
本文永久地址:https://www.askmac.cn/archives/oracle-clusterware-11-2.html
到Oracle数据库11g第2版(11.2)的过渡中,Oracle集群做了大量的改变,完全重新设计了CRSD,引进了“本地CRS”(OHASD)和紧密集成的代理层更换RACK层。新的功能,如Grid Naming Service,即插即用,集群时间同步服务和Grid IPC。集群同步服务(CSS)可能是影响最小的变化,但它提供支持新功能的功能,以及添加了新的功能,如支持IPMI。
有了这个技术文件,我们想借此机会,提供所有的我们已经积累了多年的11.2的发展技术,并将其转发给那些刚刚开始学习Oracle 11.2集群的人。本文提供了总体概述,以及相关的诊断和调试的详细信息。
由于这是Oracle集群诊断文章的第一版本,而不是11.2集群覆盖的全部详细信息。如果你觉得你可以对本文档提供帮助与修改,请告诉我们。
1. Oracle 集群架构
这节将介绍Oracle集群的主要守护进程
1.1 守护进程(Daemons)和代理(agent)概述
下图是关于Oracle集群11.2版本所使用的守护进程,资源和代理的高度概括。
11.2版本和之前的版本的第一个大的区别就是OHASD守护进程,替代了所有在11.2之前版本里的初始化脚本。
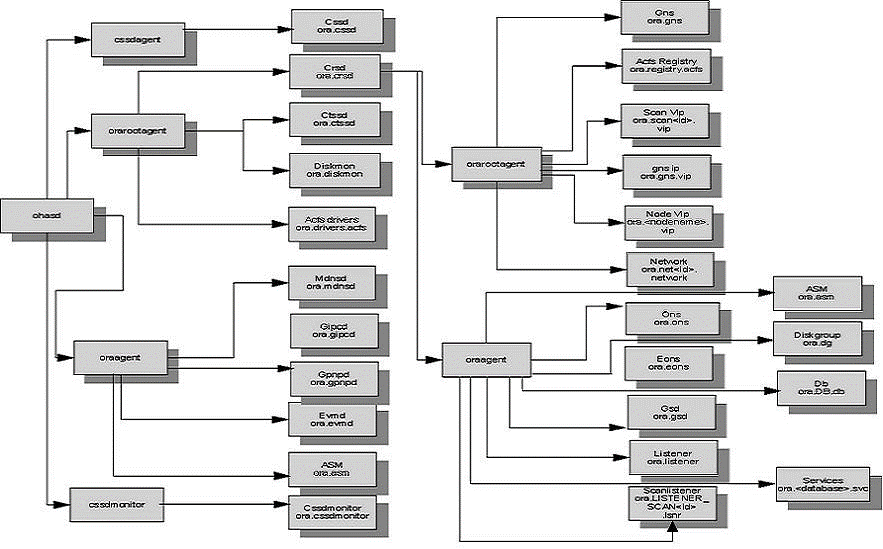
Oracle高可用服务守护进程 (OHASD)
Oracle集群由两个独立的堆栈组成。上层Cluster Ready Services守护进程(CRSD)堆栈和下层Oracle High Availability Services守护进程(ohasd)堆栈。这两个堆栈有促进集群操作几个进程。下面的章节将详细介绍这些内容。
OHASD是启动一个节点的所有其他后台程序的守护进程。OHASD将替换所有存在于11.2之前版本的初始化脚本。
OHASD入口点是/etc/inittab文件,其执行/etc/init.d/ohasd和/etc/init.d/init.ohasd。/etc/init.d/ohasd脚本是包含开始和停止操作的RC脚本。/etc/init.d/init.ohasd脚本是OHASD框架控制脚本将生成Grid_home/bin/ ohasd.bin可执行文件。
集群控制文件位于/ etc/ ORACLE / scls_scr/<hostname>/root(这是Linux的位置),并维护CRSCTL;换句话说,一个“crsctl enable / disable crs”命令将更新该目录中的文件。
| 如:
[root@rac1 root]# ls /etc/oracle/scls_scr/rac1/root crsstart ohasdrun ohasdstr
# crsctl enable -h Usage: crsctl enable crs Enable OHAS autostart on this server
# crsctl disable –h Usage: crsctl disable crs Disable OHAS autostart on this server |
scls_scr/<hostname>/root/ohasdstr文件的内容是控制CRS堆栈的自动启动;文件中的两个可能的值是“enable” – 启用自动启动,或者“disable” – 禁用自动启动。
scls_scr/<hostname>/root/ohasdrun文件控制init.ohasd脚本。三个可能的值是“reboot” – 和OHASD同步,“restart” – 重启崩溃的OHASD,“stop” – 计划OHASD关机。
Oracle 11.2集群有OHASD最大的好处是在一个集群的方式运行某些CRSCTL命令的能力。命令是完全独立于操作系统,因此他们只能靠ohasd。如果ohasd正在运行,则远程操作,如启动,停止和检查远程节点的堆栈状态都是可以执行的。
集群命令包括:
- crsctl check cluster
- crsctl start cluster
- crsctl stop cluster
| [root@rac2 bin]# ./crsctl stop cluster
CRS-2673: Attempting to stop ‘ora.crsd’ on ‘rac2’ CRS-2790: Starting shutdown of Cluster Ready Services-managed resources on ‘rac2’ CRS-2673: Attempting to stop ‘ora.OCR_VOTEDISK.dg’ on ‘rac2’ CRS-2673: Attempting to stop ‘ora.registry.acfs’ on ‘rac2’ 。。。。。。。。。。。。。
[root@rac2 bin]# ./crsctl start cluster CRS-2672: Attempting to start ‘ora.cssdmonitor’ on ‘rac2’ CRS-2676: Start of ‘ora.cssdmonitor’ on ‘rac2’ succeeded CRS-2672: Attempting to start ‘ora.cssd’ on ‘rac2’ CRS-2672: Attempting to start ‘ora.diskmon’ on ‘rac2’ CRS-2676: Start of ‘ora.diskmon’ on ‘rac2’ succeeded 。。。。。。。。。。。。。
[root@rac2 bin]# ./crsctl check cluster CRS-4537: Cluster Ready Services is online CRS-4529: Cluster Synchronization Services is online CRS-4533: Event Manager is online |
OHASD能执行更多的功能,如处理和管理Oracle本地库(OLR),以及作为OLR服务器。在集群中,OHASD以root身份运行;在Oracle重新启动的环境下,以Oracle用户运行OHASD管理应用程序资源。
OHASD Resource Dependency(OHASD资源依赖)
Oracle 11.2的集群堆栈由OHASD守护进程启动,这本身是由一个启动了的节点的/etc/init.d/init.ohasd脚本产生的。另外用’CRSCTL stop CRS后用‘CRSCTL start CRS‘,ohasd开始运行的节点上。然后OHASD守护进程将启动其他守护进程和代理。每个集群守护进程由存储在OLR的OHASD资源表示。下面的图表显示了OHASD资源/集群守护程序和各自的代理进程和所有者的关系。
| Resource Name | Agent Name | Owner |
| ora.gipcd | oraagent | crs user |
| ora.gpnpd | oraagent | crs user |
| ora.mdnsd | oraagent | crs user |
| ora.cssd | cssdagent | Root |
| ora.cssdmonitor | cssdmonitor | Root |
| ora.diskmon | orarootagent | Root |
| ora.ctssd | orarootagent | Root |
| ora.evmd | oraagent | crs user |
| ora.crsd | orarootagent | Root |
| ora.asm | oraagent | crs user |
| ora.driver.acfs | orarootagent | Root |
| ora.crf (new in 11.2.0.2) | orarootagent | root |
下面的图片显示OHASD管理资源/守护进程之间的所有资源依赖关系:
Daemon Resources(守护进程资源)
一个节点典型的守护程序资源列表如下。要获得守护资源列表,我们需要使用-init标志和CRSCTL命令。
| [grid@rac1 admin]$ crsctl stat res -init -t
——————————————————————————- NAME TARGET STATE SERVER STATE_DETAILS ——————————————————————————- Cluster Resources ——————————————————————————- ora.asm 1 ONLINE ONLINE rac1 Started ora.cluster_interconnect.haip 1 ONLINE ONLINE rac1 ora.crf 1 ONLINE OFFLINE ora.crsd 1 ONLINE ONLINE rac1 。。。。。。 |
下面的列表会显示所使用的类型和层次。一切是建立在基本“resource”类型上。cluster_resource使用“resource”类型作为基本类型。cluster_resource作为基本类型构建出ora.daemon.type,守护进程资源都是使用“ora.daemon.type”类型作为基本类型。
| [grid@rac1 admin]$ crsctl stat type -init
TYPE_NAME=application BASE_TYPE=cluster_resource
TYPE_NAME=cluster_resource BASE_TYPE=resource
TYPE_NAME=generic_application BASE_TYPE=cluster_resource
TYPE_NAME=local_resource BASE_TYPE=resource
TYPE_NAME=ora.asm.type BASE_TYPE=ora.daemon.type
TYPE_NAME=ora.crf.type BASE_TYPE=ora.daemon.type
TYPE_NAME=ora.crs.type BASE_TYPE=ora.daemon.type
TYPE_NAME=ora.cssd.type BASE_TYPE=ora.daemon.type
TYPE_NAME=ora.cssdmonitor.type BASE_TYPE=ora.daemon.type
TYPE_NAME=ora.ctss.type BASE_TYPE=ora.daemon.type
TYPE_NAME=ora.daemon.type BASE_TYPE=cluster_resource
TYPE_NAME=ora.diskmon.type BASE_TYPE=ora.daemon.type
TYPE_NAME=ora.drivers.acfs.type BASE_TYPE=ora.daemon.type
TYPE_NAME=ora.evm.type BASE_TYPE=ora.daemon.type
TYPE_NAME=ora.gipc.type BASE_TYPE=ora.daemon.type
TYPE_NAME=ora.gpnp.type BASE_TYPE=ora.daemon.type
TYPE_NAME=ora.haip.type BASE_TYPE=cluster_resource
TYPE_NAME=ora.mdns.type BASE_TYPE=ora.daemon.type
TYPE_NAME=resource BASE_TYPE= |
用ora.cssd资源作为一个例子,所有的ora.cssd属性可以使用crsctl stat res ora.cssd –init –f显示。(列出一部分比较重要的)
| [grid@rac1 admin]$ crsctl stat res ora.cssd -init -f
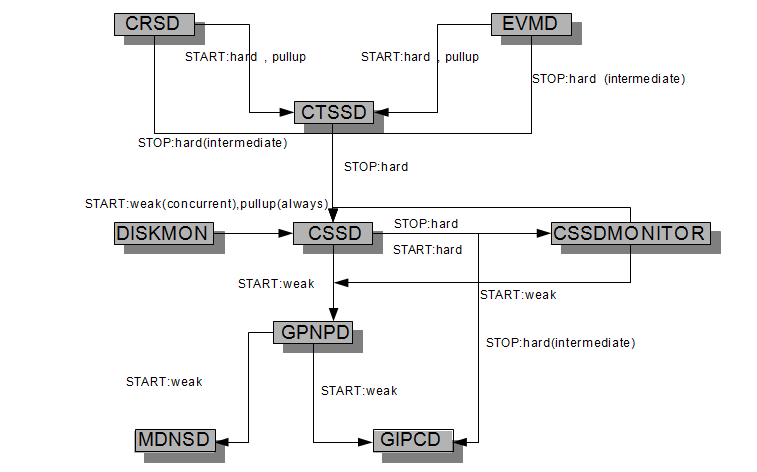
NAME=ora.cssd TYPE=ora.cssd.type STATE=ONLINE TARGET=ONLINE ACL=owner:root:rw-,pgrp:oinstall:rw-,other::r–,user:grid:r-x AGENT_FILENAME=%CRS_HOME%/bin/cssdagent%CRS_EXE_SUFFIX% CHECK_INTERVAL=30 CLEAN_ARGS=abort CLEAN_COMMAND= CREATION_SEED=6 CSSD_MODE= CSSD_PATH=%CRS_HOME%/bin/ocssd%CRS_EXE_SUFFIX% CSS_USER=grid ID=ora.cssd LOGGING_LEVEL=1 START_DEPENDENCIES=weak(concurrent:ora.diskmon)hard(ora.cssdmonitor,ora.gpnpd,ora.gipcd)pullup(ora.gpnpd,ora.gipcd) STOP_DEPENDENCIES=hard(intermediate:ora.gipcd,shutdown:ora.diskmon,intermediate:ora.cssdmonitor) |
为了调试守护进程资源,-init标志一直要用。要启用额外的调试例如ora.cssd:
| [root@rac2 bin]# ./crsctl set log res ora.cssd:3 -init
Set Resource ora.cssd Log Level: 3 |
检查log级别
| [root@rac2 bin]# ./crsctl get log res ora.cssd -init
Get Resource ora.cssd Log Level: 3 |
要检查资源属性,如log级别:
| [root@rac2 bin]# ./crsctl stat res ora.cssd -init -f | grep LOGGING_LEVEL
DAEMON_LOGGING_LEVELS=CSSD=2,GIPCNM=2,GIPCGM=2,GIPCCM=2,CLSF=0,SKGFD=0,GPNP=1,OLR=0 LOGGING_LEVEL=3 |
代理(Agents)
Oracle 11.2集群引入了一个新概念,代理,这使得Oracle集群更强大和高性能。这些代理是多线程的守护进程,实现多个资源类型的入口点和为不同的用户生成新流程。代理是高可用的,此外oraagent,orarootagent和cssdagent/ cssdmonitor,可以有一个应用程序代理和脚本代理。
两个主要代理是oraagent和orarootagent。 ohasd和CRSD各使用一个oraagent和一个orarootagent。如果CRS用户和Oracle用户不同,那么CRSD将利用两个oraagent和一个orarootagent。
oraagent
ohasd’s oraagent:
- 实现对asm, ora.evmd, ora.gipcd, ora.gpnpd, ora.mdnsd的启动/停止/检查/清除操作。
crsd’s oraagent:
- 实现对asm, ora.eons, ora.LISTENER.lsnr, SCAN listeners, ora.ons的启动/停止/检查/清除操作
- 实现对服务, 数据库和磁盘组的启动/停止/检查/清除操作
- Receives eONS events, and translates and forwards them to interested clients (eONS will be removed and its functionality included in EVM in 2.0.2)
- Receives CRS state change events and dequeues RLB events and enqueues HA events for OCI and ODP.NET clients
orarootagent
ohasd’s orarootagent:
- 实现对ora.crsd, ora.ctssd, ora.diskmon, ora.drivers.acfs, ora.crf (11.2.0.2)的启动/停止/检查/清除操作。
crsd’s orarootagent:
- 实现对GNS, VIP, SCAN VIP和网络资源的启动/停止/检查/清除操作。
cssdagent / cssdmonitor
请参照章节: “cssdagent and cssdmonitor”.
Application agent / scriptagent
请参照章节:“application and scriptagent”.
Agent Log Files
ohasd/crsd代理的日志放在Grid_home/log/<hostname>/agent/ {ohasd|crsd}/ <agentname>_<owner>/ <agentname>_<o wner>.log.例如,ora.crsd是ohasd管理属于root用户,那么代理的日志名字为:
Grid_home/log/<hostname>/agent/ohasd/orarootagent_root/orarootagent_root.log
| [grid@rac2 orarootagent_root]$ ls /u01/app/11.2.0/grid/log/rac2/agent/ohasd/orarootagent_root
orarootagent_root.log orarootagent_rootOUT.log orarootagent_root.pid |
同一个代理日志可以存放不同资源的日志,如果这些资源是由相同的守护进程管理的。
如果一个代理进程崩溃了,
-核心文件将被写入
Grid_home/log/<hostname>/agent/{ohasd|crsd}/<agentname>_<owner>
-堆栈调用将写入
Grid_home/log/<hostname>/agent/{ohasd|crsd}/<agentname>_<owner>/<agentna me>_<owner>OUT.log
代理日志的格式如下:
<timestamp>:[<component>][<thread id>]…
<timestamp>:[<component>][<thread id>][<entry point>]…
例如:
| 2016-04-01 13:39:23.070: [ora.drivers.acfs][3027843984]{0:0:2} [check] execCmd ret = 0
[ clsdmc][3015236496]CLSDMC.C returnbuflen=8, extraDataBuf=A6, returnbuf=8D33FD8 2016-04-01 13:39:24.201: [ora.ctssd][3015236496]{0:0:213} [check] clsdmc_respget return: status=0, ecode=0, returnbuf=[0x8d33fd8], buflen=8 2016-04-01 13:39:24.201: [ora.ctssd][3015236496]{0:0:213} [check] translateReturnCodes, return = 0, state detail = OBSERVERCheckcb data [0x8d33fd8]: mode[0xa6] offset[343 ms]. |
如果发生错误,确定发生了什么的入口点:
-集群告警日志,Grid_home/log/<hostname>/alert<hostname>.log
如:/u01/app/11.2.0/grid/log/rac2/alertrac2.log
-OHASD/CRSD日志
Grid_home/log/<hostname>/ohasd/ohasd.log
Grid_home/log/<hostname>/crsd/crsd.log
-对应的代理日志文件
请记住,一个代理日志文件将包含多个资源的启动/停止/检查。以crsd orarootagent资源名称”ora.rac2.vip”为例。
| [root@rac2 orarootagent_root]# grep ora.rac2.vip orarootagent_root.log
。。。。。。。。 2016-04-01 12:30:33.606: [ora.rac2.vip][3013606288]{2:57434:199} [check] Failed to check 192.168.1.102 on eth0 2016-04-01 12:30:33.607: [ora.rac2.vip][3013606288]{2:57434:199} [check] (null) category: 0, operation: , loc: , OS error: 0, other: 2016-04-01 12:30:33.607: [ora.rac2.vip][3013606288]{2:57434:199} [check] VipAgent::checkIp returned false 。。。。。。。。。。。。。 |
集群同步服务(CSS)
CSS守护进程(OCSSD)管理集群的配置,集群里有哪些节点,并在有节点离开或加入时通知集群成员。
ASM和数据库实例的其他集群守护进程依赖于一个有效的CSS。如果OCSSD因任何原因不能引导程序,比如没有发现投票的文件信息,所有其他层级将无法启动。
OCSSD还可以通过网络心跳(NHB)和磁盘心跳(DHB)监控集群的健康。NHB是主要的指标,一个节点还活着,并能参与群集。而DHB将主要用于解决脑裂。
主要的集群线程成员
下面的部分将列出并解释ocssd使用的线程。
– 集群监听线程(CLT) – 试图在启动时连接到所有远程节点,接收和处理所有收到的消息,并响应其他节点的连接请求。每当从节点收到一个数据包,监听重置该节点漏掉的统计数量。
– 发送线程(ST) -专门每秒发送一次网络心跳(NHB)到所有节点,和使用grid IPC(GIPC)每秒发送一次当地的心跳(LHB)到cssdagent和cssdmonitor。
– 投票线程(PT) – 监视远程节点的NHB的。如果CSS守护进程之间的通信通道发生故障时,心跳会被错过。如果某一个节点有太多的心跳信号被错过了,它被怀疑是关闭或断开。重新配置的线程会被唤醒,重新配置将发生,并最终将一个节点驱逐。
- 重新配置管理线程
在重新配置管理节点,唤醒的重新配置管理线程着眼于每个节点,看哪些节点已经错过了NHB的太久。在重新配置管理器线程参与了与其他CSS守护程序投票过程中,一旦确定了新的群集成员,重新配置管理器线程会在投票的文件写入驱逐通知。该RMT还发送关闭消息给被驱逐的节点。投票文件会监控检查心跳的裂脑,直到他们的磁盘心跳已经停止了<misscount>秒,远程节点才会被踢走。
– 发现进程 -发现投票文件
– 避开线程 – 用于I / O防护diskmon进程通信,如果使用EXADATA。
投票文件群集成员线程
– 磁盘ping线程(每个投票的文件)
与它相关联的节点数量和递增序列号的投票文件一起写入群集成员的当前视图;
读取驱逐通知看它的主机节点是否已被驱逐;
这个线程还监视远程节点投票磁盘心跳信息。磁盘心跳信息,以便重新配置过程中用于确定一个远程OCSSD是否已经终止。
– kill block线程 – (每个投票的文件)监控投票文件可用性,以确保足够可访问的投票文件的数量。如果使用的Oracle冗余,我们需要配置多数投票磁盘在线。
– 工作线程 – (11.2.0.1里新增加的,每个投票文件)各种I / O在投票文件。
– 磁盘Ping监视器 – 监视器的I / O投票文件状态
此监视线程,确保磁盘ping线程正确地读取多数投票配置文件里的kill blocks。如果我们不能对投票文件进行I/O操作,由于I / O挂起或I / O故障或其他原因,我们把这个投票文件设置离线。该线程监视磁盘ping线程。如果CSS是无法读取多数投票的文件,它可能不再获得至少一个盘在所有的节点上。这个节点有可能会错过的驱逐通知;换句话说,CSS是不能够进行合作,并必须被终止。
其他线程- Occasionally
– 节点杀死线程 – (瞬时的)用于通过IPMI杀死节点
– 成员杀死线程 – (瞬时的)杀成员期间使用
成员-杀死(监控)线程
本地杀死线程 – 当一个CSS客户端开始杀死成员,当地CSS杀死线程将被创建
– SKGXN监视器(skgxnmon只出现在供应商集群)
这个线程寄存器与SKGXN节点组的成员观察节点组成员身份的变化。当重新配置事件发生时,该线程从SKGXN请求当前节点组成员的位图,并将其与它接收到的最后的时间和其他两个位图的当前值的位图:驱逐待定,其标识节点在被关闭中,VMON的组成员,这表明其节点的过程oclsmon仍在运行(节点仍然是up的)。当一个成员的转变被确认,节点监视线程启动相应的操作。
其他CSS知识
在Oracle集群11g第2版(11.2)减少了配置要求,这意味节点启动时自动添加回去,如果已经停机很久则删除它们。停止超过一个星期都不再olsnodes报道的服务器。当他们离开集群这些服务器自动管理,所以你不必从集群中明确地将其删除。
固定节点
相应的命令来更改节点固定行为(固定或不固定任何特定节点),是crsctl pin/unpin的CSS命令。固定节点是指节点名称与节点号码的关联是固定的。如果一个节点不固定,如果租赁到期时,节点号可能会改变。一个固定节点的租约永不过期。用crsctl delete node命令删除一个节点隐含取消节点固定。
– 在Oracle集群升级,所有服务器都固定,而经过Oracle集群的全新安装11g第2版(11.2),您添加到集群中的所有服务器都不固定。
– 在安装了11.2集群的服务器上有比11.2早版本的实例,那么您无法取消固定。
固定一个节点需要滚动升级到Oracle集群件11g第2版(11.2),将自动完成。我们已经看到有客户进行手动升级失败,是因为没有固定节点。
端口分配
对于CSS和节点监视器固定端口分配已被删除,所以不应该有与其他应用程序的端口竞争。唯一的例外是滚动升级过程中我们分配两个固定的端口。
GIPC
该CSS层是使用新的通信层Grid PC(GIPC),它仍然支持11.2之前使用CLSC通信层。在11.2.0.2,GIPC将支持的使用多个NIC的单个通信链路,例如CSS / NM间的通信。
集群告警日志
多个cluster_alert.log消息已被添加便于更快的定位问题。标识符将在alert.log和链接到该问题的守护程序日志条目都被打印。标识符是组件中唯一的,例如CSS或CRS。
2009-11-24 03:46:21.110
[crsd(27731)]CRS-2757:Command ‘Start’ timed out waiting for response from the resource ‘ora.stnsp006.vip’. Details at (:CRSPE00111:) in
/scratch/grid_home_11.2/log/stnsp005/crsd/crsd.log.
2009-11-24 03:58:07.375
[cssd(27413)]CRS-1605:CSSD voting file is online: /dev/sdj2; details in
/scratch/grid_home_11.2/log/stnsp005/cssd/ocssd.log.
独占模式
在Oracle集群11g第2版(11.2)集群独占模式是一个新的概念。此模式将允许您在一个节点上启动堆栈无需其他跟多的堆栈启动。投票文件不是必需的,不需要的网络连接。此模式用于维护或故障定位。因为这是一个用户调用命令确保在同一时刻只有一个节点是开启的。在独占模式下root用户在某一个节点上使用crsctl start crs –excl命令启动堆栈。
如果集群中的另一个节点已经启动,那么独占模式启动时将失败。OCSSD守护进程会主动去检查节点,如果发现有其他节点已经启动,那么启动将失败报CRS-4402。这不是错误;这是一个预期的行为时,因为另一节点已经启动。约翰·利思说,“你收到CRS-4402时是没有错误文件的”。
发现投票文件
识别投票文件的方法在11.2已经改变。投票文件在11.1和更早版本里的OCR配置,在11.2投票文件通过在GPNP配置文件中的CSS文件投票字符串的发现位置。 例如:
CSS voting file discovery string referring to ASM
发现CSS投票文件字符串指向SM,所以将使用在ASM搜寻字符串值。最常见的是你会看到系统这个配置(例如Linux中,使用旧的2.6内核),其中裸设备仍可配置,裸设备被CRS和ASM使用。
例如:
<orcl:CSS-Profile id=”css” DiscoveryString=”+asm” LeaseDuration=”400″/>
<orcl:ASM-Profile id=”asm” DiscoveryString=”” SPFile=””/>
对于ASM搜寻字符串空值意味着它将恢复到特定的操作系统默认情况下。在Linux上就是/dev/raw/raw*。
CSS voting file discovery string referring to list of LUN’s/disks
在下面的例子中,CSS文件投票字符串发现其实是指磁盘/ LUN列表中。这可能是配置在块设备或设备使用非默认位置。在这种情况下,对于CSS VF发现字符串与ASM发现字符串的值是相同的。
<orcl:CSS-Profile id=”css” DiscoveryString=”/dev/shared/sdsk-a[123]-*-part8″ LeaseDuration=”400″/>
<orcl:ASM-Profile id=”asm” DiscoveryString=”/dev/shared/sdsk-a[123]-*-part8 SPFile=””/>
一些投票文件标识符必须在磁盘上找到接受它作为一种投票磁盘:文件的唯一标识符,集群GUID和匹配的配置化身号(CIN)。可以使用vdpatch检查设备是否是一个投票文件。
CSS租约
获得租约的机制是通过获得该节点的节点数字。租约表示一个节点拥有由租约期限定义的周期关联的节点数量。一个租借期限在GPNP参数文件里硬编码为一个星期。一个节点拥有从上次续租的时间租约的租期。租赁是考虑每DHB过程中得到更新。因此,租赁期满被定义
如下 – lease expiry time = last DHB time + lease duration(租约到期时间=最后一次DHB时间+租约期限)。
有两种类型的租约
– 固定租约
节点使用硬编码的静态节点数量。固定租约是指涉及到使用静态节点号旧版本集群的升级方案中使用。
– 不固定租约
一个节点动态获取节点号使用租约获得算法。租约获得算法旨在解决其试图在同一时间获得相同的插槽节点之间的冲突。
对于一个成功的租约操作会记录在Grid_home/log/<hostname>/alert<hostname>.log,
[cssd(8433)]CRS-1707:Lease acquisition for node staiv10 number 5 completed
对于租约失败的,会有一些信息记录在<alert>hostname.log和ocssd.log。在当前版本中没有可调调整租约。
解决脑裂
下面的章节将描述主要的组件和技术用来解决脑裂。
Heartbeats心跳
CSS的使用集群成员的两个主要的心跳机制,网络心跳(NHB)和磁盘心跳(DHB)。心跳机制是故意冗余的,它们用于不同的目的。在NHB用于检测群集连接丢失的,而DHB主要用于脑裂解决。每个群集节点必须参加心跳协议为了被认为是健康的集群成员。
Network Heartbeat (NHB)
该NHB是在集群安装过程中配置为私有互连专用网络接口。CSS每秒钟从一个节点发送NHB到集群中的所有其他节点,并从远程节点接收每秒一个NHB。该NHBB也发送cssdmonitor和cssdagent。
在NHB包含从本地节点时间戳信息,并用于远程节点找出NHB被发送。这表明一个节点可以参与集群的活动,例如组成员的变化,消息发送等。如果NHB缺少<misscount>秒(在Linux11.2数据库中30秒),集群成员资格更改(群集重新配置)是必需的。如果网络连接在小于<misscount>秒恢复连接到该网络,那么就不一定是致命的。
要调试NHB问题,增加OCSSD日志级别为3对于看每个心跳消息有时是有帮助的。在每个节点上的root用户运行CRSCTL设置日志命令:
# crsctl set log css ocssd:3
监测misstime最大值,看看是否misscount正在增加,这将定位网络问题。
| # tail -f ocssd.log | grep -i misstime
2009-10-22 06:06:07.275: [ ocssd][2840566672]clssnmPollingThread: node 2, stnsp006, ninfmisstime 270, misstime 270, skgxnbit 4, vcwmisstime 0, syncstage 0 2009-10-22 06:06:08.220: [ ocssd][2830076816]clssnmHBInfo: css timestmp 1256205968 220 slgtime 246596654 DTO 28030 (index=1) biggest misstime 220 NTO 28280 2009-10-22 06:06:08.277: [ ocssd][2840566672]clssnmPollingThread: node 2, stnsp006, ninfmisstime 280, misstime 280, skgxnbit 4, vcwmisstime 0, syncstage 0 2009-10-22 06:06:09.223: [ ocssd][2830076816]clssnmHBInfo: css timestmp 1256205969 223 slgtime 246597654 DTO 28030 (index=1) biggest misstime 1230 NTO 28290 2009-10-22 06:06:09.279: [ ocssd][2840566672]clssnmPollingThread: node 2, stnsp006, ninfmisstime 270, misstime 270, skgxnbit 4, vcwmisstime 0, syncstage 0 2009-10-22 06:06:10.226: [ ocssd][2830076816]clssnmHBInfo: css timestmp 1256205970 226 slgtime 246598654 DTO 28030 (index=1) biggest misstime 2785 NTO 28290 |
要显示当前misscount设置的值,使用命令crsctl get css misscount。我们不支持misscount设置默认值以外的值。
| [grid@rac2 ~]$ crsctl get css misscount
CRS-4678: Successful get misscount 30 for Cluster Synchronization Services. |
Disk Heartbeat (DHB)
除了NHB,我们需要使用DHB来解决脑裂。它包含UNIX本地时间的时间戳。
DHB明确的机制,决定有关节点是否还活着。当DHB心跳丢失时间过长,则该节点被假定为死亡。当连接到磁盘丢失时间’过长’,盘会考虑脱机。
关于“太长”的定义取决于对DHB下列情形。首先,长期磁盘I / O超时(LIOT),其中有一个默认的200秒的设定。如果我们不能在时间内完成一个投票文件内的I / O,我们将此投票文件脱机。其次,短期磁盘I / O超时(SIOT),其中CSS集群重新配置过程中使用。SIOT是有关misscount(misscount(30) – reboottime(3)=27秒)。默认重启时间为3秒。要显示CSS 的disktimeout参数的值,使用命令crsctl get css disktimeout。
| [grid@rac2 ~]$ crsctl get css disktimeout
CRS-4678: Successful get disktimeout 200 for Cluster Synchronization Services. |
网络分离检测
最后NHB的时间戳和最近DHB的时间戳进行比较,以确定一个节点是否仍然活着。
当最近DHB和最后NHB的时间戳之间的差是大于SIOT (misscount – reboottime),一个节点被认为仍然活跃。
当时间戳之间的增量小于重启时间,节点被认为是还活着。
如果该最后DHB读取的时间大于SIOT,该节点被认为是死的。
如果时间戳之间的增量比SIOT大比reboottime少,节点的状态不明确,我们必须等待做出决定,直到我们陷入上述三个类别之一。
当网络发生故障,并且仍有活动的节点无法和其他节点通信,网络被认为是分裂。为了保持分裂发生时数据完整性,节点中的一个必须失败,尚存节点应该是最优子群集。节点通过三种可能的方式逐出:
– 通过网络发送驱逐消息。在大多数情况下,这将失败,因为现有的网络故障。
– 通过投票的文件
– 通过IPMI,如果支持和配置
在我们用下面的例子与节点A,B,C和D集群更为详细的解释:
Nodes A and B receive each other’s heartbeats
Nodes C and D receive each other’s heartbeats
Nodes A and B cannot see heartbeats of C or D
Nodes C and D cannot see heartbeats of A or B
Nodes A and B are one cohort, C and D are another cohort
Split begins when 2 cohorts stop receiving NHB’s from each other
CSS任务是一个对称的失败,也就是,A+B组停止接收C+D组发送的NHB,C+D组通知接收A+B组发送的NHB。
在这种情况下,CSS使用投票文件和DHB解决脑裂。kill block,是投票文件结构的一个组成部分,将更新和用于通知已被驱逐的节点。每个节点每一秒读取它的kill block,当另一个节点已经更新kill block后,就会自杀。
在像上面,有相似大小的子群集的情况下,子群中含有低节点编号的子群的节点将生存下来,而其他子群集节点将重新启动。
在一个更大的群集分裂的情况下,更大的子群将生存。在两个节点的群集的情况下,节点号小的节点在网络分离下将存活下来,独立于网络发生错误的位置。
连接到一个节点所需的多数投票文件保持活跃。
Member Kill Architectur
在11.2.0.1中kill守护程序是一个没有杀死CSS组的成员的权利。它是由在I/ O客户端加入组OCSSD库代码催生,并在需要时重生。每个用户有一个杀守护进程(oclskd)(例如crsowner,oracle)。
杀死成员说明
下面这些OCSSD线程参与杀死成员:
client_listener – receives group join and kill requests
peer_listener – receives kill requests from remote nodes
death_check – provides confirmation of termination
member_kill – spawned to manage a member kill request
local_kill – spawned to carry out member kills on local node
node termination – spawned to carry out escalation
Member kills are issued by clients who want to eliminate group members doing IO, for example:
LMON of the ASM instance
LMON of a database instance
crsd on Policy Engine (PE) master node (new in 11.2)
成员杀死总是涉及远程目标;无论是远程ASM或数据库实例。成员杀死请求被移交到本地OCSSD,再把请求发送到OCSSD目标节点上。
在某些情况下,可能在11.2.0.1及更早版本,如极端的CPU和内存资源缺乏,远程节点的杀死守护进程或远程OCSSD不能服务当地OCSSD的成员杀死时间请求(misscount秒),因此成员杀死请求超时。如果LMON(ASM和/或RDBMS)要求成员杀死,那么请求将由当地OCSSD升级到远程节点杀。通过CRSD成员终止请求将永远不会被升级为节点杀,相反,我们依靠orarootagent的检查动作检测功能失调CRSD并重新启动。目标节点的OCSSD将收到成员杀死升级的要求,并会自杀,从而迫使节点重新启动。
与杀守护进程运行实时线程cssdagent / cssdmonitor(11.2.0.2),有更高的机会杀死请求成功,尽管高系统负载。
如果IPMI配置和功能的OCSSD节点监视器将使用IPMI产生一个节点终止线程关闭远程节点。节点终止线程通过管理LAN远程BMC通信;它将建立一个认证会话(只有特权用户可以关闭一个节点),并检查电源状态。下一步骤是请求被断电并反复检查状态直至节点状态为OFF。接到OFF状态后,我们将再次开启远程节点,节点终止线程将退出。
成员杀死的例子:
由于CPU紧缺,数据库实例3的LMON发起成员杀死比如在节点2:
2009-10-21 12:22:03.613810 : kjxgrKillEM: schedule kill of inst 2 inc 20
in 20 sec
2009-10-21 12:22:03.613854 : kjxgrKillEM: total 1 kill(s) scheduled kgxgnmkill: Memberkill called – group: DBPOMMI, bitmap:1
2009-10-21 12:22:22.151: [ CSSCLNT]clssgsmbrkill: Member kill request: Members map 0x00000002
2009-10-21 12:22:22.152: [ CSSCLNT]clssgsmbrkill: Success from kill call rc 0
本地的ocssd(第三节点,内部节点2号)收到的成员杀死请求:
2009-10-21 12:22:22.151: [ ocssd][2996095904]clssgmExecuteClientRequest: Member kill request from client (0x8b054a8)
2009-10-21 12:22:22.151: [ ocssd][2996095904]clssgmReqMemberKill: Kill requested map 0x00000002 flags 0x2 escalate 0xffffffff
2009-10-21 12:22:22.152: [ ocssd][2712714144]clssgmMbrKillThread: Kill requested map 0x00000002 id 1 Group name DBPOMMI flags 0x00000001 start time 0x91794756 end time 0x91797442 time out 11500 req node 2
DBPOMMI is the database group where LMON registers as primary member time out = misscount (in milliseconds) + 500ms
map = 0x2 = 0010 = second member = member 1 (other example: map = 0x7 = 0111 = members 0,1,2)
远程的ocssd(第二节点,内部节点1号)收到的PID的杀死守护进程的请求和提交:
2009-10-21 12:22:22.201: [ ocssd][3799477152]clssgmmkLocalKillThread: Local kill requested: id 1 mbr map 0x00000002 Group name DBPOMMI flags 0x00000000 st time 1088320132 end time 1088331632 time out 11500 req node 2
2009-10-21 12:22:22.201: [ ocssd][3799477152]clssgmmkLocalKillThread: Kill requested for member 1 group (0xe88ceda0/DBPOMMI)
2009-10-21 12:22:22.201: [ ocssd][3799477152]clssgmUnreferenceMember: global grock DBPOMMI member 1 refcount is 7
2009-10-21 12:22:22.201: [ ocssd][3799477152]GM Diagnostics started for mbrnum/grockname: 1/DBPOMMI
2009-10-21 12:22:22.201: [ ocssd][3799477152]group DBPOMMI, member 1 (client
0xe330d5b0, pid 23929)
2009-10-21 12:22:22.201: [ ocssd][3799477152]group DBPOMMI, member 1 (client 0xe331fd68, pid 23973) sharing group DBPOMMI, member 1, share type normal
2009-10-21 12:22:22.201: [ ocssd][3799477152]group DG_LOCAL_POMMIDG, member 0
(client 0x89f7858, pid 23957) sharing group DBPOMMI, member 1, share type xmbr
2009-10-21 12:22:22.201: [ ocssd][3799477152]group DBPOMMI, member 1 (client 0x8a1e648, pid 23949) sharing group DBPOMMI, member 1, share type normal
2009-10-21 12:22:22.201: [ ocssd][3799477152]group DBPOMMI, member 1 (client 0x89e7ef0, pid 23951) sharing group DBPOMMI, member 1, share type normal
2009-10-21 12:22:22.202: [ ocssd][3799477152]group DBPOMMI, member 1 (client 0xe8aabbb8, pid 23947) sharing group DBPOMMI, member 1, share type normal
2009-10-21 12:22:22.202: [ ocssd][3799477152]group DG_LOCAL_POMMIDG, member 0
(client 0x8a23df0, pid 23949) sharing group DG_LOCAL_POMMIDG, member 0, share type normal
2009-10-21 12:22:22.202: [ ocssd][3799477152]group DG_LOCAL_POMMIDG, member 0
(client 0x8a25268, pid 23929) sharing group DG_LOCAL_POMMIDG, member 0, share type normal
2009-10-21 12:22:22.202: [ ocssd][3799477152]group DG_LOCAL_POMMIDG, member 0
(client 0x89e9f78, pid 23951) sharing group DG_LOCAL_POMMIDG, member 0, share type normal
在这一点上,oclskd.log将表明成功杀死这些进程,并完成此杀死请求。在11.2.0.2及更高版本,杀死守护线程将执行杀死:
2009-10-21 12:22:22.295: [ USRTHRD][3980221344] clsnkillagent_main:killreq received:
2009-10-21 12:22:22.295: [ USRTHRD][3980221344] clsskdKillMembers: kill status 0
pid 23929
2009-10-21 12:22:22.295: [ USRTHRD][3980221344] clsskdKillMembers: kill status 0
pid 23973
2009-10-21 12:22:22.295: [ USRTHRD][3980221344] clsskdKillMembers: kill status 0
pid 23957
2009-10-21 12:22:22.295: [ USRTHRD][3980221344] clsskdKillMembers: kill status 0
pid 23949
2009-10-21 12:22:22.295: [ USRTHRD][3980221344] clsskdKillMembers: kill status 0
pid 23951
2009-10-21 12:22:22.295: [ USRTHRD][3980221344] clsskdKillMembers: kill status 0
pid 23947
2009-10-21 12:22:22.295: [ USRTHRD][3980221344] clsskdKillMembers: kill status 0
pid 23949
2009-10-21 12:22:22.295: [ USRTHRD][3980221344] clsskdKillMembers: kill status 0
pid 23929
2009-10-21 12:22:22.295: [ USRTHRD][3980221344] clsskdKillMembers: kill status 0
pid 23951
2009-10-21 12:22:22.295: [ USRTHRD][3980221344] clsskdKillMembers: kill status 0
pid 23947
但是,如果在(misscount+1/2秒)的请求没完成,本地节点上的OCSSD升级节点杀死请求:
2009-10-21 12:22:33.655: [ ocssd][2712714144]clssgmMbrKillThread: Time up:
Start time -1854322858 End time -1854311358 Current time -1854311358 timeout 11500
2009-10-21 12:22:33.655: [ ocssd][2712714144]clssgmMbrKillThread: Member kill request complete.
2009-10-21 12:22:33.655: [ ocssd][2712714144]clssgmMbrKillSendEvent: Missing answers or immediate escalation: Req member 2 Req node 2 Number of answers expected 0 Number of answers outstanding 1
2009-10-21 12:22:33.656: [ ocssd][2712714144]clssgmQueueGrockEvent: groupName(DBPOMMI) count(4) master(0) event(11), incarn 0, mbrc 0, to member 2, events 0x68, state 0x0
2009-10-21 12:22:33.656: [ ocssd][2712714144]clssgmMbrKillEsc: Escalating node
1 Member request 0x00000002 Member success 0x00000000 Member failure 0x00000000 Number left to kill 1
2009-10-21 12:22:33.656: [ ocssd][2712714144]clssnmKillNode: node 1 (staiu02) kill initiated
2009-10-21 12:22:33.656: [ ocssd][2712714144]clssgmMbrKillThread: Exiting
ocssd目标节点将中止,迫使一个节点重启:
2009-10-21 12:22:33.705: [ ocssd][3799477152]clssgmmkLocalKillThread: Time up.
Timeout 11500 Start time 1088320132 End time 1088331632 Current time 1088331632
2009-10-21 12:22:33.705: [ ocssd][3799477152]clssgmmkLocalKillResults: Replying to kill request from remote node 2 kill id 1 Success map 0x00000000 Fail map 0x00000000
2009-10-21 12:22:33.705: [ ocssd][3799477152]clssgmmkLocalKillThread: Exiting
…
2009-10-21 12:22:34.679: [
ocssd][3948735392](:CSSNM00005:)clssnmvDiskKillCheck: Aborting, evicted by node 2, sync 151438398, stamp 2440656688
2009-10-21 12:22:34.679: [ ocssd][3948735392]###################################
2009-10-21 12:22:34.679: [ ocssd][3948735392]clssscExit: ocssd aborting from thread clssnmvKillBlockThread
2009-10-21 12:22:34.679: [ ocssd][3948735392]###################################
如何识别客户端是谁最初发出成员杀死请求?
在ocssd.log里,请求者可以被找到:
2009-10-21 12:22:22.151: [ocssd][2996095904]clssgmExecuteClientRequest: Member kill request from client (0x8b054a8)
<search backwards to when client registered>
2009-10-21 12:13:24.913: [ocssd][2996095904]clssgmRegisterClient:
proc(22/0x8a5d5e0), client(1/0x8b054a8)
<search backwards to when process connected to ocssd>
2009-10-21 12:13:24.897: [ocssd][2996095904]clssgmClientConnectMsg: Connect from con(0x677b23) proc(0x8a5d5e0) pid(20485/20485) version 11:2:1:4, properties: 1,2,3,4,5
用’ps’,或从其他历史(如trace文件,IPD/OS,OSWatcher),这个进程可以通过进程id识别:
$ ps -ef|grep ora_lmon
spommere 20485 1 0 01:46 ? 00:01:15 ora_lmon_pommi_3
智能平台管理接口 (IPMI)
智能平台管理接口(IPMI),今天是包含在许多服务器的行业标准管理协议。 IPMI独立于操作系统系统,如果系统不通电也能工作。IPMI服务器包含一个基板管理控制器(BMC),其用于与服务器通信(BMC)。
关于使用IPMI避开节点
为了支持会员杀死升级为终止节点,您必须配置和使用一个外部机制能够重启问题节点, 或从Oracle集群或从运行的操作系统的配置和使用能够重新启动该节点。IPMI是这样的机制,从11.2开始支持。通常情况下,在安装的过程中配置IPMI。如果在安装过程中没有配置IPMI,则可以在CRS的安装完成后用CRSCTL配置。
About Node-termination Escalation with IPMI
To use IPMI for node termination, each cluster member node must be equipped with a Baseboard Management Controller (BMC) running firmware compatible with IPMI version 1.5, which supports IPMI over a local area network (LAN). During database operation, member-kill escalation is accomplished by communication from the evicting ocssd daemon to the victim node’s BMC over LAN. The IPMI over LAN protocol is carried over an authenticated session protected by a user name and password, which are obtained from the administrator during installation. If the BMC IP addresses are DHCP assigned, ocssd requires direct communication with the local BMC during CSS startup. This is accomplished using a BMC probe command (OSD), which communicates with the BMC through an IPMI driver, which must be installed and loaded on each cluster system.
OLR Configuration for IPMI
There are two ways to configure IPMI, either during the Oracle Clusterware installation via the Oracle Universal Installer or afterwards via crsctl.
OUI – asks about node-fencing via IPMI
tests for driver to enable full support (DHCP addresses)
obtains IPMI username and password and configures OLR on all cluster nodes
Manual configuration – after install or when using static IP addresses for BMCs
crsctl query css ipmidevice
crsctl set css ipmiadmin <ipmi-admin>
crsctl set css ipmiaddr
参见: Oracle Clusterware Administration and Deployment Guide, “Configuration and Installation for Node Fencing” for more information and Oracle Grid Infrastructure Installation Guide, “Enabling Intelligent Platform Management Interface (IPMI)”
调试CSS
有时有必要改变ocssd的默认日志级别。
在11.2的日志默认级别是2.要改变日志级别,root用户在一个节点上执行下面命令:
# crsctl set log css CSSD:N (where N is the logging level)
Logging level 2 = 默认的
Logging level 3 =详细信息,显示各个心跳信息包括misstime,有助于调试NHB的相关问题。
Logging level 4 = 超级详细
大多数问题在级别2就能解决了,有一些需要级别3,很少需要级别4. 使用3或4级,跟踪信息可能只保持几个小时(甚至分钟),因为跟踪文件可以填满和信息可以被覆盖。请注意,日志级别高会造成性能影响ocssd由于数量的跟踪。如果你需要保持更长一段时间的数据,创建一个cron作业来备份和压缩CSS日志。
为了增强对cssdagent或cssdmonitor的跟踪,可以通过crsctl命令实现:
# crsctl set log res ora.cssd=2 -init
# crsctl set log res ora.cssdmonitor=2 -init
在Oracle11.2的集群,CSS输出堆栈的dump信息到cssdOUT.log中。有助于在发生重启之前刷新诊断数据到磁盘上。因此在11.2上我们不考虑有必要的diagwait(默认0)改变,除非支持或者开发有相关建议。
在非常罕见的情况下,只有在调试期间,可能也许必要禁用ocssd重新启动。这可以通过以下crsctl命令。禁用重启应该在支持或开发人员的指导下,可以在线做不会有堆栈重启。
# crsctl modify resource ora.cssd -attr “ENV_OPTS=DEV_ENV” -init
# crsctl modify resource ora.cssdmonitor -attr “ENV_OPTS=DEV_ENV” –init
在11.2.0.2启用更高的日志级别可能介绍各种模块。
用下面命令列出css守护进程的所有模块的名字:
| [root@rac2 bin]# ./crsctl lsmodules css
List CSSD Debug Module: CLSF List CSSD Debug Module: CSSD List CSSD Debug Module: GIPCCM List CSSD Debug Module: GIPCGM List CSSD Debug Module: GIPCNM List CSSD Debug Module: GPNP List CSSD Debug Module: OLR List CSSD Debug Module: SKGFD |
CLSF and SKGFD – 关于仲裁盘的I/O
CSSD – same old one
GIPCCM – gipc communication between applications and CSS
GIPCGM – communication between peers in the GM layer
GIPCNM – communication between nodes in the NM layer
GPNP – trace for gpnp calls within CSS
OLR – trace for olr calls within CSS
下面是如何对不同的模块设置不同的日志级别的例子:
# crsctl set log css GIPCCM=1,GIPCGM=2,GIPCNM=3
# crsctl get log css CSSD=4
检查当前的跟踪日志级别用下面的命令:
# crsctl get log ALL
# crsctl get log css GIPCCM
CSSDAGENT and CSSDMONITOR
CSSDAGENT and CSSDMONITOR几乎提供相同的功能。cssdagent启动,停止,检查ocssd守护进程状态。cssdmonitor监控cssdagent。没有ora.cssdagent资源,也不是ocssd守护进程的资源。
在11.2之前实现上面两个代理的功能是oprocd,olcsmon守护进程。cssdagent和cssdmonitor运行在实时优先级锁定内存,就像ocssd一样。
另外,cssdagent 和cssdmonitor提供下面的服务来确保数据完整性:
监控ocssd,如果ocssd失败,那么cssd* 重启节点
监控节点调度:如果节点夯住了/没有进程调度,重启节点。
更全面的决策是否需要重新启动,cssdagent和cssdmonitor通过NHB从ocssd接收状态信息,确保本地节点的状态被远程节点认为是准确的。此外,集成将利用时间其他节点感知当地节点为目的,如文件系统同步得到完整的诊断数据。
调试CSSDAGENT and CSSDMONITOR
为了启动ocssd代理调试,可以用crsctl set log res ora.cssd:3 –init命令。这个操作的日志记录在Grid_home/log/<hostname>/agent/ohasd/oracssdagent_root/oracssdagent_root.log和更多跟踪信息写在oracssdagent_root.log里。
2009-11-25 10:00:52.386: [ AGFW][2945420176] Agent received the message: RESOURCE_MODIFY_ATTR[ora.cssd 1 1] ID 4355:106099
2009-11-25 10:00:52.387: [ AGFW][2966399888] Executing command:
res_attr_modified for resource: ora.cssd 1 1
2009-11-25 10:00:52.387: [ USRTHRD][2966399888] clsncssd_upd_attr: setting trace to level 3
2009-11-25 10:00:52.388: [ CSSCLNT][2966399888]clssstrace: trace level set to 2 2009-11-25 10:00:52.388: [ AGFW][2966399888] Command: res_attr_modified for resource: ora.cssd 1 1 completed with status: SUCCESS
2009-11-25 10:00:52.388: [ AGFW][2945420176] Attribute: LOGGING_LEVEL for
resource ora.cssd modified to: 3
2009-11-25 10:00:52.388: [ AGFW][2945420176] config version updated to : 7 for ora.cssd 1 1
2009-11-25 10:00:52.388: [ AGFW][2945420176] Agent sending last reply for: RESOURCE_MODIFY_ATTR[ora.cssd 1 1] ID 4355:106099
2009-11-25 10:00:52.484: [ CSSCLNT][3031063440]clssgsgrpstat: rc 0, gev 0, incarn
2, mc 2, mast 1, map 0x00000003, not posted
同样适用于cssdmonitor(ora.cssdmonitor)资源。
1.4.11 概念
heartbeats(心跳)
Disk HeartBeat (DHB) 磁盘心跳,定期的写在投票文件里,一秒钟一次
Network HeartBeat (NHB)网络心跳,每一秒钟发送一次到其他节点上
Local HeartBeat (LHB)本地心跳,每一秒钟一次发送到代理或监控
ocssd 线程
Sending Thread (ST) 同一时间发送网络心跳和本地心跳
Disk Ping thread 每一秒钟把磁盘心跳写到投票文件里
Cluster Listener (CLT) 接收其他节点发送过来的消息,主要是网络心跳
agent/monitor线程
HeartBeat thread (HBT)从ocssd接收本地心跳和检测连接失败
OMON thread (OMT) 监控连接失败
OPROCD thread (OPT) 监控agent/moniter调度进程
VMON thread (VMT)取代clssvmon可执行文件,注册在skgxn组供应商集群软件
Timeouts(超时)
Misscount (MC) 一个节点在被删除之前没有网络心跳的时间
Network Time Out (NTO) 一个节点在被删除之前没有网络心跳的最大保留时间
Disk Time Out (DTO) 大多数投票文件被认为是无法访问的最大时间
ReBoot Time (RBT) 允许重新启动的时间,默认是三秒钟。
Misscount, SIOT, RBT
Disk I/O Timeout amount of time for a voting file to be offline before it is unusable
SIOT – Short I/O Timeout, in effect during reconfig
LIOT – Long I/O Timeout, in effect otherwise
Long I/O Timeout – (LIOT)通过crsctl set css disktimeout配置超时时间,默认200秒。
Short I/O Timeout (SIOT) is (misscount – reboot time)
In effect when NHB’s missed for misscount/2
ocssd terminates if no DHB for SIOT
Allows RBT seconds after termination for reboot to complete
Disk Heartbeat Perceptions
Other node perception of local state in reconfig
No NHB for misscount, node not visible on network
No DHB for SIOT, node not alive
If node alive, wait full misscount for DHB activity to be missing, i.e. node not alive
As long as DHB’s are written, other nodes must wait
Perception of local state by other nodes must be valid to avoid data corruption
Disk Heartbeat Relevance
DHB only read starting shortly before a reconfig to remove the node is started
When no reconfig is impending, the I/O timeout not important, so need not be monitored
If the disk timeout expires, but the NHB’s have been sent to and received from other nodes, it will still be misscount seconds before other nodes will start a reconfig
The proximity to a reconfig is important state information for OPT
Clocks
Time Of Day Clock (TODC) the clock that indicates the hour/minute/second of the day (may change as a result of commands)
aTODC is the agent TODC
cTODC is the ocssd TODC
Invariant Time Clock (ITC) a monotonically increasing clock that is invariant i.e. does not change as a result of commands). The invariant clock does not change if time set backwards or forwards; it is always constant.
aITC is the agent ITC
cITC is the ocssd ITC
是如何工作的
ocssd state information contains the current clock information, the network time out (NTO) based on the node with the longest time since the last NHB and a disk I/O timeout based on the amount of time since the majority of voting files was last online. The sending thread gathers this current state information and sends both a NHB and local heartbeat to ensure that the agent perception of the aliveness of ocssd is the same as that of other nodes.
The cluster listener thread monitors the sending thread. It ensures the sending thread has been scheduled recently and wakes up if necessary. There are enhancements here to ensure that even after clock shifts backwards and forwards, the sending thread is scheduled accurately.
There are several agent threads, one is the oprocd thread which just sleeps and wakes up periodically. Upon wakeup, it checks if it should initiate a reboot, based on the last known ocssd state information and the local invariant time clock (ITC). The wakeup is timer driven. The heartbeat thread is just waiting for a local heartbeat from the ocssd. The heartbeat thread will calculate the value that the oprocd thread looks at, to determine whether to reboot. It checks if the oprocd thread has been awake recently and if not, pings it awake. The heartbeat thread is event driven and not timer driven.
文件系统同步
当ocssd失败, 启动文件系统同步。有大量的时间来做到这一点,我们可以等待几秒钟同步。最后当地心跳表明我们可以等多久,等待事件基于misscount。当等待时间超时了,oprocd会重启这个节点。大多数情况下,诊断数据会写到磁盘里。在极少数的情况下,如因为CSS夯住同步还没执行才会没写到磁盘。
集群就绪服务 (CRS)
集群就绪服务是管理高可用操作的主要程序。CRS守护进程管理集群资源基于配置在OCR上的每个资源信息。这包括启动,停止,监控和故障转移操作。csrd守护进程监控数据库实例,监听,等等,当发生故障时自动重启这些组件。
crsd守护进程由root用户运行,发生故障后自动重启。当数据库集群安装单实例环境在ASM和数据库重启时,ohasd代替crsd管理应用资源。
Policy Engine
概述
在11.2上资源的高可用是由OHASD(通常用于基础设施资源)和CRSD(应用程序部署在集群上)处理。这两个守护进程共享相同的体系结构和大部分的代码库,对于大多数意图和目的,OHASD可以看做是CRSD在单节点的集群上。在后续部分中讨论适用于这两个守护进程。
从11.2开始,CRSD的体系结构实现了主从模型:一个单一的CRSD在集群里被选作主,其他的都是从。在守护进程启动和每次主被重新选择,CRSD把当前主写入crsd.log日志里。
grep “PE MASTER” Grid_home/log/hostname/crsd/crsd.*
crsd.log:2010-01-07 07:59:36.529: [ CRSPE][2614045584] PE MASTER NAME: staiv13
CRSD是一个分布式应用程序由几个“模块”组成。模块主要是state-less和操作通过交换信息。状态(上下文)总是携带每个信息;大多数交互在本质上是异步的。有些模块有专用的,有些线程共享一个线程和一些操作共享线程池。重要的CRSD模块如下:
- The Policy Engine (a.k.a PE/CRSPE in logs)负责所有的策略决定。
- The Agent Proxy Server (a.k.a Proxy/AGFW in logs) 负责管理代理,和Policy Engine 与代理之间的代理命令/事件。
- The UI Server (a.k.a UI/UiServer in logs)负责管理客户端连接和PE与客户端的程序的代理。
- The OCR/OLR module (OCR in logs) 是所有OCR/OLR 交互的前端。
- The Reporter module (CRSRPT in logs) 负责输出CRSD的所有事件
例如,一个客户机请求修改资源将产生以下交互
CRSCTL UI Server PE OCR Module PE Reporter (event publishing)
Proxy (to notify the agent)
CRSCTL UI Server PE
注意UiServer/PE/Proxy每一个可以在不同的节点上,如下图:
Resource Instances & IDs
在11.2中,CRS模块支持资源多样性的两个概念:基数和程度。In 11.2, CRS modeling supports two concepts of resource multiplicity: cardinality and degree. The former controls the number of nodes where the resource can run concurrently while the latter controls the number of instances of the resource that can be run on each node. To support the concepts, the PE now distinguishes between resources and resource instances. The former can be seen as a configuration profile for the entire resource while the latter represents the state data for each instance of the resource. For example, a resource with CARDINALITY=2, DEGREE=3 will have 6 resource instances. Operations that affect resource state (start/stopping/etc.) are performed using resource instances. Internally, resource instances are referred to with IDs which following the following format: “<A> <B>
<C>” (note space separation), where <A> is the resource name, <C> is the degree of the instance (mostly 1), and <B> is the cardinality of the instance for cluster_resource resources or the name of the node to which the instance is assigned for local_resource names. That’s why resource name have “funny” decorations in logs:
[ CRSPE][2660580256] {1:25747:256} RI [r1 1 1] new target state: [ONLINE] old
value: [OFFLINE]
Log Correlation
CRSD is event-driven in nature. Everything of interest is an event/command to process. Two kinds of commands are distinguished: planned and unplanned. The former are usually administrator-initiated (add/start/stop/update a resource, etc.) or system-initiated (resource auto start at node reboot, for instance) actions while the latter are normally unsolicited state changes (a resource failure, for example). In either case, processing such events/commands is what CRSD does and that’s when module interaction takes place. One can easily follow the interaction/processing of each event in the logs, right from the point of origination (say from the UI module) through to PE and then all the way to the agent and back all the way using the concept referred to as a “tint”. A tint is basically a cluster-unique event ID of the following format: {X:Y:Z}, where X is the node number, Y a node-unique number of a process where the event first entered the system, and Z is a monotonically increasing sequence number, per process. For instance, {1:25747:254} is a tint for the 254th event that originated in some process internally referred to us 25747 on node number 1. Tints are new in 11.2.0.2 and can be seen in CRSD/OHASD/agent logs. Each event in the system gets assigned a unique tint at the point of entering the system and modules prefix each log message while working on the event with that tint.
例如,在3节点的集群,node0是PE,在node1上执行“crsctl start resource r1 –n node2”,恰好如上面的图形,将会在日志里产生下面信息:
节点1上的CRSD日志(crsctl总是连接本地CRSD;UI服务器把命令转发到PE)
2009-12-29 17:07:24.742: [UiServer][2689649568] {1:25747:256} Container [ Name: UI_START
…
RESOURCE:
TextMessage[r1]
2009-12-29 17:07:24.742: [UiServer][2689649568] {1:25747:256} Sending message to PE. ctx= 0xa3819430
节点0上的CRSD日志(with PE master)
2009-12-29 17:07:24.745: [ CRSPE][2660580256] {1:25747:256} Cmd : 0xa7258ba8 :
flags: HOST_TAG | QUEUE_TAG
2009-12-29 17:07:24.745: [ CRSPE][2660580256] {1:25747:256} Processing PE
command id=347. Description: [Start Resource : 0xa7258ba8]
2009-12-29 17:07:24.748: [ CRSPE][2660580256] {1:25747:256} RI [r1 1 1] new
target state: [ONLINE] old value: [OFFLINE]
2009-12-29 17:07:24.748: [ CRSOCR][2664782752] {1:25747:256} Multi Write Batch
processing…
2009-12-29 17:07:24.753: [ CRSPE][2660580256] {1:25747:256} Sending message to
agfw: id = 2198
这里,PE执行政策评估和目标节点与代理进行交互(开始行动)和OCR(记录目标的新值)。
CRSD节点2上的日志(启动代理,将消息转发给它)
2009-12-29 17:07:24.763: [ AGFW][2703780768] {1:25747:256} Agfw Proxy Server
received the message: RESOURCE_START[r1 1 1] ID 4098:2198
2009-12-29 17:07:24.767: [ AGFW][2703780768] {1:25747:256} Starting the agent:
/ade/agusev_bug/oracle/bin/scriptagent with user id: agusev and incarnation:1
节点2上的代理日志 (代理执行启动命令)
2009-12-29 17:07:25.120: [ AGFW][2966404000] {1:25747:256} Agent received the
message: RESOURCE_START[r1 1 1] ID 4098:1459
2009-12-29 17:07:25.122: [ AGFW][2987383712] {1:25747:256} Executing command:
start for resource: r1 1 1
2009-12-29 17:07:26.990: [ AGFW][2987383712] {1:25747:256} Command: start for
resource: r1 1 1 completed with status: SUCCESS
2009-12-29 17:07:26.991: [ AGFW][2966404000] {1:25747:256} Agent sending reply
for: RESOURCE_START[r1 1 1] ID 4098:1459
几点2上的CRSD日志(代理回复,将信息传回PE)
2009-12-29 17:07:27.514: [ AGFW][2703780768] {1:25747:256} Agfw Proxy Server
received the message: CMD_COMPLETED[Proxy] ID 20482:2212
2009-12-29 17:07:27.514: [ AGFW][2703780768] {1:25747:256} Agfw Proxy Server
replying to the message: CMD_COMPLETED[Proxy] ID 20482:2212
节点0上的CRSD 日志(收到回复信息,通知通讯员并返回给UI服务器,通讯员发布信息到EVM)
2009-12-29 17:07:27.012: [ CRSPE][2660580256] {1:25747:256} Received reply to
action [Start] message ID: 2198
2009-12-29 17:07:27.504: [ CRSPE][2660580256] {1:25747:256} RI [r1 1 1] new
external state [ONLINE] old value: [OFFLINE] on agusev_bug_2 label = []
2009-12-29 17:07:27.504: [ CRSRPT][2658479008] {1:25747:256} Sending UseEvm mesg
2009-12-29 17:07:27.513: [ CRSPE][2660580256] {1:25747:256} UI Command [Start
Resource : 0xa7258ba8] is replying to sender.
节点1上的CRSD日志(crsctl命令执行完成,UI服务器写出响应,完成API请求)
2009-12-29 17:07:27.525: [UiServer][2689649568] {1:25747:256} Container [ Name:
UI_DATA
r1: TextMessage[0]
]
2009-12-29 17:07:27.526: [UiServer][2689649568] {1:25747:256} Done for
ctx=0xa3819430
The above demonstrates the ease of following distributed processing of a single request across 4 processes on 3 nodes by using tints as a way to filter, extract, group and correlate information pertaining to a single event across a plurality of diagnostic logs.
1.6 Grid Plug and Play (GPnP)
11.2集群的一个新特性是即插即用,由GPnP守护进程管理。GPnPD提供访问GPnP概要文件,在集群的节点协调更新概要文件,以确保所有的节点都有最近的概要文件。
1.6.1 GPnP Configuration
GPnP配置概要文件和钱夹配置,对于每一个节点都是相同的。在数据库安装过程中概要文件和钱夹会被创建并复制。GPnP概要文件是一个XML的测试文件,其中包含必要的引导信息组成一个集群。信息内容比如集群名字,GUID,发现字符串,预期的网络连接。不包含节点的细节信息。配置文件由GPnPD管理,存在于每个节点的GPnP缓存上。如果没有进行更改,那么在所有节点上都是一样的。通过序列号来鉴别配置文件。
GPnP钱包只是一个二进制blob,包含公共/私有RSA密钥, 用于登录和验证GPnP概要文件。钱夹对于所有的GPnP是相同的,在安装数据库软件时创建,不会更改且永远的活着的。
一个典型的配置文件将包含以下信息。永远不会直接改变XML文件; 通过使用支持工具,比如ASMCA,asmcd,oifcfg等等。来修改GPnP的配置信息。
不建议用GPnP 工具来修改GPnP配置文件,要修改配置文件需要很多步骤。如果添加了无效的信息,那么就会弄坏配置文件,并后续会产生问题。
# gpnptool get
Warning: some command line parameters were defaulted. Resulting command line:
/scratch/grid_home_11.2/bin/gpnptool.bin get -o-
<?xml version=”1.0″ encoding=”UTF-8″?><gpnp:GPnP-Profile Version=”1.0″
xmlns=”http://www.grid-pnp.org/2005/11/gpnp-profile”
xmlns:gpnp=”http://www.grid- pnp.org/2005/11/gpnp-profile”
xmlns:orcl=”http://www.oracle.com/gpnp/2005/11/gpnp- profile”
xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance”
xsi:schemaLocation=”http://www.grid-pnp.org/2005/11/gpnp-profile gpnp-profile.xsd”
ProfileSequence=”4″ ClusterUId=”0cd26848cf4fdfdebfac2138791d6cf1″
ClusterName=”stnsp0506″ PALocation=””><gpnp:Network-Profile><gpnp:HostNetwork
id=”gen” HostName=”*”><gpnp:Network id=”net1″ IP=”10.137.8.0″ Adapter=”eth0″
Use=”public”/><gpnp:Network id=”net2″ IP=”10.137.20.0″ Adapter=”eth2″
Use=”cluster_interconnect”/></gpnp:HostNetwork></gpnp:Network-Profile><orcl:CSS-
Profile id=”css” DiscoveryString=”+asm”
LeaseDuration=”400″/><orcl:ASM-Profile id=”asm”
DiscoveryString=”/dev/sdf*,/dev/sdg*,/voting_disk/vote_node1″
SPFile=”+DATA/stnsp0506/asmparameterfile/registry.253.699162981″/>
<ds:Signature xmlns:ds=”http://www.w3.org/2000/09/xmldsig#”>
<ds:SignedInfo><ds:CanonicalizationM ethod
Algorithm=”http://www.w3.org/2001/10/xml-exc-c14n#”/><ds:SignatureMethod
Algorithm=”http://www.w3.org/2000/09/xmldsig#rsa-sha1″/><ds:Reference URI=””>
<ds:Transforms><ds:Transform Algorithm=”http://www.w3.org/2000/09/xmldsig#enveloped-signature”/>
<ds:Transform Algorithm=”http://www.w3.org/2001/10/xml-exc-c14n#”>
<InclusiveNamespaces xmlns=”http://www.w3.org/2001/10/xml-exc-c14n#”
PrefixList=”gpnp orcl xsi”/></ds:Transform></ds:Transforms>
<ds:DigestMethod Algorithm=”http://www.w3.org/2000/09/xmldsig#sha1″/><ds:DigestValue>ORAmrPMJ/plFtG Tg/mZP0fU8ypM=</ds:DigestValue>
</ds:Reference></ds:SignedInfo><ds:SignatureValue>
K u7QBc1/fZ/RPT6BcHRaQ+sOwQswRfECwtA5SlQ2psCopVrO6XJV+BMJ1UG6sS3vuP7CrS8LXrOTyoIxSkU 7xWAIB2Okzo/Zh/sej5O03GAgOvt+2OsFWX0iZ1+2e6QkAABHEsqCZwRdI4za3KJeTkIOPliGPPEmLuImu
DiBgMk=</ds:SignatureValue></ds:Signature></gpnp:GPnP-Profile>
Success.
初始化GPnP配置在安装数据库集群软件时由root脚本创建并传播。在全新安装配置文件的内容来自于数据库安装结构在Grid_home/crs/install/crsconfig_params。
1.6.2 GPnP 守护进程
GPnP守护进程和其他进程一样由OHASD管理并由OHASD产生oraagent。GPnPD的主要目的是服务配置文件,因此是为了启动堆栈。GPnPD的主要启动顺序:
- detects running gpnpd, connects back to oraagent 查找运行的GPnPD,连接返回给oraagent
- opens wallet/profile 打开钱夹/配置文件
- opens local/remote endpoints 打开本地/远程节点
- advertises remote endpoint with mdnsd mdnsd通知远程节点
- starts OCR availability check 启动OCR可用性检查
- discovers remote gpnpds 发现远程GPnPD
- equalizes profile 平等的概要文件
- starts to service clients 开始服务客户端
1.6.3 GPnP CLI Tools
有几个客户端工具能够直接修改GPnP配置文件。要求ocssd是运行的:
- crsctl replace discoverystring
- oifcfg getif / setif
- ASM – srvctl or sqlplus changing the spfile location or the ASM disk discoverystring
注意,参数文件的改变会系列化整个集群的CSS锁(bug 7327595)。
Grid_home/bin/gpnptool是真正维护gpnp文件的工具。查看详细的信息,可以运行:
Oracle GPnP Tool Usage:
“gpnptool <verb> <switches>”, where verbs are:
create Create a new GPnP Profile
edit Edit existing GPnP Profile
getpval Get value(s) from GPnP Profile
get Get profile in effect on local node
rget Get profile in effect on remote GPnP node put Put profile as a current best
find Find all RD-discoverable resources of given type
lfind Find local gpnpd server
check Perform basic profile sanity checks
c14n Canonicalize, format profile text (XML C14N)
sign Sign/re-sign profile with wallet’s private key
unsign Remove profile signature, if any
verify Verify profile signature against wallet certificate
help Print detailed tool help
ver Show tool version
1.6.4 Debugging and Troubleshooting
为了获取更多的日志和跟踪文件,可以设置环境变量GPNP_TRACELEVEL 范围为0-6。GPnP跟踪文件在:
Grid_home/log/<hostname>/alert*, Grid_home/log/<hostname>/client/gpnptool*, other client logs Grid_home/log/<hostname>/gpnpd|mdnsd/* Grid_home/log/<hostname>/agent/ohasd/oraagent_<username>/*
产品安装文件里有基本信息,位置在:
Grid_home/crs/install/crsconfig_params
Grid_home/cfgtoollogs/crsconfig/root*
Grid_home/gpnp/*,
Grid_home/gpnp/<hostname>/* [profile+wallet]
如果GPnP 安装失败,应该进行下面失败场景的检查:
- 不能创建配置文件,钱夹?不能访问配置文件或钱夹? [gpnpd is dead, stack is dead] (bug:8609709,bug:8445816)
- 配置文件里配置错误或者少配置了(例如没有discovery string, 没有interconnect, 太多 interconnects)? [gpnpd is up, stack is dead – e.g. no voting files, no interconnects]
- 无法传播集群范围内的配置文件?[gpnpd daemons are not communicating, no put]
如果是在GPnP运行过程中产生错误,应该进行如下检查:
- mdnsd是否在运行?GPnPD无法注册到mdnsd上?Discovery 失败? [no put, rget]
- 是否是gpnpd 死掉/或者没运行? [no get, immediately fails]
- 是否gpnpd没有全部启动[no get, no put, client spins in retries, times out]
- 发现假的节点是否是集群的成员?D [no put, can block gpnpd dispatch]
- 是否ocssd 没有启动? [no put]
- OCR 已经启动,但是是失败的 [gpnpd dispatch can block, client waits in receive until OCR recovers]
上面的解决的所有第一步都应该先活动守护进程的日志文件并通过crsctl stat res –init –t检查资源的状态。
GPnPD没有运行的其他解决步骤:
- 检查GPnP配置的有效性和检查GPnP日志里的错误信息。可以通过gpnptool check or gpnptool verify进行清晰的检查
# gpnptool check -\
p=/scratch/grid_home_11.2/gpnp/stnsp006/profiles/peer/profile.xml
Profile cluster=”stnsp0506″, version=4
GPnP profile signed by peer, signature valid.
Got GPnP Service current profile to check against.
Current GPnP Service Profile cluster=”stnsp0506″, version=4
Error: profile version 4 is older than- or duplicate of- GPnP Service current profile version 4.
Profile appears valid, but push will not succeed.
# gpnptool verify Oracle GPnP Tool
verify Verify profile signature against wallet certificate Usage:
“gpnptool verify <switches>”, where switches are:
-p[=profile.xml] GPnP profile name
-w[=file:./] WRL-locator of OracleWallet with crypto keys
-wp=<val> OracleWallet password, optional
-wu[=owner] Wallet certificate user (enum: owner,peer,pa)
-t[=3] Trace level (min..max=0..7), optional
-f=<val> Command file name, optional
-? Print verb help and exit
– 如果GPnPD服务在本地,可以用gpnptool lfind进行检查
# gpnptool lfind
Success. Local gpnpd found.
‘gpnptool get’ 可以返回本地配置文件的信息。如果gpnptool lfind|get夯住了,从客户端 夯住的信息和GPnPD日志在Grid_home/log/<hostname>/gpnpd,将会对进一步解决问题有很大的帮助。
– 检查远程GPnPD是响应的,’find’选项将很有帮助:
# gpnptool find -h=stnsp006
Found 1 instances of service ‘gpnp’. mdns:service:gpnp._tcp.local.://stnsp006:17452/agent=gpnpd,cname=stnsp0506
,host=stnsp006,pid=13133/gpnpd h:stnsp006 c:stnsp0506
如果上面的操作挂起了或者返回错误了,检查
Grid_home/log/<hostname>/mdnsd/*.log files和 gpnpd日志。
– 检查所有节点都是响应的,运行gpnptool find –c=<clustername>
# gpnptool find -c=stnsp0506
Found 2 instances of service ‘gpnp’. mdns:service:gpnp._tcp.local.://stnsp005:23810/agent=gpnpd,cname=stnsp0506
,host=stnsp005,pid=12408/gpnpd h:stnsp005 c:stnsp0506 mdns:service:gpnp._tcp.local.://stnsp006:17452/agent=gpnpd,cname=stnsp0506,host=stnsp006,pid=13133/gpnpd h:stnsp006 c:stnsp0506
我们将GPnP配置文件存放在本地OLR和OCR。如果配置文件丢失或者损坏,GPnPD重备份中重建配置文件。
1.7 Oracle网格名称服务(GNS)
集群中GNS执行名称解析。GNS并不总是使用mDNS的性能原因。
在11.2我们支持使用DHCP私人互连和几乎所有的公共网络上的虚拟IP地址。为集群之外的客户端发现集群中的虚拟主机,我们提供了GNS。这适用于任何高级DNS为外部提供名称解析。
本节介绍如何简单的进行DHCP和GNS的配置。一个复杂的网络环境可能需要更复杂的解决方案。配置GNS和DHCP必须在grid安装之前。
GSN提供什么
DHCP提供了动态配置的主机IP地址,但是不能提供一个好的外部客户端使用的名字,因此在混合服务器已经很罕见了。在Oracle 11.2集群,提供了我们的服务来解析名称解决这个问题,和DNS的连接客户是可见的。
设置网络配置
让GNS为客户端工作,需要配置高级别的DNS来代表集群中的一个子区域,集群必须在DNS已知的一个地址运行GNS。GNS地址将用集群中配置的静态VIP来维护。GNS守护进程将跟随在集群vip和子区域的服务名。
需要配置四方面:
- 需要在集群中一个公共网络的静态地址使用GNS VIP。
- 配置高级别的DNS来代表集群中的一个子区域
- 在公共网络上有一个DHCP提供动态地址
- 一个正在运行的集群正确配置GNS
获取一个IP地址作为GNS-VIP
从网络管理员那里请求一个ip地址分配作为GNS-VIP。这个IP地址必须是已经分配了的公司DNS作为给定集群的GNS-VIP,例如strdv0108-gns.mycorp.com。这个地址在集群软件安装之后将由集群软件管理。
创建一个下面格式的条目在适当的DNS区域文件里:
# Delegate to gns on strdv0108
strdv0108-gns.mycorp.com NS strdv0108.mycorp.com
#Let the world know to go to the GNS vip strdv0108.mycorp.com 10.9.8.7
在这里,子区域是strdv0108.mycorp.com,GNS VIP 已经分配了的名称是strdv0108-gns.us.mycorp.com(对应于一个静态IP地址),GNS守护进程将监听默认端口53。
注意:这并不是建立一个地址的名字strdv0108.mycorp.com,创建了一种解析子区域中名字的方法,比如clusterNode1- VIP.strdv0108.mycorp.com。
DHCP
一个主机要求一个IP地址发送广播消息给硬件网络。一个DHCP服务器可以相应请求,并返回一个地址,连同其他消息,比如使用什么网关,用了那个DNS服务,改用什么域名,改用什么NTP服务,等等。
当我们获取DHCP公共网络,我们有几个IP地址:
- 每个主机的一个IP地址(节点VIP)
- 每个集群单个IP作为SCAN
GNS VIP 不能从DHCP获取,因为它必须提前知道,因此必须静态分配。
DHCP配置文件在/etc/dhcp.conf
使用下面的配置例如:
- the interface on the subnet is 10.228.212.0/10 (netmask 255.252.0)
- the addresses allowed to be served are 10.228.212.10 through 228.215.254
- the gateway is 228.212.1
- the domain the machines will reside in for DNS purposes is mycorp.com
/etc/dhcp.conf 将包含类似的信息:
subnet 10.228.212.0 netmask 255.255.252.0
{
default-lease-time 43200;
max-lease-time 86400;
option subnet-mask 255.255.252.0;
option broadcast-address 10.228.215.255;
option routers 10.228.212.1;
option domain-name-servers M.N.P.Q, W.X.Y.Z; option domain-name “strdv0108.mycorp.com”; pool
{
range 10.228.212.10 10.228.215.254;
}
}
名称解析
/etc/resolv.conf必须包含可以解析企业DNS服务器的命名服务器条目,和总超时周期配置必须低于30秒。例如:
/etc/resolv.conf:
options attempts: 2
options timeout: 1
search us.mycorp.com mycorp.com
nameserver 130.32.234.42
nameserver 133.2.2.15
/etc/nsswitch.conf控制名称服务查找顺序。在一些系统上配置,网络信息系统可能在解析Oracle SCAN时产生错误。建议在搜索列表里添加NIS 条目。
/etc/nsswitch.conf
hosts: files dns nis
请参阅:Oracle Grid Infrastructure Installation Guide,
“DNS Configuration for Domain Delegation to Grid Naming Service” for more information.
在11.2 GNS由集群代理orarootagent管理。这个代理启动,停止和检查DNS。GNS添加到OCR和GNS添加到集群的信息通过srvctl add gns –d <mycluster.company.com>命令。
- The GNS Server
在服务器启动GNS服务器,从子区域中检索名字,需要的服务OCR和启动线程。GNS服务器将做的第一件事是一个自我检查一次所有正在运行的线程。它执行一个测试,看看名称解析正在工作。客户端API调用分配一个虚拟的名称和地址,然后服务器试图解析这个名字。如果解析成功和一个地址匹配的虚拟地址,自我检查将成功并把信息写入alert<hostname>.log.这样做自我检查是只有一次,即使测试失败GNS服务器一直运行。
GNS服务的默认trace路径是Grid_home/log/<hostname>/gnsd/。trace文件看起来像下面的格式:
<Time stamp>: [GNS][Thread ID]<Thread name>::<function>:<message>
2009-09-21 10:33:14.344: [GNS][3045873888] Resolve::clsgnmxInitialize: initializing mutex 0x86a7770 (SLTS 0x86a777c).
- The GNS Agent
GNS代理orarootagent会定期检查GNS服务。检查是通过查询GNS的状态。
代理是否成功与GNS广告,执行:
#grep -i ‘updat.*gns’
Grid_home/log/<hostname>/agent/crsd/orarootagent_root/orarootagent_*
orarootagent_root.log:2009-10-07 10:17:23.513: [ora.gns.vip] [check] Updating GNS with stnsp0506-gns-vip 10.137.13.245
orarootagent_root.log:2009-10-07 10:17:23.540: [ora.scan1.vip] [check] Updating GNS with stnsp0506-scan1-vip 10.137.12.200
orarootagent_root.log:2009-10-07 10:17:23.562: [ora.scan2.vip] [check] Updating GNS with stnsp0506-scan2-vip 10.137.8.17
orarootagent_root.log:2009-10-07 10:17:23.580: [ora.scan3.vip] [check] Updating GNS with stnsp0506-scan3-vip 10.137.12.214
orarootagent_root.log:2009-10-07 10:17:23.597: [ora.stnsp005.vip] [check] Updating GNS with stnsp005-vip 10.137.12.228
orarootagent_root.log:2009-10-07 10:17:23.615: [ora.stnsp006.vip] [check] Updating GNS with stnsp006-vip 10.137.12.226
- Command Line Interface
命令行接口通过srvctl与GNS进行交互(唯一的支持途径)。crsctl可以停在和启动ora.gsn但是我们不支持这个除了直接告诉开发。
用下面操作实现GNS操作:
# srvctl {start|stop|modify|etc.} gns …
启动 gns
# srvctl start gns [-l <log_level>] – where –l is the level of logging that GNS should run with.
停止gns
# srvctl stop gns
发布名称和地址
# srvctl modify gns -N <name> -A <address>
- Debugging GNS
默认的GNS服务日志级别是0,我们可以通过ps –ef | grep gnsd.bin简单查看:
/scratch/grid_home_11.2/bin/gnsd.bin -trace-level 0 -ip-address 10.137.13.245 – startup-endpoint ipc://GNS_stnsp005_31802_429f8c0476f4e1
调试GNS服务是可能需要提高日志级别。必须先通过srvctl stop gns命令停掉GNS服务,并通过srvctl start gns –v –l 5重启。只有root用户可以停止和启动GNS。
Usage: srvctl start gns [-v] [-l <log_level>] [-n <node_name>]
-v Verbose output
-l <log_level> Specify the level of logging that GNS should run with.
-n <node_name> Node name
-h Print usage
trace级别在0-6之间,级别5应该在所有情况下都够用了,不推荐设置级别到6,而且gnsd将消耗大量的CPU。
在11.2.0.1由于8705125bug,在初始化安装后默认的GNS服务日志级别是6。用‘srvctl stop / start’命令停掉和重启GNS,把日志级别设成0,这只需要停止和启动gnsd.bin,不会对正在运行的集群产生其他影响。
- srvctl stop gns
- srvctl start gns –l 0
用srvctl 可用查看当前GNS配置
srvctl config gns –a GNS is enabled.
GNS is listening for DNS server requests on port 53 GNS is using port 5353 to connect to mDNS
GNS status: OK
Domain served by GNS: stnsp0506.oraclecorp.com GNS version: 11.2.0.1.0
GNS VIP network: ora.net1.network
从11.2.0.2开始,使用-l 选项对调试GNS很有帮助。
1.8 Grid Interprocess Communication(GIPC)
Grid 进程间的通讯是一个普通的通讯设施用来替代CLSC/NS.他提供一个完全的控制从操作系统到任何客户端的通讯堆栈。在11.2之前依赖NS已经撤掉了,但是为了往下兼容,存在CLSC客户端(主要是从11.1开始)。
GIPC可以支持多种通讯类型:CLSC, TCP, UDP, IPC和GIPC。
关于GIPC端点的监听配置是有点不同的。私人/集群的互连现在定义在GPnP配置文件里。
The requirement for the same interfaces to exist with the same name on all nodes is more relaxed, as long as communication will be established.在GPnP配置文件里关于私人和公共的网络连接配置:
<gpnp:Network id=”net1″ IP=”10.137.8.0″ Adapter=”eth0″ Use=”public”/>
<gpnp:Network id=”net2″ IP=”10.137.20.0″ Adapter=”eth2″ Use=”cluster_interconnect”/>
本文永久地址:https://www.askmac.cn/archives/oracle-clusterware-11-2.html
日志和诊断
GIPC的默认trace级别只是输出错误,默认的trace级别在不同组件之间是0-2。要调试和GIPC相关的问题,你应该提高跟踪日志的级别,下面将进行介绍。
通过crsctl设置跟踪日志级别
用crsctl设置不同组件的GIPC trace级别。
例如:
# crsctl set log css COMMCRS:abcd
Where
- a denotes the trace level for NM
- b denotes the trace level for GM
- c denotes the trace level for GIPC
- d denotes the trace level for PROC
如果只想定义GIPC的跟踪日志级别,修改为默认值2,执行:
# crsctl set log css COMMCRS:2242
为所有的组件打开GIPC跟踪((NM, GM,等等),设置:
# crsctl set log css COMMCRS:3 or
# crsctl set log css COMMCRS:4
级别为4的话,会产生大量的跟踪日志,因此ocssd.log就会很快的进行循环覆盖。
通过GIPC_TRACE_LEVEL和GIPC_FIELD_LEVEL设置跟踪级别
Another option is to set a pair of environment variables for the component using GIPC as communication e.g. ocssd. In order to achieve this, a wrapper script is required. Taking ocssd as an example, the wrapper script is Grid_home/bin/ocssd that invokes ‘ocssd.bin’. Adding the variables below to the wrapper script (under the LD_LIBRARY_PATH) and restarting ocssd will enable GIPC tracing. To restart ocssd.bin, perform a crsctl stop/start cluster.
case `/bin/uname` in Linux)
LD_LIBRARY_PATH=/scratch/grid_home_11.2/lib export LD_LIBRARY_PATH
export GIPC_TRACE_LEVEL=4
export GIPC_FIELD_LEVEL=0x80
# forcibly eliminate LD_ASSUME_KERNEL to ensure NPTL where available
LD_ASSUME_KERNEL=
export LD_ASSUME_KERNEL LOGGER=”/usr/bin/logger”
if [ ! -f “$LOGGER” ];then
LOGGER=”/bin/logger”
fi
LOGMSG=”$LOGGER -puser.err”
;;
这将设置跟踪级别为4,环境变量的值
GIPC_TRACE_LEVEL=3 (valid range [0-6])
GIPC_FIELD_LEVEL=0x80 (only 0x80 is supported)
通过GIPC_COMPONENT_TRACE设置跟踪级别
使用GIPC_COMPONENT_TRACE环境变量进行更细粒度的跟踪。定义的组建为GIPCGEN, GIPCTRAC, GIPCWAIT, GIPCXCPT, GIPCOSD, GIPCBASE, GIPCCLSA, GIPCCLSC, GIPCEXMP, GIPCGMOD, GIPCHEAD, GIPCMUX, GIPCNET, GIPCNULL, GIPCPKT, GIPCSMEM, GIPCHAUP, GIPCHALO, GIPCHTHR, GIPCHGEN, GIPCHLCK, GIPCHDEM, GIPCHWRK
例如:
# export GIPC_COMPONENT_TRACE=GIPCWAIT:4,GIPCNET:3
跟踪信息样子如下:本文永久地址:https://www.askmac.cn/archives/oracle-clusterware-11-2.html
2009-10-23 05:47:40.952: [GIPCMUX][2993683344]gipcmodMuxCompleteSend: [mux] Completed send req 0xa481c0e0 [00000000000093a6] { gipcSendRequest : addr ”, data 0xa481c830, len 104, olen 104, parentEndp 0x8f99118, ret gipcretSuccess (0), objFlags 0x0, reqFlags 0x2 }
2009-10-23 05:47:40.952: [GIPCWAIT][2993683344]gipcRequestSaveInfo: [req]
Completed req 0xa481c0e0 [00000000000093a6] { gipcSendRequest : addr ”, data 0xa481c830, len 104, olen 104, parentEndp 0x8f99118, ret gipcretSuccess (0), objFlags 0x0, reqFlags 0x4 }
只有一些层级CSS,GPnPD,GNSD,和很小部分的MDNSD现在使用GIPC。
其他的如CRS/EVM/OCR/CTSS 从11.2.0.2开始使用GIPC。设置GIPC跟踪日志级别对于调试连接问题将很重要。
1.9 Cluster time synchronization service daemon (CTSS):
The CTSS is a new feature in Oracle Clusterware 11g release 2 (11.2), which takes care of time synchronization in a cluster, in case the network time protocol daemon is not running or is not configured properly.
The CTSS synchronizes the time on all of the nodes in a cluster to match the time setting on the CTSS master node. When Oracle Clusterware is installed, the Cluster Time Synchronization Service (CTSS) is installed as part of the software package. During installation, the Cluster Verification Utility (CVU) determines if the network time protocol (NTP) is in use on any nodes in the cluster. On Windows systems, CVU checks for NTP and Windows Time Service.
If Oracle Clusterware finds that NTP is running or that NTP has been configured, then NTP is not affected by the CTSS installation. Instead, CTSS starts in observer mode (this condition is logged in the alert log for Oracle Clusterware). CTSS then monitors the cluster time and logs alert messages, if necessary, but CTSS does not modify the system time. If Oracle Clusterware detects that NTP is not running and is not configured, then CTSS designates one node as a clock reference, and synchronizes all of the other cluster member time and date settings to those of the clock reference.
Oracle Clusterware considers an NTP installation to be misconfigured if one of the following is true:
- NTP is not installed on all nodes of the cluster; CVU detects an NTP installation by a configuration file, such as conf
- The primary and alternate clock references are different for all of the nodes of the cluster
- The NTP processes are not running on all of the nodes of the cluster; only one type of time synchronization service can be active on the
To check whether CTSS is running in active or observer mode run crsctl check ctss
CRS-4700: The Cluster Time Synchronization Service is in Observer mode.
or
CRS-4701: The Cluster Time Synchronization Service is in Active mode. CRS-4702: Offset from the reference node (in msec): 100
The tracing for the ctssd daemon is written to the octssd.log. The alert log (alert<hostname>.log) also contains information about the mode in which CTSS is running.
[ctssd(13936)]CRS-2403:The Cluster Time Synchronization Service on host node1 is in observer mode.
[ctssd(13936)]CRS-2407:The new Cluster Time Synchronization Service reference node
is host node1.
[ctssd(13936)]CRS-2401:The Cluster Time Synchronization Service started on host node1.
- CVU checks
There are pre-install CVU checks performed automatically during installation, like: cluvfy stage –pre crsinit <>
This step will check and make sure that the operating system time synchronization software (e.g. NTP) is either properly configured and running on all cluster nodes, or on none of the nodes.
During the post-install check, CVU will run cluvfy comp clocksync –n all. If CTSS is in observer mode, it will perform a configuration check as above. If the CTSS is in active mode, we verify that the time difference is within the limit.
- CTSS resource
When CTSS comes up as part of the clusterware startup, it performs step time sync, and if everything goes well, it publishes its state as ONLINE. There is a start dependency on ora.cssd but note that it has no stop dependency, so if for some reasons (maybe faulted CTSSD), CTSSD dumps core or exits, nothing else should be affected.
The chart below shows the start dependency build on ora.ctssd for other resources.
crsctl stat res ora.ctssd -init –t
———————————————————————- NAME TARGET STATE SERVER STATE_DETAILS
———————————————————————-
ora.ctssd
1 ONLINE ONLINE node1 OBSERVER
1.10 mdnsd
Debugging mdnsd
In order to capture mdnsd network traffic, use the mDNS Network Monitor located in
Grid_home/bin:
# mkdir Grid_home/log/$HOSTNAME/netmon
# Grid_home/bin/oranetmonitor &
The output from oranetmonitor will be captured in netmonOUT.log in the above directory.
2. Voting Files and Oracle Cluster Repository Architecture
在ASM上存储OCR和voting files 消除了第三方卷管理器和消除了安装Oracle集群时的OCR和投票文件复杂的磁盘分区。
2.1 Voting File in ASM
ASM管理存储投票文件和其他文件不一样。当投票文件放在ASM磁盘组的磁盘上时,Oracle集群正确的记录是存放在哪个磁盘组上的哪个磁盘。如果ASM坏了,CSS还能继续访问投票文件。如果你选择存放投票文件在ASM上,所有的投票文件都要存放在ASM上。我们不支持有一部分投票文件在ASM上有一部分在NAS上。
在一个磁盘组上能够存放的投票文件的数量依赖于你的ASM磁盘组冗余 。
- 一个磁盘组外部冗余,只能存放一个投票文件
- 一个磁盘组标准冗余,可以存放三个投票文件
- 一个磁盘组高度冗余:可以存放五个投票文件
By default, Oracle ASM puts each voting file in its own failure group within the disk group. A failure group is a subset of the disks in a disk group, which could fail at the same time because they share hardware, e.g. a disk controller. The failure of common hardware must be tolerated. For example, four drives that are in a single removable tray of a large JBOD (Just a Bunch of Disks) array are in the same failure group because the tray could be removed, making all four drives fail at the same time. Conversely, drives in the same cabinet can be in multiple failure groups if the cabinet has redundant power and cooling so that it is not necessary to protect against failure of the entire cabinet. However, Oracle ASM mirroring is not intended to protect against a fire in the computer room that destroys the entire cabinet. If voting files stored on Oracle ASM with Normal or High redundancy, and the storage hardware in one failure group suffers a failure, then if there is another disk available in a disk group in an unaffected failure group, Oracle ASM recovers the voting file in the unaffected failure group.
2.2 Voting File Changes
- The voting files formation critical data are stored in the voting file and not in the OCR anymore. From a voting file perspective, the OCR is not touched at all. The critical data each node must agree on to form a cluster are e.g. misscount and the list of voting files configured。
- In Oracle Clusterware 11g release 2 (11.2), it is no longer necessary to back up the voting disk. The voting disk data is automatically backed up in OCR as part of any configuration change and is automatically restored to any voting disk that is being added. If all voting disks are corrupted, however, you can restore them as described in the Oracle Clusterware Administration and Deployment
- New blocks added to the voting files are the voting file identifier block (needed for voting file stored in ASM), and it contains the cluster GUID and the file UID. The committed and pending configuration incarnation number (CCIN and PCIN) contain this formation critical
- 查询投票文件的配置和用crsctl query cssvotedisk查询配置文件的位置:
$ crsctl query css votedisk
| ## STATE | File Universal Id | File Name | Disk group |
| — —– | —————– | ——— | ———- |
- ONLINE 3e1836343f534f51bf2a19dff275da59 (/dev/sdf10) [DATA]
- ONLINE 138cbee15b394f3ebf57dbfee7cec633 (/dev/sdg11) [DATA] 3. ONLINE 462722bd24c94f70bf4d90539c42ad4c (/dev/sdu12) [DATA] Located 3 voting file(s).
- 投票文件存放在ASM里
o 投票文件存放在ASM里,一个现存的投票文件损坏可能会自动删除和添加回去。
- 投票文件可以从/迁移到NAS/ASM和从ASM迁移到ASM,例如
$ crsctl replace css votedisk /nas/vdfile1 /nas/vdfile2 /nas/vdfile3
或
$ crsctl replace css votedisk +OTHERDG
- 如果索引的投票文件都损坏了,你可以用下面的方法恢复。如果因为投票文件丢失而使集群已经关闭并无法重启,你必须赢独占模式启动CSS,并输入下面命令替换投票文件:
- # crsctl start crs –excl (on one node only) o # crsctl delete css votedisk FUID
- # crsctl add css votedisk path_to_voting_disk
假如是扩展的oracle集群/扩展的RAC配置, 第三投票文件必须存放在第三方存储上的三个位置防止数据中心宕机。我们支持第三方投票文件在标准的NFS上. 更多信息参考附录 “Oracle Clusterware 11g release 2 (11.2) – Using standard NFS to support a third voting file on a stretch cluster configuration”.
参见: Oracle Clusterware Administration and Deployment Guide, “Voting file, Oracle Cluster Registry, and Oracle Local Registry” for more information. For information about extended clusters and how to configure the quorum voting file see the Appendix.
2.3 Oracle Cluster Registry (OCR)
在11.2,OCR可以存放在ASM中。ASM的成员关系和状态表(PST)在多个磁盘上复制并存放在OCR。因此OCR可以容忍丢失相同数量的磁盘和底层磁盘组,针对错误磁盘,可以重定位/重新均衡。
为了在磁盘组中存放OCR,磁盘组有一个特殊的文件类型叫’ocr’.
默认的配置文件的位置是/etc/oracle/ocr.loc
# cat /etc/oracle/ocr.loc
ocrconfig_loc=+DATA
local_only=FALSE
From a user and maintenance perspective, the rest remains the same. The OCR can only be configured in ASM when the cluster completely migrated to 11.2 (crsctl query crs activeversion >= 11.2.0.1.0). We still support mixed configurations, so we could have OCR’s stored in ASM and another stored on a supported NAS device, as we support up to 5 OCR locations in 11.2.0.1. We do not support raw or block devices for neither OCR nor voting files anymore.
在ASM实例启动时,OCR磁盘组自动挂载。CRSD和ASM维护依赖于OHASD。
OCRCHECK
There are small enhancements in ocrcheck like the –config which is only checking the configuration. Run ocrcheck as root otherwise the logical corruption check will not run. To check OLR data use the –local keyword.
Usage: ocrcheck [-config] [-local]
Shows OCR version, total, used and available space Performs OCR block integrity (header and checksum) checks Performs OCR logical corruption checks (11.1.0.7)
‘-config’ checks just configuration (11.2) ‘-local’ checks OLR, default OCR
Can be run when stack is up or down
输出结果就像:
# ocrcheck
Status of Oracle Cluster Registry is as follows: Version : 3
Total space (kbytes) : 262120 Used space (kbytes) : 3072 Available space (kbytes) : 259048 ID : 701301903
Device/File Name : +DATA
Device/File integrity check succeeded Device/File Name : /nas/cluster3/ocr3
Device/File integrity check succeeded Device/File Name : /nas/cluster5/ocr1
Device/File integrity check succeeded Device/File Name : /nas/cluster2/ocr2
Device/File integrity check succeeded Device/File Name : /nas/cluster4/ocr4
Device/File integrity check succeeded
Cluster registry integrity check succeeded Logical corruption check succeeded
2.4 Oracle Local Registry (OLR)
OLR结构和OCR相似,是一个节点的本地信息库,是由OHASD管理的。OLR的配置信息只属于本地几点,不和其他节点共享。
配置信息存放在‘/etc/oracle/olr.loc’ (on Linux)或其他操作系统的类似位置上。在安装好Oracle集群后的默认位置:
- RAC: Grid_home/cdata/<hostname.olr>
- Oracle Restart: Grid_home/cdata/localhost/hostname。
在OLR里存放信息,是必须由OHASD启动或添加到集群的;包括的数据关于GPnP钱夹,集群配置和版本信息。
OLR的密匙属性和OCR是一样的,检查或者转储OLR信息的工具和OCR也是一样的。
查看OLR的位置,运行命令:
# ocrcheck -local –config
Oracle Local Registry configuration is : Device/File Name : Grid_home/cdata/node1.olr
转储OLR的内容,执行命令:
# ocrdump -local –stdout (or filename)
ocrdump –h to get the usage
参见:Oracle Clusterware Administration and Deployment Guide, “Managing the Oracle Cluster Registry and Oracle Local Registries” for more information about using the ocrconfig and ocrcheck.
2.5 Bootstrap and Shutdown if OCR is located in ASM
ASM挂载磁盘组之前OCR操作必须能执行。强制卸载OCR或ASM实例被强制关闭会报错。
当堆栈是运行的,CRSD保持读写OCR。
OHASD maintains the resource dependency and will bring up ASM with the required diskgroup mounted before it starts CRSD.
Once ASM is up with the diskgroup mounted, the usual ocr* commands (ocrcheck, ocrconfig, etc.) can be used.
执行关闭有活动的OCR的ASM实例会报ORA-15097错误。(意味着在这个节点上运行着CRSD)。为了查看哪个客户端在访问ASM,执行命令:
asmcmd lsct (v$asm_client)
DB_Name Status Software_Version Compatible_version Instance_Name Disk_Group
+ASM CONNECTED 11.2.0.1.0 11.2.0.1.0 +ASM2 DATA
asmcmd lsof
DB_Name Instance_Name Path
+ASM +ASM2 +data.255.4294967295
+data.255用来标识在ASM上的OCR。
2.6 OCR in ASM diagnostics
产生了一些错误,
- 确认ASM实例是启动的和相应的磁盘组是挂载的,检查log看ASM实例的日志。
- 核实OCR文件创建在磁盘组上了,用asmcmd ls 查看。集群堆栈保持访问OCR文件,大多数时候在log里可能会有CRSD的错误信息。一些错误关于ocr* 命令(如crsd,在客户端经常考虑),将会在Grid_home/log/<hostname>/client目录里产生跟踪文件; 其他情况下,在错误堆栈的头部寻找kgfo / kgfp / kgfn 。
- Confirm that the ASM compatible.asm property of the diskgroup is set to at least 11.2.0.0.
The ASM Diskgroup Resource
当一个磁盘组被创建,磁盘组资源将自动创建名字,ora.<DGNAME>.dg,状态被设置成ONLINE。如果磁盘组卸载了,那么状态就会设置成OFFLINE,由于这是CRS管理的资源。当删除一个磁盘组时,磁盘组资源也会被删除。
数据库要访问ASM文件时会在数据库和磁盘组之间自动建立依赖关系。然而,当数据库不再使用ASM文件或者ASM文件被移除了,我们没法自动移除依赖关系,这就需要用srvctl命令行工具了。
典型的ASM alert.log 里的成功/失败和警告信息:
Success:
NOTE: diskgroup resource ora.DATA.dg is offline
NOTE: diskgroup resource ora.DATA.dg is online
Failure
ERROR: failed to online diskgroup resource ora.DATA.dg
ERROR: failed to offline diskgroup resource ora.DATA.dg
Warning
WARNING: failed to online diskgroup resource ora.DATA.dg (unable to communicate with CRSD/OHASD)
This warning may appear when the stack is started WARNING: unknown state for diskgroup resource ora.DATA.dg
如果错误发生了,查看alert.log里关于资源操作的状态信息,如:
“ERROR”: the resource operation failed; check CRSD log and Agent log for more details
Grid_home/log/<hostname>/crsd/
Grid_home/log/<hostname>/agent/crsd/oraagent_user/
“WARNING”: cannot communicate with CRSD.
在引导ASM实例启动和在CRSD之前挂载磁盘组,这个警告可以忽略。
磁盘组资源的状态和磁盘组时要一致的。在少数情况下,会出现短暂的不同步。执行srvctl让状态同步,或者等待一段时间让代理去刷新状态。如果这个不同步的时间比较长,请检查CRSD 日志和ASM日期看更多的细节信息。
打开更全面的跟踪用事件event=”39505 trace name context forever, level 1“。
2.7 The Quorum Failure Group
一个仲裁故障组是故障组的一种特殊类型,不包含用户数据也在决定冗余要求时也不需要考虑。
COMPATIBLE.ASM磁盘组的compatibility属性必须设置为11.2或更高,用来在磁盘组里存放OCR或投票文件。
在拓展的/延伸的集群或者两个存储阵列需要第三个投票文件时,在安装数据库软件时我们不支持创建一个仲裁故障组。
创建一个仲裁故障组的磁盘组在第三阵列可用:
SQL> CREATE DISKGROUP PROD NORMAL REDUNDANCY
FAILGROUP fg1 DISK ‘<a disk in SAN1>’
FAILGROUP fg2 DISK ‘<a disk in SAN2>’
QUORUM FAILGROUP fg3 DISK ‘<another disk or file on a third location>’
ATTRIBUTE ‘compatible.asm’ = ’11.2.0.0’;
如果是用asmca创建的磁盘组,添加仲裁盘到磁盘组里,Oracle集群会自动改变CSS仲裁盘的位置,例如:
$ crsctl query css votedisk
## STATE File Universal Id File Name Disk group
— —– —————– ——— ———
- ONLINE 3e1836343f534f51bf2a19dff275da59 (/dev/sdg10) [DATA]
- ONLINE 138cbee15b394f3ebf57dbfee7cec633 (/dev/sdf11) [DATA]
- ONLINE 462722bd24c94f70bf4d90539c42ad4c (/voting_disk/vote_node1) [DATA]
Located 3 voting file(s).
如果是通过SQL*PLUS,就要执行crsctl replace css votedisk。
本文永久地址:https://www.askmac.cn/archives/oracle-clusterware-11-2.html
参见:Oracle Database Storage Administrator’s Guide, “Oracle ASM Failure Groups” for more information. Oracle Clusterware Administration and Deployment Guide, “Voting file, Oracle Cluster Registry, and Oracle Local Registry” for more information about backup and restore and failure recovery.
2.8 ASM spfile
- ASM spfile location
Oracle建议把ASM SPFILE存放在磁盘组上。你不能给已经存在的ASM SPFILE创建别名。
如果你没有用共享的Oracle grid家目录,Oracle ASM实例会使用PFILE。相同规则的文件名,默认位置,和查找用来适用于数据库初始化参数的文件和也适用于ASM的初始化参数文件。
ASM查找参数参数文件的顺序是:
- 在GPnP配置文件里指定的初始化参数文件的位置。
- 如果GPnP配置文件没有指定位置,查找顺序改变为:
- 在ASM实例的家目录下的SPFILE
例如:在Linux环境下,SPFILE的默认路径是在Oracle grid的家目录下:
$ORACLE_HOME/dbs/spfile+ASM.ora
- 在ASM实例的家目录下的PFILE
Backing Up, Moving a ASM spfile
你可以备份,复制,或移动ASM SPFILE 用ASMCMD的spbackup,spcopy或spmove命令。关于ASMCMD的命令参见Oracle Database Storage Administrator’s Guide。
参见:Oracle Database Storage Administrator’s Guide “Configuring Initialization Parameters for an Oracle ASM Instance” for more information.
3. Resources
Oracle 集群管理应用和进程是通过管理你在集群里注册的资源。你在集群里注册的资源数量取决于你的应用。应用只由一个进程组成,通常就只有一个资源。有些复制的应用,由多个进程或组件组成,可能需要多个资源。
3.1 资源类型
通常,所有的资源是唯一的但是有些资源可能有共同的属性。Oracle集群用资源类型来组织这些相似的资源。用资源类型有这些好处:
- 管理只需要资源的属性Manage only necessary resource attributes
- 管理所有的资源基于资源类型Manage all resources based on the resource type
每个在Oracle集群注册的资源都要有一个指定的资源类型。除了在Oracle集群中的资源类型,可以用crsctl工具自定义资源类型。资源类型包括:
- 基础资源:基础类型
- 本地资源:集群里的每个服务器上实例的本地资源(类型名是local_resource) 例如 node14.vip 。
- 集群资源:集群资源类型(类型名是cluster_resours)are aware of the cluster environment and are subject to cardinality and cross-server switchover and failover; 例如: asm.
所有用户定义的资源类型必须是基础的,直接的或间接的,为local_resource类型或cluster_resource类型。
执行crsctl stat type命令可以列出说有的定义的类型:
TYPE_NAME=application
BASE_TYPE=cluster_resource
TYPE_NAME=cluster_resource
BASE_TYPE=resource
TYPE_NAME=local_resource
BASE_TYPE=resource
TYPE_NAME=ora.asm.type
BASE_TYPE=ora.local_resource.type
TYPE_NAME=ora.cluster_resource.type
BASE_TYPE=cluster_resource
TYPE_NAME=ora.cluster_vip.type
BASE_TYPE=ora.cluster_resource.type
TYPE_NAME=ora.cluster_vip_net1.type
BASE_TYPE=ora.cluster_vip.type
TYPE_NAME=ora.database.type
BASE_TYPE=ora.cluster_resource.type
TYPE_NAME=ora.diskgroup.type
BASE_TYPE=ora.local_resource.type
TYPE_NAME=ora.eons.type
BASE_TYPE=ora.local_resource.type
TYPE_NAME=ora.gns.type
BASE_TYPE=ora.cluster_resource.type
TYPE_NAME=ora.gns_vip.type
BASE_TYPE=ora.cluster_vip.type
TYPE_NAME=ora.gsd.type
BASE_TYPE=ora.local_resource.type
TYPE_NAME=ora.listener.type
BASE_TYPE=ora.local_resource.type
TYPE_NAME=ora.local_resource.type
BASE_TYPE=local_resource
TYPE_NAME=ora.network.type
BASE_TYPE=ora.local_resource.type
TYPE_NAME=ora.oc4j.type
BASE_TYPE=ora.cluster_resource.type
TYPE_NAME=ora.ons.type
BASE_TYPE=ora.local_resource.type
TYPE_NAME=ora.registry.acfs.type
BASE_TYPE=ora.local_resource.type
TYPE_NAME=ora.scan_listener.type
BASE_TYPE=ora.cluster_resource.type
TYPE_NAME=ora.scan_vip.type
BASE_TYPE=ora.cluster_vip.type
TYPE_NAME=resource
BASE_TYPE=
列出类型的所有属性和默认值,执行crsctl stat type <typeName> -f (for full configuration) or –p (for static configuration)。
- Base Resource Type Definition
这节说明组成资源类型定义的属性。一个资源类型的定义是抽象的和只读的。这些类型可能只是当做其他类型的基础。在11.2.0.1的集群不允许直接拓展用户定义的类型。
查看所有的基础资源类型的名称和默认值,运行crsctl stat type resource –p命令。
| Name | History | Description |
| NAME | From 10gR2 | The name of the resource. Resource names must be unique and may not be modified once the resource is created. |
| TYPE | From 10gR2,
modified |
Semantics are unchanged; values other than application exist
Type: string Special Values: No |
| CHECK_INTERVAL | From 10gR2 | Unchanged
Type: unsigned integer Special Values: No Per-X Support: Yes |
| DESCRIPTION | From 10gR2 | Unchanged Type: string
Special Values: No |
| RESTART_ATTEMPTS | From 10gR2 | Unchanged
Type: unsigned integer Special Values: No Per-X Support: Yes |
| START_TIMEOUT | From 10gR2 | Unchanged
Type: unsigned integer Special Values: No Per-X Support: Yes |
| STOP_TIMEOUT | From 10gR2 | Unchanged
Type: unsigned integer Special Values: No Per-X Support: Yes |
| SCRIPT_TIMEOUT | From 10gR2 | Unchanged
Type: unsigned integer Special Values: No Per-X Support: Yes |
| UPTIME_THRESHOLD | From 10gR2 | Unchanged Type: string
Special Values: No Per-X Support: Yes |
| AUTO_START | From 10gR2 | Unchanged Type: string
Format: restore|never|always Required: No Default: restore Special Values: No |
| BASE_TYPE | New | The name of the base type from which this type extends. This is the value of the “TYPE” in the base type’s profile.
Type: string Format: [name of the base type] Required: Yes Default: empty string (none) Special Values: No Per-X Support: No |
| DEGREE | New | This is the count of the number of instances of the resource that are allowed to run on a single server. Today’s application has a fixed degree of one. Degree supports multiplicity within a server
Type: unsigned integer Format: [number of attempts, >=1] Required: No Default: 1 Special Values: No |
| ENABLED | New | The flag that governs the state of the resource as far as being managed by Oracle Clusterware, which will not attempt to manage a disabled resource whether directly or because of a dependency to another resource. However, stopping of the resource when requested by the administrator will be allowed
(so as to make it possible to disable a resource without having to stop it). Additionally, any change to the resource’s state performed by an ‘outside force’ will still be proxied into the clusterware. Type: unsigned integer Format: 1 | 0 Required: No Default: 1 Special Values: No Per-X Support: Yes |
| START_DEPENDENCIES | New | Specifies a set of relationships that govern the start of the resource.
Type: string Required: No Default: Special Values: No |
| STOP_DEPENDENCIES | New | Specifies a set of relationships that govern the stop of the resource.
Type: string Required: No Default: Special Values: No |
| AGENT_FILENAME | New | An absolute filename (that is, inclusive of the path and file name) of the agent program that handles this type. Every resource type must have an agent program that handles its resources. Types can do so by either specifying the value for this attribute or inheriting it from their base type.
Type: string Required: Yes Special Values: Yes Per-X Support: Yes (per-server only) |
| ACTION_SCRIPT | From 10gR2,
modified |
An absolute filename (that is, inclusive of the path and file name) of the action script file. This attribute is used in conjunction with the AGENT_FILENAME. CRSD will invoke the script in the manner it did in 10g for all entry points (operations) not implemented in the agent binary. That is, if the agent program implements a particular entry point, it is invoked; if it does not, the script specified in this attribute will be executed.
Please note that for backwards compatibility with previous releases, a built-in agent for the application type will be included with CRS. This agent is implemented to always invoke the script specified with this attribute. Type: string Required: No Default: Special Values: Yes Per-X Support: Yes (per-server only) |
| ACL | New | Contains permission attributes. The value is populated at resource creation time based on the identity of the process creating the resource, unless explicitly overridden. The value can subsequently be changed using the APIs/command line utilities, provided that such a change is allowed based on the existing permissions of the resource.
Format:owner:<user>:rwx,pgrp:<group>:rwx,other::r— Where owner: the OS User of the resource owner, followed by the permissions that the owner has. Resource actions will be executed as with this user ID. pgrp: the OS Group that is the resource’s primary group, followed by the permissions that members of the group have other: followed by permissions that others have Type: string Required: No Special Values: No |
| STATE_CHANGE_EVENT_TEM PLATE | New | The template for the State Change events. Type: string Required: No
Default: Special Values: No |
| PROFILE_CHANGE_EVENT_TE MPLATE | New | The template for the Profile Change events. Type: string Required: No
Default: Special Values: No |
| ACTION_FAILURE_EVENT_TE MPLATE | New | The template for the State Change events.
Type: string Required: No Default: Special Values: No |
| LAST_SERVER | New | An internally managed, read-only attribute that contains the name of the server on which the last start action has succeeded.
Type: string Required: No, read-only Default: empty Special Values: No |
| OFFLINE_CHECK_INTERVAL | New | Used for controlling off-line monitoring of a resource. The value represents the interval (in seconds) to use for implicitly monitoring the resource when it is OFFLINE. The monitoring is turned off if the value is 0
Type: unsigned integer Required: No Default: 0 Special Values: No Per-X Support: Yes |
| STATE_DETAILS | New | An internally managed, read-only attribute that contains details about the state of the resource. The attribute fulfills the following needs:
1. CRSD understood resource states (Online, Offline, Intermediate, etc) may map to different resource-specific values (mounted, unmounted, open, closed, etc). In order to provide a better description of this mapping, resource agent developers may choose to provide a ‘state label’ as part of providing the value of the STATE. 2. Providing the label, unlike the value of the resource state, is optional. If not provided, the Policy Engine will use CRSD- understood state values (Online, Offline, etc). Additionally, in the event the agent is unable to provide the label (as may also happen to the value of STATE), the Policy Engine will set the value of this attribute to do it is best at providing the details as to why the resource is in the state it is (why it is Intermediate and/or why it is Unknown) Type: string Required: No, read-only Default: empty Special Values: No |
- Local Resource Type Definition
The local_resource type is the basic building block for resources that are instantiated for each server but are cluster oblivious and have a locally visible state. While the definition of the type is global to the clusterware, the exact property values of the resource instantiation on a particular server are stored on that server. This resource type has no equivalent in Oracle Clusterware 10gR2 and is a totally new concept to Oracle Clusterware.
The following table specifies the attributes that make up the local_resource type definition. To see all default values run the command crsctl stat type local_resource –p.
| Name | Description |
| ALIAS_NAME | Type: string Required: No Special Values: Yes Per-X Support: No |
| LAST_SERVER | Overridden from resource: the name of the server to which the
resource is assigned (“pinned”).
|
Only Cluster Administrators will be allowed to register local resources.
- Cluster Resource Type Definition
The cluster_resource is the basic building block for resources that are cluster aware and have globally visible state. 11.1‘s application is a cluster_resource. The type’s base is resource. The type definition is read-only. The following table specifies the attributes that make up the cluster_resource type definition.
The following table specifies the attributes that make up the cluster_resource type definition. Run crsctl stat type cluster_resource –p to see all default values.
| Name | History | Description |
| ACTIVE_PLACEMENT | From 10gR2 | Unchanged
Type: unsigned integer Special Values: No |
| FAILOVER_DELAY | From 10gR2 | Unchanged, Deprecated Special Values: No |
| FAILURE_INTERVAL | From 10gR2 | Unchanged
Type: unsigned integer Special Values: No Per-X Support: Yes |
| FAILURE_THRESHOLD | From 10gR2 | Unchanged
Type: unsigned integer Special Values: No Per-X Support: Yes |
| PLACEMENT | From 10gR2 | Format: value
where value is one of the following: restricted Only servers that belong to the associated server pool(s) or hosting members may host instances of the resource. favored If only SERVER_POOLS or HOSTING_MEMBERS attribute is non-empty, servers belonging to the specified server pool(s)/hosting member list will be considered first if available; if/when none are available, any other server will be used. If both SERVER_POOLS and HOSTING_MEMBERS are populated, the former indicates preference while the latter – restricts the choices to the servers within that preference balanced Any ONLINE, enabled server may be used for placement. Less loaded servers will be preferred to more loaded ones. To measure how loaded a server is, clusterware will use the LOAD attribute of resources that are ONLINE on the server. The sum total of LOAD values is used as the absolute measure of the current server load. Type: string Default: balanced Special Values: No |
| HOSTING_MEMBERS | From 10g | The meaning from this attribute is taken from the previous release.
Although not officially deprecated, the use of this attribute is discouraged. Special Values: No Required: @see SERVER_POOLS
|
| SERVER_POOLS | New | Format:
* | [<pool name1> […]] This attribute creates an affinity between the resource and one or more server pools as far as placement goes. The meaning of this attribute depends on what the value of PLACEMENT is. When a resource should be able to run on any server of the cluster, a special value of * needs to be used. Note that only Cluster Administrators can specify * as the value for this attribute. Required: restricted PLACEMENT requires either SERVER_POOLS or HOSTING_MEMBERS favored PLACEMENT requires either SERVER_POOLS or HOSTING_MEMBERS but allows both. Balanced PLACEMENT does not require a value Type: string Default: * Special Values: No |
| CARDINALITY | New | The count of the number of servers on which a resource wants to be running simultaneously. In other words, this is the ‘upper’ limit for resource cardinality. There’s currently no support for the ‘lower’ cardinality limit.
Please note CRS special values may be used for specifying values of this attribute. Type: string Format: max Required: No Default: 1 Special Values: Yes |
| LOAD | New | A non-negative, numeric value designed to represent a quantitative measure of how much server capacity an instance of the resource consumes. The value of this parameter is interpreted in conjunction with that of the PLACEMENT attribute. For balanced placement policy, the value of this attribute place a role in determining where the resource is best placed. This value is an improvement to the original behavior of the balanced placement policy which assumed that the load of every resource is a constant and equal number (1).
Type: unsigned integer Format: non-negative number Required: No Default:1 Special Values: No Per-X Support: Yes |
3.2 资源依赖性
With Oracle Clusterware 11.2 a new dependency concept is introduced, to be able to build dependencies for start and stop actions independent and have a much better granularity.
- Hard Dependency
If resource A has a hard dependency on resource B, B must be ONLINE before A will be started. Please note there is no requirement that A and B be located on the same server.
A possible parameter to this dependency would allow resource B to be in either in ONLINE or INTERMEDIATE state. Such a variation is sometimes referred to as the intermediate dependency.
Another possible parameter to this dependency would make it possible to differentiate if A requires that B be present on the same server or on any server in the cluster. In other words, this illustrates that the presence of resource B on the same server as A is a must for resource A to start.
If the dependency is on a resource type, as opposed to a concrete resource, this should be interpreted as “any resource of the type”. The aforementioned modifiers for locality/state still apply accordingly.
- Weak Dependency
If resource A has a weak dependency on resource B, an attempt to start of A will attempt to start B if is not ONLINE. The result of the attempt to start B is, however, of no consequence to the result of starting A (it is ignored). Additionally, if start of A causes an attempt to start B, failure to start A has no affect on B.
A possible parameter to this dependency is whether or not the start of A should wait for start of B to complete or may execute concurrently.
Another possible parameter to this dependency would make it possible to differentiate if A desires that B be running on the same server or on any server in the cluster. In other words, this illustrates that the presence of resource B on the same server as A is a desired for resource A to start. In addition to the desire to have the dependent resource started locally or on any server in the cluster, another possible parameter is to start the dependent resource on every server where it can run。
If the dependency is on a resource type, as opposed to a concrete resource, this should be interpreted as “every resource of the type”. The aforementioned modifiers for locality/state still apply accordingly.
- Attraction
If resource A attracts B, then whenever B needs to be started, servers that currently have A running will be first on the list of placement candidates. Since a resource may have more than one resource to which it is attracted, the number of attraction-exhibiting resources will govern the order of precedence as far as server placement goes.
If the dependency is on a resource type, as opposed to a concrete resource, this should be interpreted as “any resource of the type”.
A possible flavor of this relation is to require that a resource’s placement be re-evaluated when a related resource’s state changes. For example, resource A is attracted to B and C. At the time of starting A, A is started where B is. Resource C may either be running or started thereafter. Resource B is subsequently shut down/fails and does not restart. Then resource A requires that at this moment its placement be re-evaluated and it be moved to C. This is somewhat similar to the AUTOSTART attribute of the resource profile, with the dependent resource’s state change acting as a trigger as opposed to a server joining the cluster.
A possible parameter to this relation is whether or not resources in intermediate state should be counted as running thus exhibit attraction or not.
If resource A excludes resource B, this means that starting resource A on a server where B is running will be impossible. However, please see the dependency’s namesake for STOP to find out how B may be stopped/relocated so A may start.
- Pull-up
If a resource A needs to be auto-started whenever resource B is started, this dependency is used. Note that the dependency will only affect A if it is not already running. As is the case for other dependency types, pull-up may cause the dependent resource to start on any or the same server, which is parameterized. Another possible parameter to this dependency would allow resource B to go to either in ONLINE or INTERMEDIATE state to trigger pull-up of A. Such a variation is sometimes referred to as the intermediate dependency. Note that if resource A has pull-up relation to resources B and C, then it will only be pulled up when both B and C are started. In other words, the meaning of resources mentioned in the pull-up specification is interpreted as a Boolean AND.
Another variation in this dependency is if the value of the TARGET of resource A plays a role: in some cases, a resource needs to be pulled-up irrespective of its TARGET while in others only if the value of TARGET is ONLINE. To accommodate both needs, the relation offers a modifier to let users specify if the value of the TARGET is irrelevant; by default, pull-up will only start resources if their TARGET is ONLINE. Note that this modifier is on the relation, not on any of the targets as it applies to the entire relation.
If the dependency is on a resource type, as opposed to a concrete resource, this should be interpreted as “any resource of the type”. The aforementioned modifiers for locality/state still apply accordingly.
- Dispersion
The property between two resources that desire to avoid being co-located, if there’s no alternative other than one of them being stopped, is described by the use of the dispersion relation. In other words, if resource A prefers to run on a different server than the one occupied by resource B, then resource A is said to have a dispersion relation to resource B at start time. This sort of relation between resources has an advisory effect, much like that of attraction: it is not binding as the two resources may still end up on the same server.
A special variation on this relation is whether or not crsd is allowed/expected to disperse resources, once it is possible, that are already running. In other words, normally, crsd will not disperse co-located resources when, for example, a new server becomes online: it will not actively relocate resources once they are running, only disperse them when starting them. However, if the dispersion is ‘active’, then crsd will try to relocate one of the resources that disperse to the newly available server.
A possible parameter to this relation is whether or not resources in intermediate state should be counted as running thus exhibit attraction or not.
4. Fast Application Notification (FAN)
- Event Sources
在11.2,CRSD所有者组织了大量的事件,RLB事件是来源于数据库。如果eONS 没有在运行,ReporterModule尝试缓存事件直到eONS启动。事件确保发送和接收发生动作发生的顺序。
- Event Processing architecture in oraagent
- database / ONS / eONS agents
每个节点在crsd的oraagent进程里运行一个数据库代理,一个ONS代理,和一个eONS代理。这些代理复制停止/启动/检查操作。每一个代理不是用专用的线程,用一个线程池来执行多种资源的操作。
- eONS subscriber threads
在oraagent日志里,可以通过字符串”Thread:[EonsSub ONS]”, “Thread:[EonsSub EONS]” 和”Thread:[EonsSub FAN]”辨识出eONS subscriber线程。在下面的例子中,一个服务已经停止,这个节点的crsd oraagent程序和三个eONS会受到这个事件:
2009-05-26 23:36:40.479: [AGENTUSR][2868419488][UNKNOWN] Thread:[EonsSub FAN]
process {
2009-05-26 23:36:40.500: [AGENTUSR][2868419488][UNKNOWN] Thread:[EonsSub FAN]
process }
2009-05-26 23:36:40.540: [AGENTUSR][2934963104][UNKNOWN] Thread:[EonsSub ONS]
process }
2009-05-26 23:36:40.558: [AGENTUSR][2934963104][UNKNOWN] Thread:[EonsSub ONS]
process {
2009-05-26 23:36:40.563: [AGENTUSR][2924329888][UNKNOWN] Thread:[EonsSub EONS]
process {
2009-05-26 23:36:40.564: [AGENTUSR][2924329888][UNKNOWN] Thread:[EonsSub EONS]
process }
- Event Publishers/processors in general
On one node of the cluster, the eONS subscriber of the following agents also assumes the role of a publisher or processor or master (pick your favorite terminology):
- One dbagent’s eONS subscriber assumes the role “CLSN.FAN.pommi.FANPROC”; this subscriber is responsible for publishing ONS events (FAN events) to the HA alerts queue for database ‘pommi’. There is one FAN publisher per database in the
- One onsagent’s eONS subscriber assumes the role “CLSN.ONS.ONSPROC”, publisher for ONS events; this subscriber is responsible for sending eONS events to ONS clients.
- Each eonsagent’s eONS subscriber on every node publishes eONS events as user callouts. There is no single eONS publisher in the cluster. User callouts are no longer produced by
The publishers/processors can be identified by searching for “got lock”:
staiu01/agent/crsd/oraagent_spommere/oraagent_spommere.l01:2009-05-26 19:51:41.549: [AGENTUSR][2934959008][UNKNOWN] CssLock::tryLock, got lock CLSN.ONS.ONSPROC
staiu02/agent/crsd/oraagent_spommere/oraagent_spommere.l01:2009-05-26 19:51:41.626: [AGENTUSR][3992972192][UNKNOWN] CssLock::tryLock, got lock CLSN.ONS.ONSNETPROC
staiu03/agent/crsd/oraagent_spommere/oraagent_spommere.l01:2009-05-26 20:00:21.214: [AGENTUSR][2856319904][UNKNOWN] CssLock::tryLock, got lock
CLSN.RLB.pommi
staiu02/agent/crsd/oraagent_spommere/oraagent_spommere.l01:2009-05-26 20:00:27.108: [AGENTUSR][3926576032][UNKNOWN] CssLock::tryLock, got lock CLSN.FAN.pommi.FANPROC
These CSS-based locks work in such a way that any node can grab the lock if it is not already held. If the process of the lock holder goes away, or CSS thinks the node went away, the lock is released and someone else tries to get the lock. The different processors try to grab the lock whenever they see an event. If a processor previously was holding the lock, it doesn’t have to acquire it again. There is currently no implementation of a “backup” or designated failover-publisher.
- ONSNETPROC
In a cluster of 2 or more nodes, one onsagent’s eONS subscriber will also assume the role of CLSN.ONS.ONSNETPROC, i.e. is responsible for just publishing network down events. The publishers with the roles of CLSN.ONS.ONSPROC and CLSN.ONS.ONSNETPROC cannot and will not run on the same node, i.e. they must run on distinct nodes.
If both the CLSN.ONS.ONSPROC and CLSN.ONS.ONSNETPROC simultaneously get their public network interface pulled down, there may not be any event.
- RLB publisher
Another additional thread tied to the dbagent thread in the oraagent process of only one node in the cluster, is ” Thread:[RLB:dbname]”, and it dequeues the LBA/RLB/affinity event from the SYS$SERVICE_METRICS queue, and publishes the event to eONS clients. It assumes the lock role of CLSN.RLB.dbname. The CLSN.RLB.dbname publisher can run on any node, and is not related to the location of the MMON master (who enqueues LBA events into the SYS$SERVICE_METRICS queue. So since the RLB publisher (RLB.dbname) can run on a different node than the ONS publisher (ONSPROC), RLB events can be dequeued on one node, and published to ONS on another node. There is one RLB publisher per database in the cluster
Sample trace, where Node 3 is the RLB publisher, and Node 2 has the ONSPROC role:
– Node 3:
2009-05-28 19:29:10.754: [AGENTUSR][2857368480][UNKNOWN]
Thread:[RLB:pommi] publishing message srvname = rlb
2009-05-28 19:29:10.754: [AGENTUSR][2857368480][UNKNOWN]
Thread:[RLB:pommi] publishing message payload = VERSION=1.0 database=pommi service=rlb { {instance=pommi_3 percent=25 flag=UNKNOWN aff=FALSE}{instance=pommi_4 percent=25 flag=UNKNOWN aff=FALSE}{instance=pommi_2 percent=25 flag=UNKNOWN aff=FALSE}{instance=pommi_1 percent=25 flag=UNKNOWN aff=FALSE} } timestamp=2009-05-28 19:29:10
The RLB events will be received by the eONS subscriber of the ONS publisher (ONSPROC) who then posts the event to ONS:
– Node 2:
2009-05-28 19:29:40.773: [AGENTUSR][3992976288][UNKNOWN] Publishing the
ONS event type database/event/servicemetrics/rlb
- Example
- Node 1
- assumes role of FAN/AQ publisher CLSN.FAN.dbname.FANPROC, enqueues HA events into HA alerts queue
- assumes role of eONS publisher to generate user callouts MMON enqueues RLB events into SYS$SERVICE_METRICS queue
- Node 2
- assumes role of ONS publisher CLSN.ONS.ONSPROC to publish ONS and RLB events to ONS subscribers (listener, JDBC ICC/UCP)
- assumes role of eONS publisher to generate user callouts
- Node 3
- assumes role of ONSNET publisher CLSN.ONS.ONSNETPROC to publish ONS events to ONS subscribers (listener, JDBC ICC/UCP)
- assumes role of eONS publisher to generate user callouts
- Node 4
- assumes role of RLB publisher CLSN.RLB.dbname, dequeues RLB events from SYS$SERVICE_METRICS queue and posts them to eONS
- assumes role of eONS publisher to generate user callouts
- Coming up in 2.0.2
The above description is only valid for 11.2.0.1. In 11.2.0.2, the eONS proxy a.k.a eONS server will be removed, and its functionality will be assumed by evmd. In addition, the tracing as described above, will change significantly. The major reason for this change was the high resource usage of the eONS JVM.
In order to find the publishers in the oraagent.log in 11.2.0.2, search for these patterns:
“ONS.ONSNETPROC CssLockMM::tryMaster I am the master” “ONS.ONSPROC CssLockMM::tryMaster I am the master” “FAN.<dbname> CssLockMM::tryMaster I am the master” “RLB.<dbname> CssSemMM::tryMaster I am the master”
5. Configuration best practices
- Cluster interconnect
Oracle不建议为集群件和RAC配置单独的接口。如果配置多个私有接口我们建议绑定成一个单独的接口,为了给网卡故障提供冗余。除非绑定,多个私有接口只是提供负载均衡,不能故障转移。
改变接口名字的后果取决于你改变了那个接口的名字和你是否也改变了IP地址。如果你只是改变了接口名字,那么后果是次要的。如果你改变的是公共接口的名字存储在OCR中,那么你必须在每个节点上修改应用。因此,你要停掉节点上的应用来进行修改。
可以用oifcfg delif / setif修改集群的网络互连,也可以修改集群的私有网络互连,在集群件重启时生效。
Oracle RAC网络互连必须用相同的接口。不要配置私有的网络互连在集群件上没有定义的不同接口。
参见: Oracle Clusterware Administration and Deployment Guide, “Changing Network Addresses on Manually Configured Networks” for more information.
- misscount
misscount的值很重要,Oracle不支持修改misscount得默认值。可以通过下面命令获取misscount的值:
# crsctl get css misscount
CRS-4678: Successful get misscount 30 for Cluster Synchronization Services.
第三方集群软件misscount的默认值是600,是为了给第三方软件提供更多的时间来做节点的加入/删除的决定。不要修改第三方集群软件的misscount默认设置.
6 Clusterware Diagnostics and Debugging
6.1 Check Cluster Health
当一个集群成功安装或者一个节点启动了,那么就可以检查整个集群或者一个节点的健康了。
本地节点的OHASD已经启动和如果守护进程是健康运行的,就可以进行‘crsctl check has’检查。
# crsctl check has
CRS-4638: Oracle High Availability Services is online
‘crsctl check crs’可以检查OHASD,CRSD,OCSSD和EVM守护进程。
# crsctl check crs
CRS-4638: Oracle High Availability Services is online CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online CRS-4533: Event Manager is online
‘crsctl check cluster –all’将检查集群里所有节点的所有守护进程
# crsctl check cluster –all
************************************************************** node1:
CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online CRS-4533: Event Manager is online
************************************************************** node2:
CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online CRS-4533: Event Manager is online
**************************************************************
在用crsctl start cluster命令启动集群时,监控输出,尝试启动所有资源应该是成功的,如果有资源启动失败,到相应的日志里查找错误信息。
# crsctl start cluster
CRS-2672: Attempting to start ‘ora.cssdmonitor’ on ‘node1’
CRS-2676: Start of ‘ora.cssdmonitor’ on ‘node1’ succeeded
CRS-2672: Attempting to start ‘ora.cssd’ on ‘node1’
CRS-2672: Attempting to start ‘ora.diskmon’ on ‘node1’
CRS-2676: Start of ‘ora.diskmon’ on ‘node1’ succeeded
CRS-2676: Start of ‘ora.cssd’ on ‘node1’ succeeded
CRS-2672: Attempting to start ‘ora.ctssd’ on ‘node1’
CRS-2676: Start of ‘ora.ctssd’ on ‘node1’ succeeded
CRS-2672: Attempting to start ‘ora.evmd’ on ‘node1’
CRS-2672: Attempting to start ‘ora.asm’ on ‘node1’
CRS-2676: Start of ‘ora.evmd’ on ‘node1’ succeeded
CRS-2676: Start of ‘ora.asm’ on ‘node1’ succeeded
CRS-2672: Attempting to start ‘ora.crsd’ on ‘node1’
CRS-2676: Start of ‘ora.crsd’ on ‘node1’ succeeded
6.2 crsctl command line tool
Oracle 集群管理工具有命令可以用来管理集群框架下的所有实体。包括集群的守护进程,钱夹管理在集群的所有节点上。
你可以用CRSCTL命令在集群上进行一些炒作,比如:
- 启动和停止集群资源
- 启动和停止集群守护进程
- 检查集群的监控状态
- 代表第三方应用管理资源
- 整合集群的智能平台管理接口(IPMI),提供故障隔离支持和集群完整性。
- 调试Oracle集群组件
几乎所有的操作都是这个集群范围的。
参见:Oracle Clusterware Administration and Deployment Guide, “CRSCTL Utility Reference” for more information about using crsctl.
可以在root用户下用crsctl set log命令启动动态调试CRS,CSS,EVM和集群的子构件。你可以动态修改调试级别用crsctl debug命令。调试信息保存在OCR中,在下次启动时使用。你可以始终开启资源调试。
调试性能和选项的完整列表在“Oracle Clusterware Administration and Deployment Guide”的“Troubleshooting and Diagnostic Output”章节里有列出。
6.3 Trace File Infrastructure and Location
Oracle集群用统一的日志目录结构来合并组件的日志文件。这种合并结构简化了诊断信息的收集和在分析问题时提供帮助。
Oracle集群在日志文件里使用循环的方法。如果你不能在文件里找到指定的告警细节信息,那么这个文件可能被循环成一个循环版本,典型的结尾是 *.lnumber,这个数字从01开始,产生更多的日志时这个数字会增长,总是能够不同的日志对应于不同的日志文件。一般不需要参考下面这些文件除非Oracle支持提出要求。你可以在文件里查看循环版本的日志文件。日志的保留策略,The log retention policy, however, foresees that older logs are be purged as required by the amount of logs generated
GRID_HOME/log/<host>/diskmon – Disk Monitor Daemon
GRID_HOME/log/<host>/client – OCRDUMP, OCRCHECK, OCRCONFIG, CRSCTL – edit the
GRID_HOME/srvm/admin/ocrlog.ini file to increase the trace level
GRID_HOME/log/<host>/admin – not used
GRID_HOME/log/<host>/ctssd – Cluster Time Synchronization Service
GRID_HOME/log/<host>/gipcd – Grid Interprocess Communication Daemon
GRID_HOME/log/<host>/ohasd – Oracle High Availability Services Daemon
GRID_HOME/log/<host>/crsd – Cluster Ready Services Daemon
GRID_HOME/log/<host>/gpnpd – Grid Plug and Play Daemon
GRID_HOME/log/<host>/mdnsd – Mulitcast Domain Name Service Daemon
GRID_HOME/log/<host>/evmd – Event Manager Daemon GRID_HOME/log/<host>/racg/racgmain – RAC RACG
GRID_HOME/log/<host>/racg/racgeut – RAC RACG GRID_HOME/log/<host>/racg/racgevtf – RAC RACG
GRID_HOME/log/<host>/racg – RAC RACG (only used if pre-11.1 database is installed)
GRID_HOME/log/<host>/cssd – Cluster Synchronization Service Daemon GRID_HOME/log/<host>/srvm – Server Manager
GRID_HOME/log/<host>/agent/ohasd/oraagent_oracle11 – HA Service Daemon Agent
GRID_HOME/log/<host>/agent/ohasd/oracssdagent_root – HA Service Daemon CSS Agent
GRID_HOME/log/<host>/agent/ohasd/oracssdmonitor_root – HA Service Daemon ocssdMonitor Agent
GRID_HOME/log/<host>/agent/ohasd/orarootagent_root – HA Service Daemon Oracle Root Agent
GRID_HOME/log/<host>/agent/crsd/oraagent_oracle11 – CRS Daemon Oracle Agent
GRID_HOME/log/<host>/agent/crsd/orarootagent_root – CRS Daemon Oracle Root Agent
GRID_HOME/log/<host>/agent/crsd/ora_oc4j_type_oracle11 – CRS Daemon OC4J Agent (11.2.0.2 feature and not used in 11.2.0.1)
GRID_HOME/log/<host>/gnsd – Grid Naming Services Daemon
6.4 Diagcollection
获取某个事件所有的相关的跟踪文件最好的路径是Grid_home/bin/diagcollection.pl。收集所有的trace和root用户在所有节点运行一个OCRDUMP命令“diagcollection.pl –collect –crshome <GRID_HOME>”。
# Grid_home/bin/diagcollection.pl
Production Copyright 2004, 2008, Oracle. All rights reserved Cluster Ready Services (CRS) diagnostic collection tool diagcollection
–collect
[–crs] For collecting crs diag information
[–adr] For collecting diag information for ADR [–ipd] For collecting IPD-OS data
[–all] Default.For collecting all diag information.
[–core] UNIX only. Package core files with CRS data
[–afterdate] UNIX only. Collects archives from the specified date. Specify in mm/dd/yyyy format
[–aftertime] Supported with -adr option. Collects archives after the specified time. Specify in YYYYMMDDHHMISS24 format
[–beforetime] Supported with -adr option. Collects archives before the specified date. Specify in YYYYMMDDHHMISS24 format
[–crshome] Argument that specifies the CRS Home location
[–incidenttime] Collects IPD data from the specified time.Specify in MM/DD/YYYY24HH:MM:SS format If not specified, IPD data generated in the past 2 hours are collected
[–incidentduration] Collects IPD data for the duration after the specified time. Specify in HH:MM format.If not specified, all IPD data after incidenttime are collected
NOTE:
- You can also do the following
./diagcollection.pl –collect –crs –crshome <CRS Home>
–clean cleans up the diagnosability information gathered by this script
–coreanalyze UNIX only. Extracts information from core files and stores it in a text file
更多的关于收集IPD的信息看6.4章节
如果是安装的供应商的集群软件,就需要给Oracle支持提供更多的关于集群的文件。
6.5 Alert Messages Using Diagnostic Record Unique IDs
从11.2开始。有些集群的信息里有用”(:” and “:)”用包含起来的文本。通常情况下,和下面的例子类似,这个标识符在文件中以”Details in…”开始和包含日志文件路径。这个标识符叫做DRUID或者诊断记录的唯一ID:
2009-07-16 00:18:44.472
[/scratch/11.2/grid/bin/orarootagent.bin(13098)]CRS-5822:Agent
‘/scratch/11.2/grid/bin/orarootagent_root’ disconnected from server.
Details at (:CRSAGF00117:) in
/scratch/11.2/grid/log/stnsp014/agent/crsd/orarootagent_root/orarootagent_root.log.
DRUID是用来关联外部产品信息和数据库集群的内部诊断日志文件。诊断问题时对用户没有直接帮助,主要是用来提供给Oracle支持人员。
6.6 OUI / SRVM / JAVA related GUI tracing
有一些基于Java的GUI工具在遇到问题时能够运行用来设置跟踪级别:
“setenv SRVM_TRACE true” (or “export SRVM_TRACE=true”)
“setenv SRVM_TRACE_LEVEL 2” (or “export SRVM_TRACE_LEVEL=2″)
在OUI安装出错时可用运行-debug选项(如安装时执行”./runInstaller -debug”
6.7 Reboot Advisory
集群在某种情况下,会重启一个节点来确保整个集群上的数据库和其他应用的健康运行。当决定重启问题节点时,普通的活动日志(比如集群的alert日志)就不可靠了:重启往往发生在操作系统刷写缓存日志到磁盘之前,这就意味着关于导致重启的原因可能丢失了。
在11.2集群里有个新特性叫Reboot Advisory,用来提高保留集群重启的说明内容。这时集群发生了重启,一个短的解释性消息会产生和试图在下面两种途径发布:
重启决策信息写到一个小文件里(通常在本地连接的存储),没有I/O缓存请求。这个文件在发生失败时(重启集群)被创建和提前格式化好的,因此I/O会有非常高的成功率,即使是在失败的系统。重启决策信息会被广播到可用的网络接口。
这些操作是并行的并有时间限制,因此不会对重启有延时。尝试多个磁盘和网络来获取这些信息,至少有一个会成功,往往是都成功的。成功的存储和发送Reboot Advisory信息,最后出现在集群的一个或多个节点上的alert日志里。
当网络广播Reboot Advisory信息成功后,在集群的其他节点的告警日志里就会出现相关的信息。这个事情是稍纵即逝的,因此立马就能看到和确定产生重启的原因。这些消息包含要进行重启节点的主机名用来区别集群里的其他节点。只是同一个集群里的失败节点会显示这些信息。
如果Reboot Advisory成功的吧信息写到一个磁盘文件里,在这个节点下次启动集群时,在告警日志的前面会产生相关的信息。
Reboot Advisory 有一个时间戳,3天内的启动都会扫描这些文件。这个扫描不能是空文件或被标记成已经公布了的文件,因此如果3天内在一个节点上多次重启,那么同一个Reboot Advisory会在告警日志里多次出现。
Reboot Advisories用相同的告警日志,一般有两个部分。一部分是CRS-8011,显示重启节点的主机名和时间戳(重启的大约时间点)。例如:
[ohasd(24687)]CRS-8011:reboot advisory message from host: sta00129, component: CSSMON, with timestamp: L-2009-05-05-10:03:25.340
在CRS-8011信息后面的是CRS-8013,表达了强制重启的信息,例如:
[ohasd(24687)]CRS-8013:reboot advisory message text: Rebooting after limit 28500 exceeded; disk timeout 27630, network timeout 28500, last heartbeat from ocssd at epoch seconds 1241543005.340, 4294967295 milliseconds ago based on invariant clock value of 93235653
请注意所有的在CRS-8013里“text”后面的集群组件的重启信息。这可能会产生重要的紧急信息,这些文本信息不是来自于Oracle的NLS信息文件,通常是用英语和USASCII7字符集。
在某些情况下,Reboot Advisories可能会在文本信息里添加二进制诊断数据。那么可能就会出现CRS-8014和一个或多个CRS-8015信息。这些二进制文件只要在重启问题报告给Oracle解决时有用。
不同的组件可以在同一时间往告警日志里写数据,因此关于Reboot Advisory的信息可能会出现在其他信息的中间。然而不同的Reboot Advisory参数的信息不会交叉在一起,一个Reboot Advisory产生的所有信息会在另一个Reboot Advisory产生的信息之前。
更多的信息,可以参照Oracle Errors manual discussion of messages CRS- 8011 and –8013。
7. Other Tools
7.1 ocrpatch
ocrpatch 开发于2005年,是为了给开发和支持人员提供一个修复错误和修改OCR的工具,当官方的工具如ocrcofig或crsctl无法处理这些变化时。ocrpatch不是集群版本的一部分。ocrpathd的功能描述在单独的文档里,因此在这里我们不会深入细节,ocrpatch文档的位置在stcontent的public RAC Performance Group Folder 里。
7.2 vdpatch
介绍
vdpatch是一个适用于11.2集群的新的Oracle内部工具。vdpatch和ocrpatch有很多相同的代码,比如look和feel就很像。这个工具的目的是便于诊断CSS关于投票文件连接的问题。vdpatch是基于每个块的操作,例如,它可以从投票文件通过块数目或者名字读取(不是写)512字节块。
一般用法
vdpatch只能root用户运行,其他用户会受到报错:
$ vdpatch
VD Patch Tool Version 11.2 (20090724) Oracle Clusterware Release 11.2.0.2.0
Copyright (c) 2008, 2009, Oracle. All rights reserved. [FATAL] not privileged
[OK] Exiting due to fatal error …
投票文件的名字和路径可以通过’crsctl query css votedisk’命令获取。这个命令只能是OCSSD是运行状态下执行。如果OCSSD没有启动,crsct将没有信号
# crsctl query css votedisk
Unable to communicate with the Cluster Synchronization Services daemon.
如果OCSSD是运行的,你能收到下面的输出:
$ crsctl query css votedisk
## STATE File Universal Id File Name Disk group
— —– —————– ——— ———
- ONLINE 0909c24b14da4f89bfbaf025cd228109 (/dev/raw/raw100) [VDDG]
- ONLINE 9c74b39a1cfd4f84bf27559638812106 (/dev/raw/raw104) [VDDG]
- ONLINE 1bb06db216434fadbfa3336b720da252 (/dev/raw/raw108) [VDDG]
Located 3 voting file(s).
上面的输出表明定义了三个投票文件在磁盘组+VDDG上面,每个位于特定的裸设备上,属于哪个ASM磁盘组。vdpatch可以每次只查看一个设备的内容:
# vdpatch
VD Patch Tool Version 11.2 (20090724)
Oracle Clusterware Release 11.2.0.2.0
Copyright (c) 2008, 2009, Oracle. All rights reserved.
vdpatch> op /dev/raw/raw100
[OK] Opened /dev/raw/raw100, type: ASM
如果投票文件在裸设备上,crsctl和vdpatch可以显示:
- ONLINE 9f862a63239b4f52bfdbce6d262dc349 (/dev/raw/raw134) [] Located 3 voting file(s).
# vdpatch
VD Patch Tool Version 11.2 (20090724) Oracle Clusterware Release 11.2.0.2.0
Copyright (c) 2008, 2009, Oracle. All rights reserved. vdpatch> op /dev/raw/raw126
[OK] Opened /dev/raw/raw126, type: Raw/FS
要打开其他投票文件,简单的再运行’op’:
vdpatch> op /dev/raw/raw126
[OK] Opened /dev/raw/raw126, type: Raw/FS
vdpatch> op /dev/raw/raw130
[INFO] closing voting file /dev/raw/raw126
[OK] Opened /dev/raw/raw130, type: Raw/FS
用’h’命令,可以列出所有的可用命令:
vdpatch> h
Usage: vdpatch
BLOCK operations
op <path to voting file> open voting file
rb <block#> read block by block# rb status|kill|lease <index> read named block
index=[0..n] => Devenv nodes 1..(n-1) index=[1..n] => shiphome nodes 1..n
rb toc|info|op|ccin|pcin|limbo read named block
du dump native block from offset
di display interpreted block
of <offset> set offset in block, range 0-511 MISC operations
i show parameters, version, info
h this help screen
exit / quit exit vdpatch
- Common Use Case
投票文件块可以读块号和块类型名。TOC, INFO, OP, CCIN, PCIN 和 LIMBO类型只会出现在投票文件的块上,因此读一个块可以执行如’rb toc’; 将输出512比特块的十六进制/ASCII 的dump文件,解释块的内容:
vdpatch> rb toc [OK] Read block 4
[INFO] clssnmvtoc block
0 73734C63 6B636F54 01040000 00020000 00000000 ssLckcoT…………
20 00000000 40A00000 00020000 00000000 10000000 ….@……………
40 05000000 10000000 00020000 10020000 00020000 ………………..
…
…
420 00000000 00000000 00000000 00000000 00000000 ………………..
440 00000000 00000000 00000000 00000000 00000000 ………………..
460 00000000 00000000 00000000 00000000 00000000 ………………..
480 00000000 00000000 00000000 00000000 00000000 ………………..
500 00000000 00000000 00000000 …………
[OK] Displayed block 4 at offset 0, length 512 [INFO] clssnmvtoc block
magic1_clssnmvtoc: 0x634c7373 – 1665954675
magic2_clssnmvtoc: 0x546f636b – 1416586091
fmtvmaj_clssnmvtoc: 0x01 – 1
fmtvmin_clssnmvtoc: 0x04 – 4
resrvd_clssnmvtoc: 0x0000 – 0
maxnodes_clssnmvtoc: 0x00000200 – 512
incarn1_clssnmvtoc: 0x00000000 – 0
incarn2_clssnmvtoc: 0x00000000 – 0
filesz_clssnmvtoc: 0x0000a040 – 41024
blocksz_clssnmvtoc: 0x00000200 – 512
hdroff_clssnmvtoc: 0x00000000 – 0
hdrsz_clssnmvtoc: 0x00000010 – 16
opoff_clssnmvtoc: 0x00000005 – 5
statusoff_clssnmvtoc: 0x00000010 – 16
statussz_clssnmvtoc: 0x00000200 – 512
killoff_clssnmvtoc: 0x00000210 – 528
killsz_clssnmvtoc: 0x00000200 – 512
leaseoff_clssnmvtoc: 0x0410 – 1040
leasesz_clssnmvtoc: 0x0200 – 512
ccinoff_clssnmvtoc: 0x0006 – 6
pcinoff_clssnmvtoc: 0x0008 – 8
limbooff_clssnmvtoc: 0x000a – 10
volinfooff_clssnmvtoc: 0x0003 – 3
块类型STATUS, KILL 和LEASE,存在一个块在每个集群节点上,因此用’rb‘命令必须包括一个十六进制的数来表示节点号。在开发环境,十六进制从0开始,在生产环境,十六进制从1开始。因此要读开发环境下第五个节点的KILL块,执行’rb kill 4’,在生成环境就要执行’rb kill 5’。
在开发环境下读第三个节点的STATUS块:
vdpatch> rb status 2 [OK] Read block 18
[INFO] clssnmdsknodei vote block
0 65746F56 02000000 01040B02 00000000 73746169 etoV…………stai
20 75303300 00000000 00000000 00000000 00000000 u03……………..
40 00000000 00000000 00000000 00000000 00000000 ………………..
60 00000000 00000000 00000000 00000000 00000000 ………………..
80 00000000 3EC40609 8A340200 03000000 03030303 ….> 4……….
100 00000000 00000000 00000000 00000000 00000000 ………………..
120 00000000 00000000 00000000 00000000 00000000 ………………..
140 00000000 00000000 00000000 00000000 00000000 ………………..
160 00000000 00000000 00000000 00000000 00000000 ………………..
180 00000000 00000000 00000000 00000000 00000000 ………………..
200 00000000 00000000 00000000 00000000 00000000 ………………..
220 00000000 00000000 00000000 00000000 00000000 ………………..
240 00000000 00000000 00000000 00000000 00000000 ………………..
260 00000000 00000000 00000000 00000000 00000000 ………………..
280 00000000 00000000 00000000 00000000 00000000 ………………..
300 00000000 00000000 00000000 00000000 00000000 ………………..
320 00000000 00000000 00000000 00000000 00000000 ………………..
340 00000000 00000000 00000000 8E53DF4A ACE84A91 ………….S.J..J.
360 E4350200 00000000 03000000 441DDD4A 6051DF4A .5……….D..J`Q.J
380 00000000 00000000 00000000 00000000 00000000 ………………..
400 00000000 00000000 00000000 00000000 00000000 ………………..
420 00000000 00000000 00000000 00000000 00000000 ………………..
440 00000000 00000000 00000000 00000000 00000000 ………………..
460 00000000 00000000 00000000 00000000 00000000 ………………..
480 00000000 00000000 00000000 00000000 00000000 ………………..
500 00000000 00000000 00000000 …………
[OK] Displayed block 18 at offset 0, length 512
[INFO] clssnmdsknodei vote block
magic_clssnmdsknodei: 0x566f7465 – 1450144869
nodeNum_clssnmdsknodei: 0x00000002 – 2
fmtvmaj_clssnmdsknodei: 0x01 – 1
fmtvmin_clssnmdsknodei: 0x04 – 4
prodvmaj_clssnmdsknodei: 0x0b – 11
prodvmin_clssnmdsknodei: 0x02 – 2
killtime_clssnmdsknodei: 0x00000000 – 0
nodeName_clssnmdsknodei: staiu03
inSync_clssnmdsknodei: 0x00000000 – 0
reconfigGen_clssnmdsknodei: 0x0906c43e – 151438398
dskWrtCnt_clssnmdsknodei: 0x0002348a – 144522
nodeStatus_clssnmdsknodei: 0x00000003 – 3
nodeState_clssnmdsknodei[CLSSGC_MAX_NODES]:
node 0: 0x03 – 3 – MEMBER
node 1: 0x03 – 3 – MEMBER
node 2: 0x03 – 3 – MEMBER
node 3: 0x03 – 3 – MEMBER
timing_clssnmdsknodei.sts_clssnmTimingStmp: 0x4adf538e – 1256149902 – Wed Oct 21 11:31:42 2009
timing_clssnmdsknodei.stms_clssnmTimingStmp: 0x914ae8ac – 2437605548
timing_clssnmdsknodei.stc_clssnmTimingStmp: 0x000235e4 – 144868
timing_clssnmdsknodei.stsi_clssnmTimingStmp: 0x00000000 – 0
timing_clssnmdsknodei.flags_clssnmdsknodei: 0x00000003 – 3
unique_clssnmdsknodei.eptime_clssnmunique: 0x4add1d44 – 1256004932 – Mon Oct 19 19:15:32 2009
ccinid_clssnmdsknodei.cin_clssnmcinid: 0x4adf5160 – 1256149344 – Wed Oct 21 11:22:24 2009
ccinid_clssnmdsknodei.unique_clssnmcinid: 0x00000000 – 0
pcinid_clssnmdsknodei.cin_clssnmcinid: 0x00000000 – 0 – Wed Dec 31 16:00:00 1969
pcinid_clssnmdsknodei.unique_clssnmcinid: 0x00000000 – 0
我们不允许vdpatch计划改变投票文件。删除和重建投票文件建议用crsctl命令。
7.3 Appvipcfg – adding an application VIP
在11.2你可以通过Grid_home/bin/appvipcfg创建和删除应用或uservip
Production Copyright 2007, 2008, Oracle.All rights reserved Usage:
appvipcfg create -network=<network_number>
-ip=<ip_address>
-vipname=<vipname>
-user=<user_name>[-group=<group_name>]
delete -vipname=<vipname>
appvipcfg命令行工具在默认的网络上(默认创建的资源ora.net.network)只能创建一个应用VIP。如果要创建应用 VIP在不同的网络或子网上,必须进行手工配置。
例如创建一个uservip在一个不同的网络上(ora.net2.network)。
srvctl add vip -n node1 -k 2 -A appsvip1/255.255.252.0/eth2
crsctl add type coldfailover.vip.type -basetype ora.cluster_vip_net2.type
crsctl add resource coldfailover.vip -type coldfailover.vip.type -attr \
“DESCRIPTION=USRVIP_resource,RESTART_ATTEMPTS=0,START_TIMEOUT=0, STOP_TIMEOUT=0, \
CHECK_INTERVAL=10, USR_ORA_VIP=10.137.11.163, \
START_DEPENDENCIES=hard(ora.net2.network)pullup(ora.net2.network), \
STOP_DEPENDENCIES=hard(ora.net2.network), \
ACL=’owner:root:rwx,pgrp:root:r-x,other::r–,user:oracle11:r-x'”
这个区域,有一些已知的bug:
– 8623900 srvctl remove vip -i <ora.vipname> is removing the associated ora.netx.network
– 8620119 appvipcfg should be expanded to create a network resource
– 8632344 srvctl modify nodeapps -a will modify the vip even if the interface is not valid
– 8703112 appsvip should have the same behavior as ora.vip like vip failback
– 8758455 uservip start failed and orarootagent core dump in clsn_agent::agentassert
– 8761666 appsvipcfg should respect /etc/hosts entry for apps ip even if gns is configured
– 8820801 using a second network (k 2) I’m able to add and start the same ip twice
7.4 Application and Script Agent
应用程序或脚本代理通过特定的用户代码管理应用资源。Oracle集群件包含一个特殊的共享库,允许用户插入应用用定义好的接口进行制定的操作。
下面的章节介绍如何用Oracle的集群件代理框架接口创建一个代理。
- Action Entry Points
在一个资源上进行操作时,行动入口点用来指向用户定点的代码。每个资源类型,集群件要求行动入口点定义了下面的行动:
start : 启动资源的行动Actions to be taken to start the resource
stop : 关闭资源的温和的行动Actions to gracefully stop the resource
check : 检查资源状态的行动Actions taken to check the status of the resource
clean : 强制关闭资源的行动Actions to forcefully stop the resource.
这些行动入口点可以用C++ 代码来定义或在脚本里。如果这些行动没有明确的定义,集群件假定他们默认的定义在脚本里。这些脚本位置通过ACTION_SCRIPT属性。因此它可能是混合的代理,一些行动的图库点用脚本,其他的一些用C++。
- Sample Agents
考虑到集群件要管理资源的文件,一个代理管理这些资源有下面的任务:
On startup : 创建文件Create the file.
On shutdown : 温和的删除文件Gracefully delete the file.
On check command:检查是否存在改文件 Detect whether the file is present or not.
On clean command: 强制删除文件Forcefully delete the file.
为了描述Oracle集的这个特殊的资源,第一次创建一个专门的资源类型,它包含了所有该资源类的特征属性。在这种情况下,所描述的唯一的特殊属性是要监控的文件名。这可以用CRSCTL命令来完成。在定义的资源类型,我们也可以指定ACTION_SCRIPT和代理FILENAME属性。这些被用来指shell脚本和包含用于代理的动作的入口点的可执行文件。
一旦资源类型定义,完成所需的任务一个专门的代理有几种选择写-代理可以写成一个脚本,作为C / C ++程序或混合。
- Shell script agent
Grid_home/crs/demo/demo脚本文件是一个已经包含所有行动入口点和资源文件代理的shell 脚本。通过实现下面几步来测试这个脚本:
(1)启动集群件安装
(2)用crsctl工具添加一个新的资源类型
$ crsctl add type test_type1 -basetype cluster_resource -attr \
“ATTRIBUTE=PATH_NAME,TYPE=string,DEFAULT_VALUE=default.txt” -attr \
“ATTRIBUTE=ACTION_SCRIPT,TYPE=string,DEFAULT_VALUE=/path/to/demoActionScript”
适当的修改文件路劲,给集群件添加一个新的资源类型。在文本文件里会添加属性并当做一个参数传递给CRSCTL工具
(3)用CRSCTL工具添加新的资源到集群里。命令如下:
$ crsctl add resource r1 -type test_type1 -attr “PATH_NAME=/tmp/r1.txt”
$ crsctl add resource r2 -type test_type1 -attr “PATH_NAME=/tmp/r2.txt”
指定资源路径是必须的。
(4)用CRSCTL工具启动/停止资源
$ crsctl start res r1
$ crsctl start res r2
$ crsctl check res r1
$ crsctl stop res r2
- Option 2: C++ agent
在Grid_home/crs/demo目录下,Oracle提供了一个demoagent1.cpp。这是一个简单的C++程序,功能和上面的shell脚本类似。这个程序还监控本地机器上指定的文件。测试这个程序,执行下面的步骤:
(1)编译demoagent1.cpp和生成文件。
makefile文件需要根据当地的编译器/连接路径和安装位置进行修改。输出将是一个可执行命名demoagent1。
(2)启动集群件
(3)用crsctl工具添加一个新的资源类型
$ crsctl add type test_type1 -basetype cluster_resource -attr \
“ATTRIBUTE=PATH_NAME,TYPE=string,DEFAULT_VALUE=default.txt” -attr \
“ATTRIBUTE=ACTION_SCRIPT,TYPE=string,DEFAULT_VALUE=/path/to/demoActionScript”
适当的修改文件路劲,给集群件添加一个新的资源类型。在文本文件里会添加属性并当做一个参数传递给CRSCTL工具
(4)用CRSCTL工具添加新的资源到集群里。命令如下:
$ crsctl add resource r3 -type test_type1 -attr “PATH_NAME=/tmp/r1.txt”
$ crsctl add resource r4 -type test_type1 -attr “PATH_NAME=/tmp/r2.txt”
指定资源路径是必须的。
(5)用CRSCTL工具启动/停止资源
$ crsctl start res r3
$ crsctl start res r4
$ crsctl check res r3
$ crsctl stop res r4
- Option 3: Hybrid agent
在Grid_home/crs/demo目录下,Oracle提供了一个demoagent2.cpp。这是一个简单的C++程序,功能和上面的shell脚本类似。这个程序还监控本地机器上指定的文件。不过,这一方案只定义了检查行动的切入点 – 所有其他操作入口点没有定义,并从ACTION_SCRIPT属性被读取。测试这个程序,执行下面的步骤:
(1)编译demoagent2.cpp和生成文件。
makefile文件需要根据当地的编译器/连接路径和安装位置进行修改。输出将是一个可执行命名demoagent2。
(2)启动集群件
(3)用crsctl工具添加一个新的资源类型
$ crsctl add type test_type1 -basetype cluster_resource -attr \
“ATTRIBUTE=PATH_NAME,TYPE=string,DEFAULT_VALUE=default.txt” -attr \
“ATTRIBUTE=ACTION_SCRIPT,TYPE=string,DEFAULT_VALUE=/path/to/demoActionScript”
适当的修改文件路劲,给集群件添加一个新的资源类型。在文本文件里会添加属性并当做一个参数传递给CRSCTL工具
(4)用CRSCTL工具添加新的资源到集群里。命令如下:
$ crsctl add resource r5 -type test_type1 -attr “PATH_NAME=/tmp/r1.txt”
$ crsctl add resource r6 -type test_type1 -attr “PATH_NAME=/tmp/r2.txt”
指定资源路径是必须的。
(5)用CRSCTL工具启动/停止资源
$ crsctl start res r5
$ crsctl start res r6
$ crsctl check res r5
$ crsctl stop res r6
7.5 Oracle Cluster Health Monitor – OS Tool (IPD/OS)
Overview
此工具(以前称为瞬时问题检测工具)是用来检测和分析操作系统(OS)和集群资源相关的退化和失败,以带来更多的解释许多Oracle Clusterware和Oracle RAC的问题,如节点驱逐。
它连续不断地跟踪节点,进程和设备级操作系统资源的消耗。它收集并分析了集群范围内的数据。在实时模式下,达到临界值时,警报显示给操作者。分析根本原因,历史数据可以重现以了解在出现故障时发生了什么。这个工具安装非常简单,在zip文件里的README里有描述。最新的版本上传到OTN。下面的连接
http://www.oracle.com/technology/products/database/clustering/ipd_download_homepag e.html
- Install the Oracle Cluster Health Monitor
为了一个节点列表上安装该工具中,运行以下基本步骤(更详细的信息,请阅读REAMDE):
– 解压包
– 创建用户crfuser:oinstall在所有节点上
– 确保crfuser的家目录在所有节点上是相同的
– 设置crfuser密码在所有节点上
– 身份登录crfuser和运行crfinst.pl用适当的选项
– 要完成安装,以root身份登录,并安装的所有节点上运行crfinst.pl-f
– 在Linux上 CRF_home设置为/ usr / lib目录/ oracrf
- Running the OS Tool stack
这个OS工具必须通过/etc/init.d/init.crfd启动。此命令启动相应osysmond程序,衍生为ologgerd守护进程。该ologgerd然后挑选一个副本节点(如>=2个节点),并通知该节点启动相应osysmond程序,衍生为ologgerd守护进程。
这个OS工具堆栈可以在一个节点上关闭如下:
# /etc/init.d/init.crfd disable
- Overview of Monitoring Process (osysmond)
osysmond(每个节点上的一个收获进程)执行下面的操作来收集数据:
– 监控和定期采集系统指标
– 运行作为实时过程
– 违背了系统指标验证规则
– 基于阈值标记颜色编码的警报
– 将数据发送到主记录器守护进程
– 记录数据到本地磁盘失败的情况下发送
该osysmond将提醒对感知节点挂起(尽管有许多潜在的用户任务未充分利用的资源)
- CPU usage < 5%
- CPU Iowait > 50%
- MemFree < 25%
- # Disk IOs persec < 10% of max possible Disk IOs persec
- # bytes of outbound n/w traffic limited to data sent by SYSMOND
- # tasks node-wide > 1024
- CRFGUI
Oracle集群健康监控器附带有两个数据检索工具,一个是CRF GUI,这是主要的GUI显示。
crfgui连接到本地或远程主LOGGERD。它是自动检测LOGGERD集群内安装了图形用户界面,否则,群集节点必须在“-m”开关指定集群外运行。
该GUI提醒关键的资源使用率事件和感知系统挂起。启动它后,我们支持不同的GUI视图如集群视图,节点视图和设备视图。
Usage: crfgui [-m <node>] [-d <time>] [-r <sec>] [-h <sec>]
[-W <sec>] [-i] [-f <name>] [-D <int>]
-m <node> Name of the master node (tmp)
-d <time> Delayed at a past time point
-r <sec> Refresh rate
-h <sec> Highlight rate
-W <sec> Maximal poll time for connection
-I interactive with cmd prompt
-f <name> read from file, “.trc” added if no suffix given
-D <int> sets an internal debug level
oclumon
一个命令行工具包括在可用于查询Berkeley DB后端打印出到终端节点的特定指标为指定的时间周期的包。该工具还支持在查询过程中一个特定的时间内打印一个节点上的资源持续时间和状态。这些状态是基于为每个资源度量的预定义的阈值和被表示为红,橙,黄,绿,指示减小临界的顺序。例如,你可以要求显示节点“节点1”在CPU的最后1小时内保持红色状态多少秒。 Oclumon也可用于执行复杂的管理任务,如改变调试级别,查询工具的版本,改变度量数据库大小等。
该oclumon的使用帮助可以通过oclumon -h打印。要获得有关每个动词选项运行oclumon <动词> -h了解更多信息。
目前支持的动词:
showtrail, showobjects, dumpnodeview, manage, version, debug, quit 和help。
下面是可以传递给oclumon一些有用的属性的例子。对于oclumon的默认位置是/usr/lib/oracrf/bin/oclumon。
Showobjects
oclumon showobjects –n node –time “2009-10-07 15:11:00”
Dumpnodeview
oclumon dumpnodeview –n node
Showgaps
oclumon showgaps -n node1 -s “2009-10-07 02:40:00” \
-e “2009-10-07 03:59:00”
Number of gaps found = 0
Showtrail
oclumon showtrail -n node1 -diskid sde qlen totalwaittime \
-s “2009-07-09 03:40:00” -e “2009-07-09 03:50:00” \
-c “red” “yellow” “green”
Parameter=QUEUE LENGTH
2009-07-09 03:40:00 TO 2009-07-09 03:41:31 GREEN
2009-07-09 03:41:31 TO 2009-07-09 03:45:21 GREEN
2009-07-09 03:45:21 TO 2009-07-09 03:49:18 GREEN
2009-07-09 03:49:18 TO 2009-07-09 03:50:00 GREEN
Parameter=TOTAL WAIT TIME
oclumon showtrail -n node1 -sys cpuqlen -s \
“2009-07-09 03:40:00” -e “2009-07-09 03:50:00” \
-c “red” “yellow” “green” Parameter=CPU QUEUELENGTH
Parameter=CPU QUEUELENGTH
2009-07-09 03:40:00 TO 2009-07-09 03:41:31 GREEN
2009-07-09 03:41:31 TO 2009-07-09 03:45:21 GREEN
2009-07-09 03:45:21 TO 2009-07-09 03:49:18 GREEN
2009-07-09 03:49:18 TO 2009-07-09 03:50:00 GREEN
- What to collect for cluster related issues
Oracle集群11g第2版的Grid_home/bin/diagcollection.pl正在收集Oracle集群健康监测数据,以及如果发现它安装在群集,它是由Oracle建议的。
节点夯住或被提出后收集数据,执行下面的步骤来分析问题:
– 在IPD的所有者下执行’Grid_home/bin/diagcollection.pl –collect –ipd –incidenttime <inc time> — incidentduration <duration>’ 命令 ,LOGGERD node, where – incidenttime格式为 MM/DD/YYYY24HH:MM:SS, –incidentduration 格式为HH:MM
– 用/usr/lib/oracrf/bin/oclumon manage -getkey “MASTER=”命令辨认出OGGERD 节点. 在Grid_home/bin目录下启动11.2.0.2的oclumonStarting 。
– 最少收集时间前后30分钟的数据。masterloggerhost:$./bin/diagcollection.pl –collect –ipd –incidenttime 10/05/200909:10:11 –incidentduration 02:00 Starting with 11.2.0.2 and the CRS integrated IPD/OS the syntax to get the IPD data collected is “masterloggerhost:$./bin/diagcollection.pl –collect –crshome /scratch/grid_home_11.2/ –ipdhome /scratch/grid_home_11.2/ –ipd — incidenttime 01/14/201001:00:00 –incidentduration 04:00”
– IPD数据文件看起来像: ipdData_<hostname>_<curr time>.tar.gz ipdData_node1_20091006_2321.tar.gz
– 需要多长时间来运行diagcollect?
4 node cluster, 4 hour data – 10 min
32 node cluster, 1 hour data – 20 min
- Debugging
为了开启osysmond或loggerd 的调试,root用户执行‘oclumon debug log all allcomp:5’。这将打开调试的所有组件。
开启的11.2.0.2 的 IPD/CH日志文件会在: Grid_home/log/<hostname>/crfmond Grid_home/log/<hostname>/crfproxy Grid_home/log/<hostname>/crflogd
- For ADE users
在开发环境上安装和启动IPD/OS更简单:
$ cd crfutl && make setup && runcrf
osysmond通常会立即启动,而这可能需要几秒钟(几分钟,如果你的I / O子系统比较慢)为ologgerd和oproxyd启动,由于Berkeley数据库(BDB)的初始化。第一个节点称之为“runcrf’将被配置为主。主后第一个节点运行’runcrf“将被配置为复制品。从那里,如果需要的话事情会移动。守护进程看出来的是:osysmond(所有节点),ologgerd(主服务器和副本节点),oproxyd(所有节点上)。
在开发环境中,IPD/ OS进程不以root或实时运行。

Comment