ORACLE DBA故障修复必备手册 本文地址:https://www.askmac.cn/archives/oracle-troubleshooting.html
在对Oracle数据库相关情况及问题进行诊断及信息捕获时, 请:
- 请确认MAX_DUMP_FILE_SIZE 参数设置, 这将避免用以诊断的追踪文件(trace file)因为空间不足而被截断 !!!
- 上传alert.log文件。11g中,文本形式的alert.log是放在ADR home相应”trace”目录下。而XML形式的alert.log则是放在ADR home下的”alert”目录下。如需验证ADR home确切位置,可以执行”select * from v$diag_info” 并从其输出中找到。
请看下页诊断追踪文件目录地址信息。
- 请对所遇问题提供详尽描述以便于分析并更快找到问题原因。
对于 较为严重的问题, 请提供:
- 相关业务及技术评估
- 两名24×7联系人,并提供相关人员邮件及电话联系方式(askmac.cn)。
- 一名相关管理联系人,需提供其邮件及电话联系方式。
问题细节描述:
- 受影响日期时间
- 相关报错号及其文本信息。
- 相关问题影响 – 数据库实例奔溃, 进程失败等.?
- 错误出现频率?
- 错误是否可重演。
- 错误是否总在特定日期时间发生?
- 错误发生是否与数据库相关活动有关?如备份或高负载处理时.
- 错误是否总是来自于某个应用或某位用户?
- 第一次产生此错误是在何时?当时是否正在做何改动?
- 当时是否有其他错误发生(例如ORA-7445 或 ORA-600错误)?
- 最近系统是否有任何改变?
- 如果你还不确定set events操作会带何种影响,请不要设置。
- 随着Oracle 11g诊断追踪文件默认地址的改变。下表展示了以前(10g以及之前版本)和最新11g(ADR)的跟踪文件目录位置。
诊断追踪文件目录地址
| 诊断数据文件 | 之前版本文件路径 | ADR中文件路径 |
| Foreground process traces | USER_DUMP_DEST | $ADR_HOME/trace |
| background process traces | BACKGROUND_DUMP_DEST | $ADR_HOME/trace |
| Alert log data | BACKGROUND_DUMP_DEST | $ADR_HOME/alert&trace |
| Core dumps | CORE_DUMP_DEST | $ADR_HOME/cdump |
| Incident Dumps | USER|BACKGROUND_DUMP_DEST | $ADR_HOME/incident/incdir_n |
Oracle数据库11g并没有对前台和后台追踪文件做区分。两种类型文件都放在$ADR_HOME/trace目录下。
- 请注意BDE及其开发需要11g漏洞 IPS打包服务. 在11g中IPS(Incident Packaging Service事件打包服务) 提供了一种对诊断信息打包的简便方法。
所有数据库事件(严重错误)的跟踪文件都被存储在Oracle自动诊断库(Automatic Diagnostic Repository: ADR)中。其提供的ADRCI工具被用于打包所有文件并上传给Oracle支持。从OEM中也能找到IPS相关链接服务。请参考以下文档了解更多相关信息:
Note:422893.1 – 11g Understanding Automatic Diagnostic Repository.
Note:443529.1 – 11g Quick Steps to Package and Send Critical Error
Note:1091653.1 – 11g Quick Steps – How to create an IPS package using Support Workbench
并非11g中所有问题都需生成诊断包. 但对于以下相关11g错误及SR应该考虑获取相关诊断包(askmac.cn)。
Manageability:
ORA-600 & ORA-7445
ORA-4030 & ORA-4031
DB Admin:
ORA-600, ORA-700 & ORA-7445
HA:
ORA-600 & ORA-7445
ORA-8103 – Object no longer exists
ORA-1410 – Invalid ROWID
ORA-1578 – Oracle data block corruption
ORA-376 – File cannot be read at this time
ORA-353 – There is a log corruption near a block, change, and time
以下是一个例子 à
客户看见alert.log中出现以下错误:
Errors in file d:\oracle\diag\rdbms\twn11g\twn11g1\trace\twn11g1_ora_201116.trc:
ORA-00600: internal error code, arguments: [17099], [], [], [], [], [], [], [], [], [], [], []
Errors in file d:\oracle\diag\rdbms\twn11g\twn11g1\trace\twn11g1_ora_201116.trc (incident=19569):
ORA-00600: internal error code, arguments: [17099], [], [], [], [], [], [], [], [], [], [], []
Incident details in: d:\oracle\diag\rdbms\twn11g\twn11g1\incident\incdir_19569\twn11g1_ora_201116_i19569.trc
…因此我们看见事件号为 19569.
在正确设置11g环境变量后,通过ADRCI(命令)进入IPS打包处理服务:
% adrci
因为我们已经知道事件号为19569, 那执行下一步:
adrci> ips pack incident 19569
…这样就在当前目录下建立了zip压缩包.如果你希望压缩包保存在其它目录中, 那么可以在命令后加上路径信息:
adrci> ips pack incident 19569 in D:/tmp/whatever
此命令会提示信息产生了包含事件号19569相关信息的IPS打包文件。这个zip压缩文件之后需要被上传到SR上。
请具体表述问题。并询问用户是否能“解冻”数据库?如何做到的?
- 使用以下命令生成HANGANALYZE追踪文件 ==>
$ sqlplus “/ as sysdba”
SQL> oradebug hanganalyze 3
… Wait 90 seconds (to 2 minutes) to give time to identify process state changes.
SQL> oradebug hanganalyze 3 (level 4 dumps leaf nodes as well and may be useful, but there is more impact on the system)
使用以下语法在执行RAC级HANGANALYZE:
ORADEBUG setmypid
ORADEBUG setinst all
ORADEBUG -g all hanganalyze 3
2) 在运行Hanganalyze之后,登入一个新SQL会话来生成系统状态转储(dump)文件==>
$ sqlplus “/ as sysdba”
SQL> oradebug setmypid
SQL> oradebug unlimit
SQL> oradebug dump systemstate 266
… wait 90 seconds
SQL> oradebug dump systemstate 266
… wait 90 seconds
SQL> oradebug dump systemstate 266
Level 266和267包含了一些堆信息。Level 266是对单实例的信息转储,而Level 267则是对RAC系统systemstate转储。请看Note:300870.1对事件10998了解更多信息。
**Note: 我们同样可以通过使用Hang File Generator (HANGFG) 工具来完成以上1)和2)中使用hanganalyze和systemstate收集信息的操作。HANGFG工具提供了一系列UNIX shell脚本命令来自动化收集和生成hanganalyze和sysemstate追踪文件。在使用HANGFG生成并收集追踪文件时需要考虑到需要在已处于性能退化的系统中进行诊断的影响。由于影响级别作为此工具参数被传给HANGFG, 所以用户需要做出决定, 在启用此工具时,何种级别的影响是可接受的。当用户选择轻度影响或中等影响(选项1 或2)作为参数时, HANGFG工具同样有能力做出调整以适应用户做出的决定。HANGFG是RAC自识别的,并且能在RAC和非RAC环境中运行。请看Note:362094.1 (the HANGFG User Guide)以了解其相关信息。
3) 当hang事件发生后,获取到的Statspack或AWR/ASH(10g/11g)报告是否具有时效性取决于做Statspack快照频繁程度。举个例子,如果你每隔1小时做一次快照,在下一次快照前发生了5分钟的数据库挂起事件。那么快照由于显得时间跨度太长而很难用于分析当时5分钟发生的情况。
AWR/ASH报告上的其他相关信息可以在“数据库性能”章节中找到。
有时在尝试连接数据库时,你的调试会话也会挂起在那里。这时留给你3种可选方法==>
1) 找一个之前已连上的可用会话。
2) 如果你正在使用10g/11g,那么你可以使用-prelim选项来登录数据库:
SQL*Plus. Eg:
sqlplus -prelim / as sysdba
oradebug setmypid
oradebug unlimit;
oradebug dump systemstate 266;
3) 使用操作系统调试器来查看运行进程
- 获取服务器oracle先关影子进程ID (请注意并非oracle后台进程,调试后台进程可能导致数据库奔溃)…”ps –ef | grep ora”
- 使用当前系统级调试器(如dbx, adb, gdb等)来获取systemstate:
$ gdb $ORACLE_HOME/bin/oracle <process ID>
(gdb) print ksudss(267)
括号中的数字(267)是你希望转储systemstate的级别.
**对于RAC挂起事件请看“RAC性能”部分中对于racdiag脚本的使用**
通过以下systemstate命令可在同一时点转储所有RAC节点状态:
SQL> oradebug -g all dump systemstate 267
总结,你可以上传以下文件:
– Hanganalyze输出
– Systemstate 转储(dumps)
– hangfiles.out (如果使用 HANGFG工具命令)
– alert.log
– 在一个很短时间内的Statspack/AWR/ASH 报告
– 可用的系统调试监控输出
更多信息,请查阅以下文档:
- Note:61552.1 – Diagnosing Database Hanging Issues
- Note:118527.1 – How to get a SYSTEMSTATE dump when unable to connect to the database
- Note:175006.1 – Steps to generate HANGANALYZE trace files
- Note 121779.1 – Taking Systemstate Dumps when You cannot Connect to Oracle
- Note:452358.1 – Database Hangs: What to collect for support.
- Note:362094.1 – HANFG User Guide
Process Spins (进程消耗CPU资源达100%)
当进程出现spinning现象,可使用以下命令:
(** Busy spin术语解释: 由于程序导致进程不断地检查是否条件为true)
sqlplus / as sysdba
SQL> oradebug setospid <OSPID of spinning process>
SQL> oradebug unlimit
SQL> oradebug dump errorstack 3
— wait for 1 minute
SQL> oradebug dump errorstack 3
从 pstack命令输出中获取进程call信息:
$ pstack <process id of spinning process>
可以使用Strace命令来记录系统进程的系统调动及相关进程输入信号等信息:
$ strace –p <process id of spinning process>
对于RAC系统,可以使用systemstate命令转储相关状态,此命令的使用在“诊断数据库挂起事件”部分有提到。
当试图在共享池中分配大块连续内存而失败时,Oracle会首先从池中清理当前不用的对象从而使得空闲内存碎片(chunk:内存块)得以合并。如果这样仍然没有足够大的单个chunk来满足分配需要,则会产生ORA-04031报错。有许多ORA-04031错误直接原因都是由于共享池的大小或调整不当造成的。
Note:报ORA-4031错误的进程并不总是内存消耗的元凶。错误的发生仅是因为此进程无法得到所需内存而造成的(askmac.cn)。
如果已经按所有步骤正确设置了共享池大小(SHARD_POOL_SIZE) , 但此问题仍然产生时,除了从应用(例如:使用绑定变量查询替代静态SQL等)入手进行分析解决问题外,也可从其他trace文件中获得共享池的一些快照信息==>
修改init.ora参数文件,增加以下事件以从追踪文件中获取相关问题信息:
event = “4031 trace name errorstack level 3”
event = “4031 trace name HEAPDUMP level 3”
注意:除非重启实例,否则这个参数文件设置不会起效。从Oracle 9.2.0.5版本起,除了在请求heapdump时使用level 1,2,3 或32 你同样可以使用相同等级并加值536870912.这样将会在此等级上再进一步显示5个最大的subheaps同时每个subheap下显示相关5个最大的heap areas.
如果问题可以重现,则可在执行有问题的SQL语句前,在会话级别对事件进行设置:
SQL> alter session set events ‘4031 trace name errorstack level 3’;
SQL> alter session set events ‘4031 trace name HEAPDUMP level 536870914’;
Level 536870912 转储5个最大subheaps并且对应每个subheap将显示其5个最大heap areas。由于ORA-04031错误可能在不同池中发生(共享池,大池,java池,流池等),其level值的设置可参照如下:
| Component | Level |
| PGA | 1 |
| SGA | 2 |
| Large Pool | 32 |
| Streams Pool | 64 |
| Java Pool | 128 |
Note: 如果4031错误出现频繁,在实例级设置此事件(heapdump 536870914)将会产生许多大的trace文件. 这不仅会影响数据库性能而且可能使数据库挂起 (某些情况下可能会使得数据库崩溃). 因此有必要及时使用以下语句关闭此事件追踪:
alter system set events ‘4031 trace name HEAPDUMP off’;
我们也通过Library cache转储来帮助确认产生ora-4031问题的游标:
sqlplus / as sysdba
SQL> oradebug setmypid
SQL> oradebug unlimit
SQL> oradebug dump library_cache 10
请注意:在Oracle 9.2.0.5+, 10g和11g版本中,4031 trace文件默认会在ORA-4031发生时产生并存放于user_dump_dest目录。如果你的数据库版本是其中的一个,那么你就不需要进行相关设置来生成4031 trace 文件。
ORA-4031 诊断 à
- 检查Alert日志并查看错误是否记录。注意不是所有ORA-4031错误都会记录在alert日志中。
- 如果错误被记录,请检查SGA的哪部分收到此错误。是共享池,大池,java池或streams池?
- 查询v$sgastat以检查是否有组件表现出非正常增长.
- 查询v$librarycache并检查:
– 有无无效对象 (多为DDL语句)
– 有无重载 (Library cache可能不够大)
– 内存命中率 (低命中率可能是非共享游标造成的)
- 检查是否存在高Version Counts的游标。 可通过v$sql_shared_cursor查询. 如果存在某父游标下有许多子游标的情况,检查不可共享的原因. 大量子游标会加快共享池的碎片化. 请确认应用正在使用绑定变量方式查询.
更多信息,请看:
- NOTE:146599.1 – Diagnosing and Resolving Error ORA-4031
- Note:396940.1 – Troubleshooting and Diagnosing ORA-4031 Error
- Note:554521.1 – ORA-4031 QUICK FIX – What to look for and what to do!
- Note:430473.1 – ORA-4031 Common Analysis/Diagnostic Scripts
这个错误原因是Oracle服务器进程不能从操作系统上分配出更多内存。含有PGA(程序全局区)的进程其内存的分配取决于服务器的设置。对于dedicated服务器进程,其包含了stack堆栈和UGA(用户全局区), 保存有用户会话信息、游标信息和数据分类排序区。在多线程模式配置(shared服务器)中,UGA是在SGA中进行分配,所以不对ORA-4030报错负责。
因此ORA-4030是对需要更多内存(用于stack UGA或PGA)来完成工作的进程而言的。
请记住产生ORA-4030错误的进程并非总是内存损耗的元凶,错误的发生仅仅是因为此进程无法取得所需的内存造成的。
当你碰到这个错误时,意味着你已不能从系统中分配内存。这可能是由于你的进程本身导致的(如果你的进程正需求很多内存),也可能是其他原因导致操作系统内存被耗尽(如过大的SGA或者太多进程占用了系统的物理内存和虚拟内存)。如何处理此问题?
- 确定是否还有足够可用内存?使用系统专用工具来检查内存使用情况 (如vmstat, top等).
- 是否存在操作系统设定限制? 检查ulimit命令检查当前资源限制.
- 是否存在Oracle限制设置? 检查pga_aggregate_target和相关会话的pga内存值.
- 找出当前哪个进程正在要求大量内存, 可通过v$statname 和v$sesstat以了解当前最忙的进程.
当进程正在稳定增长其所需内存时,我们可以观察它们的运行:
– 通过v$sql_area可以看到哪些命令正被执行:
SQL> select sql_text from v$sqlarea a, v$session s where a.address = s.sql_address and s.sid = <SID>;
– 你也可以通过heapdump转储来查看它们:
SQL> oradebug setorapid 10 (10是Oracle进程Id, 使用setospid 以设置当前调试进程)
SQL> oradebug unlimit
SQL> oradebug dump heapdump 5
– 如果报错问题间歇性发生或者由于进程失败太快以至于难以捕获(但又很可能是内存大量消耗的根本原因),则我们可以设置事件来获取heapdump转储信息:
SQL> alter sssion set events ‘4030 trace name heapdump level 5’;
…或者直接在 init.ora文件中设置event.
更多其他相关信息请看:
理解ORA-600错误含义对于评估客户数据库中可能存在的问题非常重要。ORA-600报错的第一个参数指出了问题所在的相关位置 (如 ORA-600 [XXXX]).对于此错误:
- 至少需要提供相关的 trace文件和log文件.
- 操作系统错误/消息日志 (如果可用的话, 像坏块问题等)
对此问题也有一些新工具可用于加快原因查找。工具使用及其他相关信息支持文档请看:
- Note:390293.1 – Introduction to 600/7445 Internal Error Analysis
- Note:153788.1 – Troubleshoot an ORA-600 Error Using the ORA-600 Argument Lookup Tool
此外,如果可能,请设法提供测试用例,数据库历史改变细节和出错频繁程度等情况。并查找Oracle在当时自动转储的任何system状态信息文件。
ORA-1801报错是指日期格式字符串太长以至无法做转换处理. 这仅发生在当几个长字符串按字面值被转换为一个日期部分时。如果当前没有相关错误的trace文件, 我们可以设置以下事件来获取errorstack和 heapdump ==>
对应实例级需在init.ora中设置:
event=”1801 trace name errorstack level 3; name heapdump level 13325″
或在系统级设置:
alter system set events ‘1801 trace name errorstack level 3; name heapdump level 13325’;
或在会话级设置:
alter session set events ‘1801 trace name errorstack level 3; name heapdump level 13325’;
当Oracle服务器进程做了某些错误的处理(以至于触发了某种形式的信号违背signal violation)时,会抛出ORA-7445这样一个通用错误, (就像UNIX下的SIGSEGV). 对我们来说,当碰到ORA-7445报错的时候,最重要的事情就是从trace文件中找到call stack trace信息,因为它告诉我们相关违背行为是在哪里发生的。
- 提供相关trace 文件
- 如果可以的话,请一并提供相关操作系统错误消息日志
- 如果存在相关core文件, 请从其中抓取出stack trace信息。
更多相关其它信息请看:
- Note:1812.1 – Ext/Pub TECH Getting a Stack Trace from a UNIX CORE file
- Note:164968.1 – What is an ORA-7445 Error?
- Note:390293.1 – Introduction to 600/7445 Internal Error Analysis
- Note:211909.1 – Customer Introduction to ORA-7445 Errors
另外,如果可能的话,请提供如测试用例,数据库历史改变信息以及错误放生频繁程度信息等相关信息。请查找当时Oracle自动生成的systemstate转储文件。
这里我们讨论下如何诊断一些未预料的Oracle错误(ORA-NNNN)。
在诊断问题前,做一些例行询问(按经验总结,尝试形成一种模式). 例如:
- 是否总是同一个用户/应用造成的?
- 是否是在数据导入时发生?
- 问题是在做了哪些操作或修改了哪些之后产生的?
之后,我们需要收集更多信息以了解错误是如何产生的,甚至到哪些语句触发了此问题(如果问题是由一个递归SQL语句造成的话)。为了达到此目的我们需要在会话级或实例级建立Errorstack事件. 如果你能很容易地重现问题,那么用会话级,否则则需要在实例级建立事件。
因此,假设我们收到一个ORA-904 “invalid column”报错,我们可以使用:
alter session set events ‘904 trace name errorstack level 3’;
或
alter system set events ‘904 trace name errorstack level 3’;
或
event = “904 trace name errorstack level 3” (in the init.ora)
一旦我们获取了trace文件,我们就能从以下对象中找出实际产生错误的SQL语句:
- “当前执行的SQL”
- “当前执行的游标”
然后你就能直接通过这些找到的SQL来重现问题。而这已经足以用来确认出原因。
更多相关其他信息请看:
- Note:37871.1 – EVENT: ERRORSTACK – How to get
为诊断数据库性能问题所要收集的信息:
- 提供对以下问题的回答 à
- 性能退化影响到了哪些方面?
- 是否DBA能登陆并检查v$视图?
- 你是否能将性能回复到正常? 如何做到的?
- 提供STATSPACK/AWR/ADDM 报告以能对性能问题做一些短期快照. 请不要跑得报告时间段过长超出问题发生时间. 对实例来说,如果问题持续了半小时,那么抓取那个时间段中20分钟的状态为佳。如果你能精确把握整个时间过程,那么在性能问题发生前获取第一个快照,然后在产生性能问题的过程段中获取另一个快照。请不要在两个快照间重启实例,因为这将使得获取的结果变得无意义。
- 你也可以在系统运行得“不错”的时候做一个快照(相同时间长度),这个快照可以作为和有性能问题的快照对比时基准。
- 如果我们需要一个更短时间片上信息(不如当前当前的分析需要5到10分钟的详细活动信息), 那么可以查看ASH (Active Session History活动的会话历史) 报告输出. ASH报告工具在判断活动会话数量,查询会话从事的任务和在一段时间最活跃的SQL语句时很有用。它特别擅长用于分析短暂的性能问题。 运行此报告的ashrpt.sql脚本可以在 $ORACLE_HOME/rdbms/admin目录中找到。
- 收集操作系统参数来衡量其活动(在运行正常和性能不佳时):
- CPU
- 磁盘I/O
- Memory/Swap
- 进程活动
- 操作系统监控程序OS Watcher输出
- 提供 2个 Hanganalyze报告和 3 个Systemstate转储信息报告 (具体请看“数据库挂起”部分章节)。
- 提供系统RDA收集报告。
- 提供Oracle LTOM工具收集的信息。
更多其他相关信息请看:
- Note:210014.1 – How to Log a Good Performance Service Request
- Note:438452.1 – Performance Tools Quick Reference Guide
- Note:748642.1 – What is AWR (Automatic workload repository) and How to generate the AWR report?
- Note:339834.1 – Gathering Information for RDBMS Performance Tuning issue
- Note:402983.1 – Database Performance FAQ
- Note:164768.1 – Diagnosing High CPU Utilization
- Note:301137.1 – OS Watcher User Guide
- Note:352363.1 – LTOM – The On-Board Monitor User Guide
- Note:391182.1 – Database performance competency – Road Map
- Note:605439.1 – Recommendations for Gathering Optimizer Statistics on 10g
- Note:749227.1 – Recommendations for Gathering Optimizer Statistics on 11g
- Note:465787.1 – Managing CBO Stats during an upgrade to 10g or 11g
- Note:276103.1 – Performance Tuning Using 10g Advisors and Manageability Features
- Note:744963.1 – Performance Troubleshooting Guide
当监听器(Listener)发生性能问题时设置一个级别16的客户端连接追踪。
在客户端sqlnet.ora文件中设置参数:
TRACE_LEVEL_CLIENT=16
TRACE_FILE_CLIENT=CLIENT
TRACE_DIRECTORY_CLIENT=full path to directory where you want the trace file created.
TRACE_TIMESTAMP_CLIENT=on
TRACE_UNIQUE_CLIENT=on
获取这几分钟监听器进程(tnslsnr)的truss命令输出以及(发生问题的时间段)不同时间点上pstack信息输出。
====================================================
Truss ==> truss -o /tmp/mytruss -faed -p <pid of listener process>
…这个工具会一直保持追踪直到你终止它。可以使用ctrl-c来终止truss。如果你是在后台运行此工具命令,那么可以通过kill来杀掉truss进程以终止它的运行。
Process stack ==> pstack <pid of listener process>
…执行3次此命令,之间间隔30秒左右
如果可以的话,做一个短暂的监听器追踪:
=============================================
在服务器端sqlnet.ora文件中设置参数::
TRACE_LEVEL_SERVER=16
TRACE_DIRECTORY_SERVER=<some_known_directory>
TRACE_FILE_SERVER=server
TRACE_TIMESTAMP_SERVER=ON
TRACE_FILELEN_SERVER=<file_size_in_Kbytes>
TRACE_FILENO_SERVER=<number_of_files>
…后2个参数是为了避免服务器上的监听器trace文件过多而设的. 举例如果你在客户端设置了以下参数:
TRACE_FILELEN_SERVER=100
TRACE_FILENO_SERVER=2
…那么客户端上的2个100K的trace文件会被先后填满。之后客户端会切换回第一个trace文件继续写入trace信息,覆盖原有的trace内容,当写满后,再到第二个trace文件中写,如此往复。因此在trace信息被覆盖前,你需要将这些文件拷贝到其他目录。
我们也可以通过使用LSNRCTL 来对监听器进行追踪,并且此工具会一直运行会话结束(除非你主动关闭它).在 LSNRCTL 命令中不存在“=”符号.
LSNRCTL set current_listener listenername
LSNRCTL SET TRC_LEVEL 16
…好了,这样LSNRCTL就开始追踪了. 让它跑一会,这样我们就能看到追踪到的行为信息以及相关的延迟了。
在跑了至少5分钟后, 关闭LSNRCTL:
LSNRCTL set current_listener listenername
LSNRCTL SET TRC_LEVEL OFF
在使用 LSNRCTL进行追踪时, 在listener.ora文件中设置 ADMIN_RESTRICTIONS_listener_name=ON 以禁止运行时其参数的修改. 这样,监听器就会拒绝SET命令对其参数的修改了。更多信息请看 Note:272633.1.
如果需要改变listener.ora中包括ADMIN_RESTRICTIONS_listener_name本身以及其他参数的设置。我们将不得不手工修改listener.ora文件并用RELOAD命令使得参数起效。
请注意: 服务器端的追踪并不会在你改了Oracle Net(服务器端) tracing参数为OFF后关闭。它会随着客户端tracing的关闭而自动关闭。如果tracing由于疏忽一直保持启用, 则它可能将导致非常巨大trace文件的产生并损耗服务资源。为了正确关闭Oracle Net server tracing, 在设置tracing参数值为OFF后主动 stop并restart Oracle Net server 进程. 这可能会导致一些进程的关闭并引发数据库重启,严重程度取决于当前涉及到的会话数量。
因此,你需要上传以下文件:
– 客户端sqlnet trace文件
– 对于客户端低效连接的Pstack trace
– 监听器进程的Truss输出
– 3个对监听器进程的Pstack traces (3 of them).
– alert.log
– listener.log
– listener traces
更多其他相关信息请看:
- Note:214022.1 – Oracle Net “Connect Time” Performance Tuning
- Note:67983.1 – Oracle Net Performance Tuning
- Note:28588.1 – Using Truss / Trace on Unix
- Note:110888.1 – How to Trace Unix System Calls
对于SQL语句性能问题诊断, 我们需要了解:
- 对于存在性能问题的SQL语句. 你能否通过使得性能回归正常? 如何修改?
- 提供SQL在良好和较差性能下的执行计划输出.
- 设置级别12的事件10046追踪以生成trace文件(在良好和较差性能情况下) à
alter session set events ‘10046 trace name context forever, level 12’;
- 在良好和较差性能情况下的SQL运行 Tkprof输出
- 在良好和较差性能情况下的SQL运行时间
- 在执行计划输出中对涉及对象的定义 (如 DDL).
- 在执行计划输出中对涉及基表的行数统计
- 在良好和较差性能情况下的事件10053的trace输出à
ALTER SESSION SET EVENTS ‘10053 trace name context forever, level 1’;
…为了获取有效 10053 trace信息, 就不可避免需要对SQL语句进行硬解析。我们可以通过改变SQL语句的大小写或空格多少来达到此目的或通过清空共享池(在生产环境中并不推荐)来实现。
对Oracle 10g及以上版本:
- 你能使用AWR/Statspack报告和awrsqrpt.sql脚本来获取2个AWR快照之间的SQL语句执行计划。从AWR/StatsPack报告中, 定位产生性能问题的语句的SQL_ID并生成以下:
— 对应SQL_ID的AWR SQL报告
— 以SYSDBA登陆SQL*Plus
— SQL> @?/rdbms/admin/awrsqrpt.sql
— 请确保所使用AWR快照都是来自于获取的SQL_ID地方。
- 对AWR报告中相应SQL_ID的查询提供数据字典信息:
— 以SYSDBA 登陆SQL*Plus.
— SQL> SELECT PLAN_TABLE_OUTPUT FROM
TABLE(DBMS_XPLAN.DISPLAY_CURSOR(‘<sqlid>’));
其它信息收集 (特别对于bug) à
对于执行计划的查询性能问题,请收集所有相关查询对象输出转储和其统计参数,通过使用这些信息,我们可以及时重现这些良好和较差的执行计划。
更多其它相关信息请看à
- Note:21154.1 – EVENT: 10046 “enable SQL statement tracing (including binds/waits)”
- Note:225598.1 – How to Obtain Tracing of Optimizer Computations (EVENT 10053)
- Note:41634.1 – TKProf Simplistic Overview
- Note:372431.1 – TROUBLESHOOTING: Tuning a New Query
- Note:398838.1 – FAQ: Query Tuning Frequently Asked Questions
- Note:163563.1 – TROUBLESHOOTING: Advanced Query Tuning
- Note:208340.1 – Troubleshooting SQL Tuning
- Note:215187.1 – SQLT (SQLTXPLAIN) – Enhanced Explain Plan and related diagnostic info for one DML SQL statement
如果由于数据库升级导致的查询性能退化,请看 à
- Note:160089.1 – Server Upgrade Results in Slow Query Performance
- Note 258167.1 – Upgrading from 8.1.X to 9.X – Potential Query Tuning Related Issues
- Note 295819.1 – Upgrading from 9i to 10g – Potential Query Tuning Related Issues
- Note:752662.1 – TROUBLESHOOTING Query Tuning
- Note:748200.1 – Slow Performance of Queries After Upgrading To 10g
对于数据库在安装或重连时发生问题的信息收集:
- /tmp/OraInstall/oraInstall.err
- /tmp/OraInstall/oraInstall.out
- ../oraInventory/logs/installActions.log
- $ORACLE_HOME/install/make.log
- 对于补丁安装的OPATCH工具日志
更多其他相关信息请看 à
- Note:181459.1 – How to troubleshoot an Oracle database software installation on Unix
- Note:131321.1 – How to re-link Oracle Database software on Unix
- Note:111796.1 – How to resolve Database Creation Assistant (DBCA) errors
- Note:136818.1 – Oracle Server RDBMS Installation Issues
- Note:168600.1 – How to find Server Installation log files
- Note:262592.1 – How to tune your Database after Migration/Upgrade
- Note:208946.1 – Troubleshooting Database Creation
- Note:208059.1 – OS Software Upgrades
- Note:211559.1 – Relinking Guide
- Note:466181.1 – 10g Upgrade Companion
- Note:601807.1 – Oracle 11gR1 Upgrade Companion
- Note:785351.1 – Oracle 11gR2 Upgrade Companion
- Note:1100303.1 – Upgrade to 11g Performance Best Practices
请具体描述问题. 当提到问题发生时间时,请尽量精确,如某个特定时间等。
请提供RAC配置细节:
- 在集群中节点号
- 确定是否第三方集群件正和集群就绪服务(CRS)一起被使用
- 注册盘和表决盘的存储类型
- 确认ASM是否正被使用
- 每个节点上数据库实例的数量
RAC 诊断(racdiag.sql)脚本被用于提供用户友好向导并对RAC挂起会话及低性能情景进行问题排查。脚本包括了用于判断RAC挂起原因而进行收集大量重要调试信息的相关操作信息。此脚本在转储hanganalyze信息的同时,并会在本地目录中建立一个racdiag<timestamp>.out文件。
除了从查询输出中判定锁和等待会话之外,racdiag脚本还会动态生成 systemstate 转储和 hanganalyze信息输出。此外, racdiag还提供了内部连接性能的主要度量标准。
从文档 135714.1中对于 racdiag的描述 à 这个脚本应该能在RAC环境中出现会话或系统级挂起时运行。脚本应该以SYS用户运行。在运行racdiag脚本前, catparr.sql应该已经以SYS运行过,以在受影响的数据库中建立相关GV$视图。有一些系统挂起类型事件能够阻止racdiag脚本的运行。 如果此脚本跑不起来,那么建议以SYS用户在每个节点获取systemstate转储信息以帮助调试问题。
请上传以下文件:
- sql脚本输出文件
- 每个节点的AWR/ASH报告或 Statspack输出
- 操作系统监控器输出(如果此监控器正运行在当前系统上)
相关racdiag脚本及其他信息请看à
- Note:135714.1 – Script to Collect RAC Diagnostic Information (racdiag.sql)
- Note:412894.1 – Diagnosing Hangs and Troubleshooting Performance Issues in a RAC Environment
- Note:556679.1 – Data Gathering for Troubleshooting RAC Issues
- Note:810394.1 – RAC Assurance Support Team: RAC Starter Kit and Best Practices
请具体描述问题. 当提到问题发生时间时,请尽量精确,如某个特定时间等。
请提供RAC配置细节:
- 集群中的节点数量
- 是否有第三方集群件正和集群就绪服务(CRS)一起被使用
- 注册盘和表决盘的存储类型
- 确认ASM是否正被使用
- 每个节点上数据库实例的数量
对于实例驱逐被踢(Eviction)问题的诊断– 如ORA-29740错误, 请参考以下文档来做数据收集工作:
- Note 219361.1 – Troubleshooting ORA-29740 in a RAC Environment
- Note:412884.1 – Data Gathering for Instance Evictions in a RAC environment
至少你需要上传:
- 对于此类问题,除了上传数据库实例后台进程相关trace文件以外, 也要上传(每个实例)RAC特定后台进程 (如LMON, LMS, LCK, LMD, DIAG 等) 相关trace文件.
注意: 如果问题导致实例重起, 请确保以上上传文件来自重起之前的实例。
- 每个实例的告警日志文件
- 获取被踢的每个实例AWR/ASH报告或 Statspack输出
- 使用pl工具来收集Oracle集群件日志. 更多详情请看文档 330358.1. 运行diagcollection.pl时,使用 ‘–nocore’参数选项可降低输出的文件大小.
- 系统消息日志,具体文件位置取决于所使用的操作系统:
– Linux: /var/log/messages
-Windows: 使用事件查看器查看保存的应用日志和系统日志TXT文件。 – Sun: /var/adm/messages
– IBM: /bin/errpt -a (被重定向到messages.out文件)
– HP-UX: /var/adm/syslog/syslog.log
– Tru64: /var/adm/messages
- 如果有操作系统监控器运行,则也请获取所有节点的监控器输出
注意:当Oracle实例被启动后,每个相关后台进程(PMON,SMON,LMS,DIAG等)会产生一个trace文件。之后仅当需要转储trace文件时,才会继续对这个trace 文件进行写入。请不要删除这些文件。如果你删除了属于某个后台进程的Trace文件, Oracle trace信息仍会保持向这个节点位置中写入。这造成了有用的诊断信息被丢失。如果你发现属于某个Oracle数据库后台进程trace文件被删除,请按My Oracle Support文档中提供的步骤来重建它:
Note:394891.1 – How to recreate background trace file(s) that may have been accidentally deleted
对于CRS问题:
- 如果正在使用第三方提供的clusterware (SFRAC, SUN Cluster等.), 首先判断是否第三方cluster正在运行 (参考文档 803661.1).
- 检查当前CRS是否正在运行:
◦ crsctl check crs
◦ crs_stat –t
- 检查是否所有私有内连接都起了并可ping通
◦ ifconfig –a
◦ traceroute <private interconnect IP>
- 检查表决盘(voting disks)和注册盘(OCR)都可以从所有节点访问到
◦ ocrcheck
◦ ls –l <full path of voting disk>
- 请提供以下信息:
- sql输出
- CLUVFY (Cluster 验证工具) 输出.
- 系统消息日志. 其存放位置取决于当前操作系统:
– Linux: /var/log/messages
– Windows: 使用事件查看器查看保存的应用日志和系统日志TXT文件。
– Sun: /var/adm/messages
– IBM: /bin/errpt -a (重定向到 messages.out文件)
– HP-UX: /var/adm/syslog/syslog.log
– Tru64: /var/adm/messages 如果监控工具正在运行,其操作系统监控输出将存放在此目录中
- 从每个cluster节点上的三个目录树中收集所有CRS日志文件, trace文件和core转储文件 :
– $CRS_HOME (css/log css/init crs/log crs/init evm/log evm/init srvm/log racg/dump log)
– $ORACLE_HOME (racg/dump admin/*/hdump)
– $ORACLE_BASE (admin/*/hdump)
…也可以用另一种方法获取打包的trace文件:
$CRS_HOME/bin/diagcollect.pl
其他相关信息请看:
- Note 339939.1 – Running Cluster Verification Utility to Diagnose Install Problems
- Note 272332.1 – CRS 10g Diagnostic Collection Guide
- Note 330358.1 – CRS 10gR2/ 11gR1/ 11gR2 Diagnostic Collection Guide
- Note:289690.1 – Data Gathering for Troubleshooting CRS Issues
- Note:783456.1 – CRS Diagnostic Data Gathering: A Summary of Common tools and their Usage
- Note:556679.1 – Data Gathering for Troubleshooting RAC Issues
- Note:357808.1 – Diagnosability for CRS / EVM / RACG as directed by Oracle support
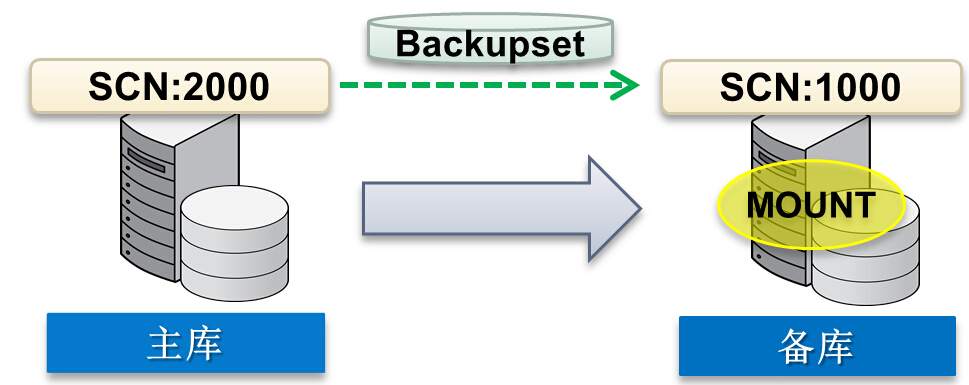
– 确认归档日志是否成功被传送到备库。
– 判断Data Guard设置是非级联设置的还是级联设置,物理备库设置还是逻辑备库设置。- 确认主库是归档日志模式并已开启自动归档。
– 确认归档有足够空间。
– 判断是否产生错误的条件都满足。
– 确认备库处于mounted状态。
– 确认managed recovery 正在运行.
其他相关信息请看:
- Note:237213.1 – Troubleshooting Data Guard
- Note:312434.1 – Oracle10g Data Guard SQL Apply Troubleshooting
- Note:814417.1 – Dataguard Information gathering to upload with the Service Requests
- Note:241374.1 – Script to Collect Data Guard Primary Site Diagnostic Information
- Note:241438.1 – Script to Collect Data Guard Physical Standby Diagnostic Information
– 检查系统瓶颈: CPU (sar -u), I/O (iostat), Memory (vmstat)
– 数据库等待事件 (ARCH 传输, SYNC传输等.)
– 查看Statspack Stats报告 (重做率”redo rate”, 事务率”transaction rate”, 平均重做写大小”average redo write size”,…)
– 检查网络 (备库是否可连?, 是否有网络错误?, 网络带宽是否足够?)
– 检查alert.log (主库和备库)文件中的所有错误.
– 检查系统消息日志中的错误. 日志文件位置取决于你所用的系统:
– Linux: /var/log/messages
– Windows: 应用日志和系统日志被保存为 .TXT文件并使用事件查看器查看
– Sun: /var/adm/messages
– IBM: /bin/errpt -a (重定向到文件 messages.out)
– HP-UX: /var/adm/syslog/syslog.log
– Tru64: /var/adm/messages
更多其他信息请看:
- Note:241925.1 – Troubleshooting 9i Data Guard Network Issues
- Note:745201.1 – Diagnosing Connection Problems with an active Data Guard Broker Configuration
- Oracle9i Data Guard: Primary Site and Network Configuration Best Practices
对于问题解决及原因分析,请à
- 具体描述问题。
- 描述Streams设置信息 – local capture or downstream capture, number of Streams database, unidirectional or bi-directional replication, etc.
- 来自源和目标系统的Alert 文件.
- 当报告Streams问题时,请提供源和目标数据库健康检查报告 (请看 Note 273674.1)
- 运行Streams 故障发现查询脚本. 参考 Note 729860.1.
- 对于STREAMS 性能问题:
◦ 请参考Streams Performance recommendations (Note 335516.1).
◦ 请参看Note 290605.1在源和目标数据库运行STRMMON.
◦ 生成源及目标数据库当时时段AWR/ASH/ADDM报告.
更多其他信息请看à
- Note:746247.1 – Troubleshooting Streams Capture when status is Paused For Flow Control
- Note:335502.1 – How To Reinstantiate a Single Table in a Streams Environment
- Note:749036.1 – How to re-synchronize the streams replicated objects online
- Note:405541.1 – Print the LCR’s listed in the Error Queue
- Note:291686.1 – LogMiner Utility Release 8.1.x – 10g
当对Streams Apply进程进行问题诊断时,我们需要注意以下3种情况:
1) 没有事务到达目的地
- 检查apply进程状态并确认其是启用的
- 确认apply进程是否还没使事务出队列。
- 检查队列的传播是否有发送事务到应用端
- 检查相关规则是否有在global, schema和table每个级别上正确建立以控制(获取capture, 传播propagation, 应用apply)
- 检查 init.ora文件
- 检查BACKGROUND_DUMP_DEST下的trace文件
2) 事务到达了目的地端, 但没有出队列.
- 确认是否 apply进程没有让任何事务出队列
- 检查出错队列
- 检查是否有定义冲突的方案
- 检查对象实例化SCN
- 检查当前数据库 SCN值
- 检查BACKGROUND_DUMP_DEST下的trace文件
3) 事务到达目的地端并出队列, 但没有被应用.
- 检查apply进程延迟
- 检查出错队列
- 检查是否有定义冲突的方案
- 检查对象实例化SCN
- 检查当前数据库 SCN值
- 检查BACKGROUND_DUMP_DEST下的trace文件
注意: 任何情况下, 请通过Streams健康检查脚本以提供报告输出。
请看以下文档以便了解与上文相关的更详细信息 à
- Note:230898.1 – How To Troubleshoot the Streams Apply Process
- Note:273674.1 – Streams Configuration Report and Health Check Script
- Note:730036.1 – Overview for Troubleshooting Streams Performance Issues
- Note:418755.1 – 10gR2 Streams Recommended Configuration
- Note:789913.1 – Streams Troubleshooting guide step by step
- Note:779801.1 – Streams Conflict Resolution
- Note:265201.1 – Troubleshooting Streams Apply Error ORA-1403, ORA-26787 or ORA-26786
如果你碰到高级队列传播问题 (很慢或卡住), 请收集以下信息:
sqlplus / as sysdba
oradebug setospid <spid of the j00 background process executing the schedule>
oradebug unlimit
oradebug Event 10046 trace name context forever, level 12
–等待10分钟
oradebug Event 10046 trace name context off
exit
sqlplus / as sysdba
oradebug setospid <spid of the j00 background process executing the schedule>
oradebug unlimit
oradebug Event 24040 trace name context forever, level 10
–等待10分钟
oradebug Event 24040 trace name context off
exit
oracledebug tracefile_name命令能显示trace文件在哪里生成
当传播问题发生,我们需要从所有实例中获取相关systemstate转储信息à
sqlplus / as sysdba
oradebug setmypid
oradebug unlimit
oradebug -g all dump systemstate 266
— 等大约2分钟
oradebug -g all dump systemstate 266
相关其他信息请看 à
- Note:233099.1 – Troubleshooting Advanced Queuing Propagation
- Note:102926.1 – Performance Tuning Advanced Queuing Databases and Applications
相关信息请看:
- Note:1035874.6 – Troubleshooting Guide: Replication Propagation
- Note:122039.1 – Troubleshooting Basics for Advanced Replication
- Note:231499.1 – Multi-Master Replication: Diagnostic Information Required & What To Check
ASM 问题诊断 (包括在空闲空间存在并可用时的 ASM磁盘空间耗尽报错)
====================================================================
▪请执行My Oracle Support Note:351117.1 中的ASM调试脚本 (收集诊断ASM空间问题所需信息)
▪ 提供ASM alert.log文件, traces 及操作系统消息文件 (可能同时需要数据库和 ASM alerts 和traces文件)
更多其他信息请看à
- Note:340417.1 – Data Gathering for Troubleshooting ASM Issues
- Note:309815.1 – Configuring Oracle ASMLib on Multipath Disks
- Note:284646.1 – Creating and using the kfed utility to view ASM disk header
当消息网关不处理任何信息,请获取以下诊断信息进行分析:
对Hang问题及 系统State进行信息收集及转储à
sqlplus / as sysdba
oradebug setmypid
oradebug unlimit
oradebug –g all hanganalyze 3;
等待30秒后再次运行hanganalyze…
oradebug setmypid
oradebug unlimit
oradebug –g all hanganalyze 3;
Sqlplus / as sysdba;
oradebug setmypid;
oradebug unlimit;
oradebug –g all dump systemstate 266;
等待30秒后再次运行hanganalyze…
oradebug setmypid;
oradebug unlimit;
oradebug –g all dump systemstate 266;
当消息网关不处理消息时,扩大gateway日志级别以收集更多gateway进程相关信息。
sqlplus / as sysdba;
SELECT * FROM MGW_GATEWAY;
exec DBMS_MGWADM.SET_LOG_LEVEL (3);
上传MGW trace文件.
获取MGW Java进程相关thread转储文件:
ps -ef | grep mgwextproc
使用以下脚本命令得到JVM下的thread转储信息
for pids in `ps -ef | grep mgwextproc | awk ‘{print $2}’`
do
echo $pids
kill -3 $pids
done
Trace文件会在当前工作目录中产生。请上传这些trace文件。
ORA-3113错误通常产生自Oracle客户端工具。此错误意味着客户端未能和Oracle影子进程进行通讯。此错误常常需要我们收集更多的信息来帮助分析原因,且原因也多种多样。因此这种“oracle影子进程通讯失败”错误是一种“普遍涉及”类型。ORA-3113常发生在当由于某些原因致Oracle服务器进程死亡时。
我们需要更多信息用来判断错误成因:
- 错误是发生在尝试建立数据库连接时或在一个已经建立的连接上?
- 在USER_DUMP_DEST(或11g上的$ADR_HOME/trace)目录下存在相关失败会话的trace文件。
- 此错误是因为特定命令造成的或是随机产生的? 如果是由于特定命令造成的,在会话级别开启 SQL_TRACE以找到问题命令.
其他相关信息,请看 à
- Note:17613.1 – ORA-3113 on Unix – What Information to Collect
- Note:1020463.6 – DIAGNOSING ORA-3113 ERRORS
为方便解决及原因分析, 请提供以下内容 à
- BACKGROUND_DUMP_DEST或$ADR_HOME/trace下的Alert.log文件
- Alert log文件中最新涉及的错误(如ORA-600或ORA-7445)相关的trace文件.
- 当时Oracle自动收集的系统状态转储文件
- RDA (Remote Diagnostic Agent远程诊断代理)输出,可参考Note 314422.1
有很多原因可能造成坏块,其包括:
– IO硬件损坏
– 操作系统问题
– Oracle造成的问题
– 对数据库中已使用”UNRECOVERABLE”或”NOLOGGING”关键字命令操作的数据恢复(这种情况会提示ORA-1578错误)
Oracle发现并报错的时间可能晚于数据最初产生讹误的时间。
由于并非总能了解当时坏块产生的原因,而多数情况下,关键业务需求数据库立即响应并再次开始运行,因此以下步骤用于处理当前问题:
- 判断数据讹误问题的影响程度及范围,是临时的还是永久不可恢复的错误。如果坏块大范围出现或者错误在各处不断产生,那么就需要先集中精力先确定问题原因(如检查硬件设备等)。这一点很重要,如果你的硬件本身出了问题,那怎么操作都无法恢复系统。
- 替换或移走(可能)存在问题的硬件设备。
- 判断哪些数据库对象收到了影响。
- 选择最恰当的数据库恢复/数据解救方案。
为方便解决及原因分析, 请提供以下内容à
- BACKGROUND_DUMP_DEST 或 $ADR_HOME/trace下的Alert.log文件
- Alert log文件中最新涉及的错误(如ORA-600或ORA-7445)相关的trace文件
- Block转储及其他相关诊断信息,可参考 Note 28814.1
- RDA (Remote Diagnostic Agent远程诊断代理)输出,可参考Note 314422.1
更多相关信息请看à
- Note:1088018.1 – Master Note for Handling Oracle Database Corruption Issues
- Note:28814.1 – Handling Oracle Block Corruptions in Oracle7/8/8i/9i/10g/11g
- Note:412566.1 – Basics of Debugging/Getting Dumps on Windows and Unix Platforms for Internals/Corruption Analysts
- Note:76375.1 – Prevention, Detection and Repair of Database Corruption
问题解决及原因分析à
- Note:132941.1 – RMAN: Quick Debugging Guide
- Note:815857.1 – Troubleshooting RMAN Performance or Hang Issues
- Note:748257.1 – RMAN Troubleshooting Catalog Performance Issues
- Note:740911.1 – RMAN Restore Performance
Oracle企业管理器 / 网格控制(OEM/Grid Control)
为方便问题解决及原因分析,请à
- 具体描述问题
- 对于EM Agent问题:
– 打包压缩并上传$AGENT_HOME/sysman/log中的文件
– $AGENT_HOME/sysman/config/emd.properties文件
– Note 229624.1 – How to Log and Trace the EM 10g Management Agents
- 对于OMS错误及问题:
– 打包压缩并上传$OMS_HOME/sysman/log中的文件
– $AGENT_HOME/sysman/config/emoms.properties文件
– Note 229627.1 How to Log and Trace the EM 10g Management Service
– Note 421053.1– EMDiagkit Download and Master Index
更多相关信息请看 à
- Note:311580.1 – How to Troubleshoot Metric Collections
- Note:421053.1 – EMDiagkit Download and Master Index
- Note:421638.1 – EMDiagkit Overview
问题解决及原因分析à
- Note:16564.1 – SQL*Net V2 on Unix – A Quick Guide to Setting Up Client Side Tracing
- Note:219968.1 – SQL*Net, Oracle Net Services – Tracing and Logging at a Glance
- Note:67983.1 – Oracle Net Performance Tuning
问题解决及原因分析à
为了调试检查补丁问题,需要设置:
◦ export OPATCH_DEBUG=TRUE
◦ export PERL_DL_DEBUG=1
请看相关信息 à
- Note:403212.1 – Location Of Logs For Opatch And OUI
问题解决及原因分析 à
- Note:338433.1 – How to Trace JDBC in 10g
- Note:434462.1 – How To Turn On Server Side Tracing From A JDBC Program
内存泄漏是指当进程始终不能归还其做临时使用而分配的内存时,可用内存在这种分配下逐渐损失的情况。内存泄漏最终可导致可用内存不断变少最终耗尽。如果不做检查,那些正受到内存泄漏的进程将不断增长对内存的需求直到其达到当前系统对用户模式下进程设置所允许的最大值。因此,对内存基线需求和内存泄漏之间的判断就很必要了。当然内存使用的增长并不一定归因于内存泄漏。
问题解决及原因分析à
- Note:477521.1 – How To Troubleshoot Memory Leaks on Microsoft Windows
- Note:477522.1 – How To Troubleshoot Memory Leaks on UNIX
- Note:1003841.1 – Diagnosing swap full problems/possible memory leak issues
- Note:166490.1 – Diagnosing Oracle memory on HP using GLANCE
- Note:163763.1 – Diagnosing Oracle memory on Sun Solaris using PMAP
- Note:166491.1 – Diagnosing Oracle Memory on AIX using SVMON
- Note:403584.1 – Understanding and Diagnosing ORA-600 [729] Space Leak Errors