
Exadata数据库一体机软硬结合了ORACLE公司技术的精华,定期的健康检查也马虎不得。
Exadata的健康检查主要基于Oracle Support标准化工具Exachk,关于Exachk的详细介绍可以参考:
介绍 Exachk 的概览和最佳实践;定期使用 Exachk 收集 Exadata 机器的系统信息, 并结合 Oracle 最佳实践与客户当前的环境配置给出建议值, 可及时发现潜在问题, 消除隐患, 保障 Exadata 系统的稳定运行。
注册: https://oracleaw.webex.com/oracleaw/onstage/g.php?d=592264766&t=a
这里我们只给出Exachk的具体使用步骤:
$./exachk
CRS stack is running and CRS_HOME is not set. Do you want to set CRS_HOME to /u01/app/11.2.0.3/grid?[y/n][y]y
Checking ssh user equivalency settings on all nodes in cluster
./exachk: line 8674: [: 5120: unary operator expected
Space available on ware at /tmp is KB and required space is 5120 KB
Please make at least 10MB space available at above location and retry to continue.[y/n][y]?
需要设置RAT_CLUSTERNODES 指定检查的节点名
su - oracle
$export RAT_CLUSTERNODES="dm01db01-priv dm01db02-priv"
export RAT_DBNAMES="orcl,dbm"
$ ./exachk
[oracle@192 tmp]$ ./exachk
CRS stack is running and CRS_HOME is not set. Do you want to set CRS_HOME to /u01/app/11.2.0.3/grid?[y/n][y]y
Checking ssh user equivalency settings on all nodes in cluster
Node dm01db01-priv is configured for ssh user equivalency for oracle user
Node dm01db02-priv is configured for ssh user equivalency for oracle user
Searching out ORACLE_HOME for selected databases.
. . . .
Checking Status of Oracle Software Stack - Clusterware, ASM, RDBMS
. . . . . . . . . . . . . . . . . . . /u01/app/11.2.0.3/grid/bin/cemutlo.bin: Failed to initialize communication with CSS daemon, error code 3
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
-------------------------------------------------------------------------------------------------------
Oracle Stack Status
-------------------------------------------------------------------------------------------------------
Host Name CRS Installed ASM HOME RDBMS Installed CRS UP ASM UP RDBMS UP DB Instance Name
-------------------------------------------------------------------------------------------------------
192 Yes Yes Yes Yes No Yes
dm01db01-priv Yes Yes Yes Yes No Yes
dm01db02-priv Yes Yes Yes Yes No Yes
-------------------------------------------------------------------------------------------------------
root user equivalence is not setup between 192 and STORAGE SERVER dm01cel01.
1. Enter 1 if you will enter root password for each STORAGE SERVER when prompted.
2. Enter 2 to exit and configure root user equivalence manually and re-run exachk.
3. Enter 3 to skip checking best practices on STORAGE SERVER.
Please indicate your selection from one of the above options[1-3][1]:- 1
Is root password same on all STORAGE SERVER?[y/n][y]y
Enter root password for STORAGE SERVER :-
97 of the included audit checks require root privileged data collection on DATABASE SERVER. If sudo is not configured or the root password is not available, audit checks which require root privileged data collection can be skipped.
1. Enter 1 if you will enter root password for each on DATABASE SERVER host when prompted
2. Enter 2 if you have sudo configured for oracle user to execute root_exachk.sh script on DATABASE SERVER
3. Enter 3 to skip the root privileged collections on DATABASE SERVER
4. Enter 4 to exit and work with the SA to configure sudo on DATABASE SERVER or to arrange for root access and run the tool later.
Please indicate your selection from one of the above options[1-4][1]:- 1
Is root password same on all compute nodes?[y/n][y]y
Enter root password on DATABASE SERVER:-
9 of the included audit checks require nm2user privileged data collection on INFINIBAND SWITCH .
1. Enter 1 if you will enter nm2user password for each INFINIBAND SWITCH when prompted
2. Enter 2 to exit and to arrange for nm2user access and run the exachk later.
3. Enter 3 to skip checking best practices on INFINIBAND SWITCH
Please indicate your selection from one of the above options[1-3][1]:- 3
*** Checking Best Practice Recommendations (PASS/WARNING/FAIL) ***
Log file for collections and audit checks are at
/tmp/exachk_040613_105703/exachk.log
Starting to run exachk in background on dm01db01-priv
Starting to run exachk in background on dm01db02-priv
=============================================================
Node name - 192
=============================================================
Collecting - Compute node PCI bus slot speed for infiniband HCAs
Collecting - Kernel parameters
Collecting - Maximum number of semaphore sets on system
Collecting - Maximum number of semaphores on system
Collecting - Maximum number of semaphores per semaphore set
Collecting - Patches for Grid Infrastructure
Collecting - Patches for RDBMS Home
Collecting - RDBMS patch inventory
Collecting - number of semaphore operations per semop system call
Preparing to run root privileged commands on DATABASE SERVER 192.
Starting to run root privileged commands in background on STORAGE SERVER dm01cel01
root@192.168.64.131's password:
Starting to run root privileged commands in background on STORAGE SERVER dm01cel02
root@192.168.64.132's password:
Starting to run root privileged commands in background on STORAGE SERVER dm01cel03
root@192.168.64.133's password:
Collecting - Ambient Temperature on storage server
Collecting - Exadata Critical Issue EX10
Collecting - Exadata Critical Issue EX11
Collecting - Exadata software version on storage server
Collecting - Exadata software version on storage servers
Collecting - Exadata storage server system model number
Collecting - RAID controller version on storage servers
Collecting - Verify Disk Cache Policy on storage servers
Collecting - Verify Electronic Storage Module (ESM) Lifetime is within Specification
Collecting - Verify Hardware and Firmware on Database and Storage Servers (CheckHWnFWProfile) [Storage Server]
Collecting - Verify Master (Rack) Serial Number is Set [Storage Server]
Collecting - Verify PCI bridge is configured for generation II on storage servers
Collecting - Verify RAID Controller Battery Condition [Storage Server]
Collecting - Verify RAID Controller Battery Temperature [Storage Server]
Collecting - Verify There Are No Storage Server Memory (ECC) Errors
Collecting - Verify service exachkcfg autostart status on storage server
Collecting - Verify storage server disk controllers use writeback cache
Collecting - verify asr exadata configuration check via ASREXACHECK on storage servers
Collecting - Configure Storage Server alerts to be sent via email
Collecting - Exadata Celldisk predictive failures
Collecting - Exadata Critical Issue EX9
Collecting - Exadata storage server root filesystem free space
Collecting - HCA firmware version on storage server
Collecting - OFED Software version on storage server
Collecting - OSWatcher status on storage servers
Collecting - Operating system and Kernel version on storage server
Collecting - Scan storage server alerthistory for open alerts
Collecting - Storage server flash cache mode
Collecting - Verify Data Network is Separate from Management Network on storage server
Collecting - Verify Ethernet Cable Connection Quality on storage servers
Collecting - Verify Exadata Smart Flash Cache is created
Collecting - Verify Exadata Smart Flash Log is Created
Collecting - Verify InfiniBand Cable Connection Quality on storage servers
Collecting - Verify Software on Storage Servers (CheckSWProfile.sh)
Collecting - Verify average ping times to DNS nameserver
Collecting - Verify celldisk configuration on disk drives
Collecting - Verify celldisk configuration on flash memory devices
Collecting - Verify griddisk ASM status
Collecting - Verify griddisk count matches across all storage servers where a given prefix name exists
Collecting - Verify storage server metric CD_IO_ST_RQ
Collecting - Verify there are no griddisks configured on flash memory devices
Collecting - Verify total number of griddisks with a given prefix name is evenly divisible of celldisks
Collecting - Verify total size of all griddisks fully utilizes celldisk capacity
Collecting - mpt_cmd_retry_count from /etc/modprobe.conf on Storage Servers
Data collections completed. Checking best practices on 192.
--------------------------------------------------------------------------------------
FAIL => CSS misscount should be set to the recommended value of 60
FAIL => Database Server InfiniBand network MTU size is NOT 65520
WARNING => Database has one or more dictionary managed tablespace
WARNING => RDBMS Version is NOT 11.2.0.2 as expected
FAIL => Storage Server alerts are not configured to be sent via email
FAIL => Management network is not separate from data network
WARNING => NIC bonding is NOT configured for public network (VIP)
WARNING => NIC bonding is not configured for interconnect
WARNING => SYS.AUDSES$ sequence cache size < 10,000 WARNING => GC blocks lost is occurring
WARNING => Some tablespaces are not using Automatic segment storage management.
WARNING => SYS.IDGEN1$ sequence cache size < 1,000 WARNING => Interconnect is configured on routable network addresses
FAIL => Some data or temp files are not autoextensible
FAIL => One or more Ethernet network cables are not connected.
WARNING => Multiple RDBMS instances discovered, observe database consolidation best practices
INFO => ASM griddisk,diskgroup and Failure group mapping not checked.
FAIL => One or more storage server has stateless alerts with null "examinedby" fields.
WARNING => Standby is not opened read only with managed recovery in real time apply mode
FAIL => Managed recovery process is not running
FAIL => Flashback on PRIMARY is not configured
WARNING => Standby is not in READ ONLY WITH APPLY mode
FAIL => Flashback on STANDBY is not configured
FAIL => No one high redundancy diskgroup configured
INFO => Operational Best Practices
INFO => Consolidation Database Practices
INFO => Network failure prevention best practices
INFO => Computer failure prevention best practices
INFO => Data corruption prevention best practices
INFO => Logical corruption prevention best practices
INFO => Storage failures prevention best practices
INFO => Database/Cluster/Site failure prevention best practices
INFO => Client failover operational best practices
FAIL => Some bigfile tablespaces do not have non-default maxbytes values set
FAIL => Standby database is not in sync with primary database
FAIL => Redo transport from primary to standby has more than 5 minutes or more lag
FAIL => Standby database is not in sync with primary database
FAIL => System may be exposed to Exadata Critical Issue DB11 /u01/app/oracle/product/11.2.0.3/dbhome_1
FAIL => System may be exposed to Exadata Critical Issue DB11 /u01/app/oracle/product/11.2.0.3/orcl
INFO => Software maintenance best practices
FAIL => Operating system hugepages count does not satisfy total SGA requirements
FAIL => Table AUD$[FGA_LOG$] should use Automatic Segment Space Management
INFO => Database failure prevention best practices
WARNING => Database Archivelog Mode should be set to ARCHIVELOG
WARNING => Some tablespaces are not using Automatic segment storage management.
WARNING => Database has one or more dictionary managed tablespace
WARNING => Unsupported data types preventing Data Guard (transient logical standby or logical standby) rolling upgrade
Collecting patch inventory on CRS HOME /u01/app/11.2.0.3/grid
Collecting patch inventory on ORACLE_HOME /u01/app/oracle/product/11.2.0.3/dbhome_1
Collecting patch inventory on ORACLE_HOME /u01/app/oracle/product/11.2.0.3/orcl
Copying results from dm01db01-priv and generating report. This might take a while. Be patient.
---------------------------------------------------------------------------------
CLUSTERWIDE CHECKS
---------------------------------------------------------------------------------
---------------------------------------------------------------------------------
Detailed report (html) - /tmp/exachk_192_dbm_040613_105703/exachk_192_dbm_040613_105703.html
UPLOAD(if required) - /tmp/exachk_192_dbm_040613_105703.zip
最后将生成打包成zip的报告,可以定期上传给GCS。
生成报告的HTML版如下图:
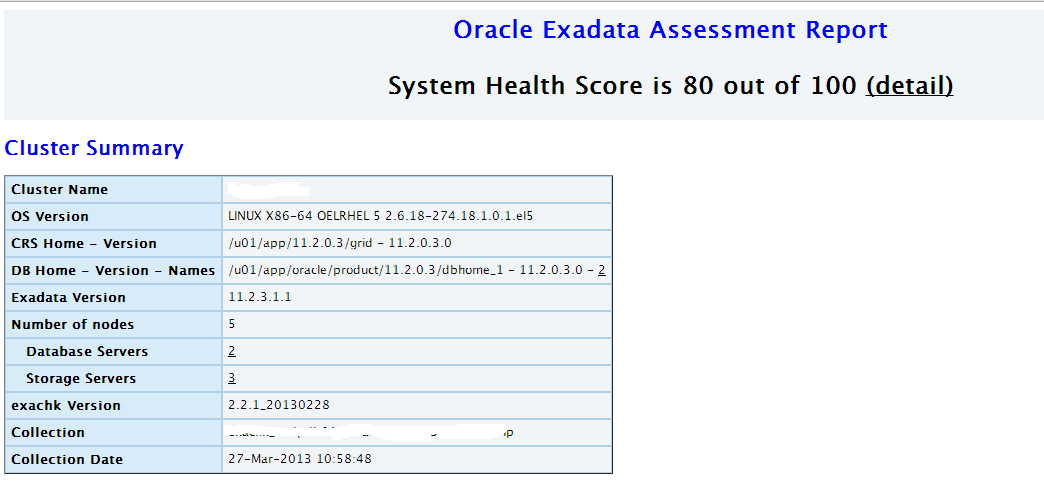

Comment