可以找诗檀软件专业ORACLE/MySQL数据库修复团队成员帮您恢复!
诗檀软件专业数据库修复团队
服务热线 : 13764045638 QQ号:47079569 邮箱:service@parnassusdata.com
误删除/丢失/损坏的SYSTEM表空间且无备份情况下的Oracle数据恢复 PRM-DUL
D公司的SA系统管理员误删除了某数据库的SYSTEM表空间所在数据文件,这导致数据库完全无法打开,数据无法取出。 在没有备份的情况下,可以使用PRM恢复接近100%的数据。
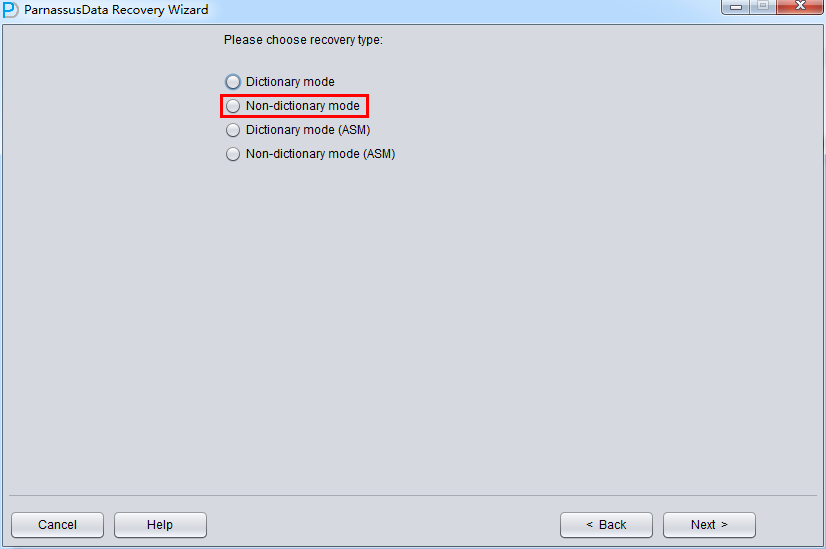
此场景中启动PRM后,进入Recovery Wizard后 选择《Non-Dictionary mode》非字典模式:
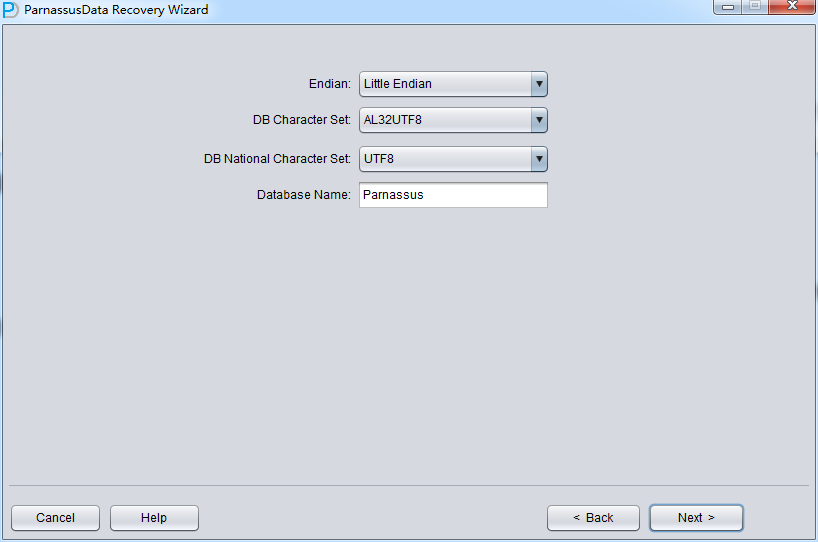
No-dictionary模式下需要用户指定 字符集和国家字符集,这是因为丢失了SYSTEM表空间后,数据库的字符集信息无法正常获得,所以需要用户的输入。 只有输入正确的字符集设置以及安装了必要的语言包才能保证No-Dictionary模式下正常抽取多国语言。
与场景演示1类似,输入用户目前可得的所有数据文件(不包括临时文件),并设置正确的Block Size和OFFSET:
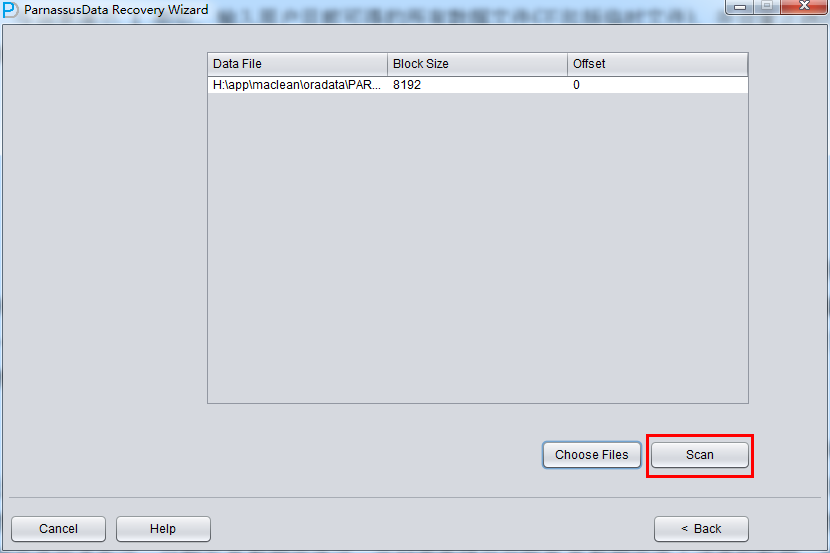
之后点击SCAN,SCAN的作用是扫描所有数据文件上的Segment Header,并记录到SEG$.DAT和EXT$.DAT中;在ORACLE中一个非分区表或者一个分区表的分区都对应着一个SEGMENT HEADER数据段头,只要能找到SEGMENT HEADER就可以获得整个表数据段的盘区EXTENT MAP 信息,通过EXTENT MAP可以获得该表上的全部记录。
通常存在这样一种情况,例如一张非分区的单表存放在某个由2个数据文件组成的表空间上,其SEGMENT HEADER以及一半的数据存放在A数据文件上,另一半数据存放在B数据文件上。但是由于某些原因,SYSTEM表空间和存放有SEGMENT HEADER的A数据文件均丢失了,只剩下B数据文件了,此时若希望仅仅恢复B数据文件上该表的数据,则不能依赖于SEGMENT HEADER,而只能依赖于从B数据文件上扫描盘区图EXTENT MAP信息了。
为了同时满足 基于SEGMENT HEADER和EXTENT MAP数据的NO-Dictionary模式恢复需要,所以SCAN操作在这里会填充SEG$.DAT和EXT$.DAT2个文件(文本文件仅仅为了便于诊断,所有程序实际依赖于PRM自带嵌入数据库DERBY的数据),并记录到DERBY数据库中。

完成SCAN 后,主界面左侧出现数据库图标。
此时可以选择2种模式:
- Scan Tables From Segments,此模式适用于
- 丢失了SYSTEM表空间,但是所有的应用数据表空间均存在
- Scan Tables From Extents
- 不适用于Dictionary模式的Truncate表数据恢复
- 丢失了SYSTEM表空间,而且丢失了SEGMENT HEADER所在数据文件
通俗地说 除非你无法使用场景2中的方式来恢复已经TRUNCATE掉的数据,否则总是优先使用Scan Tables From Segments模式,如果发现Scan Tables From Segments下找不到你要的数据,再考虑使用Scan Tables From Extents模式。
我们优先采用Scan Tables From Segments模式
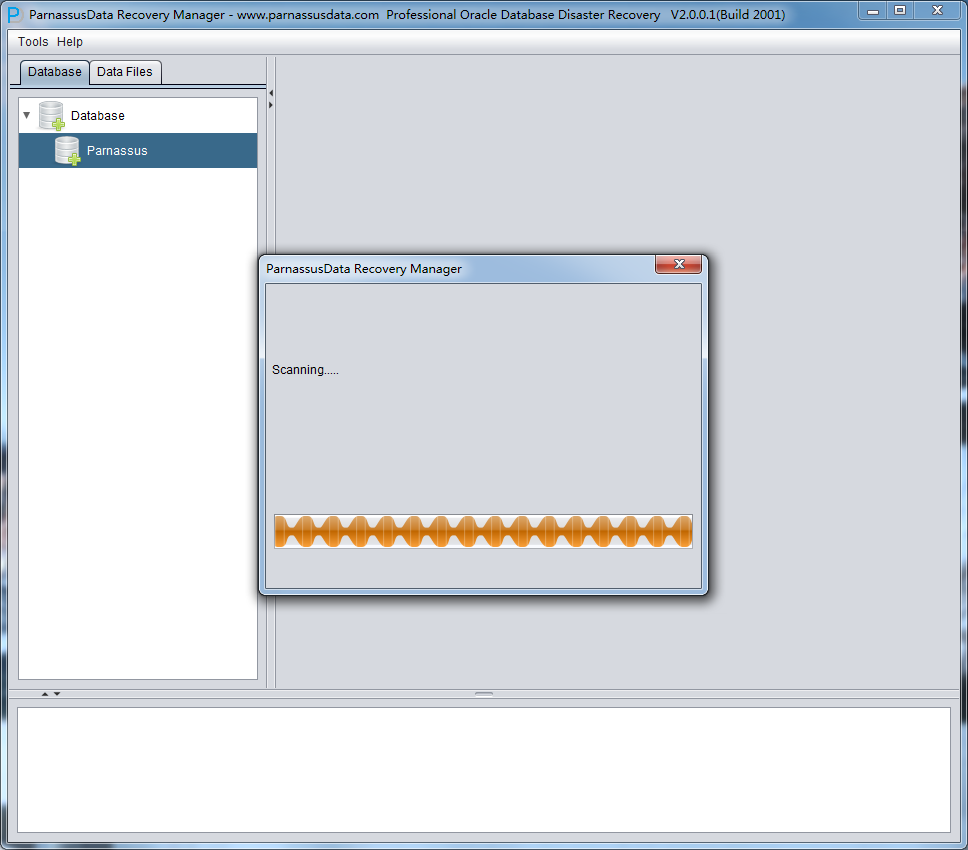
Scan Tables From Segments完成后可以点开主界面左边的树形图:
Scan Tables操作基于SEG$中的SEGMENT HEADER信息来构建数据表信息,树形图上每一个节点表示一个数据表段,其名字为obj+ 数据段上记录的DATA OBJECT ID 。
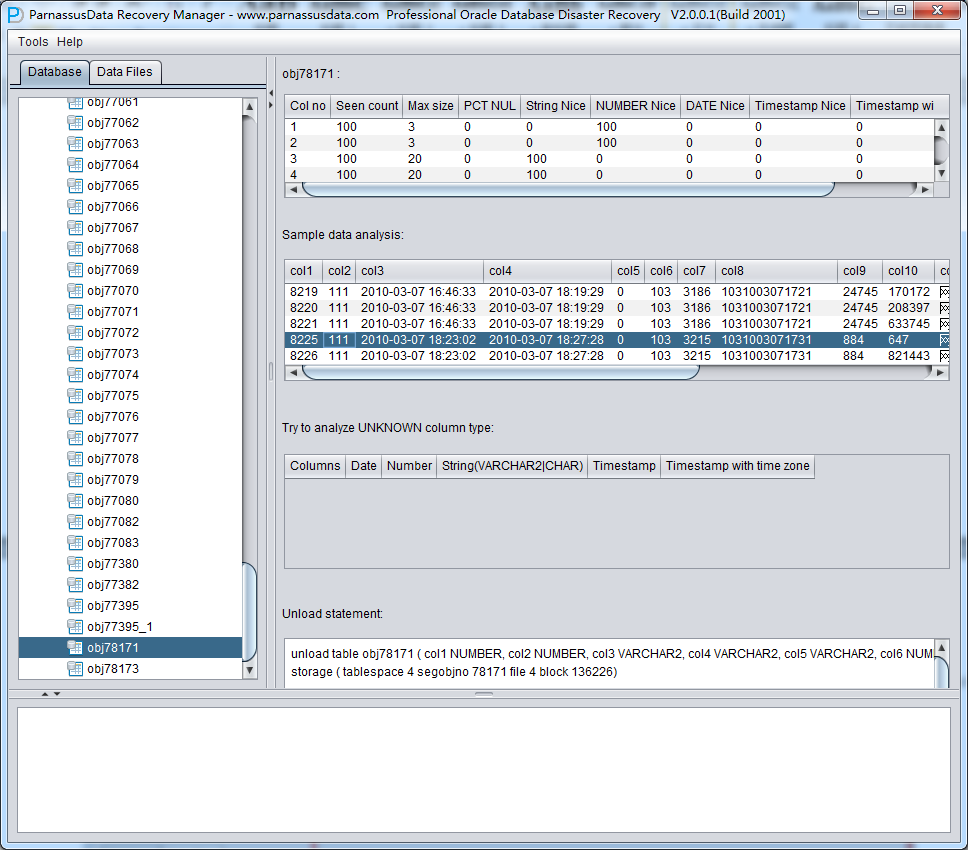
点中一个节点 并观察主界面右侧边栏:
智能字段类型解析
由于丢失了SYSTEM表空间,故NO-Dictionary模式下缺乏数据表的结构信息,这些结构信息包括表上的字段名字和字段类型,而且在ORACLE中这些信息均只保存为字典信息,不会在数据表上存放。当用户只有应用表空间时,需要基于数据段上的ROW行数据来猜测每一个字段的类型,PRM采用先进JAVA类型预判技术,可以解析多达10来种主流数据类型;、
智能解析准确度超过90%,可以自动解决大部分场景。
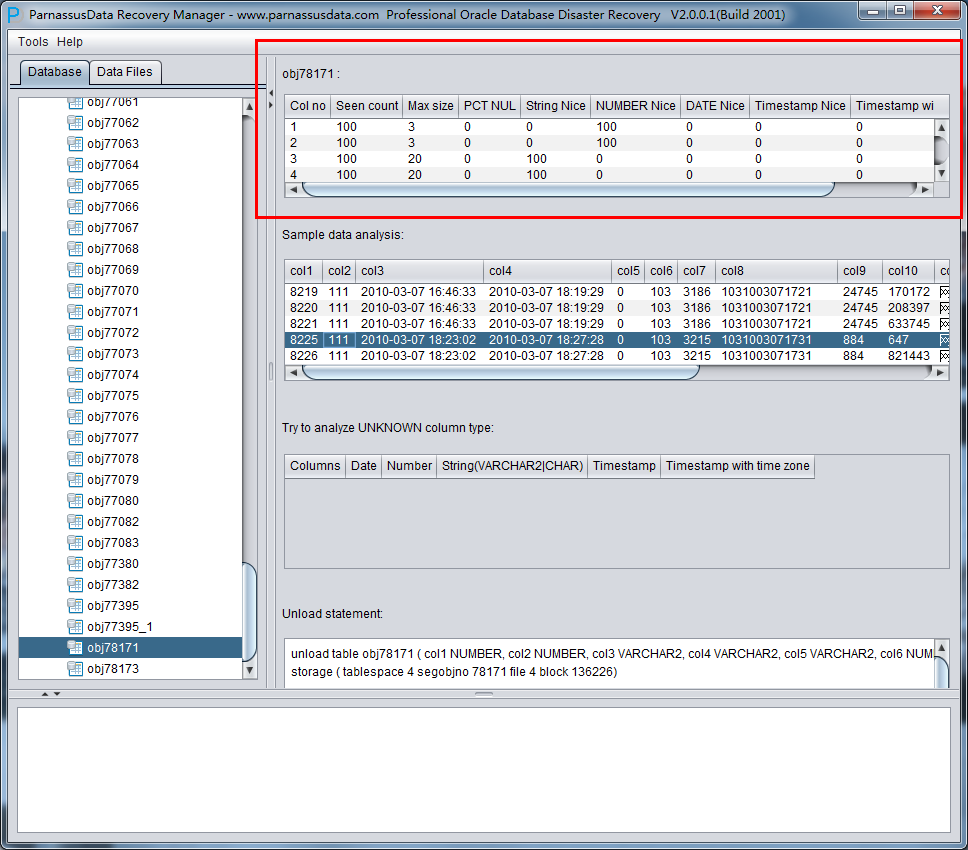
右侧边栏 上部各字段的含义:
- Col1 no 字段号
- Seen Count: 取到的行数
- MAX SIZE: 最大长度,单位为字节
- PCT NULL: 采样到的NULL的比例
- String Nice: 将该字段解析为字符串,并成功的比例
- Number Nice: 将该字段解析为数字,并成功的比例
- Date Nice: 将该字段解析为Date,并成功的比例
- Timestamp Nice: 将该字段解析为Timestamp,并成功的比例
- Timestamp with timezone Nice: 将该字段解析为Timestamp with timezone Nice,并成功的比例
示例数据分析Sample Data Analysis:
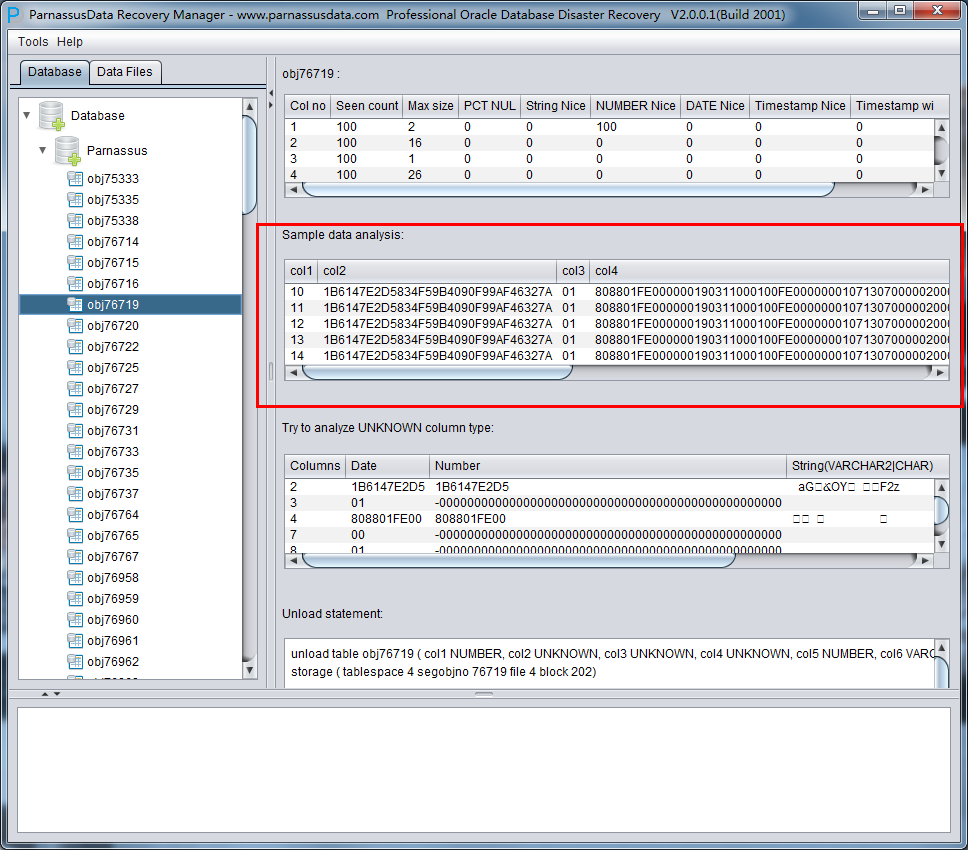
该部分依据智能字段类型解析的结果来解析10条数据,并显示解析结果。通过示例数据可以帮助用户了解实际该数据段中存放数据的情况。
如果数据段上记录条数不足10条,则显示所有记录。
TRY TO ANALYZE UNKNOWN column type:
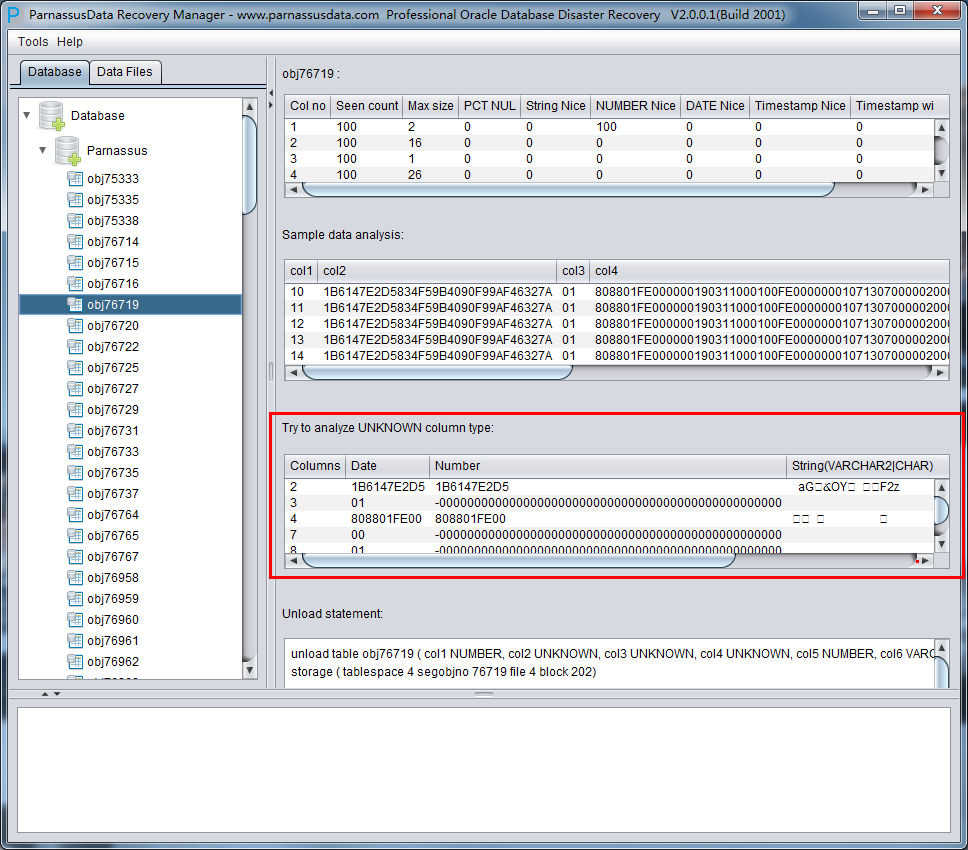
该部分是对于智能字段类型分析不能100%确认的字段,尝试用各种字段类型来解析,并呈现给用户,以便用户自行判断其究竟是什么类型。
目前PRM还不支持的类型包括:
XDB.XDB$RAW_LIST_T、XMLTYPE、用户自定义类型等
Unload Statement:
这部分是PRM生成的UNLOAD语句,此生成的UNLOAD语句仅作为系统内部使用和PRM开发团队以及ParnassusData原厂支持工程师使用。
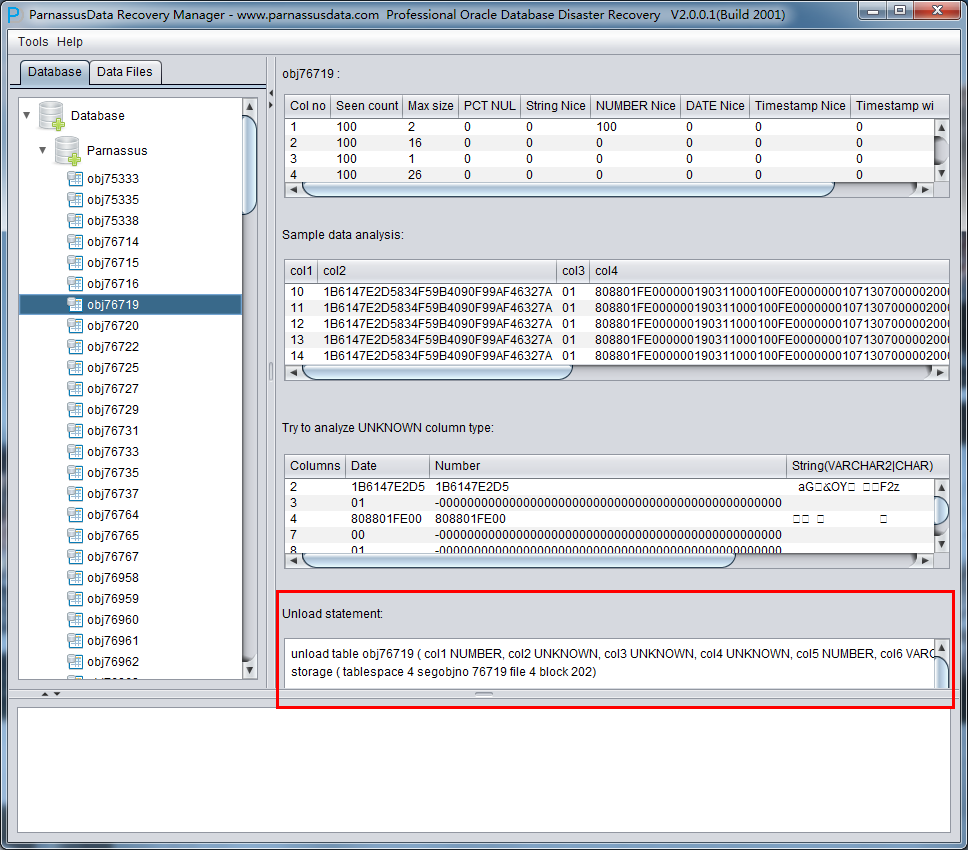
在此《Non-Dictionary Mode》非字典模式下同样可以采用常规和数据搭桥模式,与字典模式相比,主要的区别在于在非字典模式下数据搭桥时用户可以自行执行字段的类型,如下图中中部分字段类型为UNKNOWN,即未知的。这些字段可能是PRM目前还不支持的例如XML字段,也可能是PRM的智能解析没有顺利分析器类型。
如果用户知道这张表设计时的结构(也可以来源于应用开发商的文档),那么可以自行去填选正确的Column Type类型,以便PRM顺利将该表数据搭桥到目标数据库。

误删除了SYSTEM表空间和部分应用表空间数据文件的Oracle数据恢复 PRM-DUL
D公司的SA由于误操作将在线业务数据库的SYSTEM表空间上的数据文件,以及部分应用表空间数据文件意外删除了。
此场景中由于部分应用表空间数据文件被删除了,这其中可能包括含有数据表的SEGMENT HEADER的数据文件,所以使用Scan Tables From Segment Header可能不如使用Scan Tables From Extents来的合适。
其简要步骤如下:
- 进入Recovery Wizard ,选择No-Dictionary模,加入所有可用的数据文件,执行Scan Database
- 选中数据库,并右键Scan Tables From Extents
- 对于PRM主界面上生成的对象树形图中的数据进行分析和导出/数据搭桥
- 其余操作与恢复场景4中一样
【12c新特性】多LGWR进程SCALABLE LGWR “_use_single_log_writer”
SCALABLE LGWR是12cR1中引入的一个令人激动的特性, 这是由于在OLTP环境中LGWR写日志往往成为系统的主要性能瓶颈, 如果LGWR进程能像DBWR(DBW0~DBWn)那样多进程写出redo到LOGFILE那么就可能大幅释放OLTP的并发能力,增长Transcation系统的单位时间事务处理能力。
在12cR1 中真正用SCALABLE LGWR实现了这个目的, 也可以俗称为多LGWR进程。
select * from opt_12cR1 where name like '%log%' _use_single_log_writer ADAPTIVE Use a single process for redo log writing _max_outstanding_log_writes 2 Maximum number of outstanding redo log writes
SCALABLE LGWR主要受到隐藏参数_use_single_log_writer的控制, 该参数默认值为ADAPTIVE 。
该参数主要有三个可选值 true, false, adaptive, 默认值为ADAPTIVE。
- 对于ADAPTIVE 和False 如果CPU个数大于一个则会有多个lg0n进程
- 对于true 则不会生成多个lg0n进程,而如同12.1之前那样仅有单个LGWR
SQL> show parameter _use_single_log_writer NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ _use_single_log_writer string ADAPTIVE [oracle@maclean1 ~]$ ps -ef|grep lg grid 4344 1 0 08:07 ? 00:00:00 asm_lgwr_+ASM1 oracle 12628 1 0 08:48 ? 00:00:00 ora_lgwr_MAC_1 oracle 12636 1 0 08:48 ? 00:00:00 ora_lg00_MAC_1 oracle 12640 1 0 08:48 ? 00:00:00 ora_lg01_MAC_1 oracle 13206 7447 0 08:51 pts/2 00:00:00 grep lg
可以使用 10468 level 2 来trace adaptive scalable LGWR
[oracle@maclean1 trace]$ oerr ora 10468 10468, 00000, "log writer debug module" // *Document: NO // *Cause: // *Action: Set this event to the appropriate level for log writer debugging. // alter system set events '10468 trace name context forever,level 2'; LGWR TRACE: kcrfw_slave_adaptive_updatemode: time=426523948079110 scalable slave=1 arbiter=3 group0=10678 all=12733 delay=100 rw=98774 single=1973 48 scalable_nopipe=197548 scalable_pipe=108651 scalable=180439 kcrfw_slave_adaptive_savewritecounts: time=426523954275133 group0=10695 all=12752 kcrfw_slave_adaptive_savewritecounts: time=426523954662537 group0=10696 all=12753 CKPT TRACE: *** 2014-12-07 10:52:21.528 kcrfw_slave_adaptive_saveredorate: time=426523941528521 curr=16649627696 prev=16635613056 rate=14014640 avg=14307212 *** 2014-12-07 10:52:24.553 kcrfw_slave_adaptive_saveredorate: time=426523944553556 curr=16664120996 prev=16649627696 rate=14493300 avg=14318490
实际测试可以发现 仅在redo 生成率非常高的环境中SCALABLE LGWR 对于redo写出的吞吐量有所帮助,进而提高OLTP环境的TPS。
_use_single_log_writer = adaptive 2个LG slave进程:
| Per Second | Per Transaction | Per Exec | Per Call | |
|---|---|---|---|---|
| DB Time(s): | 2.8 | 0.0 | 0.00 | 0.33 |
| DB CPU(s): | 2.6 | 0.0 | 0.00 | 0.31 |
| Redo size (bytes): | 8,180,730.6 | 545.6 | ||
| Logical read (blocks): | 46,382.1 | 3.1 | ||
| Block changes: | 60,219.5 | 4.0 |
| Function Name | Reads: Data | Reqs per sec | Data per sec | Writes: Data | Reqs per sec | Data per sec | Waits: Count | Avg Tm(ms) |
|---|---|---|---|---|---|---|---|---|
| LGWR | 1M | 0.14 | .004M | 4.3G | 29.80 | 16.16M | 1785 | 79.10 |
_use_single_log_writer = true 使用single lgwr
| Per Second | Per Transaction | Per Exec | Per Call | |
|---|---|---|---|---|
| DB Time(s): | 2.8 | 0.0 | 0.00 | 0.34 |
| DB CPU(s): | 2.6 | 0.0 | 0.00 | 0.32 |
| Redo size (bytes): | 8,155,843.5 | 545.0 | ||
| Logical read (blocks): | 46,550.1 | 3.1 | ||
| Block changes: | 60,036.7 | 4.0 |
| Function Name | Reads: Data | Reqs per sec | Data per sec | Writes: Data | Reqs per sec | Data per sec | Waits: Count | Avg Tm(ms) |
|---|---|---|---|---|---|---|---|---|
| LGWR | 1M | 0.13 | .003M | 4.8G | 25.49 | 16.141M | 1611 | 95.97 |
相关AWR附件:
_use_single_log_writer = adaptive
LGWR Scalability 的正面积极意义:
12c通过并发辅助进程以及优化的log file写算法有效改善 多CPU环境中由LGWR引起的等待瓶颈,释放LGWR性能。
一般来说这种性能改善在中小型的数据库实例中并不明显,实际上它们主要是为了那些64个CPU或更多CPU可用的数据库实例。但有性能测试报告显示在最少8个CPU的情况下对性能也有改善。
在之前的版本中,单一的LGWR处理所有的redo strands收集redo记录并将其写出到redo logfile中。在Oracle Database 12c中,LGWR开始并协调多个辅助helper进程,并行地完成以前LGWR一个人做的工作。
- LGWR进程变成了多个LGnn形式的helper进程的协调指挥者,并负责保证这一堆并发进程所做的工作仍满足正确的LGWR顺序
- LGnn进程负责读取一个或多个redo strands,负责实际写出到log file以及post前台进程
限制
在Oracle database 12c中,当使用SYNC同步redo传输方式传输redo到standby database时, 不支持使用上述的并行写SCALABLE LGWR,讲返回到串行写的老路子上。 但是Parallel LGWR/SCALABLE LGWR是支持ASYNC异步redo 传输的。
ORA-1578 on Oracle Startup
An ORA-1578 on startup is usually bad news and relates to either a corrupt rollback segment header, or a corrupt block being referenced during bootstraping of the instance. eg: Database mounted. ORA-01578: ORACLE data block corrupted (file # 11, block # 2) ORA-01110: data file 1198: '/tmp/RPrbcor.dbf' SVRMGR> ( Recovery does not fail if a corrupt block is encountered - the block is skipped over and recovery continues. Warnings are written to the user trace file. eg: Corrupt block dba: 0x20000003 file=8. blocknum=3. found during media/instance recovery on disk type:6. ver:1. dba: 0x2000ffff inc:0x00000001 seq:0x00000007 incseq:0x00010007 Reread of block=20000003 file=8. blocknum=3. found same corupted data Actions: 1. Shutdown the instance (or you may get ORA-704/ORA-604/ORA-955 when you next try to open the database) eg: SHUTDOWN ABORT 2. Although it is possible to offline the affected file/s and double check which object is involved it is better to first look at recovering the corrupted file. This is only possible in ARCHIVELOG mode. eg: Take a SAFE copy of the existing problem file Restore a good backup of the problem file STARTUP MOUNT ALTER DATABASE DATAFILE 'name_of_file' ONLINE; RECOVER DATABASE ALTER DATABASE OPEN; 3. If the ORA-1578 persists or the file cannot be restored then: a. If this is a SYSTEM tablespace datafile you are in trouble. Go to "Last Options" b. If this is not a SYSTEM tablespace datafile you MAY be able to continue as below. 4. If the ORA-1578 is on a rollback segment header then it is possible that the header is only being accessed because Oracle is trying to online the rollback segment. To check for this we can comment out all of the rollback segments in the init.ora file and attempt to start the database. eg: Comment out the ROLLBACK_SEGMENTS=... clause If you are using PUBLIC rollback segments then also set the init.ora parameter TRANSACTIONS to a small number (about 20) and TRANSACTIONS_PER_ROLLBACK_SEGMENT to the same number . Additionally try to find one rollback segment which is known to be good and set this in the ROLLBACK_SEGMENTS parameter. This is done to try to stop Oracle needing to online any PUBLIC rollback segment when the database opens. If there are no rollback segments you know to be good you can try this step several times using different named rollback segments. eg: TRANSACTIONS=20 TRANSACTIONS_PER_ROLLBACK_SEGMENT=20 ROLLBACK_SEGMENTS=(OK_RBS) Now try to start the database: eg: SHUTDOWN ABORT STARTUP If the database opens go to step 6 5. If the above has not allowed you to open the database then the next step is to attempt to offline the problem file: eg: SHUTDOWN ABORT STARTUP MOUNT ALTER DATABASE DATAFILE 'name_of_file' OFFLINE; ALTER DATABASE OPEN; If the "ALTER DATABASE DATAFILE ... OFFLINE" reports "ORA-01145: offline immediate disallowed unless media recovery enabled" go to "NOARCHIVELOG" below. 6. If the database opens check which object has the ORA-1578 error. WARNING: On Oracle8 you need the file number from the accompanying ORA-1110 error. SELECT segment_type, owner, segment_name FROM dba_extents WHERE file_id= AND BETWEEN block_id and block_id+blocks-1 ; If SEGMENT_TYPE is ROLLBACK SEGMENT go to "Recovering Rollback Segments". If OWNER is SYS more detailed investigation is required to determine whether the problem object can be rebuilt. For any other object see Note:28814.1 on how to handle block corruptions.
