
1. 实验环境
虚拟机环境 ubuntu 15(桌面版)
hadoop2.7.1
JDK1.8.0_51
![]()
sudo apt-get install ssh
sudo apt-get install rsync
sudo apt-get install vim
2.实验及其结果
2.1安装hadoop
将文件上传到机器上,解压。并进入hadloop目录
mv hadoop-2.7.1 /usr/local/hadoop
cd hadoop
vim etc/hadoop/hadoop-env.sh 配置下列参数:
# set to the root of your Java installation
export JAVA_HOME=/usr/local/jdk1.8.0_51 #自己java的路径
/usr/local/hadoop/bin/hadoop:
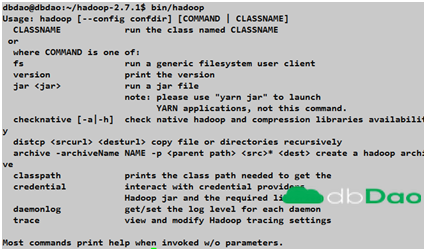
显示使用hadoop的命令说明
2.2 独立操作模式下进行调试:
mkdir input
cp etc/hadoop/*.xml input
/usr/local/hadoop/bin/hadoop jar /usr/local/hadoop /share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep input output ‘dfs[a-z.]+’
cat output/*
–注意:每次任务输出的文件目录应该不同,上面output就是输出的目录、input是之前配置的输入信息。如果要重新调试,要指定不同的目录或者删除原目录。
2.3 伪分布式操作:
cd hadoop/
vim etc/hadoop/core-site.xml:
configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
vim etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置ssh信任:
ssh-keygen -t dsa -P ” -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
export HADOOP\_PREFIX=/usr/local/hadoop
测试ssh 信任:
ssh localhost
查看文件系统启动的信息:
/usr/local/hadoop/bin/hdfs namenode -format
没问题的话就可以开启NameNode进程和 DataNode进程:
/usr/local/hadoop/sbin/start-dfs.sh
启动日志存放在:/usr/local/hadoop/logs/hadoop-dbdao-namenode-dbdao.out
第二节点是用0.0.0.0启动的
The authenticity of host ‘0.0.0.0 (0.0.0.0)’ can’t be established.
ECDSA key fingerprint is 5e:2e:56:ca:cf:a3:65:d6:25:55:b4:c2:f2:01:40:fe.
Are you sure you want to continue connecting (yes/no)? yes
第一次需要输入yes 注册ssh信息,进程已经都启动了,再次sbin/start-dfs.sh可以发现

本地启动了 namenode 和datanode进程,在第二个namenodes 0.0.0.0 也启动了一个namenode 进程3224
ps命令可以查看到这些java进程:
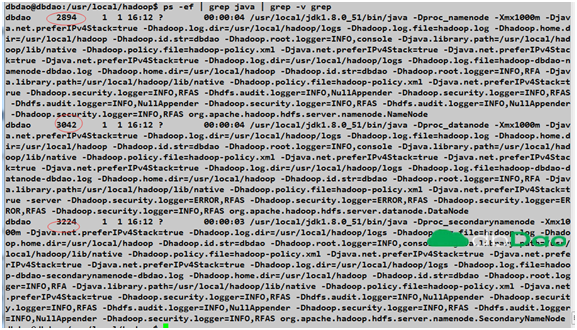
日志默认写在安装hadoop下logs文件中(这个和tomcat日志路径类似)

可以配置name节点的web页面,默认下面地址是可用的,在主机上打开页面:
http://localhost:50070/
–可以从web端直观地获取到一些节点进程的信息
为分布式任务配置HDFS目录:
/usr/local/hadoop/bin/hdfs dfs -mkdir /dbdao
/usr/local/hadoop/bin/hdfs dfs -mkdir /dbdao/test
/usr/local/hadoop/bin/hdfs dfs -put /usr/local/hadoop/etc/hadoop /dbdao/test
查看:
/usr/local/hadoop/bin/hadoop fs -ls /dbdao/test/hadoop
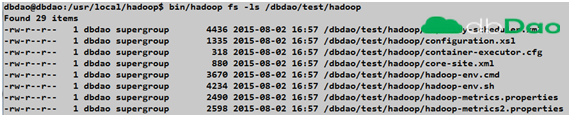
可以发现 原来etc/hadoop下的文件都放入了hadoop文件系统中。
/usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep /dbdao/test/hadoop output ‘dfs[a-z.]+’
将output 文件拷到本地文件系统来观察:
–默认是在文件系统中创建了/user/dbdao(没指定输出文件目录的话)然后输出到了output文件夹中
/usr/local/hadoop/bin/hadoop fs -ls /user/dbdao/output
/usr/local/hadoop/bin/hdfs dfs -get output output –输出到本地文件系统
15/08/02 17:05:15 WARN hdfs.DFSClient: DFSInputStream has been closed already
15/08/02 17:05:15 WARN hdfs.DFSClient: DFSInputStream has been closed already
/usr/local/hadoop/bin/hdfs dfs -cat output/* –直接查看文件系统

停止后台进程:
/usr/local/hadoop/sbin/stop-dfs.sh
Stopping namenodes on [localhost]
localhost: stopping namenode
localhost: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
2.4在单独节点上使用YARN
配置:
vi /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi /usr/local/hadoop/etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
开启资源管理器:
/usr/local/hadoop/sbin/start-yarn.sh
默认的web地址是:
http://localhost:8088/
和之前2.3一样,你可以运行一个MapReduce 任务,观察运行的结果和情况(此处略)。
关闭:
/usr/local/hadoop/sbin/stop-yarn.sh
3.其他信息
debug调试时候会出现下面信息:
WARN io.ReadaheadPool: Failed readahead on ifile
EBADF: Bad file descriptor
查阅信息后,说由于在快速读取文件的时候,文件被关闭引起,也可能是其他bug导致,此处忽略。
4.总结
本次试验主要是简单节点的hadoop安装,以及将hadoop以单机的模式进行启动后,进行简单测试。

Comment