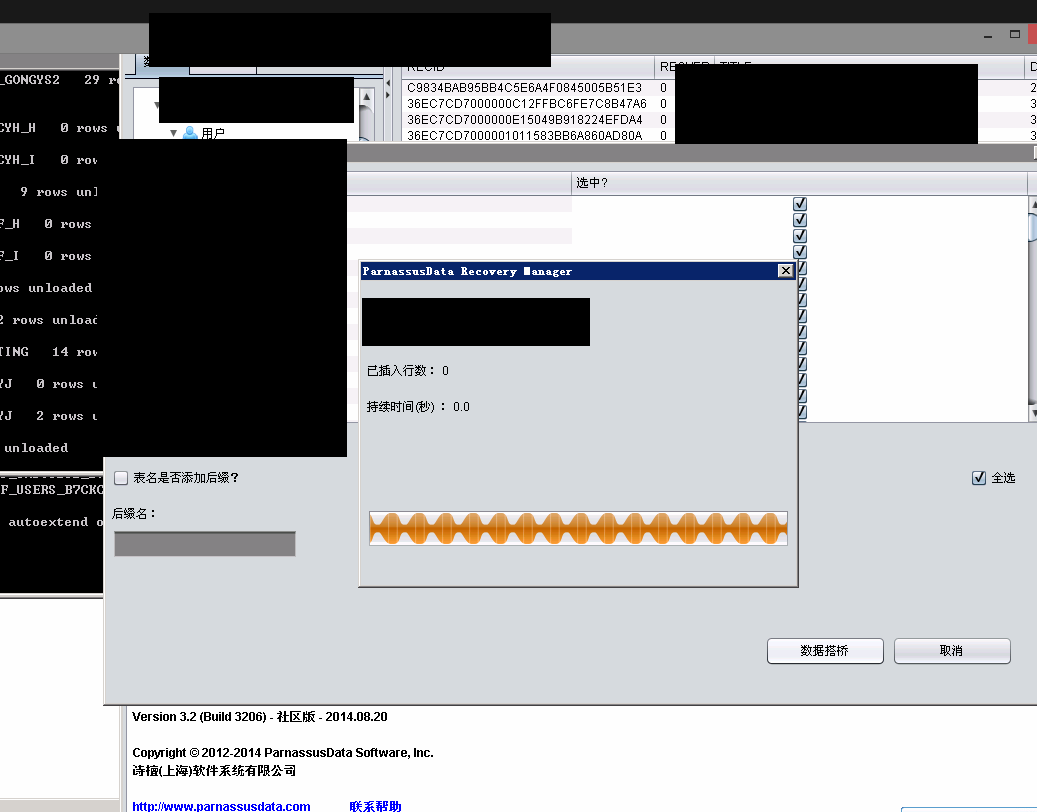
ParnassusData Recovery Manager(以下略してPRM)は企業レベルのOracleデータディザスタリカバリーソフトで、OracleデータベースのインスタンスでSQLを実行することじゃなく、直接にOracle9i,10g,11g,12cからデータベースのデータフィイルを抽出することにより、目標データを救うソフトである。ParnassusData Recovery ManagerはJavaに基づいて開発された安全性が高く、ダウンロードして解凍したあと、インストールすることなしにそのままで運用できて、とっても便利で使いやすいなソフトである。
PRMはGUIグラフィカルインターフェース(図1)を採用し、新たなプログラミング言語をあらかじめ勉強する必要はなく、Oracle bottom-level structure of database原理さえわかっていれば、リカバリーウィザード(Recovery Wizard)を使うことによって、データをリカバリーできる。
お客様きっとまだこういう疑問を抱いているでしょう:「RMANという応用歴史が長いOracleリカバリーマネジャーのバックアップによるリカバリーはまだ足りないというのか。なぜわざわざPRMを買う必要があるでしょう。」
ご存知の通りですが、今企業に発展し続けていくITシステムでは、データボリュムがまさに日進月歩である。データの整合性を確保することは何より大事ですが、このデータが爆発的に増加する時代のなか、今日のOracle DBAたちは既存のディスクボリュムが不足で、データ全体を格納できないやテープによるバックアップがリカバリーするときに要する時間が予想した平均修復時間に超えていたなどさまざまな課題に直面している。
「データベースにとって、バックアップは一番大事である」ということわざはあらゆるDBAのこころに刻んでいる。けど、現実の環境は千差万別で、筆者の経験では、企業データベース環境でバックアップスペースが足りないとか、購入したストレージデバイスが短期的に手に入ることができないとか、バックアップしていたが、実際にリカバリーしているとき、使えなくなったとか、現場に起きることが実に予想できない。
現実によくあるリカバリートラブルに対応するため、PRM 诗檀データベースリカバリーマネジャーソフトは開発された。PRM 诗檀データベースリカバリーマネジャーソフトはORACLEデータベース内部データ構造理解したうえで、全くバックアップしていないときにSYSTEMテーブルスペースなくしたとか、ORACLEデータディクショナリーテーブルを誤操作したとか、電源がきれたことによりデータディクショナリー一貫性をなくし、データベースを起動できないとか、さまざまな難題に対応できる。さらに、誤切断(Truncate)/削除 (Delete)業務データテーブルなど、人為的な誤操作もリカバリーできる。
Oracle専門家に限っていることじゃなく、わずか数日間しかOracleデータベースを接触していなかった方にも自由自在に運用できる。このすべてはPRMのインストールがとびきりたやすいところとグラフィカル対話型インタフェースのおかげです。これにより、リカバリーを実行する技術者たちはデータベースに関する専門知識を要することじゃなく、あらためて新たなプログラミング言語を勉強する必要もない。データベースの基礎になる格納構造についてはなおさらです。マウスをクルックするだけで、余裕をもってリカバリーできる。
伝統的なリカバリーツールであるDULにたいして、PRMはDULがかなわない強みをもっている。DULはOracleオリジナル内部リカバリーツールであて、使うたびに必ずOracle内部プロセスに通する。一般的に、Oracle現場技術サポートを購入した少しのユーザーがOracle会社から派遣されたエンジニアの支援の元に、リカバリー作業が始められる。PRMは少数の専門家しかデータベースリカバリー作業しか務められないという現実を一新し、データベースがトラブルを起きる時点からリカバリー完了するまでの時間を大幅に短縮したから、企業のリカバリーコストを大分軽減した。
PRMを通ってリカバリーするには二つパータンにわけている。伝統的な抽出方法として、データをファイルから完全抽出して、フラットテキストファイルに書き入れて、そしてSQLLDRなどツールでデータベースへロードする。伝統の使い方がわかりやすいが、既存二倍のデータボリュームのスペースを要求するというデメリットがある。つまり、ひとつのフラットテキストファイルが占めているスペースとあとでテキストデータをデータベースにロードするスペース。時間についても、元のデータをファイルから抽出したから、新規データベースにロードできるため、常に二倍の時間を必要としている。
もう一つはわたしたちPRMにより、独創的なデータバイパスモード、つまりPRMを通ってじかにデータを抽出し、新規や他の使用可能なデータベースにロードする。これより、着陸データストレージに避けて、伝統の方法に比べて、さらに時間もスペースも節約できる。
いま、Oracle ASMの自動ストレージ管理技術はより多くの企業により採用されて、このシステムは伝統のファイルシステムよりずっと多くのメリットをもっている。例えば、性能がより高く発揮できるところ、クラスタを支持しているところ、そして管理するとき、とても便利のところ。でも、普通のユーザーにとって、ASMの格納構造があんまりにわかりにくく、いざASMであるDisk Groupの内部データ構造が故障になって、Disk GroupがMOUNTできなくなる。つまり、ユーザーたち大事なデータをASMに閉じ込まれた。こういうときは、必ずASM内部構造に詳しいOracle会社の専門家を現場に要請して、手動的にトラブルを解決する術しかない。でも、Oracle会社の現場技術サポートを買うには大量な資金が必要としている。
そこで、PRMの開発者(前Oracle会社シニアエンジニア)はOracle ASM内部データ構造に対する幅広い知識に基づき、PRMでは、ASMに対するデータリカバリー機能を追加した。
今PRMが支持しているASMに対するデータリカバリー機能は以下ご覧のとおり:
1. たとえDisk Groupが正常にMOUNTできなくても、PRMを通って、ASMディスクに使用可能なメタデータを読み取ることができる、さらにこれらのメタデータがDisk GroupにあるASMファイルをコーピーすることもできる。
2. たとえDisk Groupが正常にMOUNTできなくても、PRMを通って、ASMにあるデータファイルを読み取ることやそのまま抽出することも支持する。抽出する方法については伝統的な抽出方法とデータバイパスモード両方も支持している。