
ParnassusData Recovery Manager(以下简称PRM-DUL)是企业级ORACLE数据灾难恢复软件,可直接从Oracle 9i,10g,11g,12c的数据库数据文件(datafile)中抽取还原数据表上的数据,而不需要通过ORACLE数据库实例上执行SQL来拯救数据。ParnassusData Recovery Manager是一款基于JAVA开发的绿色软件,无需安装,下载解压后便可直接使用。
PRM-DUL采用GUI图形化界面(如图1)简单方便。使用者无需额外学习一套命令,或者了解ORACLE的底层数据结构原理即可以通过恢复向导(Recovery Wizard)来恢复数据库中的数据。
下载PRM-DUL: https://zcdn.parnassusdata.com/DUL5108.zip
为什么要使用PRM-DUL?
难道使用RMAN这个传统ORACLE恢复管理器的备份恢复还不够吗?为什么用户需要选择购买PRM-DUL呢?您的心头或许仍有这种疑惑!
在企业日益增长的IT系统中,数据容量正以几何级数扩展。 Oracle DBA在保证数据完整性的课题上正面临着现有磁盘存储系统容量不足以存放全量备份,基于磁带的数据备份在恢复数据时往往要求远远超过预期的平均修复时间等实际问题。
“对于数据库而言,备份重于一切”是所有DBA心中谨记的格言,但现实环境千差万别,企业的数据库环境中数据备份空间不足,采购的存储设备短期内无法到货,甚至于虽然进行了备份但是却在数据恢复过程中发现备份实际不可用等问题均属常见的场景。
为了应对这些真实世界中常见的数据恢复困局,PRM-DUL 诗檀数据恢复管理软件充分发挥其对ORACLE数据库内部数据结构,核心启动流程等内部原理的理解,可以应对在完全没有备份情况下的SYSTEM表空间丢失、误操作ORACLE数据字典表、由于断电引起的数据字典不一致等数据库无法顺利打开的场景,也可以挽回误截断(Truncate)/删除(Delete)/业务数据表等人为的误操作,并从容恢复数据。
甚至于仅仅接触过ORACLE数据库几天的非DBA 人员也可以轻松地使用PRM-DUL,这得益于PRM-DUL简单的安装、和全程图形化的人机交互界面;实施恢复的人员不需要专业的数据库知识,不需要学习任何命令,更无需了解数据库底层的存储结构。仅仅需要轻轻点击几下鼠标就能从容恢复数据。
对比传统恢复工具DUL,DUL是ORACLE原厂内部恢复工具,其使用需要通过ORACLE内部流程,一般仅有购买了ORACLE原厂的现场服务的用户能够在原厂工程师的协助下使用该工具。PRM-DUL打破了只有少数专业人士才能实施数据库恢复任务的限制,极大地缩短了从数据库故障到完整恢复数据的失败时间,降低了企业恢复数据的总成本。
通过PRM-DUL恢复的数据可以分为2种形式,传统抽取方式是将数据从数据文件中完整抽取出来并写入到平面文本文件中,之后使用SQLLDR等工具再加载到数据库中。 传统方式简单易懂,但其缺点是需要2倍于现有数据容量的空间:即一份平面文本数据所占空间、以及之后将文本数据导入到数据库中所占空间;在时间上需要将原始数据从数据文件中抽取后,方能导入到新建数据库中,往往又需要2倍的时间。
另一种是诗檀强烈推荐您使用的是PRM-DUL独创的数据搭桥方式,即通过PRM-DUL直接将抽取出来的数据加载到新建或者其他可用数据库中,这样避免了数据落地存储,对比传统方式有效节省了数据恢复所需要的空间和时间成本。
ORACLE的ASM自动存储管理技术正被越来越多的企业采用,数据库采用ASM存储对比传统文件系统具有高性能、支持集群、管理方便等优势。 但ASM的问题在于,对于普通用户而言ASM的存储结构过于黑盒了,一旦ASM中的某个Disk Group的内部数据结构发生了损坏导致Disk Group无法被成功MOUNT,也就意味着用户重要的数据被锁死在这个ASM的黑盒中了。在这种场景中往往需要熟悉ASM内部数据结构的ORACLE原厂的资深工程师到达用户现场后通过手动修复ASM内部结构;而购买ORACLE原厂的现场服务对普通用户而言显得即昂贵又耗时。
基于PRM-DUL的研发人员(前ORACLE公司资深工程师)对ORACLE ASM内部数据结构的深入理解,PRM-DUL中加入了特别针对ASM的数据恢复功能。
PRM-DUL目前支持的ASM数据恢复功能包括:
- 即便Disk Group无法正常MOUNT,仍可以通过PRM-DUL直接读取ASM磁盘上的可用的元数据metadata,并基于这些元数据将Disk Group中的ASM文件拷贝出来
- 即便Disk Group无法正常MOUNT,仍可以通过PRM-DUL直接读取ASM上的数据文件,并抽取其中的数据,支持传统抽取方式和数据搭桥方式。
PRM-DUL软件介绍
ParnassusData Recovery Manager(PRM-DUL)基于JAVA开发,这保证了PRM-DUL可以跨平台运行,无论是AIX、Solaris、HPUX等Unix平台, Redhat、Oracle Linux、SUSE等Linux平台,还是Windows平台上均可以直接运行PRM-DUL。
PRM-DUL支持的操作系统平台:
| Platform Name | Supported |
| AIX POWER | ü |
| Solaris Sparc | ü |
| Solaris X86 | ü |
| Linux X86 | ü |
| Linux X86-64 | ü |
| HPUX | ü |
| MacOS | ü |
PRM-DUL目前支持的数据库版本
| ORACLE DATABASE VERSION | Supported |
| Oracle 7 | û |
| Oracle 8 | û |
| Oracle 8i | û |
| Oracle 9i | ü |
| Oracle 10g | ü |
| Oracle 11g | ü |
| Oracle 12c | ü |
考虑到部分陈旧服务器使用例如AIX 4.3 Linux 3等较早的操作系统,这些操作系统上可能无法安装最新的JDK 如1.6/1.7; PRM-DUL在研发过程中充分考虑了利旧性,任何可以运行JDK 1.4的平台均可以运行PRM-DUL。
此外由于ORACLE 10g 数据库服务器软件自带了JDK 1.4,11g自带了JDK 1.5,所以任何已安装ORACLE 10g及其以上版本的环境均可以顺利运行PRM-DUL,而且无需额外安装JDK。
对于没有安装JDK 1.4版本的环境,建议从以下地址下载
http://www.oracle.com/technetwork/java/javasebusiness/downloads/java-archive-downloads-javase14-419411.html
PRM-DUL 使用的最低JAVA软件环境为JDK 1.4;诗檀推荐您使用JDK 1.6,由于JDK 1.4以后对JAVA程序的性能做了很大优化,所以PRM-DUL在JDK 1.6环境下的恢复速度要比JDK 1.4下快一些。
PRM-DUL使用的最低硬件需求:
| CPU中央处理器 | 至少800 MHZ |
| 物理内存 | 至少512 MB |
| 硬盘空间 | 至少50 MB |
PRM-DUL推荐的硬件配置:
| CPU中央处理器 | 2.0 GHZ |
| 物理内存 | 2 GB |
| 硬盘空间 | 2 GB |
PRM-DUL目前支持的多语言:
| 语言 | 字符集 | 对应的编码 |
| 中文 简体/繁体 | ZHS16GBK | GBK |
| 中文 简体/繁体 | ZHS16DBCS | CP935 |
| 中文 简体/繁体 | ZHT16BIG5 | BIG5 |
| 中文 简体/繁体 | ZHT16DBCS | CP937 |
| 中文 简体/繁体 | ZHT16HKSCS | CP950 |
| 中文 简体/繁体 | ZHS16CGB231280 | GB2312 |
| 中文 简体/繁体 | ZHS32GB18030 | GB18030 |
| 日文 | JA16SJIS | SJIS |
| 日文 | JA16EUC | EUC_JP |
| 日文 | JA16DBCS | CP939 |
| 韩语 | KO16MSWIN949 | MS649 |
| 韩语 | KO16KSC5601 | EUC_KR |
| 韩语 | KO16DBCS | CP933 |
| 法语 | WE8MSWIN1252 | CP1252 |
| 法语 | WE8ISO8859P15 | ISO8859_15 |
| 法语 | WE8PC850 | CP850 |
| 法语 | WE8EBCDIC1148 | CP1148 |
| 法语 | WE8ISO8859P1 | ISO8859_1 |
| 法语 | WE8PC863 | CP863 |
| 法语 | WE8EBCDIC1047 | CP1047 |
| 法语 | WE8EBCDIC1147 | CP1147 |
| 德语 | WE8MSWIN1252 | CP1252 |
| 德语 | WE8ISO8859P15 | ISO8859_15 |
| 德语 | WE8PC850 | CP850 |
| 德语 | WE8EBCDIC1141 | CP1141 |
| 德语 | WE8ISO8859P1 | ISO8859_1 |
| 德语 | WE8EBCDIC1148 | CP1148 |
| 意大利语 | WE8MSWIN1252 | CP1252 |
| 意大利语 | WE8ISO8859P15 | ISO8859_15 |
| 意大利语 | WE8PC850 | CP850 |
| 意大利语 | WE8EBCDIC1144 | CP1144 |
| 泰语 | TH8TISASCII | CP874 |
| 泰语 | TH8TISEBCDIC | TIS620 |
| 阿拉伯语 | AR8MSWIN1256 | CP1256 |
| 阿拉伯语 | AR8ISO8859P6 | ISO8859_6 |
| 阿拉伯语 | AR8ADOS720 | CP864 |
| 西班牙语 | WE8MSWIN1252 | CP1252 |
| 西班牙语 | WE8ISO8859P1 | ISO8859_1 |
| 西班牙语 | WE8PC850 | CP850 |
| 西班牙语 | WE8EBCDIC1047 | CP1047 |
| 葡萄牙语 | WE8MSWIN1252 | CP1252 |
| 葡萄牙语 | WE8ISO8859P1 | ISO8859_1 |
| 葡萄牙语 | WE8PC850 | CP850 |
| 葡萄牙语 | WE8EBCDIC1047 | CP1047 |
| 葡萄牙语 | WE8ISO8859P15 | ISO8859_15 |
| 葡萄牙语 | WE8PC860 | CP860 |
PRM-DUL支持的表存储类型:
| 表存储类型 | Supported |
| Cluster Table簇表 | YES |
| 索引组织表,分区或非分区 | YES |
| 普通堆表,分区或非分区 | YES |
| 普通堆表 启用基本压缩 | YES(Future) |
| 普通堆表 启用高级压缩 | NO |
| 普通堆表 启用混合列压缩 | NO |
| 普通堆表 启用加密 | NO |
| 带有虚拟字段virtual column的表 | NO |
| 链式行、迁移行 chained rows 、migrated rows | YES |
注意事项: 对于virtual column、11g optimized default column而言 数据抽取可能没问题,但会丢失对应的字段。 这2个都是11g之后的新特性,使用者较少。
PRM-DUL 支持的数据类型
| 数据类型 | Supported |
| BFILE | No |
| Binary XML | No |
| BINARY_DOUBLE | Yes |
| BINARY_FLOAT | Yes |
| BLOB | Yes |
| CHAR | Yes |
| CLOB and NCLOB | Yes |
| Collections (including VARRAYS and nested tables) | No |
| Date | Yes |
| INTERVAL DAY TO SECOND | Yes |
| INTERVAL YEAR TO MONTH | Yes |
| LOBs stored as SecureFiles | Future |
| LONG | Yes |
| LONG RAW | Yes |
| Multimedia data types (including Spatial, Image, and Oracle Text) | No |
| NCHAR | Yes |
| Number | Yes |
| NVARCHAR2 | Yes |
| RAW | Yes |
| ROWID, UROWID | Yes |
| TIMESTAMP | Yes |
| TIMESTAMP WITH LOCAL TIMEZONE | Yes |
| TIMESTAMP WITH TIMEZONE | Yes |
| User-defined types | No |
| VARCHAR2 and VARCHAR | Yes |
| XMLType stored as CLOB | No |
| XMLType stored as Object Relational | No |
PRM-DUL对ASM的支持
| 功能 | Supported |
| 支持直接从ASM中抽取数据,无需拷贝到文件系统上 | YES |
| 支持从ASM中拷贝数据文件 | YES |
| 支持修复ASM metadata | YES |
| 支持图形化展示ASM黑盒 | Future |
PRM-DUL的安装与启动
由于PRM-DUL是基于JAVA开发的纯绿色软件,所以无需额外安装,用户仅需要在下载软件ZIP包后解压即可用于恢复数据。
| unzip PRM-DUL_latest.zip |
诗檀强烈推荐您使用命令行启动PRM-DUL,这样可以从命令行中获得更多诊断信息。
Windows平台下的启动方法
- 首先保证JDK已正确安装且java已经加入到环境变量中:
- 双击PRM-DUL解压目录下的PRM-DUL.bat

PRM-DUL.bat会在后台启动PRM:

并启动PRM-DUL 图形化主界面:
在Linux/Unix环境下的启动方法:
在Linux/Unix环境下可以在本机图形化界面或者通过Xmanager等远程图形化工具使用
- 首先保证JDK已正确安装且java已经加入到环境变量中
- Cd到PRM-DUL所在目录,并执行./PRM-DUL.sh启动程序主界面
PRM-DUL的许可证注册
ParnassusData Recovery Manager(以下简称PRM-DUL)是一款商业软件。ParnassusData提供PRM-DUL的社区版供用户测试和学习(社区版中ASM clone功能无任何限制,今后社区版将加入更多免费新特性)。
如想无限制地使用PRM-DUL软件恢复ORACLE数据库则需要购买对应的License软件许可证,目前我们只提供1种License类型: Enterprise Edition 企业版。
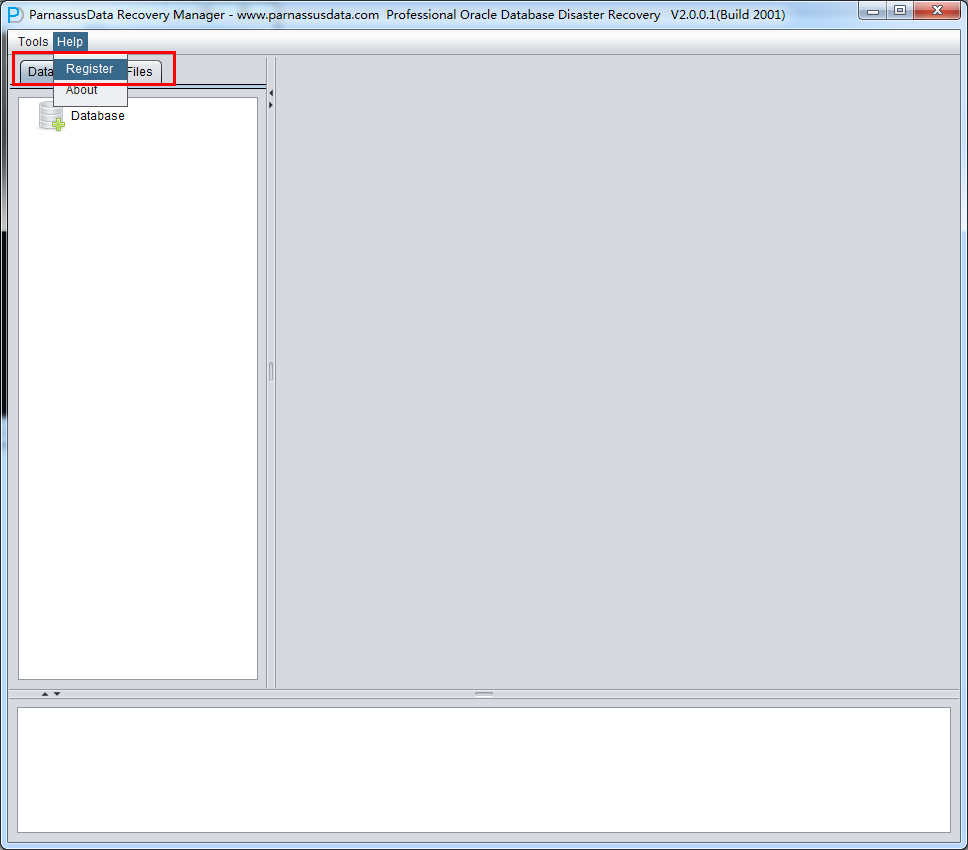
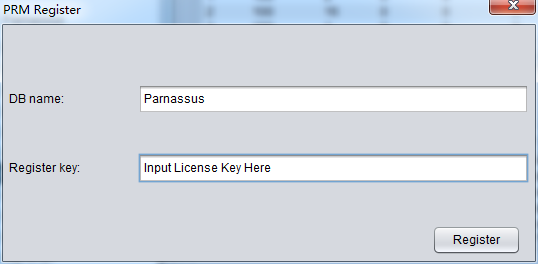
用户获得License Key之后可以自行在软件中注册Register,具体使用方法为:
- 在菜单栏Help => Register
- 输入DB NAME和发送给您的License Key并点击Register按钮即可
完成注册后,今后重新启动PRM-DUL将自动检测License注册信息,无需重复注册。
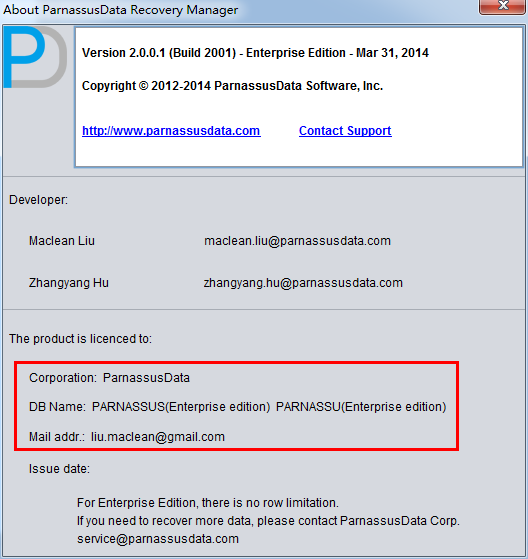
成功注册的信息可以在Help=>About中找到:
基于不同的Oracle数据库恢复场景介绍如何使用PRM-DUL
恢复场景1 误Truncate表的常规恢复
D公司的业务维护人员由于误将产品数据库当做测试环境库导致错误地TRUNCATE了一张表上的所有数据,DBA尝试恢复但是发觉最近的备份不可用,导致无法从备份中恢复出该数据表上的记录。 此时DBA决定采用PRM-DUL来恢复已经被TRUNCATE掉的数据。
由于该环境中 所有数据库文件均是可用且健康的,用户仅需要 字典模式下加载SYSTEM表空间的数据文件以及被TRUNCATED表的数据文件即可,例如:
| create table ParnassusData.torderdetail_his1 tablespace users asselect * from parnassusdata.torderdetail_his;
|
启动PRM-DUL ,并选择 Tools => Recovery Wizard
点击Next
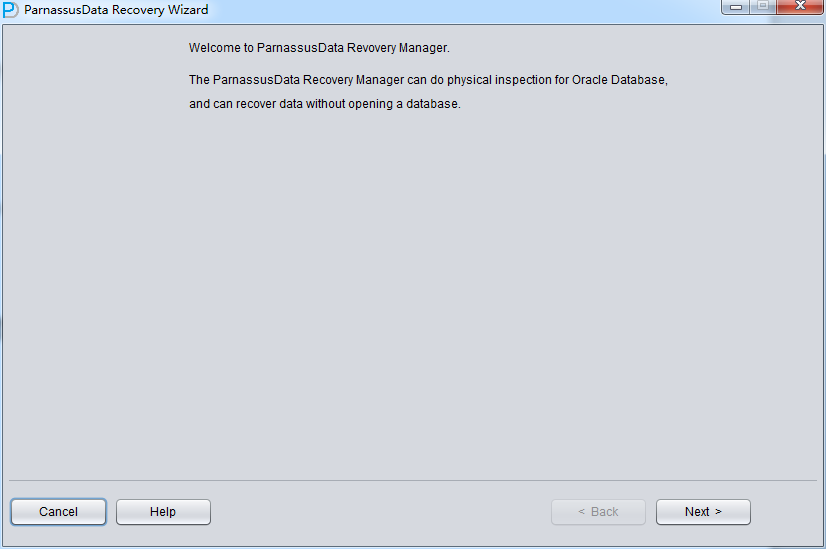
在此TRUNCATE场景中并未采用ASM存储,所以仅需要选择 《Dictionary Mode》字典模式即可:
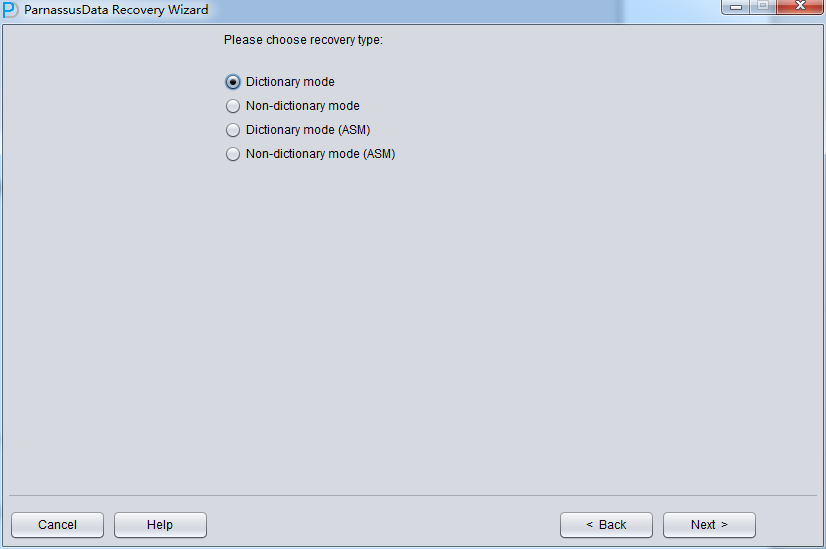
下一步骤 我们要选择几个参数 : 包括Endian 字节序和DB NAME
由于ORACLE数据文件在不同的操作系统平台上采用了不同的Endian字节序格式,字节序和平台对应列表如下:
| Solaris[tm] OE (32-bit) | Big |
| Solaris[tm] OE (64-bit) | Big |
| Microsoft Windows IA (32-bit) | Little |
| Linux IA (32-bit) | Little |
| AIX-Based Systems (64-bit) | Big |
| HP-UX (64-bit) | Big |
| HP Tru64 UNIX | Little |
| HP-UX IA (64-bit) | Big |
| Linux IA (64-bit) | Little |
| HP Open VMS | Little |
| Microsoft Windows IA (64-bit) | Little |
| IBM zSeries Based Linux | Big |
| Linux x86 64-bit | Little |
| Apple Mac OS | Big |
| Microsoft Windows x86 64-bit | Little |
| Solaris Operating System (x86) | Little |
| IBM Power Based Linux | Big |
| HP IA Open VMS | Little |
| Solaris Operating System (x86-64) | Little |
| Apple Mac OS (x86-64) | Little |
例如在传统Unix AIX-Based Systems (64-bit) 、HP-UX (64-bit) 上使用的是Big Endian大端字节序,则这里要选为Big Endian:
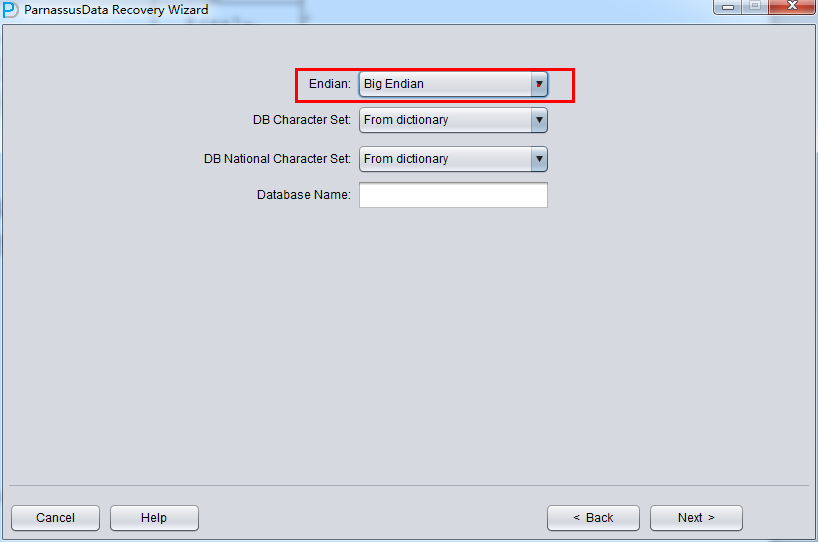
否则例如常见的Linux x86-64 、Windows都保持为默认的Little Endian:
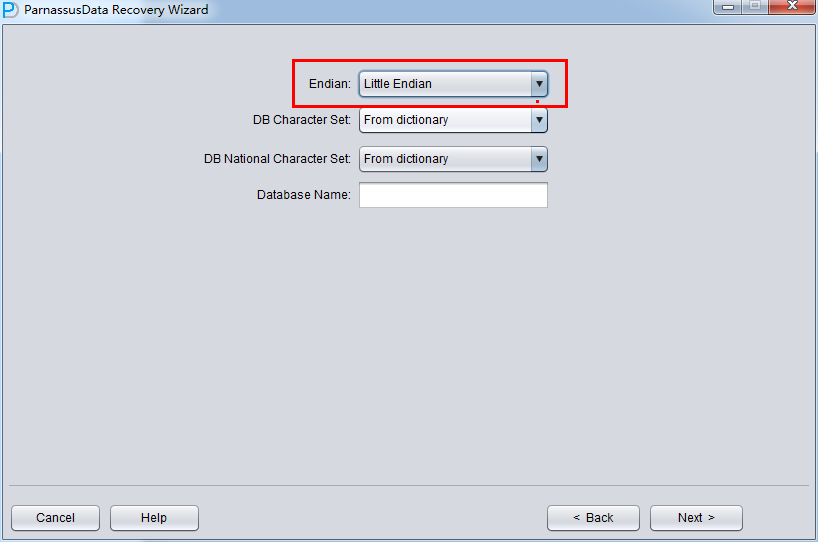
注意事项: 如果你的数据文件是在AIX(即Big Endian的)上生成的,你为了方便而将这些数据文件拷贝到Windows服务器上并使用PRM-DUL来恢复数据,那么你仍应当选择其原生的Big Endian格式。
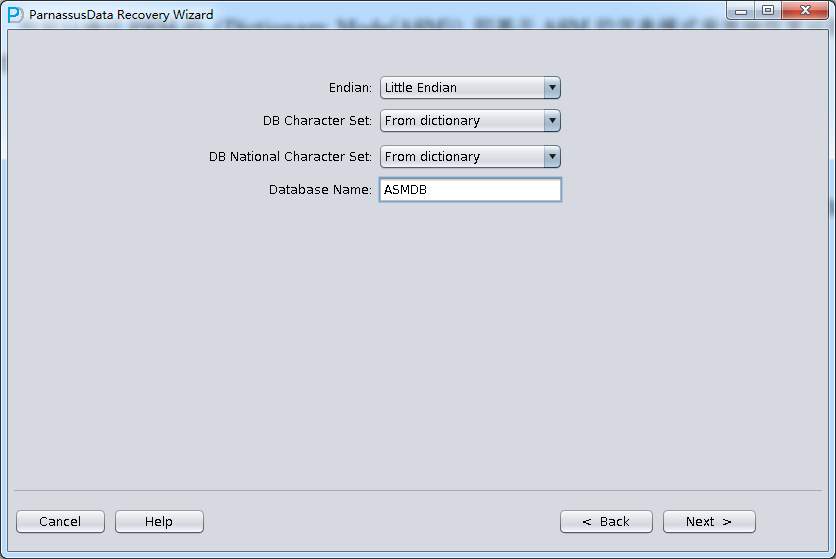
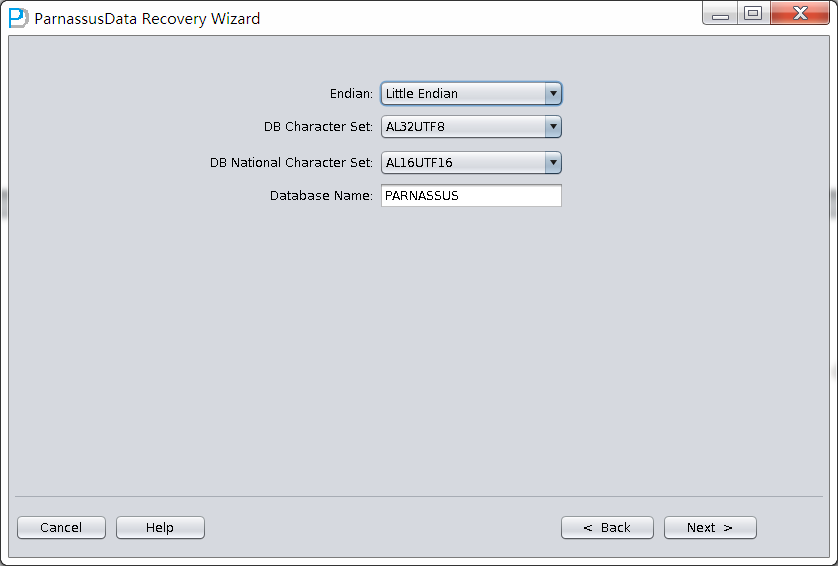
这里由于我们的数据文件是在Linux x86上所以我们选择Endian为Little,并输入Database name数据库名字(注意这里输入的数据库名仅仅是一个别名,它不代表这个数据库真实的DBNAME,PRM-DUL的LICENSE检测机制使用的是真实的DBNAME,而非此处输入的Database Name):
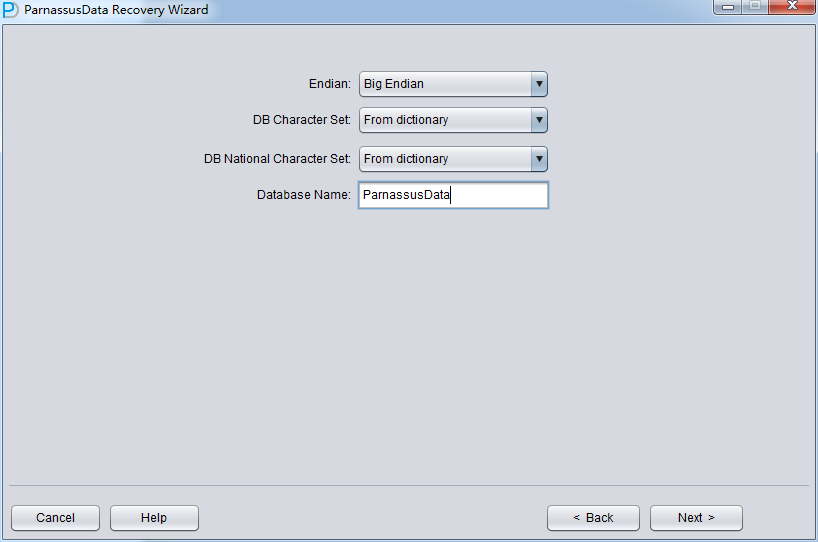
点击Next
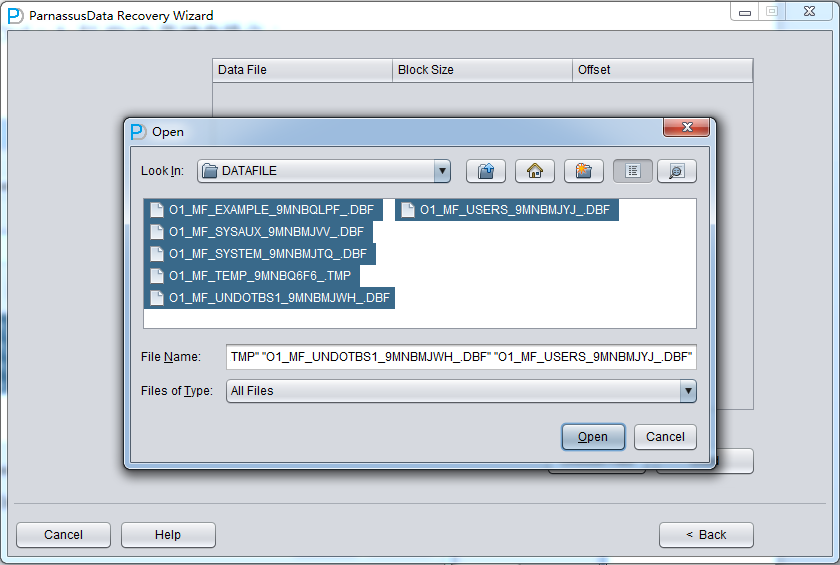
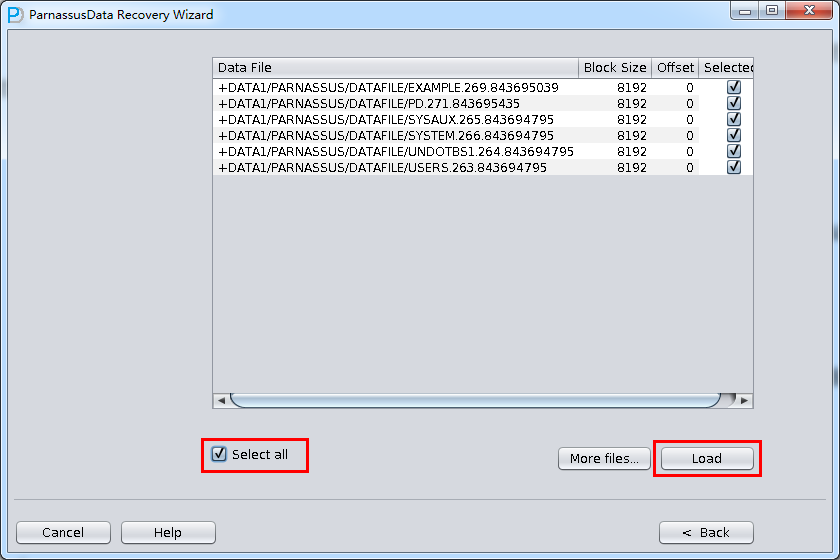
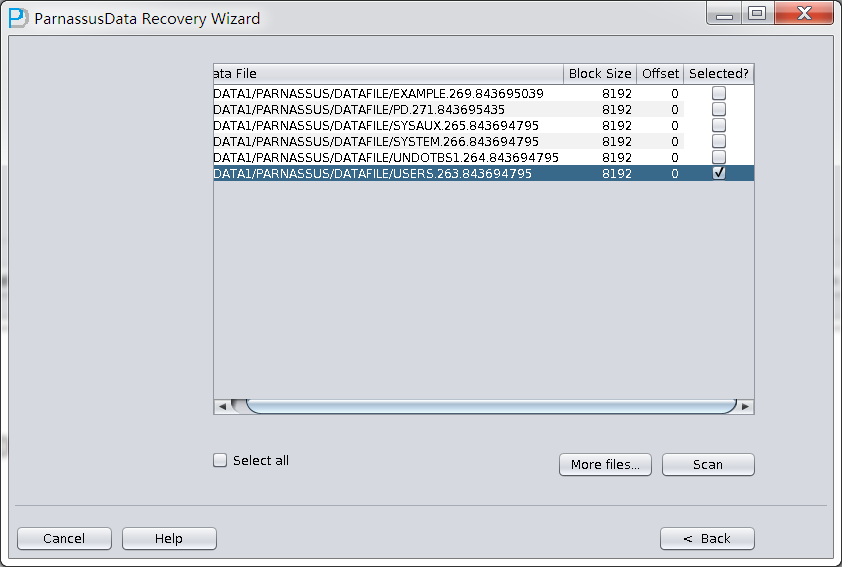
点击Choose Files, 一般我们推荐 如果数据库不大,那么将该库所有的数据文件都选择进来; 如果你的数据库很大,且你了解你的数据表位于哪些数据文件上,则你可以仅仅选择SYSTEM表空间的数据文件(必须!)以及数据所在的数据文件。
注意Choose界面支持Ctrl + A 和Shift等键盘操作:

之后需要为指定的数据文件指定其Block Size即ORACLE数据块的大小,这里根据实际情况修改即可, 例如你的DB_BLOCK_SIZE是8K,但是部分表空间指定16K作为数据块大小的,仅仅需要为那些不是8k的数据文件修改BLOCK_SIZE即可。
这里的OFFSET 参数主要是为了那些采用裸设备存放数据文件的场景,例如在AIX上基于普通VG的LV作为数据文件,则存在4k的OFFSET,需要在此处指定。
如果你恰巧正在使用裸设备数据文件,而又不知道OFFSET到底是多少? 则可以使用$ORACLE_HOME/bin下自带的dbfsize工具查看,如下面的例子高亮部分显示该裸设备具有4K的OFFSET
| $dbfsize /dev/lv_control_01Database file: /dev/lv_control_01
Database file type: raw device without 4K starting offset Database file size: 334 16384 byte blocks |
由于此场景中所有数据文件均为8K的BLOCK SIZE,且基于文件系统所以均没有OFFSET,点击Load
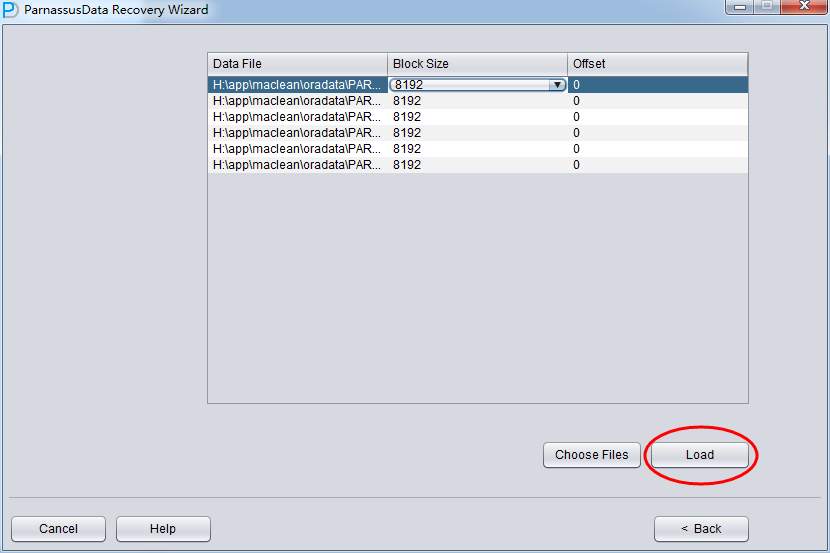
Load阶段PRM-DUL会从SYSTEM表空间中读取ORACLE数据字典信息,并在自带的Derby中自建一个数据字典,这让PRM-DUL有能力操作ORACLE数据库中的各种数据。
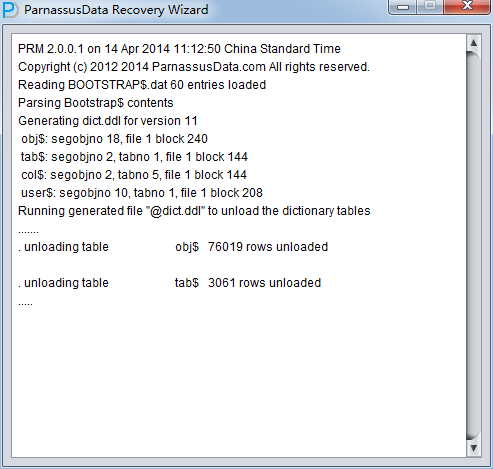
Load完成后会在后台输出数据库 字符集和国家字符集等信息:
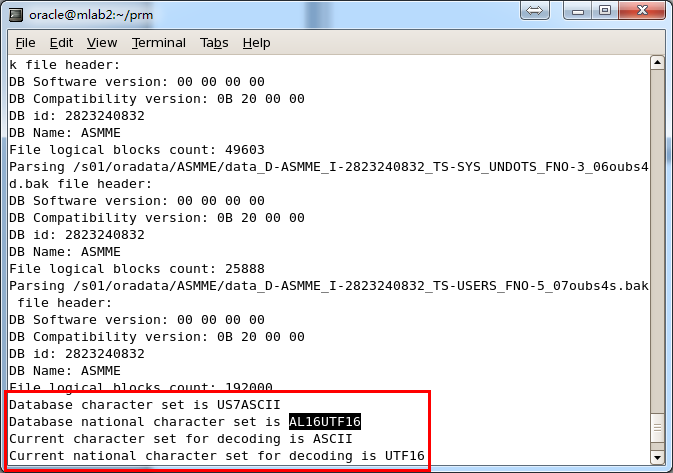
注意PRM-DUL是支持 多语言和ORACLE数据库的多字符集的, 但是前提是实施PRM-DUL数据恢复的操作系统要求已经安装了对应的语言包; 例如在Windows操作系统上没有安装中文语言包,但是由于ORACLE数据库字符集是独立于操作系统语言的,即ORACLE数据库的字符集可以为ZHS16GBK字符集,但是操作系统并不支持中文,此场景中不在本服务器上部署的ORACLE客户端并不受影响,可以正确显示数据库中的中文数据。
但是使用PRM-DUL则要求实施PRM-DUL数据恢复的操作系统已经安装了对应的语言包,例如用户要恢复ZHS16GBK的中文字符集数据库,则需要操作系统上已经安装了中文语言包才可以。
类似的 在Linux上需要安装fonts-chinese 中文字体包。
Load完成后 PRM-DUL界面左侧出现按照数据库用户分组的树形图
点开USERS,可以看到多个用户名,例如用户需要恢复PARNASSUSDATA SCHEMA下的一张表,则点开PARNASSUSDATA,并双击表名:

由于该TORDERDETAIL_HIS表之前已经被TRUNCATED掉了,所以双击没有显示有数据,此时在表上右键选择Unload truncated data:

PRM-DUL将尝试扫描该表所在表空间并将已经truncated掉的数据抽取出来:
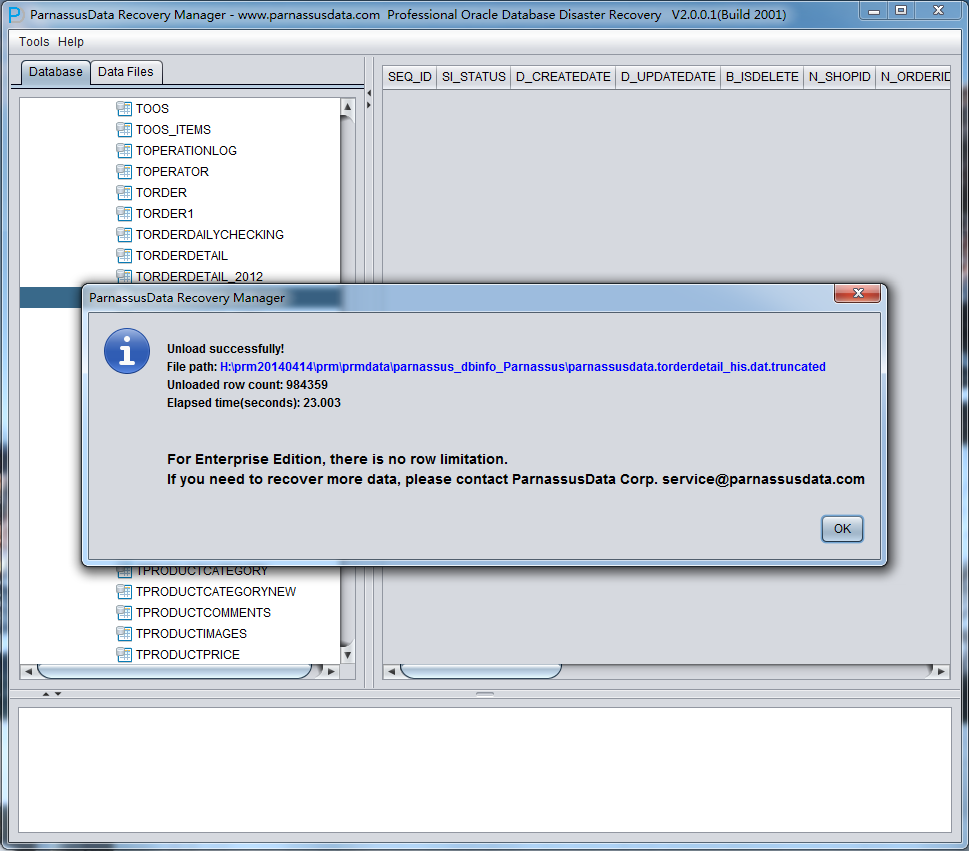
如上图所示从已经被TRUNCATE过的TORDERDETAIL_HIS表中抽取出完整的984359条记录,并存放在提示指定的路径下。
这里还自动生成了将文本数据导入到数据库中使用的SQLLDR 控制文件。
| $ cd /home/oracle/PRM-DUL/PRM-DULdata/parnassus_dbinfo_PARNASSUSDATA/$ ls -l ParnassusData*
-rw-r–r– 1 oracle oinstall 495 Jan 18 08:31 ParnassusData.torderdetail_his.ctl -rw-r–r– 1 oracle oinstall 191164826 Jan 18 08:32 ParnassusData.torderdetail_his.dat.truncated
$ cat ParnassusData.torderdetail_his.ctl LOAD DATA INFILE ‘ParnassusData.torderdetail_his.dat.truncated’ APPEND INTO TABLE ParnassusData.torderdetail_his FIELDS TERMINATED BY ‘ ‘ OPTIONALLY ENCLOSED BY ‘”‘ TRAILING NULLCOLS ( “SEQ_ID” , “SI_STATUS” , “D_CREATEDATE” , “D_UPDATEDATE” , “B_ISDELETE” , “N_SHOPID” , “N_ORDERID” , “C_ORDERCODE” , “N_MEMBERID” , “N_SKUID” , “C_PROMOTION” , “N_AMOUNT” , “N_UNITPRICE” , “N_UNITSELLINGPRICE” , “N_QTY” , “N_QTYFREE” , “N_POINTSGET” , “N_OPERATOR” , “C_TIMESTAMP” , “H_SEQID” , “N_RETQTY” , “N_QTYPOS” )
|
将数据导入到源表中(注意 ParnassusData强烈建议你修改该SQLLDR控制文件中导入的表名字为一个临时表,这样不会覆盖原环境)。
| $ sqlldr control=ParnassusData.torderdetail_his.ctl direct=yUsername:/ as sysdba//以上使用sqlldr导入了恢复的数据
//可以通过minus来对比恢复出来的数据:
select * from ParnassusData.torderdetail_his minus select * from parnassus.torderdetail_his;
no rows selected
|
测试TRUNCATE用例表与源数据表对比,发现记录完全一致。
说明PRM-DUL完整、丝毫不差地恢复了被TRUNCATE表上的记录。
恢复场景2 误Truncate表的DataBridge数据搭桥恢复
恢复场景1中我们采用了常规unload+sqlldr的恢复方式; 但实际上ParnassusData原厂更推荐您使用我们精心设计的DataBridge数据搭桥模式。
为什么要引入数据搭桥模式呢?
- 普通的unload+sqlldr恢复方式意味着要保存一份源数据,一份抽取数据,和一份目标数据,即在恢复过程中可能需要扩容2倍于原来的存储空间,这对于甚至无法腾出备份空间的企业来说十分困难
- 数据搭桥与普通unload+sqlldr模式的最大区别在于,数据搭桥直接从源库中抽取数据并传送到目标数据库中,无需在文件系统上保留一份抽取数据
- 通过数据搭桥传送到目标数据库中的数据本身就是结构化的,可以立即使用SQL语句来验证其完整性和一致性
- 如果数据搭桥的目标数据库库位于异机上,那么源数据库上仅仅做读取操作,读写IO将分布于2台服务器上,PRM-DUL恢复的速度将更快
- 如果用户所需要恢复的是Truncate数据的话,那么可以马上搭桥回到源库中,恢复仅仅是鼠标点几下的工作
使用数据搭桥模式也十分简便,通常规模式一样,在左侧树形图中点中你需要的表,右键选择DataBridge选项:
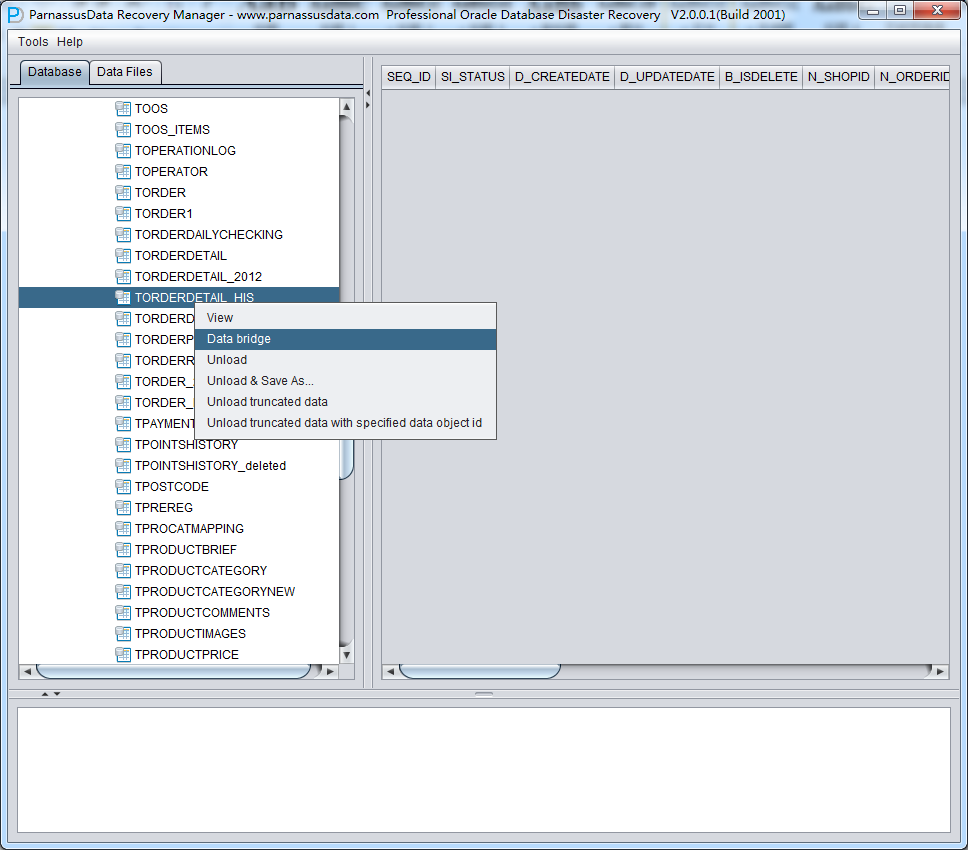
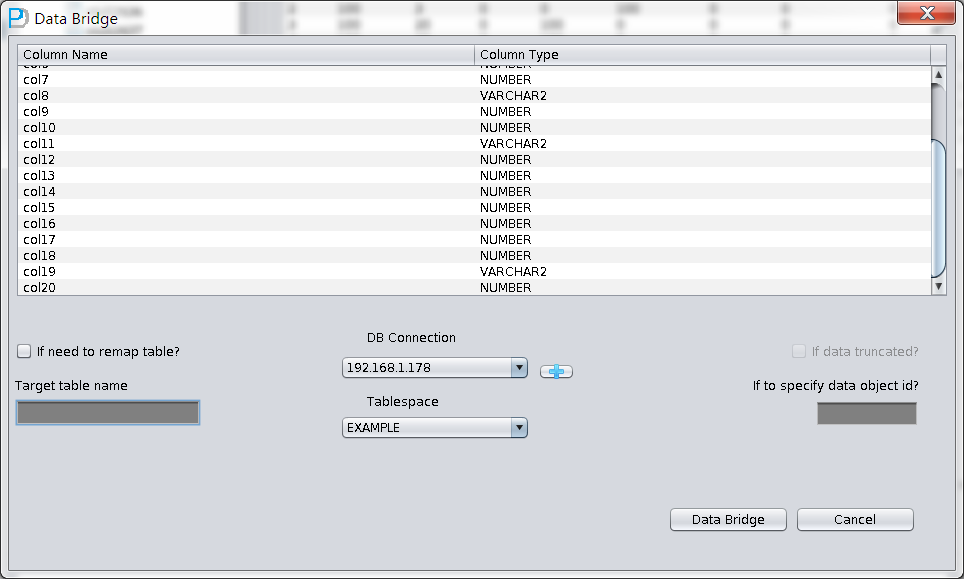
首次使用数据搭桥模式时需要先创建目标数据库连接信息,这就和我们在SQLDEVELOPER中创建一个Connection是类似的工作,包括目标数据库的Host、端口、Service_Name以及用户登录信息;注意这里填选的用户信息,将会是稍后数据搭桥使用的目标数据库的User用户,即从源库这里抽取出来的表会传输到目标数据库中此处所指定的用户名下。
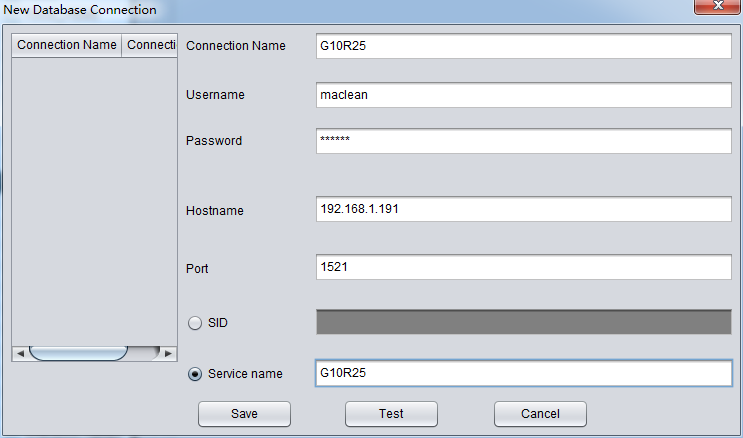
如上述建立了一个G10R25的连接,用户为maclean,对应的oracle Easy Connection连接串为 192.168.1.191:1521/G10R25。
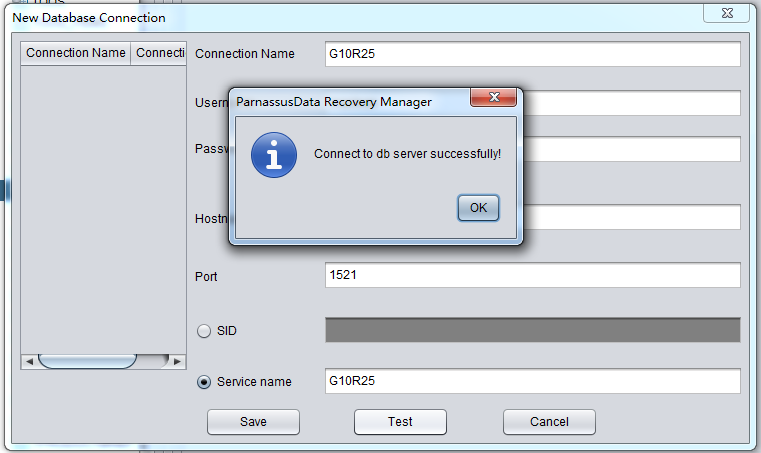
完成上述数据库连接信息填写后可以点击Test按钮来测试该连接配置是否正确可用,如果返回 “ Connect to db server successfully “则说明连接可用,点击Save按钮保存即可。
Save后进入DataBridge主界面,首先在DB Connection下拉框中选择刚刚加入的Connection G10R25:
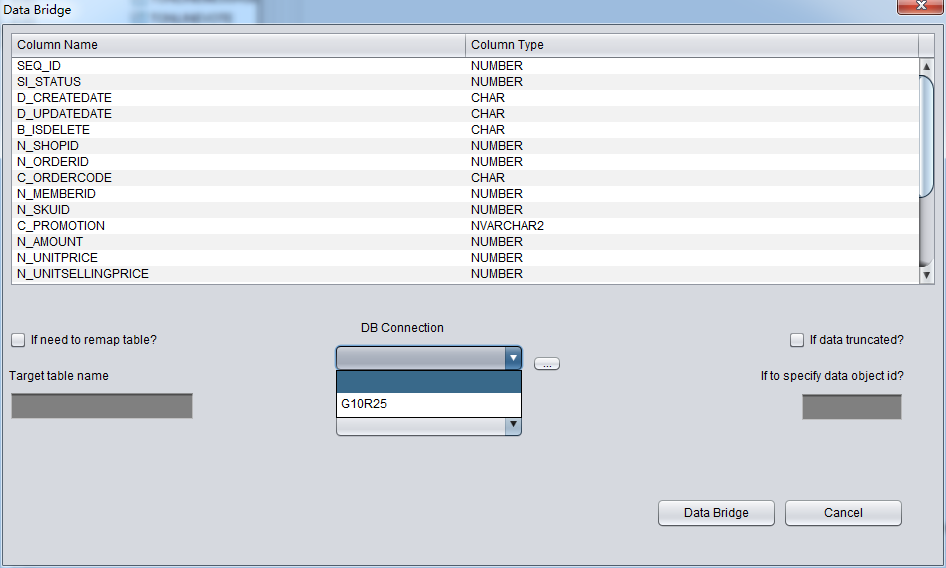
此处如果所需用的数据库连接并未在DB connection下拉框中出现,则需要点击DB connection旁的”…”按钮添加DB Connection:
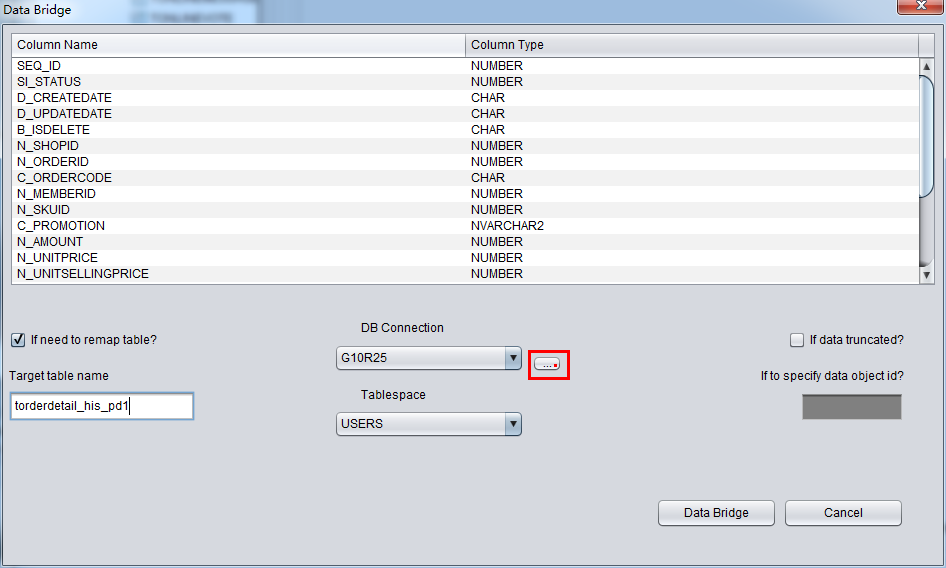
正确选择DB Connection后可以Tablespace的下拉框将变得可用,选中合适的表空间:
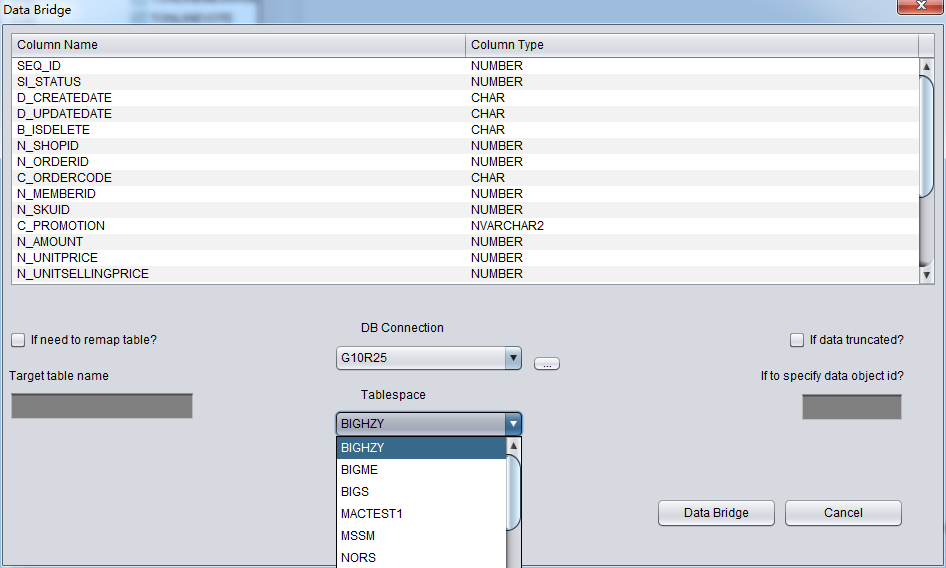
使用Data Bridge恢复truncate时的注意事项:注意当从源库中恢复出truncate数据时,若使用databridge选项传输数据回到你的源库(如果回传数据不是到源库则没有该问题)时,需要注意 Databridge插入到新建表的所在位置应当不是源库中被truncate数据所在的表空间,否则会出现一边在恢复truncate数据一边我们所需恢复的数据被新数据所覆盖的问题,可能导致该恢复场景中的数据完全无法恢复。故请注意,当使用databridge+恢复数据到源库时,在databridge中指定表空间时千万不要使用需要恢复数据所在的表空间!!!!!!
用户可以选择是否要将从源库传输到目标库的表的表名做映射修改,例如我们在源库中Truncate掉了一张表,现在通过DataBridge将数据恢复回源库中,但是不想使用原来的表名字,如原来的表名为torderdetail_his,现在希望将恢复的数据以别的表名存放,则可以选中“if need to remap table”并填入合适的目标表名,如下图所示:

注意: 1)对于目标库中已经存在对应表名的情况,PRM-DUL不会重建表而是会在现有表的基础上插入所需恢复的数据,由于表已经建立了所以指定的表空间将无效 2)对于目标数据库中还不存在对应表名的情况,PRM-DUL会尝试在指定表空间上建表并插入恢复数据
此场景中由于我们是恢复Truncate掉的数据,所以需要选中“if data truncated”选项,否则PRM-DUL将以常规模式抽取数据,将无法抽取到已经被Truncate掉的数据。
Truncate数据的大致机理是,ORACLE会在数据字典和Segment Header中更新表的Data Object ID,而实际数据部分的块则不会做修改。由于数据字典与段头的DATA_OBJECT_ID与后续的数据块中的并不一致,所以ORACLE服务进程在读取全表数据时不会读取到已经被TRUNCATE但是实际仍未被覆盖的数据。
PRM-DUL通过自动扫描被TRUNCATE掉数据段头Segment Header后续的数据块智能判断TRUNCATE前数据段的DATA_OBJECT_ID,并根据字典中的表字段定义和自动获得的原始DATA_OBJECT_ID来抽取数据。
此处还存在一个”if to specify data object id”输入框,该输入框可以让用户指定要恢复的数据的Data Object ID。一般情况下不需要指定任何值,除非你发现恢复Truncate数据不成功时,建议在ParnassusData原厂工程师的帮助下指定该值。
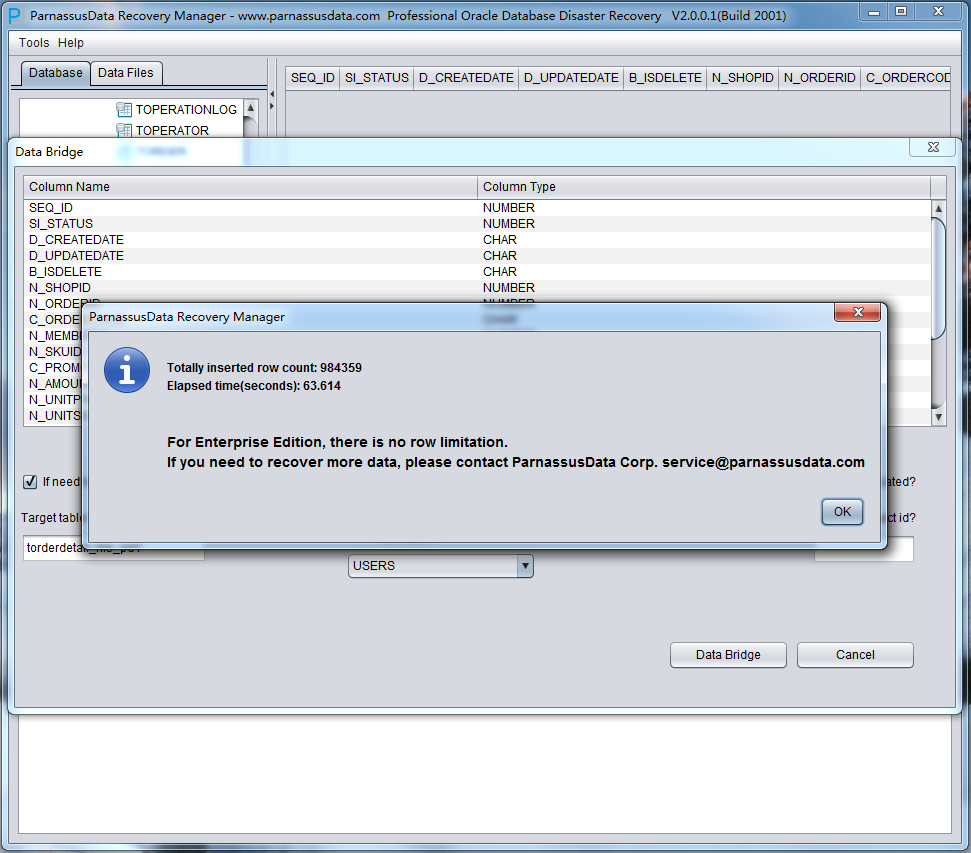
如上正确完成DataBridge配置后即可证实开始数据搭桥,只需要点击DataBridge按钮即可:

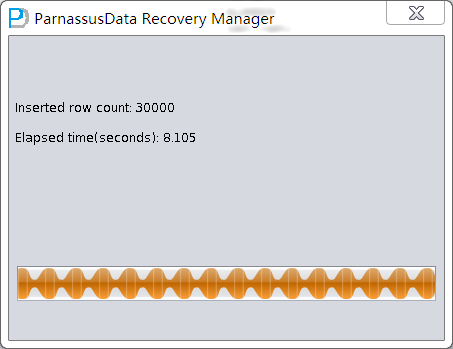
数据搭桥完成后会显示成功传输的数据行数,以及耗时。
恢复场景3 ORACLE数据字典受损导致数据库无法打开
D 公司的DBA由于误操作删除了TS$数据字典基表导致数据库无法启动
| Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 – 64bit ProductionWith the Partitioning, Automatic Storage Management, OLAP, Data Miningand Real Application Testing options
INSTANCE_NAME —————- ASMME
SQL> SQL> SQL> select count(*) from sys.ts$;
COUNT(*) ———- 5
SQL> delete ts$;
5 rows deleted.
SQL> commit;
Commit complete.
SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut down.
Database mounted. ORA-01092: ORACLE instance terminated. Disconnection forced ORA-01405: fetched column value is NULL Process ID: 5270 Session ID: 10 Serial number: 3
Undo initialization errored: err:1405 serial:0 start:3126020954 end:3126020954 diff:0 (0 seconds) Errors in file /s01/diag/rdbms/asmme/ASMME/trace/ASMME_ora_5270.trc: ORA-01405: fetched column value is NULL Errors in file /s01/diag/rdbms/asmme/ASMME/trace/ASMME_ora_5270.trc: ORA-01405: fetched column value is NULL Error 1405 happened during db open, shutting down database USER (ospid: 5270): terminating the instance due to error 1405 Instance terminated by USER, pid = 5270 ORA-1092 signalled during: ALTER DATABASE OPEN… opiodr aborting process unknown ospid (5270) as a result of ORA-1092
|
此场景中由于数据字典已经损坏,所以想要正常打开数据库是十分困难的。
此时则可以使用PRM-DUL来抽取数据库中的数据。具体步骤与场景1中的相似,用户仅仅需要输入该数据库的所有数据文件即可,其简要步骤如下:
- Recovery Wizard
- 选择字典模式 Dictionary Mode
- 合理选择Big或者Little Endian
- 加入数据文件并点击Load
- 根据实际需求恢复表中的数据
恢复场景4 误删除或丢失SYSTEM表空间
D公司的SA系统管理员误删除了某数据库的SYSTEM表空间所在数据文件,这导致数据库完全无法打开,数据无法取出。 在没有备份的情况下,可以使用PRM-DUL恢复接近100%的数据。
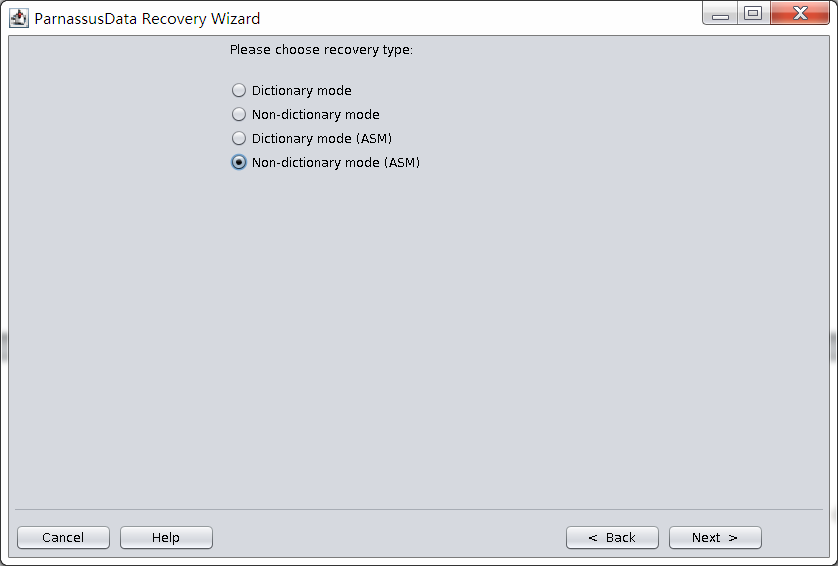
此场景中启动PRM-DUL后,进入Recovery Wizard后 选择《Non-Dictionary mode》非字典模式:
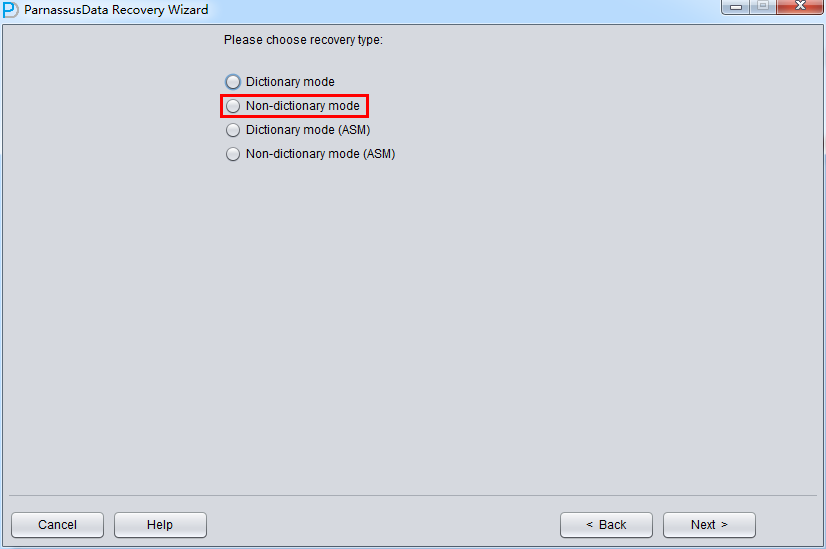

No-dictionary模式下需要用户指定 字符集和国家字符集,这是因为丢失了SYSTEM表空间后,数据库的字符集信息无法正常获得,所以需要用户的输入。 只有输入正确的字符集设置以及安装了必要的语言包才能保证No-Dictionary模式下正常抽取多国语言。
与场景演示1类似,输入用户目前可得的所有数据文件(不包括临时文件),并设置正确的Block Size和OFFSET:
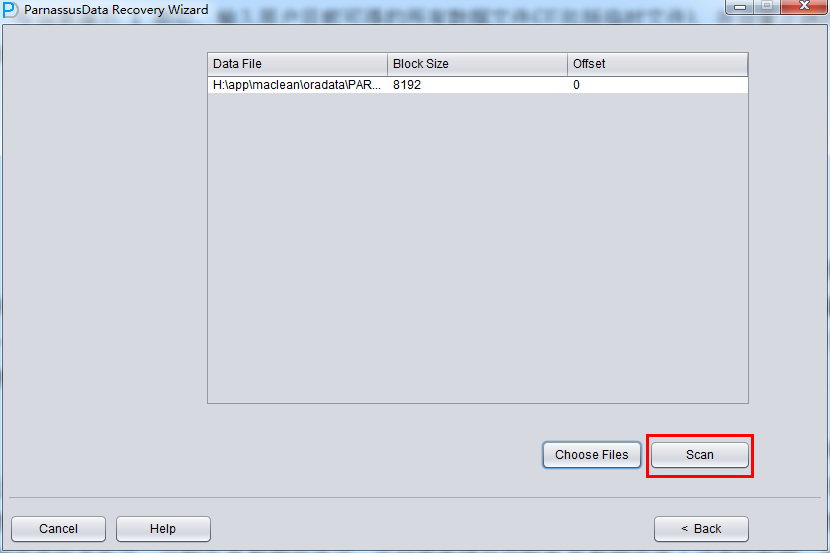
之后点击SCAN,SCAN的作用是扫描所有数据文件上的Segment Header,并记录到SEG$.DAT和EXT$.DAT中;在ORACLE中一个非分区表或者一个分区表的分区都对应着一个SEGMENT HEADER数据段头,只要能找到SEGMENT HEADER就可以获得整个表数据段的盘区EXTENT MAP 信息,通过EXTENT MAP可以获得该表上的全部记录。
通常存在这样一种情况,例如一张非分区的单表存放在某个由2个数据文件组成的表空间上,其SEGMENT HEADER以及一半的数据存放在A数据文件上,另一半数据存放在B数据文件上。但是由于某些原因,SYSTEM表空间和存放有SEGMENT HEADER的A数据文件均丢失了,只剩下B数据文件了,此时若希望仅仅恢复B数据文件上该表的数据,则不能依赖于SEGMENT HEADER,而只能依赖于从B数据文件上扫描盘区图EXTENT MAP信息了。
为了同时满足 基于SEGMENT HEADER和EXTENT MAP数据的NO-Dictionary模式恢复需要,所以SCAN操作在这里会填充SEG$.DAT和EXT$.DAT2个文件(文本文件仅仅为了便于诊断,所有程序实际依赖于PRM-DUL自带嵌入数据库DERBY的数据),并记录到DERBY数据库中。
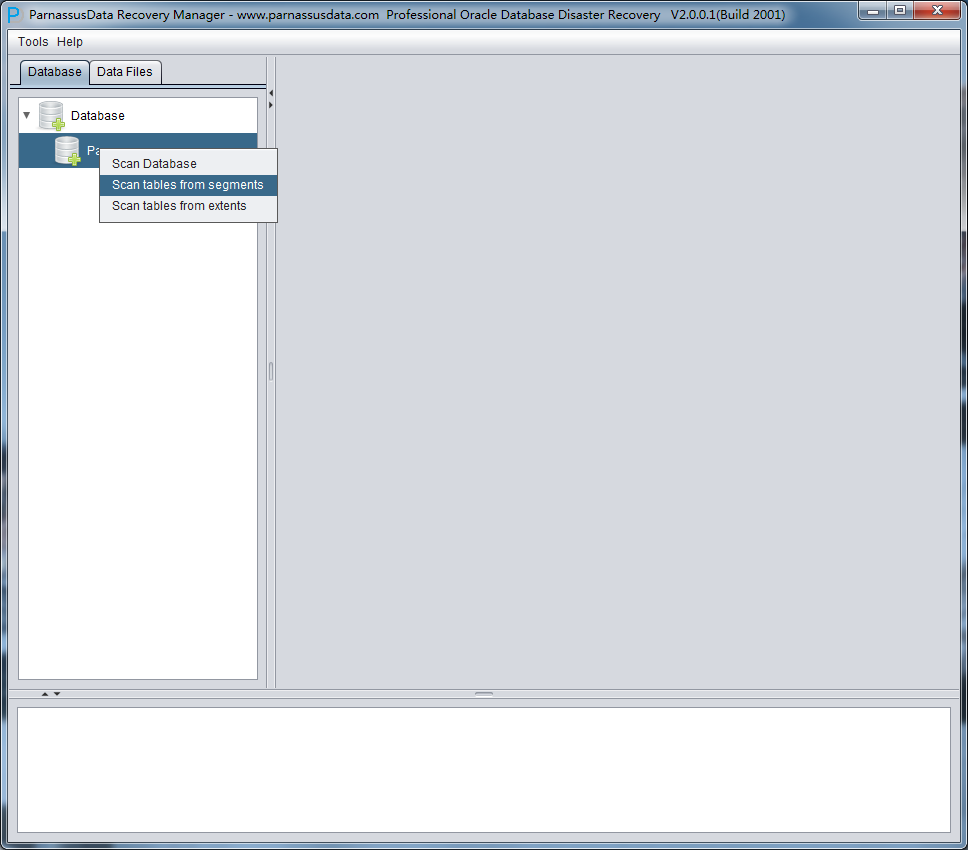
完成SCAN 后,主界面左侧出现数据库图标。
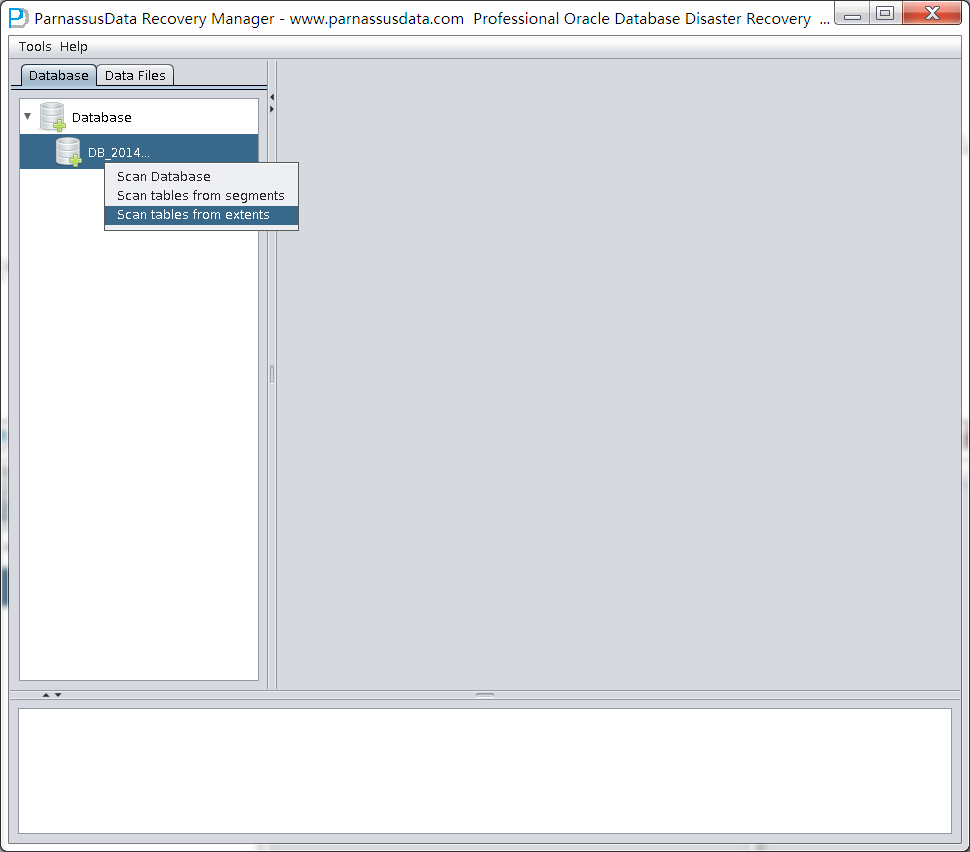
此时可以选择2种模式:
- Scan Tables From Segments,此模式适用于
- 丢失了SYSTEM表空间,但是所有的应用数据表空间均存在
- Scan Tables From Extents
- 不适用于Dictionary模式的Truncate表数据恢复
- 丢失了SYSTEM表空间,而且丢失了SEGMENT HEADER所在数据文件
通俗地说 除非你无法使用场景2中的方式来恢复已经TRUNCATE掉的数据,否则总是优先使用Scan Tables From Segments模式,如果发现Scan Tables From Segments下找不到你要的数据,再考虑使用Scan Tables From Extents模式。
我们优先采用Scan Tables From Segments模式
Scan Tables From Segments完成后可以点开主界面左边的树形图:
Scan Tables操作基于SEG$中的SEGMENT HEADER信息来构建数据表信息,树形图上每一个节点表示一个数据表段,其名字为obj+ 数据段上记录的DATA OBJECT ID 。
点中一个节点 并观察主界面右侧边栏:
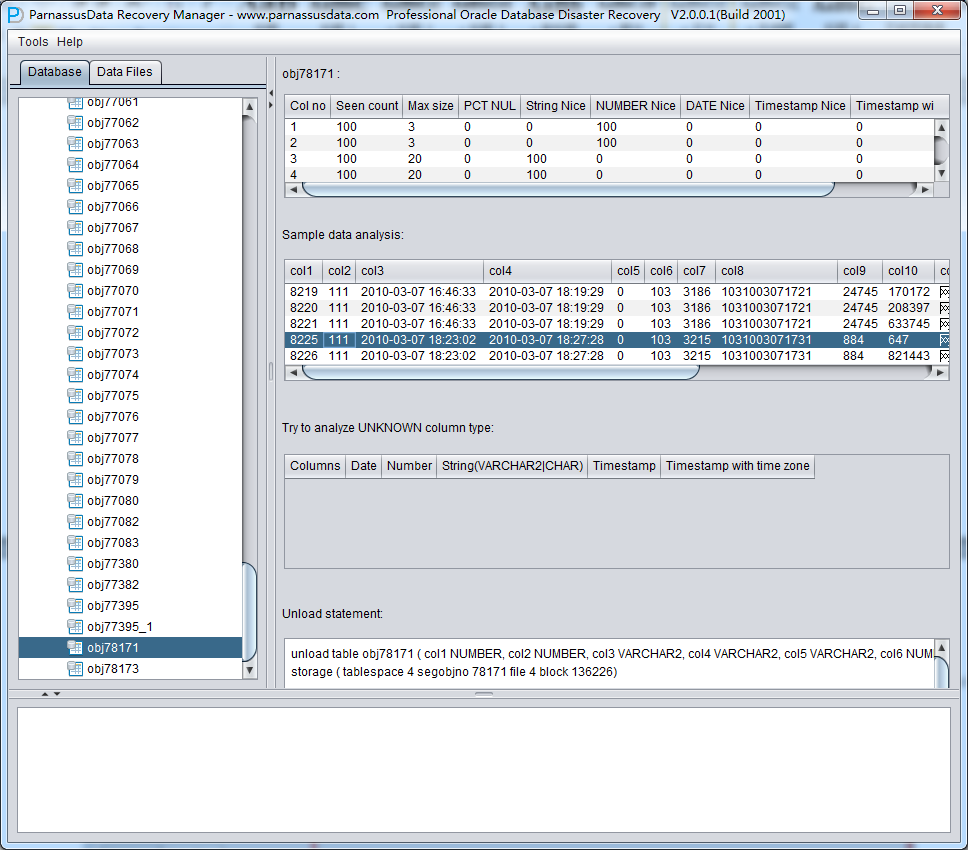
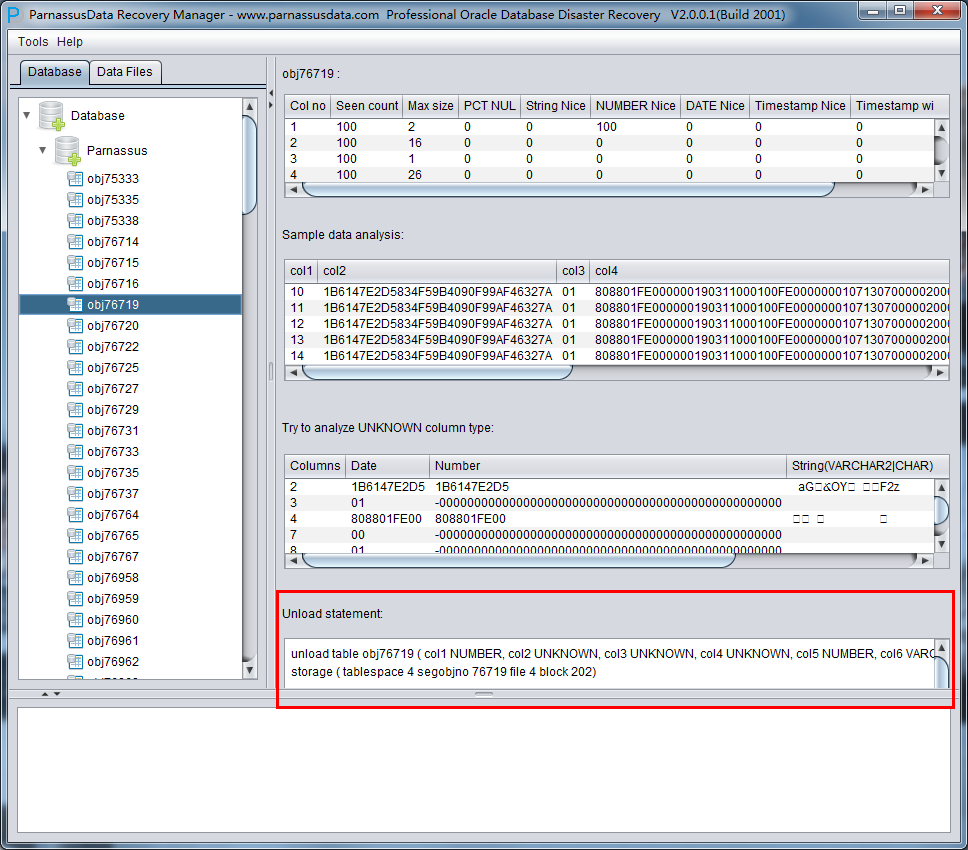
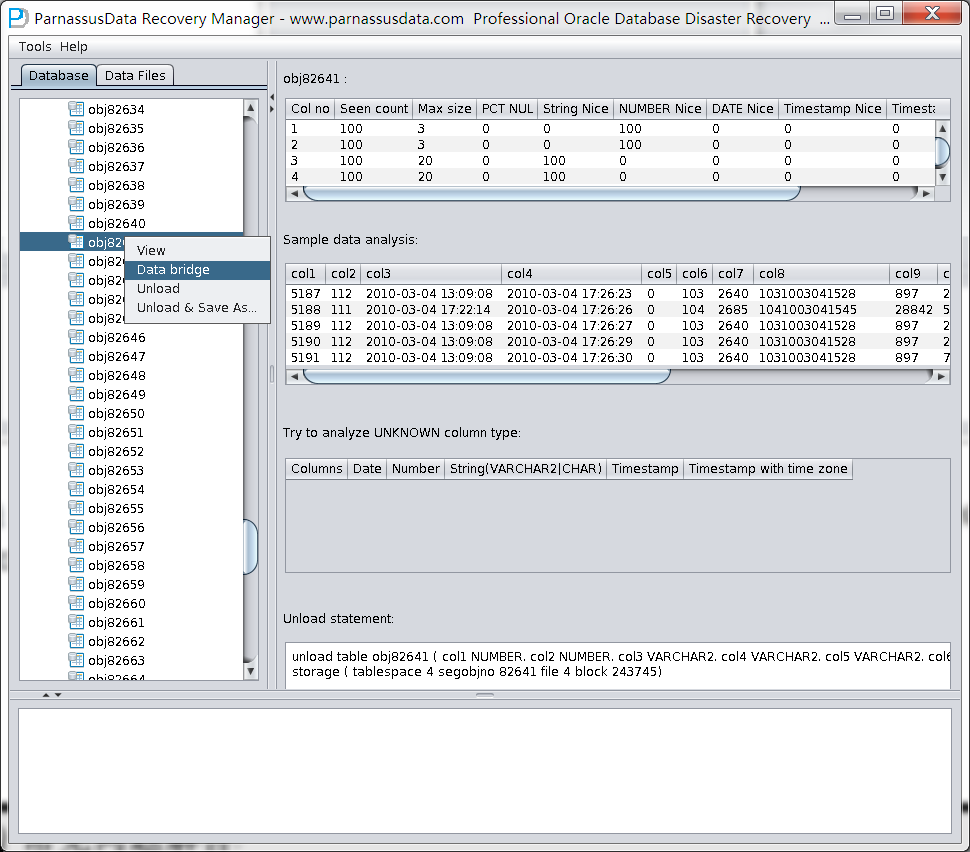
智能字段类型解析
由于丢失了SYSTEM表空间,故NO-Dictionary模式下缺乏数据表的结构信息,这些结构信息包括表上的字段名字和字段类型,而且在ORACLE中这些信息均只保存为字典信息,不会在数据表上存放。当用户只有应用表空间时,需要基于数据段上的ROW行数据来猜测每一个字段的类型,PRM-DUL采用先进JAVA类型预判技术,可以解析多达10来种主流数据类型;、
智能解析准确度超过90%,可以自动解决大部分场景。
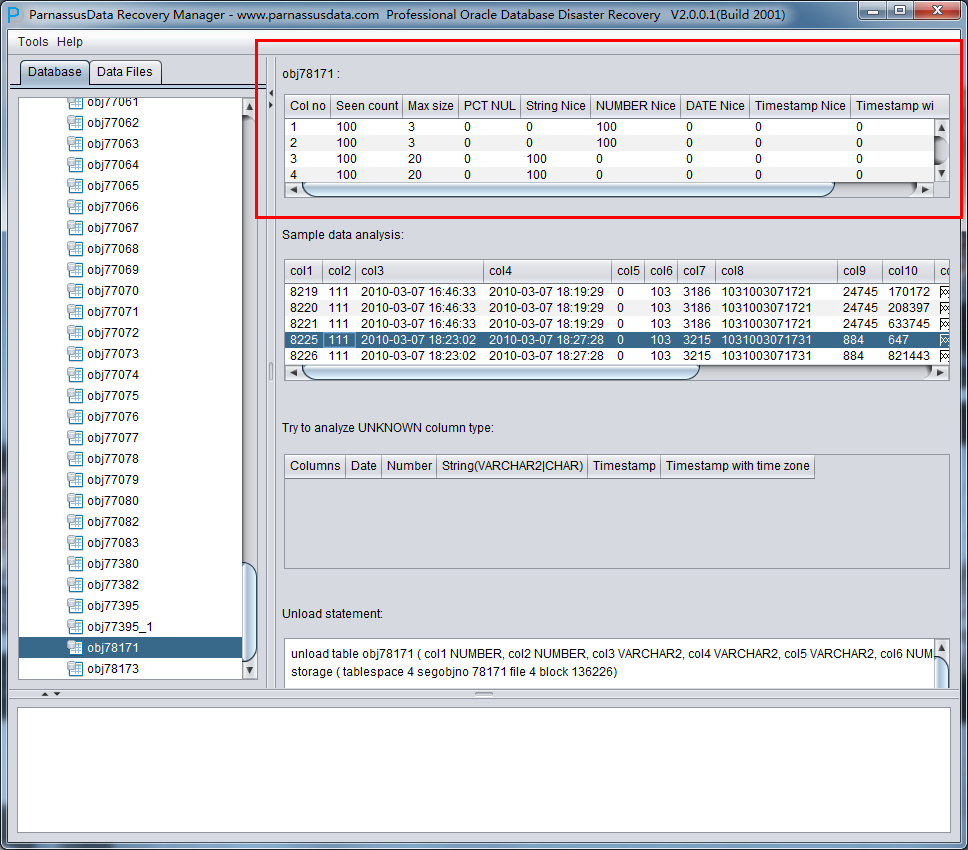
右侧边栏 上部各字段的含义:
- Col1 no 字段号
- Seen Count: 取到的行数
- MAX SIZE: 最大长度,单位为字节
- PCT NULL: 采样到的NULL的比例
- String Nice: 将该字段解析为字符串,并成功的比例
- Number Nice: 将该字段解析为数字,并成功的比例
- Date Nice: 将该字段解析为Date,并成功的比例
- Timestamp Nice: 将该字段解析为Timestamp,并成功的比例
- Timestamp with timezone Nice: 将该字段解析为Timestamp with timezone Nice,并成功的比例
示例数据分析Sample Data Analysis:
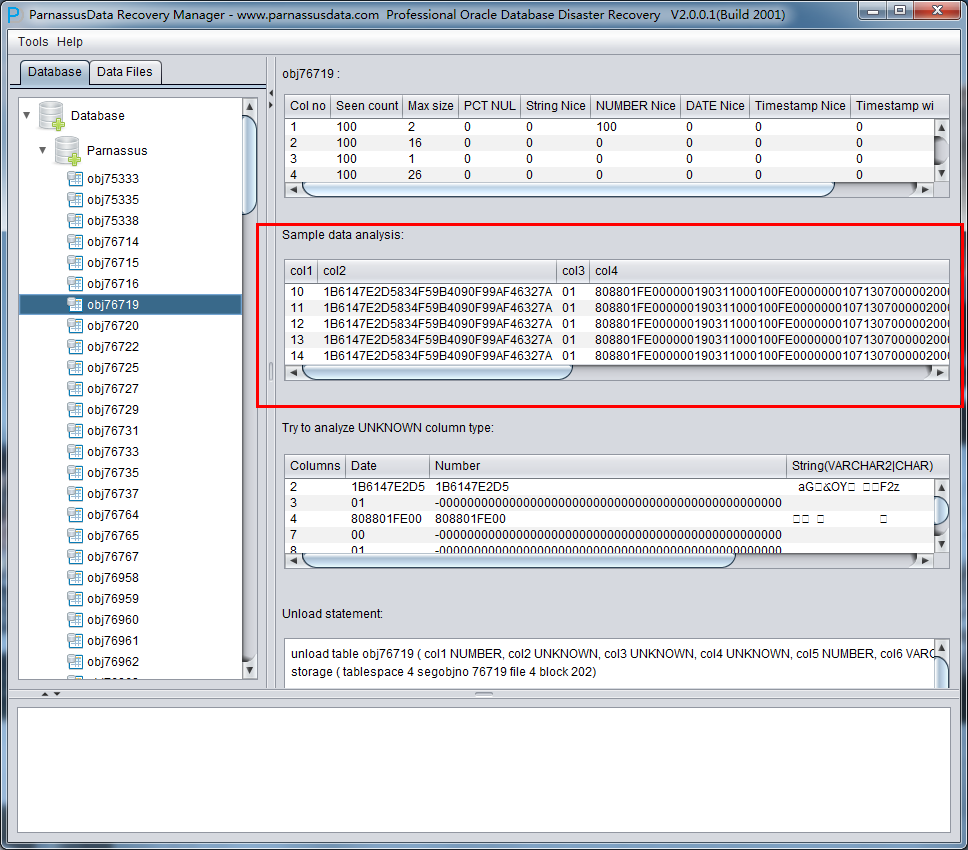
该部分依据智能字段类型解析的结果来解析10条数据,并显示解析结果。通过示例数据可以帮助用户了解实际该数据段中存放数据的情况。
如果数据段上记录条数不足10条,则显示所有记录。
TRY TO ANALYZE UNKNOWN column type:

该部分是对于智能字段类型分析不能100%确认的字段,尝试用各种字段类型来解析,并呈现给用户,以便用户自行判断其究竟是什么类型。
目前PRM-DUL还不支持的类型包括:
XDB.XDB$RAW_LIST_T、XMLTYPE、用户自定义类型等
Unload Statement:
这部分是PRM-DUL生成的UNLOAD语句,此生成的UNLOAD语句仅作为系统内部使用和PRM-DUL开发团队以及诗檀软件原厂支持工程师使用。
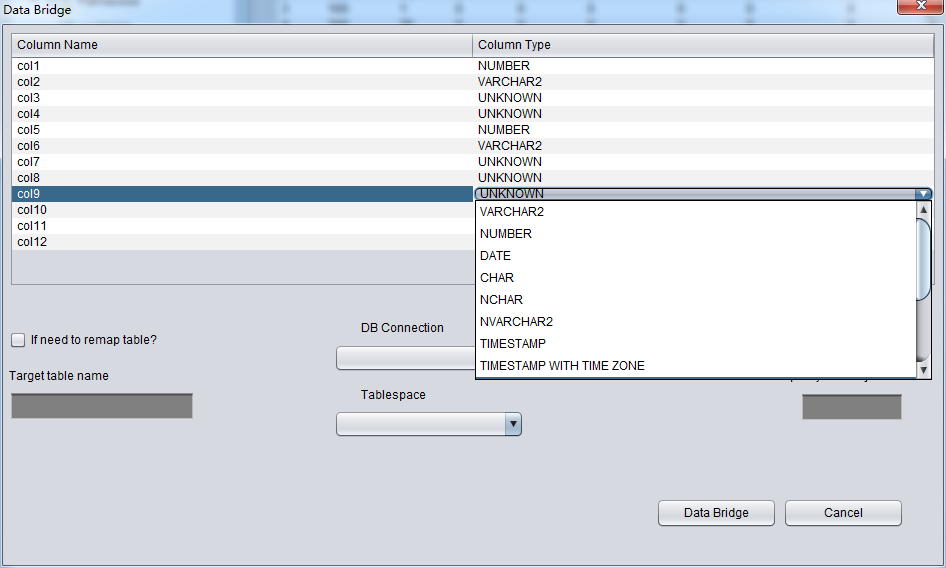
在此《Non-Dictionary Mode》非字典模式下同样可以采用常规和数据搭桥模式,与字典模式相比,主要的区别在于在非字典模式下数据搭桥时用户可以自行执行字段的类型,如下图中中部分字段类型为UNKNOWN,即未知的。这些字段可能是PRM-DUL目前还不支持的例如XML字段,也可能是PRM-DUL的智能解析没有顺利分析器类型。
如果用户知道这张表设计时的结构(也可以来源于应用开发商的文档),那么可以自行去填选正确的Column Type类型,以便PRM-DUL顺利将该表数据搭桥到目标数据库。
恢复场景5 误删除了SYSTEM表空间和部分应用表空间数据文件
D公司的SA由于误操作将在线业务数据库的SYSTEM表空间上的数据文件,以及部分应用表空间数据文件意外删除了。
此场景中由于部分应用表空间数据文件被删除了,这其中可能包括含有数据表的SEGMENT HEADER的数据文件,所以使用Scan Tables From Segment Header可能不如使用Scan Tables From Extents来的合适。
其简要步骤如下:
- 进入Recovery Wizard ,选择No-Dictionary模,加入所有可用的数据文件,执行Scan Database
- 选中数据库,并右键Scan Tables From Extents
- 对于PRM-DUL主界面上生成的对象树形图中的数据进行分析和导出/数据搭桥
- 其余操作与恢复场景4中一样
恢复场景6 从被损坏的ASM Diskgroup中拷贝出数据库数据文件
D公司开始采用ASM方案来替代文件系统和裸设备,但是由于使用的11.2.0.1版本ASM上Bug较多导致ASM DISKGROUP磁盘组无法加载MOUNT,通过多方修复ASM Disk Header无果。
此场景可以使用PRM-DUL的ASM Files Clone文件克隆功能从受损的ASM Diskgroup中拷贝出数据库数据文件。
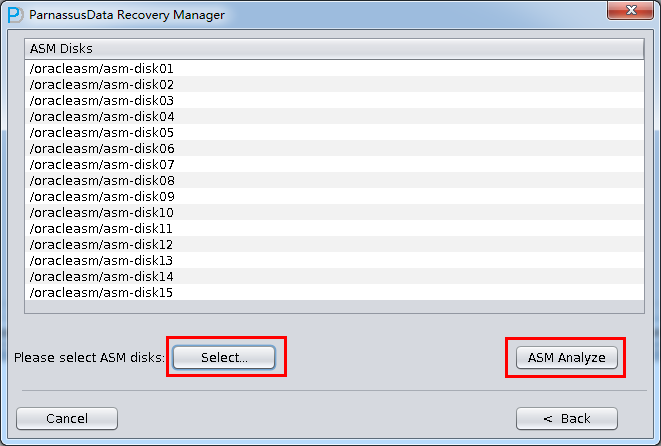
- 打开主界面,菜单栏Tools选择ASM File(s) Clone:
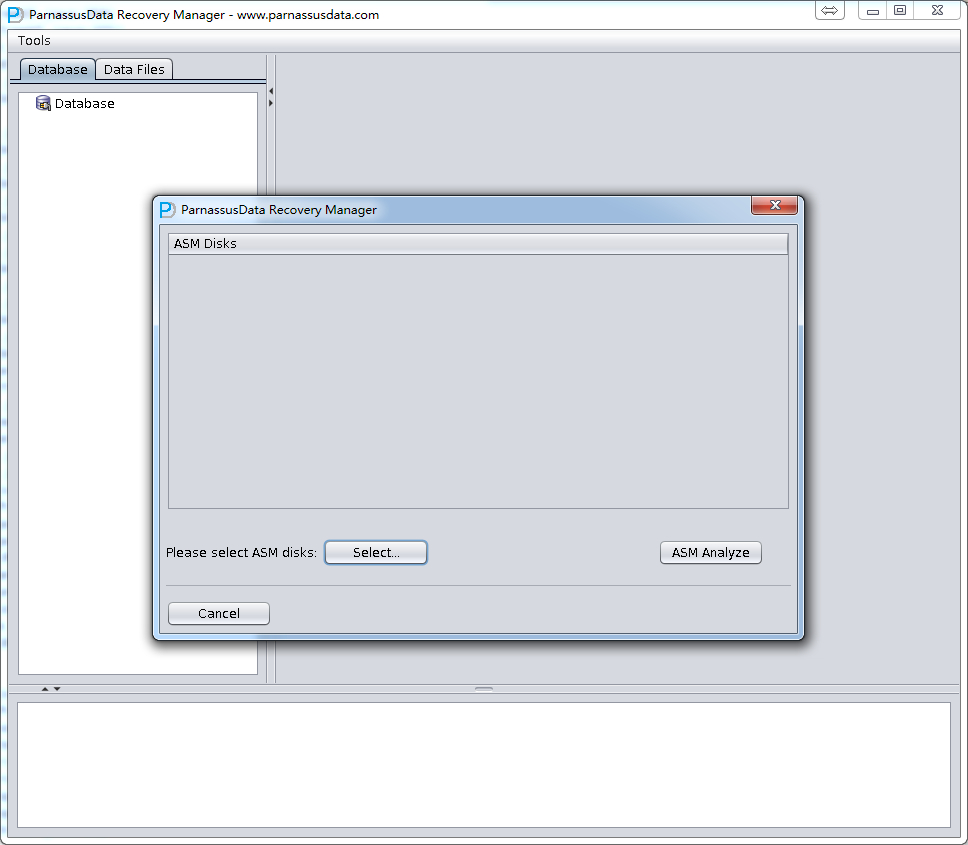
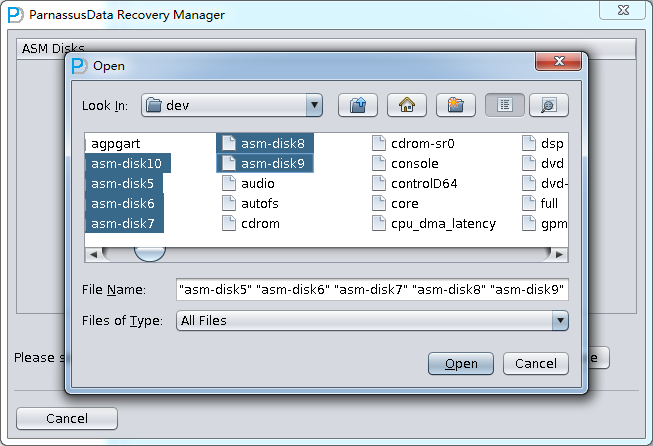
- 进入ASM Disks界面,点击SELECT…按钮加入仍可用的ASM Disks,如/dev/asm-disk5(linux);确保加入所有可用LUN后,点击ASM analyze按钮
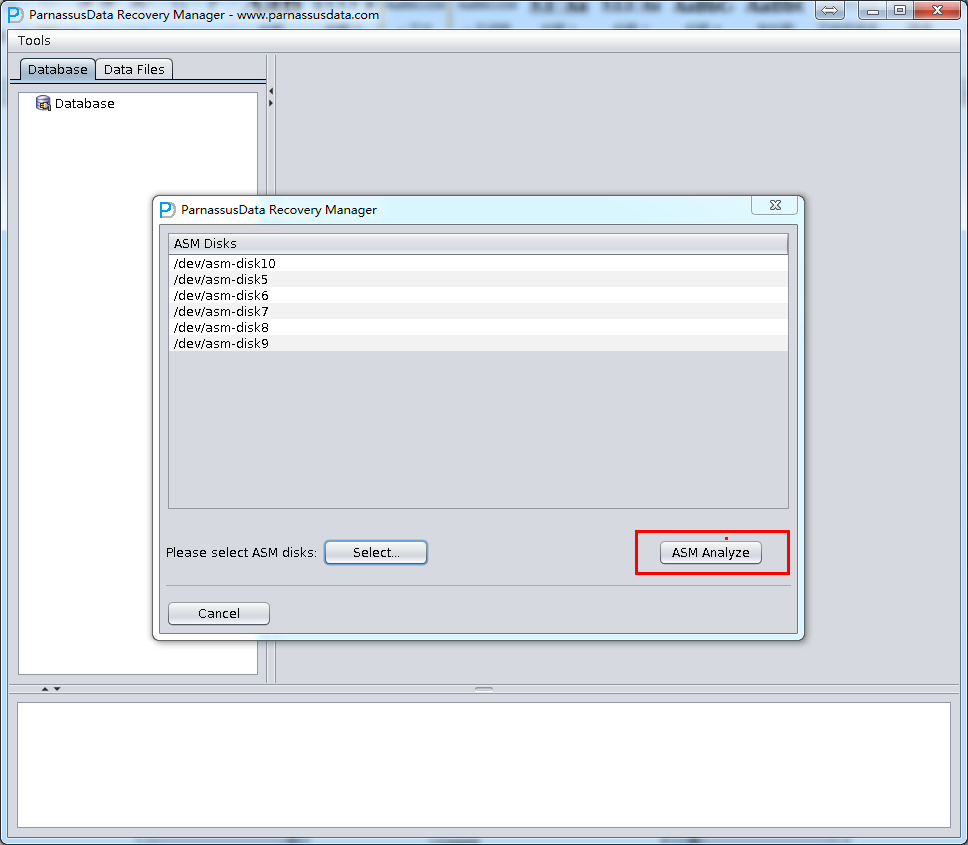
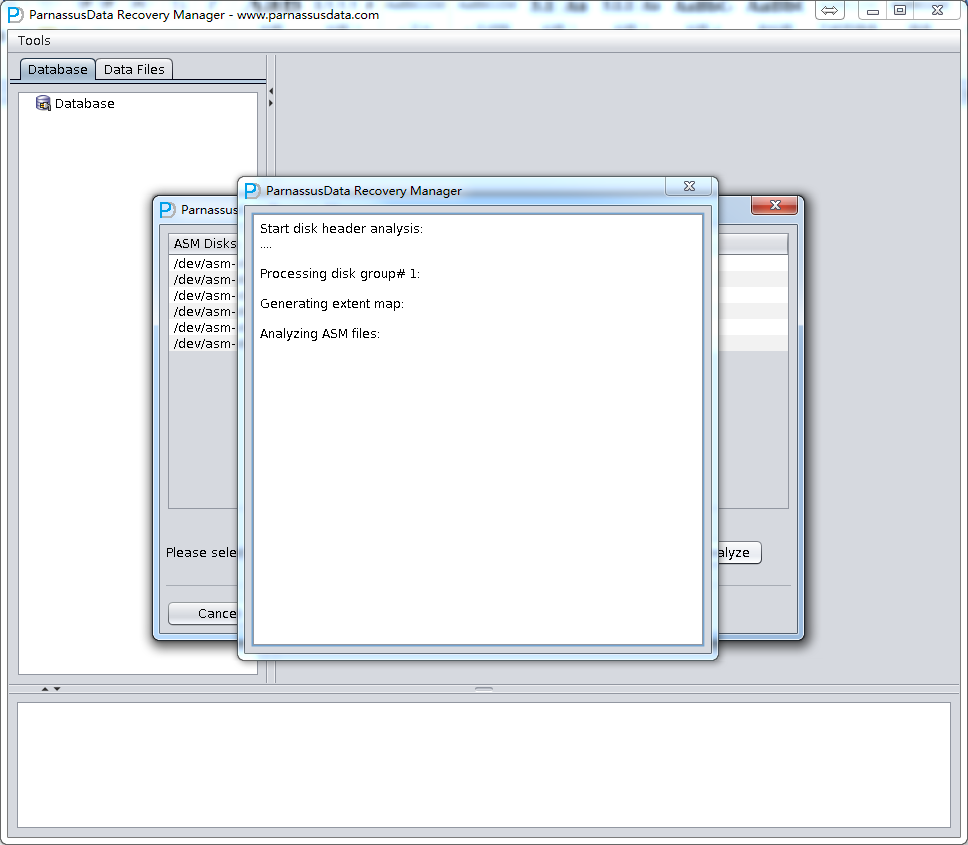
- ASM Files Clone将分析指定的ASM Disk的磁盘头,以便找出对应Disk group磁盘组中的文件,以及这些文件的分布位置(File Extent Map); 这些信息均将记录到Derby数据库中以便今后使用; 可以说PRM-DUL将ASM的所有Metadata元数据均收集、分析、并存储起来,并通过各种形式来完善PRM-DUL的基本功能,并以图形化地方式展现给用户。
- ASM Analyze分析完成后,PRM-DUL将列出找到的ASM上文件的列表,用户可以勾选那些文件需要被克隆,并指定文件克隆的目标文件夹。
之后点击ASM Clone按钮,进入文件克隆阶段。
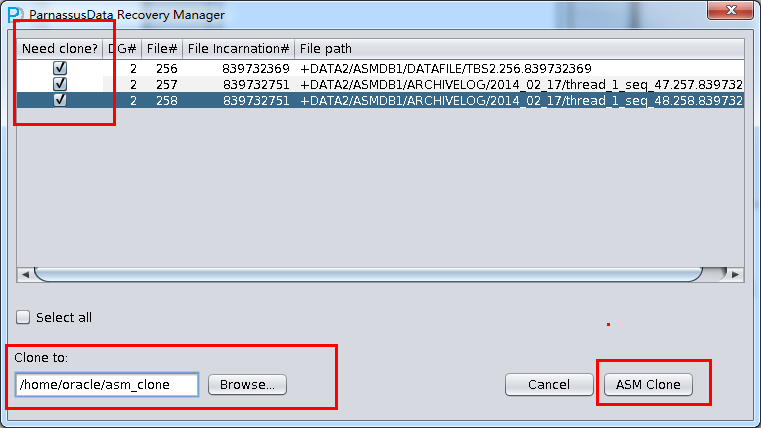
文件克隆阶段中,将列出ASM File的克隆进度,克隆完成后点击OK。
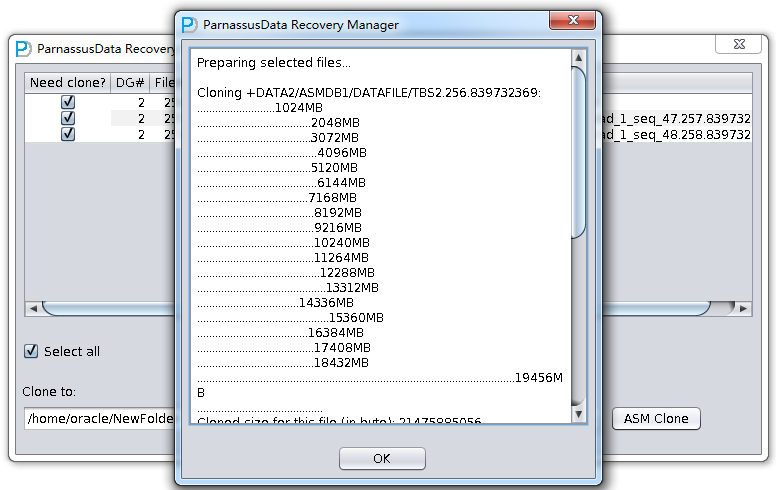
克隆阶段的进度日志输出如下:
| Preparing selected files…Cloning +DATA2/ASMDB1/DATAFILE/TBS2.256.839732369:
……………………..1024MB ………………………………..2048MB ………………………………..3072MB ………………………………….4096MB ………………………………..5120MB ………………………………….6144MB ……………………………….7168MB …………………………………8192MB …………………………………9216MB …………………………………10240MB …………………………………11264MB …………………………………..12288MB …………………………………….13312MB …………………………….14336MB ……………………………………..15360MB ……………………………….16384MB …………………………………17408MB …………………………………18432MB …………………………………………………………………………………………….19456MB …………………………………… Cloned size for this file (in byte): 21475885056
Cloned successfully!
Cloning +DATA2/ASMDB1/ARCHIVELOG/2014_02_17/thread_1_seq_47.257.839732751: …… Cloned size for this file (in byte): 29360128
Cloned successfully!
Cloning +DATA2/ASMDB1/ARCHIVELOG/2014_02_17/thread_1_seq_48.258.839732751: …… Cloned size for this file (in byte): 1048576
Cloned successfully!
All selected files were cloned done. |
- 可以通过dbv或者rman validate命令来验证克隆出来的数据文件,例如:
| rman target /
RMAN> catalog datafilecopy ‘/home/oracle/asm_clone/TBS2.256.839732369.dbf’;
cataloged datafile copy datafile copy file name=/home/oracle/asm_clone/TBS2.256.839732369.dbf RECID=2 STAMP=839750901
RMAN> validate datafilecopy ‘/home/oracle/asm_clone/TBS2.256.839732369.dbf’;
Starting validate at 17-FEB-14 using channel ORA_DISK_1 channel ORA_DISK_1: starting validation of datafile channel ORA_DISK_1: including datafile copy of datafile 00016 in backup set input file name=/home/oracle/asm_clone/TBS2.256.839732369.dbf channel ORA_DISK_1: validation complete, elapsed time: 00:03:35 List of Datafile Copies ======================= File Status Marked Corrupt Empty Blocks Blocks Examined High SCN —- —— ————– ———— ————— ———- 16 OK 0 2621313 2621440 1945051 File Name: /home/oracle/asm_clone/TBS2.256.839732369.dbf Block Type Blocks Failing Blocks Processed ———- ————– —————- Data 0 0 Index 0 0 Other 0 127
Finished validate at 17-FEB-14
|
对于使用ASMLIB的ASM环境要如何使用PRM-DUL呢?
其实也很简单,asmlib相关的ASM DISK在OS操作系统上会以ll /dev/oracleasm/disks 的形式存放,例如:直接将/dev/oracleasm/disks下的文件加入到PRM-DUL ASM DISK中即可
| $ll /dev/oracleasm/diskstotal 0brw-rw—- 1 oracle dba 8, 97 Apr 28 15:20 VOL001
brw-rw—- 1 oracle dba 8, 81 Apr 28 15:20 VOL002 brw-rw—- 1 oracle dba 8, 65 Apr 28 15:20 VOL003 brw-rw—- 1 oracle dba 8, 49 Apr 28 15:20 VOL004 brw-rw—- 1 oracle dba 8, 33 Apr 28 15:20 VOL005 brw-rw—- 1 oracle dba 8, 17 Apr 28 15:20 VOL006 brw-rw—- 1 oracle dba 8, 129 Apr 28 15:20 VOL007 brw-rw—- 1 oracle dba 8, 113 Apr 28 15:20 VOL008 |
直接将/dev/oracleasm/disks下的文件加入到PRM-DUL ASM DISK中即可。
恢复场景7 ASM下数据库无法打开
D公司的某套核心CRM库由于加入到ASM Diskgroup中的少量磁盘存在I/O问题,导致SYSTEM表空间的DBF数据文件发生讹误,导致数据库无法打开。
此时即可以通过PRM-DUL恢复软件从ASM Diskgroup中将DATAFILE全部克隆到文件系统上,如恢复场景6中所述,并进一步修复数据库。
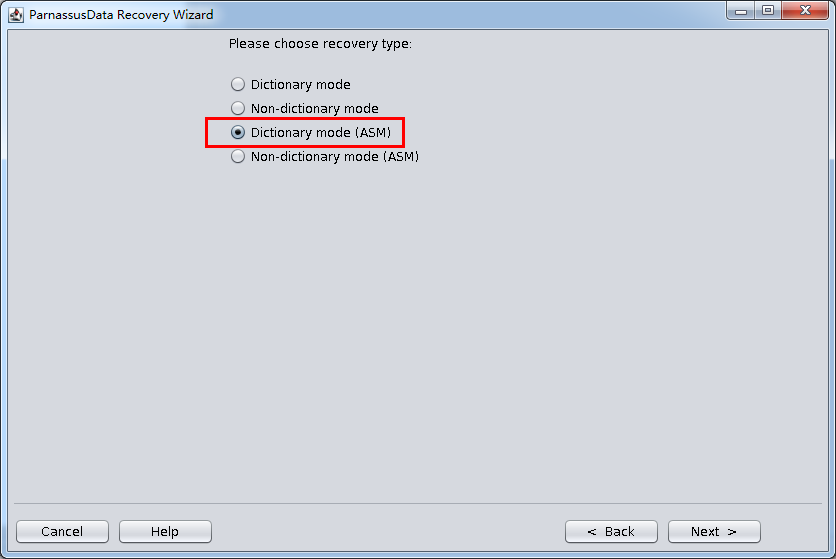
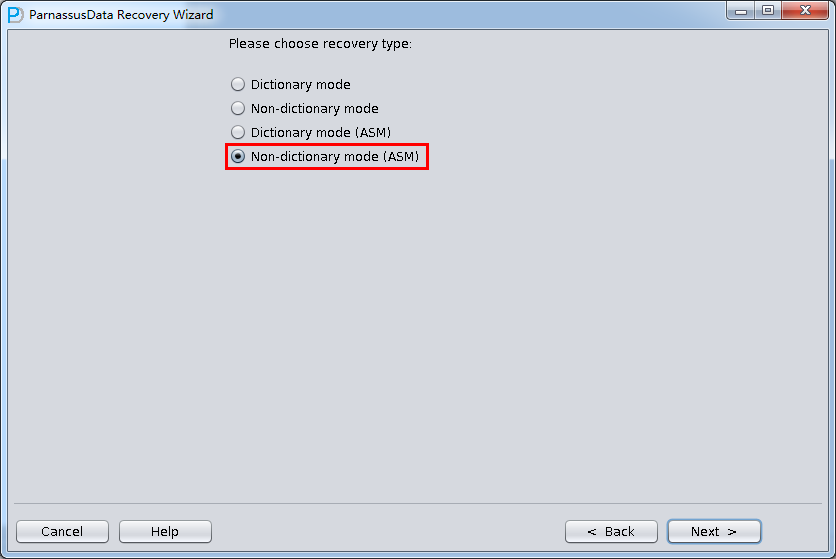
也可以通过PRM-DUL的《Dictionary Mode(ASM)》即基于ASM的字典模式来直接恢复问题数据库。其简要步骤如下:
- Recovery Wizard
- Dictionary Mode(ASM)
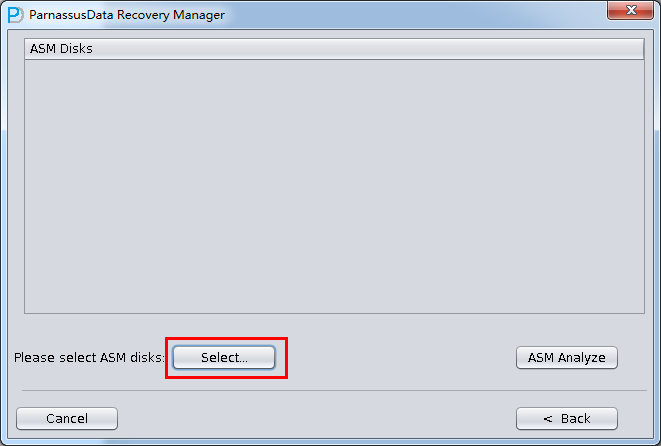
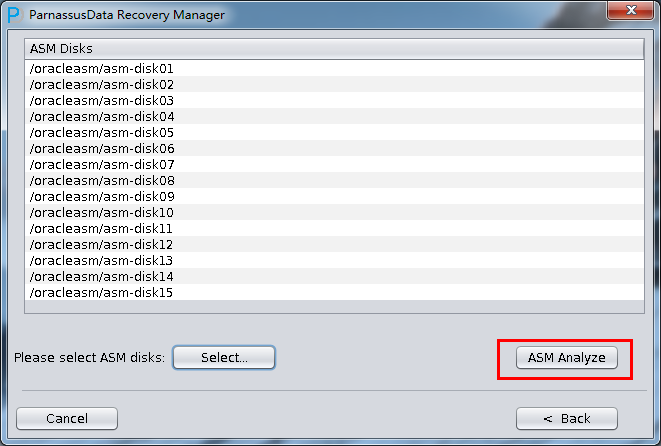
- 加入必要的ASM DISK(你所要恢复数据库的所在的ASM Disk Group的所有ASM DISK)
- 点击ASM analyze
- 为后面的数据文件选择合适的Endian
- 在ASM analze给出的数据文件列表中选中需要的数据文件,如果嫌麻烦且只有一套库,那么可以勾选”Select all”
- 点击load按钮,后续的恢复与《场景3》中类似
恢复场景8 ASM下误删或丢失SYSTEM表空间的恢复
D公司的运维人员误操作删除了核心数据库的SYSTEM表空间FILE#=1的数据文件以及部分应用表空间,导致数据库无法正常打开。
此场景下可以通过PRM-DUL的《Non-Dictionary Mode(ASM) 》ASM下的非字典模式基于现有的数据文件尽可能恢复出数据。
其简要的流程如下:
- Recovery Wizard
- Non-Dictionary Mode(ASM)
- 加入必要的ASM DISK(你所要恢复数据库的所在的ASM Disk Group的所有ASM DISK)
- 点击ASM analyze
- 为后面的数据文件选择合适的Endian以及字符集(由于是非字典模式所以需要手动选择字符集)
- 在ASM analyze给出的数据文件列表中选中需要的数据文件,如果嫌麻烦且只有一套库,那么可以勾选”Select all”
- 点击scan按钮,后续的恢复与《场景5》中类似
恢复场景9 对于误操作DROP TABLESPACE的数据恢复
D公司的员工需要删除某个无用的表空间即DROP TABLESPACE INCLUDING CONTENTS操作,但是在操作DROP TABLESPACE后,开发部门反映该被DROP掉的TABLESPACE上其实有一个SCHEMA的数据是有用且重要的,但现在表空间被DROP了,且无任何备份。
此时可以利用PRM-DUL的No-Dict模式去抽取被DROP TABLESPACE的对应的所有数据文件中的数据。 通过这种方式可以恢复大部分数据,但由于是非字典模式所以需要将恢复出来的表与应用数据表一一对应起来,此时一般需要应用开发维护人员介入,通过人工识别来分辨哪些数据属于哪张表。由于DROP TABLESPACE操作修改了数据字典,并在OBJ$中删除了对应表空间上的对象,所以无法从OBJ$上获得DATA_OBJECT_ID与OBJECT_NAME之间的对应关系。此时我们可以利用如下的方法,尽可能多得获取DATA_OBJECT_ID与OBJECT_NAME之间的对应关系。
| select tablespace_name,segment_type,count(*) from dba_segments where owner=’PARNASSUSDATA’ group by tablespace_name,segment_type;
TABLESPACE SEGMENT_TYPE COUNT(*) ———- ————— ———- USERS TABLE 126 USERS INDEX 136
SQL> select count(*) from obj$;
COUNT(*) ———- 75698
SQL> select current_scn, systimestamp from v$database;
CURRENT_SCN ———– SYSTIMESTAMP ————————————————————————— 1895940 25-4月 -14 09.18.00.628000 下午 +08:00
SQL> select file_name from dba_data_files where tablespace_name=’USERS’;
FILE_NAME ——————————————————————————– H:\PP\MACLEAN\ORADATA\PARNASSUS\DATAFILE\O1_MF_USERS_9MNBMJYJ_.DBF
SQL> drop tablespace users including contents;
表空间已删除。
C:\Users\maclean>dir H:\APP\MACLEAN\ORADATA\PARNASSUS\DATAFILE\O1_MF_USERS_9MNBMJYJ_.DBF 驱动器 H 中的卷是 entertainment 卷的序列号是 A87E-B792
H:\APP\MACLEAN\ORADATA\PARNASSUS\DATAFILE 的目录
找不到文件
因为drop tablespace 后该TABLESPACE对应的数据文件在 OS上被删除。
|
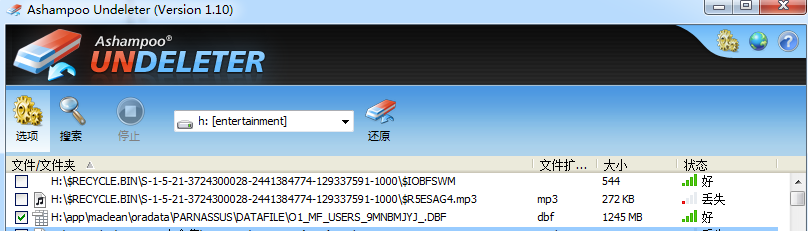
此时通过文件恢复工具例如Windows平台上可以使用UNDELETER将被误删除的数据文件还原出来
启动PRM-DUL => recovery Wizard => 非字典模式
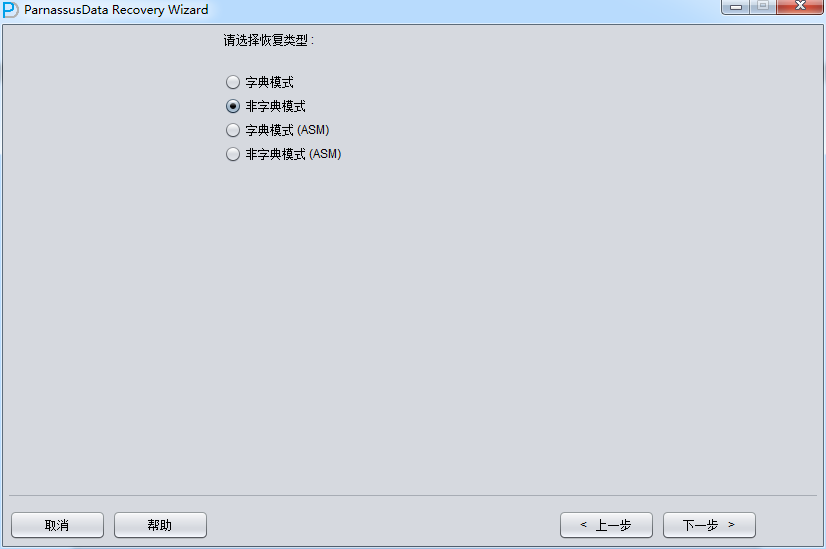
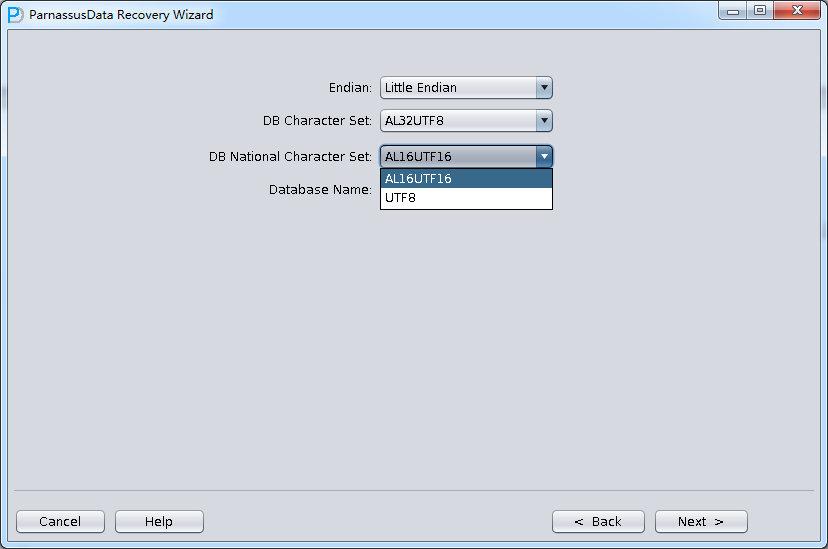
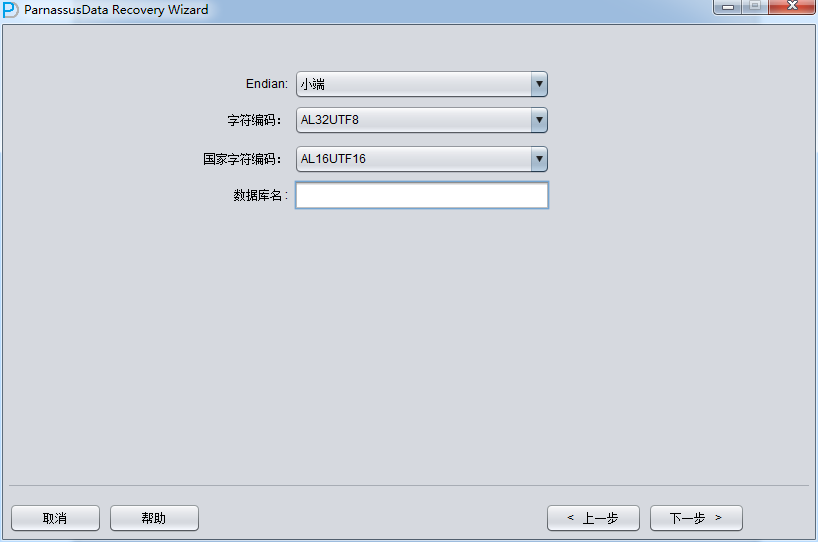
由于是非字典模式,所以需要自己选择合理的字符集!
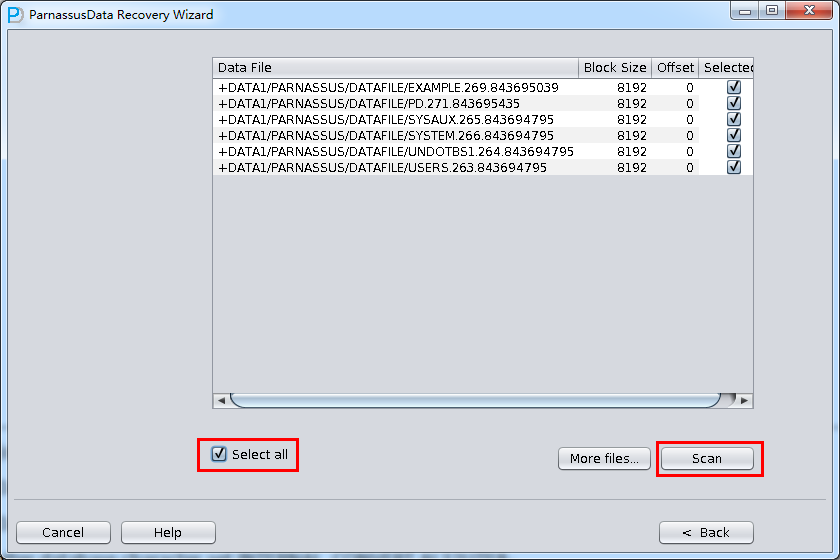
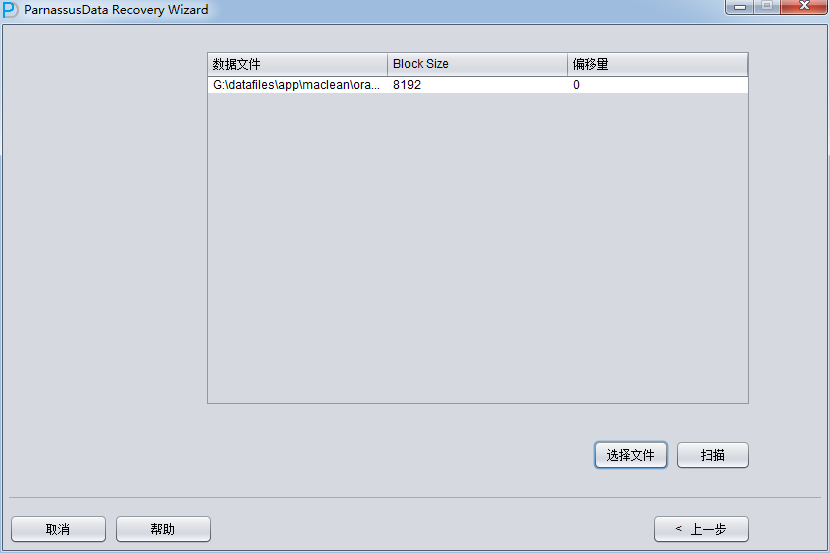
加入刚才恢复出来的数据文件并点击扫描
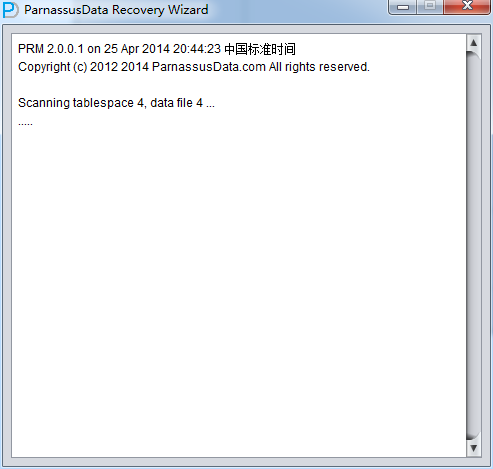
之后选择从段头/盘区扫描表,如果从段头扫描表未能找到所有表,则考虑用从盘区扫描:
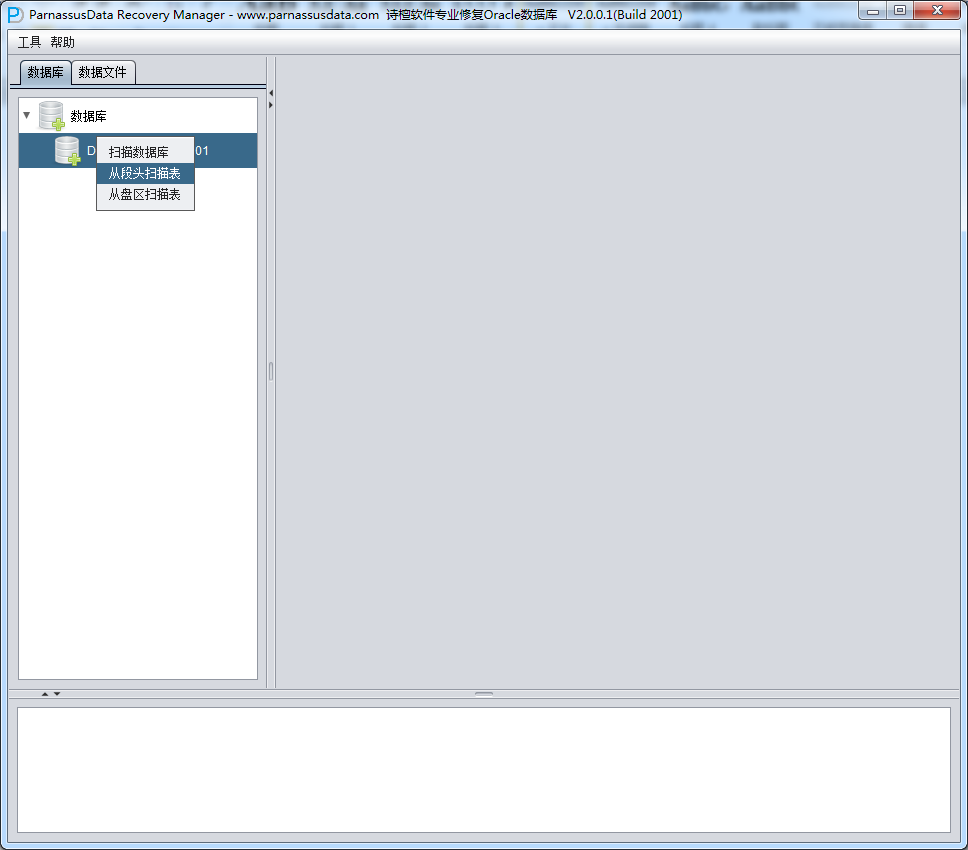
此时可以看到主界面树形图出现大量OBJXXXXX的表,这里的OBJXXXXX实际就是表的DATA_OBJECT_ID,一般如果有熟悉该套系统应用模式开发的技术人员可以通过浏览样本数据分析将该表与应用表对应起来:
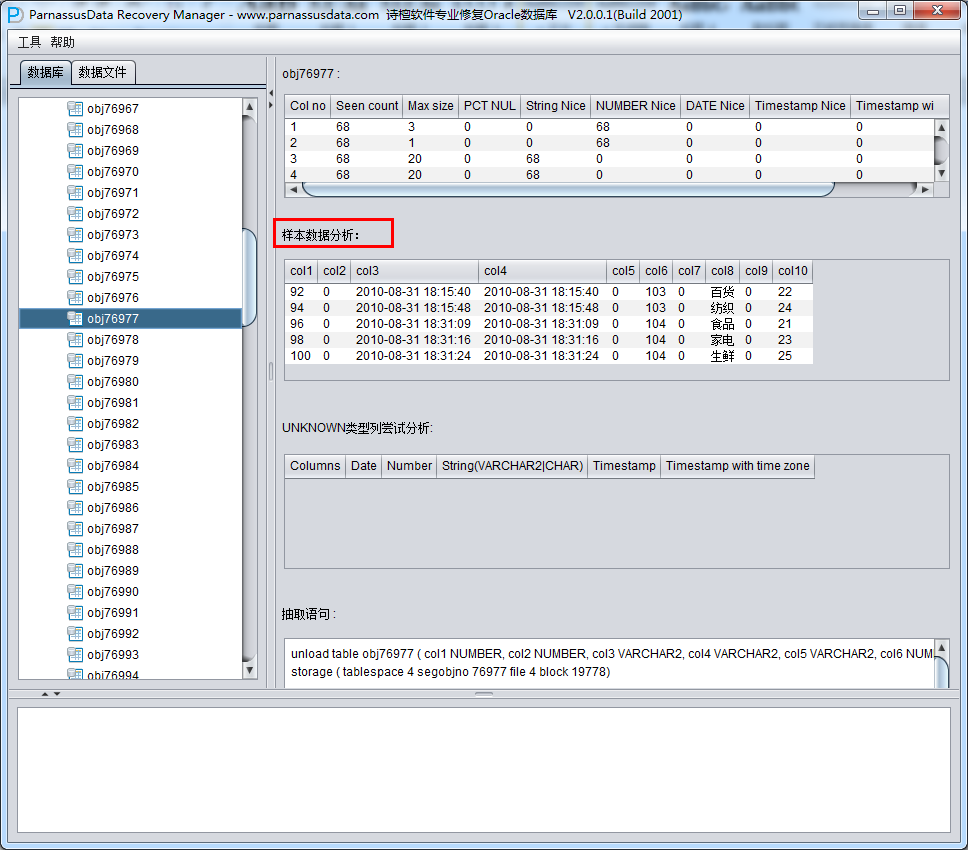
如果没有人可以帮忙对应数据与表之间的关系,则可以考虑使用如下的手段:
由于此例子中仅仅是DROP了TABLESPACE表空间,而数据库本身完全是可用的,则此时可以利用FLASHBACK QUERY来获得DATA_OBJECT_ID与表名之间的映射关系。
| SQL> select count(*) from sys.obj$;COUNT(*)
———- 75436
SQL> select count(*) from sys.obj$ as of scn 1895940; select count(*) from sys.obj$ as of scn 1895940 * 第 1 行出现错误: ORA-01555: 快照过旧: 回退段号 0 (名称为 “SYSTEM”) 过小
一开始想利用FLASHBACK QUERY来找出OBJ$上之前的记录,但是发现由于使用SYSTEM ROLLBACK SEGMENT所以会出现ORA-01555错误
此时可以考虑使用AWR视图DBA_HIST_SQL_PLAN,只要在最近7天中访问过该表一般可以从执行计划中获得OBJECT#和OBJECT_NAME的映射关系:
SQL> desc DBA_HIST_SQL_PLAN 名称 是否为空? 类型 —————————————– ——– ———————– DBID NOT NULL NUMBER SQL_ID NOT NULL VARCHAR2(13) PLAN_HASH_VALUE NOT NULL NUMBER ID NOT NULL NUMBER OPERATION VARCHAR2(30) OPTIONS VARCHAR2(30) OBJECT_NODE VARCHAR2(128) OBJECT# NUMBER OBJECT_OWNER VARCHAR2(30) OBJECT_NAME VARCHAR2(31) OBJECT_ALIAS VARCHAR2(65) OBJECT_TYPE VARCHAR2(20) OPTIMIZER VARCHAR2(20) PARENT_ID NUMBER DEPTH NUMBER POSITION NUMBER SEARCH_COLUMNS NUMBER COST NUMBER CARDINALITY NUMBER BYTES NUMBER OTHER_TAG VARCHAR2(35) PARTITION_START VARCHAR2(64) PARTITION_STOP VARCHAR2(64) PARTITION_ID NUMBER OTHER VARCHAR2(4000) DISTRIBUTION VARCHAR2(20) CPU_COST NUMBER IO_COST NUMBER TEMP_SPACE NUMBER ACCESS_PREDICATES VARCHAR2(4000) FILTER_PREDICATES VARCHAR2(4000) PROJECTION VARCHAR2(4000) TIME NUMBER QBLOCK_NAME VARCHAR2(31) REMARKS VARCHAR2(4000) TIMESTAMP DATE OTHER_XML CLOB
例如:
select object_owner,object_name,object# from DBA_HIST_SQL_PLAN where sql_id=’avwjc02vb10j4′
OBJECT_OWNER OBJECT_NAME OBJECT# ——————– —————————————- ———-
PARNASSUSDATA TORDERDETAIL_HIS 78688
可以利用如下脚本获得较多OBJECT_ID与OBJECT_NAME的映射关系
Select * from (select object_name,object# from DBA_HIST_SQL_PLAN UNION select object_name,object# from GV$SQL_PLAN) V1 where V1.OBJECT# IS NOT NULL minus select name,obj# from sys.obj$;
select obj#,dataobj#, object_name from WRH$_SEG_STAT_OBJ where object_name not in (select name from sys.obJ$) order by object_name desc;
另一个查询: SELECT tab1.SQL_ID, current_obj#, tab2.sql_text FROM DBA_HIST_ACTIVE_SESS_HISTORY tab1, dba_hist_sqltext tab2 WHERE tab1.current_obj# NOT IN (SELECT obj# FROM sys.obj$ ) AND current_obj#!=-1 AND tab1.sql_id =tab2.sql_id(+);
|
注意以上方法仅仅在用户确实找不到所要恢复的数据表的任何定义信息时使用(即用户找任何对该应用模式设计有了解的人、脚本和文档),且由于依赖于AWR数据,所以并不十分准确。
恢复场景10 对于误操作DROP TABLE的数据恢复
D公司的应用开发人员在ASM存储环境下,在没有任何备份的情况下DROP了系统中一张核心应用表,此时第一时间采用PRM-DUL可以恢复该DROP掉数据表的绝大部分数据。10g以后提供了 recyclebin回收站特性,可以首先通过查询DBA_RECYCLEBINS视图来确定被DROP掉的表是否在回收站中,如果在则优先通过回收站flashback to before drop,如果回收站中也没有了,则第一时间使用PRM-DUL恢复。
恢复简要流程如下:
- 首先将被DROP掉的数据表所在的表空间OFFLINE
- 通过查询数据字典或者LOGMINER找到被DROP掉数据表的DATA_OBJECT_ID,如果此步骤中得不到这个DATA_OBJECT_ID,则需要在NON-DICT非字典模式下
- 启动PRM-DUL,进入NON-DICT非字典模式,并加入被DROP掉数据表所在的表空间的所有数据文件,之后SCAN DATABASE+SCAN TABLE from Extent MAP
- 通过DATA_OBJECT_ID定位到展开对象树形图中对应的数据表,采用DataBridge模式插回到源数据库中
| SQL> select count(*) from “MACLEAN”.”TORDERDETAIL_HIS”;COUNT(*)
———- 984359
SQL> SQL> create table maclean.TORDERDETAIL_HIS1 as select * from maclean.TORDERDETAIL_HIS;
Table created.
SQL> drop table maclean.TORDERDETAIL_HIS;
Table dropped. |
可以通过logminer或者《恢复场景9》中提供的方法得到大致的DATA_OBJECT_ID,使用LOGMINER则大致的脚本如下:
| EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => ‘/oracle/logs/log1.f’, OPTIONS => DBMS_LOGMNR.NEW);EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => ‘/oracle/logs/log2.f’, OPTIONS => DBMS_LOGMNR.ADDFILE);
Execute DBMS_LOGMNR.START_LOGMNR(DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG+DBMS_LOGMNR.COMMITTED_DATA_ONLY);
SELECT * FROM V$LOGMNR_CONTENTS ;
EXECUTE DBMS_LOGMNR.END_LOGMNR; |
即便这里得不到DATA_OBJECT_ID,在数据表不多的情况下还是可以通过人工识别数据来定位我们需要恢复的数据表。
首先将被DROP掉的数据表所在的表空间OFFLINE
| SQL> select tablespace_name from dba_segments where segment_name=’TPAYMENT’;TABLESPACE_NAME
—————————— USERS
SQL> select file_name from dba_data_files where tablespace_name=’USERS’;
FILE_NAME —————————————————————- +DATA1/parnassus/datafile/users.263.843694795
SQL> alter tablespace users offline;
Tablespace altered. |
启动PRM-DUL到NON-DICT模式,并加入对应的数据文件选择SCAN DATABASE+SCAN TABLE From Extents:
加入相关ASM Diskgroup所有相关的ASM Disks后点击ASM analyze

由于是在非字典模式下所有需要输入必要的字符集信息:
选择被DROP掉的表所在的数据文件即可,多余的数据文件可不选择,并点击SCAN:
点中生成的数据库名,并右键选择scan tables from extents:
通过人工识别发现DATA_OBJECT_ID=82641的数据对应于被DROP掉的TORDERDETAIL_HIS表,通过DataBridge技术将其传输回源库别的表空间中。
FAQ 常见问题解答
- 我不知道我的数据库的字符集信息怎么办?
你可以通过ORACLE告警日志alert.log来大致了解你的数据库字符集信息,例如:
| [oracle@mlab2 trace]$ grep -i character alert_Parnassus.logDatabase Characterset is US7ASCIIDatabase Characterset is US7ASCII
alter database character set INTERNAL_CONVERT AL32UTF8 Updating character set in controlfile to AL32UTF8 Synchronizing connection with database character set information Refreshing type attributes with new character set information Completed: alter database character set INTERNAL_CONVERT AL32UTF8 alter database national character set INTERNAL_CONVERT UTF8 Completed: alter database national character set INTERNAL_CONVERT UTF8 Database Characterset is AL32UTF8 Database Characterset is AL32UTF8 Database Characterset is AL32UTF8 |
- 为什么我使用PRM-DUL总是闪退或者报一些例如” gc warning: Repeated allocation of very large block (appr.size 512000)”的GC报错?
就目前ParnassuData看到的案例而言,绝大多数此类问题都是由于使用了非推荐的JAVA环境所造成的;特别是在Linux平台上使用了redhat gcj java的话很容易造成该问题。ParnassusData建议用户使用ORACLE提供的JDK1.6以上环境运行PRM-DUL,可以直接使用$JAVA_HOME/bin/java –jar PRM-DUL.jar来启动PRM-DUL。
各个操作系统平台的JDK 1.6的下载连接如下:
- 如果我发现了PRM-DUL的bug,我应当如何report bug给ParnassusData?
ParnassusData欢迎任何人给我们report bug,只需要发邮件到report_bugs@parnassusdata.com就好了, 建议提交bug时附上您详细的运行环境 包括操作系统、JAVA运行环境和ORACLE数据库版本的环境信息。
- 我启动PRM-DUL出现下面的错误怎么办?
Error: no `server’ JVM at `D:\Program Files (x86)\Java\jre1.5.0_22\bin\server\jvm.dll’.
这是由于用户的环境中安装的是JAVA Runtime Environment JRE,而没有安装JDK。而启动PRM-DUL的脚本中加入了-sever的选项,该选项在JRE 版本1.5之前是没有的,所以会出现该错误。
ParnassusData建议用户使用ORACLE提供的JDK1.6以上环境运行PRM-DUL。
各个操作系统平台的JDK 1.6的下载连接如下:
- 为什么我在使用PRM-DUL时中文显示乱码?
目前已知有2种可能导致该中文显示乱码问题:
- PRM-DUL所运行操作系统环境没有安装中文语言包,例如PRM-DUL运行在没有安装中文语言包的Linux平台上,那么PRM-DUL作为一个软件是无法正常显示中文的。
- 操作系统已经安装了必要的语言包,但启动PRM-DUL使用的是JDK 1.4的JAVA运行环境,同样可能出现中文乱码,该问题建议使用JDK 1.6或以上版本来解决
- PRM-DUL是否支持LOB大对象字段?
PRM-DUL支持CLOB、NCLOB、BLOB等大对象字段,包括分区表、Disable/Enable Storage in ROW等情况均支持对LOB的数据搭桥模式,LOB数据一样无需落地,就可以应用到远程目标数据库中。
对于LOB大对象字段不支持普通的UNLOAD抽取方式,因为抽取方式在数据导入时会十分麻烦;所以我们也推荐用户尽可能使用DataBridge数据搭桥模式。
- PRM-DUL有什么讨论的论坛吗?
目前我们有中文的PRM-DUL讨论BBS版面,地址为:
http://t.askmac.cn/forum-24-1.html
Find More
Resource : http://www.parnassusdata.com/resources/
Technical Support: service@parnassusdata.com
Sales: sales@parnassusdata.com
Download Software: http://www.parnassusdata.com/
Contact: http://www.parnassusdata.com/zh-hans/contact
Conclusion
ParnassusData Corporation , Shanghai , GaoPing Road No. 733 . China
Phone: (+86) 13764045638
ParnassusData.com
Facebook: http://www.facebook.com/parnassusData
Twitter: http://twitter.com/ParnassusData
Weibo: http://weibo.com/parnassusdata
Copyright © 2013, ParnassusData and/or its affiliates. All rights reserved. This document is provided for information purposes only and the contents hereof are subject to change without notice. This document is not warranted to be error-free, nor subject to any other warranties or conditions, whether expressed orally or implied in law, including implied warranties and conditions of merchantability or fitness for a particular purpose. We specifically disclaim any liability with respect to this document and no contractual obligations are formed either directly or indirectly by this document. This document may not be reproduced or transmitted in any form or by any means, electronic or mechanical, for any purpose, without our prior written permission.
Oracle and Java are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.
AMD, Opteron, the AMD logo, and the AMD Opteron logo are trademarks or registered trademarks of Advanced Micro Devices. Intel and Intel Xeon are trademarks or registered trademarks of Intel Corporation. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. UNIX is a registered trademark licensed through X/Open Company, Ltd. 0410
Copyright © 2014 ParnassusData Corporation. All Rights Reserved.

Comment