
本文固定链接:https://www.askmac.cn/archives/advanced-mapreduce-development.html
高级MapReduce开发
第五章从我们熟悉的SQL概念的角度讨论了MapReduce的基础知识。学习了如何用MapReduce来解决一些常见的问题。还学习了数据是如何从输入文件中读取,然后在MAP中处理,使用Partitioner传送至Reducers,最后由Reducers处理,并写入HDFS输出文件中去的。
本章探讨SQL的排序和连接特性,这需要引入MapReduce程序更为复杂的概念。我们学习了多个输出文件是如何从单一的MapReduce程序被写入的。最后,我们了解了计数器,它可以用来收集MapReduce程序的统计数据(www.askmac.cn)。
MapReduce编程模式
本章介绍了在SQL功能背景下,MapReduce设计模式:
- 排序:当需要输出必须按照一定的标准进行排序时
- 连接:以各表的相似列值为基础,将各个不同的表组合起来
在看这些案例之前,我们先来简单探讨一下Hadoop框架基本的I / O类。搞清楚这一点,你就能真正了解Hadoop在幕后是如何工作的。
Hadoop I / O介绍
本章介绍了两种常见的基于关系数据库的案例:排序和连接。但首先,你需要了解Hadoop的I / O系统。第5章讨论了以下类:
- Text
- IntWritable
这些由Hadoop框架提供的类,有非常具体的实现方案,使其能够作为Mappers 和Reducers的键和值被使用。我们首先讨论提供此功能的这些类的特点。在这一过程中,也应该学会如何在Hadoop框架内开发可作为键和值类型使用的自定义类。
用于Mappers 和Reducers中键和值的所有类,都应该能够被序列化为一个原始字节流,以及反序列化回类实例。当被读入Mapper 后,这些类实例被反序列化,然后再序列化到一个字节流,并通过网络发送给Reducer 使用。在Reducer 节点内,这些原始字节被反序列化回Reducer 端的键/值类实例中。该记录由Reducer 端输入键排序(正如第5章中所讨论的,此进程一部分在Mapper 上进行,最终在Reducer上完成),然后提交给Reducer的reduce方法。最后,Reducer输出需要数据,序列化成原始字节,并写入到磁盘(www.askmac.cn)。
键和值类的主要特征如下:
- 用作键和值的类应该能够被序列化和反序列化
- 用作Reducer端键的类应该能够支持用户自定义排序
图6-1 展示了一个MapReduce程序从输入文件到输出文件的流程
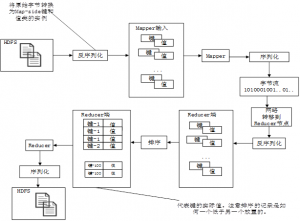
图6-1 Hadoop中的序列化/反序列化和排序流程
图6-1展示了Mappers 和 Reducers 是如何通过网络进行通信的。写入文件或通过网络传输时,键和值实例需要被序列化。字节流在被Mappers 或Reducers 可使用前,首先需要被反序列化为键和值实例。
Writable和WritableComparable接口
参与Mapper 和Reducer 进程的所有对象都必须实现一个特定的接口:Writable接口。或者,Reducer 端键类可以实现WritableComparable实例。虽然后者不是必需的(用来支持排序的替代方法,在本章后面将会讨论到),却是一个你将定义的键类中支持自定义排序最简单的方法。Hadoop所有主要的Writable实例,如Text和IntWritable,都实现了该接口,来支持这些类实例默认的排序标准。
图6-2展示了Writable和WritableComparable接口的继承层次。Writable接口拥有支持对象序列化和反序列化的方法。
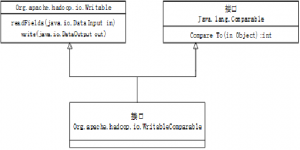
图6-2 Hadoop I/O类层次
Writable接口有两种方法:
- write(java.io.DataOutput out): 将该实例的所有原始属性写入到由io.DataOutput实例表示的输出流中。该DataOutput类中有序列化Java基本类型的方法。
- readFields(java.io.DataInput in): 利用从io.DataInput实例所表示的输入流中获取的数据,重新创建Writable实例。该DataInput类中有反序列化Java基本类型的方法。
这些方法之间的唯一契约是,在write()方法 和readFields()方法中的字段的顺序应相同。数据在从数据流中读取和写入的顺序相同(www.askmac.cn)。
Hadoop也提供了一定的保障。Reducer 输入通过键进行排序。WritableComparable接口可用于自定义排序行为。WritableComparable接口从Writable类继承了它序列化和反序列化记录的能力,以及标准java.lang.Comparable类的排序功能。
实际经验证明,Mapper 输出(或Reducer 输入)键类应实现WritableComparable接口。所有其他类型(如用于Mapper 输入的键和值类,Mapper 输出的值类,以及Reducer 输出的键类)只需实现Writable接口。因为WritableComparable接口是Writable类的一个子类型,当使用Writable 时总是会用到WritableComparable,但反过来就不一定。目前为止你遇到的所有类(如,Text和IntWritable)都实现了WritableComparable接口,使得它们在 Mappers 和Reducers中被作为键和值使用。
Mappers 输出键类(或Reducers输入键类)并不是必须要实现WritableComparable。如果仅实现了Writable,你必须创建一个实现RawComparator接口的类。在本章后面你将会看到这样的例子。
问题定义:排序
本节探讨了使用Hadoop的排序案例。排序在实践中是非常普遍的,在使用SQL时通过ORDER BY关键字实现。
通过研究排序功能,使你学会了如何开发前面所讨论过的自定义Writable和WritableComparable类。但首先我们必须为该练习创建一个案例上下文。该排序方法实现了以下功能:
- 航空公司数据集将按照月份和一周中的天数进行排序。为了使它更有趣一点,我们也将增加另一项要求:输出的月份按递增顺序排序,每周天数按递减顺序排序。
- 下述示例程序支持任意数量的reducers。如果我们用12 个reducers,则输出将被分成12个文件,以便每个月的数据是在其自己的文件里。例如,一月的数据在文件part-r-00000中,二月的数据在文件part-r-00001中,依此类推,直到十二月的数据在part-r-00011文件中。在每个文件内,数据将按星期以递减顺序排序。或者,我们可以只使用一个Reducer,则输出月份以递增顺序排序,星期以递减顺序排序。如果我们所使用的reducers数量大于1且不等于12,则记录将被划分在不同的文件中,使得输出键(月份和星期的组合)能在文件间被均匀地划分。他们还可以跨文件排序(称为总排序)。这意味着,如果我们对它们按名称升序排序后又附加文件,则按键排序与使用单一reducers是相同的。
- MapReduce程序的输出为文本行的记录,仅包括以逗号分隔格式的以下字段:
- 月份
- 一周的天数
- 年份
- 日期
- 到达延迟
- 起飞延迟
- 起飞机场代码
- 目的地机场代码
- 航空公司代码
根据输出我们可以做出的一些分析,来确定航班延误与延误位置或航空公司之间是否有关系。
主要挑战:总排序
MapReduce的保证之一是,Reducer 的输入总是由Reducer 输入键排序。如果我们只用一个Reducer,排序就很简单:我们只要选择进行排序的键,并使它成为Reducer 输入键。Reducer 中的到达记录按键(由Sort Comparator implementation定义,我们很快会研究)进行排序(www.askmac.cn)。
使用单一Reducer 是运行任务最有效的方式,实际上,它很快遇到大量记录的瓶颈。我们希望使用多个Reducers,虽然给定Reducers的键被排序,也不能保证它们在Reducers间被排序。因此,如果我们使用IntWritable实例作为Reducers的键,很可能Reducer1按此顺序将获得键1,2,5,8 ;Reducer2将获得键3,4,6,7 。即使为给定Reducer对它们进行排序,也不会跨Reducer排序。将有两个输出文件被单独排序,但part-00002输出文件上的所有键并不比part-00001输出文件上的所有键高(降序排序情况下不比它低),这是进行跨文件总排序的一个要求。
总排序的诀窍在于分区程序的执行。我们利用本节中考虑的用例:月份按升序排序,星期按降序排序。因为我们每年有12个月,每周有7天,共有84个键。根据该标准,键的顺序如下,其中第一个元素是月份,逗号后面的第二个元素是星期:
- 1,7
- 1,6
- …
- 1,1
- 2,7
- …
- 2,1
- …
- 12,7
- …
- 12,1
接下来,我们利用下列公式将前述键范围转换为索引号(Month_Id-1)*7 + (7-Day_of_Week Id),其中Month_Id取值范围为1到12 ,Day_of_Week取值范围为1到7
索引0对应一月和星期日,索引1对应一月和星期六,索引6对应一月和星期一,以此类推,直到索引83对应十二月和星期一。
最后,我们用Reducer对键的索引号范围0-83进行分区。如果有12个Reducer,索引就被均匀划分:Reducer-0获取范围0-6 ,Reducer- 1获取范围7-13 ,以此类推,直到达到Reducer-11,其获取范围为77-83 。这种情况下,每个Reducer处理特定月份的记录。
但是,如果我们使用不同的Reducer 计数会怎样,比如说20?在这种情况下,我们需要更复杂的逻辑分区。处理这种情况的一种方法是执行运算84/20 = 4(忽略余数)。各个Reducer 处理索引如下:Reducer – 0处理范围0-3,Reducer – 1处理范围4-7 ,Reducer 18处理范围72-75 ,剩下Reducer -19来处理剩余的8个键索引范围为76-83 。虽然这种分区方法很简单,但会导致分区严重不平衡。Reducer – 19需要其他Reducer两倍的时间来完成,这会对整体的任务执行产生消极影响。随着Index_Range%#Reducers计算(或Index_Range/#Reducers计算余数)的增加,这一问题变得更糟。 (本书中执行的简化分区程序,我们使用的是这种方法,但在实践应用中你应该考虑根据接下来的讨论改变这种方法)
一个更好的分区方案是采取计算84%20 = 4的余数,并使前4个Reducers处理额外的键。例如,Reducer-0处理键索引0-4 ;Reducer- 1处理键索引5-9 ;Reducer- 2和Reducer- 3分别处理索引10-14和15-19。以Reducer- 4开头,各Reducers处理4个连续的索引键范围。例如,Reducer- 5处理范围20-23 ;Reducer- 6处理范围24-27,依此类推,直至Reducer-20 处理范围80-83。
总排序的关键步骤如下:
- 在WritableComparable键上实现排序逻辑或编写自定义的比较器。这可确保键能够到达以自定义方式排序的Reducer中。在这个例子中,我们将用WritableComparable键类的compareTo方法实现排序逻辑。
2.定义将Reducer键实例转换成索引号的函数,并限定这些索引号的范围。
- 用以下方式实现自定义分区:
1.了解整个Reducer键的索引范围。
2.利用键、传递到分区调用Reducer的数量和对Reducer键索引范围的情况来实现先前描述的分区逻辑(www.askmac.cn)。
这里暗含了一个问题。我们的键范围是固定的,但如果在运行时我们必须通过动态传递键范围来配置Partitioner ,该如何做到?默认情况下,Partitioner 接口不支持配置。用各个键来传递信息是非常昂贵的,因为键是通过网络传输的。关键是要让自定义分区程序实现org.apache.hadoop.conf.Configurable接口,它提供两种重要的配置方法:
- getConf()
- setConf(Configuration conf)
前一个方法用来传递配置对象的整个范围。在初始化阶段, Hadoop框架创建一个自定义Partitioner 的实例。当Hadoop反射工具实例化该类时,他们通过检查来看该类是否是可配置的类型。如果是,调用 setConf,那么在第一次调用getPartition之前该任务的配置实例对Partitioner 可用。
- 注意:在本书源代码以下类中提供了可配置定制partitioner的一个示例模板(自定义此模板来创建自己的配置分区):org.apress.prohadoop. c6.ConfigurablePartitioner。
Hadoop通过如TotalOrderPartitioner和InputSampler类来支持总排序。目的是让一个单独MapReduce程序在你自己的程序之前执行。该程序的目的是有效地确定键范围,因为在大多数情况下,你并不知道键范围。Hadoop库提供旨在通过采样记录有效识别键范围的InputSampler类。利用InputSampler类返回的键范围可创建一个分区文件,其中每个分区的范围都被明确定义,且分区数量与Reducers 数目相同,来为主MapReduce程序配置。用InputSampler创建的分区是基于这样的假设:键均匀分布,这并不是对每个案例都可行。然后分区文件被TotalOrderPartitioner类用来根据键挑选Reducers (记住,分区文件有和Reducers 同样多的分区,每个分区都有一个最小和最大配置键值。所以根据键很容易挑选正确的减速器索引)。注意,Reducers 的数目被分区文件中的分区数固定。要改变减速器的数目,首先要重新生成分区文件。你也可以通过编写自定义类代替使用InputSampler来创建分区文件。如果键的分布不均匀,并且你想利用这些知识创建大小均匀的分区,你就应该这样做(www.askmac.cn)。
实现一个自定义键类:MonthDoWWritable
我们使用自定义Writable类代替Hadoop提供的默认类,如Text和IntWritable来实现MapReduce的排序例程。随着设计的发展,这样做的好处显而易见。首先我们来定义键类,我们称之为MonthDoWWritable。表6-1展示了该类的实现。
表6-1 MonthDoWWritable实现
package org.apress.prohadoop.c6;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.WritableComparable;
public class MonthDoWWritable implements WritableComparable<MonthDoWWritable>{
public IntWritable month=new IntWritable();
public IntWritable dayOfWeek = new IntWritable();
public MonthDoWWritable(){
}
@Override
public void write(DataOutput out) throws IOException {
this.month.write(out);
this.dayOfWeek.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
this.month.readFields(in); this.dayOfWeek.readFields(in);
}
//Sort ascending my month and descending my day of the week
@Override
public int compareTo(MonthDoWWritable second) {
if(this.month.get()==second.month.get()){
return -1*this.dayOfWeek.compareTo(second.dayOfWeek);
}
else{
return 1*this.month.compareTo(second.month);
}
}
@Override
public boolean equals(Object o) {
if (!(o instanceof MonthDoWWritable)) {
return false;
}
MonthDoWWritable other = (MonthDoWWritable)o;
return (this.month.get() == other.month.get() && this.dayOfWeek.get() == other.dayOfWeek.get());
}
@Override
public int hashCode() {
return (this.month.get()-1)*7;
}
}
该设计的主要特点如下所示:
- 总是为 Mapper 输出或Reducer 输入键类实现WritableComparable。
- 提供一个无参数的构造函数。虽然在默认情况下提供,如果你提供了另一种带参数的构造函数,记得要加无参数的构造函数。 Hadoop框架通过调用无参数构造函数创建实例,如果它没有被定义,在运行时会产生异常,然后任务失败。
- write()方法是一种将字段写入输出流的序列化方法。注意,只有必要信息才被序列化,这是为Hadoop编写新的序列化框架背后的一个主要动机。网络论坛上充斥着很多关于原始Java序列化框架是如何充分的热烈讨论。现在要知道Hadoop机制非常的高效且表现良好。
- readFields()方法负责将数据流反序列化回一个Writable实例。注意,字段的顺序与write()方法相同。
回想一下,Writable接口有两种方法:write() 和 readFields()。由于WritableComparable扩展了Writable,这些方法都是从Writable接口继承的。因为我们正在编写一个自定义类,所以必须实现这两种方法。
- compareTo方法用于比较Writable的两个实例。它是WritableComparable接口扩展的 lang.Comparable接口的一部分。compareTo操作的实现确保输出月份按升序排序,星期按降序排序。1和-1的倍增因数确保这一点。
- hashCode的作用仅仅是为MonthDoWWritable实例提供一个散列。我们通过定义使其根据MonthDoWWritable的month字段拥有0到11的值。注意,这不是唯一一个基于MonthDoWWritable属性值的。hashCode显然不需要是唯一的。因此equals方法应当与hashCode一起实现以确定返回相同hashCode的两个实例是否确实相等。注意,hashCode返回值用于HashPartitioner,它是Hadoop中的默认 Partitioner类。因此,如果我们不定义一个自定义分Partitioner,用MonthDoWWritable作为Mapper 输出键类的MapReduce程序将只根据MonthDoWWritable实例的月份属性进行分区。在该例中,我们将定义一个自定义分区器,因为我们的分区逻辑是以MonthDoWWritable的月份和星期属性为基础的(www.askmac.cn)。
实现一个自定义值类:DelaysWritable
现在,让我们来定义值类,我们称之为DelaysWritable。表6-2展示了该类的实现。
为什么要有一个自定义的Writable类?为什么不直接在Reducer 中提取我们需要的字段,用上一节中我们所定义的键类实例将整行记录传递到Reducer ?尽管这是可能的,却大大增加了Mapper 和Reducer 之间的I / O。在将其发送到Reducer 之前仅提取Mapper 中所需的字段,这确实是个好方法。
在这种情况下,为什么不直接提取我们所需的字段,并创建一个Text实例?Text实例只是所需字段的逗号分隔字符串。虽然这是一个可以接受的解决办法,但Text实例包含的只有字符串,而字符串需要比原始变量更多的空间。大部分输出都是由数字构成。因此,使用自定义的Writable类可提升程序的I / O性能。(第7章中你将了解二进制格式的存储结果,如序列文件)
表6-2 DelaysWritable实现
package org.apress.prohadoop.c6;
//Import statements
public class DelaysWritable implements Writable{ public IntWritable year=new IntWritable();
public IntWritable month = new IntWritable();
public IntWritable date = new IntWritable();
private IntWritable dayOfWeek = new IntWritable();
public IntWritable arrDelay = new IntWritable();
public IntWritable depDelay = new IntWritable();
public Text originAirportCode = new Text();
public Text destAirportCode = new Text();
public Text carrierCode = new Text();
public DelaysWritable(){
}
public void setDelaysWritable(DelaysWritable dw){
this.year = dw.year;
this.month = dw.month;
this.date = dw.date;
this.dayOfWeek = dw.dayOfWeek;
this.arrDelay = dw.arrDelay;
this.depDelay = dw.depDelay;
this.originAirportCode = dw.originAirportCode;
this.destAirportCode = dw.destAirportCode;
this.carrierCode = dw.carrierCode;
}
@Override
public void write(DataOutput out) throws IOException {
this.year.write(out);
this.month.write(out);
this.date.write(out);
this.dayOfWeek.write(out);
this.arrDelay.write(out);
this.depDelay.write(out);
this.originAirportCode.write(out);
this.destAirportCode.write(out);
this.carrierCode.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
this.year.readFields(in);
this.month.readFields(in);
this.date.readFields(in);
this.dayOfWeek.readFields(in);
this.arrDelay.readFields(in);
this.depDelay.readFields(in);
this.originAirportCode.readFields(in);
this.destAirportCode.readFields(in);
this.carrierCode.readFields(in);
}
}
该设计的主要特点如下所示:
- 对于值类,仅实现Writable接口是足够的。因为DelaysWritable从未被作为键使用。
- 因前一节中所述原因,提供一个无参数的构造函数。
- write() 和 readFields()方法负责序列化和反序列化。
对MapReduce程序排序
用于实现用例排序的客户端程序列于org.apress.prohadoop.c6.SortAscMonthDescWeekMRJob文件中。
该程序的一些特点如下所示:
- 它支持可变数量的Reducers ,和Reducers 输入键在不同Reducers (总排序)间的排序记录
- 采用智能分区器,为一个键选一个Reducers 以确保总排序。
- 虽然该代码使用任意数量的Reducers 都可工作。但是记住以下几点Reducers 的计数特点:
- 理想情况下,Reducers 数量应使键的整个范围(84个键对应12个月,一周中的7天)为Reducers 数量的倍数。因此,如果选了21个Reducers ,那么每个Reducers 就有4个键。如果选了20个减速器,则前19个Reducers 每个获得4个键,最后一个Reducers 获得8个键。
- 如果所选的Reducers 数量大于这个范围(84),则前84个减速器每个获得1个键,其余的Reducers 没有键(www.askmac.cn)。
run()方法
与该任务不同的run()方法的主要代码行如下:
job.setMapOutputKeyClass(MonthDoWWritable.class); job.setMapOutputValueClass(DelaysWritable.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); job.setMapperClass(SortAscMonthDescWeekMapper.class); job.setReducerClass(SortAscMonthDescWeekReducer.class); job.setPartitionerClass(MonthDoWPartitioner.class);
本书中第一次,使用自定义类型的键和值类。在该例中,Mapper 的输出键和值对都是自定义类型。
也使用到了Partitioner 的服务。此类是负责确保这些键进入适当的Reducer ,以便输出以正确方式在各Reducer 间排序。
Reducer 的数量必须作为参数传递(参见第5章):
-D mapred.reduce.tasks=12
为了更好的学习,应使用不同数量的Reducer 运行此程序。
SortAscMonthDescWeekMapper类
表6-3显示了SortByMonthAndDayOfWeekMapper类的源代码。
注意用于Mapper 输出的键是如何表示的。
表6-3 SortByMonthAndDayOfWeekMapper
public static class SortAscMonthDescWeekMapper extends Mapper<LongWritable, Text, MonthDoWWritable, DelaysWritable> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
if(!AirlineDataUtils.isHeader(value)){
String[] contents = value.toString().split(",");
String month = AirlineDataUtils.getMonth(contents);
String dow = AirlineDataUtils.getDayOfTheWeek(contents);
MonthDoWWritable mw = new MonthDoWWritable();
mw.month=new IntWritable(Integer.parseInt(month));
mw.dayOfWeek=new IntWritable(Integer.parseInt(dow));
DelaysWritable dw = AirlineDataUtils.parseDelaysWritable(value.toString());
context.write(mw,dw);
}
}
}
parseDelaysWritable()方法的代码列表如表6-4所示。它采用航空公司的数据并将其转换为DelaysWritable()的一个实例。
表6-4 AirlineDataUtils.parseDelaysWritable()
public static DelaysWritable parseDelaysWritable(String line) {
String[] contents = line.split(",");
DelaysWritable dw = new DelaysWritable();
dw.year = new IntWritable(Integer.parseInt(AirlineDataUtils.getYear(contents)));
dw.month = new IntWritable(Integer.parseInt(AirlineDataUtils.getMonth(contents)));
dw.date = new IntWritable(Integer.parseInt(AirlineDataUtils.getDateOfMonth(contents)));
dw.dayOfWeek = new IntWritable(Integer.parseInt(AirlineDataUtils.getDayOfTheWeek(contents)));
dw.arrDelay = new IntWritable(AirlineDataUtils.parseMinutes(AirlineDataUtils.getArrivalDelay(contents), 0));
dw.depDelay = new IntWritable(AirlineDataUtils.parseMinutes(AirlineDataUtils.getDepartureDelay(contents), 0));
dw.destAirportCode = new Text(AirlineDataUtils.getDestination(contents));
dw.originAirportCode = new Text(AirlineDataUtils.getOrigin(contents));
dw.carrierCode = new Text(AirlineDataUtils.getUniqueCarrier(contents));
return dw;
}
MonthDoWPartitioner类
排序的核心在于MonthDoWPartitioner类。如果没有这个元件,结果将在一个Reducer内部排序,而不是跨Reducer排序。表6-5展示了该类的实现。
表6-5 MonthDoWPartitioner
public static class MonthDoWPartitioner extends Partitioner<MonthDoWWritable, Text> implements Configurable {
private Configuration conf = null;
private int indexRange = 0;
private int getDefaultRange(){
int minIndex = 0;
int maxIndex = 11 * 7 + 6;
int range = (maxIndex - minIndex) + 1;
return range;
}
@Override
public void setConf(Configuration conf) {
this.conf = conf;
this.indexRange = conf.getInt("key.range", getDefaultRange());
}
@Override
public Configuration getConf() {
return this.conf;
}
public int getPartition(MonthDoWWritable key,
Text value,int numReduceTasks) {
return AirlineDataUtils.getCustomPartition(key,indexRange, numReduceTasks);
}
}
如前面所讨论的,我们使用可配置的Partitioner。为做到这一点,我们需要为我们的自定义Partitioner 实现Configuragle接口。我们在setConf()方法中配置范围。虽然我们可以将索引范围作为配置参数“key.range”传递,但在客户端程序中我们不这么做。这是因为我们的范围是固定的,且由getDefaultRange()方法来进行计算。下面一行只是证明Partitioner 是如何从配置实例中被配置的一个例子(www.askmac.cn)。
this.indexRange = conf.getInt("key.range", getDefaultRange())
用于计算reducer 索引的实际逻辑存在于AirlineDataUtils类的getCustomPartition方法中。将其保存在一个单独的工具类使我们能够直接测试此方法,而不必处理各种Hadoop的特定类以及Hadoop环境。(这一部分将在测试Hadoop程序那一章展开讨论)表6-6展示了getCustomPartition( )方法的程序代码。
表6-6 AirlineDataUtils.getCustomPartition
public static int getCustomPartition(MonthDoWWritable key,
int indexRange, int noOfReducers) {
int indicesPerReducer = (int) Math.floor( indexRange/ noOfReducers);
int index = (key.month.get()-1) * 7 + (7- key.dayOfWeek.get());
/*
*If the noOfPartitions is greater than the range just return the index
*All Partitions above the (range-1) will receive no records.
*/
if (indexRange < noOfReducers) {
return index;
}
for (int i = 0; i < noOfReducers; i++) {
int minValForPartitionInclusive = (i) * indicesPerReducer; int maxValForParitionExclusive = (i + 1) * indicesPerReducer;
if (index >=minValForPartitionInclusive && index < maxValForParitionExclusive) {
return i;
}
}
/*
If the index>=indicesPerReducer*(noOfReducers) the last partition
gets the remainder of records.
*/
return (noOfReducers - 1);
}
Partitioner逻辑的特点如下所示:
- 键的范围是确定的。我们将每个键定义为一个数字,可通过前面所述的公式计算:索引键 = 月份 * 7 + (7-星期几)
- The total number of partitions handled are calculated as the floor of the calculation range/ no Of Reducers where range = 84 because there are 84 distinct Thus, if the number of Reducers is 19, this value will be floor (4.42) = 4.
- 处理的分区总数被作为Reducers数量/计算范围的基底计算,其中范围=84,因为有84个不同的键。因此,如果Reducers的数量为19,该值将是基底(4.42)= 4。
- 每个Reducer的范围按如下公式计算:
- 最小值= Reducer指数*每个Reducer的键数
- 最大值= (Reducer指数+1)*每个Reducer的键数
最小值是包容性的,最大值是排他性的。当使用19个reducers,Reducer 0的这些值分别为0和4。Reducer 0处理索引范围0-3; Reducer 1处理索引范围4-7等。
- 当范围不是Reducers数目的倍数时,最后一个Reducer获得剩余的索引。在我们19个reducers例子中,最后一个Reducer索引为18,而它的键索引范围是72-75。然而,基于前述讨论,它也能处理索引值为76-83的键。为确保键能更均匀地分布,该范围应为Reducers数目的倍数。如果我们所使用的Reducers数量为21,所有的Reducers就能均匀处理键索引范围(每个Reducer四个索引)。
- 如果Reducers的数目大于所述范围,则Reducers索引只是前面所计算的索引值。如果Reducers数量是90,Reducers 0-83分别处理0-83的索引,但Reducers 84-89没有记录。
您可能要参考本章前面讨论的总排序问题,将它与刚才的讨论联系起来。实现的是Hadoop中TotalOrderPartitioner类的简单变化。这种简化性质对解释与实现总排序相关的关键概念是有用的(www.askmac.cn)。
- 注意 在我们的例子中,没必要使用一个Configurable partitioner。我们可以只计算每次调用getPartition()时的indexRange变量。这当然是可以接受的。然而,用MapReduce处理数十亿的记录是非常普遍的。必须避免产生不必要的变量。随着JVM变得高效,程序员已经习惯不去担心对象创建和垃圾收集的成本。然而,当运用到数十亿记录的批处理,成本就变得显而易见,并对其产生不利影响。用setConf()方法预先计算indexRange就是这样优化的一个例子。
SortAscMonthDescWeekReducer类
Reducer类通过调用AirlineDataUtils.parseDelaysWritableToText(…)将接收的DelaysWritable实例转换为逗号分隔的记录。
表6-7展示了SortAscMonthDescWeekReducer类。
表6-7 SortAscMonthDescWeekReducer
public static class SortAscMonthDescWeekReducer extends Reducer<MonthDoWWritable, DelaysWritable, NullWritable, Text> {
public void reduce(MonthDoWWritable key,
Iterable<DelaysWritable> values, Context context)
throws IOException, InterruptedException {
for (DelaysWritable val : values) {
Text t = AirlineDataUtils.parseDelaysWritableToText(val) context.write(NullWritable.get(),t);
}
}
}
在集群上运行排序任务
最后,我们用Maven重建,在Hadoop环境下执行如下任务:
hadoop jar prohadoop-0.0.1-SNAPSHOT.jar \ org.apress.prohadoop.c6.SortAscMonthDescWeekMRJob \ -D mapred.reduce.tasks=21 \ /user/hdfs/sampledata \ /user/hdfs/output/c6/sortbymonthandweek
输出目录应该有21个文件:part-r-00000到part-r-00020。确保记录是按月份(升序)和星期排序(降序),因此part-r-{index_i}文件中的每个记录遵守有关part-r-{index_j)文件的排序顺序,条件是{index_i}<{index_j}。
用Writable-Only键排序
本节考察了当仅使用Writable实例作为键时必须做出的修改。有时,你使用的是第三方库,且对这些所使用的类没有控制权。试想一下,你使用的是包含你希望用作键的Writable类的库。这些类被定义为final,这意味着你不能扩展他们以实现WritableComparable。本节将展示在这种情况下你应该怎样做。
- 注意 演示Writable实例作为键使用的Mapreduce程序在本书源代码中是可用的。类名称为org.apress.prohadoop.c6.SortAscMonthDescWeekWithOnlyWritableKeysMRJob。
本节只讨论主要区别。首先,键类,也就是现在所谓的MapDowOnlyWritable,只实现了Writable接口,而不是WritableComparable接口。在run()方法中不同的的行是这些:
job.setMapOutputKeyClass(MonthDoWOnlyWritable.class); job.setSortComparatorClass(ComparatorForMonthDoWOnlyWritable.class);
注意,我们现在已经提出了一个必须实现RawComparator接口的新的Sort Comparator类。表6-8展示了该类的源代码。
表6-8 一个RawComparator的实现
package org.apress.prohadoop.c6;
import java.io.IOException;
import org.apache.hadoop.io.DataInputBuffer;
import org.apache.hadoop.io.RawComparator;
public class ComparatorForMonthDoWOnlyWritable implements RawComparator {
MonthDoWOnlyWritable first = null;
MonthDoWOnlyWritable second = null;
DataInputBuffer buffer = null;
public ComparatorForMonthDoWOnlyWritable(){
first = new MonthDoWOnlyWritable();
second = new MonthDoWOnlyWritable();
buffer = new DataInputBuffer();
}
@Override
public int compare(Object a, Object b) {
MonthDoWOnlyWritable first = (MonthDoWOnlyWritable)a;
MonthDoWOnlyWritable second = (MonthDoWOnlyWritable)b;
if(first.month.get()!=second.month.get()){
return first.month.compareTo(second.month);
}
if(first.dayOfWeek.get()!=second.dayOfWeek.get()){
return -1 * first.dayOfWeek.compareTo(second.dayOfWeek);
}
return 0;
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
buffer.reset(b1, s1, l1);
first.readFields(buffer);
buffer.reset(b2, s2, l2);
second.readFields(buffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
return this.compare(first,second);
}
}
注意以下两种compare()方法:
- compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2): 通过框架用原始字节调用。该实现是负责调用创建在constructor上的Writable实例的readFields(),以重建Writable实例。
- compare(Object a,Object b): 调用在前面的步骤中使用重构的Writable实例。自定义排序实现中提出了此方法(www.askmac.cn)。
完全绕过第二个compare()方法是有可能的。重建Writable实例的整个过程都可避免,并在原始字节上完成比较。Hadoop的Text.Comparator类通过使用两个字段进行此操作来存储信息。第一个是存储在Text实例中的字符串的长度,第二个是在表示文本的字符串中包含实际字节的字段。该Text.Comparator类使用下面第一个compare()方法的实现:
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
int n1 = WritableUtils.decodeVIntSize(b1[s1]);
int n2 = WritableUtils.decodeVIntSize(b2[s2]);
return compareBytes(b1, s1+n1, l1-n1, b2, s2+n2, l2-n2);
}
注意,我们读取字节长度,并完全跳过这些字节。传递给compareBytes()方法的剩余信息仅表示Text实例中表示字符串的字节。底层实现在同一时间对其来比较字节数。只要两个实例间遇到的字节不同,就可对两个Text实例的排序顺序做出决定。讽刺的是,相等的字符串需要做的工作最多,因为需要比较所有的字节!
以下是Hadoop框架用来选择正确的排序实现的规则:
- 如果一个comparator类,实现了接口apache.hadoop. io.RawComparator,是通过在Job实例上调用setSortComparatorClass或通过设置mapred.output.key.comparator提供的(该属性在Hadoop 2中是被舍弃的,且用mapreduce.job.output.key.comparator.class取代。但是,如第5章所讨论的,舍弃的属性仍然有效,并被广泛使用)。
- 如果排序比较没有设置,所用的默认SortingComparator是注册为键类的。Hadoop库中的大多数WritableComparable类,如IntWritable类,在加载期间注册WritableComparator类( org.apache.hadoop. io.IntWritable.Comparator)。Hadoop库IntWritable类中的以下几行代码执行此功能:
static{
WritableComparator.define(IntWritable.class,new Comparator());
}
该org.apache.hadoop.io.IntWritable.Comparator是扩展了WritableComparator类的IntWritable类中定义的内部类。但是,如果一个WritableComparable的实现没有注册一个comparator类,默认行为是使用WritableComparator类,它的比较方法比较WritableComparable类的两个键实例。WritableComparator. compare方法被定义如下:
public int compare(WritableComparable a, WritableComparable b) {
return a.compareTo(b);
}
以排序探索重述Hadoop的关键特性
通过实现排序功能,讨论以下Hadoop的新特征:
- 实现一个自定义的键和值,分别作为WritableComparable和Writable接口的实现。
- 用一个自定义的Partitioner来实现跨多个Reducers记录的总排序。
- TotalOrderPartitioner是通常用来实现跨Reducers总排序的Hadoop类。它是本节中实现的自定义Partitioner类一种更通用的实现。
- Implement sorting when only Writable instances are used as the Mapper output
- 仅使用Writable实例作为Mapper输出键来实现排序
- 执行RawComparator为排序提供了非常有效的实现。我们研究了Hadoop库中Text 类的内部类Comparator是如何做到这一点的。
问题定义:分析连续记录
本节向你介绍了二次排序的概念。默认情况下,Hadoop框架通过一个键对Reducer输入进行排序,有时我们需要通过组合键排序。在如上一节所遇到的情况下,我们在键的WritableComparator接口上就可以实现这种逻辑。你已经见过默认HashPartitioner是如何以键类的hashCode()值为基础,决定哪些Reducer发送键和值对的。如果我们想一起处理那些只属于键的一部分的记录,该怎么办?我们将围绕这一概念创建一个案例。
我们已经创建了在机场识别到达及起飞延误的程序。假设除了报告一个给定航班的到达延迟情况,我们还应该报告前述延迟到达机场航班具体的航班信息。它要求我们在单个reduce调用中,处理机场所有到达航班的记录。我们将需要接收由航班到达时间排序的值。这是我们第一次面临按排序顺序接收值的挑战。
但是,为什么不能只创建一个包含所有组成排序标准属性(目的地机场代码+到达航班日期和时间)的组合键?这个问题引出两个复杂性:
- Partitioner需要确保涉及相同目的地机场代码的航班进入同一个Reducer。如果键的hashCode()实现使用了键的两种属性(目的地机场代码和到达时间),我们使用默认的HashPartitioner,则拥有相同目的地机场代码,但是不同到达时间的键将进入不同的reducers。
- 每个键是Reducer上一次单独的reduce调用。我们必须保持Reducer类中的状态变量,以确定目的地机场代码何时改变。
我们可以实现一个更好的解决方案。使用Secondary Sort方法,我们不仅可以确保属于同一到达机场代码的所有键进入同一个Reducer实例,而且所有的值都能按到达日期和时间正确排序,且这些值是在同一reduce调用中被处理的。
对于一个给定目的地机场端口,以下列的格式输出:
<ARRIVAL_DELAY_RECORD>|<PREVIOUS_ARRIVAL_DELAY_RECORD>
- 注意 为什么不直接使用目的地机场代码作为键,只需通过迭代reduce调用中的Iterable实例的值收集列表中键的所有值?然后,按到达日期和时间对内存中此列表进行排序。再然后,迭代已排序的列表产生所需的输出。虽然这一过程在函数上是正确的,但将导致内存使用爆炸,因为每个目的地机场代码都有数百万的记录。另外,我们只能等所有的记录都抵达了才能开始排序,因为给定键的值(recall,reducer输入是由键来排序的。给定键的值不排序)。这是使用Secondary Sort的理由;即使复杂;它也是实现这一目标的唯一途径。
对于给定目的地机场代码的第一个到达延迟记录,PREVIOUS_ARRIVAL_DELAY_RECORD为空白的。实现该功能的程序为:
org.apress.prohadoop.c6.AnalyzeConsecutiveArrivalDelaysMRJob.
支持Secondary Sort的关键部件
首先,我们来看实现Secondary Sort所需的关键部件;然后来研究在集群中这些部件是在哪儿执行的(Mapper端或Reducer端)。
实现Secondary Sort必需的四个主要部件如图6-3所示:
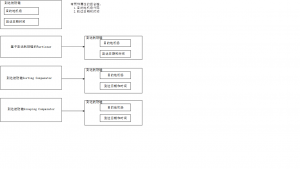
图6-3 用于Secondary Sort的部件及它们是如何使用这些关键属性
- 自定义WritableComparable键类:用于Mapper输出或 Reducer输入。compareTo方法实现的方式是非常微妙的(稍后将讨论)。其类为ArrivalFlightKey。
- 自定义Partitioner类:确保即使在自定义键类中两个属性都使用,也只用目的地机场代码选择Reducer。因此,即使有不同的键,代表某一特定目的地机场代码的键会进入同一个Reducer节点。其目标是使给定目的地代码的所有值都由同一reduce调用来处理。注意区别:首先我们必须获得同一Reducer节点的键和值对。接下来,我们在同一reduce调用中处理这些键和值对。我们已经明确地定义了这些组件,但因为hashCode功能,这在实现中并不需要,自定义键只使用目的地机场代码。因此,默认的Partitioner(HashCodePartitioner)是足够的。不过,为了解释说明,我们将对它进行明确定义。在实践中,你可能会使用无法控制的键类。理解Partitioner在实现Secondary Sort功能中所起的关键作用,这一点很重要。
- Sorting Comparator类:对记录排序。排序是完整的,并使用自定义Writable类ArrivalFlightKey的所有字段。类名是ArrivalFlightKeySortingComparator。如果我们使用ArrivalFlightKey中的compareTo操作来实现基于这两种属性的排序,则可以跳过编写该类。但在当前的实现中,我们不能这样做,因为自定义键类仅在目的地机场代码上排序,SoringComparator类需要以该键的两种属性为基础进行排序。
- Grouping Comparator类:在Reducer端对键进行分组。它被用来确定分组的标准,分组标准决定从Mapper 到Reducer是在一次reduce调用中处理哪个值。我们所使用的Grouping Comparator类为ArrivalFlightKeyGroupingComparator,它在一次reduce调用中对某一目的地机场代码的所有值进行分组。默认情况下,Grouping Comparator与Sorting Comparator类相同。
- 我们可以将Sorting Comparator 或 Grouping Comparator功能的其中之一委托给Reducer输入键类的compareTo方法。在例子中,我们选择同时自定义实现Sorting Comparator 类和Grouping Comparator类。不过,至于ArrivalFlightKey类是如何实现的,我们可以将Grouping Comparator功能委托给ArrvialFlightKey类的compareTo方法(www.askmac.cn)。
自定义键类:ArrivalFlightKey
ArrivalFlightKey类如表6-8所示。为简洁起见,只展示与该类相关的部分。已省略了readFields()和 write()方法,因为它们在前面章节中已经讨论过。
表6-9 ArrivalFlightKey
public class ArrivalFlightKey implements WritableComparable<ArrivalFlightKey> {
public Text destinationAirport = new Text("");
public Text arrivalDtTime = new Text("");
public ArrivalFlightKey() {
}
public ArrivalFlightKey(Text destinationAirport,Text arrivalDtTime) {
this.destinationAirport = destinationAirport;
this.arrivalDtTime = arrivalDtTime;
}
@Override
public int hashCode() {
return (this.destinationAirport).hashCode();
}
@Override
public boolean equals(Object o) {
if (!(o instanceof ArrivalFlightKey))
return false;
ArrivalFlightKey other = (ArrivalFlightKey) o;
return this.destinationAirport.equals(other.destinationAirport) ;
}
@Override
public int compareTo(ArrivalFlightKey second) {
return this.destinationAirport.compareTo(second.destinationAirport);
}
...
}
上述对compareTo方法的定义只使用了目的地机场代码来实现排序。我们很快就会发现,这个实现足以支持Grouping Comparator函数,而不是Sorting Comparator函数。我们可以用不同的方式实现它,以支持Sorting Comparator。在这种情况下,二者都不是必要的,因为我们将实现Sorting Comparator类 和 Grouping Comparator类,它们不将其函数提交给自定义键类处理。但是,我们将展示Grouping Comparator是如何将其函数提交给ArrivalFlightKey类的compareTo方法处理的。
自定义Partitioner: ArrivalFlightKeyBasedPartioner
表6-10 展示了自定义Partitioner的实现。Partitioner在自定义键的目的地机场代码基础上进行分区,忽略到达日期和时间。
表6-10 ArrivalFlightKeyBasedPartioner
public static class ArrivalFlightKeyBasedPartioner extends Partitioner<ArrivalFlightKey, Text> {
@Override
public int getPartition(ArrivalFlightKey key, Text value,
int numPartitions) {
return Math.abs(key.destinationAirport.hashCode() % numPartitions);
}
}
ArrivalFlightKey类的的hashCode()函数只通过使用目的地机场代码进行定义的,因此我们可以跳过定义一个自定义Partitioner,并允许Hadoop框架使用上一章中描述的默认HashPartitioner。不过,定义这些类的目的是使你理解这些Secondary Sorting工作所需的部件。需要注意的是,尽管这两个键不同(同一目的地机场代码,但不同的到达日期和时间),他们都进入同一个Reducer节点。因此Secondary Sort面临的第一个挑战是确保不同的键被路由到相同的Partitioner,条件是他们的目的地机场代码都相同且已处理。接下来的挑战是要确保通过使用Sorting Comparator和 Grouping Comparator(下面将会讨论),这些键和它们的值由同一Reducer节点上相同的reduce调用进行处理(www.askmac.cn)。
Sorting Comparator类:ArrivalFlightKeySortingComparator
Sorting Comparator类,如表6-11所示,通过使用从键中获取的全部信息对键进行排序。它运用你之前所看到的正常的排序,并确保值由全部键正确排序(至于键的两个属性,按升序排序)。Sorting Comparator类用在Mapper 和 Reducer的排序阶段。它确保Reducer输入按照目的地机场代码和到达日期时间以升序排序。
表6-11 ArrivalFlightKeySortingComparator
public class ArrivalFlightKeySortingComparator extends WritableComparator {
public ArrivalFlightKeySortingComparator() {
super(ArrivalFlightKey.class, true);
}
/*Default implementation is to invoke a.compareTo(b)*/
@Override
public int compare(WritableComparable a, WritableComparable b) {
ArrivalFlightKey first = (ArrivalFlightKey) a;
ArrivalFlightKey second = (ArrivalFlightKey) b;
if (first.destinationAirport.equals(second.destinationAirport)) {
return first.arrivalDtTime.compareTo(second.arrivalDtTime);
} else {
return first.destinationAirport.compareTo(second.destinationAirport);
}
}
}
需要注意的是,我们需要一个Sorting Comparator;我们不能使用在ArrivalFlightKey类中应用的排序。因为ArrivalFlightKey类的compareTo方法仅使用目的地代码。Sorting Comparator类中的constructor注册为自定义键类。当第二个参数为true时,WritableComparator constructor在构造函数中使用如下反射创建两个键类实例
protected WritableComparator(Class<? extends WritableComparable> keyClass,
boolean createInstances) {
this.keyClass = keyClass; if (createInstances) {
/*key1 and key2 are instance variables of type WritableComparable*/
/*newKey() is a method which uses reflection to create the
*custom WritableCompar
able instance
*/
key1 = newKey() key2 = newKey();
buffer = new DataInputBuffer();
} else {
key1 = key2 = null; buffer = null;
}
}
Hadoop框架在WritableComparator类中调用下列方法来比较键的两个实例:compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)
之前创建的两个实例用于通过使用键类Writable接口中的readFields()方法读取数据。
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) { try {
buffer.reset(b1, s1, l1); // parse key1 key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2 key2.readFields(buffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
return compare(key1, key2); // compare them
}
上述方法最终使用这两个实例调用compare(WritableComparable a, WritableComparable b)。我们已经覆写了compare(WritableComparable a, WritableComparable b)方法。compare方法的默认实现如下所示:
public int compare(WritableComparable a, WritableComparable b) {
return a.compareTo(b);
}
默认的实现清楚地表明为什么我们需要覆写此方法。ArrivalFlightKey类使用目的地机场代码进行比较。在我们先前讨论过的Text.Comparator类环境中对比上述讨论。在构造函数中作为第二个参数的类没有传递true 。它也没有调用WritableComparator的compare(WritableComparable a, WritableComparable b)方法。它使用字节流直接比较字节。从我们前面讨论的仅使用Writable (不是WritableComparable)实例作为键的角度考虑整个讨论。在这种情况下,我们不能调用compare(WritableComparable a, WritableComparable b),而要通过compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)方法来决定比较(www.askmac.cn)。
Grouping ComparatorClass: ArrivalFlightKeyGroupingComparator
Grouping Comparator类,如表6-12所示,仅在目的地机场代码的基础上对Reducer接收到的键和值对分组。该类连同Sorting Comparator,可以使我们解决Seconday Sorting的第二个挑战,即确保同一目的地代码的飞行记录在同一个reduce调用中处理,即使他们的抵达时间不同。Grouping Compartor只在乎它的compare方法是返回一个零值还是非零值。零意味着从分组的角度来说,两个键是相等的,非零意味着不相等。排序顺序不能被Grouping Comparator改变。
回想一下在第5章最后一节中对Shuffle 和Sort的讨论。当Reducer节点上的键和值被Sorting Comparator排序后,reduce被调用。因为每个键值对都会遇到需要作出是否应该由当前的reduce调用处理,还是需要调用新的一个reduce。做出这一决定是Grouping Comparator的责任。因为默认情况下它与Sorting Comparator相同,当Sorting Comparator的compare操作返回一个非零值时,新的reduce被调用。然而,当一个Grouping Comparator被配置时,这种行为可根据Reducer输入键部分属性的设置,在一个reduce调用中被定制为组值。
只有当ArrivalFlightKey实例的目的地代码不同时,ArrivalFlightKeyGroupingComparator的compare方法才返回一个非零值。因此,当与前一实例具有相同目的地代码和不同到达时间的新的ArrivalFlightKey实例到达时,一个新的reduce调用不会被激发。具有相同目的地代码和不同到达时间的键的值在同一reduce调用中被处理。由于原Mapper输出是由Sorting Comparator按目的地机场代码和到达时间进行排序的,在reduce调用中处理的值由目的地机场代码和到达时间进行排序。然而,在reduce调用内,键永远不会改变,且仍然是给定目的地机场代码中由Sorting Comparator排序的第一个键。这也是为什么把键的每个属性都包括在值对象中很重要的原因;否则,在reduce调用内迭代值时,这些属性就不能被访问。
表6-12 ArrivalFlightKeyGroupingComparator
public class ArrivalFlightKeyGroupingComparator extends WritableComparator {
public ArrivalFlightKeyGroupingComparator() {
super(ArrivalFlightKey.class, true);
}
/* Optional. If not provided the Key class compareTo method is invoked
Default implementation is as follows. Hence the custom key could
implement the sorting from a Grouping perspective
*
public int compare(WritableComparable a, WritableComparable b) {
return a.compareTo(b);
* }
*
* /
@Override
public int compare(WritableComparable a, WritableComparable b) {
// We could have simply used return a.compareTo(b); See comment above ArrivalFlightKey first = (ArrivalFlightKey) a;
ArrivalFlightKey second = (ArrivalFlightKey) b;
return first.destinationAirport.compareTo(second.destinationAirport);
}
}
为了便于说明,我们已经覆写了compare方法。但是,我们并不需要这样做,因为ArrivalFlightKey实现其compareTo方法,以适应Grouping Comparator的要求。WritableComparator类中compare方法的默认实现如下:
public int compare(WritableComparable a, WritableComparable b) {
return a.compareTo(b)
}
ArrivalFlightKey实例将被从compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)中传递,compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)负责调用创建在constructor实例上的readFields()方法,和调用compare(WritableComparable a, WritableComparable b)。我们在自定义实现中执行显式类型转换的唯一理由是,我们代替ArrivalFlightKey实例在destinationAirport属性中调用了compareTo。
这是很重要的一点:执行Secondary Sort时,Sorting Comparator或Grouping Comparator其中之一都可以使用自定义键类的排序行为,但不能同时使用(www.askmac.cn)。
Mapper类: AnalyzeConsecutiveDelaysMapper
Mapper类,非常简单,如表6-13所示。它所做的就是确定是否有到达延迟,并在创建自定义键后,将这些记录发送到Reducer。
表6-13 AnalyzeConsecutiveDelaysMapper
public static class AnalyzeConsecutiveDelaysMapper extends Mapper<LongWritable, Text, ArrivalFlightKey, Text> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if (!AirlineDataUtils.isHeader(value)) {
String[] contents = value.toString().split(",");
String arrivingAirport = AirlineDataUtils.getDestination(contents);
String arrivingDtTime = AirlineDataUtils.getArrivalDateTime(contents);
int arrivalDelay = AirlineDataUtils.parseMinutes(
AirlineDataUtils.getArrivalDelay(contents),0);
if(arrivalDelay>0){
ArrivalFlightKey afKey = new ArrivalFlightKey(new Text(arrivingAirport),new Text(arrivingDtTime));
context.write(afKey, value);
}
}
}
}
Reducer 类: AnalyzeConsecutiveDelaysReducer
表6-14展示了自定义的Reducer,它在reduce方法的local变量中对目的地机场以前的到达延迟进行跟踪记录。关键点在于:当我们使用Secondary Sort时,可以用局部变量做所有的计算。如果我们不使用Secondary Sort,我们将不得不在实例级上移动这个变量。这就是在相同Reducer实例中处理键/值对与在相同reduce调用中处理之间的区别。
表6-14 AnalyzeConsecutiveDelaysReducer
public static class AnalyzeConsecutiveDelaysReducer extends Reducer<ArrivalFlightKey, Text, NullWritable, Text> {
public void reduce(ArrivalFlightKey key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
Text previousRecord = null;
for (Text v : values) {
StringBuilder out = new StringBuilder("");
if(previousRecord==null){
out.append(v.toString()).append("|");
}
else{
out.append(v.toString()).append("|").append(previousRecord.toString());
}
context.write(NullWritable.get(), new Text(out.toString()));
//Remember to not use references as the same Text instance
//is utilized across iterations previousRecord=new Text(v.toString());
}
}
}
run( )方法
run()方法的关键行如表6-15所示。注意:Sorting Comparator 和Grouping Comparator被明确定义。
表6-15 AnalyzeConsecutiveArrivalDelaysMRJob.run()
job.setMapperClass(AnalyzeConsecutiveDelaysMapper.class); job.setReducerClass(AnalyzeConsecutiveDelaysReducer.class); job.setPartitionerClass(ArrivalFlightKeyBasedPartioner.class); job.setSortComparatorClass(ArrivalFlightKeySortingComparator.class); job.setGroupingComparatorClass(ArrivalFlightKeyGroupingComparator.class);
无Grouping Comparator,实现Secondary Sort
本书中附带的源代码包含不用Grouping Comparator实现Secondary Sort的列表。唯一的区别是,我们不用run()方法指定Grouping Comparator。默认情况下它与Sorting Comparator是一样的。因此,每个不同的ArrivalFlightKey实例(其中,它的两个属性中的一个是不同的),将产生一个新的reduce调用。我们仍然使用我们的自定义Partitioner,确保同一目的地机场代码的所有键都是由相同的Reducer实例处理。自定义Reducer如表6-16所示。注意,previousRecord变量现在已经从reduce方法向上转移到实例级别。区别是在相同Reducer实例中处理还是在同一reduce调用中处理(www.askmac.cn)。
表6-16 AnalyzeConsecutiveDelaysReducer no Secondary Sort
public static class AnalyzeConsecutiveDelaysReducer extends Reducer<ArrivalFlightKey, Text, NullWritable, Text> {
Text previousRecord = null;
public void reduce(ArrivalFlightKey key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text v : values) {
StringBuilder out = new StringBuilder("");
if(previousRecord==null){
out.append(v.toString()).append("|");
}
else{
out.append(v.toString()). append("|").append(previousRecord.toString());
}
context.write(NullWritable.get(), new Text(out.toString()));
//Remember to not use references as the same Text instance
//is utilized across iterations previousRecord=new Text(v.toString());
}
}
}
- 注意 根据前面的例子,似乎Secondary Sor不是那么重要,我们用正常排序就可以很容易地实现我们的目标。然而事实并非如此,也有一些复杂的必须使用Secondary Sort不可的案例。在实例级(reducer)管理状态比较复杂,与在本地方法: reduce中管理状态相比有可能造成副作用。hadoop实现是复杂的。它应该是简单和可维护的,特别是在Hadoop代码方面,其中的数据很大,漏洞也表现得很微妙。代码易于阅读和审查将使你在以后的过程中不那么头痛。
在集群上运行Secondary Sort任务
最后,我们执行一个maven构建。结果是生成一个叫做prohadoop-0.0.1-SNAPSHOT.jar的JAR文件。
在Hadoop环境下执行如下任务:
hadoop jar prohadoop-0.0.1-SNAPSHOT.jar \ org.apress.prohadoop.c6.AnalyzeConsecutiveArrivalDelaysMRJob \ /user/hdfs/sampledata \ /user/hdfs/output/c6/secondarysort
以Secondary Sort探索重述Hadoop的关键特性
随着Secondary Sort的实现,探索出Hadoop的以下关键特性:
- Sorting Comparator 和Grouping Comparator是如何用WritableComparable类工作的。
- 如何用一个仅使用部分自定义键的Partitioner控制哪个键被发送到哪个Reducer。
- Sorting Comparator在第一次调用Reducer上的reduce之前确保记录高效排序中发挥的作用
- Grouping Comparator在对多个值进行分组中发挥的作用,在单个reduce调用中,它的键只有部分是相等的。
问题定义:用MapReduce连接
连接两个数据集是SQL调用最常见的功能。在Hadoop框架中实现连接有两种方式:
- Map-side join:当两个数据集之一非常小时使用。例如,本章中所用的主数据量非常小。如果我们扩大载体描述的载体代码,就可以在每个Mapper内存中保存载体文件。当每次飞行记录经过map方法,由载体代码为载体描述执行内存中查找。该记录被扩展到包含载体描述,然后被写出;不需要任何Reducer。
- Reduce-side join: 当两个数据集都很大,且其中之一不能完全缓存在存储器时,但连接标准是:对于任何给定的连接实例,结果数量都非常小。在这样的情况下,我们可以利用Reduce-Side连接。两个数据集被读取,连接键被用作Mapper输出键。Mapper输出值也包含一个标记属性,显示记录(值部分)来自哪个数据集。在Reducer端上,两个记录被一起接收,并执行连接。为了使该方法有效,一个给定连接键从两个数据集中接收到的记录总数要足够小到足以在整个reduce调用期间保持在存储器中。如果连接的一端本来就小,而另一端非常大时,往往使用Secondary Sort。Secondary Sort确保记录是由最先来的较小的数据集排序。较小的数据集被保留在reduce调用内存中。当较大数据集的记录流入时,它们被用较小数据集的缓存记录连接起来。
本节讨论如何用Secondary Sort在MapReduce中执行连接。本节中的这一实现可以帮助你了解Secondary Sort的多种用途。join输出的特征如下:
- 我们必须生成和前面章节排序中所生成的同样的输出
- 在这种情况下,我们必须将载体代码扩展到其完整描述。最终输出与前面排序章节中的相似,但它最后有一个额外的字段:载体描述。
我们将用MapReduce程序通过Secondary Sort来说明这一概念,尽管我们本来可以只通过在每个Mapper实例的内存中缓存整个载体主文件来使用Map-side连接。事实上,我们在本章随后小节中用分布式缓存讨论连接时,将会探讨该连接方法(www.askmac.cn)。
处理多个输入:MultipleInputs类
通过使用MultipleInputs,我们可以为每个文件夹指定多个输入文件夹并给相应的Mappers使用。唯一的限制是他们Mapper输出的定义应该是相同的。其输入格式和输入的定义可能有所不同。以下作业定义中的行配置输入和输出路径:
String[] args = new GenericOptionsParser(getConf(), allArgs).getRemainingArgs(); Job job = Job.getInstance(getConf()); job.setJarByClass(JoinMRJob.class); job.setOutputFormatClass(TextOutputFormat.class); MultipleInputs.addInputPath(job, new Path(args[0]),TextInputFormat.class, FlightDataMapper.class); MultipleInputs.addInputPath(job, new Path(args[1]), TextInputFormat.class, CarrierMasterMapper.class); FileOutputFormat.setOutputPath(job, new Path(args[2]));
在该例中,我们用相同的输入输出格式。但如果我们的输入文件有不同的格式,MultipleInputs类可满足该要求。
多个输入的Mapper类
表6-17 展示了CarrierMasterMapper的定义,表6-18展示了FlightDataMapper的列表。
表6-17 CarrierMasterMapper
public static class CarrierMasterMapper extends Mapper<LongWritable, Text, CarrierKey, Text> {
public voidmap(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if (!AirlineDataUtils.isCarrierFileHeader(value.toString()))
{
String[] carrierDetails = AirlineDataUtils.parseCarrierLine(value.toString());
Text carrierCode = new Text(carrierDetails[0].toLowerCase().trim());
Text desc = new Text(carrierDetails[1].toUpperCase().trim());
CarrierKey ck = new CarrierKey(CarrierKey.TYPE_CARRIER,
carrierCode,desc);
context.write(ck,new Text());
}
}
}
表6-18 FlightDataMapper
public static class FlightDataMapper extends Mapper<LongWritable, Text, CarrierKey, Text> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if (!AirlineDataUtils.isHeader(value)) {
String[] contents = value.toString().split(",");
String carrierCode = AirlineDataUtils.getUniqueCarrier(contents);
Text code = new Text(carrierCode.toLowerCase().trim());
CarrierKey ck = new CarrierKey(CarrierKey.TYPE_DATA,code);
DelaysWritable dw = AirlineDataUtils.parseDelaysWritable(value.toString());
TextdwTxt=AirlineDataUtils.parseDelaysWritableToText(dw); context.write(ck, dwTxt);
}
}
}
Mapper的输出键类为CarrierKey类,如表6-19所示。注意他们每个是如何在构造函数中显示调用每个CarrierKey的,它们分别处理哪个数据集。还要注意,他们使用不同的构造函数。只有CarrierMasterMapper才能调用使用Carrier键描述的构造函数。为简便起见,表6-19只显示了CarrierKey类的相关部分,省略了readFields() 和 write()方法,因为他们在前面已经讨论过(www.askmac.cn)。
表6-19 CarrierKey
public class CarrierKey implements WritableComparable<CarrierKey> {
public static final IntWritable TYPE_CARRIER = new IntWritable(0);
public static final IntWritable TYPE_DATA = new IntWritable(1);
public IntWritable type = new IntWritable(3);
public Text code = new Text("");
public Text desc = new Text("");
public CarrierKey() {
}
public CarrierKey(IntWritable type, Text code,Text desc) {
this.type = type;
this.code = code;
this.desc = desc;
}
public CarrierKey(IntWritable type, Text code) {
this.type = type;
this.code = code;
}
@Override
public int hashCode() {
return (this.code.toString()+ Integer.toString(
this.type.get())).hashCode();
}
@Override
public int compareTo(CarrierKey second) {
CarrierKey first = this;
if (first.code.equals(second.code)) {
return first.type.compareTo(second.type);
} else {
return first.code.compareTo(second.code);
}
}
...
}
我们想要属于同一航空公司键码的记录(不论它们是从哪个Mapper类发送过来的)由相同的reduce调用处理。从第5章我们得知,MapReduce中默认的Partitioner是HashPartitioner,它根据CarrierKey上的hashCode()调用值进行分区。
现在来看hashCode ( )实现,它同时使用代码和类型属性来计算哈希值。因此,一个CarrierKey实例具有不同的哈希值,这取决于它来自哪个文件。因此,主记录可以到一个Reducer,而飞行详细记录可以到另一个Reducer。
这个问题很容易解决。我们可以定义一个自定义的Partitioner,只根据航空公司键码来分区(www.askmac.cn)。
自定义Partitioner: CarrierCodeBasedPartioner
表6-20 展示了一个自定义Partitioner的实现:CarrierCodeBasedPartitioner。
表6-20 CarrierCodeBasedPartitioner
public static class CarrierCodeBasedPartioner extends
Partitioner<CarrierKey, Text> {
@Override
public int getPartition(CarrierKey key, Text value,
int numPartitions) {
return Math.abs(key.code.hashCode() % numPartitions);
}
}
添加下行代码到run()方法
job.setPartitionerClass(CarrierCodeBasedPartitioner.class);
现在在该实例中记录确实都到了相同的Reducer实例,我们故意没有实现自定义键的hashCode ( )方法,只使用载体的代码部分,来说明我们为什么不能使用默认的HashPartitioner。我们不得不创建自己的自定义Partitioner。
在Reducer中实现连接
要实现连接,我们仍需要CarrierKey实例的所有值能够使相同的载体代码在同一reduce调用中处理,而不论它们来自哪个文件(CarrierKey类的类型属性)。我们也希望这些值被排序,使得与主文件相对应的值能在航班详细信息文件中的值处理前被处理。这就要求传递到reduce调用的CarrierKey实例是一个含有载体描述的实例。回想上一节中reduce调用中的键是如何成为Grouping Comparator遇到的第一个键。这将使得该描述被缓存在Iterable实例值的第一次迭代中,并在随后的迭代中,把载体描述放到表示延迟航班记录的代码行中。为了实现此功能,我们需要实现一次排序和一次分组比较。
SortingComparator类: CarrierSortComparator
表6-21展示了CarrierSortComparator,这是负责确保由CarrierMasterMapper处理的记录在排序时低于由FlightDataMapper处理的记录。前者分配的类型值为0,后者为1。定义见CarrierType列表。
表6-21 CarrierSortComparator
public class CarrierSortComparator extends WritableComparator { public CarrierSortComparator() {
super(CarrierKey.class, true);
}
}
我们没有覆盖Sorting Comparator类的compare方法; 实现自定义键是为了执行Sorting Comparator的职能。这与前面的例子不同,前面例子中实现自定义键是为了执行Grouping Comparator的职能。我们所要做的就是在构造函数中注册类。默认WritableComparator的compare实现调用自定义键的compareTo功能。
run()方法需要做如下更新:
job.setSortComparatorClass(CarrierSortComparator.class);
Grouping Comparator 类: CarrierGroupComparator
从Reducer的角度,我们希望具有相同的代码的CarrierKey实例的记录一起处理,不论他们是来自载体主文件还是航班信息文件。换句话说,我们希望这两个键的记录都由Reducer中的同一reduce调用处理。正如在Secondary Sort部分所讨论的,用GroupingComparator可实现这一目标。Sorting Comparator的实现确保了主数据记录在航班数据记录之前到达。
表6-22展示了CarrierGroupComparator。它确保具有相同载体代码的CarrierKey实例的记录在单个reduce调用中一起处理,不论他们是来自载体主文件还是航班信息文件。注意,它只通过代码属性判断CarrierKey实例中的哪些记录属于一类。
表6-22 CarrierGroupComparator
public class CarrierGroupComparator extends WritableComparator { public CarrierGroupComparator() {
super(CarrierKey.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
CarrierKey first = (CarrierKey) a;
CarrierKey second = (CarrierKey) b;
return first.code.compareTo(second.code);
}
}
run()方法需要做如下更新:
job.setGroupingComparatorClass(CarrierGroupComparator.class);
这样就完成了全部实现,最后我们来看Reducer实现。
Reducer 类: JoinReducer
表6-23展示了执行最终连接的JoinReducer类。注意,Reducer依赖于比FlightDataMapper记录先到达的CarrierMasterMapper的载体键记录。如果主数据中不包含代码,则航班详细信息记录用UNKNOWN作为载体描述(www.askmac.cn)。
表6-23 JoinReducer
public static class JoinReducer extends
Reducer<CarrierKey, Text, NullWritable, Text> {
public void reduce(CarrierKey key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
String carrierDesc = "UNKNOWN";
for (Text v : values) {
if (key.type.equals(CarrierKey.TYPE_CARRIER)) {
carrierDesc = key.desc.toString();
continue;// Coming from the Master Data Mapper
}
else{
//The sorting comparator ensures carrierDesc was already set
//by the time this section is reached.
Text out = new Text(v.toString()+","+carrierDesc); context.write(NullWritable.get(), out);
}
}
}
}
对run()方法的以下修改配置Reducer:
job.setReducerClass(JoinReducer.class);
在集群上运行MapReduce连接任务
最后,我们用Maven重建,并在Hadoop环境下执行如下任务:
hadoop jar prohadoop-0.0.1-SNAPSHOT.jar \ org.apress.prohadoop.c6.JoinMRJob \ -D mapred.reduce.tasks=12 \ /user/hdfs/sampledata \ /user/hdfs/masterdata/carriers.csv \ /user/hdfs/output/c6/mrjoin
输出目录应有12个文件:part-r-00000 到part-r-00011。代码看起来如下所示:
1,5,1988,29,32,32,19,DFW,CVG,AA,AMERICAN AIRLINES INC. 1,1,1988,18,6,6,0,SNA,SFO,AA,AMERICAN AIRLINES INC. 1,5,1988,1,3,3,-1,HRL,DFW,AA,AMERICAN AIRLINES INC.
最后两个属性为载体代码和载体描述。
以MapReduce探索Hadoop的关键特性
我们已经用MapReduce实现了连接功能,接下来探讨以下Hadoop的新特征:
- Secondary Sort 在一个reduce-side连接中发挥的作用。
- 当使用Secondary Sort时,一个自定义Partitioner 在reduce-side连接中所起的作用。
- Sorting Comparator在确保到达Reducer实例中的记录高效排序方面所起的作用。
- Grouping Comparator在确保即使键可能在物理上不同,但键的记录在同一reduce调用中根据值的逻辑分组被一起处理中发挥的作用,其中分组是用户定义的。
用这种方法,即使是两个大数据集也可以被连接。较小的数据集的记录应首先处理,并保存到本地硬盘。当迭代器最终到达较大数据集的记录时,可以用保存到磁盘的较小数据集的记录将它们连接起来。由于需要额外的磁盘I / O,这个过程会比较慢,但我们不会耗尽内存。此方法起作用,因为连接的每一端的记录都按顺序处理,且不与Reducer端上的彼此混合。Reducer确切地知道何时关闭含有较小数据集记录的文件,以及何时开始处理较大数据集的记录。
问题定义:用Map-Only任务连接
在现实中,有时主数据的量非常小。例如,假设我们想增加前述程序的输出:
- 对每一个机场,起飞地及目的地机场代码,我们想添加有关机场的详细信息。在这个例子中,我们只用增加带机场名称的记录,就可以很容易地添加更多属性。这些详细信息都来自另一个叫csv的文件。该文件中包含的属性有:
- 机场代码
- 机场名称
- 机场所在市,州及国家
- 机场方位的维度和经度坐标
- 对于载体代码,我们以载体名称补充,与上一节中讨论的过程类似。这里我们用map-only任务也这么做。这种执行连接的方法被称作map-side连接,以与上一节中的reduce-side连接方法区分开来。
这种方法的优点显而易见:我们是根据一个作业中的三个独立的键连接的。对于Reducers,这是不可能在一个任务中做到的,因为Reducer只能有一个连接键。由于其在Sort 和Shuffle阶段节省的时间,map- only任务不仅速度更快,我们还可以在一个任务中执行三个连接,通过大量的航班详细记录节省了两次传递。
以分布式缓存为基础的解决方案
这是MapReduce程序提供的一种缓存应用程序所需文件(文本、档案)的能力。应用程序可用下列方法指定文件:
- 使用GenericOptions解析器和实现Tool接口的任务,可在命令行上用–files <comma separated URI’s>参数指定。这些文件可位于本地文件系统,HDFS中,甚至可通过HTTP URL访问。在URI前面供给的方案用于确定如何获取文件。如果没有提供方案,则文件被假定为本地。可以使用的另一参数是–archives <comma separated URI’s>。档案如ZIP文件,TAR文件,以及JAR文件,可通过这种方式传递。-files和-archives之间的区别在于,在后一种情况下,文件在容器运行Mapper 或 Reducer任务的节点上未存档。
- 另外,任务可通过addCacheFile(…) 或job. addCacheArchive(…)调用指定文件(www.askmac.cn)。
为确保性能,文件在任务一开始曾被复制到运行MapReduce任务的节点上。每次一开始,setup() method检索缓存文件。用DistributedCache表示map-side连接的类是org.apress.prohadoop.c6.MapSideJoinMRJob。
run( )方法
表6-24 展示了MapSideJoinMRJob的run()方法。
public int run(String[] allArgs) throws Exception {
Job job = Job.getInstance(getConf());
job.setJarByClass(MapSideJoinMRJob.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(MapSideJoinMapper.class);
String[] args = new GenericOptionsParser(getConf(), allArgs).getRemainingArgs();
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.addCacheFile((new File(args[2])).toURI());
job.addCacheFile((new File(args[3])).toURI());
job.waitForCompletion(true);
return 0;
}
提供DistributedCache功能的行前面被突出强调。我们用这一方式传递airlines.csv和 carriers.csv文件。传递到该程序的输入参数如下:
- <input path of the file in hdfs>
- <output path in hdfs>
- <local path for airports.csv>
- <local path for carriers.csv>
接下里,我们研究Mapper类。
MapSideJoinMapper类
Mapper类如表6-25所示。该类的关键部件如下所示:
- 私有变量airports 和carriers用于缓存与机场和载体相关的主数据。查找键为机场代码和载体代码。
- setup()方法调用getCacheFiles()方法为缓存文件获取URIs。等该方法被调用时,本地节点上的缓存文件通过一个符号连接早已是可用的。
- readAirports 和readCarriers方法负责填充缓存变量。
- 接下来每次飞行记录都在map方法的一个独立调用中处理。缓存变量airports 和 carriers是可用的,用来获取每个机场代码和载体代码的详细信息。
- 重写的parseDelaysWritableToText用于增强先前创建的DelaysWritable实例。返回的Text实例用始发地和目的地机场描述,以及载体描述的名称增强延迟行。
表6-25 MapSideJoinMapper.run() Implementation
public static class MapSideJoinMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
//Cache variables for airports and carrier master
private Map<String, String[]> airports = new HashMap<String, String[]>();
private Map<String, String[]> carriers = new HashMap<String, String[]>();
private void readAirports(URI uri) throws Exception {
//Read airports.csv
List<String> lines = FileUtils.readLines(new File(uri));
//populate the airports atttibute. Key is the airport code
...
}
private void readCarriers(URI uri) throws Exception {
//Read carriers.csv
List<String> lines = FileUtils.readLines(new File(uri));
//populate the carriers atttibute. Key is the carrier code
...
}
public void setup(Context context) {
try {
URI[] uris = context.getCacheFiles();
for (URI uri : uris) {
if (uri.toString().endsWith("airports.csv")) {
this.readAirports(uri);
}
if (uri.toString().endsWith("carriers.csv")) {
this.readCarriers(uri);
}
}
} catch (Exception ex) {
//IOExceptions while reading master files throw new RuntimeException(ex);
}
}
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if (!AirlineDataUtils.isHeader(value)) {
DelaysWritable dw = AirlineDataUtils.parseDelaysWritable(value.toString());
String orginAirportCd = dw.originAirportCode.toString();
String destAirportCd = dw.destAirportCode.toString();
String carrierCd = dw.carrierCode.toString();
String[] originAirport = this.airports.get(orginAirportCd);
String[] destAirport = this.airports.get(destAirportCd);
String[] carrier = this.carriers.get(carrierCd);
String originAirportDesc = "";
if (originAirport != null)
originAirportDesc = originAirport[1].replaceAll(",", "");
String destAirportDesc = "";
if (destAirport != null)
destAirportDesc = destAirport[1].replaceAll(",", "");
String carrierDesc = "";
if (carrier != null)
carrierDesc = carrier[1].replaceAll(",", "");
Text outLine = AirlineDataUtils.parseDelaysWritableToText(dw,originAirportDesc, originAirportDesc, destAirportDesc, carrierDesc);
context.write(NullWritable.get(), outLine);
}
}
}
在集群上运行Map-Only连接任务
我们用Maven重建,并在Hadoop环境下执行如下任务:
hadoop jar prohadoop-0.0.1-SNAPSHOT.jar \ org.apress.prohadoop.c6.MapSideJoinMRJob \ /user/hdfs/sampledata \ /user/hdfs/output/c6/mapsidejoin \ /user/local/input/master/airports.csv \ /user/local/input/master/carriers.csv
输出目录中应有几个名称看起来像part-m-nnnnn的文件,n是一个0到9之间的数字。样本输出记录看起来如以下所示(代码是粗体以提高可读性)。第一代码是始发地机场代码,第二个是目的地机场代码,最后一个是载体代码。每个代码后跟一个该代码的描述属性。
- 注意 MapSideJoinMrJob在Hadoop 2的某些版本中可能无法如预期的那样正常工作。job.getCacheFiles( )方法可能无法正常地从本地文件系统中返回URI实例。这一故障以及修复方法在以下JIra ticket中有介绍: https://issues.apache.org/jira/browse/MAPREDUCE-5385。如果你正使用的Hadoop版本不具备上述JIRA单中描述的补丁,可使用从本书源代码MapSideJoinMrJob2或MapSideJoinMrJob3类中所采用的方法。如果你使用这些类,从客户的角度来看,唯一的不同是,主数据文件路径是hdFS路径:/user/hdfs/masterdata/airports.csv和/user/hdfs/masterdata/carriers.csv。MapSideJoinMrJob2使用已被废弃的函数调用job.getlocalCacheFiles()。该调用从Mapper执行任务节点上的本地文件系统返回路径。该框架在任务启动前,将这些文件复制到Mapper任务节点的本地文件系统上。MapSideJoinMrJob2类在伪分布式或完全分布式集群中将工作。但与MapSideJoinMrJob不同的是,它可能无法在本地开发环境中工作。另外,使用MapSideJoinMrJob3类。该类除了两个关键差异外,其它与MapSideJoinMrJob类完全相同。类似于MapSideJoinMrJob2类,主数据文件路径是hdFS路径,且job.getCacheFiles()假定返回的urI实例表示与客户传递相同的hdFS路径。相反,MapSideJoinMrJob假定由job.getCacheFiles( )返回的url实例,映射到其本地文件系统中(上面链接中描述的JIra fix)的文件。这就是为什么在MapSideJoinMrJob和MapSideJoinMrJob3类中使用的方法不兼容的原因。MapSideJoinMrJob3的MapSideJoinMapper内部类提供了一种方法readlinesFromJobFS以读取由job.getCacheFiles()方法返回的URI实例。总的来说,需要注意两个关键元素——从客户角度,主数据文件的文件系统(本地或hdFS),以及job.getCacheFiles()返回的urI的文件系统(本地或hdFS)。基于所述的hadoop文档,后者有可能是本地的。如果他们不是本地的,在MapSideJoinMrJob类中描述的方法就行不通。如果你想使用客户端本地文件系统的缓存文件,可使用MapSideJoinMrJob2类中描述的方法。如果你不愿意使用被弃用的方法(job.getlocalCacheFiles()方法就是被弃用的任务类),请使用MapSideJoinMrJob3类中描述的方法。
以Map-Only连接探索重述Hadoop的关键特性
我们已经用分布式缓存实现了连接功能,接着探讨以下Hadoop的新特征:
- 使用命令行参数以编程方式将文件和档案传递到一个任务的方法
- 如何利用DistributedCache在单一map()调用的多个变量上执行Map-Only连接。
尽管本节可能给人的印象是该方法只有当分布文件的数目小时才适合,但并非总是如此(例如,对于由连接标准排序的一个大的主数据文件)。假设我们接收一个同样由连接标准排序的大数据文件。并且假设主文件中的记录是由连接标准排序的。进一步假设主数据文件存储在HDFS中。然后在处理来自数据文件的行之前,我们在Mapper中 缓存主数据文件的前几行。当记录进入map方法时,通过在缓存主记录上执行查找,在Mapper中持续执行连接。随着我们继续处理数据文件,在某一点上我们很快会遇到一个在缓存主记录中不存在的连接标准的值。从这一点开始,我们开始读主数据,直到我们在主数据文件中遇到连接标准值等于Mapper正处理的当前数据记录的值,或到达主数据文件的末尾。由于两个数据集都是由连接标准排序,到达主数据文件的末尾意味着:即使有数据记录要处理,也没有更多可行的连接了(内部的)。根据正在执行的连接类型(内部或外部),可适当地处理剩余的数据记录。这种技术,被称为Merge Join,广泛用于多种Hadoop库,如Hive 和 Pig(www.askmac.cn)。
在单个MR任务上写入多个输出文件
到现在为止,我们讨论了只生成单组输出的任务。如果文件是由Map-only任务生成,输出文件的名称采用part-m- nnnnn格式,如果文件是由Reducer任务生成,则采用part-r-nnnnn。本节将探讨生成多组文件的任务。
我们先来定义问题。假设我们想要得到飞行记录的延迟信息,但我们希望根据以下四个标准生成四个单独的输出文件:
- 到达和起飞都准时的航班
- 到达延迟、起飞准时的航班
- 到达准时、起飞延迟的航班
- 到达和起飞都延迟的航班
我们将编写一个Map-only任务实现这些目标。我们也抑制part-m-nnnnn文件,因为不想有任何输出到那些文件。该程序的源代码在org.apress.prohadoop. c6.MultiOutputMRJob中可获取。
我们需要添加到run() 方法以支持前面所提功能的代码行如下所示:
job.setOutputFormatClass(NullOutputFormat.class); MultipleOutputs.addNamedOutput(job,"OnTimeDepOnTimeArr",TextOutputFormat.class, NullWritable.class, Text.class); MultipleOutputs.addNamedOutput(job, "DelayedDepOnTimeArr",TextOutputFormat.class, NullWritable.class, Text.class); MultipleOutputs.addNamedOutput(job, "OnTimeDepDelayedArr",TextOutputFormat.class, NullWritable.class, Text.class); MultipleOutputs.addNamedOutput(job, "DelayedDepDelayedArr",TextOutputFormat.class, NullWritable.class, Text.class);
第一行确保了不会有part-m-nnnnn文件。当你不希望任务通过context.write调用产生任何输出时,用NullOutputFormat。然而,这并不限制通过调用write方法在MultipleOutputs实例上创建输出的能力。当你想用MultipleOutputs类生成多个输出时通常会用到它。接下来四行是配置多个输出。第一个参数是Job实例;第二个参数表示指定输出的文件名前缀。接下来的三个参数定义了用于指定输出的OutputFormat以及输出键和值类型。除了TextOutputFormat,至今我们还没探索出其他格式。第7章我们讨论输出格式,如SequenceFileOutputFormat时,该功能的值将变得明显。
如果输出文件被写入Mapper,则文件命名惯例为<name>-m-nnnnn,若被写入Reducer,则命名惯例为<name>- r-nnnnn。表6-26展示了MultiOutputMapper。配置在run()方法中的MultipleOutputs实例,被初始化为Mapper setup()方法中的实例变量。
以下map方法实现展示了多个指定输出是如何被写入的。注意,相同名称用于恢复流的句柄,配置run()方法中的指定输出。
表6-26 MultiOutputMapper
public static class MultiOutputMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
private MultipleOutputs mos;
@Override
public void setup(Context context){
this.mos = new MultipleOutputs(context);
}
public void map(LongWritable key, Text line, Context context)
throws IOException, InterruptedException {
if(!AirlineDataUtils.isHeader(line)){
DelaysWritable dw = AirlineDataUtils.parseDelaysWritable(line.toString());
int arrivalDelay = dw.arrDelay.get();
int departureDelay = dw.depDelay.get();
Text value = AirlineDataUtils.parseDelaysWritableToText(dw);
if(arrivalDelay<=0 && departureDelay<=0){
this.mos.write("OnTimeDepOnTimeArr",NullWritable.get(), value);
}
if(arrivalDelay<=0 && departureDelay>0){
this.mos.write("DelayedDepOnTimeArr",NullWritable.get(), value);
}
if(arrivalDelay>0 && departureDelay<=0){
this.mos.write("OnTimeDepDelayedArr",NullWritable.get(), value);
}
if(arrivalDelay>0 && departureDelay>0){
this.mos.write("DelayedDepDelayedArr",NullWritable.get(), value);
}
}
}
}
用Counters收集数据
Counters是通过它可收集一个任务的各种数据的机制。MapReduce任务输出展示了由MapReduce操控的给各种counters。该类counters包括以下:
- Map 输入记录
- Map输出记录
- Reduce输出记录
- Map任务启动
- Map任务失败
- Reduce任务启动
- Reduce任务失败
在作业上有很多的counters被MapReduce框架用来收集统计数据。
你也可以创建自定义counters来收集特定应用的统计数据。创建特定应用counters有两种方式:
- 定义一个 Java 枚举,它代表一组counters。组的名称是枚举类型的完全限定名称。
- 通过动态地提供counter组名称以及counter名称来创建动态counter。
Counters是全局的,可以从Mappers 和Reducers中递增(或递减,当我们传递一个负增量值时)。Counters的管理属于主应用程序级别。counter每个增量的信息通过运行Mapper和Reducer任务的容器和主应用程序之间的心跳消息传递给主应用程序(www.askmac.cn)。
我们来扩展在最后一节开发的MultipleOutputs程序以收集以下统计数据:
- OnTimeStatistics: 基于Enum的统计数据。该组的名称为枚举定义的完全限定路径:apress.prohadoop.c6.MultiOutputMRJob$MultiOutputMapper$On TimeStatistics
- DepOnTimeArrOnTime
- DepOnTimeArrDelayed
- DepDelayedArrOnTime
- DepDelayedArrDelayed
- DELAY_BY_PERIOD: 每个月或一周的每一天都动态生成。有助于确定给定月份或给定某天所发生的延迟次数。
- MONTH_{MONTH_ID}
- DAY_OF_WEEK_{DAY_OF_WEEK_ID}
表6-27展示了修改Mapper类。
表6-27带Counters的MultiOutputMapper
public static class MultiOutputMapper
extends Mapper<LongWritable, Text, NullWritable, Text> {
enum OnTimeStatistics{
DepOnTimeArrOnTime, DepOnTimeArrDelayed, DepDelayedArrOnTime, DepDelayedArrDelayed
}
private MultipleOutputs mos;
@Override
public void setup(Context context){
this.mos = new MultipleOutputs(context);
}
public void map(LongWritable key, Text line, Context context)
throws IOException, InterruptedException {
if(!AirlineDataUtils.isHeader(line)){
DelaysWritable dw = AirlineDataUtils.parseDelaysWritable(line.toString());
int arrivalDelay = dw.arrDelay.get();
int departureDelay = dw.depDelay.get();
Text value = AirlineDataUtils.parseDelaysWritableToText(dw);
if(arrivalDelay<=0 && departureDelay<=0){
this.mos.write("OnTimeDepOnTimeArr",NullWritable.get(), value);
context.getCounter(OnTimeStatistics.DepOnTimeArrOnTime).increment(1);
}
if(arrivalDelay<=0 && departureDelay>0){
this.mos.write("DelayedDepOnTimeArr",NullWritable.get(), value);
context.getCounter(OnTimeStatistics.DepDelayedArrOnTime).increment(1);
}
if(arrivalDelay>0 && departureDelay<=0){
this.mos.write("OnTimeDepDelayedArr",NullWritable.get(), value);
context.getCounter(OnTimeStatistics.DepOnTimeArrDelayed).increment(1);
}
if(arrivalDelay>0 && departureDelay>0){
this.mos.write("DelayedDepDelayedArr",NullWritable.get(), value);
context.getCounter(OnTimeStatistics.DepDelayedArrDelayed).increment(1);
}
if(arrivalDelay>0 || departureDelay>0)
context.getCounter("DELAY_FOR_PERIOD","MONTH_"+Integer.toString(dw.month.get())).increment(1);
context.getCounter("DELAY_FOR_PERIOD","DAY_OF_WEEK_"+Integer.toString(dw.month.get())).increment(1)
}
}
}
}
counters可在任务完成后,通过run()方法访问。可通过run()方法中的以下代码行实现:
this.printCounterGroup(job,"DELAY_FOR_PERIOD"); this.printCounterGroup(job,"org.apress.prohadoop.c6.MultiOutputMRJob$MultiOutputMapper$OnTime Statistics");
注意由enum表示的counter长组名。表6-28展示了printCounterGroup方法的实现。我们用Job实例检索counters组,然后获取该组的iterator,进行迭代以访问那个组中的各个counter。
表6-28 printCounterGroup
private void printCounterGroup(Job job,String groupName)
throws IOException{ CounterGroup cntrGrp = job.getCounters().getGroup(groupName);
Iterator<Counter> cntIter = cntrGrp.iterator();
System.out.println("\nGroup Name = " + groupName);
while(cntIter.hasNext()){
Counter cnt = cntIter.next();
System.out.println(cnt.getName() + "=" + cnt.getValue());
}
}
在我的开发环境中运行printCounterGroup方法调用获取抽样数据,打印以下输出到控制台(www.askmac.cn):
Group Name = DELAY_FOR_PERIOD DAY_OF_WEEK_1=25 DAY_OF_WEEK_12=21 MONTH_1=25 MONTH_12=21 Group Name = org.apress.prohadoop.c6.MultiOutputMRJob$MultiOutputMapper$OnTimeStatistics DepDelayedArrDelayed=27 DepDelayedArrOnTime=2 DepOnTimeArrDelayed=17 DepOnTimeArrOnTime=10
Summary 小结
最后两章涵盖了许多内容。你已经学会了如何使用MapReduce模仿几乎每一个重要的SQL方法。本章探讨了使用各种方法对多个数据集进行排序和连接。在这个过程中,你学习了如何创建MapReduce框架的自定义I / O类,以及如何控制Reducers中接收和分组的键的顺序。我们讨论了诸如Secondary Sort和分布式缓存等复杂的技术。你还学会了如何处理多个输入文件夹,并写入到多个输出文件中。最后,你学会了如何在作业中收集统计数据。
下一章会更详细地讨论MapReduce框架,尤其是它内部的工作原理。要成为一个强大的Hadoop开发人员,对这一点的认识很有必要。

Comment