
随着DigitalOcean上专用网络来临,我想用一个基于droplet的集群取代我的本地物理Cloudera Hadoop集群。其中关于使用DigitalOcean droplet最好的就是,你可以快照任何图像和破坏VM,当他们不在使用和你无需他们。不好的方面是,专用网络上DigitalOcean droplet实施并不能保证任何安全,只要其他主机在同一专用网络上,你应该在使用专用网络时考虑到这一点;因频宽是自由的,它不是真正的私有。
这里我们概述了4主机群集耗资0.15美元 /小时(1X0.06美元+ 3X0.03美元/小时),使之成为一个连接率很高的平台。
如果你不熟悉DigitalOcean – 它们提供了非常简单,便宜的虚拟服务器(droplets在DigitalOcean说法)。
我将使用Cloudera Manager自动化安装程序指南,我发现这是管理群集一个很好的工具。
Happy Path适当路径
这个帖子不包括Happy Path – 还有,我已经在这里记录了一些陷阱,还有一些错误(对于那些遇到同样的问题的人)。我很快就会写一个Happy Path的帖子(我在这个帖子做了笔记),但这个指南将会帮助你理解,如果你通过它仔细阅读。下面是几个陷阱要记住。最重要的是这个位置提供的是一个指示,你可以在DigitalOcean droplets上做到!
所有节点都必须用相同的密码使用root(或使用相同的密码和无密码sudo功能的超级用户)。每个节点必须有一个有给所有hosts的私有IP的主机名的映射的host文件(修改/ etc / hosts文件)。当你的网络交互运行起来,会有一个搜索屏幕,您需要输入的所有节点(包括1,你登陆上的,Cloudera Manager安装好的)。
当我终于得到了集群来适当安装,我已经把Cloudera的管理服务器提高到4GB的服务器,基于一个不完全失败的安装中RAM的使用量。
因为在这种情况下缺乏安全,当Web界面的Cloudera管理器中出现,我做的第一件事是改变管理员密码,注销并重启并重新安装 。
这对使用主机名方案来反映了你试图完成什么有帮助。
Cloudera Manager的要求是2GB内存能满足涉及少于100台主机非Oracle部署的要求,我要创造一个更小的VS知道我可以重新设置droplet在fly的大小。我最终使用4GB存储管理服务器,我成功地建立一个集群,在其他主机创建为2GB 。
点击“创建”按钮。
主机名 hadoop1.nerdnuts.com
选择尺寸 4GB(早期试图512MB和2GB,不能确定这是一个问题)
选择地区 纽约2(这是唯一支持专用网络的地区,在这篇文章的时候)
选择图片 CentOS 6.4 x64
设置 选择“Enable Virtio”和“Private Networking”
点击“Create Droplet”按钮。
马上,你将从Digital Ocean Support收到一封电子邮件,同你的新的Droplet IP和凭据。
我做的在新的droplet做的第一件事是改变root密码:
root@hadoop1:~# passwd
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
root@hadoop1:~#
我相信,对于Cloudera的自动安装程序,在所有的节点使用相同的root口令更简单。
安装Cloudera Manager和CDH
按照说明安装路径A – 由Cloudera的经理自动安装完成这一部分 – 这个过程是非常简单的,通过所有的文档整理比做安装更加困难。
下载Cloudera的管理安装程序(Cloudera的经理-installer.bin)文件上传到您所安装的主机。
[root@hadoop1 ~]# chmod u+x cloudera-manager-installer.bin
[root@hadoop1 ~]# sudo ./cloudera-manager-installer.bin
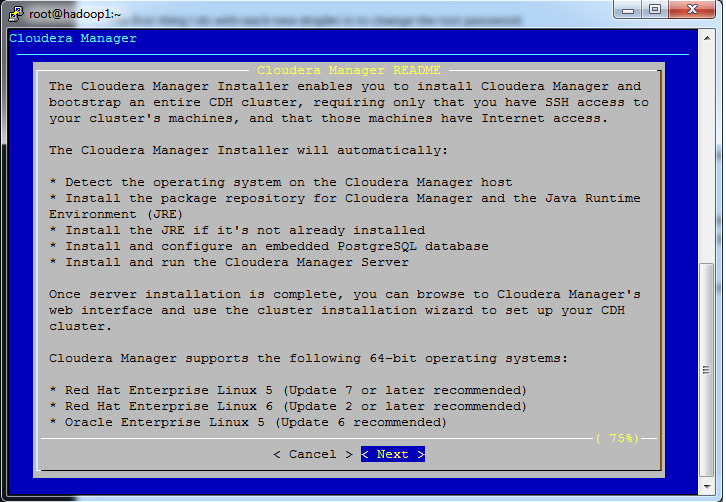
一路next+accept license

访问:http://haodoop1.nerdnuts.com:7180

/etc/hosts
在/etc/hosts文件中加入所有节点的合适hostname和IP ,例如:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.128.6.202 hadoop1.nerdnuts.com hadoop1 10.128.6.236 hadoop2.nerdnuts.com hadoop2 10.128.6.246 hadoop3.nerdnuts.com hadoop3 10.128.6.247 hadoop4.nerdnuts.com hadoop4
为CDH 安装指定节点
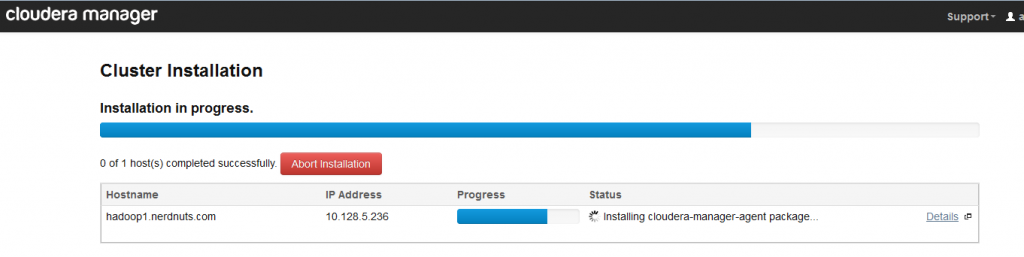
此时配置cloudera installation 需要增加一些节点到集群中,在下面的界面中输入集群中的所有节点,包括目前运行此GUI的节点。 当我配置了3个节点后收到了3个节点的报错,原因就是在/etc/hosts中缺少对应的记录:

详细的报错信息如下:
/tmp/scm_prepare_node.G4WA613r using SSH_CLIENT to get the SCM hostname: 10.128.6.236 43470 22 opening logging file descriptor Starting installation script... Acquiring installation lock... BEGIN flock 4 END (0) Detecting root privileges... effective UID is 0 Detecting distribution... BEGIN grep Tikanga /etc/redhat-release . . . >>agent.py: error: argument --hostname is required >>[15/Sep/2013 06:24:47 +0000] 1928 Dummy-1 agent INFO Stopping agent... >>/usr/lib64/cmf/agent/src/cmf/parcel.py:15: DeprecationWarning: the sets module is deprecated >> from sets import Set >>/usr/lib64/cmf/agent/src/cmf/agent.py:31: DeprecationWarning: the sha module is deprecated; use the hashlib module instead >> import sha >>[15/Sep/2013 06:24:47 +0000] 1928 MainThread agent INFO SCM Agent Version: 4.7.1 >>[15/Sep/2013 06:24:47 +0000] 1928 MainThread agent ERROR Could not determine hostname or ip address; proceeding. >>Traceback (most recent call last): >> File "/usr/lib64/cmf/agent/src/cmf/agent.py", line 1600, in parse_arguments >> ip_address = socket.gethostbyname(fqdn) >>gaierror: [Errno -2] Name or service not known >>usage: agent.py [-h] [--agent_dir AGENT_DIR] >> [--agent_httpd_port AGENT_HTTPD_PORT] --package_dir >> PACKAGE_DIR [--parcel_dir PARCEL_DIR] >> [--supervisord_path SUPERVISORD_PATH] >> [--supervisord_httpd_port SUPERVISORD_HTTPD_PORT] >> [--standalone STANDALONE] [--master MASTER] >> [--environment ENVIRONMENT] [--host_id HOST_ID] >> [--disable_supervisord_events] --hostname HOSTNAME >> --ip_address IP_ADDRESS [--use_tls] >> [--client_key_file CLIENT_KEY_FILE] >> [--client_cert_file CLIENT_CERT_FILE] >> [--verify_cert_file VERIFY_CERT_FILE] >> [--client_keypw_file CLIENT_KEYPW_FILE] [--logfile LOGFILE] >> [--logdir LOGDIR] [--optional_token] [--clear_agent_dir] >>agent.py: error: argument --hostname is required >>[15/Sep/2013 06:24:47 +0000] 1928 Dummy-1 agent INFO Stopping agent... END (0) BEGIN tail -n 50 /var/log/cloudera-scm-agent//cloudera-scm-agent.log | sed 's/^/>>/' tail: tail: cannot open `/var/log/cloudera-scm-agent//cloudera-scm-agent.log' for reading: No such file or directory cannot open `/var/log/cloudera-scm-agent//cloudera-scm-agent.log' for reading: No such file or directory END (0) end of agent logs. scm agent could not be started, giving up waiting for rollback request
注意上面的这个hosts中的记录要在所有节点上都有,不仅仅是你运行cloudera installer的这个节点。
之后点击 “Retry Failed Hosts”, 成功安装后的界面如下:

点击下一步安装包
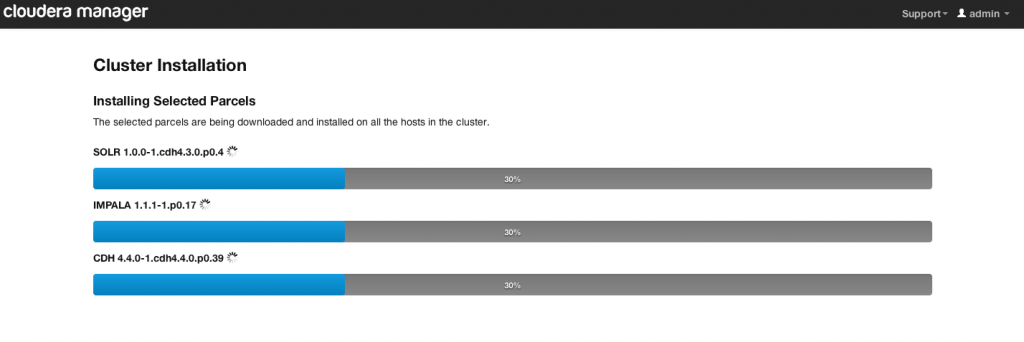
成功安装后点击continue
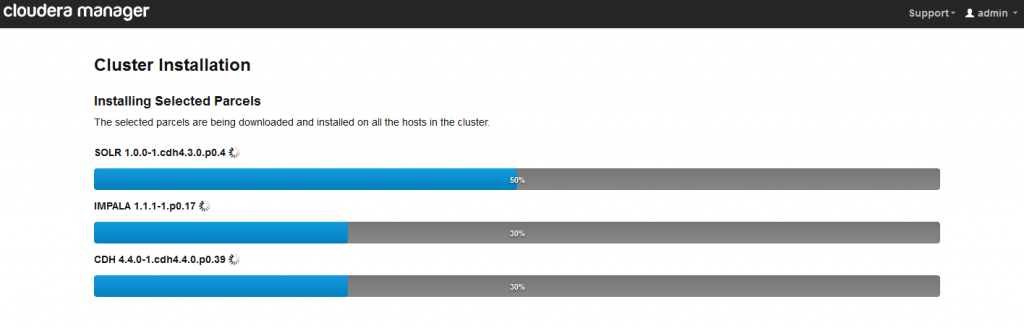
点击 continue ,选择你需要安装CDH 4的节点, 我选择了“Core Hadoop“并点击continue:
“Database Setup” > “Use Embedded Database” > “Test Connection” >
I get the feeling that I have fubared the happy path to installation. Let’s see… there isn’t a way to insert connection data for the imbedded database… I’ve seen this work without setting up my own mysql or postgres install… I think I’ll start over and see if I can get on the happy path. This time around I will add all 4 hosts to the search initially and hopefully that will evade the issues I’ve had so far.
2nd Time I’ve completely restarted by destroying all the VM’s.
Reboot.
Destroy all droplets.
Change passwords. I like to log into one box “passwd” then ssh into the next box, then as I’m exiting boxes I can add the hosts entry[ies].
Create host entries.
[root@hadoop1 ~]# vi /etc/hosts
And add all of your node host names and [private] IP’s to each node (this must be done on all of your nodes!):
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.128.6.202 hadoop1.nerdnuts.com 10.128.6.236 hadoop2.nerdnuts.com 10.128.6.246 hadoop3.nerdnuts.com 10.128.6.247 hadoop4.nerdnuts.com
Upload bin to 1, change permissions, execute…
Go through a few simple GUI screens.
http://162.243.8.116:7180
(admin/admin)
Search for all the hosts (all 4 private ip’s), it finds them.
Now installing on all hosts (not just the additional nodes).
Installation completed successfully.
“Continue”
Installing Selected Parcels
I’ve stalled here before… Completed! <Continue>
Inspect hosts for correctness
Much better results! No warnings, lots of green! <Continue>
Choose the CDH4 services that you want to install on your cluster.
Core Hadoop <Continue>
Database Setup
Use Embedded Database <Test Connection>
Successful! <Continue>
Review configuration changes
<Continue>
Starting your cluster services.
This takes a while, but has an indicator of the service(s) it’s working on.
It’s been stalled at “Creating Oozie database” for quite some time (11 of 17 services).
It’s never completed…. it ran for 8 hours, Oozie is still hanging and the Cloudera Manager is no longer responsive. Re-running the bin installer gives me a message that Cloudera Manager is already installed, rung /usr/share/cmf/uninstall-cloudera-manager.sh to uninstall.I’m unable to hit the management web interface (http://162.243.8.116:7180) so I check the status of the the Cloudera Management service:
[root@hadoop1 ~]# service cloudera-scm-server status
cloudera-scm-server dead but pid file exists
[root@hadoop1 ~]# service cloudera-scm-server stop
Stopping cloudera-scm-server: [FAILED]
[root@hadoop1 ~]# service cloudera-scm-server start
Starting cloudera-scm-server: [ OK ]
[root@hadoop1 ~]#
Now the admin interface is coming up:
http://162.243.8.116:7180
Right on the home page is a error stating “Unable to issue query: the Host Monitor is not running”, without this I’m not seeing hardware monitoring details for each node. It looks like the cluster may be up and running otherwise. Lets test out the functionality in a simple way (Word Count Tutorial).
I’m unable to even create directories on the filesystem:
[hdfs@hadoop1 wordcount]$ hadoop fs -mkdir /user/cloudera /user/cloudera/wordcount /user/cloudera/wordcount/input mkdir: `/user/cloudera': Input/output error mkdir: `/user/cloudera/wordcount': Input/output error mkdir: `/user/cloudera/wordcount/input': Input/output error [hdfs@hadoop1 wordcount]$
Is it time for a 3rd complete restart? I haven’t been able to definitively identify a single issue that I would do differently on the next try, even after combing through all the log files that I can locate on the primary server.
The only things that come to mind are:
- The version of CentOS – maybe there is something going awry in the virtualization of 6.4, it’s fairly new and I’ve already had other issues in the past few weeks.
- Perhaps the multi-homed network adapters are causing an issue – I could try VM’s without private networking to test this.
Resources
Before destroying the cluster I took a look at the resources being used by each host. It appears that I could get away with using 1GB host nodes for everything except the management node. Next time through I will be upping the size of the first (management) node to ensure that it has the resources required to function properly.

3rd Time I’ve completely restarted by destroying all the VM’s.
Based on the snapshot of the resources above, I’ve decided to create a 4GB VM for the hadoop1 and create 2GB VS’s for hadoop2-4. The smallest server I’ve ever seen the Cloudera Manager running on was in the range of 3GB in a 4 host cluster.
The other change for this round of install is that I’m adding the short name to the hosts file:
10.128.6.246 hadoop1.nerdnuts.com hadoop1 10.128.6.247 hadoop2.nerdnuts.com hadoop2 10.128.6.236 hadoop3.nerdnuts.com hadoop3 10.128.6.202 hadoop4.nerdnuts.com hadoop4
I also changed the password within the web interface for the Cloudera Management interface as soon as I have access to it.
So after several tries I now get the following message:

Comment