
结构化查询语言
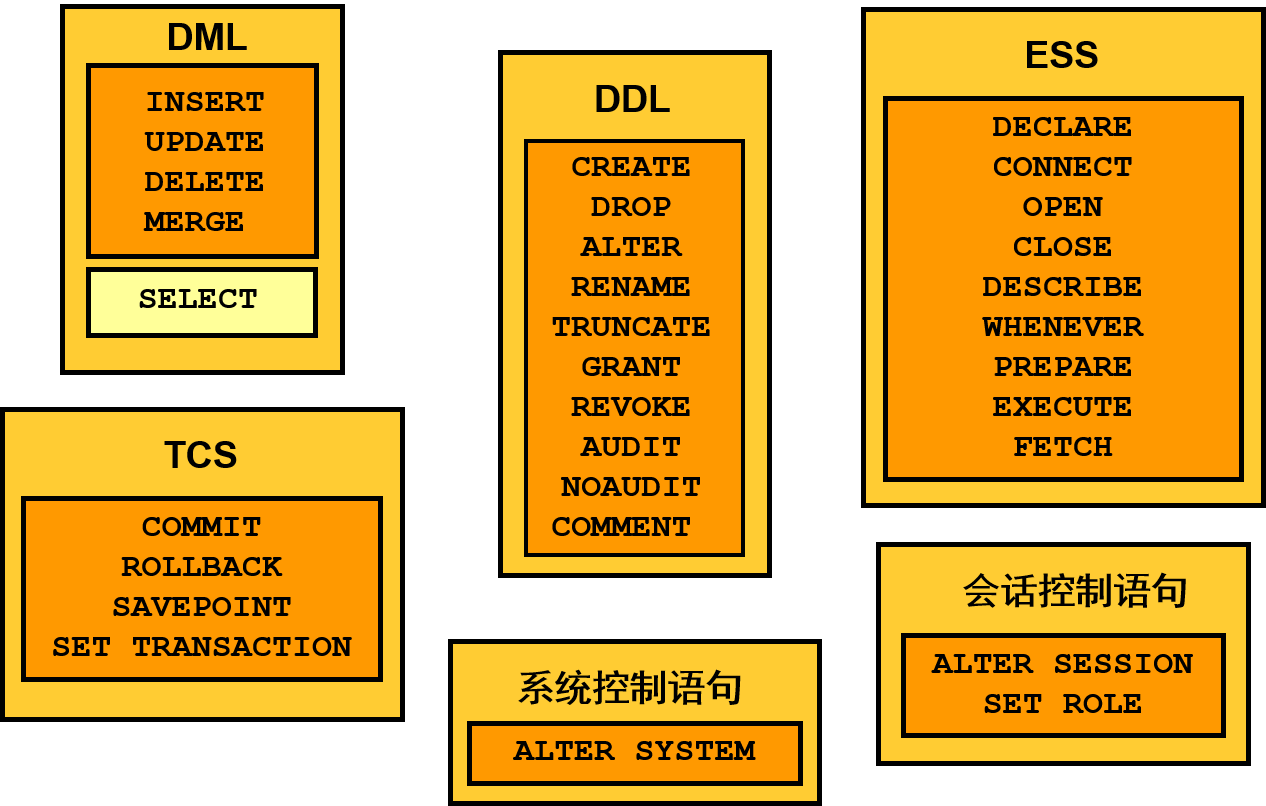
SQL 是所有程序和用户访问 Oracle DB 中的数据时使用的语言。借助应用程序和 Oracle 工具,用户通常不需要直接使用 SQL 访问数据库,但这些应用程序在执行用户请求时必须使用 SQL。Oracle 尽量遵守行业公认的标准,并积极参加 SQL 标准委员会(ANSI 和 ISO)的工作。最新的 SQL 标准是在 2003 年 7 月采用的,通常称为 SQL:2003。可以将 SQL 语句分为六大类:
- 数据操纵语言 (DML) 语句操纵或查询现有方案对象中的数据。
- 数据定义语言 (DDL) 语句定义、修改方案对象的结构以及删除方案对象。
- 事务处理控制语句 (TCS) 管理 DML 语句所做的更改,以及将 DML 语句分组到事务处理中。
- 系统控制语句更改 Oracle DB 实例的属性。
- 会话控制语句管理特定用户会话的属性。
- 嵌入式 SQL (ESS) 语句将 DDL、DML 和 TCS 整合到过程语言程序(如 PL/SQL 和 Oracle 的预编译器)中。这种整合是使用幻灯片中 ESS 类别下列出的语句完成的。
注: SELECT 语句是最常用的语句。虽然本课程的其余部分主要侧重于查询,但仍必须注意这一点:任何类型的 SQL 语句都可能需要优化。
SQL 语句表示形式
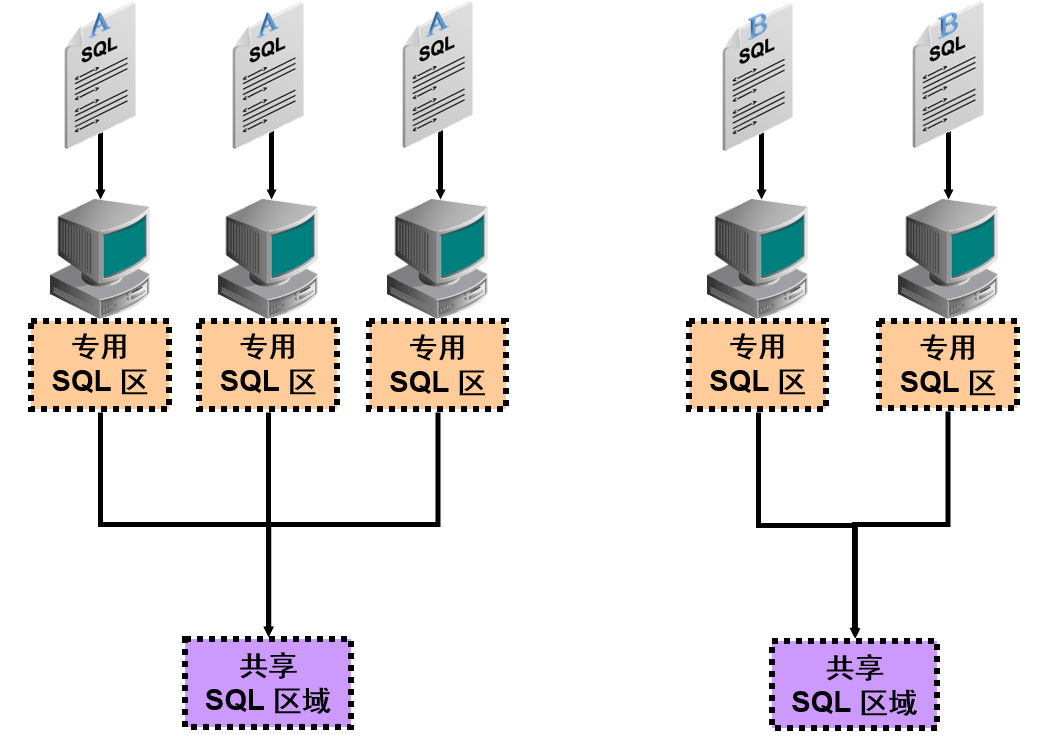
Oracle DB 使用一个共享 SQL 区域和一个专用 SQL 区域来表示它运行的每个 SQL 语句。Oracle DB 可识别两个用户执行相同 SQL 语句的情况,从而为这些用户重用共享 SQL 区域。但是对于语句的专用 SQL 区域,每个用户必须有一个单独的副本。
共享 SQL 区域包含执行语句所必需的所有优化信息,而专用 SQL 区域包含与语句的某一次执行相关的所有运行时信息。
Oracle DB 通过对多次运行的 SQL 语句使用一个共享 SQL 区域来节省内存。当许多用户运行同一个应用程序时,同一 SQL 语句通常会多次运行。
注:在评估语句是否相同或相似时,Oracle DB 会考虑用户和应用程序直接发出的 SQL 语句,以及 DDL 语句内部发出的递归 SQL 语句。
SQL 语句实施

对新的 SQL 语句进行语法分析时,Oracle DB 会将共享池中的内存分配给共享 SQL 区域中的存储。该内存的大小取决于语句的复杂性。如果已经分配了整个共享池,则 Oracle DB 可使用修改后的最近最少使用 (LRU) 算法,对共享池中的项目取消空间分配,直到有足够的空闲空间供新语句的共享 SQL 区域使用。如果 Oracle DB 取消分配某个共享 SQL 区域,则在下一次执行关联的 SQL 语句时必须重新分析该语句,并为其重新分配另一共享 SQL 区域。
SQL 语句处理:概览
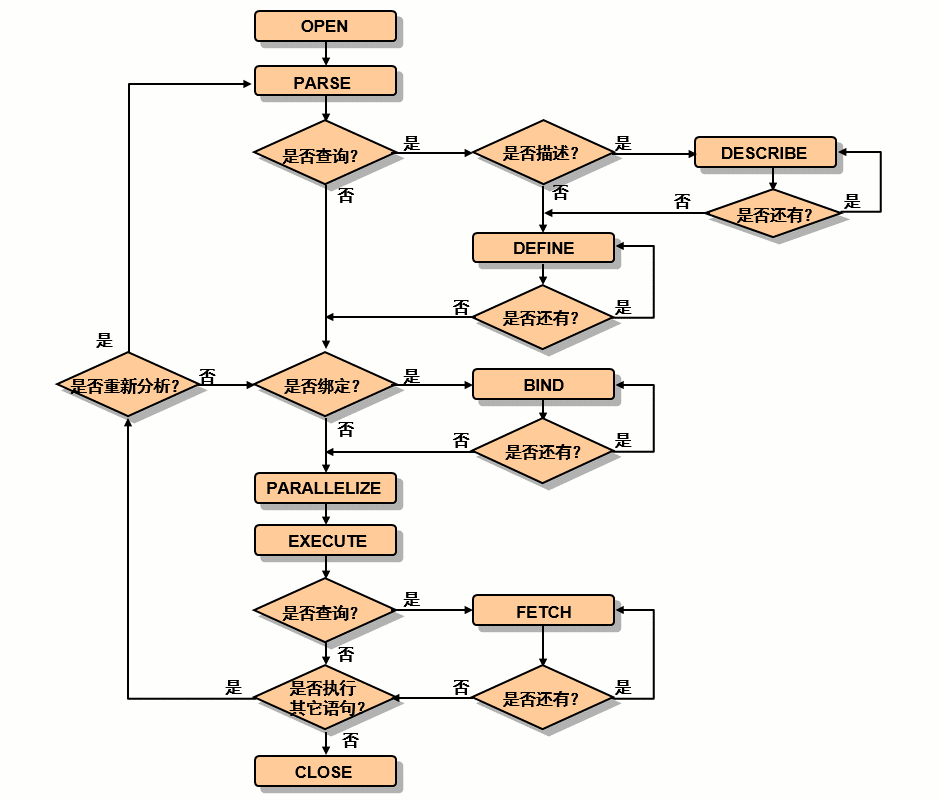
SQL 语句处理:步骤
- 创建游标。
- 分析语句。
- 描述查询结果。
- 定义查询输出。
- 绑定变量。
- 语句并行化。
- 执行语句。
- 提取查询的行。
- 关闭游标。
请注意,并非所有语句都需要执行以上全部步骤。例如,非并行的 DDL 语句只需要两个步骤:创建和分析。
语句并行化需要确定语句是否可并行化,这与实际建立并行执行结构不同。
步骤 1:创建游标
- 游标是专用 SQL 区域的句柄或名称。
- 它包含语句处理所需的信息。
- 它是在执行 SQL 语句之前通过编程接口调用创建的。
- 游标结构独立于其包含的 SQL 语句。
游标可以看成是客户机程序中的游标数据区域与 Oracle 服务器的数据结构之间的关联。大多数 Oracle 工具向用户隐藏了许多游标处理过程,但 Oracle 调用接口 (OCI) 程序需要有一定的灵活性,以便可以单独处理查询执行的每个部分。因此,预编译器允许使用显式游标声明。也可以使用 DBMS_SQL 程序包完成以上大部分操作。
句柄类似于杯子的把手。如果持有了句柄,就持有了游标。它是某个特定游标的唯一标识符,一次只能由一个进程获取。
要处理 SQL 语句,程序必须要有一个打开的游标。游标包含一个指向当前行的指针。指针会在提取行时移动,直到不再有要处理的行为止。
后面的幻灯片将使用 DBMS_SQL 程序包来说明游标管理。这可能会让不熟悉该程序包的人感到困惑;但是,它比 PRO*C 或 OCI 更容易使用。不过存在一点小问题:因为它将 FETCH 与 EXECUTE 一起执行,所以不能在跟踪中单独标识执行阶段。
步骤 2:分析语句
- 语句从用户进程传递到 Oracle 实例
- 如果共享 SQL 区域中没有相同的 SQL,则会创建 SQL 语句分析后的表示形式,并将其移到共享 SQL 区域
- 如果存在相同的 SQL,则可重用这些 SQL
在分析过程中,SQL 语句从用户进程传递到 Oracle 实例,SQL 语句分析后的表示形式被加载到共享 SQL 区。
转换和验证时要检查库高速缓存中是否已存在相应的语句。
对于已分配的语句,要检查是否存在数据库链接。
通常,分析阶段代表生成查询计划的阶段。
客户机软件可以延迟分析步骤以降低网络流量。也就是说,PARSE 与 EXECUTE 捆绑在一起执行,因此减少了到服务器的往返次数。
注:检查语句是否相同时,必须是所有方面都相同,包括大小写和空格。
步骤 3 和步骤 4:描述和定义
- 描述步骤提供有关选择列表项的信息;通过 OCI 应用程序输入动态查询时,会涉及该步骤。
- 定义步骤定义在变量中存储提取值所需的位置、大小和数据类型信息。
步骤 3:描述
仅当不知道查询结果的特征时,才需要有描述阶段,例如,用户以交互方式输入查询。在这种情况下,描述阶段确定查询结果的特征(数据类型、长度和名称)。描述告诉应用程序需要哪些选择列表项。例如,如果输入如下查询:
SQL> select * from employees;,
则需要有关 employees 表中的列的信息。
步骤 4:定义
在定义阶段,将为所定义的接收提取值的变量指定位置、大小和数据类型。这些变量称为定义变量。必要时,Oracle DB 将执行数据类型转换。
用户在使用 SQL*Plus 之类的工具时通常看不到这两个步骤。但是,使用 DBMS_SQL 或 OCI 时,必须在客户机上指定输出数据和设置区域。
步骤 5 和步骤 6:绑定和并行化
- 绑定任何绑定值:
–启用内存地址以存储数据值
–即使绑定值发生更改,也允许使用共享 SQL
- 使语句并行化:
–SELECT
–INSERT
–UPDATE
–MERGE
–DELETE
–CREATE
–ALTER
步骤 5:绑定
此时,Oracle DB 已知道 SQL 语句的含义,但现有的信息仍不足以运行语句。Oracle DB 还需要语句中列出的所有变量的值。获取这些值的过程称为绑定变量。
步骤 6:并行化
Oracle DB 可以并行执行 SQL 语句(如 SELECT、INSERT、UPDATE、MERGE 和 DELETE)以及一些 DDL 操作(如创建索引、创建含子查询的表和针对分区的操作)。并行化将使多个服务器进程执行 SQL 语句的工作,因此可以加快完成速度。
并行化会将一条语句的工作拆分给多个从属进程。
在分析时已经确定了语句是否可并行化,并建立了相应的并行计划。在执行时即可实施此计划(如果有足够的可用资源)。
步骤 7 到步骤 9
- 执行:
–促使 SQL 语句产生所需的结果
- 提取行:
–放入定义的输出变量中
–以表格式返回查询结果
–数组提取机制
- 关闭游标。
此时,Oracle DB 拥有所有必要的信息和资源,因此执行语句。如果语句是一个查询(不带 FOR UPDATE 子句)语句,则不需要锁定任何行,因为没有更改任何数据。但是,如果语句是 UPDATE 语句或 DELETE 语句,则在下一次对事务处理执行 COMMIT、ROLLBACK 或 SAVEPOINT 之前受该语句影响的所有行都将被锁住。这样可以确保数据的完整性。
对于有些语句,可以指定执行次数。这称为数组处理。假定执行次数为 n,则绑定和定义位置步骤要在大小为 n 的数组开始时完成。
在提取阶段,选择行并对行进行排序(如果查询要求),而且每个后续提取操作都会检索另一行结果,直到提取完最后一行为止。
处理 SQL 语句的最后一个阶段是关闭游标。
SQL 语句处理 PL/SQL:示例
SQL> variable c1 number
SQL> execute :c1 := dbms_sql.open_cursor;
SQL> variable b1 varchar2
SQL> execute dbms_sql.parse
2 (:c1
3 ,’select null from dual where dummy = :b1′
4 ,dbms_sql.native);
SQL> execute :b1:=’Y’;
SQL> exec dbms_sql.bind_variable(:c1,’:b1′,:b1);
SQL> variable r number
SQL> execute :r := dbms_sql.execute(:c1);
SQL> variable r number
SQL> execute :r := dbms_sql.close_cursor(:c1);
此示例汇总了前面讨论的各个步骤。
注:在此示例中,未展示提取操作。还可以将 EXECUTE 和 FETCH 操作组合为 EXECUTE_AND_FETCH,在一次调用中一起执行 EXECUTE 和 FETCH。用于远程数据库时,这可以减少网络往返次数。
SQL 语句分析:概览
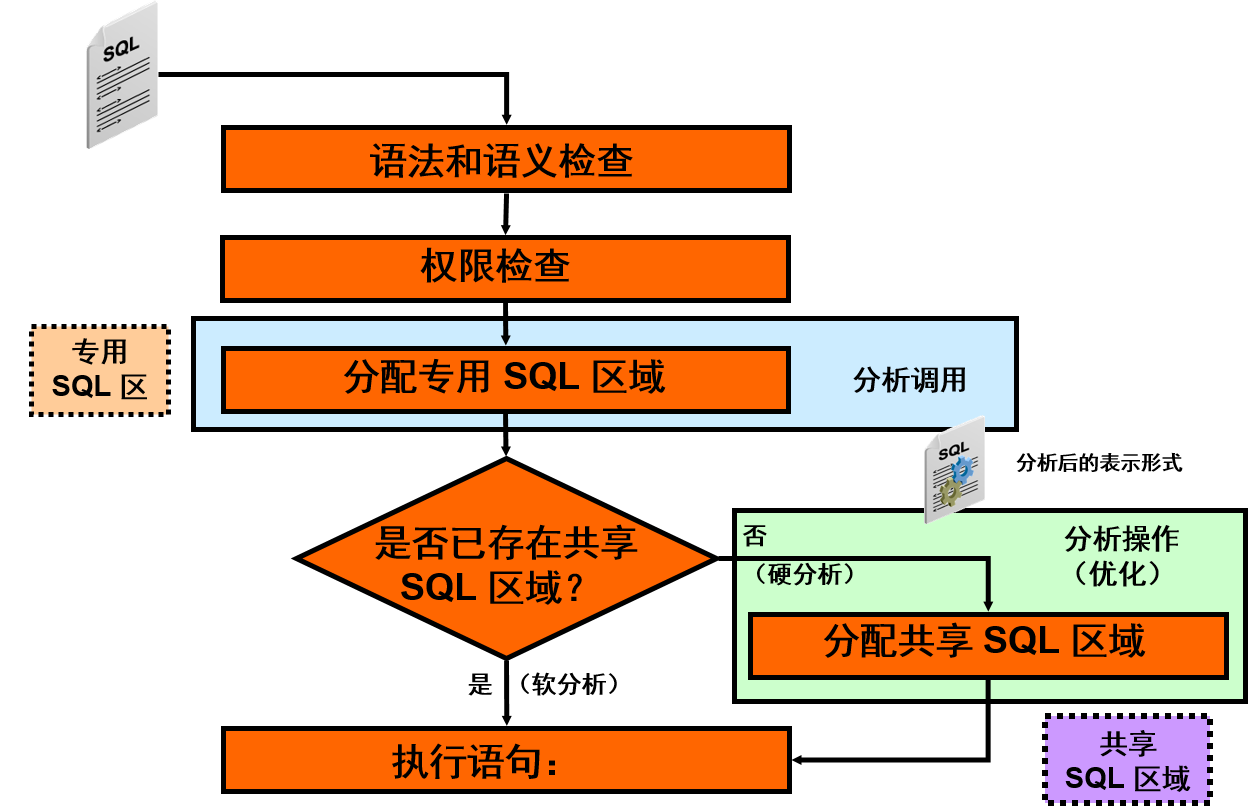
分析是 SQL 语句处理中的一个阶段。应用程序发出 SQL 语句时,会对 Oracle DB 发出一个分析调用。在分析调用过程中,Oracle DB 会执行下列操作:
- 检查语句的语法和语义是否有效
- 确定发出语句的进程是否有运行语句的权限
- 为语句分配一个专用 SQL 区域
- 确定在库高速缓存中是否已存在共享 SQL 区域(该区域包含语句分析后的表示形式)。如果已存在,则用户进程使用此分析后的表示形式,并立即运行语句。如果不存在,则 Oracle DB 生成语句分析后的表示形式,用户进程在库高速缓存中为语句分配一个共享 SQL 区域,并将语句分析后的表示形式存储在该区域中。
请注意对 SQL 语句发出分析调用的应用程序与实际分析语句的 Oracle DB 之间的差异。
- 应用程序发出的分析调用将 SQL 语句与某个专用 SQL 区域关联起来。语句与专用 SQL 区域关联之后,可以重复运行该语句,不需要应用程序发出分析调用。
Oracle DB 的分析操作会为 SQL 语句分配一个共享 SQL 区域。为语句分配了共享 SQL 区域后,可以重复运行该语句,无需重新分析。
相对于执行来说,分析调用和分析的成本会高得多,因此,请尽可能少执行它们。
注:虽然分析某个 SQL 语句会验证该语句,但分析只能找出可在语句执行之前发现的错误。因此,某些错误可能无法通过分析发现。例如,只有在执行阶段才会发觉并报告数据转换错误或数据错误(例如,尝试在主键中输入重复的值)和死锁这类错误或情形。
为什么需要优化程序
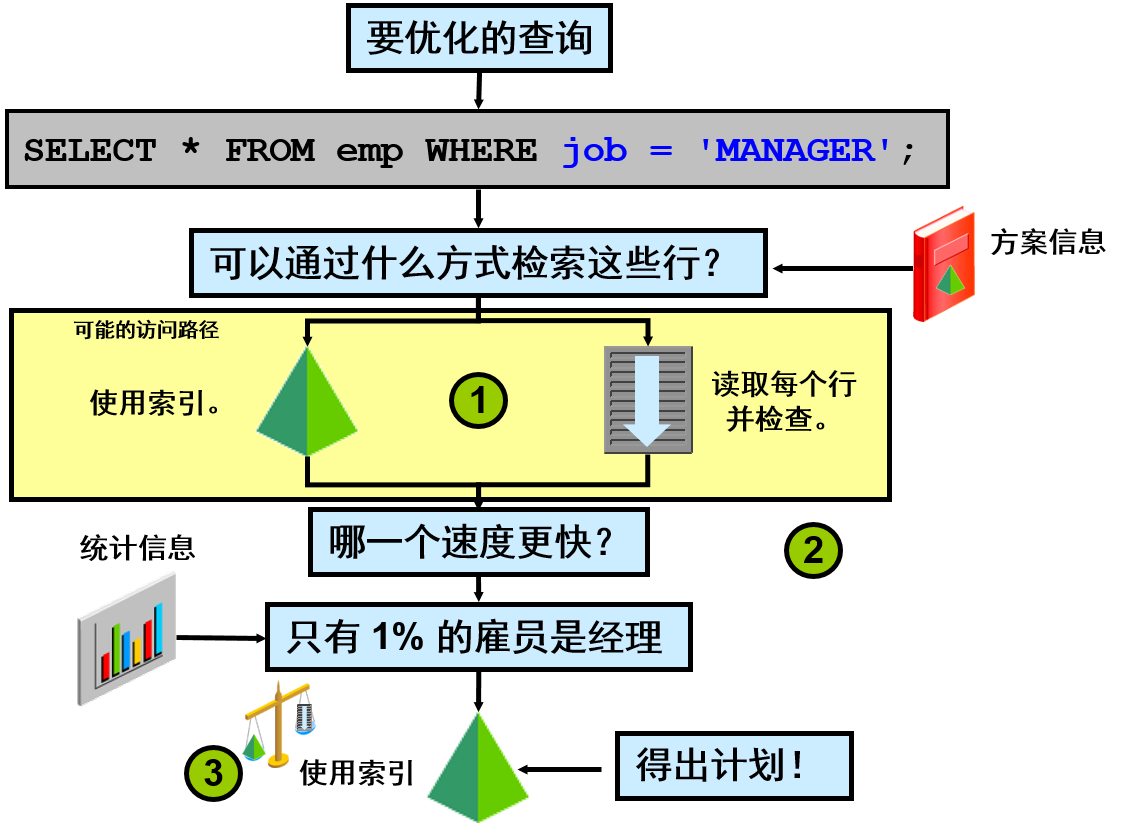

优化程序的目标始终是尽快返回正确的结果。
查询优化程序会考虑可用的访问路径,并采纳从 SQL 语句访问的方案对象(表或索引)的统计数据中获取的信息,尝试确定最高效的执行计划。
查询优化程序执行下列步骤:
- 优化程序根据可用的访问路径为 SQL 语句生成一组可能的计划。
- 优化程序在评估每个计划的成本时,会根据数据字典中的统计信息了解表的数据分配和存储特征,还会考虑语句访问的索引。
- 优化程序比较各个计划的成本,并选择成本最低的计划。
注:由于为特定查询找出最佳可行计划十分复杂,优化程序的目标是查找一个“好”计划,通常称为成本最佳计划。
幻灯片中的示例显示,如果统计信息发生变化,优化程序会调整其执行计划。在本例中,统计信息显示 80% 的雇员是经理。在该假定情形中,与使用索引相比,全表扫描可能是一种更好的解决方案。
在硬解析操作过程中进行优化
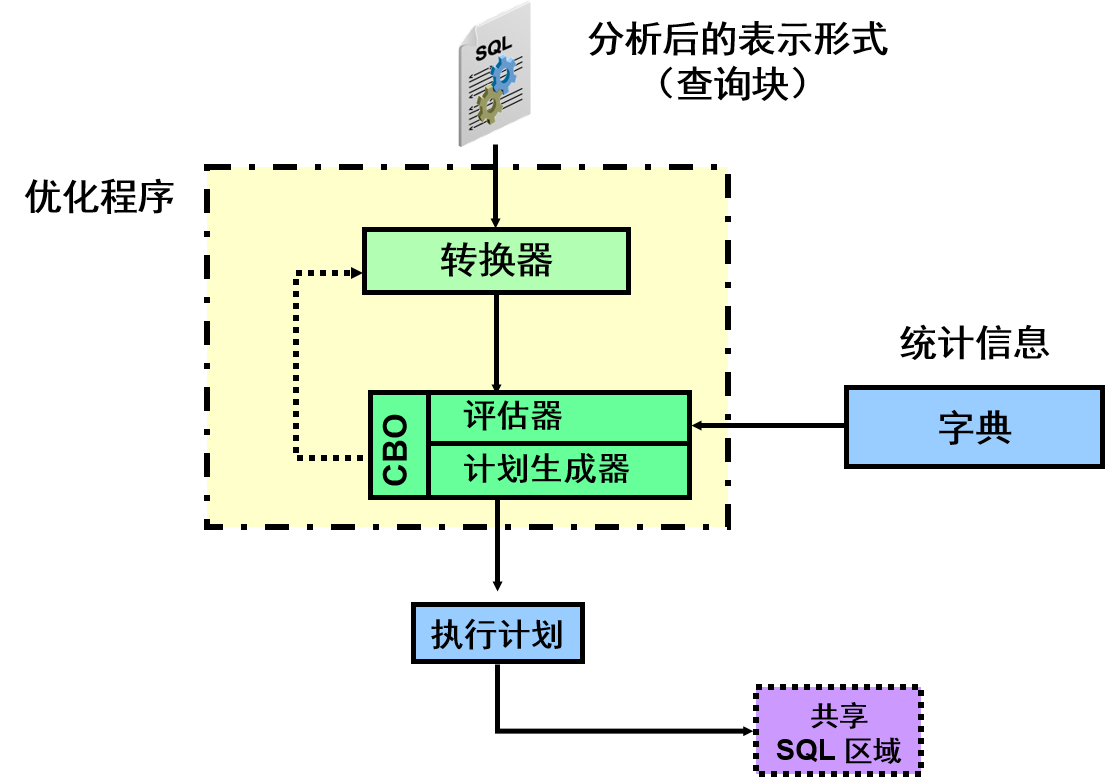
优化程序为 SQL 语句创建执行计划。
提交到系统的 SQL 查询先通过分析程序运行;分析程序会检查语法并分析语义。此阶段的结果称为语句分析后的表示形式,由一组查询块组成。查询块是一种针对表的自包含 DML。查询块可以是顶层 DML,也可以是子查询。然后,将这种分析后的表示形式发送到优化程序;优化程序执行三种主要功能:转换、评估和生成执行计划。
在执行成本计算之前,系统可能会将语句转换为等效语句,并计算等效语句的成本。
根据 Oracle DB 的版本,有些转换不会执行,有些转换始终执行,还有一些转换,虽然执行了,但由于其高成本,最后被弃用。
查询转换器的输入是分析后的查询,该查询用一组相互关联的查询块表示。查询转换器的主要目标是确定更改查询结构是否有益,以便生成更好的查询计划。查询转换器采用了多种查询转换技术,如应用传递性、合并视图、推入谓词、对子查询解除嵌套、重写查询、星形转换和 OR 扩展。
转换器:OR 扩展示例

如果查询包含 WHERE 子句,并且有多个使用 OR 运算符组合的条件,则优化程序会将其转换为使用集合运算符 UNION ALL 的等效复合查询(如果这样可以提高查询执行效率
的话)。
例如,如果每个条件都可以单独使用索引访问路径,优化程序就可以进行转换。优化程序会为产生的语句选择这样的执行计划:该计划使用不同的索引多次访问表,然后将各次的结果放到一起。如果估计的成本比原始语句的成本低,则执行此转换。
幻灯片中的示例假定 JOB 列和 DEPTNO 列上都有索引。这样,优化程序可以将原始查询转换为等效的查询(转换后的查询如幻灯片中所示)。基于成本的优化程序 (CBO) 在决定是否进行转换时,会将使用全表扫描执行原始查询的成本与执行转换后的查询的成本进行比较。
转换器:子查询解除嵌套示例
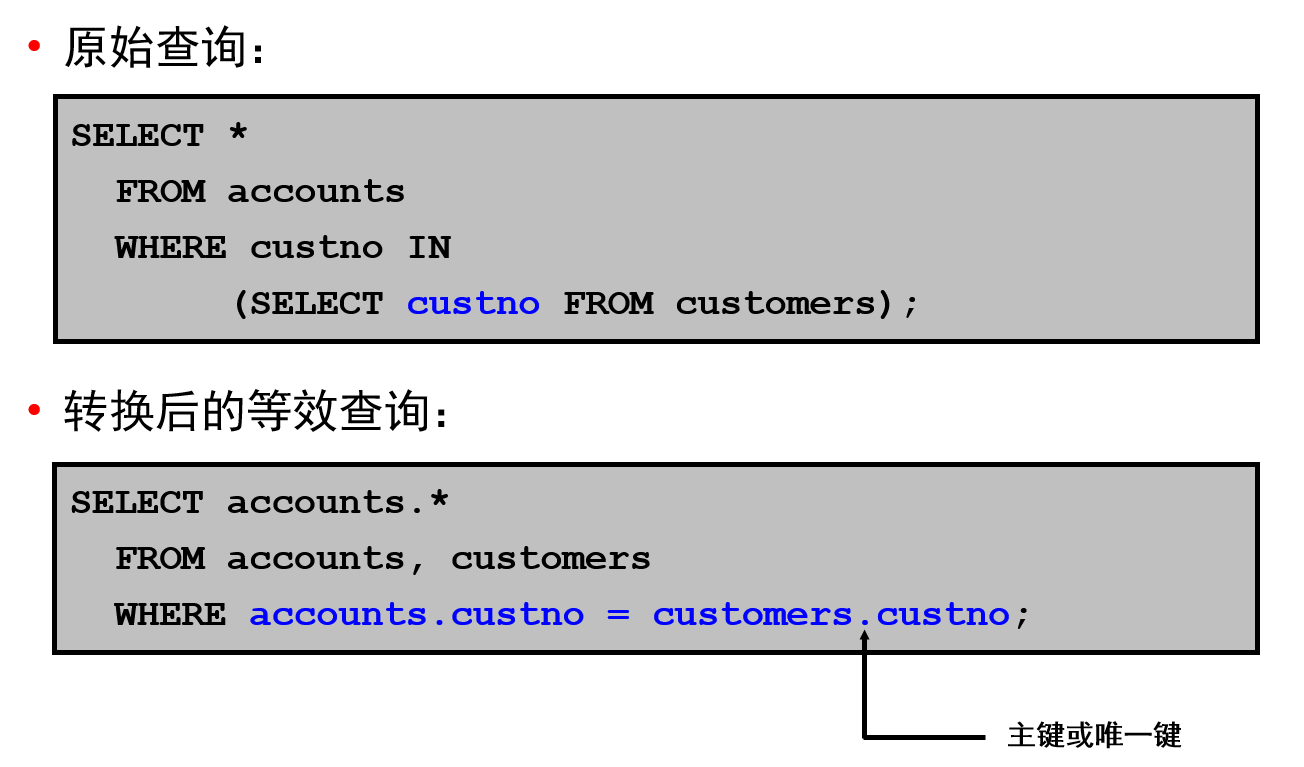
为了解除查询嵌套,优化程序可能会选择将原始查询转换为等效的 JOIN 语句,然后优化 JOIN 语句。
仅当生成的 JOIN 语句保证能像原始语句一样返回完全相同的行时,优化程序才会执行此项转换。通过此项转换,优化程序可以利用联接优化程序技术。
在幻灯片上的示例中,如果 customers 表的 CUSTNO 列是主键或者有一个 UNIQUE 约束条件,优化程序就可以将复杂查询转换为所示的 JOIN 语句(该语句保证可以返回相同的
数据)。
如果优化程序不能将复杂语句转换为 JOIN 语句,则将为父语句和子查询分别选择执行计划,就像它们是单独的语句一样。然后,优化程序执行子查询,并使用返回的行执行父
查询。
注:子查询包含聚集函数(如 AVG)的复杂查询不能转换为 JOIN 语句。
转换器:视图合并示例
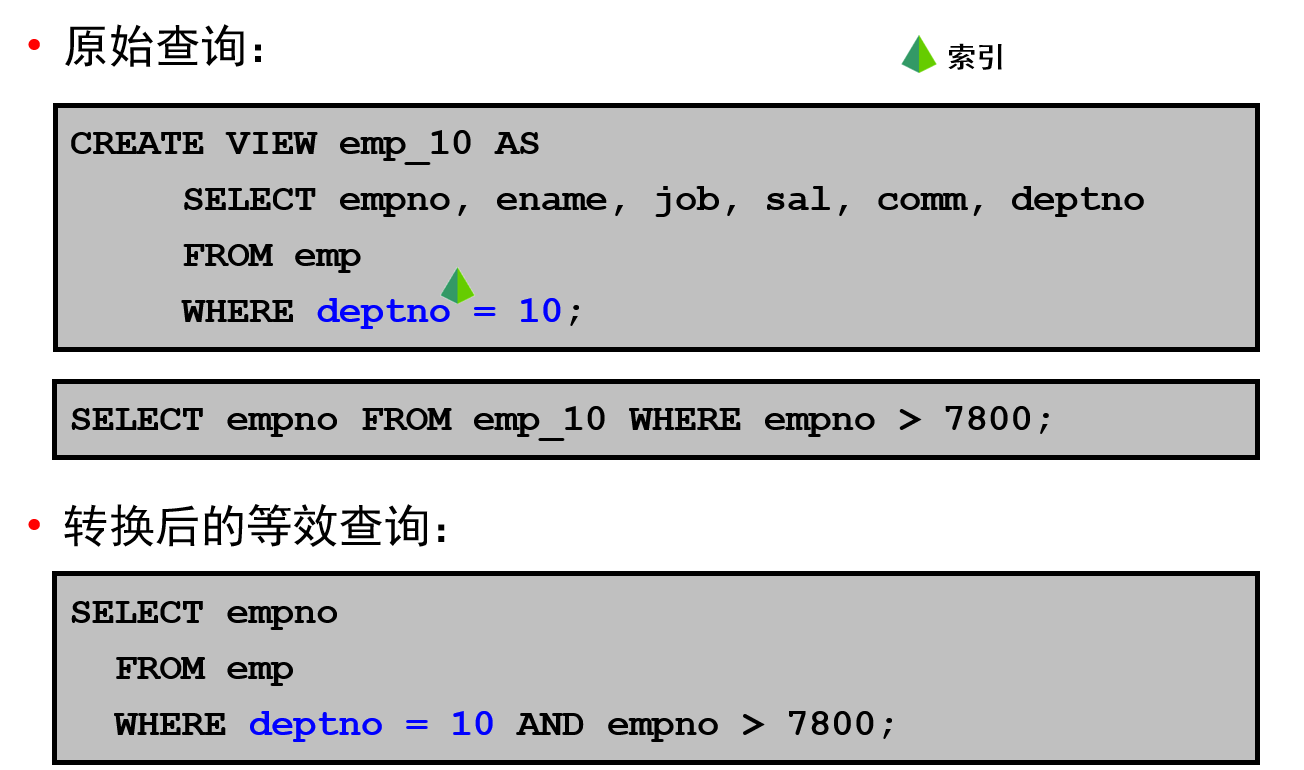
为了将视图查询合并到访问语句的一个引用查询块中,优化程序会将视图的名称替换为查询块中其基表的名称,并将视图查询的 WHERE 子句的条件添加到访问查询块的 WHERE 子句中。
这种优化适用于选择-映射-联接视图,这种视图仅包含选择、映射和联接。即,这类视图不包含集合运算符、聚集函数、DISTINCT、GROUP BY、CONNECT BY 等等。
本例中的视图用于显示在部门 10 中工作的所有雇员的信息。
在幻灯片中,位于视图定义下方的查询要访问该视图。该查询将选择 ID 大于 7800 并且在部门 10 中工作的雇员。
优化程序可以将该查询转换为幻灯片中所示的等效查询,该转换后的查询将访问视图的基表。
如果在 DEPTNO 列或 EMPNO 列上有索引,则生成的 WHERE 子句就可使这些索引变为可用。
转换器:谓词推入示例
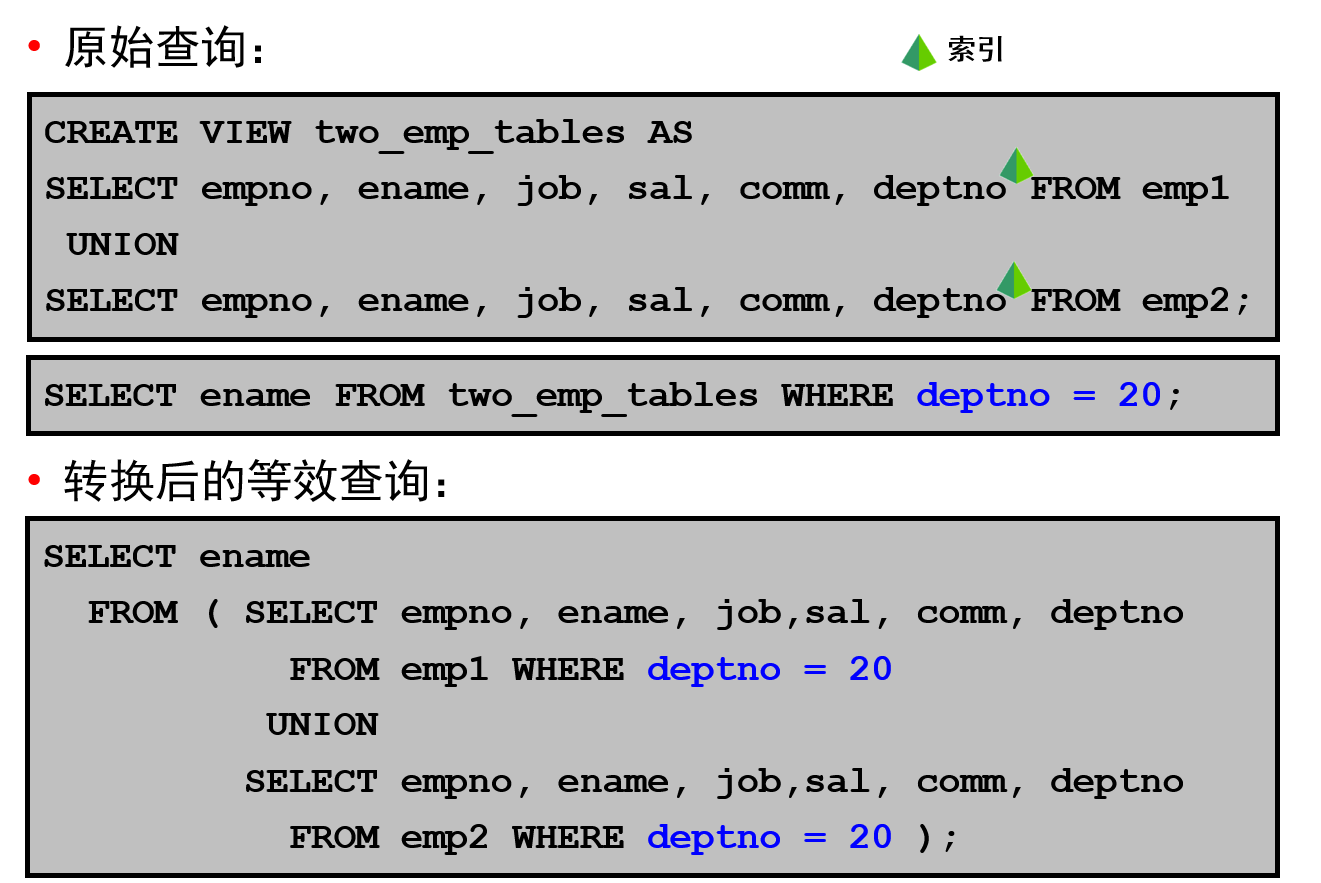
优化程序可以对访问不可合并视图的查询块进行转换,即将查询块的谓词推入视图查询中。
在幻灯片上的示例中,two_emp_tables 视图是两个 employee 表的并集。该视图是用一个复合查询定义的,该复合查询使用集合运算符 UNION 连接。
在幻灯片中,位于视图定义下方的查询要访问该视图。该查询选择任意一个表中在部门 20 中工作的所有雇员的 ID 和姓名。
由于视图被定义为复合查询,因此优化程序无法将视图查询合并到访问查询块中。优化程序此时可以采用另一种方法,即将访问语句的谓词(WHERE 子句的条件 deptno = 20)推入视图的复合查询中,以此转换访问语句。幻灯片中展示了转换后的等效查询。
如果在这两个表的 DEPTNO 列上有索引,则生成的 WHERE 子句就可使这些索引变为可用。
转换器:传递性示例

如果 WHERE 子句中的两个条件有某个公用列,则优化程序有时可以使用传递性原则推断出第三个条件。然后,优化程序可以使用推断出的条件来优化语句。
通过该推断出的条件,基于原始条件不可用的索引访问路径就能变为可用。
幻灯片中的示例展示了这种情况。原始查询的 WHERE 子句包含两个条件,其中的每个条件都使用 EMP.DEPTNO 列。通过使用传递性,优化程序可以推断出下列条件:dept.deptno = 20
如果在 DEPT.DEPTNO 列上存在索引,通过此条件,使用该索引的访问路径就变为可用。
注:优化程序仅推断将列与常量表达式关联的条件,而非将列与其它列关联的条件。
基于成本的优化程序
- 代码片段:
–评估器
–计划生成器
- 评估器确定计划生成器提出的优化建议的成本。
–成本:优化程序对优化特定语句所需的标准化 I/O 次数的最恰当评估
- 计划生成器:
–尝试不同的语句优化技术
–使用评估器计算每个优化建议的成本
–根据成本选择最佳优化建议
–为最佳优化方案生成执行计划
评估器代码和计划生成器代码通常合称为基于成本的优化程序 (CBO)。
评估器生成三种类型的度量:选择性、基数和成本。这些度量彼此相关。基数是根据选择性导出的,成本通常取决于基数。评估器的最终目的是评估指定计划的整体成本。如果有可用的统计信息,则评估器在计算度量时将使用这些信息提高准确度。
计划生成器的主要功能是尝试指定查询的各种可能计划,并挑选出成本最低的计划。有许多不同的计划可以使用,因为可以使用不同访问路径、联接方法和联接顺序的各种组合,以不同方式访问和处理数据,并生成相同的结果。某个查询块可能计划的数量与 FROM 子句中的联接项目的数量成比例。此数量会随联接项目的数量呈幂指数增长。
优化程序使用各种信息来确定最佳路径:WHERE 子句、统计信息、初始化参数、提供的提示和方案信息。
评估器:选择性

- 选择性是特定谓词或谓词组合检索到的行集占总行数的估计
比例。 - 它以一个 0.0 到 1.0 之间的值表示:
–选择性高:行数比例小
–选择性低:行数比例大
- 选择性计算:
–如果没有统计信息:使用动态采样
–如果没有直方图:假定行平均分布
- 统计信息:
–DBA_TABLES 和 DBA_TAB_STATISTICS (NUM_ROWS)
–DBA_TAB_COL_STATISTICS(NUM_DISTINCT、DENSITY、HIGH/LOW_VALUE…)
选择性表示行集中的一部分行。行集可以是一个基表、一个视图或者联接或 GROUP BY 运算符的结果。选择性与查询谓词(如 last_name = ‘Smith’)或谓词组合(如 last_name = ‘Smith’ AND job_type = ‘Clerk’)相关联。谓词的作用相当于过滤器,可以从行集中过滤掉一定数量的行。因此,谓词的选择性表示行集中通过谓词测试的行占总行数的百分比。选择性用从 0.0 到 1.0 的值表示。选择性 0.0 表示未从行集中选择任何行,选择性 1.0 表示选择了所有行。
如果没有可用的统计信息,则优化程序将使用动态采样或内部默认值,具体取决于 OPTIMIZER_DYNAMIC_SAMPLING 初始化参数的值。如果有可用的统计信息,则评估器将使用这些信息来评估选择性。例如,对于等式谓词 (last_name = ‘Smith’),选择性等于 LAST_NAME 非重复值的数量 (n) 的倒数,因为查询选择的行包含 n 个不同值中的一个。因此,这假定数值是平均分布的。如果在 LAST_NAME 列中有可用的直方图,则评估器将使用该图,而不使用非重复值的数量。直方图获取了列中不同值的分布,因此得出的选择性估计值更符合实际。
注:如果列包含的值的重复项数量变化很大(数据偏差),则列必须有直方图。
评估器:基数

- 执行计划中的某个特定操作预计会检索的行数。
- 用于确定联接、过滤和排序成本的重要数值
- 简单示例:
SELECT days FROM courses WHERE dev_name = ‘ANGEL’;
–DEV_NAME 中的不同值数量为 203。
–COURSES 中的行数(原始基数)为 1018。
–选择性 = 1/203 = 4.926xe-03
–基数 = (1/203)x1018 = 5.01(舍入到 6)
查询的执行计划中的特定操作的基数表示该特定操作估计会检索的行数。大多数时候,行源会是基表、视图,或者是联接或 GROUP BY 运算符的结果。
计算联接操作的成本时,必须了解驱动行源的基数。例如,对于嵌套循环联接,驱动行源定义了系统探测内部行源的频率。
因为排序成本与要排序的行的大小和数量相关,所以基数数值对排序成本的计算也至关
重要。
在幻灯片上的示例中,优化程序根据假定的统计信息知道在 DEV_NAME 列中有 203 个不同的值,并且 COURSES 表的总行数为 1018。根据上述假定,优化程序推导出 DEV_NAME=’ANGEL’ 谓词的选择性为 1/203(假定不存在直方图),还推导出查询的基数是 (1/203)x1018。然后,将此数值舍入到最近的整数 6。
评估器:成本

- 成本是优化程序对优化特定语句所需的标准化 I/O 次数的最恰当评估。
- 成本单位是一次标准化的单个块随机读取 (SRds):
–1 成本单位 = 1 SRds
- 成本公式将三种不同的成本单位合并为标准成本单位。
语句的成本是优化程序对优化该语句所需的标准化输入/输出 (I/O) 次数的最恰当评估。本质上,成本是以单个块随机读取次数为单位的一个标准化值。
优化程序测量出的标准成本度量以单个块随机读取次数为单位,因此一个成本单位对应于一次单个块随机读取。幻灯片中所示的公式合并了三种不同的成本单位:
- 完成所有单个块随机读取的估计时间
- 完成所有多块读取的估计时间
- CPU 将语句处理为一个标准成本单位的估计时间
该模型包括了 CPU 成本计算,因为在大多数情况下,CPU 使用率和 I/O 次数一样重要;它经常是成本的唯一来源(如在内存中排序、散列运算、谓词求值和高速缓存的 I/O)。
这种模型可直接用于串行执行。对于并行执行,会在计算 #SRds、#MRds 和 #CPUCycles 的估计值时进行必要的调整。
注: #CPUCycles 包括处理查询的 CPU 成本(纯 CPU 成本)和检索数据的 CPU 成本(获取缓冲区高速缓的 CPU 成本)。
 
计划生成器
select e.last_name, c.loc_id from employees e, classes c where e.emp_id = c.instr_id; Join order[1]: DEPARTMENTS[D]#0 EMPLOYEES[E]#1 NL Join: Cost: 41.13 Resp: 41.13 Degree: 1 SM cost: 8.01 HA cost: 6.51 Best::JoinMethod: Hash Cost: 6.51 Degree: 1 Resp: 6.51 Card: 106.00 Join order[2]: EMPLOYEES[E]#1 DEPARTMENTS[D]#0 NL Join: Cost: 121.24 Resp: 121.24 Degree: 1 SM cost: 8.01 HA cost: 6.51 Join order aborted Final cost for query block SEL$1 (#0) All Rows Plan: Best join order: 1 +----------------------------------------------------------------+ | Id | Operation | Name | Rows | Bytes | Cost | +----------------------------------------------------------------+ | 0 | SELECT STATEMENT | | | | 7 | | 1 | HASH JOIN | | 106 | 6042 | 7 | | 2 | TABLE ACCESS FULL | DEPARTMENTS| 27 | 810 | 3 | | 3 | TABLE ACCESS FULL | EMPLOYEES | 107 | 2889 | 3 | +----------------------------------------------------------------+
计划生成器会尝试不同的访问路径、联接方法和联接顺序,为查询块查找各种计划。最后,计划生成器将为语句提供最佳执行计划。幻灯片展示了为 select 语句生成的优化程序跟踪文件的一个片段。如该跟踪文件所示,计划生成器有六种可能的计划(即六种不同的计划)需要测试:两种联接顺序,每种顺序有三种不同的联接方法。此示例假定不存在索引。
要检索行,可以首先将 DEPARTMENTS 表与 EMPLOYEES 表联接。对于该特定联接顺序,可以使用优化程序知道的三种可能联接机制:嵌套循环、排序合并或散列联接。对于每种可能的机制,都有相应计划的成本。最佳计划是显示在跟踪记录末尾的那个计划。
在查找成本最低的计划时,计划生成器使用内部中断来减少计划测试数量。基于当前最佳计划的成本确定是否中断。如果当前最佳成本很大,则计划生成器将提高难度(即查找其它备选计划),以便找出成本更低的更好计划。如果当前最佳成本很小,则计划生成器会快速结束搜索,因为成本的降低空间已经很小了。如果计划生成器首先尝试的初始联接顺序很合适,即所生成的计划的成本接近最佳成本,则中断的效果会很好。要找出合适的初始联接顺序很难。
注:访问路径、联接方法和计划将在“优化程序运算符”和“解释执行计划”这两课中做详细讨论。
控制优化程序的行为
- CURSOR_SHARING: SIMILAR、EXACT、FORCE
- DB_FILE_MULTIBLOCK_READ_COUNT
- PGA_AGGREGATE_TARGET
- STAR_TRANSFORMATION_ENABLED
- RESULT_CACHE_MODE: MANUAL、FORCE
- RESULT_CACHE_MAX_SIZE
- RESULT_CACHE_MAX_RESULT
- RESULT_CACHE_REMOTE_EXPIRATION
以下参数可以控制优化程序行为:
- CURSOR_SHARING 确定什么样的 SQL 语句可以共享相同的游标:
-FORCE:强制那些只是有一些文字差异但其它方面相同的语句共享游标(除非这些文字会影响语句的意义)。
-SIMILAR:使那些只是有一些文字差异但其它方面相同的语句共享游标(除非这些文字会影响语句的意义或者影响计划的优化程度)。如果强制在相似(但不相同)的语句间共享游标,则可能会在某些决策支持系统 (DSS) 应用程序中或者使用存储大纲的应用程序中产生意外结果。
-EXACT:仅允许具有相同文本的语句共享同一个游标。这是默认设置。
- DB_FILE_MULTIBLOCK_READ_COUNT 是可用于在表扫描或索引快速完全扫描过程中最大程度减少 I/O 次数的参数之一。该参数指定在一次顺序扫描过程中,一次 I/O 操作的最大块读取数。执行全表扫描或索引快速完全扫描所需的 I/O 总数取决于多种因素,如段的大小、多块读取计数以及是否对操作使用了并行执行。从 Oracle Database 10gR2 开始,此参数的默认值对应于可高效执行的最大 I/O 大小。此值与平台相关,在多数平台上为 1 MB。
- 由于参数用块表示,因此系统会自动计算一个值,该值等于可高效执行的最大 I/O 大小除以标准块大小。请注意,如果会话数量极大,则会减少多块读取计数值,以避免缓冲区高速缓存中充斥太多表扫描缓冲区。即使默认值较大,但如果不设置此参数,优化程序也不会倾向于选择大型计划。仅当将此参数显式设置为一个较大值时,优化程序才会选择大型计划。一般情况下,如果不显式设置此参数(或设置为 0),则在计算全表扫描和索引快速完全扫描的成本时,优化程序将使用默认值 8。对于联机事务处理 (OLTP) 和批处理环境,此参数的值通常在 4 到 16 这个范围内。对于 DSS 和数据仓库环境,此参数的值越大越好。如果此参数的值很大,则优化程序就更有可能选择全表扫描,而不选择索引。
- PGA_AGGREGATE_TARGET 指定可供与该实例关联的所有服务器进程使用的目标 PGA 内存总计。将 PGA_AGGREGATE_TARGET 设置为一个非零值相当于将 WORKAREA_SIZE_POLICY 参数设置为 AUTO。这意味着系统将自动调整内存密集型 SQL 运算符(如排序、GROUP BY、散列联接、位图联接和位图创建)使用的 SQL 工作区大小。非零值是此参数的默认值,因为除非另行指定,否则系统会将其设置为 SGA 大小的 20% 或 10 MB(取两者中的较大值)。将 PGA_AGGREGATE_TARGET 设置为 0 时,也会自动将 WORKAREA_SIZE_POLICY 参数设置为 MANUAL。这意味着会使用 *_AREA_SIZE 参数来调整 SQL 工作区的大小。系统会尝试通过调整工作区大小来适应专用内存,将专用内存大小保持在此参数指定的目标值以下。如果增加该参数值,则也会间接地增加分配给工作区的内存。因此,可以有更多的内存密集型操作完全在内存中运行,只有较少的内存密集型操作将转至磁盘运行。设置此参数时,应检查系统上可供 Oracle 实例使用的总内存,然后从中减去 SGA。可以将剩余内存分配至 PGA_AGGREGATE_TARGET。
- STAR_TRANSFORMATION_ENABLED 确定是否将基于成本的查询转换应用于星形查询。此项优化将在“案例分析:星形转换”一课中介绍。
- 查询优化程序根据初始化参数文件中 RESULT_CACHE_MODE 参数的设置管理结果高速缓存机制。可以使用此参数确定优化程序是否将查询结果自动发送到结果高速缓存中。可能的参数值包括 MANUAL 和 FORCE:
-设置为 MANUAL(默认值)时,必须使用 RESULT_CACHE 提示,指定要在高速缓存中存储特定结果。
-如果设置为 FORCE,则所有结果都将存储在高速缓存中。对于 FORCE 设置,如果语句中包含 [NO_]RESULT_CACHE 提示,则该提示优先于参数设置。
- 分配给结果高速缓存的内存大小取决于 SGA 的内存大小以及内存管理系统。可以通过设置 RESULT_CACHE_MAX_SIZE 参数来更改分配给结果高速缓存的内存。如果将结果高速缓存的值设为 0,则会禁用此结果高速缓存。此参数的值将四舍五入到不超过指定值的 32 KB 的最大倍数。如果四舍五入得到的值是 0,则会禁用该功能。
- 使用 RESULT_CACHE_MAX_RESULT 参数可以指定任一结果可使用的最大高速缓存量。默认值为 5%,但可指定 1 到 100 之间的任何百分比值。
- 使用 RESULT_CACHE_REMOTE_EXPIRATION 参数可以指定依赖于远程数据库对象的结果保持有效的时间(以分钟为单位)。默认值为 0,表示不会高速缓存使用远程对象的结果。例如,如果结果使用的远程表在远程数据库上发生了更改,则将此值设置为一个非零值可能会产生过时的答案。
控制优化程序的行为
- OPTIMIZER_INDEX_CACHING
- OPTIMIZER_INDEX_COST_ADJ
- OPTIMIZER_FEATURES_ENABLED
- OPTIMIZER_MODE: ALL_ROWS、FIRST_ROWS、FIRST_ROWS_n
- OPTIMIZER_CAPTURE_SQL_PLAN_BASELINES
- OPTIMIZER_USE_SQL_PLAN_BASELINES
- OPTIMIZER_DYNAMIC_SAMPLING
- OPTIMIZER_USE_INVISIBLE_INDEXES
- OPTIMIZER_USE_PENDING_STATISTICS
- OPTIMIZER_INDEX_CACHING 参数与嵌套循环或 INLIST 迭代程序一起使用时,可控制索引探测的成本计算。OPTIMIZER_INDEX_CACHING 的值范围是 0 到 100,表示缓冲区高速缓存中的索引块的百分比,可用于修改优化程序有关嵌套循环和 INLIST 迭代程序的索引高速缓存的假设。值 100 表示有可能在缓冲区高速缓存中找到 100% 的索引块,优化程序会相应地调整索引探测或嵌套循环的成本。此参数的默认值为 0,该值将使优化程序采取默认行为。请慎重使用此参数,因为执行计划可能会因采用索引高速缓存而更改。
- OPTIMIZER_INDEX_COST_ADJ 可用于调整优化程序在选择访问路径时的行为,提高或降低其选择索引的倾向性。即,提高或降低优化程序选择索引访问路径,而不选择全表扫描的可能性。值的范围是 1 到 10000。此参数的默认值为 100%,此时优化程序将按常规成本评估索引访问路径。设为其它值时,优化程序以其相对于常规成本的百分比评估访问路径。例如,设置为 50 将使索引访问路径的成本大约是正常成本的一半。
- OPTIMIZER_FEATURES_ENABLED 相当于一个综合参数,用于启用某一 Oracle 版本号对应的一系列优化程序功能。
例如,如果您将数据库从版本 10.1 升级到 11.1,但希望 保持版本 10.1 的优化程序行为,则可通过将此参数设置为 10.1.0 做到这一点。以后,可以通过将参数设置为 11.1.0.6,尝试版本 11.1 及其之前的版本引入的增强功能。但是,不建议将 OPTIMIZER_FEATURES_ENABLE 参数显式设置为一个较早的版本。要避免因执行计划更改而可能出现的 SQL 性能下降,请考虑换用 SQL 计划管理。
- OPTIMIZER_MODE 用于建立在选择实例或会话的优化方法时使用的默认行为。可能的值包括:
-ALL_ROWS:优化程序对会话中的所有 SQL 语句使用基于成本的方法,不考虑是否存在统计信息;且优化目标为吞吐量达到最佳(用尽可能少的资源完成整个语句)。这是默认值。
-FIRST_ROWS_n:优化程序使用基于成本的方法,不考虑是否存在统计信息;且优化目标为返回前 n 个行的响应时间达到最佳,其中 n 可以等于 1、10、100 或 1000。
-FIRST_ROWS:优化程序结合使用成本和试探值查找一个最佳计划,实现快速提供前几行。使用试探值有时会导致查询优化程序生成的计划的成本明显大于不应用试探值的计划的成本。提供 FIRST_ROWS 是为了向后兼容和保持计划稳定性;其它情况下,可换用 FIRST_ROWS_n。
- OPTIMIZER_CAPTURE_SQL_PLAN_BASELINES 启用或禁用自动识别可重复的 SQL 语句,以及为此类语句生成 SQL 计划基线。
- OPTIMIZER_USE_SQL_PLAN_BASELINES 启用或禁用 SQL 管理库中存储的 SQL 计划基线。如果启用,优化程序将为正在编译的 SQL 语句查找 SQL 计划基线。如果在 SQL 管理库中找到了一个 SQL 计划基线,则优化程序将计算每个基线计划的成本,并挑选成本最低的计划。
- OPTIMIZER_DYNAMIC_SAMPLING 控制优化程序执行的动态采样的级别。如果 OPTIMIZER_FEATURES_ENABLE 设置为:
-10.0.0 或更高版本,则默认值为 2
-9.2.0,则默认值为 1
-9.0.1 或更低,则默认值为 0
- OPTIMIZER_USE_INVISIBLE_INDEXES 允许或禁止使用不可见的索引。
- OPTIMIZER_USE_PENDING_STATISTICS 指定优化程序在编译 SQL 语句时是否使用暂挂统计信息。
注:本课程以后将介绍不可见的索引、暂挂统计信息和动态采样。
优化程序功能和 Oracle DB 版本 OPTIMIZER_FEATURES_ENABLED

OPTIMIZER_FEATURES_ENABLED 相当于一个综合参数,用于启用某一 Oracle 版本号对应的一系列优化程序功能。幻灯片中的表描述了部分优化程序功能,这些功能是根据 OPTIMIZER_FEATURES_ENABLED 参数中指定的值启用的。

Comment