Hello DUL ,
Can I have the contact name and details of someone with Oracle DUL expertise?
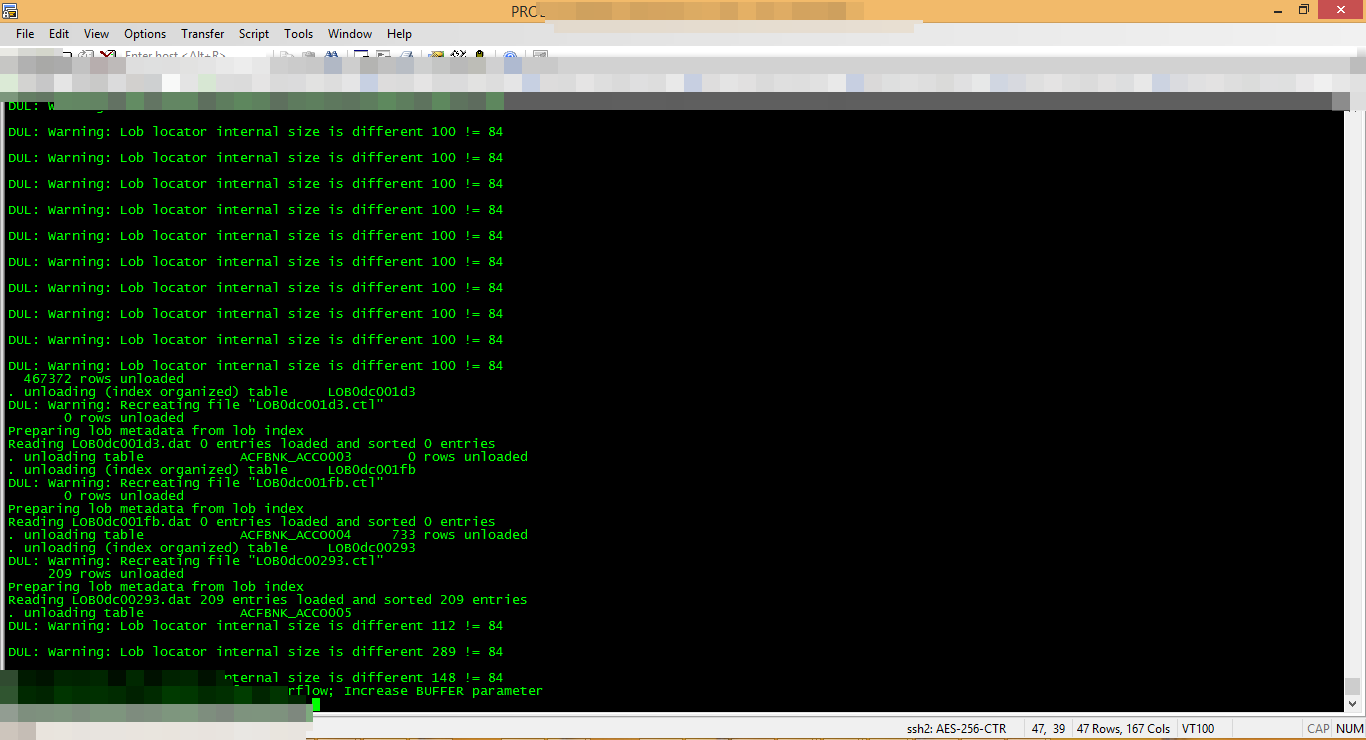
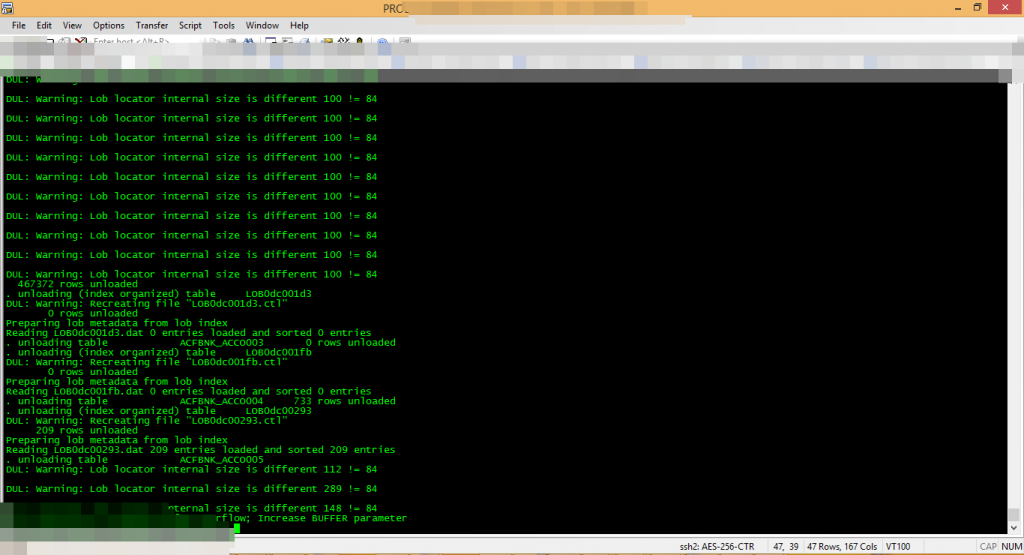
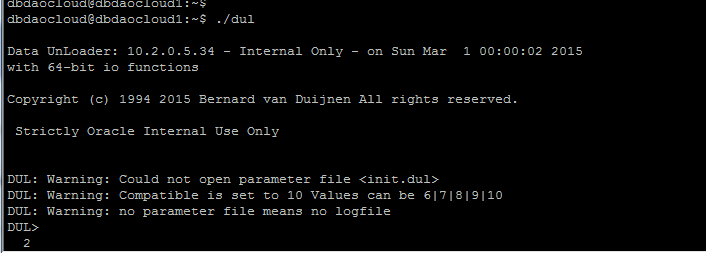
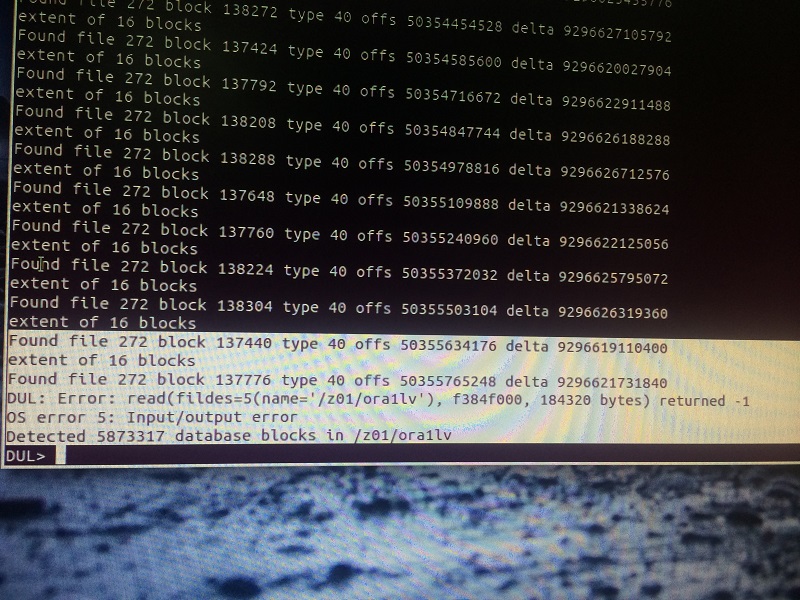
A customer, AS Brazil , has a corrupt DB of 800GB
I have spoken in broad lines regarding what the DUL service is and they would like to proceed.
Questions that have arisen:
1) How must the remote connection be set up?
2) How is the costing formulated and what can they expect?
3) Time frame?
Answer:
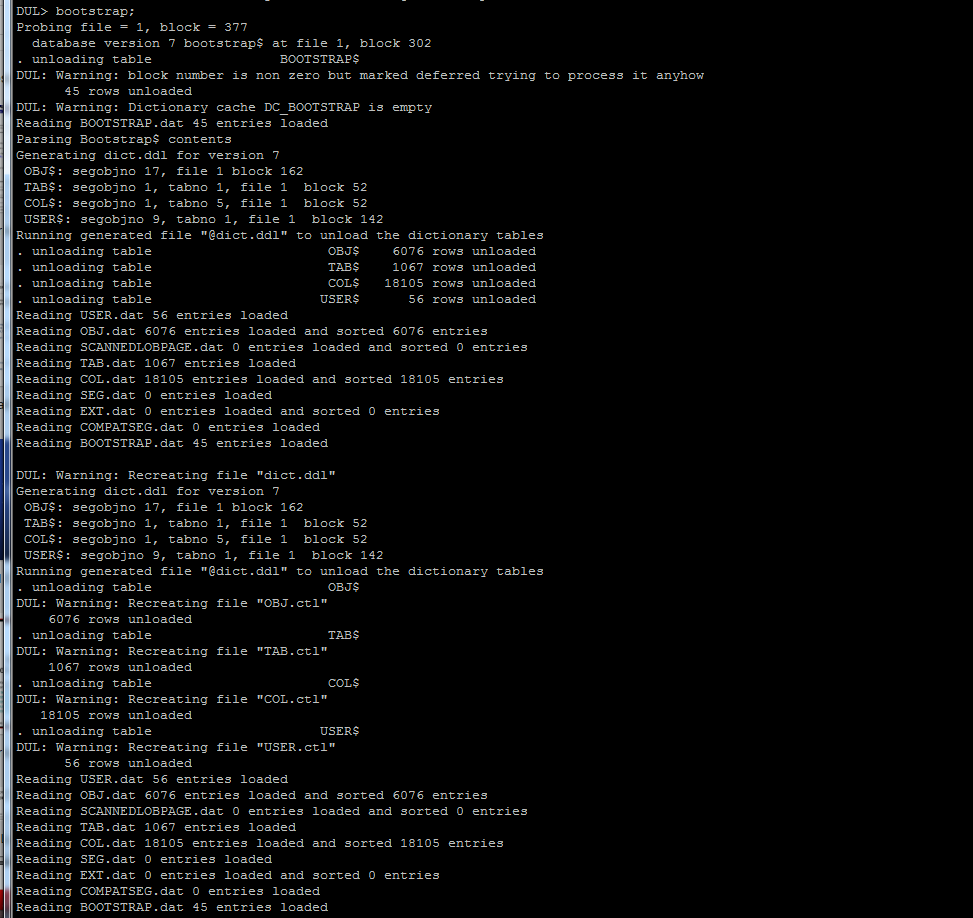
Pls check this:
http://www.parnassusdata.com/en/emergency-services









![[3]](http://img.t.sinajs.cn/t35/style/images/common/face/ext/normal/78/three_org.gif "[3]") , num2 =
, num2 = ![[1]](http://img.t.sinajs.cn/t35/style/images/common/face/ext/normal/82/one_org.gif "[1]") , error = [type_kfbh]
, error = [type_kfbh]