
本文永久链接地址:https://www.askmac.cn/archives/oracle-11g-ocm-materializedview.html
1.物化视图
物化视图是在一个时间点的目标master的一个副本。这个master可以是表,一个主站点,物化视图站点上的一个主物化视图。物化视图通过刷新的方式,在多个master之间进行更新:
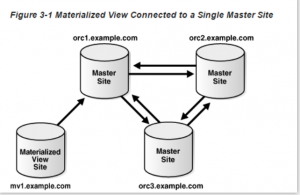
为什么要使用物化视图
1.减轻网络负载
可以使用物化是来分发数据到不同的站点,来减轻网络负载。而不是整个公司访问一个数据库服务器,用户负载分布在多个数据库服务器。为了减少复制的数据量,一个物化视图可以是一个主表或主物化视图的子集。
物化视图不需要专门的网络,只需要定期的刷新物化视图,复制目标的数据让本地访问。结合大规模的部署环境和数据子集(减少带宽),可以大大提高你的复制数据库的可靠性和性能。
2、创建大规模的部署环境
部署模板可以让你再本地环境预创建物化视图。你可以使用部署模板来快速和简单的部署物化视图环境到支持的销售自动化和其他大规模部署环境。一些参数可以在不更改部署模板的条件下让你创建自定义的数据集。
3.启用数据子集
物化视图可以基于列和行的子集来复制数据。而多主复制需要整个表。你可以只复制必要的数据,从而减少不必要的网络流量。
4.启用非连接计算
物化视图并不需要专用网络连接。尽管你通过job有一个自动刷新的过程,你也可以按照需求手动的刷新物化视图。
一个物化视图可以是只读,可更新或可写的。用户不能再只读物化视同上执行DML语句。但是可以在可更新和可写的物化视图上执行DML。
只读物化视图:
你可以在创建物化视图的时候忽略FOR UPDATE子句来创建只读物化视图,其和可更新物化视图的机制一样。但是它们不需要属于一个物化视图组。
只读物化视图消除了出现于主站点数据冲突的可能性,下面是一个只读物化视图的例子:
CREATE MATERIALIZED VIEW hr.employees AS SELECT * FROM hr.employees@orc1.example.com;
可更新物化视图:
你可以在创建的时候使用FOR UPDATE子句来创建一个可更新的物化视图。可更新的物化视图可以让你在物化视图端变更数据
可写物化视图:
一个可写的物化视图 就是使用for update 字句创建,但是不是物化视图组的一部分。用户可以在这个物化视图上进行DM,但是如果一旦刷新了物化视图,这些变更不会push回master,在这上面的变更会丢失。
创建复杂的物化视图
为了快速刷新,定义的查询要遵守限制。如果一个物化视图定义的查询很一般但是不能遵守限制,那么这个物化视图是复杂的并且不能被快速刷新
1.connect by 子句,例如下列语句创建了一个复杂视图:
CREATE MATERIALIZED VIEW hr.emp_hierarchy AS
SELECT LPAD(' ', 4*(LEVEL-1))||email USERNAME
FROM hr.employees@orc1.example.com START WITH manager_id IS NULL
CONNECT BY PRIOR employee_id = manager_id;
2.INTERSECT,MINUS,UNION ALL操作,例如下列语句创建了一个复杂物化视图:
CREATE MATERIALIZED VIEW hr.mview_employees AS SELECT employees.employee_id, employees.email FROM hr.employees@orc1.example.com UNION ALL SELECT new_employees.employee_id, new_employees.email FROM hr.new_employees@orc1.example.com;
3.DISTINCT 或者UNIQUE。
4.一些聚合函数,例如AVG
5.一些表链接。
创建物化视图的一些选项:
on commit:
当主表上的事务一旦提交,就进行刷新操作。不能和 on demand(推迟)子句一起使用,所以也不能指定start with 或next
这个子句会增加事务提交的时间,因为数据在提交过程中将刷新操作也作为了其中一部分。
ON COMMIT的一些限制:
不支持物化视图有远程的表。
如果指定了这个子句,那么不能在随后的主表上执行分布式事务。例如,你不能通过查询远程表来插入主表。
on demand:
用户手动的通过DBMS_MVIEW刷新。默认是on demand。可以通过指定START WITH 或NEXT子句来覆盖默认值。可以在创建的时候指定,也可以在之后的ALTER MATERIAILIZED VIEW 语句中指定。
START WITH 和NEXT 子句会优先考虑,所以在同时指定ON DEMAND 的时候,ON DEMAND没有意义。
START WITH:
自定一个时间表达式,来进行第一次自动的刷新
NEXT 子句:
指定自动刷新的时间间隔
START WITH和NEXT的值必须是在未来时间。如果你忽略了 START WITH的值,那么数据库通过评估NEXT的表达式和物化视图创建时间来决定第一次刷新的时间。如果只指定START WITH但是忽略NEXT的值,那么只会刷新一次。
NERVER REFRESH:
防止任何刷新机制和存储过程刷新物化视图,你可以执行DML。直到使用 ALTER MATERIALIZED VIEW … REFRESH
FOR UPDATE :
表名是可更新的表,配合高级复制技术一起使用时,可以将这些更新传递到主端。
QUERY REWRITE:
让你指定物化视图是否有资格被查询重写
enable 启用物化视图查询重写。
查询重写的限制:
1.你指定在所有物化视图中用户定义的功能都是DETERMINISTIC时启用查询重写。
2.你只有当表达式中的表达式是可重复的时候启用查询重写。例如,你不能包含CURRENT_TIME或USER,序列值(例如 CURRVAL或NEXTVAL),或SAMPLE子句作为物化视图的时候使用。
默认是不开启的,DBMS_MVIEW 中的 EXPLAIN_MVIEW可以帮助确定不能查询重写的原因
2 分区表
2.1 概述
分区可以让表,索引或者索引组织表被细分为更小的片段,每个片段在数据库中的对象被称为一个分区。每一个分区都有它自己的名字,也可以有它自己的存储特性。
对于应用来说,分区表和非分区表是相同的。在使用SQL查询和DML的时候没有区别。
分区键:
在分区表中的每一行是明确被分配到一个单独的分区。分区键由一个或多个字段组成来决定每行被存储的分区。Oracle 会自动的根据分区键对相应的操作进行直接插入,更新和删除操作。
分区表:
任何表可以被分隔成很多分区,除了那些包含LONG或 LONG RAW数据类型的表。但是你可以使用CLOB,BLOB来代替这些数据类型。
在下列场景满足时,可以考虑使用分区表:
1.表大小超过2GB,通常被考虑。
2.表包含历史数据。新数据可以被增加到新分区。一个经典的例子是,一个历史表只有当前月的数据被更新,其他11月的数据都是只读的。
3.当表中的内容必须必须分布式存储到不同设备上时
下列场景考虑分区索引:
1.当数据清理时避免重建整个索引
2.在部分数据上维护索引,而不是在整个数据上。
3.避免在一个字段上的单调递增造成的索引指数影响
通过限制被检索或操作的数据量,并且为并行执行提供分布式数据,分区提供了很多性能优势:
分区可以提高多表连接的性能,被称为分区智联接技术。当2个表被连接时,当2个表被连接键分区时,或者当引用分区表和其父表进行连接时。分区智联会将大的连接,在每个分区上变成小的连接,在短时间内完成整体连接。无论是串行还是并行,这都提供了很好的性能。
在备份的时候,可以只需要备份一个分区,而不用对整个表进行备份。对于数据库对象的维护操作,可以在分区的基础上进行,从而将维护过程分为更易管理的块。
使用分区交换来添加一个区,比修改整个表更有效,因为你不需要修改任何分区。
分区表提供了更好的可用性。例如,当一个分区不可用(存储问题),其他的分区仍然可以被查询而不影响其他的业务。DBA可以将每个分区指定到单独的表空间,通常的做法是这些表空间存储在不同的存储上。
这样可以在相对小的批量窗口中完成大型数据对象的操作。
2.2 常见的分区类型
单一的分区包含:范围分区,哈希分区,列表分区
复合分区:
复合分区是一种结合基础数据的方式;一个表被一个数据分布方法分区,并且每个分区进一步使用第二种数分布方法细分为子分区。对于给定分区的所有子分区表示数据的逻辑子集。
复合分区支持例如添加新范围分区的操作,但是也提供了更高程度的数据修剪和更细粒度的数据布局。下图表示了范围-哈希分区和范围-列表分区:
引用分区:
引用分区让使用分区的2个表,按照彼此的参数完整性约束。分区键通过一个现有的父子关系,强制启用活动的主键和外键约束。
这个拓展的好处是,这些有父子关系的表,可以通过附表的间隔分区键逻辑的继承,不需要重复key字段。逻辑的依赖也能自动的进行级联维护操作,从而使得开发更容易,不容易出错。
间隔分区:
当数据插入到表的数据超过了所有现有的范围分区时,其会指示数据库自动创建一个指定时间的时间建成分区。你必须至少指定一个范围分区。分区键的值决定了范围分区的最高值,这就是转折点。数据库为超过转折点的数据创建间隔分区。每个间隔分区的下边界是之前范围或间隔分区的非包容上边界。
在使用间隔分区的时候,你应该注意:
1.你指定指定一个分区键字段,而且这个只能是NUMBER或DATE数据类型
2.组织索引表不支持间隔分区
3.你不能在间隔分区表上创建一个全局(域)索引
可以创建这些复合分区表:
间隔-范围 ,间隔-哈希 ,间隔-列表
2.3 创建分区表
1.创建范围分区:
CREATE TABLE sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY RANGE (time_id)
( PARTITION sales_q1_2006 VALUES LESS THAN (TO_DATE('01-APR-2006','dd-MON-yyyy'))
TABLESPACE tsa
, PARTITION sales_q2_2006 VALUES LESS THAN (TO_DATE('01-JUL-2006','dd-MON-yyyy'))
TABLESPACE tsb
, PARTITION sales_q3_2006 VALUES LESS THAN (TO_DATE('01-OCT-2006','dd-MON-yyyy'))
TABLESPACE tsc
, PARTITION sales_q4_2006 VALUES LESS THAN (TO_DATE('01-JAN-2007','dd-MON-yyyy'))
TABLESPACE tsd);
2.创建间隔分区:
创建间隔分区表:
CREATE TABLE 中的INTERVAL子句用来创建间隔分区表。在PARTITION必须至少指定一个范围分区。这个范围分区键的值决定了范围分区的最大值,也就是所谓的切换点,数据库会在当超过这个点的时候自动的创建间隔分区。
例如,你创建了一个间隔分区表,使用月间隔并且切换点时 2010 年1月1号。那么2010年1月的最低边界是2010 1月1号:
CREATE TABLE interval_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY RANGE (time_id)
INTERVAL(NUMTOYMINTERVAL(1, 'MONTH'))
( PARTITION p0 VALUES LESS THAN (TO_DATE('1-1-2008', 'DD-MM-YYYY')),
PARTITION p1 VALUES LESS THAN (TO_DATE('1-1-2009', 'DD-MM-YYYY')),
PARTITION p2 VALUES LESS THAN (TO_DATE('1-7-2009', 'DD-MM-YYYY')),
PARTITION p3 VALUES LESS THAN (TO_DATE('1-1-2010', 'DD-MM-YYYY')) );
p3就是上边界,超过p3的将会放置到间隔分区。
- 创建列表分区表:
可以是用default 子句来指定没匹配的行存放到这个分区中:
CREATE TABLE sales_by_region (item# INTEGER, qty INTEGER,
store_name VARCHAR(30), state_code VARCHAR(2),
sale_date DATE)
STORAGE(INITIAL 10K NEXT 20K) TABLESPACE tbs5
PARTITION BY LIST (state_code)
(
PARTITION region_east
VALUES ('MA','NY','CT','NH','ME','MD','VA','PA','NJ')
STORAGE (INITIAL 8M)
TABLESPACE tbs8,
PARTITION region_west
VALUES ('CA','AZ','NM','OR','WA','UT','NV','CO')
NOLOGGING,
PARTITION region_south
VALUES ('TX','KY','TN','LA','MS','AR','AL','GA'),
PARTITION region_central
VALUES ('OH','ND','SD','MO','IL','MI','IA'),
PARTITION region_null
VALUES (NULL),
PARTITION region_unknown
VALUES (DEFAULT)
);
- 创建引用分区:
你可以使用PARTITION BY REFERNACE子句来创建引用分区。这个子句指定了外键约束,并且这个约束成为了外键约束用于这个表的引用分区。这个外键约束必须强制启用。
下面的例子创建了一个父表 orders 有范围分区在 order_date。引用得子表是order_item 被创建有4个分区Q1_2005, Q2_2005, Q3_2005, 和Q4_2005。每个order_items中分区包含的行对应orders中各子的父表:
CREATE TABLE orders
( order_id NUMBER(12),
order_date TIMESTAMP WITH LOCAL TIME ZONE,
order_mode VARCHAR2(8),
customer_id NUMBER(6),
order_status NUMBER(2),
order_total NUMBER(8,2),
sales_rep_id NUMBER(6),
promotion_id NUMBER(6),
CONSTRAINT orders_pk PRIMARY KEY(order_id)
)
PARTITION BY RANGE(order_date)
( PARTITION Q1_2005 VALUES LESS THAN (TO_DATE('01-APR-2005','DD-MON-YYYY')),
PARTITION Q2_2005 VALUES LESS THAN (TO_DATE('01-JUL-2005','DD-MON-YYYY')),
PARTITION Q3_2005 VALUES LESS THAN (TO_DATE('01-OCT-2005','DD-MON-YYYY')),
PARTITION Q4_2005 VALUES LESS THAN (TO_DATE('01-JAN-2006','DD-MON-YYYY'))
);

Comment